|
使用一个真实的客户场景分析面临的难题及其解决方式,以确保持续部署。持续交付已经成为在云平台上交付解决方案一种常见模式。要让持续交付成为可能,所有构建、部署、测试与发布阶段都需要自动完成,以提供频繁的迭代,这样开发人员和操作专业人员才能时刻了解代码变化与缺陷修复。过程自动化程度的提高也会提高云交付的效率。应用本文中的安装与部署技术改进了解决方案安装程序,让它更适合于持续部署和交付。本文演示了一种改变解决方案安装与配置来支持持续部署的方法。
简介
随着云计算技术的发展,云环境被认为是向客户交付行业解决方案的最有前途的方式。为了确保软件的持续交付,开发、测试与运营团队必须相互协作,在一起高效工作。云环境非常适合这种类型的交互。然而,因为开发阶段涉及到复杂的分布式拓扑,很容易出错,而且通常需要手动排除故障。在很多情况下,部署设计支持单一部署,不支持持续部署。应用持续交付原则的产品部署阶段经常成为瓶颈,同时还会给 DevOps 过程的效率带来负面影响。
本文将使用一个真实的客户场景来分析面临的难题及其解决方式,以确保持续部署。
致力于行业部署自动化的软件工程师会发现本文很有用处,可以帮助他们实现云上的持续交付。这些指导假定您拥有部署行业解决方案和开发脚本方面的技巧。
持续交付过程
持续交付的目标是确保能够使用最有效和安全的方法来开发、测试、部署软件并将其交付生产。对软件系统任意部分所做的改动,从基础架构层、应用层到定制数据层,通过一条特定的交付管道持续应用于生产环境。这种方法让用户相信,产品环境能够访问最新发布的代码。
常用的模型与框架
如图 1 中所示的通用模型广泛应用于大多数 IBM 行业解决方案的交付中。
图 1. 常用的持续交付模型
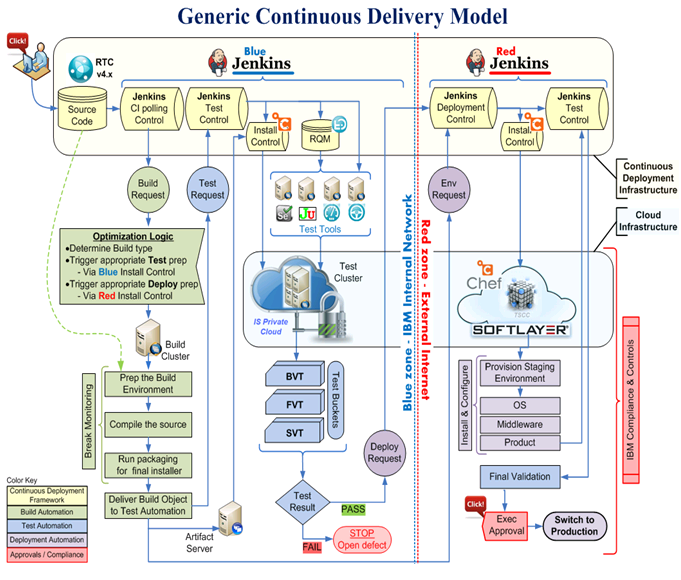
图 1 演示了一条端到端的自动化通道,它将解决方案开发与生产环境联系起来。该通道使用 Jenkins 作为一种自动化引擎,可以:
1.检测代码更改和触发持续构建。
2.将构建版本安装到 Blue 区。Blue 区被认为是 DevOps 团队在本地进行构建确认的测试环境。
3.在 Blue 区上开始自动化测试并确认测试结果。
4.当 Blue 区准备就绪并经过确认后,从测试环境切换到运行的生产环境(Red 区)。
持续交付中的并发因素
步骤 2 是本文的主要重点。在持续交付过程中,最具有挑战性的方面是如何高效地实现持续部署。部署阶段必须适应复杂的分布式拓扑、不断变化的基础架构和配置变更。这些并发因素很容易导致客户数据的丢失。传统的解决方案部署设计支持单一部署,但不支持持续部署。
为了减少错误,让过程变得更加高效,并节省 DevOps 时间与工作量,需要最大限度地提高解决方案部署与排除故障的自动化程度。我们要做的第一步是了解在真实的解决方案部署场景中可能遇到的难题。
行业解决方案部署案例
考虑每月在云平台上交付一个行业解决方案的场景。因为 DevOps 团队必须在生产环境中部署每月一次的构建,安装程序需要能够在部署过程开始时运行在生产环境中。
持续交付过程中的常见问题
下面的例子从安装角度说明了一些常见问题:
1.文件替换
2.资源更新
3.数据库配置
4.文件替换
通常需要更新或替换配置文件。在清单 1 中,安装程序在安装时替换了第 3 行中的占位符。第 4 行中的 URL 是根据运行时的用户输入进行设置的。
一个新的要求让安装程序在稍后的一次迭代中在安装时添加一个新的 URL someURL。传统的解决方案是将 <someURL>@url@<someURL> 附加到第 4 行并完全替换占位符,但这种方法会导致错误并丢失 customizationURL 的用户输入。
清单 1. 带有用于主机和 URL 的示例占位符的脚本
1 <servers>
2 <server id="appServer">
3 <host>@host@</host>
4 <customizationURL>@cusUrl@</customizationURL>
5 </servers> |
资源更新
假定您有一个使用 Java Naming and Directory Interface (JNDI) 创建的应用服务器调度程序,名叫 test/schedulerA。相关的表是使用前缀testA_ 进行创建的。过一段时间,您需要将这个调度程序的表前缀重命名为 testB_。通常,您可能会调用 WebSphere Application Server API AdminControl 来更新对新表的调度程序引用。但对持续更新而言,旧表已经创建,即便是毫无用处也不会删除。当另一调度程序使用 testA_前缀时,就会出现错误。
数据库配置
数据库配置变更将带来最具有挑战性的问题。由于解决方案被更新,数据库会仔细检查对表结构、用户权限、已存储数据的变更和其他变更。适应变化的选择之一是在 SAMPLE.TEST_TAB 表中插入一个新的 COL_C 列。但在下一次迭代中,表结构将会发生变化。例如,需要删除 COL_B列。清单 2 中显示了一种应对变更的传统部署调整,即在数据库脚本中添加第 6 行。
清单 2. 使用新行删除数据库中一列的脚本
1 CREATE TABLE SAMPLE.TEST_TAB (
2 "COL_A" INTEGER NOT NULL ,
3 "COL_B" VARCHAR(100) )
4 IN "USERSPACE1" ;
5 ALTER TABLE SAMPLE.TEST_TAB 6 DROP COLUMN COL_B 7 ADD COLUMN COL_C INTEGER; |
但在持续交付中,添加一行会导致错误,因为:
1.当脚本第二次运行时,SAMPLE.TEST_TAB 已经存在。
2.列 COL_B 已经被删除。因此,SQL 处理将在没有添加 COL_C 的情况下停止。
适用于解决持续交付问题的原则
为了解决文件变化、资源更新与配置变更所带来的问题,可使用以下原则。
最小化解决方案安装程序所需的开发工作量。 不要为每次交付开发不同的安装程序,确保开发阶段中的所有变更都能被快速而又安全地交付生产。开发新部署时,尽可能从过去的迭代进行继承。例如,假设您已经在前一次迭代中开发了 Resource A。在当前迭代中,Resource A 没有发生变化,但您需要添加一个新资源 Resource B。添加脚本以创建 Resource B,但即便对于 Resource A 没有新的需求,也要保持创建 Resource A 的前一个脚本。
针对安装阶段使用自动的故障排除。持续交付的效率在很大程度上依赖于过程的自动化程度。因为环境之间存在的差异、手动操作引起的错误和其他类似的因素,您必须提供处理故障和安装失败的自动机制。
支持重复部署解决方案的能力。 这条原则最为关键,也最难实现。为了尽可能地从过去的迭代进行继承,比如确定如何:
管理重复部署。
1.使用现有的基础架构与资源来部署新代码。
2.更新以前的配置或者删除过时的部署。
解决方案安装程序的元素
修改典型解决方案安装程序的以下方面,以便改进解决方案部署:
文件构件
企业应用程序 和 企业相关资源
数据库
文件构件
为了持续交付,安装过程必须能够:
1.复制和替换构件
2.集成构件
3.合并构件。
为了防止出现 文件替换的问题 中提及的客户数据丢失,将客户数据合并到新版本的文件中,而不是简单地复制和替换文件。清单 3 中显示了过去与当前迭代的文件:old.xml 和 new.xml。
清单 3. old.xml 与 new.xml 之间的比较
[root@server diff]# cat old.xml
<servers>
<server id="appServer">
<host>appserver.test.com</host>
<customizationURL>http://abc.com</customizationURL>
</servers> [root@server diff]# cat new.xml
<servers>
<server id="appServer">
<host>appserver.test.com</host>
<customizationURL>@cusUrl@</customizationURL>
<someURL>http://someOtherUrl<someURL>
</servers>
|
为了通过编程方式合并文件,给安装程序添加脚本(用于 Linux 的 Shell 脚本)来找出版本之间的差异。将差异记录到一个文件中,以备日后以补丁的形式处理这些差异。然后通过搜索补丁来获取老版本文件中的定制信息,再将所有变更合并到当前文件中,如清单 4 中所示。
清单 4. 以编程方式合并文件
[root@server diff]# diff old.xml new.xml > patch.txt
[root@server diff]# cat patch.txt
4c4,5
< <customizationURL>http://abc.com</customizationURL>
--- > <customizationURL>@cusUrl@</customizationURL>
> <someURL>http://someOtherUrl<someURL>
[root@server diff]#
|
企业应用
在整个持续交付过程中,企业应用程序都会发生改变。这种改变可以出现在代码、资源和 EAR 结构中。因为更改会影响安装脚本,您必须清楚对模型的所有更改,以及对 EAR 模块与目标部署服务器之间映射的更改。要管理变更,可以使用一个自动程序来生成 EAR 部署代码。
首先,在构建阶段从 application.xml 文件中提取定义好的模型信息。清单 5 显示了一个目标 application.xml 文件的例子。
清单 5. 示例应用描述符
<?xml version="1.0" encoding="UTF-8"?>
<application xmlns="http://java.sun.com/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee version="5"
http://java.sun.com/xml/ns/javaee/application_5.xsd">
<display-name>sample_rest_ear</display-name>
<module id="Module_1361859780281">
<web>
<web-uri>sample_test_rest.war</web-uri>
<context-root>/ibm/test/api/services</context-root>
</web>
</module>
<module id="Module_1364467704309">
<ejb>sample_test_ejb.jar</ejb>
</module>
</application>
|
接下来,自动生成部署描述符。该描述符基于已获取到的模型信息。清单 6 显示了一个示例的部署描述符属性文件,它描述了显示名称、EAR 文件位置和要映射到所要部署应用的模块。通过使用属性文件,可以确保应用部署参数更加灵活,更容易自动化。
清单 6. 描述应用部署的示例属性文件
application.0.name=sample_rest_ear
application.0.earfile=content/config/apps/sample_rest_ear.ear
application.0.module.0.name=sample_test_rest
application.0.module.0.moduleFile=sample_test_rest.war
application.0.module.0.deployment=WEB-INF/web.xml
application.0.module.0.cluster.0.name=~{PORTAL_CLUSTER_NAME}
application.0.module.1.name=sample_test_ejb
application.0.module.1.moduleFile=sample_test_ejb.jar
application.0.module.1.deployment=META-INF/ejb-jar.xml
application.0.module.1.cluster.0.name=~{PORTAL_CLUSTER_NAME}
|
后端代码解析属性,并调用一个应用服务器 API 来部署它。如清单 7 中所示,参数 deploymentInstruction_attrs 是根据清单 6 中的属性生成的。
清单 7. deploymentInstruction_attrs 的示例值
[ -operation update -contents
sample_rest_ear.ear -installed.ear.destination
$(APP_INSTALL_ROOT)/cell1 -distributeApp
-MapModulesToServers [[sample_test_rest sample_test_rest.war,WEB-INF/web.xml
WebSphere:cell=cell1,cluster=ClusterA+WebSphere:cell=cell1, node=ihsnode1,server=ihsserver1 ]
[sample_test_ejb sample_test_ejb.jar META-INF/ejb-jar.xml
WebSphere:cell=cell1,cluster=ClusterA]]]
|
清单 8 显示了如何调用应用服务器 API 来执行一次可重复的安装。
清单 8. 调用应用服务器 API 来执行可重复安装的示例脚本
if (exist == "true"):
# 现有应用已经找到 AdminApp.update(appNametrim,
'app',
deploymentInstruction_attrs)
else: # Existing application not found.
AdminApp.install(earFile, deploymentInstruction_attrs)
#endIf
|
AdminApp 提供了函数 update()、install() 和 uninstall() 来配置 EAR 部署。使用 update 函数而非 delete 函数,以便反复部署应用程序。
企业应用程序资源
部署应用程序资源的配置类似于部署应用的配置。使用 update 函数而非 delete 和 re-create 函数,以避免丢失配置中的任意自定义设置。因为应用资源的部署包含资源之间的关系,所以可以使用一个与 Java 中垃圾收集方法类似的方法来维护这些关系。
清单 9 显示了应用服务器调度程序 schedulerA 的示例部署描述符属性,这一点在 资源更新的问题 部分中已经提及。选择是否要创建相关的数据库表。如果选择创建相关表,应用服务器就会使用数据源定义的模式(在本例中为 jdbc/ds)和前缀(在本例中为 testA)生成数据库表。
清单 9. 描述调度程序部署的示例属性文件
scheduler.0.name=schedulerA
scheduler.0.jndiname=test/schedulerA
scheduler.0.description=Scheduler for Task A
scheduler.0.datasourceJNDIName=jdbc/ds
scheduler.0.datasourceAlias=dbuser
scheduler.0.workManagerInfoJNDIName=wm/default
scheduler.0.tablePrefix=testA_ scheduler.0.createTables=true
scheduler.0.target.cluster=~{PORTAL_CLUSTER_NAME}
|
使用 DBUSR 与前缀 TESTA_ 创建的相关表如图 2 中所示。
图 2. 已创建表的列表
只要调度程序表的前缀或数据源引用发生变化,就需要在创建新表之前回收被引用的表。为此,可以使用类似于清单 10 的部署描述符。
清单 10. 调用应用服务器 API 执行可重复的调度程序安装的示例脚本
if (existScheduler):
if (createTables):
#drop existing old tables if new tables required
cellNameStr = 'cell=' + getCellName()
nodeNameStr = 'node=' + getNodeName()
Scheduler_Config_Helper_str = AdminControl.completeObjectName
('WebSphere:name=Scheduler_Config_Helper,process=dmgr,platform=dynamicproxy,' + nodeNameStr + ',
type=WASSchedulerCfgHelper,mbeanIdentifier=Scheduler_Config_Helper,' + cellNameStr + ',*')
AdminControl.invoke(Scheduler_Config_Helper_str, 'dropTables', scheduler, '[java.lang.String]')
#endIf
AdminConfig.modify(scheduler, deploymentInstruction_attrs)
#endIf
else:
attrs.append(["name", name])
scheduler = AdminConfig.create("SchedulerConfiguration", schedulerProvider,
deploymentInstruction_attrs)
#endIf
|
数据库
数据库配置是持续交付中需要处理的最复杂的方面。频繁的数据库配置变更和代码更新会让安装过程变得容易出错。考虑以下例子,它显示了当数据库变更被传播到测试或生产环境中时出现的错误。
错误 1:创建表错误
在传统的安装程序中,每条 SQL 指令只会运行一次。但在持续交付的情况下,SQL 指令可能会重复运行,以便适应每月、每周或每天的交付。在清单 11 中,因为脚本不适应重复运行而导致表创建失败。您可以忽略这类错误。
清单 11. 表创建错误示例
CREATE TABLE SAMPLE.TEST_TAB
( COLA INTEGER NOT NULL,
COLB VARCHAR(200) NOT NULL UNIQUE ) ;
SQL failed with: The name of the object to be created is identical to the existing name
"SAMPLE.TEST_TAB" of type "TABLE".. SQLCODE=-601, SQLSTATE=42710, DRIVER=3.64.106
|
错误 2:修改表错误
修改表时会遇到与错误 1 中类似的情况。如果删除代码运行多次就会失败,如清单 12 中所示。但与错误 1 不同,您不能忽略这种错误,因为其余针对 COL_C 的代码将无法运行。
清单 12. 修改表错误示例
ALTER TABLE SAMPLE.TEST_TAB
DROP COLUMN COL_B
ADD COLUMN COL_C INTEGER;
SQL failed with: Column, attribute, or period "COL_B" is not defined in
"SAMPLE.TEST_TAB"..SQLCODE=-205,SQLSTATE=42703, DRIVER=3.64.106
|
错误 3:数据错误
假设 COL_A 已经被设置为 TEST_TAB 中的主键。前面的 SQL 使用如清单 13 中所示的 SQL 指令在数据库中插入了数据。
清单 13. 前面交付中执行的 SQL
INSERT INTO SAMPLE.TEST_TAB (COL_A, COL_B) VALUES ('max_number_to_display', '20');
|
当业务逻辑变更时,要求会随之变化,而 SQL 指令也会被更新,如清单 14 中所示。
清单 14. 当前交付中已更新的 SQL
INSERT INTO SAMPLE.TEST_TAB (COL_A, COL_B) VALUES ('max_number_to_display', '40');;
DB2 SQL error: SQLCODE: -803, SQLSTATE: 23505, SQLERRMC: 1;SAMPLE.TEST_TAB, DRIVER=4.12.55
|
这种更改对于传统安装程序完全没问题,但在持续交付中是无效的,因为前面的代码已经部署在前面的交付中。
这些错误示例显示了在针对持续交付部署的数据库配置过程中实现安装可重复性的必要性。用于持续交付部署的安装程序必须提供更高的可重复性。应用以下模式来实现数据库配置的安装可重复性。
模式 A:让 SQL 脚本变得安全以便多次运行
为了防止类似于 错误 2 的错误,并确保脚本运行多次时 SQL 脚本的正确性,禁止访问已被直接更新的现有 SQL 语句。
避免在代码开发与代码评审期间直接更新 SQL 脚本。相反要交付代码变更给现有配置(无论变更是针对现有表结构还是现有数据),具体方法是将更改划分为更小的单元,然后将代码片段附加到现有脚本的末尾。为了避免类似于 错误 2 的错误,使用清单 15 中的 SQL 脚本。这个脚本确保当脚本运行多次时,可成功将代码添加 COL_C。
清单 15. 经过优化的修改表脚本
ALTER TABLE SAMPLE.TEST_TAB
DROP COLUMN COL_B; ALTER TABLE SAMPLE.TEST_TAB
ADD COLUMN COL_C INTEGER;
|
模式 B:应用选择性的安装验证
验证传统安装时,安装验证器会检查数据库安装日志,并记录检测到的所有 SQL 错误。但在持续交付中,SQL 脚本可以运行多次。避免每个 SQL 错误几乎是不可能的。过滤出不重要的错误和可以忽略的错误,比如:
1.创建重复的表、列、模式、键等
2.删除不存在的对象
3.插入重复数据
选择性验证可以确保重要错误受到最大的关注,并得到诊断与修复。
模式 C:简化与加速 SQL 脚本的运行
随着数据库相关代码的持续添加,安装程序变得越来越大。应用以下过程可以提高部署的成功率和性能。
- 定期对脚本进行存档。 例如,假设每月将代码交付生产。脚本可以每月进行存档,如图 3 中所示。
图 3. 存档脚本的文件结构
除了文件夹之外,content-spec_<time stamp> 可用于识别调用脚本的命令。如清单 16 中所示,脚本来自于 content-spec_201311.xml 文件,它调用了 November 存档文件夹中的脚本。
清单 16. content-spec_201311.xml 的内容
<SYS command="db2 connect to DB" />
<SQL file="content/config/script/201311/delta_ update.ddl" />
<SQL file="content/config/script/201311/delta_sample_data_ update.ddl" />
<SYS command="db2 commit work;db2 CONNECT RESET;db2 TERMINATE;" />
|
- 将时间戳映射到存档文件。 脚本存档后,建立一个自动方法将时间戳与已存档构件进行映射,比如清单 17 中所示的映射文件。在清单中,timestamp 参数表示脚本存档时的特定日期。对该日期所做的代码变更包含在存档文件夹内。
清单 17. 映射文件示例
<buildHistory projectName="Sample_Project">
<build timestamp="20131130" folder="201311" />
<build timestamp="20131230" folder="201312" />
<build timestamp="20140130" folder="201401" />
<build timestamp="20140228" folder="201402" />
</buildHistory>
|
- 自动生成脚本队列。将存档文件夹与时间戳映射之后,安装程序会整合目标脚本并自动生成脚本执行队列。首先它会检测当前的构建级别,并将该构建级别与清单 17 中定义的 timestamp 参数进行比较。对于时间戳比当前构建级别晚的每一项,都会运行映射文件夹中的脚本,如清单 18 中所示。
清单 18. 整合脚本以管理存档的数据库脚本
scriptLocation=$(cd -P -- "$(dirname -- "$0")" && pwd -P)|
# build level get from user's current environment
startVersion=$1
if [[ $startVersion == "" ]];
then $startVersion="00000000"
fi
# mapping file containing relationship between time stamp and archived
fname="$scriptLocation/buildHistory.xml"
exec<$fname while read line
do
if grep -q timestamp <<<$line;
then
timestamp=`echo $line | awk '{print $2}' | sed 's/timestamp=//' | sed 's/.\(.*\)/\1/' | \ sed 's/\(.*\)./\1/'`
if (( "$timestamp" > "$startVersion" ));then
folder=`echo $line | awk '{print $3}' | sed 's/folder=//' | sed 's/.\(.*\)/\1/' | \ sed 's/\(.*\)./\1/'`
FOLDERARRAY[$index]="$folder"
index=$(($index+1))
fi
fi
done
|
例如,如果当前用户环境上的构建级别是 20140205,那么只会调用在文件夹 201402 中存档的脚本,因为文件夹的映射时间戳为 20140228。对于其他文件夹,安装程序假设它们在使用构建级别 20140205 进行部署之后已经运行。整合后的 cont-spec 文件看起来类似于清单 19。它包含最后一个月的所有 delta 脚本。
清单 19. 由整合脚本生成的 Delta 脚本
<SYS command="db2 connect to DB" />
<SQL file="content/config/script/201311/delta_ update.ddl" />
<SQL file="content/config/script/201311/delta_sample_data_ update.ddl" />
<SQL file="content/config/script/201312/delta_ update.ddl" />
<SQL file="content/config/script/201401/delta_ update.ddl" / <SQL file="content/config/script/201401/delta_sample_data_ update.ddl" />
<SQL file="content/config/script/201402/delta_ update.ddl" />
<SYS command="db2 commit work;db2 CONNECT RESET;db2 TERMINATE;" />
|
|





