|
简介: Amazon SimpleDB
是 Amazon Web Services 系列的一部分,是一个可大规模扩展且可靠的键 / 值数据存储服务,可通过一个
Web 界面显示,且可使用 Java 语言访问。这个包含两个部分的系列文章探讨 SimpleDB 独有的无模式数据存储方法,本文是系列的第
1 部分,介绍如何开始使用 Amazon SimpleDB,包括对数据存储最不寻常的特性的演示:字典式搜索。
整个系列中,我和您了分享大量非关系型数据存储,统称为 NoSQL。在一篇最近的文章中,我向您展示了一个面向文档的数据存储(CouchDB)与面向模式的关系型数据库的巨大区别。此外,CouchDB
的整个 API 是 REST 式的,且支持不同的查询方式:JavaScript 中定义的 MapReduce
功能。很显然,这是对传统 JDBC 的一个很大突破。
我最近还写了 Google 的 Bigtable 相关内容,它不是一种关系型
或面向文档的数据解决方案(且它偶尔不支持 JDBC)。Bigtable 就是所谓的键 / 值存储。也就是说,它是
无模式的,一般支持您存储的任何内容,不管是一个停车罚单实例、比赛列表还是比赛中的参赛者。Bigtable
的无模式形式提供了大量灵活性,因而支持快速开发。
Bigtable 不是惟一可供我们选择的键 / 值数据存储。Amazon
有自己的基于云的键 / 值存储式 Amazon SimpleDB。Bigtable 是通过 Google
App Engine 提供的一个抽象公开给 Java 开发人员的,而 Amazon SimpleDB 是通过
web 服务界面公开的。因此,您可以通过 web 和 HTTP 操作 SimpleDB 数据存储。Amazon
的 Web Service 基础设施之上的绑定使得我们可以自己选择语言来使用 SimpleDB,包括 PHP、Ruby、C#
和 Java 语言。
这个月,我将通过 Amazon 的官方 SDK 向您介绍 SimpleDB。我将使用另一个比赛相关示例展示这个而强大的、基于云的数据存储更加不同的一面:字典式搜索。
SimpleDB 简介
在底层,SimpleDB 是一个可大规模伸缩、用 Erlang 编写的高可用数据存储。从概念上讲,它就像
Amazon 的 S3。但是 S3 有对象位于 bucket 中,而 SimpleDB 在逻辑上被定义为包含项目的域。SimpleDB
也允许项目包含属性。将一个 域看作是 S3 中的一个 bucket 或关系意义中的一个表(或更准确地讲,Bigtable
的 “kind” 概念)。不过要注意,不要将关系性投射到 SimpleDB 的概念中,因为它最终会像 Bigtable
一样无模式。域可以有多个项目(类似于行),且项目可以有多个属性(类似于关系型表中的列)。
SimpleDB 的‘最终一致性’
CAP theorem(参见 参考资料)表明,一个分布式系统不能同时高度可用、可伸缩并确保一致性;确实,一个分布式系统任何时候仅支持这三个特质中的两种。相应地,SimpleDB
可以确保一个高度可用、可伸缩的数据存储,但不支持即时一致性。SimpleDB 支持的是 最终一致性,这并不像您想象的那样糟糕。
对于 Amazon 来说,最终一致性是指一切在 几秒内在所有节点(不过在一个区域内)上都变得一致。在这一小段时间内,两个并发进程可能会读取同一数据的两个不同实例,而在此期间您换来的是大规模可靠性和一个实惠的价格。(您只需向提供类似可靠性的商业实体漫天要价,从而查看其区别。)
属性是真正的名 / 值对(有点像 Bigtable,不是吗?)且 “对”
并不局限于一个值。也就是说,一个属性名可以有一个相关值集合(或列表);例如,一个词项目可以有多重定义的属性值。此外,SimpleDB
内的所有数据都以 String形式表示,这明显不同于 Bigtable 或甚至是一个 RDBMS,后者通常支持混合数据类型。
impleDB 的单数据类型属性值方法有利有弊,这取决于您如何去看待它。不管是利是弊,它确实隐含着查询的运行方式(不久将介绍更多相关内容)。SimpleDB
也不支持跨域联接的概念,因此您不能查询多个域中的项目。不过,您可以通过执行多个 SimpleDB 并在您这一端执行联接来克服此局限。
项目 本身没有主键(就像 Bigtable 一样)。一个项目的主键或惟一标识符是项目的名称。SimpleDB
非常智能,能够在发出一个副本创建请求时更新一个项目,只要该项目的属性已被更改。
与其他 Amazon Web Services 一样,SimpleDB
通过 HTTP 公开一切内容,因而有多种方式可与之交互。在 Java 中,我们的选项从 Amazon 自己的
SDK(我们会在接下来的例子中用到)到一个名为 Topica 的流行项目,甚至到成熟的 JPA 实现(我们将在第
2 部分探讨)。
云中赛事
目前为止,我使用了一个比赛和停车罚单类比来展示各种 Java 2.0
技术的特性。使用一个熟悉的问题域,更易于领会系统间的差异和共同点。因此,我们这次将继续沿用终点线类比,来看一下参赛者和比赛在
Amazon SimpleDB 中是如何表示的。
在 SimpleDB 中,我们可以将一个比赛建模为一个域。比赛实例会是
SimpleDB 中的一个项目,其名称和日期会以属性(带值)表示。很重要的一点是,本例中的 名称是一个属性,不是属性本身。您赋给一个项目实例的名称成为它的键。该项目的键可以是马拉松的名称。另外,我们可以不将一个比赛实例局限为一个时间点(比赛通常是年度活动),而是赋给项目一个惟一名(如同一个时间戳),它允许我们在
SimpleDB 中存储多个半年度比赛。
同样地,runner可以是一个域。个人参赛者可以是项目,参赛者的姓名和年龄可以是属性。如同一个比赛,每个
runner项目需要一个惟一名(例如,Pete Smith 或 Marty Howard)。不同于 Bigtable,SimpleDB
不在乎您为每个项目如何命名,事实上,它不会为您提供一个主键生成器。可能在本例中,我们可以使用一个时间戳或仅为每个参赛者增加一个计数器,比如
runner_1、runner_2等。
因为没有框架,个人项目可以随便变更属性。同样地,您可以随意更改一个域中的项目。不过您需要限制该变化性,因为它往往使数据变得无序,从而不易于查找或管理。请注意我这里的一句话:杂乱无章、无模式、无组织的数据是造成灾难的因素!
轻松使用 Amazon SDK
Amazon 最近标准化了一个库,该库包含使用所有 web 服务(包括
SimpleDB)所用的代码。该库和大多数库一样,提取访问和使用这些服务所需的底层通信,支持客户以自然方式运作。例如,Amazon
用于 SimpleDB 的 Java 库允许您创建域和项目,查询它们,当然也支持从存储中更新和删除它们
―自始自终不需要知道这些经由 HTTP 传输到云中的操作。
清单 1 显示了一个使用纯 Java 代码定义的 AmazonSimpleDBClient,以及一个
Races域。(如果您希望将该练习复制您的工作站上,将需要使用 Amazon 创建一个帐户。)
清单 1. 创建 AmazonSimpleDBClient 的一个实例
AmazonSimpleDB sdb = new AmazonSimpleDBClient(new PropertiesCredentials(
new File("etc/AwsCredentials.properties")));
String domain = "Races";
sdb.createDomain(new CreateDomainRequest(domain));
|
注意,Amazon SDK 的 Request对象模式将为所有 SimpleDB
活动保留。在本例中,创建一个 CreateDomainRequest就创建了一个域。我可以通过客户的 batchPutAttributes方法添加项目,这实际上是采用项目的一个
List,如清单 2 所示:
清单 2. Race_01
List data = new ArrayList();
data.add(new ReplaceableItem().withName("Race_01").withAttributes(
new ReplaceableAttribute().withName("Name").withValue("Charlottesville Marathon"),
new ReplaceableAttribute().withName("Distance").withValue("26.2")));
|
在 Amazon 的 SDK 中,Item以 ReplaceableItem类型表示。您为每个实例赋一个名称(即一个键),然后您可以添加属性(ReplaceableAttribute类型)。在清单
2 中,我创建了一个比赛,一个带有简单键的马拉松比赛,“Race_01”。我创建一个 BatchPutAttributesRequset并将其一同发送到
AmazonSimpleDBClient,从而将该实例添加到我的 Races域,如清单 3 所示:
清单 3. 在 SimpleDB 中创建一个项目
sdb.batchPutAttributes(new BatchPutAttributesRequest(domain, data));
|
SimpleDB 中的查询
在保存了一个比赛之后,我当然可以通过 SimpleDB 的查询语言(与
SQL 很像)搜索它。不过有一个缺点。还记得我说过,所有项目属性都存储为 String吗?这意味着,数据比较是
按字母顺序进行的,这在执行搜索时有影响。
如果我根据数字运行一个查询,例如,SimpleDB 会基于字符执行搜索,而非真正的整数值。现在,我有一个简单的比赛实例存储在
SimpleDB 中,我可以使用 SimpleDB 的类似于 SQL 的语句轻松对其进行搜索,如清单 4
所示:
清单 4. Searching for Race_01
String qry = "select * from `" + domain + "` where Name = 'Charlottesville Marathon'";
SelectRequest selectRequest = new SelectRequest(qry);
for (Item item : sdb.select(selectRequest).getItems()) {
System.out.println("Race Name: " + item.getName());
}
|
清单 4 中的查询类似于标准 SQL。在本例中,我仅查询 Name为
“Charlottesville Marathon” 的所有 Race实例。 发送一个 SelectRequest到
AmazonSimpleDBClient会产生许多 Item。因此,我能够迭代项目并打印其名称,在本例中,我应该只收到一个项目。
现在让我们看一下,当我添加另一个带不同距离属性的比赛时会发生什么,如清单 5 所示:
清单 5. 较短的比赛
List data2 = new ArrayList();
data2.add(new ReplaceableItem().withName("Race_02").withAttributes(
new ReplaceableAttribute().withName("Name").withValue("Charlottesville 1/2 Marathon"),
new ReplaceableAttribute().withName("Distance").withValue("13.1")));
sdb.batchPutAttributes(new BatchPutAttributesRequest(domain, data2));
|
由于两个比赛距离不同,所以基于距离执行搜索很合理,如清单 6 所示:
清单 6. 根据距离进行搜索
String disQry = "select * from `" + domain + "` where Distance > '13.1'";
SelectRequest selectRequest = new SelectRequest(disQry);
for (Item item : sdb.select(selectRequest).getItems()) {
System.out.println("Race Name: " + item.getName());
}
|
毫无疑问,返回的比赛是 Race_01,从数学 和字母角度来说都是正确的,26.2
大于 13.1。但当我添加一个 真的很长的比赛时,看看会发生什么。
清单 7. Leesburg Ultra Marathon
List data3 = new ArrayList();
data3.add(new ReplaceableItem().withName("Race_03").withAttributes(
new ReplaceableAttribute().withName("Name").withValue("Leesburg Ultra Marathon"),
new ReplaceableAttribute().withName("Distance").withValue("103.1")));
sdb.batchPutAttributes(new BatchPutAttributesRequest(domain, data3));
|
在清单 7 中,我添加了一个距离为 103.1 的比赛。当我从清单 6
返回查询时,猜猜是什么?对了,就是 103.1,按字母顺序来讲,它小于 13.1。这就是您看不到所列的
Leesburg Ultra Marathon 的原因(如果您在家跟着操作)!
现在看一下,当我运行一个不同的查询来查找较短的比赛时,会发生什么,如清单 8 所示:
清单 8. 看一下会出现什么!
String disQry = "select * from `" + domain + "` where Distance < '13.1'";
SelectRequest selectRequest = new SelectRequest(disQry);
for (Item item : sdb.select(selectRequest).getItems()) {
System.out.println("Race Name: " + item.getName());
}
|
如果对此深信不疑,运行清单 8 中的查询会产生一个令人惊讶的结果。我们知道,搜索是按字母顺序执行的,不过这总的来说很有意义
―即使您在寻找较短的比赛,(虚构的)Leesburg Ultra Marathon 也不会在您的范围之内!
字典式搜索
在查找编号数据(包括日期)时,字典式搜索会产生问题,但是还有弥补的余地。解决按距离搜索的一种方式是填充距离属性使用的编号。
我目前最长的比赛是 103.6 公里(尽管我个人从没有跑过甚至与此接近的距离),按字母顺序读取小数点前面的三个数字。因此,我要用前导零填充其余比赛,为所有比赛赋相同数量的字符。这样做会使我的基于距离的搜索起作用。
图 1 是 SDB Tool 的一个屏幕截图,该工具是一个 Firefox
插件,用于可视地查询和更新 SimpleDB 数据库域(参见 参考资料):

图 1. 填充距离值
如您所见,我对 Race_01和 Race_02的距离值都添加了一个零。对于未培训过的人来说,这可能不是很有意义,但是它将大大简化搜索。因此,在图
2 中,您可以看到我对距离小于 020.0(或仅仅等于 20 公里) 公里的比赛执行了搜索,并看一下最终
―且正确的 ―结果:
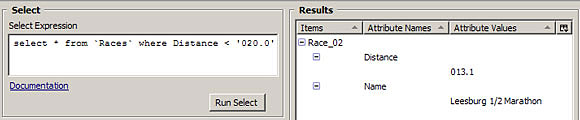
图 2. 填充式搜索解决了问题
只要有一点先见之明,就不难克服对于字典式搜索来说看似局限的因素。如果填充不在您的范围之内,另一个选择是过滤应用内容。即,您可以将整数作为标准整数,并在有大量来自
Amazon 的未经过滤的项目时对其进行过滤 ―即对所有项目应用一个 select *。不过如果您有大量数据,该方法代价很高。
SimpleDB 中的关系
在 SimpleDB 中不难建立关系。从概念上, 您可以在一个名为 race的参赛者项目上轻松创建一个属性,然后在其中置入一个比赛名(比如
Race_01)。更好的是,您可以在该值中保留一系列比赛名。反过来也一样:您可以在一个 race域中轻松保留许多参赛者姓名(如清单
9 所示)。只需记住:您不能通过 Amazon 的查询语言真正将这两个域联接起来;您必须自己执行该操作。
清单 9. 创建一个 Runners 域和两个参赛者
sdb.createDomain(new CreateDomainRequest("Runners"));
List runners = new ArrayList();
runners.add(new ReplaceableItem().withName("Runner_01").withAttributes(
new ReplaceableAttribute().withName("Name").withValue("Sally Smith")));
runners.add(new ReplaceableItem().withName("Runner_02").withAttributes(
new ReplaceableAttribute().withName("Name").withValue("Richard Bean")));
sdb.batchPutAttributes(new BatchPutAttributesRequest("Runners", runners));
|
在创建了一个 Runners域并将参赛者添加到域中时,我可以更新一个现有比赛并在其中添加我的参赛者,如清单
10 所示:
清单 10. 更新一个比赛来保留两个参赛者
races.add(new ReplaceableItem().withName("Race_01").withAttributes(
new ReplaceableAttribute().withName("Name").withValue("Charlottesville Marathon"),
new ReplaceableAttribute().withName("Distance").withValue("026.2"),
new ReplaceableAttribute().withName("Runners").withValue("Runner_01"),
new ReplaceableAttribute().withName("Runners").withValue("Runner_02")));
|
底线在于关系是可行的,但是您必须在 SimpleDB 之外对其进行管理。如果您想获取
Race_01中所有参赛者的全名,例如,您需要在一个查询中获取名称,然后针对 runner域执行查询(本例中是两个查询,因为
Race_01仅有两个属性值)来获取答案。
清理操作
清理工作很重要,因此我最后将介绍如何使用 Amazon 的 SDK 执行快速清理。清理操作与创建和查询数据操作没有多大区别;您只需创建
Request类型并进行删除即可。
删除 Race_01很简单,如清单 11 所示:
清单 11. 在 SimpleDB 中执行删除
sdb.deleteAttributes(new DeleteAttributesRequest(domain, "Race_01"));
|
如果我使用了一个 DeleteAttributesRequest来删除项目,你认为我删除一个域需要使用什么?您猜到了:DeleteDomainRequest!
清单 12. 在 SimpleDB 中删除一个域
sdb.deleteDomain(new DeleteDomainRequest(domain));
|
旅程尚未结束!
我们尚未完成借由 Amazon SimpleDB 的云中旅行,但是我们目前已经介绍完了
Amazon SDK。Amazon 的 SDK 是功能较多,且在某种程度上会很有用,但是如果您想建模对象
―比如比赛和参赛者 ―您可能希望利用 JPA 之类的工具。下个月,我们将探寻在合并 JPA 和 SimpleDB
时会发生什么。在此之前,请尽情体会字典式搜索!
参考资料
Java 开发 2.0 :这个 developerWorks 系列探讨正在重新定义
Java 开发面貌的技术和工具,包括 CouchDB(2009 年 11 月)和 Bigtable(2010
年 5 月)。
“用 Amazon Web Services 进行云计算,第 5 部分:用
SimpleDB 在云中处理数据集”(Prabhakar Chaganti,developerWorks,2009
年 2 月):学习基本的 Amazon SimpleDB (SDB) 概念,研究 boto(一个用于与
SDB 交互的开放源码 Python 库)提供的一些功能。
“Eventually Consistent - Revisited”(Werner
Vogels,All Things Distributed,2008 年 12 月):Amazon 的
CTO 解释了 Eric Brewer 的 CAP Theorem及其对 Amazon 的 Web Services
基础设施的影响。
“NoSQL Patterns”(Ricky Ho,Pragmatic
Programming Techniques,2009 年 11 月):数据库的一个概述和清单,以及对
NoSQL 数据存储的公共模式的深入见解。
“Bigtable: A Distributed Storage System
for Structured Data”(Fay Chang et al.,Google,2006 年
11 月):Bigtable 是一个用于管理结构化数据的分布式存储系统,设计用于伸缩到非常大的规模:跨数千个商品服务器的数
P 字节数据。
浏览 技术书店,阅读关于这些和其他技术主题的图书。 developerWorks
Java 技术专区:这里有数百篇关于 Java 编程各个方面的文章。
|


