|
�⼸��һֱ�ڰ�װCDH,ͷ������ˣ���װ�����Σ����ڳɹ��ˡ�
��һ������ܶ࣬����ж���ˣ�����û��ж�ظɾ����µڶ��ΰ�װʧ�ܡ�����������װϵͳ�ˣ�ֱ��ʹ���˴���ϵͳ���а�װ��һ�����ܵ�ѧԺ����ȥװϵͳ����Ʋ��ˡ�

�����ˣ���¼�°�װ���̡�
ϵͳ����
����ϵͳ��CentOS 6.5 x64���������£�

Cloudera Manager��5.3.4
CDH: 5.3.4
ǰ����������ϵͳ�������
��������
cloudera-manager-el6-cm5.3.4_x86_64.tar.gz
mysql-connector-java-5.1.25-bin.jar |
1�����þ�̬IP��ַ
vi /etc/sysconfig/network-scripts/ifcfg-eth0 |
��������װϵͳʱ�Ѿ������ˣ�����Ͳ������ˡ�
2����������
hostname ������ ����ǰ��Ч��
vi /etc/sysconfig/network ���´�������Ч��
[root@hadoop2 opt]# cat /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=hadoop2
GATEWAY=172.23.253.1
NTPSERVERARGS=iburst |
��������װϵͳʱ�Ѿ������ˣ�����Ͳ������ˡ�
3���� IP��HostName
��hadoop1�ڵ��ϲ���
172.23.253.20 hadoop1
172.23.253.22 hadoop2
172.23.253.23 hadoop3
172.23.253.24 hadoop4
172.23.253.25 hadoop5
172.23.253.26 hadoop6 |
���Ƶ������ڵ㣨hadoop2~hadoop6��
scp /etc/hosts hadoop2:/etc/
������
scp /etc/hosts hadoop6:/etc/ |
4������SSH�������¼�����нڵ㣩
1������������Կ �������ڵ㣩
[root@hadoop1 /]# cd /root/.ssh/
[root@hadoop1 .ssh]# ssh-keygen -t rsa
[root@hadoop1 .ssh]# cat id_rsa.pub >> authorized_keys |
�����Ƿ�ɹ�ssh localhost
���������ڵ�ͬ���ķ�ʽ������Կ��
2����������������������¼
hadoop2~hadoop6���Լ��Ĺ�Կ���Ƹ��Է�����
hadoop1�����Լ���authorized_keys���������� hadoop2~hadoop6�����������Ի����������¼�ˡ�
scp /root/.ssh/authorized_keys hadoop2:/root/.ssh/
...
scp /root/.ssh/authorized_keys hadoop6:/root/.ssh/ |
5����װOracle��Java
CentOS�Դ�Open Jdk����������CDH5��Ҫʹ��Oracle��jdk����ҪJava
7��֧�֡�jdk��װ��ʱ��һ��Ҫ����rpm�İ�װ��ʽ������Ҫ����tar��ѹ�İ�װ��ʽ����Ϊrpm�İ�װ��ʽ������/usr/lib���½����������ӡ�
���ȣ�ж���Դ���OpenJdk��ʹ��rpm -qa | grep java��ѯjava��صİ���ʹ��rpm
-e --nodeps ����ж�ص���
������rpm��������Ҫ���������û�������������ֻ��Ҫ����һ��ȫ�ֵ�JAVA_HOME�������ɣ�ִ�����
echo "JAVA_HOME=/usr/java/latest/"
>> /etc/environment
ִ������java -version��javac -version���鿴Jdk�Ƿ�װ��ȷ��
1��ж��ϵͳ�Դ�OPEN-JDK�����нڵ㣩
[root@hadoop1 .ssh]# rpm -qa | grep java
java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64
tzdata-java-2013g-1.el6.noarch
java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.x86_64
[root@hadoop1 .ssh]# rpm -e --nodeps java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64
tzdata-java-2013g-1.el6.noarch java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.x86_64 |
2����װOracle��JDK�����нڵ㣩
[root@hadoop1 opt]# rpm -ivh jdk-7u80-linux-x64.rpm
Preparing... ########################################### [100%]
1:jdk ########################################### [100%]
Unpacking JAR files...
rt.jar...
jsse.jar...
charsets.jar...
tools.jar...
localedata.jar...
jfxrt.jar...
[root@hadoop1 opt]# echo "JAVA_HOME=/usr/java/latest/" >> /etc/environment
[root@hadoop1 opt]# java -version
java version "1.7.0_80"
Java(TM) SE Runtime Environment (build 1.7.0_80-b15)
Java HotSpot(TM) 64-Bit Server VM (build 24.80-b11, mixed mode)
[root@hadoop1 opt]# javac -version
javac 1.7.0_80 |
6����װ������MySql�����ڵ㣩
ͨ��yum install mysql-server��װmysql��������
���ÿ�������chkconfig mysqld on�� ������mysql����service
mysqld start�� ��������ʾ����root�ij�ʼ���룺mysqladmin -u root password
'xxxx'��
[root@hadoop1 opt]# yum install mysql-server
[root@hadoop1 opt]# chkconfig mysqld on
[root@hadoop1 opt]# service mysqld start
[root@hadoop1 opt]# service mysqld status
[root@hadoop1 opt]# mysqladmin -u root password
'liguodong' |
����mysql������mysql -uroot -pxxxx�������������ݿ⣺
[root@hadoop1 opt]# mysql -uroot -pliguodong
mysql> create database hive DEFAULT CHARSET
utf8 COLLATE utf8_general_ci;
Query OK, 1 row affected (0.00 sec)
mysql> create database amon DEFAULT CHARSET
utf8 COLLATE utf8_general_ci;
Query OK, 1 row affected (0.00 sec)
mysql> create database hue DEFAULT CHARSET
utf8 COLLATE utf8_general_ci;
Query OK, 1 row affected (0.00 sec) |
����root��Ȩ�����������е����ݿ⡣
mysql> grant all privileges on *.* to 'root'@'hadoop1' identified by 'liguodong' with grant option;
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec) |
7���رշ���ǽ��SELinux�����нڵ㣩
ע�⣺ ��Ҫ�����еĽڵ���ִ�У���Ϊ�漰���Ķ˿�̫���ˣ���ʱ�رշ���ǽ��Ϊ�˰�װ���������㣨����ǽ������hadoop������ͨѶ�ĸ����쳣��������װ��Ϻ���Ը�����Ҫ���÷���ǽ���ԣ���֤��Ⱥ��ȫ��
�رշ���ǽ��
service iptables stop ����ʱ�رգ�
chkconfig iptables off ������������
�ر�SELINUX��
��ʵ�ʰ�װ�����з���û�йر�Ҳ�ǿ��Եģ���֪����������⣬�����һ��������֤��
setenforce 0����ʱ��Ч��
��/etc/selinux/config �µ� SELINUX=disabled��������������Ч��
[root@hadoop1 opt]# service iptables stop
iptables����������Ϊ���� ACCEPT��filter [ȷ��]
iptables���������ǽ���� [ȷ��]
iptables������ж��ģ�飺 [ȷ��]
[root@hadoop1 opt]# chkconfig iptables off
[root@hadoop1 opt]# setenforce 0
[root@hadoop1 opt]# vi /etc/selinux/config
[root@hadoop1 opt]# cat /etc/selinux//config
SELINUXTYPE=targeted
SELINUX=disabled |
8����װ������NTP�������нڵ㣩
��Ⱥ�������������뱣��ʱ��ͬ�������ʱ�����ϴ������������⡣
����˼·���£�
master�ڵ���Ϊntp������������ʱ����ͬ��ʱ�䣬��������datanode�ڵ��ṩʱ��ͬ����������datanode�ڵ���master�ڵ�Ϊ����ͬ��ʱ�䡣
���нڵ㰲װ��������yum install ntp��
��ɺ����ÿ���������chkconfig ntpd on��
����Ƿ����óɹ���chkconfig --list ntpd������2-5Ϊon״̬�ʹ����ɹ���
[root@hadoop1 opt]# yum install ntp
[root@hadoop1 opt]# chkconfig ntpd on
[root@hadoop1 opt]# chkconfig --list ntpd
ntpd 0:�ر� 1:�ر� 2:���� 3:���� 4:���� 5:���� 6:�ر� |
��������NTP�����������ڵ㣩
������֮ǰ����ʹ��ntpdate�ֶ�ͬ��һ��ʱ�䣬��ñ������ʱ����ʱ����̫��ʹ��ntpd��������ͬ��������ѡ��202.112.10.36��Ϊ��ʱ���ģ��������£�ntpdate
-u 202.112.10.36��
# ntpdate -u 202.112.10.36
22 Dec 16:52:38 ntpdate[6400]: adjust time server 202.112.10.36 offset 0.012135 sec |
ntp����ֻ��һ�������ļ������úþͿ��ԡ� ����ֻ�������õ����ã�����Ҫ�����ö���#ע��������Ͳ��ڸ�����
[root@hadoop1 opt]# vi /etc/ntp.conf
[root@hadoop1 opt]# cat /etc/ntp.conf
driftfile /var/lib/ntp/drift
restrict 127.0.0.1
restrict -6 ::1
restrict default nomodify notrap
server 202.112.10.36 prefer
includefile /etc/ntp/crypto/pw
keys /etc/ntp/keys |
�����ļ���ɣ������˳���
��������ִ���������
[root@hadoop1 opt]# service ntpd start |
����Ƿ�ɹ�����ntpstat����鿴ͬ��״̬����������״̬���������ɹ���
[root@hadoop1 ~]# ntpstat
synchronised to NTP server (202.112.10.36) at stratum 3
time correct to within 133 ms
polling server every 1024 s |
��������쳣��ȴ������ӣ�һ��ȴ�5-10���Ӳ���ͬ����
����ntp�ͻ��ˣ�hadoop2~hadoop6��
driftfile /var/lib/ntp/drift
restrict 127.0.0.1
restrict -6 ::1
restrict default kod nomodify notrap nopeer noquery
restrict -6 default kod nomodify notrap nopeer noquery
#���������ڵ�(����NTP������)������������ip
server hadoop1
includefile /etc/ntp/crypto/pw
keys /etc/ntp/keys |
�����˳������������ǰ������ʹ��ntpdate�ֶ�ͬ��һ��ʱ�䣺ntpdate
-u hadoop1 (���ڵ�ntp������)
������ܳ���ͬ��ʧ�ܵ�������벻Ҫ�ż���һ���DZ��ص�ntp��������û������������һ����Ҫ�ȴ�5-10���Ӳſ�������ͬ����
��������service ntpd start
[root@hadoop2 ~]# ntpdate -u hadoop1
27 Jun 08:14:38 ntpdate[1899]: adjust time server 172.23.253.20 offset 0.000293 sec
[root@hadoop2 ~]# service ntpd start
[root@hadoop2 ~]# chkconfig ntpd on |
��װ������Cloudera Manager Server ��Agent
Server���ã����ڵ㣩
���ص�ַ��http://archive-primary.cloudera.com/cm5/cm/5/��ѡ���ʺ����һ�
�����Լ���ϵͳѡ����Ӧ�İ汾�����ΰ�װѡ�õ���cloudera-manager-el6-cm5.3.4_x86_64.tar.gz��������ɺ�ֻ�ϴ������ڵ㼴�ɡ�
Ȼ���ѹ��/optĿ¼�£����ܽ�ѹ�������ط���
��Ϊcdh5��Դ��Ĭ����/opt/cloudera/parcel-repoѰ�ң���ô����cdh5�ı���Դ�ļ�����֮����ܡ�
[root@hadoop1 opt]# tar -zxvf cloudera-manager-el6-cm5.3.4_x86_64.tar.gz |
�����нڵ�����cloudera-scm�û���
[root@hadoop1 lib]# useradd --system --home=
/opt/cm-5.3.4/run/cloudera-scm-server/ --no-create-home --shell=/bin/false
--comment "Cloudera SCM User" cloudera-scm |
ΪCloudera Manager 5�������ݿ⣺
��Ϊ�����õ���Mysql���ݿ⣬����������Ҫ����Mysql��JDBC���������δӹ��������صİ汾�ǣ�mysql-connector-java-5.1.25-bin.jar�ŵ�/opt/cm-5.3.4/share/cmf/lib/Ŀ¼�¡�
[root@hadoop1 opt]# mv mysql-connector-java-5.1.25-bin.jar /opt/cm-5.3.4/share/cmf/lib/ |
Ȼ�������ݿ⣺
[root@hadoop1 opt]#/opt/cm-5.3.4/share/cmf/schema/scm_prepare_database.sh mysql
cm -hlocalhost -uroot -pliguodong --scm-host localhost scm scm scm |
��ʽ��:scm_prepare_database.sh ���ݿ����� ���ݿ� ������ �û��� ���� �Cscm-host
Cloudera_Manager_Server���ڵĻ�����������������֪������ʲô��ֱ���ճ��������ˡ�
����Cloudera Manager 5 Server�ˣ�
[root@hadoop1 lib]# /opt/cm-5.3.4/etc/init.d/cloudera-scm-server start |
ע�⣺
server�״�������Ҫ�����رջ���������Ϊ�״��������Զ�������ر��Լ����ݣ�
�����Ϊ����ԭ����;�˳�������ɾ�����б��Լ�����֮���ٴ���������������������ɹ��������
Agent���ã����нڵ㣩
����Cloudera Manager 5 Agents�ˡ�
�������ڵ���/opt/cm-5.3.4/etc/cloudera-scm-agent/config.ini�����serer_hostΪ���ڵ����������
[root@hadoop1 lib]# vi /opt/cm-5.3.4/etc/cloudera-scm-agent/config.ini
server_host=hadoop1 |
�ȸ���/opt/cm-5.3.4��hadoop2~hadoop6�ڵ��ϣ�
scp -r /opt/cm-5.3.4 hadoop2:/opt/
������
scp -r /opt/cm-5.3.4 hadoop6:/opt/ |
�ȴ������ɹ��������нڵ�������Agent����ע������Թ���ԱȨ��������
[root@hadoop1 lib]# /opt/cm-5.3.4/etc/init.d/cloudera-scm-agent start |
���������Cloudera Manager 5 ����̨��Ĭ�϶˿ں���7180���������ɹ��ͻῴ����½ҳ�档
Cloudera Manager Server��Agent�������ԺͿ��Խ���CDH5�İ�װ�����ˡ�
��ʱ����ͨ��������������ڵ��7180�˿ڲ���һ���ˣ�����CM Server��������Ҫ����ʱ�䣬�������Ҫ�ȴ�һ����ܷ��ʣ���Ĭ�ϵ��û����������Ϊadmin��
��������Դ
������CDH������http://archive-primary.cloudera.com/cdh5/parcels/5.3.4/��������Ҫ��������������
���������Լ�ϵͳ�汾���Ӧ��parcel����Ȼ����manifest.json�ļ���
CDH-5.2.0-1.cdh5.2.0.p0.12-el6.parcel��
CDH-5.2.0-1.cdh5.2.0.p0.12-el6.parcel.sha1��
manifest.json |
������ɺ��������ļ��ŵ�master�ڵ��/opt/cloudera/parcel-repo�£�Ŀ¼�ڰ�װCloudera
Manager 5ʱ�Ѿ����ɣ���ע��Ŀ¼һ���ֶ����ܴ���
[root@hadoop1 parcel-repo]# pwd
/opt/cloudera/parcel-repo
[root@hadoop1 parcel-repo]# ll
������ 1533188
-rw-r-----. 1 root root 1569930781 6�� 27 11:49 CDH-5.3.4-1.cdh5.3.4.p0.4-el6.parcel
-rw-r--r--. 1 root root 41 6�� 27 11:49 CDH-5.3.4-1.cdh5.3.4.p0.4-el6.parcel.sha
-rw-r--r--. 1 root root 42475 6�� 27 10:18 manifest.json |
��������manifest.json�ļ���������json��ʽ�����ã�������Ҫ�ľ���������ϵͳ�汾���Ӧ��hash�룬��Ϊ�����õ���Centos6.5�������ҵ�����λ�ã�

����������ŵ��������ҵ���hash������Ӧ��ֵ��

����hash����ֵ����������Ȼ��CDH-5.2.0-1.cdh5.2.0.p0.12-el6.parcel.sha1�ļ�����ΪCDH-5.2.0-1.cdh5.2.0.p0.12-el6.parcel.sha��������������hashֵ�滻���ı��е�hashֵ������˵Ӧ����һ�µġ�������ˣ����������ǵı���Դ��������ˡ�
Ȼ��IJ������ǿ���̨���ղ��谲װ���ɡ�
��װCDH
��http://hadoop1:7180����½����̨��Ĭ���˻������붼��admin����װʱѡ����Ѱ棬֮������cm5�����ĵ�֧�ֺ�ǿ������ʾ��װ���ɣ����ϵͳ������ʲô�����ڰ�װ�����л�����ʾ��������ʾ��ϵͳ��װ����Ϳ����ˡ�
��¼����
ѡȡ��װ�汾
ָ����װ����
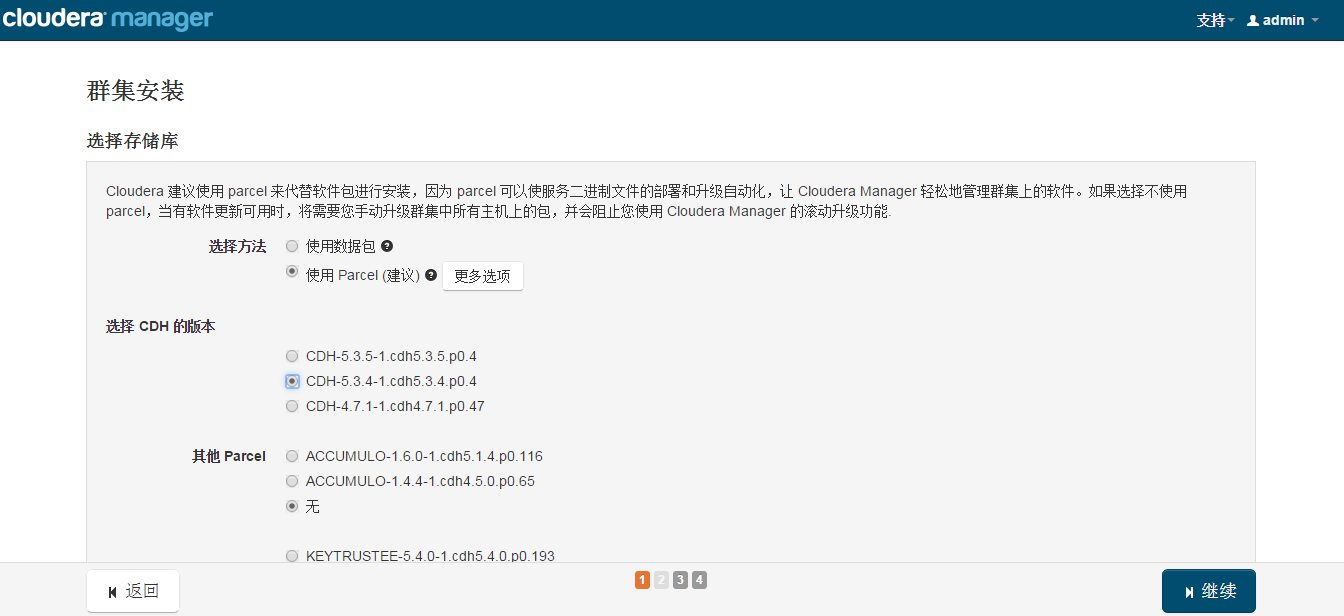
ѡȡ����Parcel��
���������������°�����˵������Parcel����������ֱ�ӵ�����Ϳ����ˡ�
��Ⱥ��װ
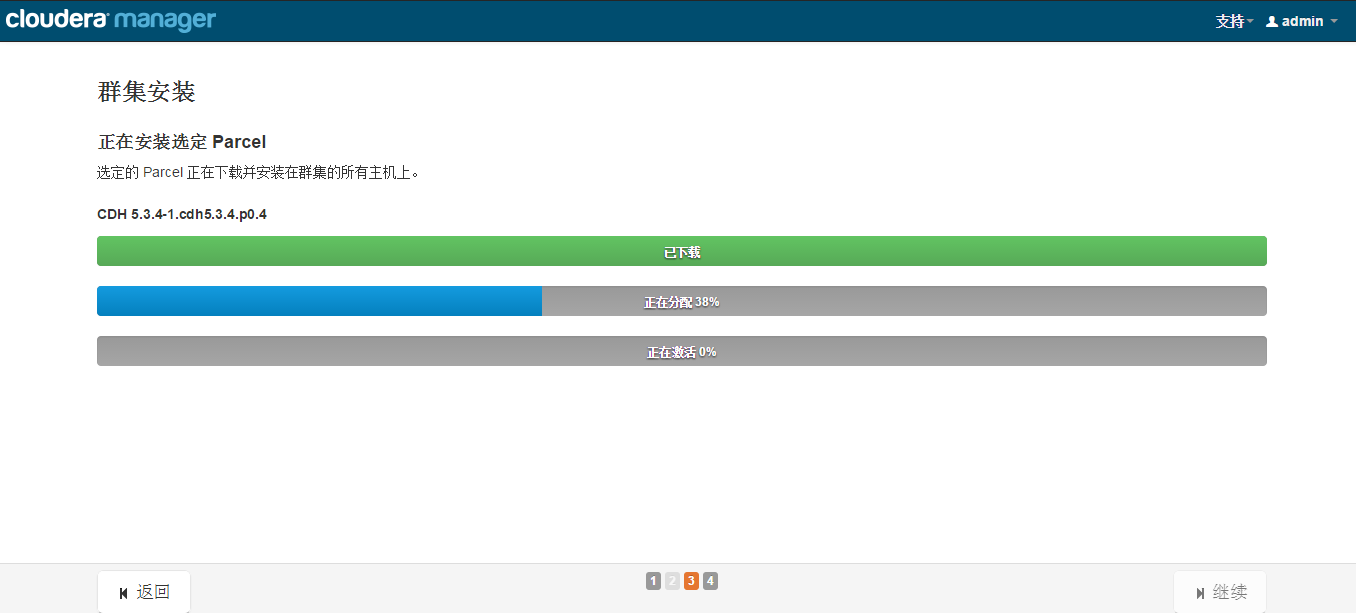
���������ȷ��
�������Ƿ�������飬���ܻ������������⣺
Cloudera ���齫 /proc/sys/vm/swappiness
����Ϊ 0����ǰ����Ϊ 60��
ʹ�� sysctl ����������ʱ���ĸ����ò��༭ /etc/sysctl.conf
��������������á�
�����Լ������а�װ�������ܻ��������⣬Cloudera Manager
���������������ڽ�������״�����ѡ�
���������ܵ�Ӱ�죺
�ڻ��ܵ�Ӱ���������ִ��echo 0 > /proc/sys/vm/swappiness����ɽ����
ѡ��װ����
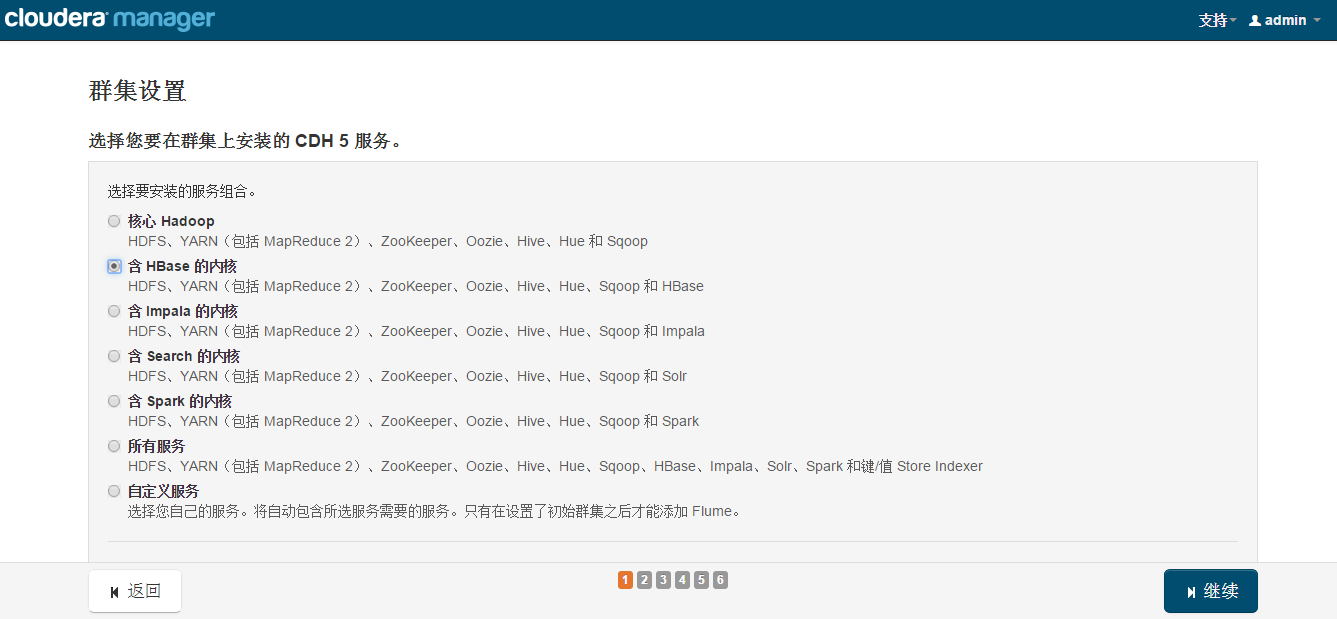
��Ⱥ��ɫ����
һ������±���Ĭ�ϾͿ����ˣ�Cloudera Manager����ݻ����������Զ��������ã������Ҫ������������н������þͿ����ˣ���
��Ⱥ���ݿ�����
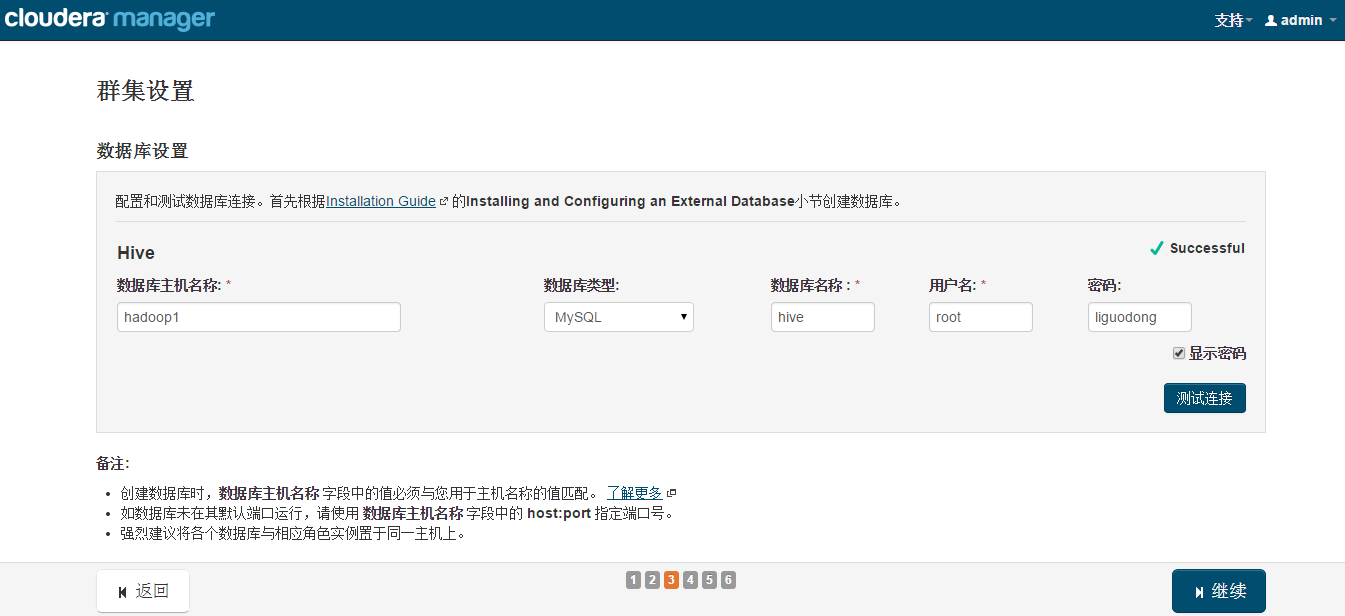
��Ⱥ������
���û����������Ĭ�����á�
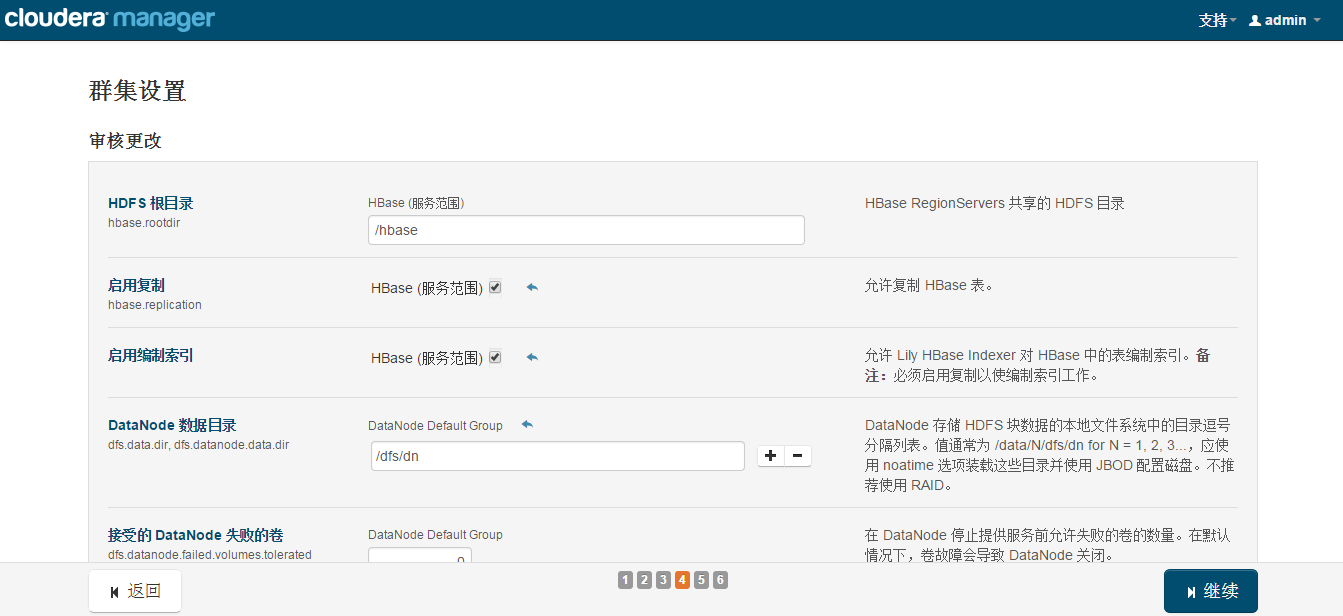
���ڵ���װ��������ĵط��ˡ�
ע�⣬���ﰲװHive��ʱ����ܻᱨ������Ϊ����ʹ����MySql��Ϊhive��Ԫ���ݴ洢��hiveĬ��û�д�mysql��������ͨ�����������һ�������ˣ�
cp /opt/cm-5.3.4/share/cmf/lib/mysql-connector-java-5.1.25-bin.jar
/opt/cloudera/parcels/CDH-5.3.4-1.cdh5.3.4.p0.12/lib/hive/lib/ |
֮���ټ�����װ�Ͳ������������ˡ�
���������ĵȴ�����İ�װ��ɣ�
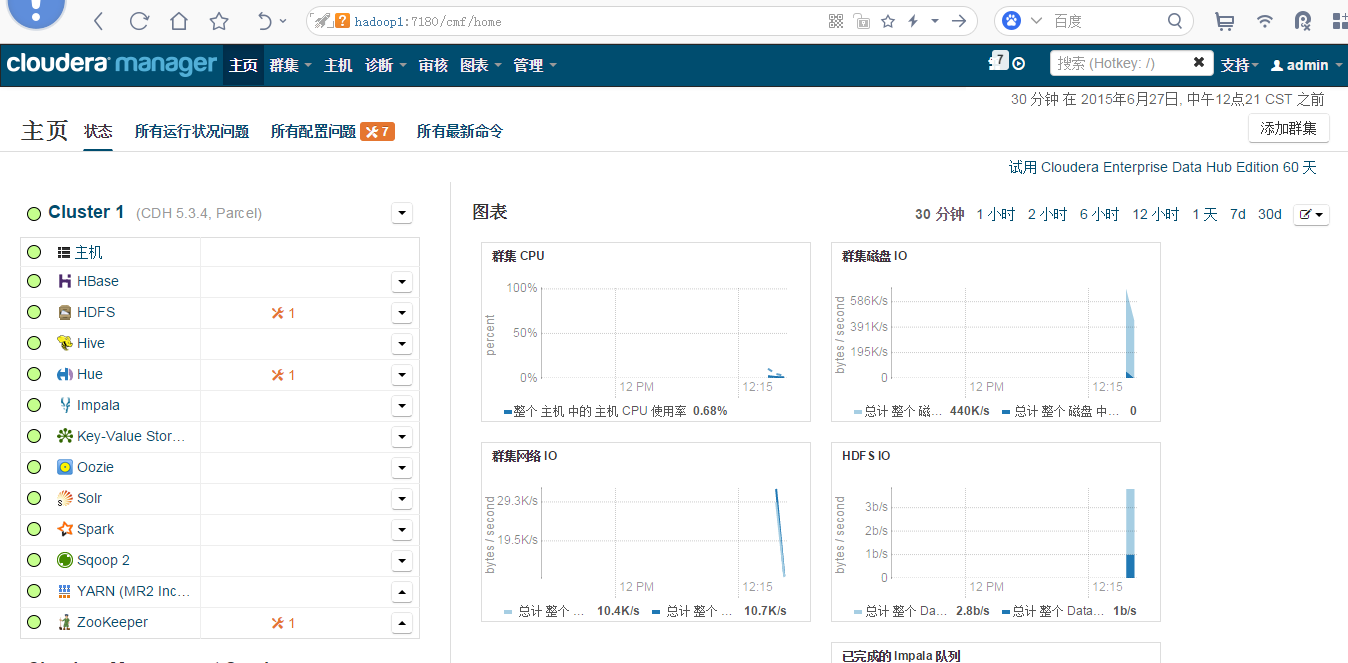
��װ��ɺͿ��Խ��뼯Ⱥ���濴һ�¼�Ⱥ�ĵ�ǰ״���ˡ�
����
[root@hadoop1 /]# su hdfs
[hdfs@hadoop1 /]$ yarn jar /opt/cloudera/parcels/CDH/lib/
hadoop-mapreduce/hadoop-mapreduce-examples.jar pi 100 1000
Number of Maps = 100
Samples per Map = 1000
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Wrote input for Map #5
Wrote input for Map #6
Wrote input for Map #7
Wrote input for Map #8
Wrote input for Map #9
Wrote input for Map #10
��������
15/06/27 22:45:55 INFO mapreduce.Job: map 100%
reduce 0%
15/06/27 22:46:00 INFO mapreduce.Job: map 100%
reduce 100%
15/06/27 22:46:01 INFO mapreduce.Job: Job job_1435378145639_0001
completed successfully
15/06/27 22:46:01 INFO mapreduce.Job: Counters:
49
Map-Reduce Framework
Map input records=100
Map output records=200
Map output bytes=1800
Map output materialized bytes=3400
Input split bytes=14490
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=3400
Reduce input records=200
Reduce output records=0
Spilled Records=400
Shuffled Maps =100
Failed Shuffles=0
Merged Map outputs=100
GC time elapsed (ms)=3791
CPU time spent (ms)=134370
Physical memory (bytes) snapshot=57824903168
Virtual memory (bytes) snapshot=160584515584
Total committed heap usage (bytes)=80012115968
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=11800
File Output Format Counters
Bytes Written=97
Job Finished in 50.543 seconds
Estimated value of Pi is 3.14120000000000000000 |
�鿴mapreduce��ҵ
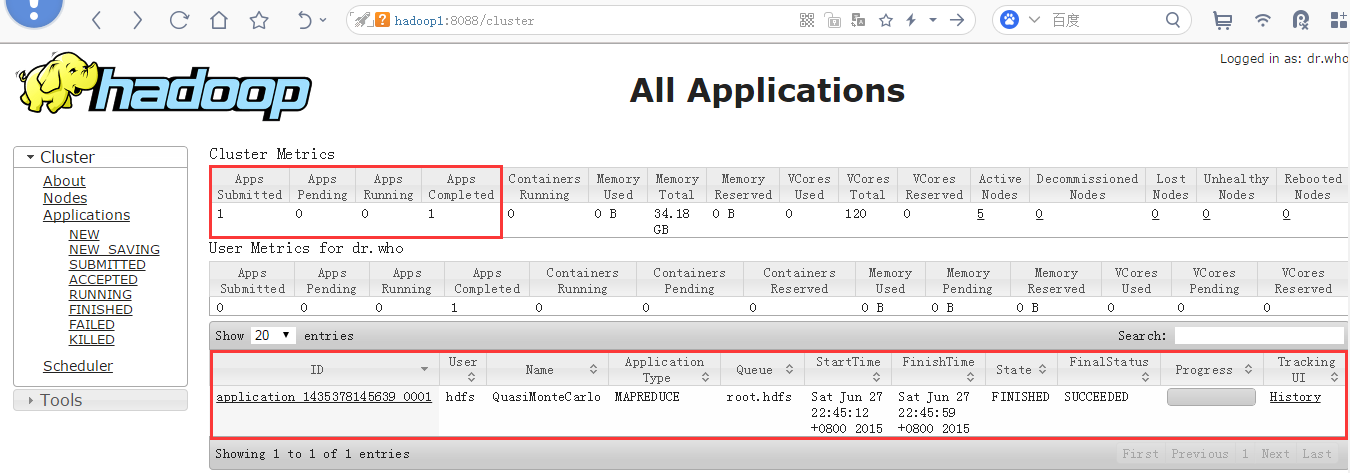
���Hue
�״ε�½Hue��������һ�����Ե��û��������룬���úã���½����̨������һ�μ�飬һ�����������ʾ��
������������ǵļ�Ⱥ����ʹ���ˡ�
|





