|
һ ���������磨��֪����
1.�ṹ
������˵����֪��ģ�͡�
��ԭ��MPģ�͵ġ����롱λ��������Ԫ�ڵ㣬��־��Ϊ�����뵥Ԫ��������䣬�������Ǿ�������ͼ���ӱ�ͼ��ʼ�����ǽ�Ȩֵw1, w2, w3д���������ߡ����м䡣
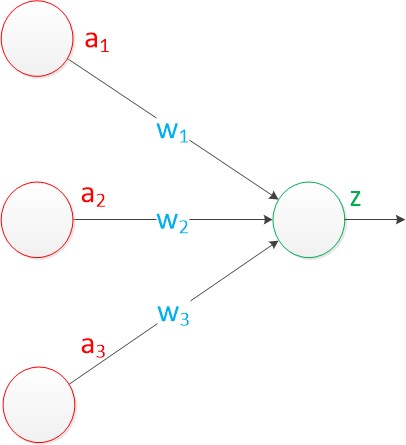
ͼ1 ����������
�ڡ���֪�����У���������Ρ��ֱ�������������㡣�������ġ����뵥Ԫ��ֻ���������ݣ��������㡣�������ġ������Ԫ������Ҫ��ǰ��һ���������м��㡣
���ǰ���Ҫ����IJ�γ�֮Ϊ������㡱������ӵ��һ�������������֮Ϊ�����������硱����һЩ���ᰴ������ӵ�еIJ���������������ѡ���֪������Ϊ���������硣���ڱ�������Ǹ��ݼ�����������������
��������ҪԤ���Ŀ�겻����һ��ֵ������һ������������[2,3]����ô�����������������һ���������Ԫ����
��ͼ��ʾ�˴������������Ԫ�ĵ��������磬���������Ԫz1�ļ��㹫ʽ����ͼ��
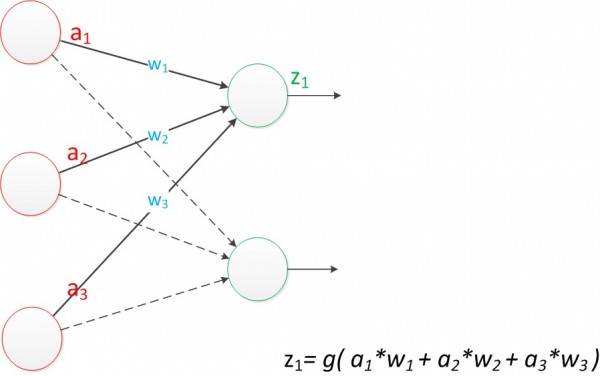
ͼ2 ����������(Z1)
���Կ�����z1�ļ����ԭ�ȵ�z��û������
������֪һ����Ԫ���������������Ԫ���ݣ����z2�ļ��㹫ʽ����ͼ��
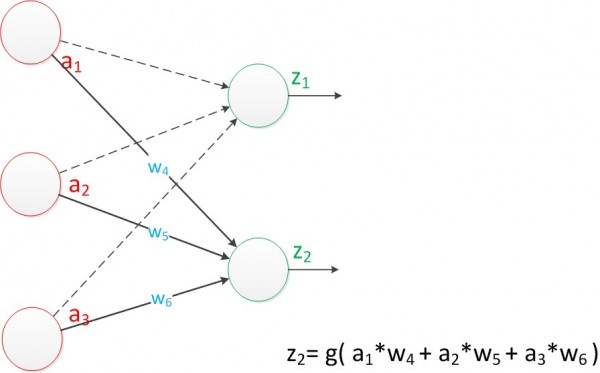
ͼ3 ����������(Z2)
���Կ�����z2�ļ����г��������µ�Ȩֵ��w4��w5��w6���⣬������z1��һ���ġ�
����������������ͼ��
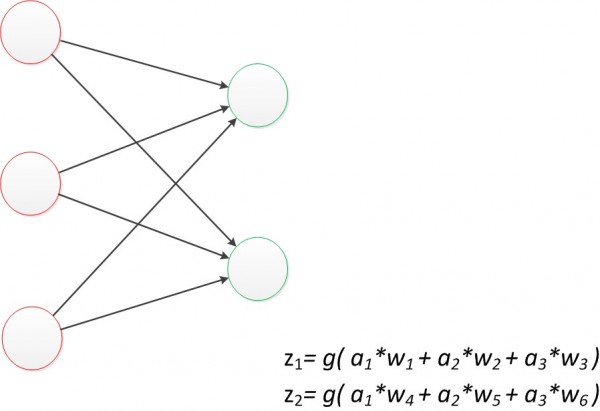
ͼ4 ����������(Z1��Z2)
Ŀǰ�ı��﹫ʽ��һ�㲻��������ľ��ǣ�w4��w5��w6�Ǻ����ӵģ����ѱ��ֳ���ԭ�ȵ�w1��w2��w3�Ĺ�ϵ��
������Ǹ��ö�ά���±꣬��wx,y������һ��Ȩֵ���±��е�x������һ����Ԫ����ţ���y����ǰһ����Ԫ����ţ���ŵ�˳����ϵ��£���
���磬w1,2������һ��ĵ�1����Ԫ��ǰһ��ĵ�2����Ԫ�����ӵ�Ȩֵ�����ֱ�Ƿ�ʽ������Andrew Ng�Ŀμ������������Ϸ�����ǣ�����������ͼ��
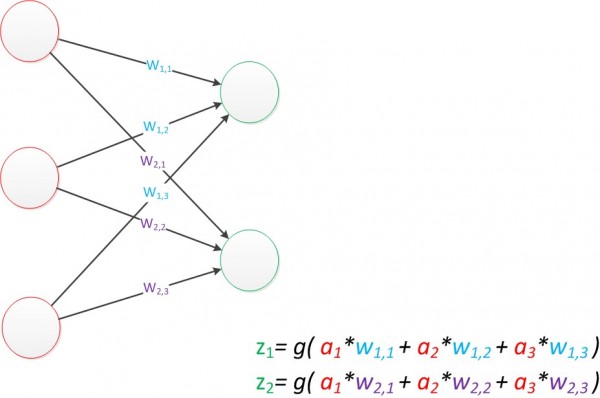
ͼ5 ����������(��չ)
���������ϸ������ļ��㹫ʽ���ᷢ����������ʽ�������Դ��������顣��˿����þ���˷���������������ʽ��
���磬����ı�����[a1��a2��a3]T��������a1��a2��a3��ɵ�����������������a����ʾ�����̵������[z1��z2]T��������z����ʾ��
ϵ�����Ǿ���W��2��3�еľ���������ʽ�빫ʽ�е�һ������
���ǣ������ʽ���Ը�д�ɣ�
g(W * a) = z;
�����ʽ�����������д�ǰһ������һ��ľ������㡣
2.��
����Ԫģ�Ͳ�ͬ����֪���е�Ȩֵ��ͨ��ѵ���õ��ġ���ˣ�������ǰ��֪ʶ����֪������֪������һ�����ع�ģ�ͣ����������Է�������
���ǿ����þ��߷ֽ�������ı�������Ч�������߷ֽ�����ڶ�ά������ƽ���л���һ��ֱ�ߣ������ݵ�ά����3ά��ʱ���ǻ���һ��ƽ�棬�����ݵ�ά����nάʱ�����ǻ���һ��n-1ά�ij�ƽ�档
��ͼ��ʾ���ڶ�άƽ���л������߷ֽ��Ч����Ҳ���Ǹ�֪���ķ���Ч����
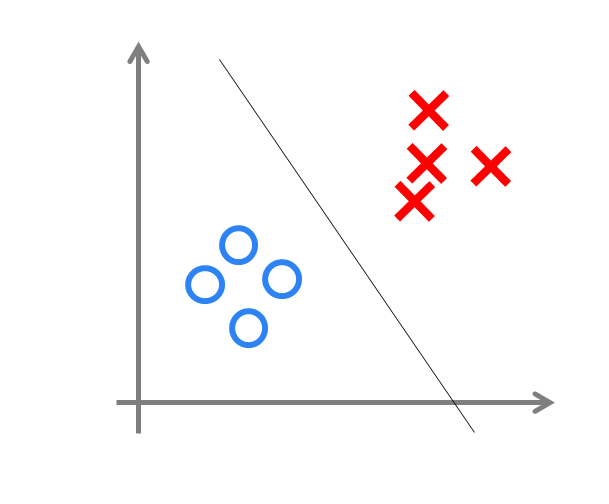
ͼ6 ���������磨���߷ֽ磩
�� ���������磨����֪����
1.�ṹ
������������˰���һ������㣬һ����������⣬��������һ���м�㡣��ʱ���м�������㶼�Ǽ���㡣������չ�Ͻڵĵ��������磬���ұ��¼�һ����Σ�ֻ����һ���ڵ㣩��
���ڣ����ǵ�Ȩֵ�������ӵ����������������ϱ������ֲ�ͬ���֮��ı�����
����ax(y)������y��ĵ�x���ڵ㡣z1��z2�����a1(2)��a2(2)����ͼ������a1(2)��a2(2)�ļ��㹫ʽ��
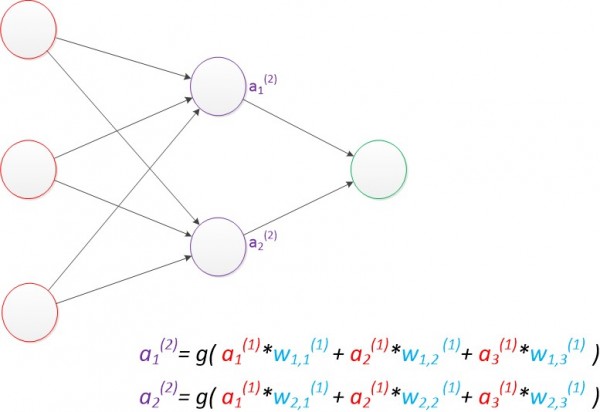
ͼ7 ���������磨�м����㣩
�����������z�ķ�ʽ���������м���a1(2)��a2(2)�͵ڶ���Ȩֵ�������õ��ģ�����ͼ��
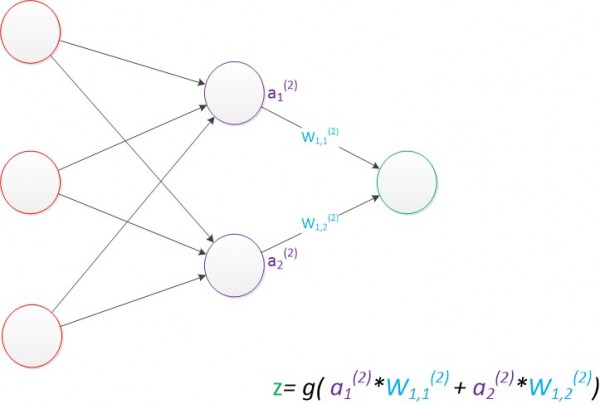
ͼ8 ���������磨�������㣩
�������ǵ�Ԥ��Ŀ����һ����������ô��ǰ�����ƣ�ֻ��Ҫ�ڡ�����㡱�����ӽڵ㼴�ɡ�
����ʹ�������;�������ʾ����еı�����a(1)��a(2)��z�������д�����������ݡ�W(1)��W(2)������ľ������������ͼ��
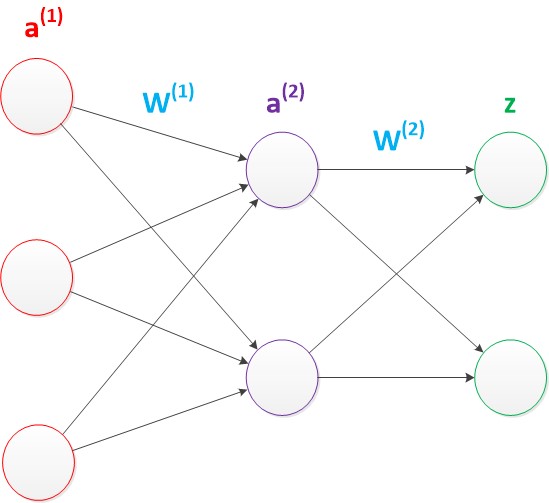
ͼ9 ���������磨������ʽ��
ʹ�þ��������������������㹫ʽ�Ļ����£�
g(W(1) * a(1)) = a(2);
g(W(2) * a(2)) = z;
�ɴ˿ɼ���ʹ�þ��������������Ǻܼ��ģ�����Ҳ�����ܵ��ڵ��������Ӱ�죨�����ж��ٽڵ�������㣬�˷����˶�ֻ��һ�������������������Ľ̳��д���ʹ�þ���������������
��Ҫ˵�����ǣ�����Ϊֹ�����Ƕ�������Ľṹͼ�������ж�û���ᵽƫ�ýڵ㣨bias unit������ʵ�ϣ���Щ�ڵ���Ĭ�ϴ��ڵġ�����������һ��ֻ���д洢���ܣ��Ҵ洢ֵ��ԶΪ1�ĵ�Ԫ�����������ÿ������У�������������⣬���Ậ������һ��ƫ�õ�Ԫ���������Իع�ģ�������ع�ģ���е�һ����
ƫ�õ�Ԫ���һ������нڵ㶼�����ӣ���������Щ����ֵΪ����b����֮Ϊƫ�á�����ͼ��
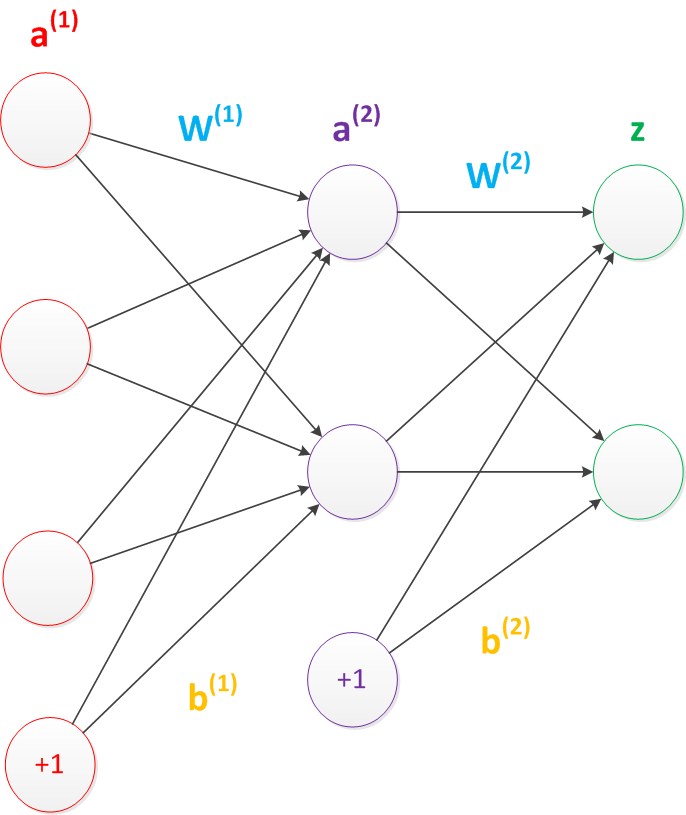
ͼ10 ���������磨����ƫ�ýڵ㣩
���Կ�����ƫ�ýڵ�ܺ��ϣ���Ϊ��û�����루ǰһ����û�м�ͷָ����������Щ������Ľṹͼ�л��ƫ�ýڵ����Ի���������Щ���ᡣһ������£����Ƕ�������ȷ����ƫ�ýڵ㡣
�ڿ�����ƫ���Ժ��һ��������ľ����������£�
g(W(1) * a(1) + b(1)) = a(2);
g(W(2) * a(2) + b(2)) = z;
��Ҫ˵�����ǣ��������������У����Dz���ʹ��sgn������Ϊ����g������ʹ��ƽ������sigmoid��Ϊ����g�����ǰѺ���gҲ�����������active function����
��ʵ�ϣ�������ı��ʾ���ͨ�������뼤��������������Ŀ��֮�����ʵ������ϵ����ѧ�߿�����Ϊ��������Ľṹͼ��Ϊ���ڳ�����ʵ����ЩԲȦ���ߣ�����һ��������ij����У���û�С��ߡ��������Ҳû�С���Ԫ���������ʵ��һ������������Ҫ�������Դ����⡣
2.��
�뵥�������粻ͬ������֤��������������������ޱƽ���������������
����ʲô��˼�أ�Ҳ����˵����Ը��ӵķ����Է����������㣨��һ�����ز㣩��������Է���ĺܺá�
�������һ�����ӣ�����ͼ����colah�IJ��ͣ�����ɫ��������ɫ���ߴ������ݡ�����ɫ�������ɫ��������������绮�����������ߵķֽ��߾��Ǿ��߷ֽ硣
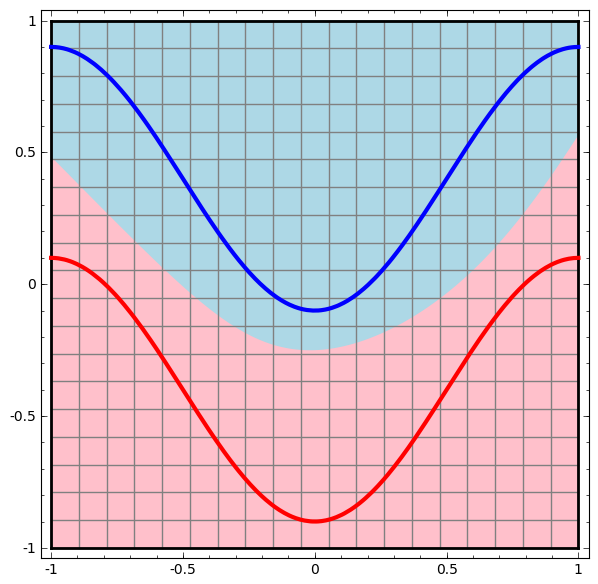
ͼ11 ���������磨���߷ֽ磩
���Կ������������������ľ��߷ֽ��Ƿdz�ƽ�������ߣ����ҷ���ĺܺá���Ȥ���ǣ�ǰ���Ѿ�ѧ��������������ֻ�������Է������������������еĺ�һ��Ҳ�����Է���㣬Ӧ��ֻ�������Է�������Ϊʲô�������Է��������ϾͿ����������Է�������
���ǿ��������ľ��߷ֽ絥���ó�����һ�¡�������ͼ��
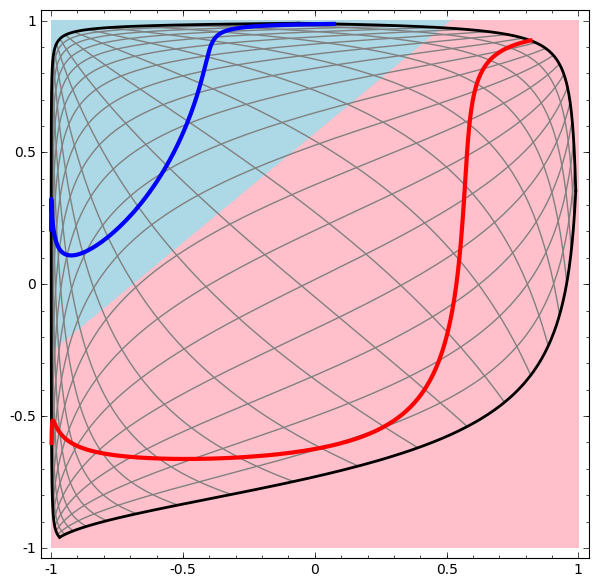
ͼ12 ���������磨�ռ�任��
���Կ����������ľ��߷ֽ���Ȼ��ֱ�ߡ��ؼ����ǣ�������㵽���ز�ʱ�����ݷ����˿ռ�任��Ҳ����˵�������������У����ز��ԭʼ�����ݽ�����һ���ռ�任��ʹ����Ա����Է��࣬Ȼ�������ľ��߷ֽ绮����һ�����Է���ֽ��ߣ�������з��ࡣ
�����͵�������������������������Է���Ĺؼ��C���ز㡣���뵽����һ��ʼ�Ƶ����ľ���ʽ������֪���������������ˣ������Ͼ��Ƕ�����������ռ����һ���任����ˣ����ز�IJ�����������þ���ʹ�����ݵ�ԭʼ����ռ�����Բ��ɷ֣�ת���������Կɷ֡�
����������ͨ�����������ģ��ģ������������ʵ�ķ����Ժ�������ˣ�����������ı��ʾ��Ǹ��Ӻ�����ϡ�
����������һ�����ز�Ľڵ�����ơ������һ��������ʱ�������Ľڵ�����Ҫ��������ά��ƥ�䣬�����Ľڵ���Ҫ��Ŀ���ά��ƥ�䡣���м��Ľڵ�����ȴ���������ָ���ġ���ˣ������ɡ�����������ߵ����С����ǣ��ڵ������õĶ��٣�ȴ��Ӱ�쵽����ģ�͵�Ч������ξ���������ɲ�Ľڵ����أ�Ŀǰҵ��û�����Ƶ�������ָ��������ߡ�һ���Ǹ��ݾ��������á��Ϻõķ�������Ԥ���趨������ѡֵ��ͨ���л��⼸��ֵ��������ģ�͵�Ԥ��Ч����ѡ��Ч����õ�ֵ��Ϊ����ѡ�����ַ����ֽ���Grid Search��������������
�˽�������������Ľṹ�Ժ����ǾͿ��Կ����������ƵĽṹͼ������EasyPR�ַ�ʶ������ܹ�����ͼ����
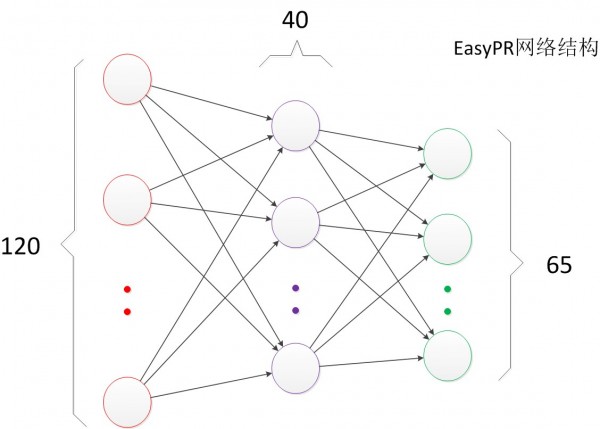
ͼ13 EasyPR�ַ�ʶ������
EasyPRʹ�����ַ���ͼ��ȥ�����ַ����ֵ�ʶ��������120ά�������������ҪԤ���������𣬹���65�ࡣ����ʵ�飬���Dz�����һЩ���ز���Ŀ�����ֵ�ֵΪ40ʱ�����������ڲ��Լ��ϵ�Ч���Ϻã����ѡ����������սṹ����120��40��65��
3.ѵ��
�������һ�������������ѵ����
��Rosenblat����ĸ�֪��ģ���У�ģ���еIJ������Ա�ѵ��������ʹ�õķ�����Ϊ����û��ʹ��Ŀǰ����ѧϰ��ͨ�õķ������������չ���������Էdz����ޡ������������翪ʼ����������о���Ա��ʼʹ�û���ѧϰ��صļ��������������ѵ���������ô��������ݣ�1000-10000���ң���ʹ���㷨�����Ż��ȵȣ��Ӷ�ʹ��ģ��ѵ�����Ի�����������������ϵ�˫�����ơ�
����ѧϰģ��ѵ����Ŀ�ģ�����ʹ�ò��������ܵ�����ʵ��ģ�ͱƽ������������������ġ����ȸ����в����������ֵ������ʹ����Щ������ɵIJ���ֵ����Ԥ��ѵ�������е�������������Ԥ��Ŀ��Ϊyp����ʵĿ��Ϊy����ô������һ��ֵloss�����㹫ʽ���¡�
loss = (yp - y)2
���ֵ��֮Ϊ��ʧ��loss�������ǵ�Ŀ�����ʹ������ѵ�����ݵ���ʧ�;����ܵ�С��
�������ǰ��������Ԥ��ľ���ʽ���뵽yp�У���Ϊ��z=yp������ô���ǿ�����ʧдΪ���ڲ�����parameter���ĺ��������������֮Ϊ��ʧ������loss function����������������������Ż��������ܹ�����ʧ������ֵ��С��
��ʱ�������ͱ�ת��Ϊһ���Ż����⡣һ�����÷������Ǹߵ���ѧ�е�������������������ڲ�����ֹһ��������㵼������0���������ܴ�����һ����˵�������Ż�����ʹ�õ����ݶ��½��㷨���ݶ��½��㷨ÿ�μ�������ڵ�ǰ���ݶȣ�Ȼ���ò��������ݶȵķ�����ǰ��һ�ξ��룬�����ظ���ֱ���ݶȽӽ���ʱ��ֹ��һ�����ʱ�����еIJ���ǡ�ôﵽʹ��ʧ�����ﵽһ�����ֵ��״̬��
��������ģ���У����ڽṹ���ӣ�ÿ�μ����ݶȵĴ��ۺܴ���˻���Ҫʹ�÷����㷨�������㷨��������������Ľṹ���еļ��㡣��һ�μ������в������ݶȣ����ǴӺ���ǰ�����ȼ����������ݶȣ�Ȼ���ǵڶ�������������ݶȣ��������м����ݶȣ���Ȼ���ǵ�һ������������ݶȣ�������������ݶȡ���������Ժ���Ҫ����������������ݶȾͶ����ˡ�
�����㷨����ֱ�۵�����Ϊ��ͼ���ݶȵļ���Ӻ���ǰ��һ��㷴����ǰE��������Ե�������˼��
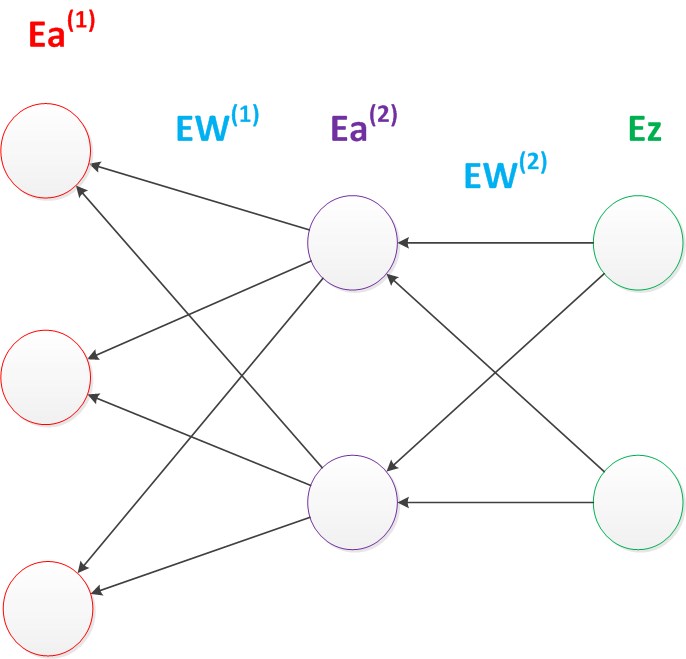
ͼ14 �����㷨
�����㷨����ʾ����ѧ�е���ʽ�����ڴ���Ҫ˵�����ǣ�����������������о���ԱŬ��������ѧ�еõ�����������BP�㷨��ʼ���о����Ǹ���ش���ѧ��Ѱ����������Ž⡣����äĿģ�������������������о��������ı�־�������ѧ���ǿ��Դ�����ķ����еõ���������û�б�Ҫһ��Ҫ��ȫģ������ķ��з�ʽ��Ҳ��������Է���ķɻ���
�Ż�����ֻ��ѵ���е�һ�����֡�����ѧϰ����֮���Գ�Ϊѧϰ���⣬�������Ż����⣬������Ϊ������Ҫ��������ѵ���������һ����С�����ڲ��Լ���ҲҪ���ֺá���Ϊģ��������Ҫ����û�м���ѵ�����ݵ���ʵ����������ģ���ڲ��Լ��ϵ�Ԥ��Ч�����������������generalization������ط�������������regularization�����������г��õķ���������Ȩ��˥���ȡ�
�� ��������磨���ѧϰ��
1.�ṹ
������������������ķ�ʽ�����һ����������硣
��������������������棬�������Ӳ�Ρ�ԭ������������м�㣬�¼ӵIJ�γ�Ϊ�µ�����㡣���Կ��Եõ���ͼ��
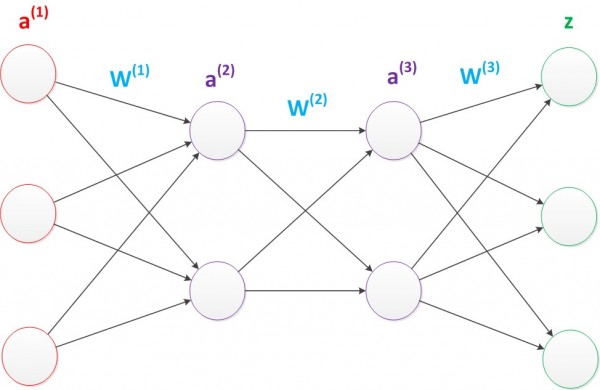
ͼ15 ���������
���������ķ�ʽ�������ӣ����ǿ��Եõ������Ķ�������硣��ʽ�Ƶ��Ļ���ʵ���������������ƣ�ʹ�þ�������Ļ��ͽ����Ǽ�һ����ʽ���ѡ�
����֪����a(1)������W(1)��W(2)��W(3)������£����z���Ƶ���ʽ���£�
g(W(1) * a(1)) = a(2);
g(W(2) * a(2)) = a(3);
g(W(3) * a(3)) = z;
����������У����Ҳ�ǰ���һ��һ��ķ�ʽ�����㡣��������IJ㿪ʼ��������е�Ԫ��ֵ�Ժ��ټ����������һ�㡣ֻ�е�ǰ�����е�Ԫ��ֵ����������ԺŻ�����һ�㡣�е��������ǰ�����ƽ��ĸо�������������̽�������������
��������һ�¶���������еIJ�����
�������ǿ���һ��ͼ�����Կ���W(1)����6��������W(2)����4��������W(3)����6�����������������������еIJ�����16�����������Dz�����ƫ�ýڵ㣬��ͬ����
�������ǽ��м��Ľڵ�����һ�µ�������һ���м���Ϊ3����Ԫ���ڶ����м���Ϊ4����Ԫ��
���������Ժ���������IJ��������33����
��Ȼ�������ֲ��䣬���ǵڶ���������IJ�������ȴ�ǵ�һ��������Ľӽ�����֮�࣬�Ӷ������˸��õı�ʾ��represention����������ʾ�����Ƕ���������һ����Ҫ���ʣ�����������ܡ�
�ڲ���һ�µ�����£�����Ҳ���Ի��һ������������硣
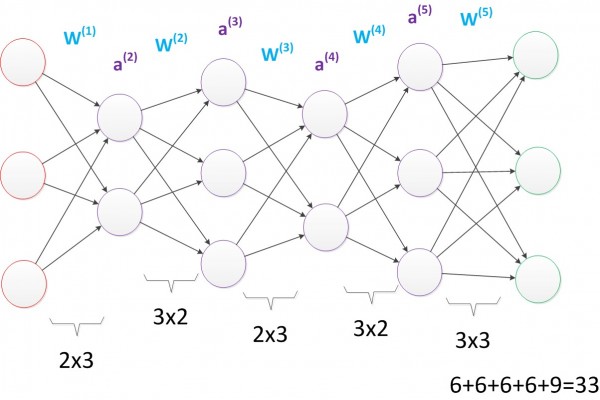
ͼ16 ��������磨����IJ�Σ�
��ͼ�������У���Ȼ����������Ȼ��33����ȴ��4���м�㣬��ԭ�������Ľӽ�����������ζ��һ���IJ��������������ø���IJ��ȥ���
2.��
������������粻ͬ������������еIJ��������˺ܶࡣ
���Ӹ���IJ����ʲô�ô���������ı�ʾ�������Լ���ǿ�ĺ���ģ��������
������ı�ʾ���������������⣬��������IJ������ӣ�ÿһ�����ǰһ��εij����ʾ�����롣���������У�ÿһ����Ԫѧϰ������ǰһ����Ԫֵ�ĸ�����ı�ʾ�������һ�����ز�ѧϰ�����ǡ���Ե�����������ڶ������ز�ѧϰ�������ɡ���Ե����ɵġ���״�������������������ز�ѧϰ�������ɡ���״����ɵġ�ͼ�������������������ز�ѧϰ�������ɡ�ͼ������ɵġ�Ŀ�ꡱ��������ͨ����ȡ�������������������������֣��Ӷ���ø��õ����������������
�����������ѧϰ�����ӣ����Բο���ͼ��

ͼ17 ��������磨����ѧϰ��
��ǿ�ĺ���ģ���������������Ų��������ӣ���������IJ�����Խ�ࡣ����������ʵ���ʾ���ģ��������Ŀ��֮�����ʵ��ϵ�����ķ���������IJ�����ζ����ģ��ĺ������Ը��ӵĸ��ӣ������и����������capcity��ȥ��������Ĺ�ϵ��
ͨ���о����֣��ڲ�������һ��������£�����������������б�dz���������õ�ʶ��Ч�ʡ����Ҳ��ImageNet�Ķ�δ����еõ���֤ʵ����2012����ÿ����ImageNet�ھ������������IJ����������ӣ�2015����õķ���GoogleNet��һ�����22��������硣
������һ���ImageNet�����ϣ�Ŀǰ�õ���óɼ���MSRA�Ŷӵķ���ʹ�õĸ���һ�����152������磡������������������Ϣ����Ȥ�Ŀ��Բ���ImageNet��վ��
3.ѵ��
�ڵ���������ʱ������ʹ�õļ������sgn��������������������ʱ������ʹ�õ�������sigmoid�����������˶��������ʱ��ͨ��һϵ�е��о����֣�ReLU������ѵ�����������ʱ������������������Ԥ�����ܸ��á���ˣ�Ŀǰ�����ѧϰ�У������еķ����Ժ�����ReLU������ReLU�������Ǵ�ͳ�ķ����Ժ��������Ƿֶ����Ժ����������ʽ�dz�������y=max(x,0)�������֮����x����0������������룬����xС��0ʱ������ͱ���Ϊ0�����ֺ������������������������Ԫ���ڼ�����������Ӧ���Լ�������ij����ֵ��Ͳ�����Ӧ��ģ�⡣
�ڶ���������У�ѵ����������Ȼ���Ż��ͷ�������ʹ���㹻ǿ�ļ���оƬ������GPUͼ�μ��ٿ���ʱ���ݶ��½��㷨�Լ������㷨�ڶ���������е�ѵ������Ȼ�����ĺܺá�Ŀǰѧ������Ҫ���о������ڿ����µ��㷨��Ҳ���ڶ��������㷨���в��ϵ��Ż������磬������һ�ִ��������ӣ�momentum�����ݶ��½��㷨��
�����ѧϰ�У�����������ı��������ӵ���Ҫ������Ҫ����Ϊ������IJ��������ˣ�����Ҳ�����ˣ���ʾ�����������ǿ�������׳��ֹ��������������������Ե�ʮ����Ҫ��Ŀǰ��Dropout�������Լ��������ݣ�Data-Augmentation��������Ŀǰʹ�õ�������������
�� ���ѧϰ��֪�Ŀ��
GitHub����ʵ���кܶ���Ŀ�Դ��Ŀֵ�ù�ע�����������Ƽ�Ŀǰ��ģ������ߵ�TOP3��
һ��Caffe��Դ�Լ��ݲ�������У��Caffe���㷺Ӧ�ã�����Pinterest������web����TensorFlowһ����CaffeҲ����C++������CaffeҲ��Google������Щʱ����DeepDream��Ŀ������ʶ�������˵��˹����������磩�Ļ�����
����Theano��2008�굮����������������ѧԺ��Theano�������˴������ѧϰPython���������������İ���Blocks��Keras��
����Torch��Torch�����Ѿ���ʮ��֮�ã������������Ƶ�����ȥ��Facebook��Դ�˴���Torch�����ѧϰģ�����չ��Torch����һ������֮���Dz����˲���ô���еı������Lua����������������������Ƶ��Ϸ����
�������������Ƚϳ���֪������Ŀ�����кܶ�����ɫ�����ѧϰ��Դ���Ҳֵ�ù�ע��
�ġ�Brainstorm��������ʿ�˹�����ʵ����IDSIA��һ���dz���չǰ���ܲ��������ѧϰ��������Brainstorm�ܹ������ϰٲ�ij�����������硪����ν�Ĺ�·����Highway Networks��
�塢Chainer������һ���ձ������ѧϰ��ҵ��˾Preferred Networks������6�·�����һ��Python��ܡ�Chainer����ƻ���define by runԭ��Ҳ����˵���������������ж�̬���壬������������ʱ���壬������Chainer����ϸ�ĵ���
����Deeplearning4j�� ����˼�壬Deeplearning4j�ǡ�for Java�������ѧϰ��ܣ�Ҳ�������ü�������ѧϰ��Դ�⡣Deeplearning4j�ɴ�ҵ��˾Skymind��2014��6�·�����ʹ�� Deeplearning4j�IJ�����ɭ�ܡ�ѩ��������˹��ѯ��IBM��������ҵ��
DeepLearning4j��һ������������������ҵӦ�õĸ߳�������ѧϰ��Դ�⣬����Hadoop��Spark���ɣ����弴�ã����㿪������APP�п��ټ������ѧϰ���ܣ���Ӧ�����������ѧϰ����
- ����/ͼ��ʶ��
-
��������
-
����ת���֣�Speech to text��
-
������Ϣ���ˣ��쳣��⣩
-
������թ���
�ߡ�Marvin��������˹�ٴ�ѧ�Ӿ����������Ƴ���C++��ܡ����Ŷӻ��ṩ��һ���ļ����ڽ�Caffeģ��ת������Marvin���ݵ�ģʽ��
�ˡ�ConvNetJS������˹̹����ѧ��ʿ��Andrej Karpathy���������������������ܵ�JavaScript�����������������ѵ�������硣Karpathy��д��һ��ConvNetJS�����Ž̳̣��Լ�һ�������������ʾ��Ŀ��
�š�MXNet������CXXNet��Minerva��Purine����Ŀ�Ŀ�����֮�֣���Ҫ��C++��д��MXNetǿ������ڴ�ʹ�õ�Ч�ʣ��������������ֻ�����������ͼ��ʶ�������
ʮ��Neon���ɴ�ҵ��˾Nervana Systems�ڽ������¿�Դ����ijЩ�������У���Python��Sass������Neon�IJ��Գɼ�����Ҫ����Caffeine��Torch�ȸ��TensorFlow��
|





