| ժҪ���ֲ�ʽϵͳ��Ҫ������������һ���Ժ����ܼ���ƽ�⡣����ϵͳ�����˴����ֲ�ʽ����һ���Եļ���ģ�ͣ��磺Master-Slave��Master-Master��2PC/3PC������Ľ������⣬Paxos���Լ�Dynamo��NRW��VectorClock��ģ�͡�
���ݷ���ĸ߿�����������ҵ����ӵ�еģ�����Ҫ���������и߿����ԣ�����Ҫ��������д��ݡ�д��ݵ���������һ���Ե����⣬��һ���Ե������ֻ�����������⣬��ͻ�����һ�������ѭ����������ν����һ���ԣ����ǵ�����û���ͼͬʱ����һ�����ݿ�ʱ��������ǵ�����ͬʱʹ����ͬ�����ݣ����ܻᷢ�����������������ʧ���¡�δȷ��������ԡ���һ�µķ����ͻ����������Ͱͱ����з����ġ��̼�ҵ��������ר�ҳ��IJ��͡��ֲ�ʽϵͳ����������һ�ĶԴ�������ϸ���������Ƽ�����ҡ�����������ԭ�ģ�
������������һ̨���������ṩ���ݷ����ʱ�������������µ��������⣺
1.һ̨�����������ܲ������ṩ�㹻������������������������
2.���ķ�����崻�����ɷ����û������ݶ�ʧ��
�����Щ����,���Dz��ò��Է�����������չ���������Ļ������ֵ��������⣬�Լ��������������⡣ͨ�������ǻ�ͨ�������ֶ�����չ���ǵ����ݷ���
1.���ݷ��������ǰ����ݷֿ���ڲ�ͬ�ķ������ϣ��磺uid % 16��һ���Թ�ϣ�ȣ���
2.���ݾ��������еķ���������ͬ�����ṩ�������ݷ���
ʹ�õ�һ�ַ�������������ݶ�ʧ���⣬��̨������������ʱ��һ�����в������ݶ�ʧ�����ԣ����ݷ���ĸ߿�����ֻ��ͨ���ڶ��ַ�������ɡ������ݵ�����洢��һ�㹤ҵ����Ϊ�Ƚϰ�ȫ�ı�����Ӧ����3�ݣ��磺Hadoop��Dynamo����
���ǣ�����Ļ���Խ�����ݾͻ���Խ���ӣ������ǿ����������������Ҳ���ǿ������������һ���ԡ������һ�����ѵ����⣡������������Use
Case����A�ʺ���B�ʺŻ�Ǯ����˵��һ�£���ϤRDBMS����Ķ�֪�����ʺ�A���ʺ�B��Ҫ6��������
��A�ʺ��а�����������
��A�ʺ�������������
�ѽ��д��A�ʺ��У�
��B�ʺ��а�����������
��B�ʺ����ӷ�������
�ѽ��д��B�ʺ��С�
Ϊ�����ݵ�һ���ԣ���6���£�Ҫô���ɹ����꣬Ҫô�����ɹ���������������Ĺ����У���A��B�ʺŵ��������ʱ�����������ν��������Ҫ�ų������Ķ�д��������Ȼ�������������⣬����������ǣ��ڼ����˶�����������������ø���������
�����ݷ����ķ����У����A�ʺź�B�ʺŵ����ݲ���ͬһ̨����������ô�죿������Ҫһ�����������������Ҳ����˵�����A�Ŀ�Ǯ�ɹ��ˣ���B�ļ�Ǯ���ɹ������ǻ�Ҫ��A�IJ������ع���ȥ���ڲ�ͬ�Ļ�����ʵ�֣��ͻ�Ƚϸ��ӡ�
�����ݾ���ķ����У�A�ʺź�B�ʺż�Ļ���ǿ�����һ̨��������ɵģ����DZ����������ж�̨��������A�ʺź�B�ʺŵĸ����������A�ʺŵĻ�Ǯ����������������Ҫ���B��C�������������������ڲ�ͬ����̨����������ô�죿Ҳ����˵�������ݾ����У��ڲ�ͬ�ķ������϶�ͬһ�����ݵ�д������ô��֤��һ���ԣ���֤���ݲ���ͻ��
ͬʱ�����ǻ�Ҫ�����������أ�������������ܵĻ���������ɲ������ѣ�ϵͳ��һ������ˡ����˿��������⣬���ǻ�Ҫ���ǿ����ԣ�Ҳ����˵��һ̨����û�ˣ����ݲ���ʧ��������ɱ�Ļ��������ṩ��
���ǣ�������Ҫ�ص㿼���������ô���������
1.���֣����ݲ���������Failover
2.���ݵ�һ���ԣ�������
3.���ܣ������� �� ��Ӧʱ��
ǰ��˵����Ҫ������ݲ�����ֻ��ͨ����������ķ��������������ݷ�����ÿ����Ҳ��Ҫ�����������ദ������������ݸ�����������ij���ڵ�����ݶ�ʧʱ���ԴӸ������������ݸ����Ƿֲ�ʽϵͳ������ݶ�ʧ�쳣��Ψһ�ֶΡ����ԣ�����ƪ�����У�����ֻ������������������¿������ݵ�һ���Ժ����ܵ����⡣��˵����
1.Ҫ���������и߿����ԣ��͵�д������ݡ�
2.д��ݵ�����ᵼ������һ���Ե����⡣
3.����һ���Ե������ֻ�������������
��������������������˺�«����ư��
һ����ģ��
˵������һ������˵����˵���������ͣ���Ȼ�����ϸ�ֵĻ������кܶ�һ����ģ�ͣ��磺˳��һ���ԣ�FIFOһ���ԣ��Ựһ���ԣ�����һ���ԣ���дһ���ԣ���Ϊ�˱��ĵļ�������ֻ˵�������֣���
1.Weak ��һ���ԣ�����д��һ����ֵ�����������ݸ����Ͽ��ܶ�������Ҳ���ܶ������������磺ijЩcacheϵͳ��������Ϸ������ҵ����ݺ���ûʲô��ϵ��VOIP������ϵͳ�����ǰٶ��������档
2.Eventually ����һ���ԣ�����д��һ����ֵ���п��ܶ�������������ij��ʱ�䴰��֮��֤�����ܶ����������磺DNS�������ʼ���Amazon
S3��Google��������������ϵͳ��
3.Strong ǿһ���ԣ��µ�����һ��д�룬�����⸱������ʱ�̶��ܶ�����ֵ�����磺�ļ�ϵͳ��RDBMS��Azure
Table����ǿһ���Եġ�
��������һ���͵�ģ������˵�����ǿ��Կ�����Weak��Eventuallyһ����˵���첽����ģ���Strongһ����˵��ͬ������ģ��첽��ͨ����ζ�Ÿ��õ����ܣ���Ҳ��ζ�Ÿ����ӵ�״̬���ƣ�ͬ����ζ�ż���Ҳ��ζ�������½�����������dz���һ��һ������������Щ������
Master-Slave
������Master-Slave�ṹ���������ּӹ���Slaveһ����Master�ı��ݡ���������ϵͳ�У�һ����������Ƶģ�
1.�������Master����
2.д����д��Master�Ϻ���Masterͬ����Slave�ϡ�
��Masterͬ����Slave�ϣ�����ʹ���첽��Ҳ����ʹ��ͬ��������ʹ��Master��push��Ҳ����ʹ��Slave��pull��
ͨ����˵��Slave�������Ե�pull������������һ���ԡ������Ƶ������ǣ����Master��pull�����ڿ���ˣ���ô�ᵼ�����ʱ��Ƭ�ڵ����ݶ�ʧ������㲻�������ݶ�����Slaveֻ�ܳ�ΪRead-Only�ķ�ʽ��Master�ָ���
��Ȼ����������������ݶ����Ļ�������������Slave����Master����������ֻ�������Ľ����˵��û������һ���Ժ����ݶ�ʧ�����⣬Master-Slave�ķ�ʽ�Ϳ��Խ�����������ˣ�
��Ȼ��Master SlaveҲ������ǿһ���Եģ� ���磺��дMaster��ʱ��Master�����ȱ��ݣ��ȳɹ�����дSlave�����߶��ɹ��سɹ�������������ͬ���ģ����дSlaveʧ���ˣ���ô���ַ�����һ���DZ��Slave�����ñ�������������Slave�ָ���ͬ��Master�����ݣ������ж��Slave��������һ�������б��ݣ�����ǰ��˵��д��������������һ���ǻع��Լ�������дʧ�ܡ���ע��һ�㲻��дSlave����Ϊ���дMaster�Լ�ʧ�ܺ�Ҫ�ع�Slave����ʱ����ع�Slaveʧ�ܣ��͵��ֹ����������ˣ����Կ��������Master-Slave��Ҫ����ǿһ�����жิ�ӡ�
Master-Master
Master-Master���ֽ�Multi-master����ָһ��ϵͳ������������Master��ÿ��Master���ṩread-write�������ģ����Master-Slave��ǿ�棬���ݼ�ͬ��һ����ͨ��Master���첽��ɣ�����������һ���ԡ�
Master-Master�ĺô���һ̨Master���ˣ����Master������������д���������Master-Slaveһ����������û�б����Ƶ����Master��ʱ���ݻᶪʧ���ܶ����ݿⶼ֧��Master-Master��Replication�Ļ��ơ�
���⣬������Master��ͬһ�����ݽ����ĵ�ʱ�����ģ�͵Ķ��ξͳ����ˡ�����Ҫ�����ݼ�ij�ͻ���кϲ�����dz����ѡ�����Dynamo��Vector
Clock����ƣ���¼���ݵİ汾�ź����ߣ���֪������²�����ô������Dynamo�����ݳ�ͻ������ǽ����û��Լ���ġ�����SVNԴ���ͻһ��������ͬһ�д���ij�ͻ��ֻ�ܽ����������Լ������������ڱ��ĺ���������һ��Dynamo��Vector
Clock��
Two/Three Phase Commit
���Э�����д�ֽ�2PC�����Ľ������ύ���ڷֲ�ʽϵͳ�У�ÿ���ڵ���Ȼ����֪���Լ��IJ���ʱ�ɹ�����ʧ�ܣ�ȴ��֪�������ڵ�IJ����ijɹ���ʧ�ܡ���һ�������Խ����ڵ�ʱ��Ϊ�˱��������ACID���ԣ���Ҫ����һ����ΪЭ���ߵ������ͳһ�ƿ����нڵ�(����������)�IJ������������ָʾ��Щ�ڵ��Ƿ�Ҫ�Ѳ�����������������ύ(���罫���º������д����̵ȵ�)��
�����ύ���㷨���£�
��һ�Σ�
Э���������еIJ����߽�㣬�Ƿ����ִ���ύ������
���������߿�ʼ����ִ�е����������磺Ϊ��Դ������Ԥ����Դ��дundo/redo log����
��������ӦЭ���ߣ����������������ɹ������Ӧ�������ύ���������Ӧ���ܾ��ύ����
�ڶ��Σ�
������еIJ����߶���Ӧ�������ύ������ô��Э���������еIJ����߷��͡���ʽ�ύ������������������ʽ�ύ�����ͷ�������Դ��Ȼ���Ӧ����ɡ���Э�����ռ������ġ���ɡ���Ӧ��������Global
Transaction��
�����һ��������Ӧ���ܾ��ύ������ô��Э���������еIJ����߷��͡��ع������������ͷ�������Դ��Ȼ���Ӧ���ع���ɡ���Э�����ռ������ġ��ع�����Ӧ��ȡ�����Global
Transaction��
���Կ�����2PC˵���˾��ǵ�һ����Vote���ڶ�����������һ���㷨��Ҳ���Կ���2PC�������ǿһ���Ե��㷨����ǰ�����۹�Master-Slave��ǿһ���Բ��ԣ���2PC�е����ƣ�ֻ����2PC��Ϊ����һЩ�����ȳ������ύ��
2PC�õ��DZȽ϶�ģ���һЩϵͳ����У��ᴮ��һϵ�еĵ��ã����磺A -> B -> C ->
D��ÿһ���������һЩ��Դ���дһЩ���ݡ�����B2C���Ϲ�����µ������ں�̨����һϵ�е�������Ҫ�������һ��һ���������ͻ�������������⣬���ijһ��������ȥ�ˣ���ôǰ��ÿһ�����������Դ��Ҫ��������������Ƕ����յ������ԣ����������Ƚϸ��ӡ����ںܶദ�����̣�Workflow��������2PC����㷨��ʹ��
try -> confirm��������ȷ���������̵��ܹ��ɹ���ɡ� �ٸ�ͨ�����ӣ��������ý���ʱ�����������ŶΣ�
��ʦ�ֱ������ɺ�������Ƿ�Ը�⡭���������ϲ�������
�����ɺ����ﶼ�ش�Ը�������һ������Դ������ʦ�ͻ�˵�����������ǡ����������ύ��
���Ƕ�ô�����һ�������ύ���������� ������Կ������е�һЩ���⣬ A������һ����ͬ��������������������Ȼ��dz����Ӱ�����ܡ�
B����һ����Ҫ����������TimeOut�ϣ����磬
�����һ���У�������û���յ�ѯ�������Dz����ߵĻ�Ӧû�е���Э���ߡ���ô����ҪЭ��������ʱ������һ����ʱ�����Ե���ʧ�ܣ�Ҳ�������ԡ�
����ڶ����У���ʽ�ύ����������еIJ�����û���յ������Dz������ύ/�ع����ȷ����Ϣû�з��أ�һ�������ߵĻ�Ӧ��ʱ��Ҫô���ԣ�Ҫô���Ǹ������߱��Ϊ��������������Ⱥ���������Ա�֤�����㶼������һ���Եġ�
��������ǣ��ڶ����У�����������ղ���Э���ߵ�commit/fallbackָ������߽����ڡ�״̬δ֪���Σ���������ȫ��֪��Ҫ��ô�죬���磺������еIJ�������ɵ�һ�εĻظ�����ȫ��yes������ȫ��no�����ܲ���yes����no�������Э���������ʱ��ҵ��ˡ���ô���еĽ����ȫ��֪����ô�죨�����IJ����߶����У���Ϊ��һ���ԣ�Ҫô����Э���ߣ�Ҫô�ط���һ�ε�yes/no���
�����ύ����������ǵ�3������һ����ɺ������ڵڶ���û���յ����ߣ���ô���ݽ�����롰��֪���롱��״̬�����״̬��blockס��������Ҳ����˵��Э����Coordinator�����������ɷdz���Ҫ��Coordinator�Ŀ������Ǹ��ؼ���
��Щ���������������ύ�������ύ��Wikipedia�ϵ��������£����Ѷ����ύ�ĵ�һ����break�������Σ�ѯ�ʣ�Ȼ��������Դ����������ύ�������ύ��ʾ��ͼ���£�
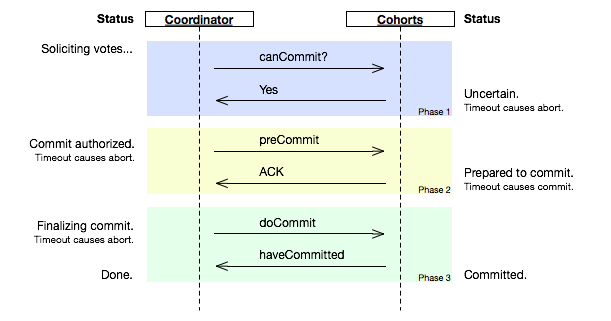
�����ύ�ĺ��������ǣ���ѯ�ʵ�ʱ��������Դ�����������˶�ͬ���ˣ��ſ�ʼ����Դ��
��������˵�������һ�����еĽ�㷵�سɹ�����ô���������ųɹ��ύ�ĸ��ʺܴ�����һ�������Խ��Ͳ�����Cohorts��״̬δ֪�ĸ��ʡ�Ҳ����˵��һ���������յ���PreCommit����ζ��֪�������ʵ��ͬ�����ˡ���һ�����Ҫ����������һ��3PC��״̬Ǩ��ͼ����ע��ͼ�е����ߣ���ЩF,T��Failuer��Timeout�����еģ�״̬������
q �C Query��a �C Abort��w �C Wait��p �C PreCommit��c �C Commit��
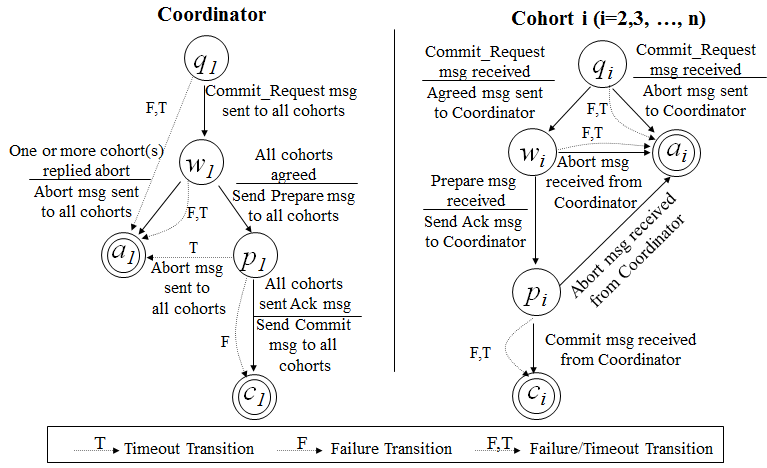
��ʵ�������ύ��һ���ܸ��ӵ����飬ʵ�������൱�ѣ�����Ҳ��һЩ���⡣
����������������кܶ�ܶ�����⣬��һ����˼��2PC/3PC�и��ָ�����ʧ�ܳ�������ᷢ��Timeout�Ǹ��dz��Ѵ��������飬��Ϊ�����ϵ�Timeout�ںܶ�ʱ�����������´ӣ���Ҳ��֪���Է������˻���û������������úõ�һ��״̬������ΪTimeout���˸����衣
һ����������������״̬��1��Success��2��Failure��3��Timeout�������������Ƕ��Σ�����������Ҫά��״̬��ʱ��
Two Generals Problem�����������⣩
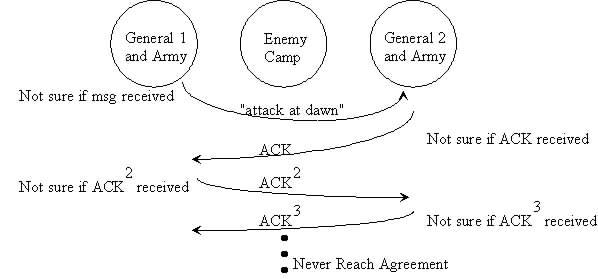
Two Generals Problem ��������������ôһ��˼ά��ʵ�����⣺ ����֧���ӣ����Ƿֱ���һλ�����쵼������������һ�������˷������µij��С�����֧���Ӷ�פ�����������еĸ�������ռһ��ɽͷ��һ��ɽ�Ȱ�����ɽ�ָ�������������λ����Ψһ��ͨ�ŷ�ʽ�����ɸ��Ե���ʹ������ɽ�����ߡ����ҵ��ǣ����ɽ���Ѿ����������еı�����ռ�죬���Ҵ���һ�ֿ��ܣ��Ǿ����κα��ɳ�����ʹͨ��ɽ���ǻᱻ����
��ע�⣬��Ȼ��λ�����Ѿ������������д�ɹ�ʶ���������Ǹ���ռ��ɽͷ���֮ǰ����û�оͽ���ʱ���ɹ�ʶ����λ�����������Լ��ľ���ͬʱ�������в���ȡ�óɹ�����ˣ����DZ��뻥�ͨ����ȷ��һ��ʱ������������ͬ�������ʱ���������ֻ��һ���������й�������ô�⽫��һ�������Ե�ʧ�ܡ�
���˼άʵ��Ͱ������ǽ������ȥ��������顣�����Ƕ�����������˼����
��һλ�����ȷ���һ����Ϣ��������������9�㿪ʼ��������Ȼ����һ����ʹ����Dz�����Ƿ�ͨ����ɽ�ȣ���һλ�����Ͳ��ö�֪�ˡ��κ�һ��IJ�ȷ���Զ���ʹ�õ�һλ����������ԥ����Ϊ����ڶ�λ����������ͬһʱ�̷����������������е�פ���ͻ�������ľ��ӵĽ������������ľ��Ա��ݻ١�
֪������һ�㣬�ڶ�λ��������Ҫ����һ��ȷ����Ϣ�������յ�������Ϣ��������9��Ĺ����������ǣ��������ȷ����Ϣ����ʹ��ץ��ô�죿���Եڶ�λ��������ԥ�Լ���ȷ����Ϣ�Ƿ��ܵ��
���ǣ��ƺ����ǻ�Ҫ�õ�һλ�����ٷ���һ��ȷ����Ϣ���������յ������ȷ�ϡ���Ȼ���������λ��ʹ��ץ��ô���أ�
����һ�����Dz������ǻ�Ҫ�ڶ�λ��������һ����ȷ���յ����ȷ�ϡ�����Ϣ��
������ᷢ�֣�������ܿ�ͷ�չ��Ϊ���ܷ��Ͷ��ٸ�ȷ����Ϣ����û�а취����֤��λ�������㹻�������Լ�����ʹû�б��о�����
�����������ġ��������������������֤��������E.A.Akkoyunlu,K.Ekanadham��R.V.Huber��1975���ڡ�һЩ���������Ե�����ͨ����ơ�һ���з�����������ƪ���µĵ�73ҳ��һ�����������ڰ�֮���ͨ���б�������
1978�꣬��Jim Gray�ġ����ݿ����ϵͳע�����һ���У��ӵ�465ҳ��ʼ��������Ϊ����������ۡ���Ϊ������������Ķ�������Ե�֤������Դ����һ�ο����㷺�ἰ��
���ʵ�����ڲ�������ͼͨ��������һ�����ɿ��������ϵĽ�����Э��һ���ж�������������ϵľ���ս��
�ӹ�������˵��һ������������������ʵ�ʷ�����ʹ��һ���ܹ�����ͨ���ŵ����ɿ��Եķ�����������ͼȥ����������ɿ��ԣ���Ҫ�����ɿ���������һ�����Խ��ܵij̶ȡ����磬��һλ�����ų���100λ��ʹ��Ԥ�����Ƕ������Ŀ����Ժ�С������������£����ܵڶ�λ�����Ƿ�ṥ�������ܵ��κ���Ϣ����һλ����������й��������⣬��һλ�������Է���һ����Ϣ�������ڶ�λ�������Զ����е�ÿһ����Ϣ����һ��ȷ����Ϣ���������ÿ����Ϣ�������յ�����λ������о����á�Ȼ����֤���������������������ܿ϶���������ǿ���Э���ġ�����û���㷨���ã����磬�յ�4�����ϵ���Ϣ�������ܹ�ȷ����ֹ����һ�����������ߣ���һλ����������Ϊÿ����Ϣ��ţ�˵����1�ţ�2�š���ֱ��n�š����ַ������õڶ�λ����֪��ͨ���ŵ������ж�ɿ������ҷ��غ��ʵ���������Ϣ��ȷ�����һ����Ϣ�����յ�������ŵ��ǿɿ��Ļ���ֻҪһ����Ϣ�����ˣ�����ľͰﲻ��ʲôæ�ˡ����һ���͵�һ����Ϣ��ʧ�ĸ�������ȵġ�
���������������չ�ɸ���̬�İ�ռͥ�������� (Byzantine Generals Problem)������±����������ģ���ռͥλ���������������˹̹�������Ƕ������۹����������ڵ�ʱ��ռͥ�����۹�����������Ϊ�˷���Ŀ�ģ����ÿ�����Ӷ��ָ���Զ�������뽫��֮��ֻ�ܿ��Ų��Ϣ��
��ս����ʱ��ռͥ���������н���������һ�µĹ�ʶ�������Ƿ���Ӯ�Ļ����ȥ������˵���Ӫ�����ǣ����ӿ�������ͽ�͵о��������Щ��ͽ�����ǻ����һ����Ҿ��ߵĹ��̡���ʱ������֪�г�Աı��������£������ҳϵĽ����ڲ�����ͽ��Ӱ������δ��һ�µ�Э�飬����ǰ�ռͥ�������⡣
PAXOS�㷨
Wikipedia�ϵĸ���Paxos�㷨�������dz���ϸ����ҿ���ȥΧ��һ�¡�
Paxos �㷨�������������һ�����ܷ��������쳣�ķֲ�ʽϵͳ����ξ�ij��ֵ���һ�£���֤���۷��������κ��쳣���������ƻ������һ���ԡ�һ�����͵ij����ǣ���һ���ֲ�ʽ���ݿ�ϵͳ�У�������ڵ�ij�ʼ״̬һ�£�ÿ���ڵ㶼ִ����ͬ�IJ������У���ô��������ܵõ�һ��һ�µ�״̬��Ϊ��֤ÿ���ڵ�ִ����ͬ���������У���Ҫ��ÿһ��ָ����ִ��һ����һ�����㷨���Ա�֤ÿ���ڵ㿴����ָ��һ�¡�һ��ͨ�õ�һ�����㷨����Ӧ�������ೡ���У��Ƿֲ�ʽ�����е���Ҫ���⡣��20����80��������һ�����㷨���о���û��ֹͣ����
Notes��Paxos�㷨����˹���������أ�Leslie Lamport������ LaTeX �еġ�La�����������������о�Ժ����1990�������һ�ֻ�����Ϣ���ݵ�һ�����㷨�������㷨�������������û���������ǵ����ӣ�ʹLamport�ڰ����1998�����·�����ACM
Transactions on Computer Systems�ϡ��������paxos�㷨����û�еõ����ӣ�2001��Lamport
����ͬ��������������Ĭ�У������������ܵķ������±�����һ�顣�ɼ�Lamport��Paxos�㷨���ж��ӡ�������Paxos�㷨���ձ�ʹ��Ҳ֤�����ڷֲ�ʽһ�����㷨�е���Ҫ��λ��2006��Google����ƪ���ij��֡��ơ��Ķ��ߣ����е�Chubby
Lock����ʹ��Paxos��ΪChubby Cell�е�һ�����㷨��Paxos�������Ӵ�һ·��쭡���Lamport
����������blog ����д������9��ʱ�䷢������㷨��ǰǰ���
ע��Amazon��AWS�У����е��Ʒ�����һ��ALF��Async Lock Framework���Ŀ��ʵ�ֵģ����ALF�õľ���Paxos�㷨������Amazon��ʱ���ڲ��ķ�����Ƶʱ����������ڲ���Principle
Talk��˵���ο���ZooKeeper�ķ���������������һ�ֱ�ZooKeeper�����ķ�ʽʵ��������㷨��
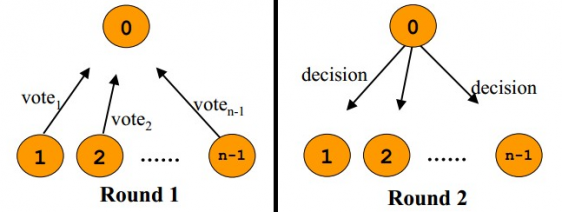
��˵����Paxos��Ŀ������������Ⱥ�Ľ���ij��ֵ�ı�����һ�¡�Paxos�㷨��������˵�Ǹ�����ѡ�ٵ��㷨����������ľ�����ɸ�������Ⱥ��ͳһ�������κ�һ���㶼�������Ҫ��ij�����ݵ�����Ƿ�ͨ������ȡ���������Ⱥ���Ƿ��г��������Ľ��ͬ�⣨����Paxos�㷨��Ҫ��Ⱥ�еĽ���ǵ�������
����㷨�������Σ����������������㣺A��B��C����
��һ�Σ�Prepare��
A�������ĵ�����Prepare Request�������еĽ��A��B��C��ע�⣬Paxos�㷨����һ��Sequence
Number���������Ϊ��һ����ţ���������ϵ�����������Ψһ�ģ�Ҳ����˵A��B����������ͬ����ţ����������Ż��������һͬ�������κν���ڡ�Prepare�Ρ�ʱ����ܾ���ʵС�ڵ�ǰ��ŵ��������ԣ����A�������н�������������ʱ����Ҫ��һ����ţ�Խ�µ���������ž�Խ�������ġ�
������ս���յ������n����������㷢��������ţ���������ӦYes������������µı�����ţ�������֤����������<n���������һ�����������Prepare�������ǻ�����µ������ŵ��
�Ż��������� prepare �����У�����κ�һ����㷢�ִ���һ�����߱�ŵ��������Ҫ֪ͨ ��ˣ��������ж�������
�ڶ��Σ�Accept��
������A�յ��˳��������Ľ�㷵�ص�Yes��Ȼ�����ͻ������еĽ������Accept Request��ͬ������Ҫ�������n�������û�г��������Ļ����Ǿͷ���ʧ�ܡ�
��������յ���Accept Request��������ڽ��յĽ����˵��n�������ˣ���ô�����ͻ������ֵ����������Լ���һ���������ţ���ô�����ͻ�ܾ��ġ�
���ǿ��Կ��ԣ����ƺ�����һ���������ύ�����Ż�����ʵ��2PC/3PC���Ƿֲ�ʽһ�����㷨�IJдΰ汾��Google
Chubby������Mike Burrows˵�����������ֻ��һ��һ�����㷨���Ǿ���Paxos���������㷨���Dzд�Ʒ��
���ǻ����Կ���������ͬһ��ֵ���ڲ�ͬ��������������ڽ��շ��������յ�Ҳ��û������ġ�
����һЩʵ��������Կ�һ��Wikipedia�����еġ�Paxos������һ�ڣ���������Ͳ��ٶ�˵�ˡ�����Paxos�㷨�е�һЩ�쳣ʾ������ҿ����Լ��Ƶ�һ�¡���ᷢ�ֻ�������˵ֻҪ��֤�а������ϵĽ�����û��ʲô���⡣
��˵һ�£��Դ�Lamport��1998�귢��Paxos�㷨��Paxos�ĸ��ָĽ������ʹ�δֹͣ�����ж�������Ī����2005�귢����Fast
Paxos�����ۺ��ָĽ������ص���Ȼ������Ϣ�ӳ������ܡ�������֮����������Ȩ�⡣Ϊ�����شӸ��������ֶ��ߣ���ǰ��Classic
Paxos���Ľ���ĺ���ΪFast Paxos��
�ܽ�
��ͼ���ԣ�Google App Engine��co-founder Ryan
Barrett��2009���google i/o�ϵ��ݽ�:
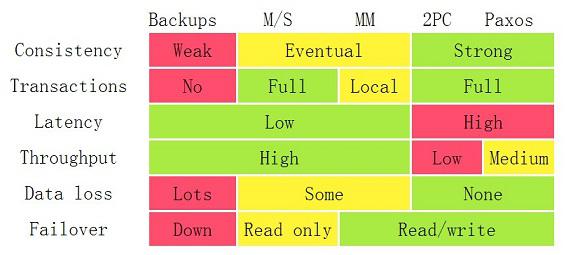
ǰ�棬����˵����Ҫ���������и߿����ԣ�����Ҫ��������д��ݡ�д��ݵ���������һ���Ե����⣬��һ���Ե������ֻ�����������⡣����ͼ���ǿ��Կ��������ǻ�������˵�����������е���������������������CAP���ۣ�һ���ԣ������ԣ����������ԣ������Ҫ���е�������
NWRģ��
����һ�����һ��Amazon Dynamo��NWRģ�͡����NWRģ�Ͱ�CAP��ѡ��Ȩ�������û������û��Լ���ѡ�����CAP�е���������
��νNWRģ�͡�N����N�����ݣ�W����Ҫд������W�ݲ���Ϊ�ɹ���R��ʾ���ٶ�ȡR�����ݡ����õ�ʱ��Ҫ��W+R
> N�� ��ΪW+R > N�� ���� R > N-W �����ʲô��˼�أ����Ƕ�ȡ�ķ���һ��Ҫ���ܱ�������ȥȷ��д�ɹ��ı����IJ�ֵҪ��
Ҳ����˵��ÿ�ζ�ȡ�������ٶ�ȡ��һ�����µİ汾���Ӷ��������һ�ݾ����ݡ���������Ҫ�߿�д�Ļ�����ʱ�����ǿ�������W
= 1 ���N=3 ��ôR = 3�� ���ʱ��ֻҪд�κνڵ�ɹ�����Ϊ�ɹ������Ƕ���ʱ���������еĽڵ㶼�������ݡ��������Ҫ����ĸ�Ч�ʣ����ǿ�������
W=N R=1�����ʱ���κ�һ���ڵ���ɹ�����Ϊ�ɹ�������д��ʱ�����д���������ڵ�ɹ�����Ϊ�ɹ���
NWRģ�͵�һЩ���û���������ݵ����⣬��Ϊ������Բ�����Paxosһ����һ��ǿһ�µĶ��������ԣ�����ÿ�εĶ�д����������ͬһ������ϣ����ǻ����һЩ����ϵ����ݲ��������°汾����ȴ���������µIJ�����
���ԣ�Amazon Dynamo�������ݰ汾����ơ�Ҳ����˵���������������ݵİ汾��v1�����������ɺ�Ҫ�������ݺ�ȴ�������ݵİ汾���Ѿ����˸��³���v2����ô�������ͻ�ܾ��㡣�汾����¾����ֹ�����һ����
���ǣ����ڷֲ�ʽ��NWRģ����˵���汾Ҳ���ж��ε�ʱ�����ǰ汾������⣬���磺����������N=3 W=1�����A����Ͻ�����һ��ֵ���汾��v1
-> v2������û�����ü�ͬ�������B�ϣ��첽�ģ�Ӧ��W=1��дһ�ݾ���ɹ�����B����ϻ���v1�汾����ʱ��B���ӵ�д����������˵������Ҫ�ܾ�����������һ���沢��֪����Ľ���Ѿ������µ�v2����һ������Ҳ���ܾ�����ΪW=1������дһ�־ͳɹ��ˡ����ǣ����������صİ汾��ͻ��
Amazon��Dynamo�Ѱ汾��ͻ�����������ػرܵ��ˡ����汾������½����û��Լ���������
���ǣ�Dynamo������Vector Clock��ʸ���ӣ�!�������ơ���������ÿ�������Լ�¼�Լ��İ汾��Ϣ��Ҳ����˵������ͬһ�����ݣ���Ҫ��¼�����£�1��˭���µ��ң�2���ҵİ汾����ʲô��
���棬��������һ���������У�
һ��д����һ�α��ڵ�A�����ˡ��ڵ�A������һ���汾��Ϣ(A��1)�����ǰ����ʱ������ݼ���D1(A��1)��
Ȼ������һ����ͬ��key�������DZ�A������������D2(A��2)�����ʱ��D2�ǿ��Ը���D1�ģ������г�ͻ������
�������Ǽ���D2�����������нڵ�(B��C)��B��C�յ������ݲ��Ǵӿͻ������ģ����DZ��˸��Ƹ����ǵģ��������Dz������µİ汾��Ϣ����������B��C�����е����ݻ���D2(A��2)������A��B��C�ϵ����ݼ���汾�Ŷ���һ���ġ�
���������һ���µ�д������B����ϣ�����B�����������D3(A,2; B,1)����˼�ǣ�����Dȫ�ְ汾��Ϊ3��A�������£�B����һ�Ρ��ⲻ������ν�Ĵ���汾��logô�����D3û�д�����C��ʱ����һ������C�����ˣ����ǣ���C����ϵ�������D4(A,2;
C,1)��
���D3û�д�����C��ʱ����һ������C�����ˣ����ǣ���C����ϵ�������D4(A,2; C,1)��
�ã���ʵ��������ˣ�������ʱ������һ������������Ҫ�ǵã����ǵ�W=1 ��ôR=N=3������R������������ڵ��϶�����ʱ��������������汾��
A��㣺D2(A,2)
B��㣺D3(A,2; B,1);C��㣺D4(A,2; C,1)
C��㣺D4(A,2; C,1)
6.���ʱ������жϳ���D2�Ѿ��Ǿɰ汾���Ѿ�������D3/D4�У�������������
7.����D3��D4�����Եİ汾��ͻ�����ǣ��������÷��Լ�ȥ���汾��ͻ����������Դ����汾����һ����
�����ԣ�������Dynamo�������õ���CAP���A��P�� |


