���
���Ľ�����һ��Hadoop2.2.0��Ⱥ�Ĵ���̣���2̨4G�ڴ�Ŀ��˫��PC���ϣ�ʹ��VMWare
WorkStation������4��RHEL6.2��1G�ڴ桢����CPU��10GӲ�̣����ܼ���10��Сʱ��ʱ�䣬��������������Hadoop�������̣�����Ƚ�˳����
���μ�Ⱥ������У���Ҫ�����������⣺
��1����һ���ǣ�DataNode�����ˣ�ʹ��jps���Կ������̣���������NameNode�п�������192.168.1.10:50070�������Ѵ�Լ3��Сʱʱ������⣬����logsĿ¼����־��org.apache.hadoop.ipc.Client:
Retrying connect to server: master/192.168.1.10:9000�������ٶ���������������˵�Ƿ���ǽû�ص����⣬�����ҵķ���ǽ�����ˡ������ַ�ʽ���ԣ�ԭ����/etc/hosts�У�����master���˶�Ӧ��192.168.1.10֮�⣬�һ���Ӧ����127.0.0.1��ȥ��֮�������������Ͷ����ˡ�
��2���ڶ����ǣ��������⣬���format namecode��ɵ�DataNode��������ɾ��/home/hadoop/dfs/data/current/VERSION�ͺ��ˡ�
��3���������ǣ����밲ȫģʽ�����˳�����ʼ�����ֹ��˳���hadoop fs -safemode leave������ʹ��hdfs
fsck /�����ֻ�������ϴ�70+%������Ӳ�̺ö����ˣ����ƻ����϶࣬Ҳ������ǿ�ƹػ���һЩ�����쳣���£���Ȼ��ǿ��������һ��
hdfs fsck / -delete������hadoop���ͻ��Զ��뿪��ȫģʽ�ˡ�
��4�����־�����ܽ��
Hadoop��ʲô
Hadoop��Lucene��ʼ��Doug Cutting������Google���������ɽկ�����ķֲ�ʽ�ļ�ϵͳ�ͶԺ������ݽ��з�������Ļ������ϵͳ�����а���MapReduce����hdfsϵͳ�ȡ�
���ʽ���
��1��Hadoop��Apache��Դ�ķֲ�ʽ��ܡ�
��2��HDSF��Hadoop�ķֲ�ʽ�ļ�ϵͳ��
��3��NameNode��Hadoop HDFSԪ�������ڵ�����������𱣴�DataNode �ļ��洢Ԫ������Ϣ������������ǵ���ġ�
��4��JobTracker��Hadoop��Map/Reduce��������������TaskTrackerͨ�ŷ������������������ȣ����������Ҳ�ǵ���ġ�
��5��DataNode��Hadoop���ݽڵ㣬����洢���ݡ�
��6��TaskTracker��Hadoop���ȳ�����Map,Reduce�����������ִ�С�
Hadoop1�ļ�Ⱥ����ṹͼ
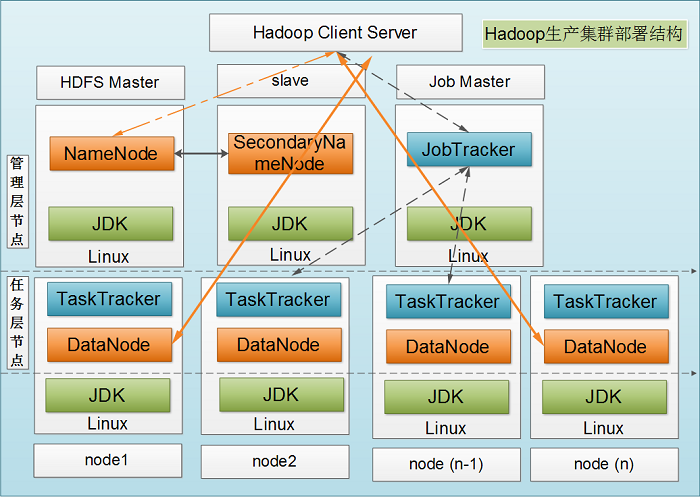
Hadoop1�����������ϵͼ

Hadoop2��Yarn�ܹ�ͼ

��װRHEL����
ʹ��VMWare WorkStation��װ�������
http://blog.csdn.net/puma_dong/article/details/17889593#t0
http://blog.csdn.net/puma_dong/article/details/17889593#t1 |
��װJava������
http://blog.csdn.net/puma_dong/article/details/17889593#t10 |
��װ���֮��4̨�����IP�������������£�
192.168.1.10 master
192.168.1.11 node1
192.168.1.12 node2
192.168.1.13 node3 |
����ͨ��vim /etc/hosts�鿴��ע�⣺��/etc/hosts�У���Ҫ�ѻ������֣�ͬʱ��Ӧ��127.0.0.1�����ַ���ᵼ�����ݽڵ����Ӳ��������ڵ㣬�������£�
org.apache.hadoop.ipc.Client: Retrying connect to server: master/192.168.1.10:9000 |
��װ���֮��Javaλ�����£�/usr/jdk1.6.0_45 ������ͨ��echo $JAVA_HOME�鿴��
����Hadoop����
����Hadoop�˺�
��1������Hadoop�û��飺groupadd hadoop
��2������Hadoop�û���useradd hadoop -g hadoop
��3������Hadoop�û����룺passwd ����hadoop
4����hadoop�˻�����sudoȨ�ޣ� vim /etc/sudoers
���������ݣ�hduser ALL=(ALL) ALL
ע�⣺���϶���ÿһ̨������Ҫִ��
����master��slave���������¼
��1���л���Hadoop �û��£�su hadoop cd /home/hadoop/
��2�����ɹ�Կ��˽Կ��ssh-keygen -q -t rsa -N ""
-f /home/hadoop/.ssh/id_rsa
��3���鿴��Կ���ݣ�cd /home/hadoop/.ssh cat id_rsa.pub
��4������id_rsa.pub��Կ�� authorized_keys �ļ���cat
id_rsa.pub > authorized_keys
��5����master��ԿȨ�ޣ�chmod 644 /home/hadoop/.ssh/authorized_keys
��6���� master �����ϵ� authorized_keys �ļ�
copy �� node1 �ڵ��ϣ�
scp /home/hadoop/.ssh/authorized_keys node1:/home/hadoop/.ssh/ |
���node1/node2/node3������û��.sshĿ¼��������chmod
700 /home/hadoop/.ssh
��װHadoop
��װĿ¼
Hadoop��װĿ¼��/home/hadoop/hadoop-2.2.0
�ļ�Ŀ¼��/home/hadoop/dfs/name ��/home/hadoop/dfs/data
��/home/hadoop/tmp
��װ����
ע�⣺���²���ʹ��hadoop�˺Ų�����
��1��ת�� home/hadoopĿ¼��cd /home/hadoop
��2������hadoop��wget http://mirror.esocc.com/apache/hadoop/common/stable2/hadoop-2.2.0.tar.gz
��3����ѹhadoop���ŵ��ƻ���װλ�ã�tar zxvf hadoop-2.2.0.tar.gz
��4�������ļ�Ŀ¼��mkdir -p /home/hadoop/dfs/name
/home/hadoop/dfs/data /home/hadoop/tmp
��5����7�������ļ����ļ�λ�ã�/home/hadoop/hadoop-2.2.0/etc/hadoop/���ļ����ƣ�hadoop-env.sh��yarn-evn.sh��slaves��core-site.xml��hdfs-site.xml��mapred-site.xml��yarn-site.xml
�����ļ�hadoop-env.sh
���ϵͳ��������������$JAVA_HOME��������ļ������ģ�����Ҫ��${JAVA_HOME}Ϊ��/usr/jdk1.6.0_45
�����ļ�yarn-env.sh
���ϵͳ��������������$JAVA_HOME��������ļ������ģ�����Ҫ��${JAVA_HOME}Ϊ��/usr/jdk1.6.0_45
�����ļ�slaves
vim /home/hadoop/hadoop-2.2.0/etc/hadoop/slaves��������Ϊ���е�DataNode�Ļ������֣�ÿ������һ�У���ƪ���µ��������£�
�����ļ�core-site.xml
vim /home/hadoop/hadoop-2.2.0/etc/hadoop/core-site.xml����configuration�������£�
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration> |
hadoop.tmp.dir��Ĭ��ֵ��/tmp/hadoop-${user.name}
�����ļ�hdfs-site.xml
vim /home/hadoop/hadoop-2.2.0/etc/hadoop/hdfs-site.xml����configuration�������£�
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration> |
dfs.namenode.name.dir��Ĭ��ֵ��file://${hadoop.tmp.dir}/dfs/name
dfs.namenode.data.dir��Ĭ��ֵ��file://${hadoop.tmp.dir}/dfs/data
�����ļ�mapred-site.xml
vim /home/hadoop/hadoop-2.2.0/etc/hadoop/mapred-site.xml����configuration�������£�
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration> |
���ýڵ�yarn-site.xml
vim /home/hadoop/hadoop-2.2.0/etc/hadoop/yarn-site.xml����configuration�������£�
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration> |
����Hadoop�������ڵ�
��1��scp -r /home/hadoop/hadoop-2.2.0
hadoop@node1:~/
��2��scp -r /home/hadoop/hadoop-2.2.0
hadoop@node2:~/
��3��scp -r /home/hadoop/hadoop-2.2.0
hadoop@node3:~/
����Hadoop
��1���л���hadoop�û���su hadoop
��2�����밲װĿ¼�� cd ~/hadoop-2.2.0/
��3����ʽ��namenode��./bin/hdfs namenode �Cformat
����ʽ�������$dfs.namenode.name.dir/current����һϵ��Ŀ¼
��4������hdfs�� ./sbin/start-dfs.sh
��5��jps�鿴����ʱmaster�н��̣�NameNoce SecondaryNameNode��node1/node2/node3���н��̣�DataNode
��6������yarn�� ./sbin/start-yarn.sh
��7��jps�鿴����ʱmaster�н��̣�NameNoce SecondaryNameNode
ResourceManager��node1/node2/node3���н��̣�DataNode NodeManager
��8���鿴��Ⱥ״̬��./bin/hdfs dfsadmin -report
��9���鿴�ļ�����ɣ� ./bin/hdfs fsck / -files
-blocks
��10��Web�鿴HDFS�� http://192.168.1.10:50070
��11��Web�鿴RM��Resource Manager���� http://192.168.1.10:8088
��12��Web�鿴NM��Node Manager����http://192.168.1.11:8042
��13������JobHistory Server��mr-jobhistory-daemon.sh
start historyserver������ͨ����http://192.168.1.10:19888/
�鿴����ִ����ʷ��Ϣ����ֹJobHistory Server��ִ���������mr-jobhistory-daemon.sh
stop historyserver ��
HADOOP_HOME��������
�����з��㣬��������һ��HADOOP_HOME����������������PATHĿ¼���������£�
��1��vim /etc/profile.d/java.sh #��Ϊhadoop����java���������ǰ�ʹ������ļ����ɡ�
��2���������ݣ�
export HADOOP_HOME=/home/hadoop/hadoop-2.2.0
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH |
����Hadoop��������
WordCount
��1��/home/hadoopĿ¼���������ı��ļ�file01.txt��file02.txt���ļ����ݷֱ�Ϊ��
file01.txt��
kongxianghe
kong
yctc
Hello World
file02.txt��
11
2222
kong
Hello
yctc |
��2�����������ļ�����hadoop��HDFS�У�
hadoop fs -ls //�鿴hdfsĿ¼���
hadoop fs -mkdir -p input
hadoop fs -put /home/hadoop/file*.txt
input
hadoop fs -cat input/file01.txt //�鿴����
��3�����㲢�鿴�����
hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount input output
hadoop fs -ls output
hadoop fs -cat output/part-r-00000 |
���Կ������ݶ��Ѿ���ͳ�Ƴ����ˡ�
hadoop fs������ʹ��hdfs dfs�����Dz�Ҫʹ��hadoop dfs����Ϊ�Ѿ����Ƽ�ʹ���ˣ����о��档
����������
Hadoop�Դ�һЩ�����Գ����������Լ�Ⱥ���ܡ����磺
���µ������������ÿ���ڵ�����10��G��������֣�Ȼ������������
��1��./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar
randomwriter rand
��2��./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar
sort rand sort-rand
��һ���������rand Ŀ¼������û����������ݡ��ڶ������������ݣ�����Ȼ��д��rand-sort
Ŀ¼��
���磬hadoop_*_test.jar TestDFSIO����������IO���ܣ��������õĻ��У�
��1��MRBench��ʹ��mrbenchѡ���������һ��С����ҵ���Լ���С����ҵ�ܷ���ٵ���Ӧ��
��2��NNBench��ʹ��nnbenchѡ�ר�����ڲ���namenodeӲ���ĸ��ء�
��3��Gridmix��һ�������Գ�����װ��ͨ��ģ��һЩ��ʵ���������ݷ���ģʽ���ܱ����Ϊһ����Ⱥ�ĸ��ؽ�ģ��
��������
��1��Name node is in safe mode
����hadoop����ʱ�� �쳣��ֹ�ˣ�Ȼ������hdfs���ļ���ɾ���ļ�ʱ������Name
node is in safe mode����
rmr: org.apache.hadoop.dfs.SafeModeException: Cannot delete /user/hadoop/input. Name node is in safe mode |
��������
hdfs dfsadmin -safemode leave #�ر�safe mode |
��2��DataNode ������
�����������������DataNode����������һ����/etc/hosts����������ֳ��˺�IP��Ӧ֮�⣬����127.0.0.1��Ӧ������DataNode����NameNode��9000�˿�һֱ���Ӳ��ϣ��ڶ����Ƕ��format
namenode ���namenode ��datanode��clusterID��һ�£�ͨ���鿴NameNode��DataNode��/home/hadoop/dfs/data/current/VERSION������ȷʵ��һ�¡�
��֮����������Ҫ�ţ����$HADOOP_HOME/logs�������־�������ҵ����⡣ |


