简介: 云计算与大规模数据分析是相辅相成的,云的优点包括灵活性、随需应变的资源访问和实用工具式的计费,而大规模数据处理/分析提供了一个利用云资源的框架。云与 Hadoop 的结合让处理大量的结构化与非结构化数据成为可能。在本文中,作者将解释如何开始在 IBM SmartCloud Enterprise 上使用 Hadoop(以 InfoSphere? BigInsights Basic 的形式)。我们还将了解如何建立由三个节点组成的集群并确认它能够有效工作。
云计算与大规模数据分析这两个技术领域如今越来越流行:
- 云计算提供了灵活性、随需应变的资源访问与实用工具式计费等优势。
- 使用 Hadoop 的大规模数据处理与分析提供了一个框架,通过将工作负载分散到一个计算机集群中来充分利用这些资源。
由于云和 Hadoop 的出现,及时处理大量的结构化或非结构化数据目前已成为可能。尽管 Hadoop 并非专为与云一起提供的虚拟化环境而设计,但云仍然提供了一个易于搭建和高性价比的环境。在物理节点上运行 Hadoop 作业可能比在云上的虚拟化节点上运行相同作业要好;不过, 云让所有类型的用户都能运行 Hadoop 作业,这意味着用户能够操作大规模数据,而这在过去是不可能的。
目前还缺乏关于了解如何配置并管理云和 Hadoop 技术的技巧。通过使用本文中的实践指导,您应该能够快速而又高效地掌握这些技术。本文向您介绍:
- 在 IBM SmartCloud Enterprise 上预备三个实例以组建由三节点组成的集群的过程。
- 如何通过停止与启动所有 Hadoop 组件、测试一些命令以及检查 Web 控制台来验证集群。
您应该能够遵照本文中的指示组建一个能满足您需求的更大集群。
准备知识
本文中使用了 IBM InfoSphere BigInsights Basic 软件(简称 BigInsights)。BigInsights 是 IBM 发行的拥有额外功能的 Hadoop。基本版是免费的。在 侧边栏中可找到更多信息。
如果您是 Hadoop 方面的新手,您可以学习免费的在线课程 (BigDataUniversity.com),其中包括一些视频与实验练习。该课程包含本文中描述的组建过程的一段视频演示,以及在 IBM Cloud 上运行一些 Hadoop 命令的视频演示。这些材料包含在课程 “Lesson 1: Hands-on lab: Creating your own Hadoop cluster, Option 3” 中。如果您想学习更加详细的课程,IBM 提供了收费的 “InfoSphere BigInsights Essential” 课程。请参见 侧边栏 中关于这些资源的链接。
如果您愿意在阅读指导说明的同时尝试这些实践练习,请继续阅读。
准备好开始了吗?您需要有一个 IBM Cloud 账号。
云上的数据分析入门
- 为了在 IBM Cloud 中预备三个实例来组建由三节点组成的集群,并验证和测试您的集群,请执行以下操作:
- 登录到 IBM Cloud 中。
- 预备一个 BigInsights Master 节点实例。
- 预备一个 BigInsights Data 节点实例。
- 核实您的 Hadoop 集群正在工作。
步骤 1:登录到 IBM Cloud
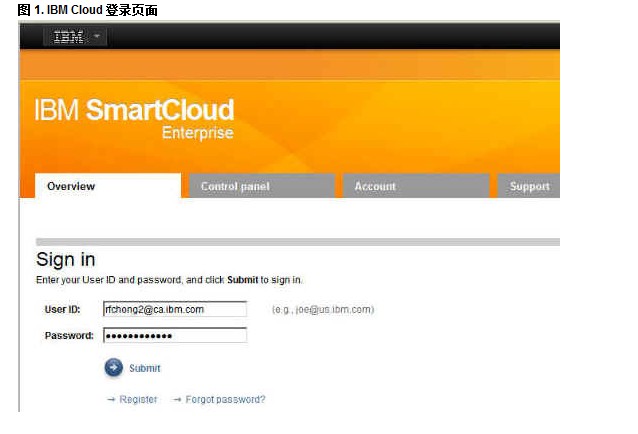
- 打开 IBM Cloud 门户页面 并登录。
- 输入您的用户 ID 和密码,然后单击 Submit。
图 1. IBM Cloud 登录页面
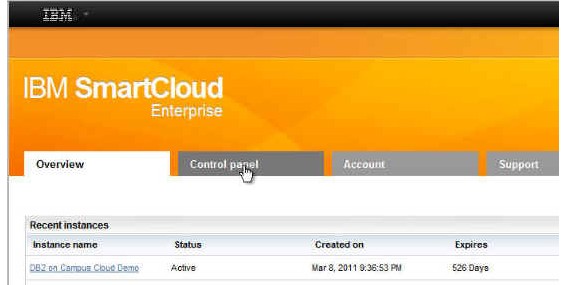
3.登录之后,IBM Cloud 仪表板将打开并自动选择 Overview 选项卡,如图 2 所示。其上显示了您过去配给的实例。单击 Control panel 选项卡。
图 2. IBM Cloud 仪表板
步骤 2:预备一个 BigInsights 主节点实例
本文撰写之际,IBM Cloud 为 BigInsights 提供了两种类型的映像:
- IBM BigInsights Basic 1.1 Hadoop Master 节点
- IBM BigInsights Basic 1.1 Hadoop Data 节点
这些映像运行在带有 “pay as you go” 选项的 64 位 RedHat Enterprise Linux (RHEL) 5.6 之下。如前所述,BigInsights Basic 版本是免费的,但是使用 RHEL 与 IBM Cloud 基础架构的费用为 0.30 美元/每小时。
Hadoop 使用一种主从架构,其中主结构中包括 NameNode 与 JobTracker 节点,而从属结构中包括 DataNode 与 TaskTracker 节点。
通过配置 Hadoop,您可以在以下三种模式中的一种模式下工作:
- 单机模式:不启动所有组件,在一个节点上工作。
- 伪分布模式:启动所有组件,在一个节点上工作。
- 完全分布模式:启动所有组件,并要求在多个节点上工作。
单机模式与伪分布模式通常用在开发或测试中,而完全分布模式通常用在生产环境中。
本文假定您在伪分布模式或完全分布模式下工作,具体使用哪种模式取决于除了 Hadoop Data 节点之外您是否提供了 Hadoop Master 节点。
- 如果您只提供一个 Hadoop Master 节点,那么只能在一个节点上工作,即在伪分布模式下工作。
- 如果除了 Hadoop Master 节点之外,您还提供了一个或多个 Hadoop Data 节点,那么您是在完全分布模式下工作。
IBM Cloud BigInsights 已经经过配置,因此只要在配给 Hadoop Data 节点时指定 Hadoop Master 节点的 IP 地址,便可轻松构建集群。必须首先提供 Hadoop Master 节点实例。
如果您想在单机模式下工作,可以预备一个 BigInsights Master 节点,并在 Hadoop 中设置这种操作模式(注释掉文件 core-site.xml、hdfs-site.xml 与 mapred-site.xml中的所有参数)。
让我们预备一些 Hadoop Master 节点实例。
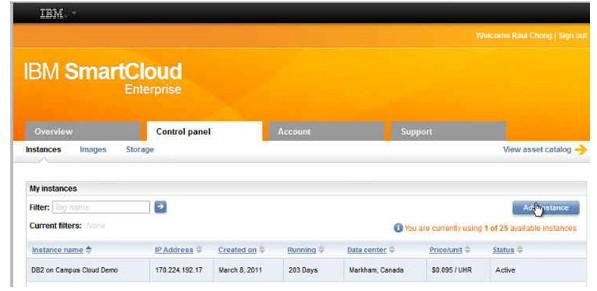
在 Control panel 选项卡中,单击 Add instance。
图 3. 添加一个 BigInsights 实例
选择您将在其上运行实例的数据中心。
2.选择您将在其上运行实例的数据中心。
图 4. 选择一个数据中心
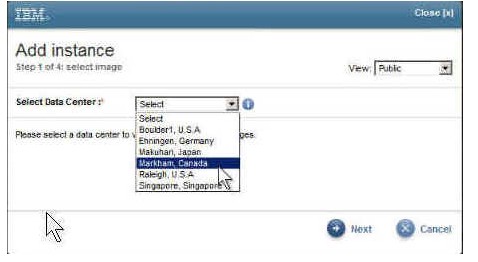
BigInsights 映像在所有数据中心都应该是可用的。在这个示例中,选择使用的是 Markham、Canada 数据中心。
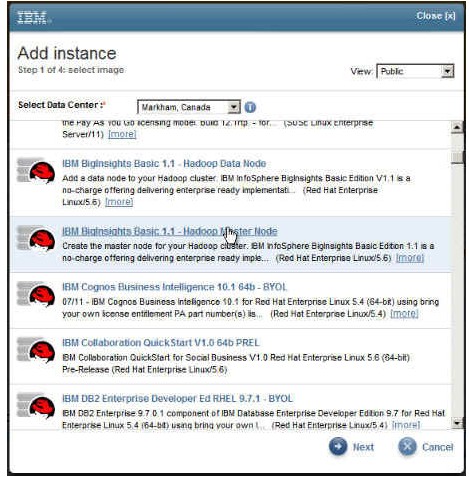
选定数据中心之后,就会显示该数据中心中可用映像的列表。请选择 IBM BigInsights Basic 1.1 - Hadoop Master Node 映像,然后单击 Next。
图 5. 选择 BigInsights Basic 1.1 - Hadoop Master Node
BigInsights 映像在所有数据中心都应该是可用的。在这个示例中,选择使用的是 Markham、Canada 数据中心。
选定数据中心之后,就会显示该数据中心中可用映像的列表。请选择 IBM BigInsights Basic 1.1 - Hadoop Master Node 映像,然后单击 Next。
4.配置 BigInsights Hadoop Master Node 映像。
图 6. 配置 BigInsights Hadoop Master Node 映像
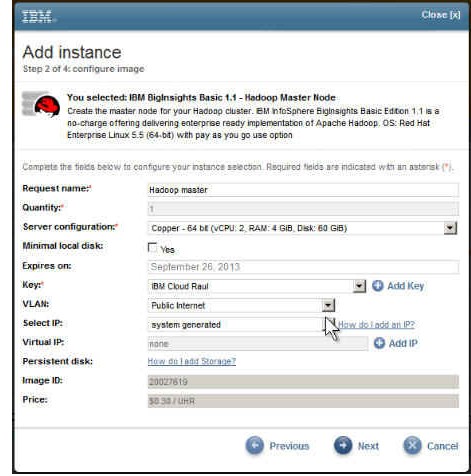
在该示例中,将这个实例命名为 “Hadoop master”。
对于 Server configuration 选项,如果您只是尝试一下,并不真正为了生产目的而去搭建环境,那么 Copper 很可能就已经够用。如果您是为了生产目的而搭建环境,应该首先使用 IBM Cloud 中不同的配置规模(Copper、Bronze、Silver、Gold、Platinum)来检验 MapReduce 作业的性能。您还可以尝试使用 Hadoop wiki (参见 参考资料)中指定的基准。如果您尝试使用这些基准,可以只预备一个节点(Hadoop Master 节点)。创建好集群之后,就可以再次重复使用基准。特别是对于 BigInsights IBM Cloud 映像,需要针对基准运行以下特定命令:
cd /mnt/biginsights/opt/ibm/biginsights/IHC
hadoop jar hadoop-*-examples.jar randomwriter rand
hadoop jar hadoop-*-examples.jar sort rand rand-sort
因为我用过 IBM Cloud,我以前在 Key 下生成过密钥;因此,我可以重用这些密钥之一。这个示例使用的是 IBM Cloud Raul。
为所有其他参数选择默认值,然后单击 Next。
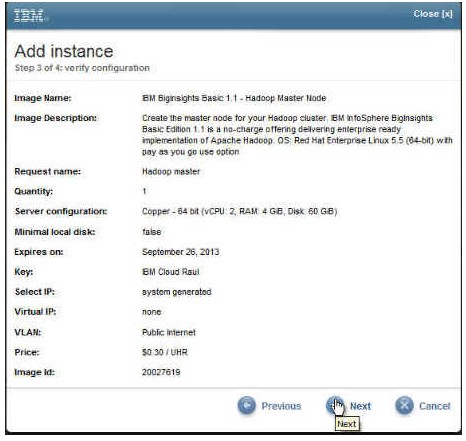
这将显示您为映像指定的配置的概要介绍。如果没问题,请单击 Next。
图 7. 针对您的 Hadoop Master 节点映像的配置概要介绍
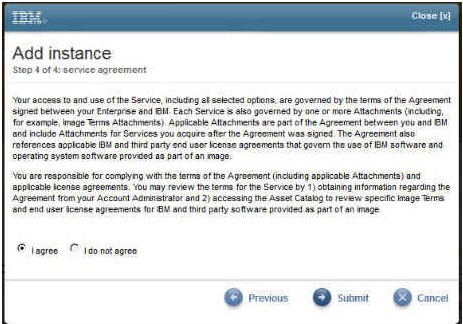
7.您会看到一份服务协议,必须同意协议条款才能继续后面的步骤。请单击 I agree ,然后单击 Submit。
图 8. 同意服务协议后才能继续后面的步骤
8.提交预备映像的请求之后将显示成功的消息面板。
图 9. 提交预备实例的请求之后的成功消息
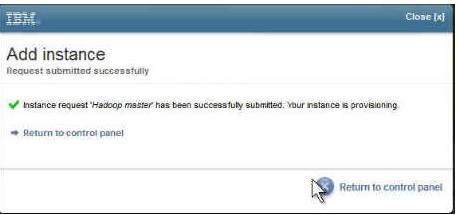
9.几分钟后,您的实例将被请求、预备好并激活,这意味着它已经开始运行并且可以使用。对于此映像,只要映像变为活动状态,就会自动启动所有的 Hadoop 组件。实例的 IP 地址也应该显示出来,如图 10 中所示。
图 10. 成功预备了 Hadoop Master 节点实例
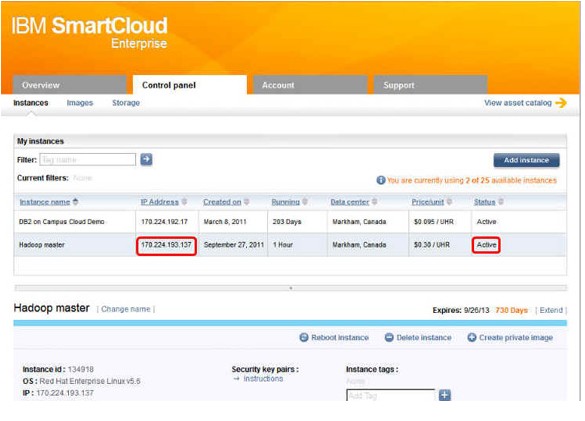
在这个示例中,指定给这个 Hadoop Master 节点实例的 IP 地址是 170.224.193.137。记下这个地址,预备 Hadoop Data 节点时会用到它。
步骤 3:预备一个 BigInsights Data 节点实例
预备 Hadoop Master 节点实例之后,您可以开始预备将用于集群的多个 Data 节点。在这个示例中,您需要预备两个 Data 节点来创建由三节点组成的 Hadoop 集群。
因为预备 Hadoop Data 节点实例的过程十分类似于预备 Hadoop Master 节点,所以这里只描述不同的步骤或需要关注的步骤。
使用 Hadoop 时,访问位于不同数据中心内的数据是最糟糕的情况。因此,这个示例中使用了为主节点(Markham, Canada)选择的相同数据中心。当然,我们为映像选择的是 IBM BigInsights Basic 1.1 - Hadoop Data 节点 映像,如图 11 所示。
图 11. 选择 Markham, Canada 数据中心内的 Hadoop Data Node 映像
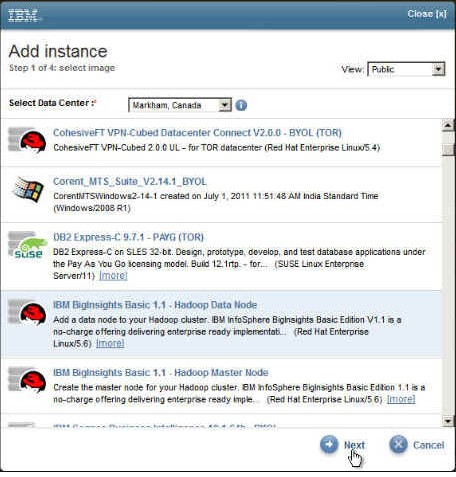
2.输入 Hadoop slave 1 作为实例名称。对于所有其他设置,保留其默认值或者选择与 Hadoop Master 节点相同的值。
图 12. 配置 BigInsights Hadoop Data 节点映像
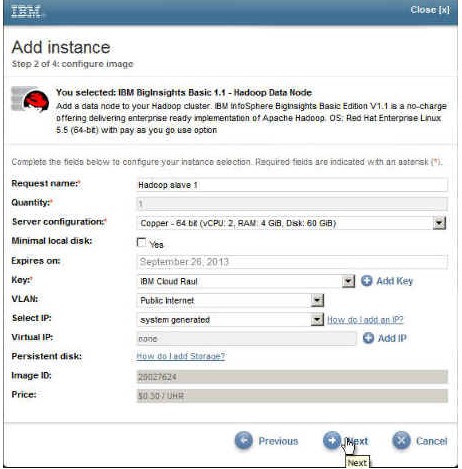
3.配置完 BigInsights Hadoop Data 节点后会显示一个面板,您需要在其中输入 Hadoop Master 节点的 IP 地址。为了能够将 Hadoop Data 节点自动添加到集群,该地址是必不可少的。请输入 IP 地址,然后单击 Next。在这个示例中,Hadoop Master 节点的 IP 地址是 170.224.193.137。
图 13. 输入 BigInsights Hadoop Master IP 地址
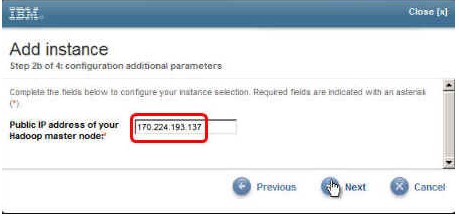
4.继续完成接下来的步骤,接受其默认值,从而添加 Hadoop Data 节点实例。
5.重复完全相同的过程即可创建另一个 Hadoop Data 节点;这次将它命名为 Hadoop slave 2。
图 14 显示了 Hadoop Master 实例与两个 Hadoop Data 节点(从)实例。
图 14. 您的三节点 Hadoop 集群已经可以使用
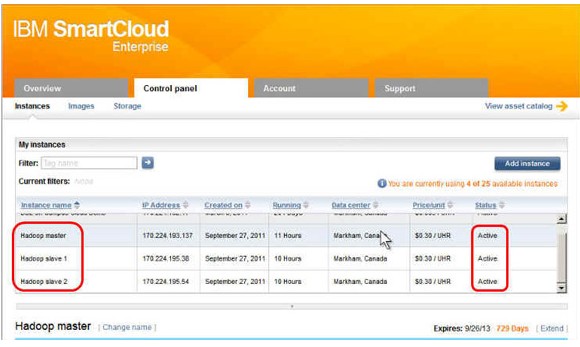
当所有实例都已预备好并激活时,您的 Hadoop 集群已经可以使用。恭喜您!
步骤 4:确认您的 Hadoop 集群能够正常工作
在 IBM Cloud Control 面板的选项卡中,单击 Hadoop master 实例。向下滚动。您应该看到与图 15 和图 16 中类似的信息。
图 15. Hadoop Master 节点的总配置
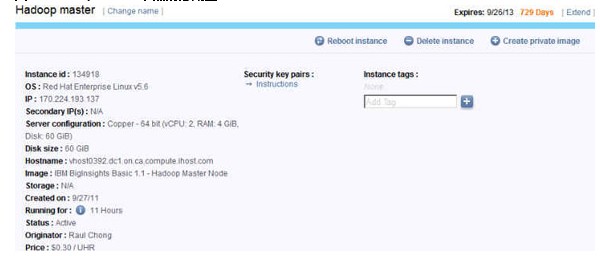
图 15 显示了 Hadoop Master 节点的配置内容的摘要。
图 16. Hadoop Master 节点的 “Getting started” 部分
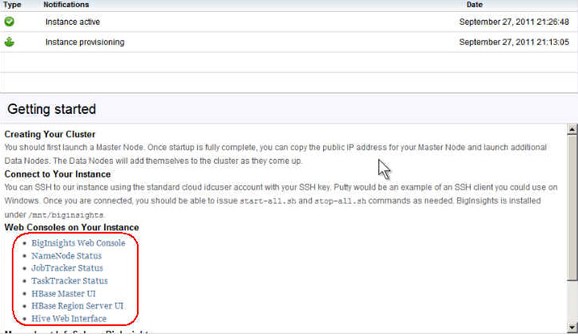
图 16 显示了用于监控您的集群的一些有用链接的列表。特别要注意的是第一个链接 BigInsights Web Console。当您单击该链接时,会在您的浏览器中打开 Web Console,如图 17 所示。
图 17. BigInsights Web Console
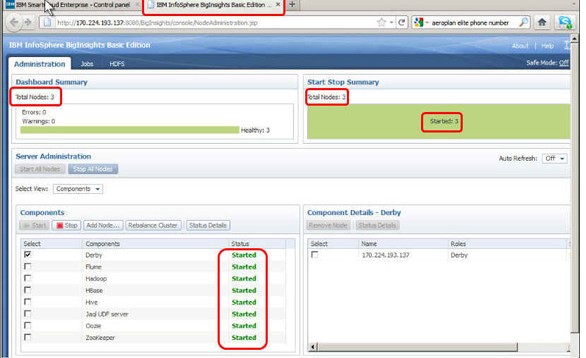
2.在 BigInsights Web Console 中,可以通过在 Components 部分中确认每个组件均已启动来验证 Hadoop 集群正在运行。在 Start Stop Summary 部分,可以验证三个节点均已启动。
让我们尝试一些命令。对主节点使用 putty to ssh。和 IBM Cloud 中的其他实例一样,指定 idcuser 作为用户。
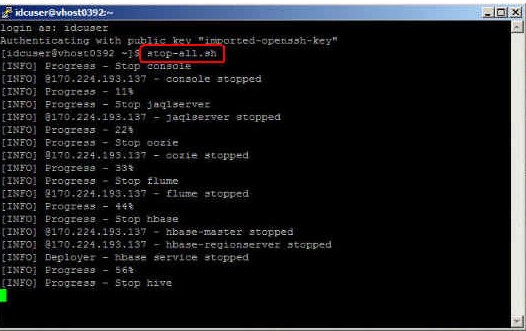
使用 stop-all.sh 命令停止 Hadoop 的所有组件。
图 18. 使用 stop-all.sh 命令停止所有组件
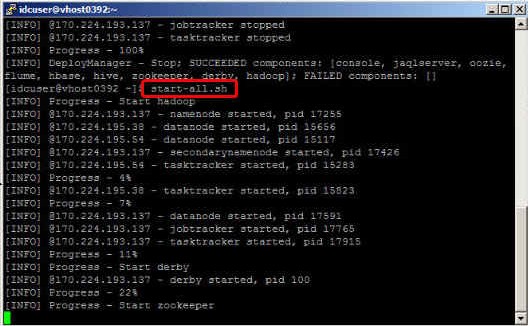
5.现在,使用 start-all.sh 命令启动 Hadoop 的所有组件。
图 19. 使用 start-all.sh 命令启动所有组件
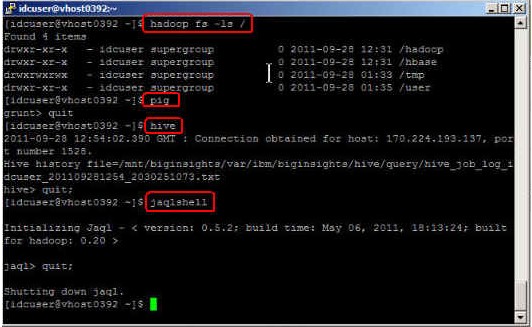
6. 执行这些命令以确认一切正常:
hadoop fs -ls /
This tests the Hadoop Distributed File System (HDFS) is working by listing all files and directories in the root of HDFS.
pig
Grunt> quit;
This starts pig and exits.
hive
Hive> quit
This starts hive and exits.
jaqlshell
Jaql> quit;
This starts jaql and exits.
图 20 中显示了这些命令及其输出。
图 20. 测试一些 Hadoop 命令和组件
结束语
本文描述了数分钟内在 IBM Cloud 上组建由三节点组成的 Hadoop 集群的详细步骤。这个过程非常简单,适用于创建规模更大的集群。您需要确保首先预备了 Hadoop Master 节点,并写下其 IP 地址,以便在预备 Hadoop Data 节点时指定它。
参考资料
学习
在 developerWorks 云开发人员资源 中,发现和共享应用程序和服务开发人员有关构建云部署项目的知识和经验。
了解如何 访问 IBM SmartCloud Enterprise。
| 

