|
DataFrame APIΒΡ“ΐ»κ“ΜΗΡRDD APIΗΏάδΒΡFPΉΥΧ§Θ§ΝνSpark±δΒΟΗϋΦ”ΤΫ“ΉΫϋ»ΥΓΘΆβ≤Ω ΐΨί‘¥APIΧεœ÷≥ωΒΡ‘ρ «Φφ»ί≤Δ–νΘ§Spark SQLΕύ‘Σ“ΜΧεΒΡΫαΙΙΜ· ΐΨί¥ΠάμΡήΝΠ’ΐ‘Ύ÷πΫΞ ΆΖ≈ΓΘ
ΙΊ”ΎΉς’ΏΘΚΝ§≥«Θ§DatabricksΙΛ≥Χ ΠΘ§Spark committerΘ§Spark SQL÷ς“ΣΩΣΖΔ’Ώ÷°“ΜΓΘ‘Ύ4‘¬18»’’ΌΩΣΒΡ 2015 SparkΦΦ θΖεΜα …œΘ§Ν§≥«ΫΪΉωΟϊΈΣΓΑΥΡΝΫ≤Π«ßΫοΓΣΓΣSpark SQLΫαΙΙΜ· ΐΨίΖ÷ΈωΓ±ΒΡ÷ςΧβ―ίΫ≤ΓΘ
Ή‘2013Ρξ3‘¬Οφ ά“‘ά¥Θ§Spark SQL“―Ψ≠≥…ΈΣ≥ΐSpark Core“‘ΆβΉν¥σΒΡSparkΉιΦΰΓΘ≥ΐΝΥΫ”ΙΐSharkΒΡΫ”ΝΠΑτΘ§ΦΧ–χΈΣSpark”ΟΜßΧαΙ©ΗΏ–‘ΡήΒΡSQL on HadoopΫβΨωΖΫΑΗ÷°ΆβΘ§ΥϋΜΙΈΣSpark¥χά¥ΝΥΆ®”ΟΓΔΗΏ–ßΓΔΕύ‘Σ“ΜΧεΒΡΫαΙΙΜ· ΐΨί¥ΠάμΡήΝΠΓΘ‘ΎΗ’Η’ΖΔ≤ΦΒΡ1.3.0Αφ÷–Θ§Spark SQLΒΡΝΫ¥σ…ΐΦΕ±ΜΎΙ ΆΒΟΝήάλΨΓ÷¬ΓΘ
DataFrame
ΨΆ“Ή”Ο–‘Εχ―‘Θ§Ε‘±»¥ΪΆ≥ΒΡMapReduce APIΘ§ΥΒSparkΒΡRDD API”–ΝΥ ΐΝΩΦΕΒΡΖ…‘Ψ≤Δ≤ΜΈΣΙΐΓΘ»ΜΕχΘ§Ε‘”ΎΟΜ”–MapReduceΚΆΚ· ΐ Ϋ±ύ≥ΧΨ≠―ιΒΡ–¬ ÷ά¥ΥΒΘ§RDD API»‘»Μ¥φ‘ΎΉ≈“ΜΕ®ΒΡΟ≈ΦςΓΘΝμ“ΜΖΫΟφΘ§ ΐΨίΩΤ―ßΦ“Ο«Υυ λœΛΒΡRΓΔPandasΒ»¥ΪΆ≥ ΐΨίΩρΦήΥδ»ΜΧαΙ©ΝΥ÷±ΙέΒΡAPIΘ§»¥Ψ÷œό”ΎΒΞΜζ¥ΠάμΘ§ΈόΖ® Λ»Έ¥σ ΐΨί≥ΓΨΑΓΘΈΣΝΥΫβΨω’β“ΜΟ§ΕήΘ§Spark SQL 1.3.0‘Ύ‘≠”–SchemaRDDΒΡΜυ¥Γ…œΧαΙ©ΝΥ”κRΚΆPandasΖγΗώάύΥΤΒΡDataFrame APIΓΘ–¬ΒΡDataFrame AP≤ΜΫωΩ…“‘¥σΖυΕ»ΫΒΒΆΤ’Ά®ΩΣΖΔ’ΏΒΡ―ßœΑΟ≈ΦςΘ§Ά§ ±ΜΙ÷ß≥÷ScalaΓΔJava”κPython»ΐ÷÷”ο―‘ΓΘΗϋ÷Ί“ΣΒΡ «Θ§”…”ΎΆ―ΧΞΉ‘SchemaRDDΘ§DataFrameΧλ»Μ ”Ο”ΎΖ÷≤Φ Ϋ¥σ ΐΨί≥ΓΨΑΓΘ
DataFrame « ≤Ο¥ΘΩ
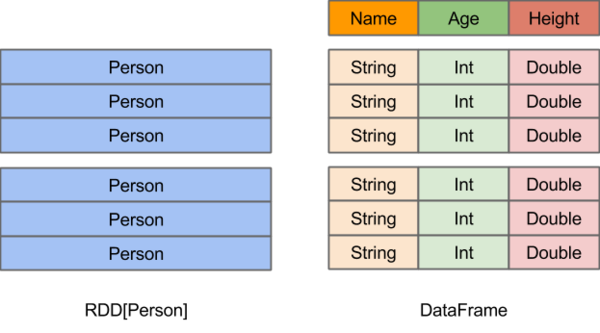
‘ΎSpark÷–Θ§DataFrame «“Μ÷÷“‘RDDΈΣΜυ¥ΓΒΡΖ÷≤Φ Ϋ ΐΨίΦ·Θ§άύΥΤ”Ύ¥ΪΆ≥ ΐΨίΩβ÷–ΒΡΕΰΈ§±μΗώΓΘDataFrame”κRDDΒΡ÷ς“Σ«χ±π‘Ύ”ΎΘ§«Α’Ώ¥χ”–schema‘Σ–≈œΔΘ§Φ¥DataFrameΥυ±μ ΨΒΡΕΰΈ§±μ ΐΨίΦ·ΒΡΟΩ“ΜΝ–ΕΦ¥χ”–Οϊ≥ΤΚΆάύ–ΆΓΘ’β ΙΒΟSpark SQLΒΟ“‘Ε¥≤λΗϋΕύΒΡΫαΙΙ–≈œΔΘ§¥”ΕχΕ‘≤Ί”ΎDataFrame±≥ΚσΒΡ ΐΨί‘¥“‘ΦΑΉς”Ο”ΎDataFrame÷°…œΒΡ±δΜΜΫχ––ΝΥ’κΕ‘–‘ΒΡ”≈Μ·Θ§Ήν÷’¥οΒΫ¥σΖυΧα…ΐ‘Υ–– ±–߬ ΒΡΡΩ±ξΓΘΖ¥ΙέRDDΘ§”…”ΎΈό¥”ΒΟ÷ΣΥυ¥φ ΐΨί‘ΣΥΊΒΡΨΏΧεΡΎ≤ΩΫαΙΙΘ§Spark Core÷ΜΡή‘Ύstage≤ψΟφΫχ––ΦρΒΞΓΔΆ®”ΟΒΡΝςΥ°œΏ”≈Μ·ΓΘ
¥¥Ϋ®DataFrame
‘ΎSpark SQL÷–Θ§ΩΣΖΔ’ΏΩ…“‘Ζ«≥Θ±ψΫίΒΊΫΪΗς÷÷ΡΎΓΔΆβ≤ΩΒΡΒΞΜζΓΔΖ÷≤Φ Ϋ ΐΨίΉΣΜΜΈΣDataFrameΓΘ“‘œ¬Python Ψάΐ¥ζ¬κ≥δΖ÷Χεœ÷ΝΥSpark SQL 1.3.0÷–DataFrame ΐΨί‘¥ΒΡΖαΗΜΕύ―υΚΆΦρΒΞ“Ή”ΟΘΚ
1. # ¥”Hive÷–ΒΡusers±μΙΙ‘λDataFrame
2. users = sqlContext.table("users")
3.
4. # Φ”‘ΊS3…œΒΡJSONΈΡΦΰ
5. logs = sqlContext.load("s3n://path/to/data.json", "json")
6.
7. # Φ”‘ΊHDFS…œΒΡParquetΈΡΦΰ
8. clicks = sqlContext.load("hdfs://path/to/data.parquet", "parquet")
9.
10.# Ά®ΙΐJDBCΖΟΈ MySQL
11.comments = sqlContext.jdbc("jdbc:mysql://localhost/comments", "user")
12.
13.# ΫΪΤ’Ά®RDDΉΣ±δΈΣDataFrame
14.rdd = sparkContext.textFile("article.txt") \
15. .flatMap(lambda line: line.split()) \
16. .map(lambda word: (word, 1)) \
17. .reduceByKey(lambda a, b: a + b) \
18.wordCounts = sqlContext.createDataFrame(rdd, ["word", "count"])
19.
20.# ΫΪ±ΨΒΊ ΐΨί»ίΤςΉΣ±δΈΣDataFrame
21.data = [("Alice", 21), ("Bob", 24)]
22.people = sqlContext.createDataFrame(data, ["name", "age"])
23.
24.# ΫΪPandas DataFrameΉΣ±δΈΣSpark DataFrameΘ®Python APIΧΊ”–ΙΠΡήΘ©
25.sparkDF = sqlContext.createDataFrame(pandasDF)
|
Ω…ΦϊΘ§¥”Hive±μΘ§ΒΫΆβ≤Ω ΐΨί‘¥API÷ß≥÷ΒΡΗς÷÷ ΐΨί‘¥Θ®JSONΓΔParquetΓΔJDBCΘ©Θ§‘ΌΒΫRDDΡΥ÷ΝΗς÷÷±ΨΒΊ ΐΨίΦ·Θ§ΕΦΩ…“‘±ΜΖΫ±ψΩλΫίΒΊΦ”‘ΊΓΔΉΣΜΜΈΣDataFrameΓΘ’β–©ΙΠΡή“≤Ά§―υ¥φ‘Ύ”ΎSpark SQLΒΡScala APIΚΆJava API÷–ΓΘ
Ι”ΟDataFrame
ΚΆRΓΔPandasάύΥΤΘ§Spark DataFrame“≤ΧαΙ©ΝΥ“Μ’ϊΧΉ”Ο”Ύ≤ΌΉί ΐΨίΒΡDSLΓΘ’β–©DSL‘Ύ”ο“ε…œ”κSQLΙΊœΒ≤ι―·Ζ«≥ΘœύΫϋΘ®’β“≤ «Spark SQLΡήΙΜΈΣDataFrameΧαΙ©ΈόΖλ÷ß≥÷ΒΡ÷Ί“Σ‘≠“ρ÷°“ΜΘ©ΓΘ“‘œ¬ «“ΜΉι”ΟΜß ΐΨίΖ÷Έω ΨάΐΘΚ
1.# ¥¥Ϋ®“ΜΗω÷ΜΑϋΚ§"Ρξ«α"”ΟΜßΒΡDataFrame
2.young = users.filter(users.age < 21)
3.
4.# “≤Ω…“‘ Ι”ΟPandasΖγΗώΒΡ”οΖ®
5.young = users[users.age < 21]
6.
7.# ΫΪΥυ”–»ΥΒΡΡξΝδΦ”1
8.young.select(young.name, young.age + 1)
9.
10.# Ά≥ΦΤΡξ«α”ΟΜß÷–Ης–‘±π»Υ ΐ
11.young.groupBy("gender").count()
12.
13.# ΫΪΥυ”–Ρξ«α”ΟΜß”κΝμ“ΜΗωΟϊΈΣlogsΒΡDataFrameΝΣΫ”Τπά¥
14.young.join(logs, logs.userId == users.userId, "left_outer")
|
≥ΐDSL“‘ΆβΘ§Έ“ϫ±»Μ“≤Ω…“‘œώ“‘Άυ“Μ―υΘ§”ΟSQLά¥¥ΠάμDataFrameΘΚ
1.young.registerTempTable("young")
2.sqlContext.sql("SELECT count(*) FROM young") |
ΉνΚσΘ§Β± ΐΨίΖ÷Έω¬ΏΦ≠±ύ–¥Άξ±œΚσΘ§Έ“Ο«±ψΩ…“‘ΫΪΉν÷’ΫαΙϊ±Θ¥φœ¬ά¥Μρ’Ιœ÷≥ωά¥ΘΚ
1.# ΉΖΦ”÷ΝHDFS…œΒΡParquetΈΡΦΰ
2.young.save(path="hdfs://path/to/data.parquet",
3. source="parquet",
4. mode="append")
5.
6.# Η≤–¥S3…œΒΡJSONΈΡΦΰ
7.young.save(path="s3n://path/to/data.json",
8. source="json",
9. mode="append")
10.
11.# ±Θ¥φΈΣSQL±μ
12.young.saveAsTable(tableName="young", source="parquet" mode="overwrite")
13.
14.# ΉΣΜΜΈΣPandas DataFrameΘ®Python APIΧΊ”–ΙΠΡήΘ©
15.pandasDF = young.toPandas()
16.
17.# “‘±μΗώ–Έ Ϋ¥ρ”Γ δ≥ω
18.young.show() |
ΡΜΚσ”Δ–έΘΚSpark SQL≤ι―·”≈Μ·Τς”κ¥ζ¬κ…ζ≥…
’ΐ»γRDDΒΡΗς÷÷±δΜΜ ΒΦ …œ÷Μ «‘ΎΙΙ‘λRDD DAGΘ§DataFrameΒΡΗς÷÷±δΜΜΆ§―υ“≤ «lazyΒΡΓΘΥϋΟ«≤Δ≤Μ÷±Ϋ”«σ≥ωΦΤΥψΫαΙϊΘ§Εχ «ΫΪΗς÷÷±δΜΜΉιΉΑ≥…”κRDD DAGάύΥΤΒΡ¬ΏΦ≠≤ι―·ΦΤΜ°ΓΘ»γ«ΑΥυ ωΘ§”…”ΎDataFrame¥χ”–schema‘Σ–≈œΔΘ§Spark SQLΒΡ≤ι―·”≈Μ·ΤςΒΟ“‘Ε¥≤λ ΐΨίΚΆΦΤΥψΒΡΨΪœΗΫαΙΙΘ§¥”Εχ ©––ΨΏ”–Κή«Ω’κΕ‘–‘ΒΡ”≈Μ·ΓΘΥφΚσΘ§Ψ≠Ιΐ”≈Μ·ΒΡ¬ΏΦ≠÷¥––ΦΤΜ°±ΜΖ≠“κΈΣΈοάμ÷¥––ΦΤΜ°Θ§≤ΔΉν÷’¬δ ΒΈΣRDD DAGΓΘ

’β―υΉωΒΡΚΟ¥ΠΧεœ÷‘ΎΦΗΗωΖΫΟφΘΚ
1. ”ΟΜßΩ…“‘”ΟΗϋ…ΌΒΡ…ξΟς Ϋ¥ζ¬κ≤ϊΟςΦΤΥψ¬ΏΦ≠Θ§Έοάμ÷¥––¬ΖΨΕ‘ρΫΜ”…Spark SQLΉ‘––Χτ―ΓΓΘ“ΜΖΫΟφΫΒΒΆΝΥΩΣΖΔ≥…±ΨΘ§“ΜΖΫΟφ“≤ΫΒΒΆΝΥ Ι”ΟΟ≈ΦςΓΣΓΣΚήΕύ«ιΩωœ¬Θ§Φ¥±ψ–¬ ÷–¥≥ωΝΥΫœΈΣΒΆ–ßΒΡ≤ι―·Θ§Spark SQL“≤Ω…“‘Ά®ΙΐΙΐ¬ΥΧθΦΰœ¬ΆΤΓΔΝ–Φτ÷ΠΒ»≤Ώ¬‘”η“‘”––ß”≈Μ·ΓΘ’β «RDD APIΥυ≤ΜΨΏ±ΗΒΡΓΘ
2. Spark SQLΩ…“‘Ε·Χ§ΒΊΈΣΈοάμ÷¥––ΦΤΜ°÷–ΒΡ±μ¥ο Ϋ…ζ≥…JVMΉ÷ΫΎ¬κΘ§Ϋχ“Μ≤Ϋ Βœ÷Ιι±ή–ιΚ· ΐΒς”ΟΩΣœζΓΔœςΦθΕ‘œσΖ÷≈δ¥Έ ΐ»¹≤ψ”≈Μ·Θ§ ΙΒΟΉν÷’ΒΡ≤ι―·÷¥–––‘ΡήΩ…“‘”κ ÷–¥¥ζ¬κΒΡ–‘Ρήœύφ«ΟάΓΘ
3. Ε‘”ΎPySparkΕχ―‘Θ§≤…”ΟDataFrame±ύ≥Χ ±÷Μ–η“ΣΙΙ‘λΧεΜΐ–Γ«…ΒΡ¬ΏΦ≠÷¥––ΦΤΜ°Θ§Έοάμ÷¥––»Ϊ≤Ω”…JVMΕΥΗΚ‘πΘ§PythonΫβ ΆΤςΚΆJVMΦδ¥σΝΩ≤Μ±Ί“ΣΒΡΩγΫχ≥ΧΆ®―ΕΒΟ“‘Οβ≥ΐΓΘ»γ…œΆΦΥυ ΨΘ§“ΜΉιΦρΒΞΒΡΕ‘“Μ«ßΆρ’ϊ ΐΕ‘ΉωΨέΚœΒΡ≤β ‘÷–Θ§PySpark÷–DataFrame APIΒΡ–‘Ρή«αΥ… Λ≥ωRDD APIΫϋΈε±ΕΓΘ¥ΥΆβΘ§ΫώΚσSpark SQL‘ΎScalaΕΥΕ‘≤ι―·”≈Μ·ΤςΒΡΥυ”––‘ΡήΗΡΫχΘ§PySparkΕΦΩ…“‘ΟβΖ―Μώ“φΓΘ
Άβ≤Ω ΐΨί‘¥API‘ω«Ω

¥”«ΑΈΡ÷–Έ“Ο«“―Ψ≠Ω¥ΒΫΘ§Spark 1.3.0ΈΣDataFrameΧαΙ©ΝΥΖαΗΜΕύ―υΒΡ ΐΨί‘¥÷ß≥÷ΓΘΤδ÷–ΒΡ÷ΊΆΖœΖΘ§±ψ «Ή‘Spark 1.2.0“ΐ»κΒΡΆβ≤Ω ΐΨί‘¥APIΓΘ‘Ύ1.3.0÷–Θ§Έ“Ο«Ε‘’βΧΉAPIΉωΝΥΫχ“Μ≤ΫΒΡ‘ω«ΩΓΘ
ΐΨί–¥»κ÷ß≥÷
‘ΎSpark 1.2.0÷–Θ§Άβ≤Ω ΐΨί‘¥API÷ΜΡήΫΪΆβ≤Ω ΐΨί‘¥÷–ΒΡ ΐΨίΕΝ»κSparkΘ§ΕχΈόΖ®ΫΪΦΤΥψΫαΙϊ–¥ΜΊ ΐΨί‘¥ΘΜΆ§ ±Θ§Ά®Ιΐ ΐΨί‘¥“ΐ»κ≤ΔΉΔ≤αΒΡ±μ÷ΜΡή «ΝΌ ±±μΘ§œύΙΊ‘Σ–≈œΔΈόΖ®≥÷ΨΟΜ·ΓΘ‘Ύ1.3.0÷–Θ§Έ“Ο«ΧαΙ©ΝΥΆξ’ϊΒΡ ΐΨί–¥»κ÷ß≥÷Θ§¥”Εχ≤Ι»ΪΝΥΕύ ΐΨί‘¥ΜΞ≤ΌΉςΒΡΉνΚσ“ΜΩι÷Ί“ΣΤ¥ΆΦΓΘ«ΑΈΡ Ψάΐ÷–HiveΓΔParquetΓΔJSONΓΔPandasΒ»Εύ÷÷ ΐΨί‘¥ΦδΒΡ»Έ“βΉΣΜΜΘ§’ΐ «’β“Μ‘ω«ΩΒΡ÷±Ϋ”≥…ΙϊΓΘ
’Ψ‘ΎSpark SQLΆβ≤Ω ΐΨί‘¥ΩΣΖΔ’ΏΒΡΫ«Ε»Θ§ ΐΨί–¥»κ÷ß≥÷ΒΡAPI÷ς“ΣΑϋά®ΘΚ
1. ΐΨί‘¥±μ‘Σ ΐΨί≥÷ΨΟΜ·
1.3.0“ΐ»κΝΥ–¬ΒΡΆβ≤Ω ΐΨί‘¥DDL”οΖ®Θ®SQL¥ζ¬κΤ§ΕΈΘ©
CREATE [TEMPORARY] TABLE [IF NOT EXISTS]
<table-name> [(col-name data-type [, ...)]
USING <source> [OPTIONS ...]
[AS <select-query>]
|
”…¥ΥΘ§ΉΔ≤αΉ‘Άβ≤Ω ΐΨίΒΡSQL±μΦ»Ω…“‘ «ΝΌ ±±μΘ§“≤Ω…“‘±Μ≥÷ΨΟΜ·÷ΝHive metastoreΓΘ–η“Σ≥÷ΨΟΜ·÷ß≥÷ΒΡΆβ≤Ω ΐΨί‘¥Θ§≥ΐΝΥ–η“ΣΦΧ≥–‘≠”–ΒΡRelationProvider“‘ΆβΘ§ΜΙ–ηΦΧ≥–CreatableRelationProviderΓΘ
2. InsertableRelation
÷ß≥÷ ΐΨί–¥»κΒΡΆβ≤Ω ΐΨί‘¥ΒΡrelationάύΘ§ΜΙ–ηΦΧ≥–trait InsertableRelationΘ§≤Δ‘ΎinsertΖΫΖ®÷– Βœ÷ ΐΨί≤ε»κ¬ΏΦ≠ΓΘ
Spark 1.3.0÷–ΡΎ÷ΟΒΡJSONΚΆParquet ΐΨί‘¥ΕΦ“― Βœ÷…œ ωAPIΘ§Ω…“‘ΉςΈΣΩΣΖΔΆβ≤Ω ΐΨί‘¥ΒΡ≤ΈΩΦ ΨάΐΓΘ
Ά≥“ΜΒΡload/save API
‘ΎSpark 1.2.0÷–Θ§“ΣœκΫΪSchemaRDD÷–ΒΡΫαΙϊ±Θ¥φœ¬ά¥Θ§±ψΫίΒΡ―Γ‘ώ≤Δ≤ΜΕύΓΘ≥Θ”ΟΒΡ“Μ–©Αϋά®ΘΚ
- rdd.saveAsParquetFile(...)
- rdd.saveAsTextFile(...)
- rdd.toJSON.saveAsTextFile(...)
- rdd.saveAsTable(...)
- ....
Ω…ΦϊΘ§≤ΜΆ§ΒΡ ΐΨί δ≥ωΖΫ ΫΘ§≤…”ΟΒΡAPI“≤≤ΜΨΓœύΆ§ΓΘΗϋΝν»ΥΆΖΧέΒΡ «Θ§Έ“Ο«»±ΖΠ“ΜΗωΝιΜνά©’Ι–¬ΒΡ ΐΨί–¥»κΗώ ΫΒΡΖΫ ΫΓΘ
’κΕ‘’β“ΜΈ ΧβΘ§1.3.0Ά≥“ΜΝΥload/save APIΘ§»Ο”ΟΜßΑ¥–ηΉ‘”…―Γ‘ώΆβ≤Ω ΐΨί‘¥ΓΘ’βΧΉAPIΑϋά®ΘΚ
1.SQLContext.table
¥”SQL±μ÷–Φ”‘ΊDataFrameΓΘ
2.SQLContext.load
¥”÷ΗΕ®ΒΡΆβ≤Ω ΐΨί‘¥Φ”‘ΊDataFrameΓΘ
3.SQLContext.createExternalTable
ΫΪ÷ΗΕ®ΈΜ÷ΟΒΡ ΐΨί±Θ¥φΈΣΆβ≤ΩSQL±μΘ§‘Σ–≈œΔ¥φ»κHive metastoreΘ§≤ΔΖΒΜΊΑϋΚ§œύ”Π ΐΨίΒΡDataFrameΓΘ
4.DataFrame.save
ΫΪDataFrame–¥»κ÷ΗΕ®ΒΡΆβ≤Ω ΐΨί‘¥ΓΘ
5.DataFrame.saveAsTable
ΫΪDataFrame±Θ¥φΈΣSQL±μΘ§‘Σ–≈œΔ¥φ»κHive metastoreΘ§Ά§ ±ΫΪ ΐΨί–¥»κ÷ΗΕ®ΈΜ÷ΟΓΘ
Parquet ΐΨί‘¥‘ω«Ω
Spark SQL¥”“ΜΩΣ Φ±ψΡΎ÷Ο÷ß≥÷Parquet’β“ΜΗΏ–ßΒΡΝ– Ϋ¥φ¥ΔΗώ ΫΓΘ‘ΎΩΣΖ≈Άβ≤Ω ΐΨί‘¥API÷°ΚσΘ§‘≠”–ΒΡParquet÷ß≥÷“≤’ΐ‘Ύ÷πΫΞΉΣœρΆβ≤Ω ΐΨί‘¥ΓΘ1.3.0÷–Θ§ParquetΆβ≤Ω ΐΨί‘¥ΒΡΡήΝΠΒΟΒΫΝΥœ‘÷χ‘ω«ΩΓΘ÷ς“ΣΑϋά®schemaΚœ≤ΔΚΆΉ‘Ε·Ζ÷«χ¥ΠάμΓΘ
1.SchemaΚœ≤Δ
”κProtocolBufferΚΆThriftάύΥΤΘ§Parquet“≤‘ –μ”ΟΜß‘ΎΕ®“εΚΟschema÷°ΚσΥφ ±ΦδΆΤ“Τ÷πΫΞΧμΦ”–¬ΒΡΝ–Θ§÷Μ“Σ≤Μ–όΗΡ‘≠”–Ν–ΒΡ‘Σ–≈œΔΘ§–¬Ψ…schema»‘»ΜΩ…“‘Φφ»ίΓΘ’β“ΜΧΊ–‘ ΙΒΟ”ΟΜßΩ…“‘Υφ ±Α¥–ηΧμΦ”–¬ΒΡ ΐΨίΝ–Θ§ΕχΈό–η≤Ό–Ρ ΐΨί«®“ΤΓΘ
2.Ζ÷«χ–≈œΔΖΔœ÷
Α¥ΡΩ¬ΦΕ‘Ά§“Μ’≈±μ÷–ΒΡ ΐΨίΖ÷«χ¥φ¥ΔΘ§ «HiveΒ»œΒΆ≥≤…”ΟΒΡ“Μ÷÷≥ΘΦϊΒΡ ΐΨί¥φ¥ΔΖΫ ΫΓΘ–¬ΒΡParquet ΐΨί‘¥Ω…“‘Ή‘Ε·ΗυΨίΡΩ¬ΦΫαΙΙΖΔœ÷ΚΆΆΤ―ίΖ÷«χ–≈œΔΓΘ
3.Ζ÷«χΦτ÷Π
Ζ÷«χ ΒΦ …œΧαΙ©ΝΥ“Μ÷÷¥÷ΝΘΕ»ΒΡΥς“ΐΓΘΒ±≤ι―·ΧθΦΰ÷–Ϋω…φΦΑ≤ΩΖ÷Ζ÷«χ ±Θ§Ά®ΙΐΖ÷«χΦτ÷ΠΧχΙΐ≤Μ±Ί“Σ…®ΟηΒΡΖ÷«χΡΩ¬ΦΘ§Ω…“‘¥σΖυΧα…ΐ≤ι―·–‘ΡήΓΘ
“‘œ¬Scala¥ζ¬κ ΨάΐΆ≥“Μ’Ι ΨΝΥ1.3.0÷–Parquet ΐΨί‘¥ΒΡ’βΦΗΗωΡήΝΠΘ®Scala¥ζ¬κΤ§ΕΈΘ©ΘΚ
// ¥¥Ϋ®ΝΫΗωΦρΒΞΒΡDataFrameΘ§ΫΪ÷°¥φ»κΝΫΗωΕάΝΔΒΡΖ÷«χΡΩ¬Φ
val df1 = (1 to 5).map(i => (i, i * 2)).toDF("single", "double")
df1.save("data/test_table/key=1", "parquet", SaveMode.Append)
val df2 = (6 to 10).map(i => (i, i * 2)).toDF("single", "double")
df2.save("data/test_table/key=2", "parquet", SaveMode.Append)
// ‘ΎΝμ“ΜΗωDataFrame÷–“ΐ»κ“ΜΗω–¬ΒΡΝ–Θ§≤Δ¥φ»κΝμ“ΜΗωΖ÷«χΡΩ¬Φ
val df3 = (11 to 15).map(i => (i, i * 3)).toDF("single", "triple")
df3.save("data/test_table/key=3", "parquet", SaveMode.Append)
// “Μ¥Έ–‘ΕΝ»κ’ϊΗωΖ÷«χ±μΒΡ ΐΨί
val df4 = sqlContext.load("data/test_table", "parquet")
// Α¥Ζ÷«χΫχ––≤ι―·Θ§≤Δ’Ι ΨΫαΙϊ
val df5 = df4.filter($"key" >= 2) df5.show()
|
’βΕΈ¥ζ¬κΒΡ÷¥––ΫαΙϊΈΣΘΚ
6 12 null 2
7 14 null 2
8 16 null 2
9 18 null 2
10 20 null 2
11 null 33 3
12 null 36 3
13 null 39 3
14 null 42 3
15 null 45 3
|
Ω…ΦϊΘ§Parquet ΐΨί‘¥Ή‘Ε·¥”ΈΡΦΰ¬ΖΨΕ÷–ΖΔœ÷ΝΥkey’βΗωΖ÷«χΝ–Θ§≤Δ«“’ΐ»ΖΚœ≤ΔΝΥΝΫΗω≤ΜœύΆ§ΒΪœύ»ίΒΡschemaΓΘ÷ΒΒΟΉΔ“βΒΡ «Θ§‘ΎΉνΚσΒΡ≤ι―·÷–≤ι―·ΧθΦΰΧχΙΐΝΥkey=1’βΗωΖ÷«χΓΘSpark SQLΒΡ≤ι―·”≈Μ·ΤςΜαΗυΨί’βΗω≤ι―·ΧθΦΰΫΪΗΟΖ÷«χΡΩ¬ΦΦτΒτΘ§Άξ»Ϊ≤Μ…®ΟηΗΟΡΩ¬Φ÷–ΒΡ ΐΨίΘ§¥”ΕχΧα…ΐ≤ι―·–‘ΡήΓΘ
–ΓΫα
DataFrame APIΒΡ“ΐ»κ“ΜΗΡRDD APIΗΏάδΒΡFPΉΥΧ§Θ§ΝνSpark±δΒΟΗϋΦ”ΤΫ“ΉΫϋ»ΥΘ§ Ι¥σ ΐΨίΖ÷ΈωΒΡΩΣΖΔΧε―ι”κ¥ΪΆ≥ΒΞΜζ ΐΨίΖ÷ΈωΒΡΩΣΖΔΧε―ι‘Ϋά¥‘ΫΫ”ΫϋΓΘΆβ≤Ω ΐΨί‘¥APIΧεœ÷≥ωΒΡ‘ρ «Φφ»ί≤Δ–νΓΘΡΩ«ΑΘ§≥ΐΝΥΡΎ÷ΟΒΡJSONΓΔParquetΓΔJDBC“‘ΆβΘ§…γ«χ÷–“―Ψ≠”Ωœ÷≥ωΝΥCSVΓΔAvroΓΔHBaseΒ»Εύ÷÷ ΐΨί‘¥Θ§Spark SQLΕύ‘Σ“ΜΧεΒΡΫαΙΙΜ· ΐΨί¥ΠάμΡήΝΠ’ΐ‘Ύ÷πΫΞ ΆΖ≈ΓΘ
ΈΣΩΣΖΔ’ΏΧαΙ©ΗϋΕύΒΡά©’ΙΒψΘ§ «SparkΙᥩ’ϊΗω2015ΡξΒΡ÷ςΧβ÷°“ΜΓΘΈ“Ο«œΘΆϊΆ®Ιΐ’β–©ά©’ΙAPIΘ§«– ΒΒΊ“ΐ±§…γ«χΒΡΡήΝΩΘ§ΝνSparkΒΡ…ζΧ§ΗϋΦ”Ζα¬ζΚΆΕύ―υΓΘ
|





