|
DockOne����������ʮһ����DockerCon ����
������Ҫ����DockerCon�ϵļ��ţ������������ݴ��¿��Է�Ϊ�������֣�1.
Docker 1.7.0��Ƚ�����2.DockerCon Hackathon���ţ�3. DockerConʢ�䡣
��һ���ڣ�Docker 1.7.0��Ƚ���
��Docker�İ汾�����־������Docker 1.7.0���ĸ�������л����ٵı䶯���ֱ��ǣ�Docker����ʱ��Runtime����Docker�Ĵ���仯��Docker��builderģ�飬�Լ�Docker��bug����
�˴η�����Ҫ�漰Docker 1.7.0��runtime��
1.1.������һ����Ȼ��������ε����ԣ�֧��out of process�����ݾ����
��Ϊ�������ʵ����ԣ�����֮Docker���ⲿ�����Ի���֧�������������в��ã���Щ���Ը����ϣ���û������ڲ��Ի������Լ�ɳ�价���в��á�������������ȫ��Docker
1.7.0��һ�����㡣
�����ϵĻ���������out-of-process�������ܶ࣬���������Docker Daemon����ϣ����弴�ã���Docker
Daemon����֮�ⷢ�����á�
ĿǰDocker�����������Կ��Դ���������������������DockerĿǰ�Ѿ�֧���û��Զ�������������ʹ�ã�������������ϣ�Docker����֧�����������ݾ�volume��������⣬Docker��������һ����������ص�API�������û�ʹ�á���Ȼ�����ź����ڸ���������Docker�ٷ�������������������������µIJ��������ֵ��һ��ģ������ݾ�volume������棬������Flocker����Ӱ����Ҳ��ζ�����������ݴ洢���⣬����������̨�棬������Ӧ�����Ľ��������
1.2.��docker daemon�ĽǶȣ�������userland-proxy����ͣ����
���Ƚ���userland-proxyһֱ���������á�������֪����Docker���Ž�bridge����ģʽ�£�Docker����ʱ��ͨ���������ϵ�NATģʽ��������������֮�������ͨ�š�Ȼ�����������ϣ�һ������£����̿���ͨ�����ַ�ʽ�����������ֱ�Ϊ��<eth0IP>:<hostPort>,
<containerIP>:<containerPort>,�Լ�<0.0.0.0>:<hostPort>��ʵ���ϣ����һ�ַ�ʽ�ijɹ�������ȫ������userland-proxy����Docker
Daemon������һ��Docker����ʱ��ÿΪ��������������ӳ��һ���˿ڣ���������һ��docker-proxy���̣�ʵ����������0.0.0.0��ַ�϶������ķ��ʴ�����
��ʱ����userland-proxyʱ��Ҳ������Ϊ�������ʶ����0.0.0.0��ַ�Լ�localhost�����������ϵĹ���ȱ�ݡ�Ȼ������docker-proxy����Docker֮���൱����һ��ʱ���ڡ�Docker�������ձ���ܵ����ܶೡ���£�docker-proxy���DZ��裬���������һЩ�����ıˡ�
Ӱ��ϴ�ij�����Ҫ�����֡�
��һ������������Ҫ���������ж���˿ڵ�ӳ�䡣�˳����£���������Ҫӳ��1000���˿��������࣬��ô�������Ͼͻᴴ��1000�����������docker-proxy���̡��ݲ���ȫ���ԣ�ÿһ��docker-proxyռ�õ��ڴ���4-10MB���ȡ����һ����ֱ����������4-10GB�ڴ棬�Լ�����1000�����̣������Ǵ�ϵͳ�ڴ棬���Ǵ�ϵͳCPU��Դ���������ⶼ���Ǻܴ�ĸ�����
�ڶ����ڶ�����ͬʱ���������������������������ӳ��˿ڼ��١����ֳ����£�������������Դ�����IJ�û�����һ�ֳ�������������������һ�ֽ�Ϊ���Եķ�ʽ������Դ��
���Docker Daemon����- -userland-proxy���flag�������ϳ����Ŀ���Ȩ��ȫ�������û������û������Ƿ�����ҲΪ�û��ij�����proxy�����ṩ������ԡ�
1.3. docker exec��������- -user�������û�����docker
exec��������ִ������ʱ�������û�
�Դ�docker 1.3.0����docker exec֮���û��������IJ�������������ͷţ��������û����Բ�����һ�����еĺںС�Ȼ����docker
exec������ô���ͬʱ������Ҳ�ܿ��������е�һЩ覴ã���ȻDocker����Ҳ�ڲ��ϵ�����docker
exec��
���ȣ�docker exec�����������еĽ��̻���rootȨ�����У���Ȩ����ȱ������Ե�ͬʱ�������İ�ȫ���п���ʧ�ء�����-
-userǡ���ֲ����ⷽ��IJ��㡣��Σ�docker exec�Ĵ��ڴ����������ڽ��̳�����״��ϵ����״������Ƴ���Docker�����ĺܶ�����������˼���init
process���֣����Ŀǰdocker exec�Ľ��̲����ܺ�ԭ��̬����������ȫһ���ر�Docker
Daemon������
1.4. ��ǿDocker�������ص�ַ�����ù��
Docker 1.7.0����֮ǰ����bridge�Ž�ģʽ�£�Docker���������ص�ַ��Ĭ�����ɵģ�һ��ΪDocker�����е�docker0���ŵ�ַ��������ͨ�ŵĽǶȶ��ԣ�Ĭ�ϵķ�ʽ�Ѿ�����������Ҫ�����ǣ�������Ȼ���Է��֣�����ģʽ����һЩ�ˣ������������õ�������Լ����簲ȫ�ԡ�
Docker����������һֱ���ܹ�ע��ȱ�������õ����ԣ�������������չ�У���������ζ�ŷ�ա� �Cdefault-gateway
�Լ��Cdefault-gateway-v6 �������������ܴ�̶���������û��Զ����������������ԣ��û����ೡ���ĸ��ǣ��ƺ���Docker�ķ�չ����Ӱ���֡������������°汾�����ܵ���ǿ��ḻ�����Ѳ²⣬Docker����ҵ���Լ����������Ѿ�����һ��¥��
Ĭ�����ص����ã�Ϊʲô˵������������簲ȫ����أ���ȥ�ܳ�һ��ʱ���ڣ�docker0��Ϊ���������ص�ַ�����ַ�ʽ������������������Ϲ�ϵ���ֵĺܳ��ס�docker0��Ϊ�������ϵ�����ӿڣ��䵱��������������������Ȼ����Ҳ���������Ĵ��ڣ�ʹ�������ڲ����̺����״������أ��������������˹��̲��Ƕ��û�����
1.5. ����CFS quota��֧��
����Docker���ں�cgoups��֧�֣�ָ���Ƕ���һ�����ڵĽ�������һ�������ڱ��ں�CFS�����㷨���ȵ�ʱ�����λΪ�롣����������cgroups����Ӧ���ļ�Ϊ/sys/fs/cgroup/cpu/cpu.cfs_quota_us��
1.6. ��������IO���Ƶ�֧��
������֪����������Ϊ�û��ṩһ����������л����������ڲ��Ľ��̻��߽�����ʹ����Դʱ���ܵ����ƣ���������Դ���������ڴ���Դ�������ڴ��Լ�swap����CPU��Դ��CPUʱ��Ƭ�Լ�CPU�˵ȣ������̿ռ���Դ�ȣ������ⲿ�����ݻ����٣�Docker���°汾֮ǰ�����ٶ�����ʵ�֣�Ȼ������ά�����ɲ������������Docker�����ˡ�blkio-weight������ʵ�ֶ���������IO���Ƶ�֧�֡���������걸���û�Ҳ������Ҫ�������������IO��Դ�ľ�����
1.7. ZFS֧��
Docker 1.7.0 ��ʽ����֧��ZFS�ļ�ϵͳ���˾�Ҳ��ζ��Docker�����ļ�ϵͳ��֧�ִ�ԭ�ȵ�5�����ӵ�6�֡���ǰ��Docker֧��aufs��devmapper��btrfs��ovelayfs��vfs������֧��volume����������Ӷ�ZFS��֧�֡�ZFS��֧�֣������������뵽��Docker�����ݾ�volume�����Flocker�������������ƺ���ϵ��Ϊ�
ֵ��һ����ǣ�����֧��ZFS֮�⣬���߷����ڸ��������ļ�ϵͳ��graphģ���У�������driver_windows.go,��Ȼ���ݼ�����ף�������ȫʵ�ֶ�windows��ȫ��֧�֣����������ô�ҿ���Docker֧��windows�IJ����ڲ���������
1.8. docker logs�Ĺ�����չ
�鿴������־�����źܶ�Docker�����߶����������Ҳ���û��鿴��������״̬����Ҫ���ݡ�
���Լ��˽�Docker������־��ԭ��������ÿһ��������Docker������Docker Daemon�������ڲ�����һ��goroutine�����������ڲ����̵ı����stdout�Լ�������stderr���������ݴ�������־�ļ��С�ÿ���û���ͨ��Docker
Client����鿴������־������docker logs֮��Docker Daemon�Ὣ��־�ļ������ݴ�����Docker
Client��ʾ��
docker logs�ķ�չ���������Է�Ϊ4���Σ�Docker�������ڵ�ԭ��̬��־��ӡ�������û�follow��������־������������־��tail���ܣ��Լ�������־��since���ܣ���ӡ��ijһ��ʱ�����ʼ֮���������־��
��Ȼ������־�Ĺ���������ǿ�����Dz��ɷ��ϵ��ǣ�������־������������Docker Daemon�������ģ��֮һ�������漰Docker���֮���ļƻ�����������������ȷ�Ƕ�ʱ���������õķ�����
1.9. ����������������UTS�����ռ��֧��
��ͬ�ij����£�������������������ȫ���룬����Ҳ���������������ڹ�����Ϣ�������Docker�����hostģʽ����һ���ܺõ����ӣ���ģʽ�µ��������������������������ռ䡣
����UTS�����ռ��֧�֣���ζ���������������Ĺ�ϵԽ��Խ�Ҳ��Ŀǰ�ܶ�Docker�������Ѿ�ϰ����������������ȫ��������У���ȻҲ����һЩ�û�������Թ��ȫ��������л���������ƽ���Ľ���ͳ����ҵ������������ô��ĿǰDocker�ڼ�����ߵ�����£��������������ߵ������õĽ�����Docker���������ó����ؽ����ӷḻ����Ҳ��Docker������ҵ���Լ�����������Ҫ�˵�·��
������ԣ�Docker 1.7.0�����ߵĸ����ǣ�������������ҵ����£����production-ready��·�ϲ����Ż��������ڰ�ȫ�����ڲ��漰�ں˻�����Ҳ�������ơ�
���ڷ���1.7.0֮��û�����DockerCon�ϣ�Docker����production-ready���������ȫ����ʵ��1.7.0�ı����������ȫ���Ը��ܵ���һ�㡣
���⣬��Ҫ�ἰ���ǣ����ϵ�3��5��6������ǹ��ڹ�˾��Ϊ�Ĵ����ƶ�����ɵģ���Ϊһ��Docker�����ߣ����Եĸ�л��Ϊ�Լ��ڶ��docker
committer�Ĺ��ס�
�ڶ����ڣ�DockerCon Hackathon
6��7��8�ţ������й��Ŀ������ڱ����ٰ���һ��Golang&Docker Hackathon��DockerConǰϦ�ɽ�ɽҲ�ٰ���һ��Docker
Hackathon��
��κڿ������ɵ����˺ܶ���ӱ���뷨������۵�Geek���ӵ����쾡�¡��������ݹ��ڷḻ���ҽ�������ҽ���������ӡ��dz���̵���Ŀ��
2.1.������Ŀ��Swarm-SEC
����һ��Swarm��Ⱥ��ȫ��������
ͨ��Swarm��Ԥ�ȶ���İ�ȫ�淶��ɨ��������Ⱥ�������İ�ȫά������Ҫ�����㣺Swarm��docker
daemon�İ�ȫ���ã�Swarm��Ⱥ��Docker Node�ľ��尲ȫ����ʹ�������Swarm��Ⱥ������ʱ��ȫ�����
����swarm-sec��������ʽ��
docker run -it --net host --pid host --cap-add audit_control \
-v /var/lib:/var/lib \
-v /var/run/docker.sock:/var/run/docker.sock \
-v /usr/lib/systemd:/usr/lib/systemd \
-v /etc:/etc --label swarm-sec \
swarm-sec <token-id> |
���������ռ䣬Pid�����ռ䣬���������е�Docker��Ϣ�����ص������ڲ��ˣ����������һ��Capability����audit_control�����Ի�ȡaudit�ػ����̵���Ϣ��
����Ҫ����һ��Swarm-sec��ע��Swarm Daemon�Լ�Docker
Node��Docker Daemon����Щ��ȫ���⡣
Swarm Daemon
1.�鿴Swarm�Ƿ�����������֮�У�
2.�鿴Swarm�Ƿ���һ�����µ��ȶ��汾
3.�鿴Swarm����־���𣬲�����ʹ��debugģʽ
4.��֤�Ƿ�ռ��Docker��Ĭ�϶˿�
5.��֤Swarm Daemon�Ƿ�������TLS��ȫ����Э��
6.��֤�������������Ƿ���mesos��Ŀǰmesos�����Դ��������
7.�鿴������SELinux��AppArmor�Ƿ�����
����
Docker Daemon
��֤Docker Node��label�����Ƿ�淶����֤docker daemon�������ַ���ϰ�ȫ�����粻����ʹ��AUFS�ȡ�
��ĿԴ�룺https://github.com/snrism/swarm-sec
2.2.������Ŀ��Sherdock RancherOS����Ʒ
��Ҫ�������У�
�����������ʽ����Docker��������Զ����ա�
����GC�ĵ�ԭ����Ҫ������Ϊ��buildʧ�ܵ�ʱ������һϵ�е�none������Щ����δ�����á���ʱ�Ϳ��Ի��ڸ������������ʽ���������ľ�����������
����docker 1.7.0���¶����ݾ����������������¶����ݾ�����data
volume��������ɾ��ʱû��ָ����v������
�ṩUI���档
Hackathon�ı���������̫������ռƪ���������Ҹ���Ȥ�����Բ��ģ�DockerCon֮�ڿ������ɼ���
�������ڣ�DockerConʢ��
����DockerCon���ţ�DockerCon���췢����������Ȼ����ͷϷ���ⲿ�ֵķ���������Ҫ��Ϊ�����֣���һ��keynotes�����ݣ���ͨ�������ؼ��ֽ��н��ܣ��ڶ��������Ҳμӵļ����ֻ᳡��topic���ݡ�
3.1 keynotes�ؼ���
3.1.1 OCP
Docker�����ڶ�IT��ͷ��������ȫ���ŵ�����������ΪOCP����Ϊ������ʽ������Ŀ�����ҹ��Ĺ�˾��ΪҲ��Ȼ���С�OCP��ȫ�������������翪�Ų�ͳһ�ı���
OCP�ĵ�����ζ��Docker��CoreOS֮�����е�������֮�����ݸ�һ���䡣OCP�Ŀ�����ʹ�������ı��ܹ��õ����õ����ơ�
OCPʹ�������ķ�չ�ܹ����㷺��ͬ��֧�֣����˻��Ŷ���ֱ��ҵ�����������Ĺ����ܹ�����ı�˼�����ܹ�����ı�ʵ�����䷢չ��������Ӱ����Բ���С����
3.1.2 ����Ŀ
Experimental binary
Docker��experimental binary�����ֹ��ܷdz�ǿ�������ܱ�����Docker�ٷ��汾�Ĺ������������ʵ�����ʵĹ��������û���������Docker���¹��ܣ����Ҹ�Docker��ά�����ṩ������ͨ�����ַ�ʽ��Docker�ٷ�ϣ�����Խ�һЩ�¹���Ԥ�ȱ�¶��ȫ��Ŀ����ߣ��Ӷ��ô����ʵ���Լ�������������Щ��Ҫ���ܡ�
Ŀǰ��Docker���������Լ����ݾ�volume����������������Ҽ���������Թ��ܲ����
Docker plugins
Docker�Ŀ���չ���ٴα�Solomom�����Ŷ�������̲�ʵ����Ŀǰ��Docker��networkģ�飬���ݿ�volumeģ�飬swarm�еĵ���ģ���Լ�������ģ�飬���Ѿ��������������Docker��̬������ǿ�����չ������֮�⣬��������Docker��̬�Ŀ����ԡ���Ȼ����������Щ�Ѿ�֧�ֵIJ��֮�⣬δ���IJ���ض�����ࡣ
���⣬�����ʹ�ã�����Docker Daemon�Լ�����������ģ��û��������patch���룬Ȼ��Ŀǰ��Ȼ��Ҫ����Docker
Daemon�����������������⣬�����֧�֣�����DockerӦ�ö�����ȫ�����ģ���������벻��ı�ԭ��DockerӦ�õ�ʹ�÷�ʽ��
Docker Notary for security
Notary��server�˺�client����ɣ�Server����Ҫ���в�ά��һ�����������ż��ϣ�Client��������Server��������ʵ�ְ�ȫ����ķַ���
������ԣ�Notaryϣ���ṩһ�ּķ�ʽ�������û�����ȫ�ķ����Լ���֤�������ݡ�ԭ���ϣ����ǿ���ͨ��TLS��ȫ�����Э�鱣��ͨ��˫���İ�ȫ�ԣ�Ȼ���Ȿ���ϴ���ȱ�ݣ�ԭ��ܼ�Server�˵��κ�������������¶��������滻�Ϸ����ݣ��Ӷ�ǰ��Σ������ͨ�š�
��Notary�İ����£��������ݵķ����߿���ͨ��ǿ��ȫ��key���û����ݽ���ǩ�����ܡ�һ����ɲ������������������ȱ�������Notary���ŵļ����С�������ֻ��ͨ����ȫ������ȡ�˷����ߵĹ�Կ֮���ܺ�Notary�е�����server����ͨ�ţ������ʵ�����ȷ����Դ��
runC.io
runC��һ��OS����ͨ�õ�����ʱ���������ҽ�����OS���������ʱ����Ŀ��ַ��[https://runc.io]
Docker�ٷ�����runC�Լ�ͨ��ȫ����ԣ�����production-ready��
�ڹ��ܷ��棬runC֧��Linux���еİ�ȫ���ԣ����磺SELinux��apparmor��cgroups��seccomp�ȡ�
֧��Ŀǰ��docker����֧�ֵ�user namespace
֧����������Ǩ�ơ�
�����ڻ�����չwindows��runC��֧�֡�
ARM��ϵ��֧��Ҳ���ڻ�����չ�С�
IntelҲ�ڶ�DPDK����
��ȷ�˱���������ֲ�������еĸ�ʽ
��������������ʽ�Լ���̷�ʽ
3.1.3 ������
Docker Hub���Ϸ������ǿ�Ľ�
������V2 open source registry
�Ż���ˣ�ʵ���˸���������ٶȣ����ٵĿͷ���/�������˵Ľ�������
����ȶ��ԡ������û���������
�µ�UI����
������ȫ�Է���Docker���˺ܶ�Ŭ��������
authentication micro services
content-addressable images
one time use build hosts
on-ging scanning and audits�ȵȡ�
Ocra
Project Orca��Ը�����ṩһ�����϶��µ�����ջ���ܹ�ץȡ���еĹ��ߺ�plumbing��Docker
Engine��Docker Swarm��Networking��GUI��Docker Compose����ȫ����װ���ߡ��������õȣ���Project
Orca�dz��ʺϡ�build��ship��run���С�run���IJ��֡�
������Docker��ʼ�����Ľ�����ҵ�г���˽�л����������������Docker�Ƴ����������
3.2 �ֻ᳡����
3.2.1Docker�İ�ȫ
Docker���ṩ�İ�ȫ���Ͻ���������7�㣺
namespace����ϵͳ��Դ�ĸ���
cgroup��ɽ�������Դ������
Linux�İ�ȫģ���ṩMAC��apparmor�� SELinux��
capabilities��root��Ȩ��ϸ��Ϊ��������
ulimit�Ĺ��ܸ���ά�ȵ�������Դ��docker 1.6֮��֧�֣�
user namespace���������ڲ���root��host�ϲ���root��Ԥ��docker
1.8֧�֣�
seccompʹ�������ڽ����ܵ�ϵͳ����Ȩ�Ŀ���
Docker�ڰ�ȫ���滹�������¹�����
���;�������İ�ȫ����
���ø�Ϊ�����Linux���а棺
�Ƴ�����Ҫ��package���û��Լ������ƹ����ļ�
���Tailored Profiles
�������Դ���least-privildge���ļ�
�ļ�����������������
ͨ���������ļ����ñ������е�Ȩ��
�Ѿ��滮��runC
�������еĸ�������
ֵ���ἰ���ǣ�DockerCon��ȫ����ķ����ߣ���л�������й��Ļ�Ϊ��˾��
3.2.2 Netflix��Docker��ҵ��ʵ��
Ϊʲôѡ��Docker��
1. ��netflix�ڲ����̸��������ܴ�
2. Docker���������ڶ�ܼ�һ�����������һ��Docker�������ļ����û�������������linux�ں�����������֮���������ϵ��ֻ�����Docker����API����
3. Docker���ܱ߹������ķ�չ�Լ���Ⱥ��Ӧ�÷����Ŀ���չ�Դ��������Netflix
DockOne����������ʮ��������������η�������32����ʵʱ��־�ģ�
�Ҵ�2014�����ְ���˺�Ϳ�ʼ�Ӵ�ʵʱ��־������صļ�������Ҫ��ELK��Elasticsearch��Logstash��Kibana������ʱ��ѧϰ+ELK�Ż�����һЩ��־��С��С�֡���2015����������ʽ�ð�ʵʱ��־������Ϊ�����ṩ����˾���������š�����Ҫ����ҷ��������ڷ��ĵ�·�ϣ����ǵ��뷨�����������ʡ�
�������
����ʵʱ���������ķ�չ���ɱ��Ľ��ͣ��û��Ѿ����������������߷�����Ŀǰ���Ƿ�����û����������̡��ƴ洢�����Լ���ƽ̨��ʮ������ŵĶ����Ʒ����־��������ҵ��ÿ�촦��Լ32������2TB����־��
�����ܹ�
����һ�·���ļ����ܹ���
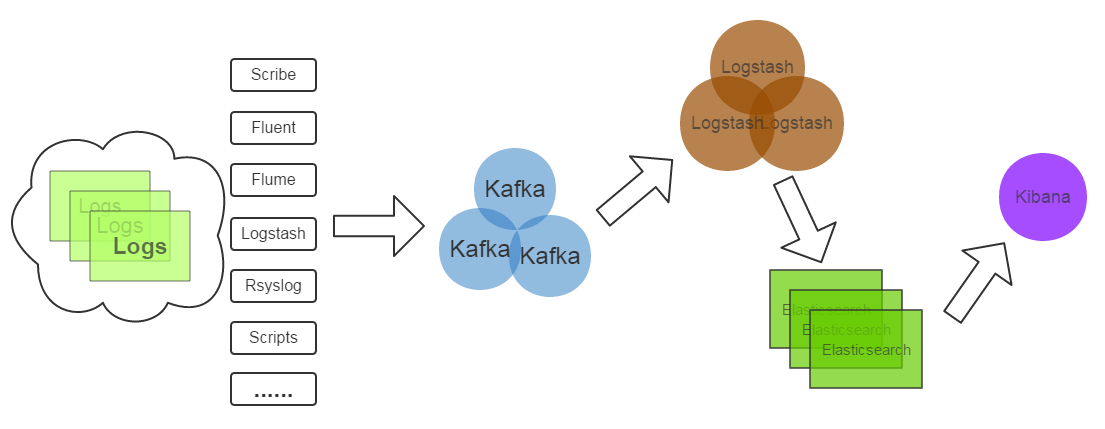
����һ���ٳ��������ļܹ��ˣ�
��1��Kafka�������û���־����Ϣ���С�
��2��Logstash������־������ͳһ��JSON�����Elasticsearch��
��3��Elasticsearch��ʵʱ��־��������ĺ��ļ�����һ��schemaless��ʵʱ�����ݴ洢����ͨ��index��֯���ݣ����ǿ���������ͳ�ƹ��ܡ�
��4��Kibana������Elasticsearch�����ݿ��ӻ��������ǿ�����ݿ��ӻ��������ڶ˾ѡ��ELK
stack����Ҫԭ��
Ŭ���ṩ���õķ���
����η������ص㲻�����ּܹ������ӻ�Ϊʲôѡ�������ļܹ�����������˵ļܹ�����θ��õش���ʵʱ��־�����ļ�ֵ��Ϊ�û����÷���Ҳ�����ļ��������ļ������ż����������в������ܸ㶨�ġ�Ϊ���ṩ���õķ�������������������������Ŭ����
һ��������������
������������Elasticsearch�Ż���Hardware Level�������ǵ�ʱ�õ�����û��ѡ����أ�ֻ�����˳��̣߳�System
Level���Ż���ر�swap������max open files�ȣ�App Level���Ż���Java���л����汾��ѡ��ES_HEAP_SIZE�����ã���bulk
index��queue size�ȣ����������Ĭ�ϵ�index template��Ŀ���Ǹ���Ĭ�ϵ�shard��replica������string��Ϊnot_analyzed������doc_values��Ӧ��elasticsearch����OOM����ϸ���Ż����ݼ�Elasticsearch
Optimization Checklist��
�����û����ݵIJ���������index����Ҳ���˴����⣬������Ҫ���ڴ�����ͬ���û����ö��ڵ�create��optimize��close��delete��snapshot��ͬ��index����ij�����������ֹ�����crontab���Dz����ܣ�����cron�ǵ��㡣�������ǿ�����һ��������Elasticsearch
Index����ϵͳ��������������ĵ��ȼ�ִ�С��������ϵͳ����ʹ�õļ�����Celery��һ����Python������������м�ִ��ϵͳ���ṩ������crontab�Ķ�ʱ���������������ʵ���˷ֲ�ʽ�������Ը��ߵļܹ���
����ķ�������������ΪElasticsearch��װ��HDFS Snapshot��������Զ��ڽ�index���ݵ�HDFS���������Ŀǰ��Ҫ���ڱ���Kibana������index�����Իָ��û��鿴�����ÿ��ӻ�����ʱ�Ĵ��������
��ر������棬System Level�ļ�ر�������Ӳ��������������崻���ֱ��ʹ�����������ڲ��ṩ�˶�������sinawatch��App
Level����Elasticsearch JVM Heap Usage���ߣ�Kibana�ܷ��������ʣ�Kafka
topic��consumer offset lag�������ǿ����˶�Ӧ�ļ�ر����ű���User Level������־����ʧ������������Ҫͨ��elasticsearch
python clientִ��queryȥͳ�ƻ������������ı�����Logstash-filter-grok��logstash-filter-json������־ʧ�ܻ������json������_grokparserfailure��_jsonparsefailure������ִ��query�жϽ������������
Ҫ˵�����ǣ�Marvel��Elasticsearch�ܺõļ�ع��ߺͲ����������������ҵ����������û�в��á�Marvel�ǻ���Kibana���ģ������һЩ��Ҫָ�꣨��index
bulk reject number����չʾ���м�ֵ��
������ǿ������
��ǿ����������Ծ��Ǹ��û����õ��û����飬�����û��ı�Թ��ELK�����Ż���һ���棬������ԶԶ�����ģ�����������ʵ������ǣ��û����������汧Թ���࣬���£�
1���û����ȱ�Թ����IP�����ɵ�����ISP��Ϣһ�㶼������ȫû�вο����塣
�����CDN���ַ������ǽ����û�IP������λ�����Ե�ڵ��������û���飬���ǰﵹæ��ԭ��LogstashĬ���Դ���IP���ǹ���maxmind��˾����Ѱ汾���й�����Ϣ���䲻�����������ʹ�����˽��½�ȫ��IP������������maxmind
geoip2 api�Ķ����Ƹ�ʽIP�⣨maxmindDB�����ٿ���logstash-filter-geoip2������IP��ʵ�ⲻ��IP����ȷ���빫˾IP����ͬ�ˣ������ٶ�Ҳ����ˡ�
2��Ȼ���������û���������־�������̸��ӣ���ͨ���ѡ�
�����������������ֺ������ɶ˵ɶ�������û���־��ʱ�����糣����Ϊ�û�����־��ʽ����IJ�ȫ�棬ģ�����ɣ�������־����ʧ�ܣ�����Խ��˶����д���á����û��������û����Կ������ݿ��ӻ�Ч�����ѵ���־����Ҫ����Сʱ�����졣һ����ȥ���û������Ƕ����ˣ�ֻ����䡣Ϊ�ˣ�����������ʵ���û����ݽ�����Զ��������ٽ���ʱ���ͨ�ɱ����������Ҫ3���ؼ���A.�û�������־��ʽ�Ľ��棬�����ܼ���B.�����û������Զ�����logstash
config��index������Ҫ�����ã�C.�Զ��������ã�logstash config�ȣ�����ͨ��־����
������������һ��������Э����־��ʽ�Ľ��棺
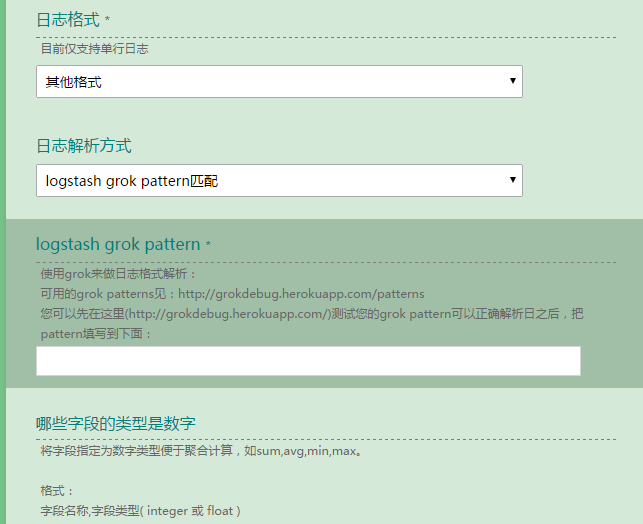
Ŀǰ�����������A��һ���֣��û���־��ʽ���ý��棻B��ȫ�����������Զ�����logstash conf��
python api��C������ʼ�����ҿ���ʹ��Docker����Ϊ�����ṩһЩ������
3���������ݿ��ӻ�����ò������㣬Kibana�����Ѷȴ�
����������ùٷ�Kibana v3���û����������SQL�еĶ��group
by�����ٷֱȣ���ָ������ռ�ȵȳ������������㡣֮��ͨ����������(��@argv)���ư��Kibana
3������һЩ�û�����Kibana 4�������뼸���Ƕ�Kibana3����д�����˴���Ľ���ͨ��Elasticsearch
Aggregation��ǿ������ͳ�ƹ��ܼ��������ô�Kibana 3��ų������������ǽ�Ǩ�Ƶ�Kibana
4��
�����ṩ�¹���
����ΪElasticsearch��װ�˹���medcl������ik���ķִʲ��elasticsearch-analysis-ik��֮ǰ���ִ�Ϊ���С��͡��������й����������ڿ��Ա�����һ�������Ĵʻ㣬�����������й�������������Ҳ����֡��̵�һЩ������������ʹ�������ǵķ���Ҳ�õ������ķִʣ�Elasticsearch�������츳���������ǵ������������ǵ�ʹ�ࡣ

���Ǿ������ĿӺͿ�����
1��elasticsearch ����JVM Heap High Usage�� > 90% ����
�ܳ�һ��ʱ�䣬���Ƕ���Ӧ��JVM Heap High Usage�������˵�������Old GC�����࣬ʱ�䳤��es�ڵ�Ƶ���˳���Ⱥ��������Ⱥ����ֹͣ��Ӧ���������ǵ���Ҫ�����ǿ���doc_values������queryִ��ʱռ�õ�JVM
Heap size��analyzed stringֻ������query��������facets����aggs������close
�û�����Ҫ��index��
2��Elasticsearch Query DSL��Facets��Aggsѧϰ����
����Ϊ�˿�����ʹ��SQLִ��ES Query�IJ����һ���̶��ϼ����˽����ż������Ǹ�����ѧϰ���ǵĽ����ǹ۲�Kibana��Request
Body������Marvel��Senese����������Զ����Query��Facets��Aggs�Ĺ��ܡ�������õ�query��query
string query����õ�aggs��Terms��Date Histogram������Ӧ��������
3��logstash��������
�ǹٷ�������������ʹ��logstash-filter-rubyʱδ���ǵ����쳣�ȣ�����Logstash����ʱ�����̣߳�worker
thread���쳣�˳���Logstash���������ǵĽ����Ǿ����ܲ�Ҫ��config��ʹ��logstash-filter-ruby������ʹ�ùٷ��������������Ҳ���������ӵ���־��д��250��+��config���þ���ruby
filter����ǰδ����Logstash�кõij���ļ�ط�����Logstash���ڲ�״̬Ҳ��ȡ����������Ŀǰͨ����ӵļ��Kafka
topic consumer�Ƿ�����elasticsearch indexing rate������logstash�Ĺ��������
4��Kibanaû���û��ĸ����ͬ�û������������롣
����û�������Kibana Dashboard�����������ɾʱ��Ӱ�������û��������dashboard̫�࣬�ҵ��ض���dashboard�����ѡ��ٷ���ĿǰΪֹ��δ���ⷽ�������Ľ����кܶ�ǹٷ��ĸĽ�������Ҳ�����ù����������Ƶ�Kibana3��Ҳ��Kibana
index����snapshot���浽HDFS���档
5�����û���ͨ�ɱ��ߡ�
�����ǵ��û�Э����־��ʽ�����ݿ��ӻ�����ʱ�������˵IJ�ȷ����������ɶ������ȷ�����ģ�Ч�ʵ��¡����DZϾ����ṩ��־��������ģ������û�����־��ά�����Խ���Ҳ��̽��ͨ����־�����Զ������Ƽ��û��ṩ������json��ʽ���ݣ�������֯�û���Kibana��ѵ�����ٹ�ͨ�ɱ���
DockOne����������ʮ������ʮ����������˽�Windows Docker
����5�·�Build����ϵĹٷ�˵����˵����������ų�Windows
Server Container�IJ��档Ҳ����˵��Ŀǰ���ǻ�������Windows Docker�IJ��汾����ֱ�����ֲ��ԡ�
����5�·�Build����ϵĹٷ�˵����˵����������ų�Windows
Server Container�IJ��档Ҳ����˵��Ŀǰ���ǻ�������Windows Docker�IJ��汾����ֱ�����ֲ��ԡ��������Ҿʹ�ҹ��ĵ�ʮ��������н��ܣ�
1. Windows Docker��Hyper-V��ɶ����
Hyper-V��VMware/Xen/KVM�����ƣ�����Ӳ�����⻯����ȫ�����ء�
Windows Docker��OS���⻯�������߱�һ���ĸ������������ܸ��á�������ֲ��
���߲��ǻ���ȡ���Ĺ�ϵ��
ע�⣺Windows Docker������������Docker 1.6ʱ������Windows
Docker Client��Ҳ����Boot2docker���Windows�µ�linux�����������������Windows�汾��Docker����ʵ����ʽ���Ʋ�����Docker�����ǽ���Windows
Server Container������Hyper-V Container����2����Ʒ������Windows
Server Container������linux Docker����Hyper-V Container��������clear
linux����Hyper Docker��
������ΪDocker���̱����ƣ�������ֱ������ʹ�á�
2. Windows Docker��Softgrid(APP-V)/Thinstall����ɶ����
Docker��OS���⻯����Ҫ�����Ƿ����Ӧ�ã���Щ����(Ӧ��)֮��ͨ����������ӿڽ���ͨ�ţ����������һ����
Softgrid��Ӧ�ó������⻯����Ҫ���ڿͻ���Ӧ�ò�������Office����ЩӦ����ͬһ���Ự�����У���ȫ���Ǵ�ͳ��Ӧ�ã��˴�֮
����Խ��н��̼�ͨ�ţ�����Word����OLE����Excel�ı����ȵȡ���ͬ�Ľ��̣��������ļ�ϵͳ������롣��������������ͻ���Ӧ�á�
3. ������ɳ����ʲô��ϵ��
��������һ��ܰ�����������������λ��
Sandboxing is focused on just security with code isolation.
Containers have some security code isolation, but this
is not the only or primary purpose. One way to think
about containers is as a layered/quarantined filesystem
which makes it quick/easy/lightweight to run an application
and also makes the application (in the container) very
portable.
����ͼ�����ǿ��Կ�������Windows 10�IE�ļ�����Edge������Ͳ�����ɳ�м�����
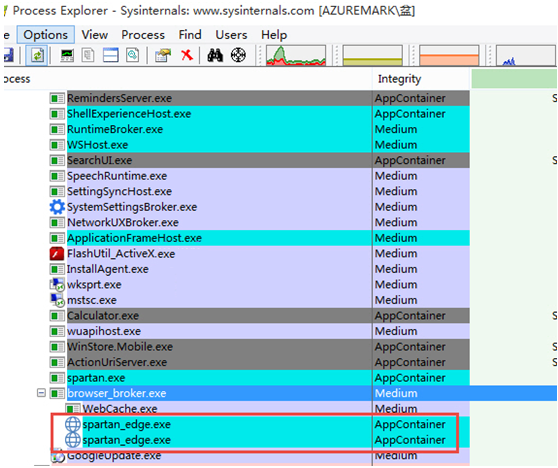
ͬ���ڱ���ģʽ�����е�Office�ĵ���Ҳ������ ɳ�������ͼ��ʾ��
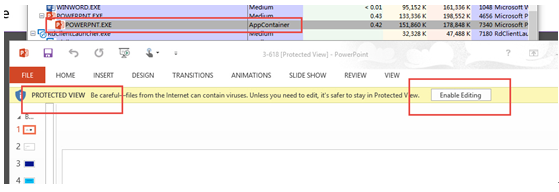
������������Ҫ���ƶ�����������������ȷ����Ӧ�ã�Ҳ�ܱ�ɰ���ݽ��Ķ�̬������ǰ��Ӳ�����⻯���ܽ�OS��App�ȱ���ĵ����Ӷ��ѷ�������Դ��ɰ���ݽ��ķ�������Windows
Docker��linuxһ����Ҳ�ܱ��image������ĵ�����ɰ���ݽ��Ķ�̬����
4. Windows Docker������OS���⻯����֮����ʲô��ϵ�������������ŵ�VPS�ȣ�
�Ӽ����Ƕȿ����ײ�ԭ����ͬС�졣��ͼ�ɡ�
Docker������OS���⻯����һ��������ʵ�ִ��²�ࡣ�ؼ���˭�ܴ�����̬Ȧ���ܹ�Ӯ���������̵�֧�֡�ͬʱDocker�ķֲ��ļ�
ϵͳʵ�֣�Ҳ�����ر�������ʤ�ĵط��������ͼ�����ص�ַ�����
5. Windows Docker�ֲ��ļ�ϵͳ��
�ȿ���Linux��ʵ�֡�DaoCloud�Ĵ�ţ�������ʦָ������������������Ubuntu:14.04ӳ��ͨ������docker
run �Cit ubuntu:14.04 /bin/bash�����������С���DockerΪ�䴴����rootfs�Լ������ɶ�д���ļ�ϵͳ���ο����Ž�ͼ
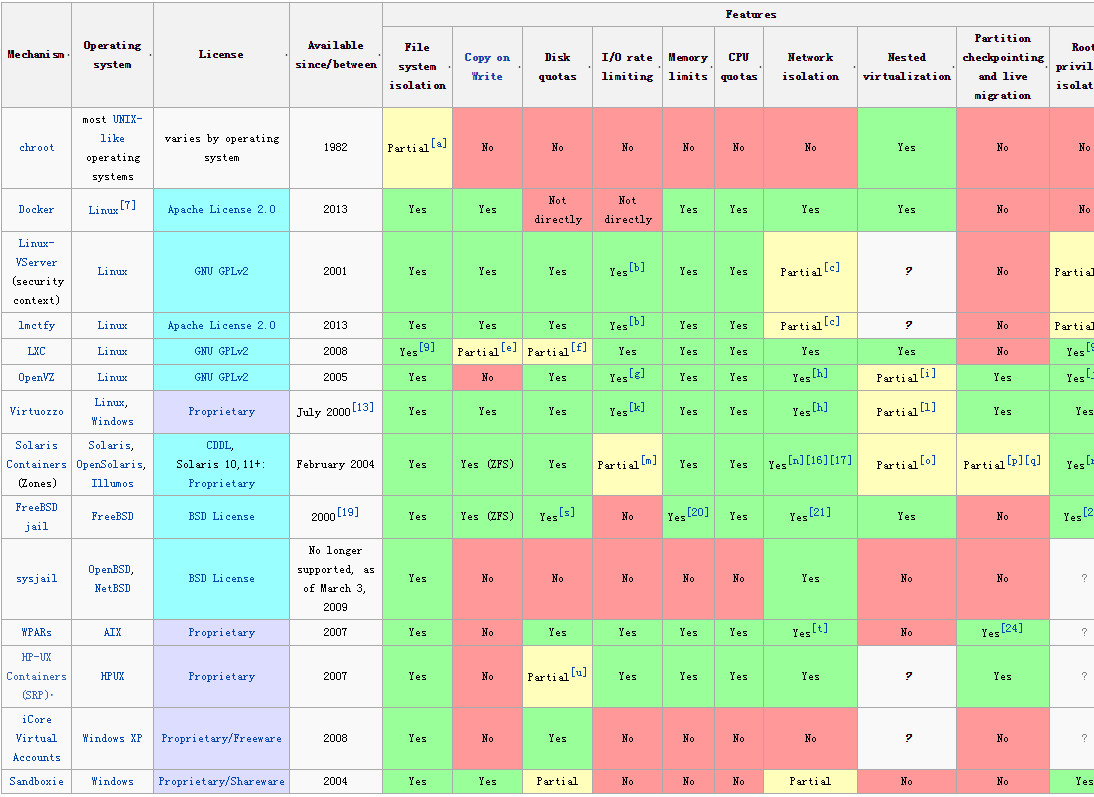
���������ӽ���������Ȼֻ��һ�����������ļ�ϵͳ�������ļ�ϵͳ�ɡ�2�㡱��ɣ��ֱ�Ϊ��д�ļ�ϵͳ��ֻ���ļ�ϵͳ������ʦ�����������ڴˡ�
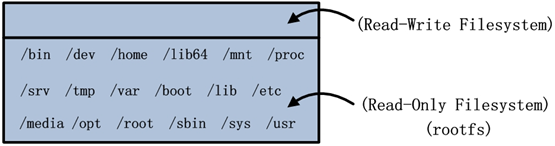
Windows Docker�������Ƶķֲ��ļ�ϵͳ���ο���ͼ��
Windows Docker����NTFS�ļ�ϵͳ���ؽ����㼼����reparse point���������ɳ�в�(sandbox
layer)�ǿɶ�д�ģ�ֻ�����������Լ�ռ�ã��������� ����ֻ���ġ�������ͼ�У��ײ�Ļ���OS����м��Ӧ�ó����ܲ㶼��ֻ���ģ��������ɳ�в���ɶ�д����
�������ӽǿ���������ռ���������ļ�ϵͳ��
���е�������Hyper-V�IJ�������������������̲��ܶ�д�����Ϸ������и��̺�Base�̶���ֻ���ģ���
Windows Docker�ķֲ��ļ�ϵͳ�����ǽ�������Ϊ���Ʒ�������(���������������⣬��Ҫ�������)���������ɳ�в���ļ�ʱ��
�൱�ڴ�һ���������ӣ���������ʱ����COW��Copy on write�������ײ���ʲô�ײ��ļ�ϵͳ���������ʵ�ֶ��������������ֻ
��Layer�ļ������ܣ����cache�ȣ�Ŀǰһ�Ų�֪����sorry��
6. Windows Docker���ļ�ϵͳ����
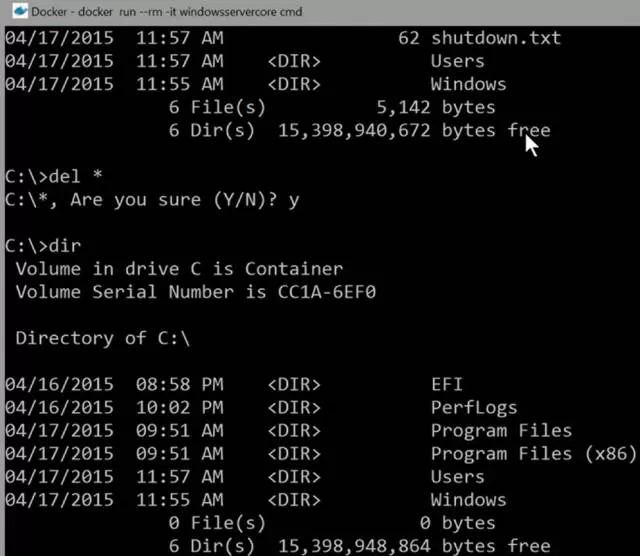
ǰ��ʱ������Ż��⣬���˹�Ʊ����Ҫ����ij���������̵ı����ˣ���������������Ϊ������ɾ������
�пͻ������ʵ���Docker�ܷ�������ֱ��磿��ʵDocker�������һ����������������ֺͱ��ݵĻ��ơ�����Dockerȷʵ���ļ�ϵͳ����
������������Build����������ʾ����Windows Container��ִ��ɾ��C�̸�Ŀ¼�������ļ���ע�����ֵ�������������������
�����Ǹ�������Ӱ������������������Ӱ�����������linux Dockerһ������ͼƬ�ɡ�
7. IPC�������
����һλ����ʦ���ィ����ʦ�����������ǿ�����linux Docker������IPC������ơ���Windows
DockerҲ�������Ƶĸ�����ơ�������ƾ�����ν�ĻỰ���롣
��ôWindows���Щ�������õ��Ự�����أ�������ܽ�һ�£�
�������ն˷��Ự����Ϊ����������������ġ�
�����û��л�������ն˷���ʵ������һ����ֻ���������û��л�ֻ���ṩ���µ�¼�û������棨shell����
��Windows Vista��ʼ��ϵͳ�����̺ͷ��������ڻỰ0������Ϊʲô����������"mstsc
/console"��������¼���������Ŀ���̨�Ự��
��Windows 8��ʼ��Metro Application��ƽ��ר�õ�Ӧ�ã���Ҳ���ûỰ���뼼����
Ҳ����˵���Ự��Ϊ���ն˷������ֶ��û����������ġ�
��Sysinternals Suite���߰����Winobj���С���ߣ����Կ����Ự�����Ч����
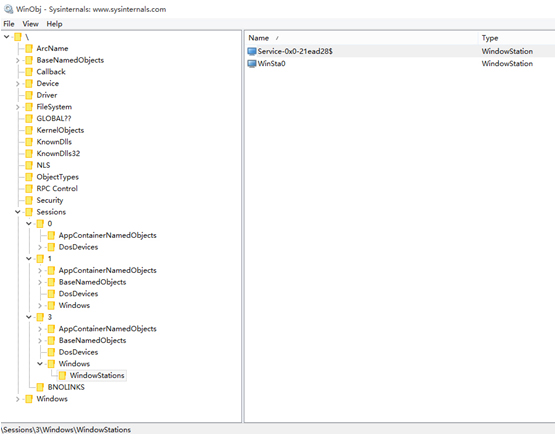
��ͼ�п��Կ�������ͬ�Ự��ӵ�в�ͬ�Ķ��������ռ䣬���粻ͬ���������Լ������Ĵ���վ(�ն˷�����������ֻ�е�ǰ��¼��
������Winsta����վ)��BaseNamedObjectsĿ¼�������¼��������źź��ڴ�εȶ���ͬ�Ự���Ӧ�ã����ܹ����ʹ�����Ϣ��Window
Message���Է�ֹ���鹥������
Windows Docker�����˻Ự���뼼������ͬ������ͬһ��Windows�����Ϸ���ͬһ���������Ͳ��ᵼ�³�ͻ��
��Build������ʾ�������2�����������Ǵ�ͬһ��Windows Server
Coreӳ���ﴴ��������������һ������������tasklist��� ��ʾ��ǰ�Ľ�����Ϣ�������Ự��
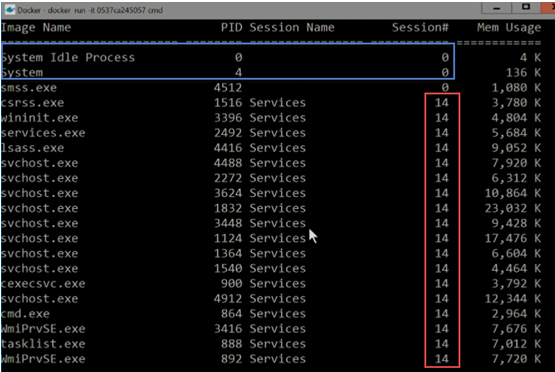
�������ͼ�У����ǿ��Կ��������������ڻỰ14�
������һ��������ͬ������tasklist�����Կ��������������ڻỰ15�
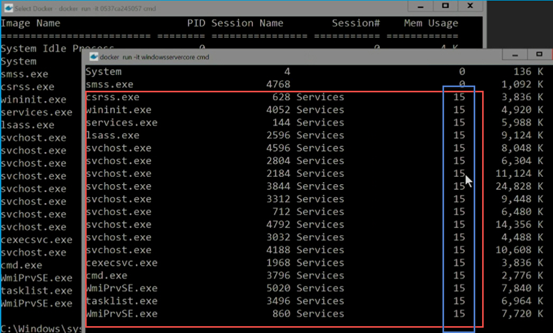
�����������������ֱ�ͨ��Զ���������һ�����õ���ͬ�ĻỰ��session�����Ӷ����namespace����������
��������ͼ���ܿ���ʲô������System�Ϳ��н����ǹ����ģ���˵��Docker�ǹ������������ںˡ���Ȼ���̺Ŷ�һ��������ʲô����
Ϊ����Windows����������̵�PID��һ������ÿ�����������Լ���svchost���̡�csrss���̺�wininit���̵ȡ���Щ���̶���
per-session�ġ�
8. Windows Docker����ʾͼ�λ�������
��ͳ��WindowsӦ�ô������GUI�ģ�������ЩӦ�ÿ�����Ҫͨ��ͼ�λ���ʽ����Զ�̲ٿء�Windows
Docker��ͨ��������RDP������ ��������
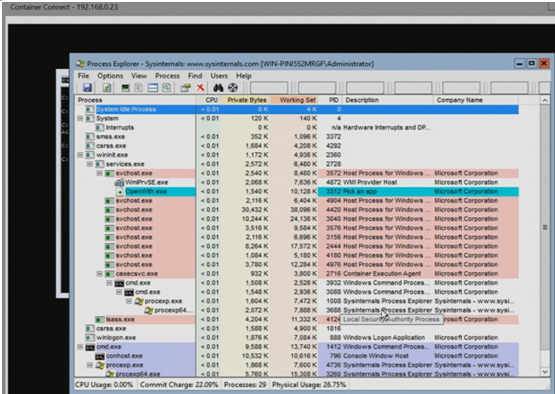
ͼ����ʾͨ��RDP�������ӵ�Process Explorer�����GUI��ϵͳ���̹������ߡ�����RDPʵ���Ͼ����ն˷�������Process
Explorer���ͼ�λ������൱����������һ���µĻỰ���ˣ����˵�����е��ֿڡ�

������ͼ�����ǿ��Կ���������Process Explorer�����ն˻Ự��ģ��������ǿ������������������������������Ự��
1.�Ự14��Docker�Լ��ĻỰ�������ﳢ������Process Exploer������ɶ��������������������ģ���Ϊͼ�λ���������Docker�ͻ���
����ʾ��LinuxҲ��������VNC/RDP�Ȱ취��ר�ŵ�ͨ�����ʡ�
2.���Ự15����ͨ��RDP���ʵĻỰ
9. ����Windows Docker
��linux Docker��Windows Docker����ס��������Ʒ��Windows server
container��hyper-v container����ȫ֧��linux Docker�Ľӿں������ͺñȵ��ӻ���ͶӰ�ǣ����ڲ�ʵ�ֹ�Ȼ���ྶͥ��Ȼ��͵��Ե�֮��Ľӿ�����ȫһ�¡�
����Windows ��������linuxһ������Docker file��ֱ��Docker build������Image��
Docker File�ļ�����
From Windowsservercore
WORKDIR \
COPY bin\Debug\ \Deapp
CMD \DemoApp\Demoapp.exe |
�������Windows azure�ƣ�����ֱ��֧��Docker��������Windows����linux��������ֱ�������µ�visual
studio�Ѵ���ǩ��azure��linux����Windows�������ȻҲ����ֱ����azure��visual
studio online����
10. Windows Docker��ͬ�汾���Լ�linux֮����ͬ
���ȷ�����ȸ���ϴ���h��ʦ��PPT��
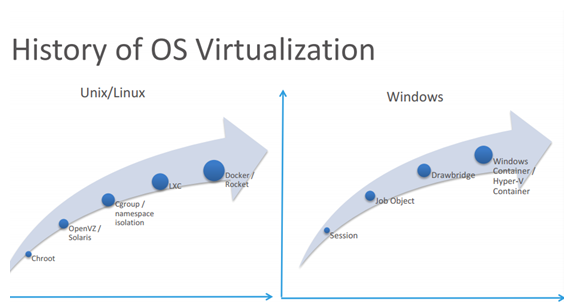
���Կ���session��JO����Windows Docker�ĸ��뼼����ͬʱJO����������linux���CGroup�����Բο�chrome����ؼ�����chrome�����õ��˲���Windows�ĸ��뼼����
�ٿ�һ��ͼƬ��
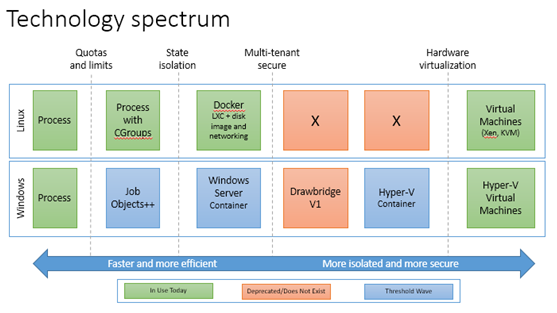
��������Կ���Windows Docker��ͬ�汾��linux֮�����ͬ�㡣����Hyper-V Container�İ�ȫ��������Windows
Server Container��
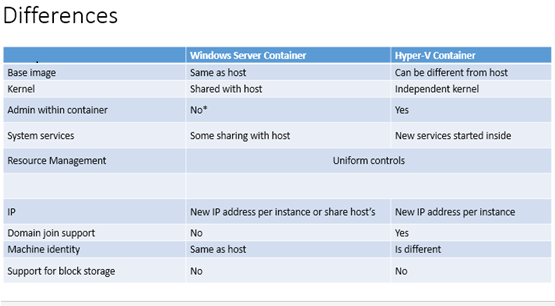
Windows Server Container��Hyper-V Container֮��IJ��죬���Բο����ͼƬ�����IJ�����ڣ�hyper-v
container֧�ֶ��⻧��ȫ������ͬʱ֧�ּ���Windows server container���ܼ�������ζ��������Ӧ����Ҫ����Ļ���������Windows
Server Container��
|





