»ÁĻŻń„ŌŽ Ļ”√KubernetesņīĻĻĹ®ń„Ķń”¶”√≥Ő–ÚĽ∑ĺ≥£¨Õ®ĻżOpenStackņī≤Ņ ūKubernetes∆šľ‹ĻĻ «“Ľ÷÷Õ∆ľŲĶń∑Ĺ Ĺ£¨ĪĺőńĹꔎīůľ“∑÷ŌŪKubernetes‘ŕOpenStack…ŌĶńĪŗŇŇ∑Ĺ Ĺ”Ž∆š”ŇĽĮ∑Ĺ∑®°£
“‘Ō¬Ĺť…‹5÷÷’Ž∂‘KubernetesĶńĶų”Ň∑Ĺ Ĺ£¨Ō£ÕŻ∂‘īůľ“”–ňýįÔ÷ķ°£
Ĺ”Ō¬ņī»√ő“√«ī”ľ‹ĻĻ∑÷őŲŅ™ ľ£¨ŃňĹ‚ő™ ≤√ī–Ť“™’‚—ýĶńľ‹ĻĻīś‘ŕ£¨Ĺ‚ĺŲ ≤√ī—ýĶńő Ő‚°£Ĺ”◊ŇŃňĹ‚”ŇĽĮĶńńŅĶń£¨ő“√«…Ó»ŽŐĹŐ÷ľłłŲ”ŇĽĮ∑Ĺ Ĺ”Ž—°ŌÓ°£ĹŠļŌ≤Ņ∑÷ Ķľ įłņżĽÚ≤‚ ‘ņī”ŇĽĮļůĶńłń…∆°£◊ÓļůŐĹŐ÷ļů–Ý∑Ę’Ļ”Žľ∆Ľģ°£
ľ‹ĻĻ∑÷őŲ
»›∆ųĶńīś‘ŕ «ő™ŃňĹ‚ĺŲőř◊īŐ¨(stateless)Ķń∑ĢőŮ’ľ”√ŌĶÕ≥◊ ‘īĶńő Ő‚°£’Ž∂‘ÕݬÁ”¶”√≥Ő–ÚņīňĶ£¨ľīń‹ľű…Ŕ–ťń‚ĽĮňýīÝņīĶńŌŻļń£¨≥…ő™–ßń‹”ŇĽĮĶń“ĽīůŃŃĶ„°£‘ŕ»›∆ų÷ģ…Ō”¶”√≥Ő–Ú»‘–Ť”Ž∂ŗłŲ»›∆ųĻ≤īś£¨…ű÷ŃĽ•ŌŗÕ®–Ň°£
“ÚīňKubernetes°ĘMesos°ĘSwarmĶ»»›∆ųĪŗŇŇ∑ĢőŮĺÕ≥…ő™–¬ ņīķľ‹ĻĻĶń≥Ť∂ý°£
KubernetesłŇńÓľ‹ĻĻ»ÁŌ¬Õľňý ĺ£ļ

‘ŕKubernetesľ‹ĻĻŌ¬,ŐŠĻ©docker»›∆ųÕݬÁ”Ž÷‹∆ŕĻ‹ņŪ°£Õ®ĻżCOE£®Container
Orchestration Engine£©Ļ‹ņŪĶń»›∆ų»ļ£¨≤ĽĶęŌŪ ‹Ī„ņŻ£¨“≤”Ķ”–ŅžňŔĪŗŇŇ”¶”√≥Ő–Úľ‹ĻĻĶń”Ň ∆°£
ĶęÕ®ĻżŌ¬Õľ£®Cloud Native Landscape by Cloud
Native Computing Foundation£©Ņ…“‘»Ō ∂ĶĹ£ļKubernetesĽĻ–Ť“™Ĺ®ŃĘ‘ŕ“ĽłŲŅ…“‘Ńľļ√Ķō≥–‘ō»Áīň∂ŗ—ý–‘∑ĢőŮĶńĽýī¶Ĺ®…Ť£®ľīIaaS£©£¨∂Ý‘ŕÕľ÷–◊ÓĶ◊Ō¬ĶńĽýī°ľ‹ĻĻ£®Infrastructure£©ń„ĽŠ—°‘Ůń«łŲ∆ĹŐ®£Ņ

“‘Ō÷ĹŮĶń‘∆”¶”√£¨Ōŗ–Ň∂ŗ żňĹ”–‘∆ĽŠ—°‘Ů“‘OpenStack◊ųő™Ľýī°ŅÚľ‹£¨Ļę”–‘∆“≤”–≤Ľ…Ŕįłņż Ļ”√OpenStack°£∂Ý‘ŕ—°ļ√ĶńŅÚľ‹…Ō≥–‘ōŌŗ”¶Ķń”¶”√≥Ő–Ú°£
Õ®Ļż…Ō√ś“Ľ∆ūňľŅľ≥ŲĶń◊ťļŌ£¨»ŰłųőĽ“—ĺ≠ žŌ§MagnumŅ™‘īŌÓńŅĽÚ «∆ů“ĶKubernetes≤ķ∆∑£®ņż»ÁESContainer£©£¨∆šŐŠĻ©ń„‘ŕOpenStackľ‹ĻĻ…ŌŌŽ“™ĶńKubernetesŅÚľ‹Ķń∑Ĺ Ĺ°£
ŃŪÕ‚īňľ‹ĻĻ“≤ĽĻ”–ľłłŲ”ŇĶ„Ļ©īůľ“≤őŅľ£ļÕ®Ļżīňľ‹ĻĻŅ…“‘īÔ≥…Kubernetes»ę◊‘∂ĮĽĮĻ‹ņŪ£¨Õ®Ļżīňľ‹ĻĻŅ…“‘ŐŠĻ©ÕÍ’Ż∂ŗ◊‚ĽßŅÚľ‹°£
‘ŕ’‚—ýĶń’ŻŐŚľ‹ĻĻĻśĽģŌ¬£¨Ņ…“‘…Ó»ŽŐ÷¬Ř“‘Ō¬ľłīů÷ōĶ„£ļÕݬÁ°Ę‘ňň„°ĘīĘīś”ŽĪŗŇŇ°£ŌŽĪōīůľ“Õ®Ļż÷ģ«įÕݬÁĶų”ŇĶńł…Ľű£®http://www.easystack.cn/en/technical_share/748/
£©”ŽNUMAŌŗĻōī¶ņŪ∆ųľľ űł…Ľű£®http://www.easystack.cn/en/ technical_share/700/
)“—ĺ≠∂‘◊‘ľļĶńĽ∑ĺ≥ĶńĽýī°ľ‹ĻĻ”–ŌŗĶĪĶńŃňĹ‚£¨…ű÷Ń“—ĺ≠◊Ň ÷ĹÝ––”ŇĽĮ°£
Ĺ”Ō¬ņī’ż «őń’¬ŌŽ“™ÕĽŌ‘Ķń÷ōĶ„£¨»Áļőī”ĪŗŇŇŌ¬ ÷»√OpenStack…ŌĶńKubernetesľ”ňŔ£Ņ»ÁļőĶų”Ň£ŅĶĪń„“—ĺ≠«ß∑ĹįŔľ∆”ŇĽĮŃňń„Ķń”¶”√≥Ő–Ú Ī£¨ĽĻ”–ń«–©∑Ĺ ĹŅ…“‘»√–ßń‹łŁ…Ō“Ľ≤„¬•£Ņ
”ŇĽĮŌÓńŅ-Ķų”ŇĪŗŇŇ
ĪŗŇŇŌÓńŅ∂‘”ŕ‘ŕOpenStackĻĻĹ®»őļő”¶”√≥Ő–Ú∂ľĺŖ”–÷ō“™Ĺ«…ę£¨‘ŕŌ¬Õľ£®MagnumĶńľ‹ĻĻÕľ£©÷–Ņ…“‘ŅīľŻHeat
(ĪŗŇŇ∑ĢőŮ£©∂‘”ŕ’ŻŐŚŃų≥ŐĶń÷ō“™–‘°£Õ®ĻżHeatĹŇĪĺŅ…“‘≤ľ ūľĮ»ļ”Žį≤◊į»őļő”¶”√≥Ő–Ú”ŕľĮ»ļ…Ō°£“Úīň—°‘ŮĶų”ŇHeatĺÝ∂‘ «÷ĶĶ√≤őŅľĶń—°ŌÓ°£

Ķų”Ň1:Ņ™∆Űconvergenceń£ Ĺ
»Űń„ĶńOpenStackĽ∑ĺ≥“—ĺ≠ĶĹŃňMitakaĽÚ «“‘…ŌįśĪĺ°£‘ÚĹ®“ťń„Ĺęconvergenceń£ ĹīÚŅ™£®»ŰįśĪĺő™Newton“‘…ŌįśĪĺ£¨‘§…Ť“—ĺ≠ «Ņ™∆Ű£©°£īÚŅ™∑Ĺ Ĺő™‘ŕ`/etc/heat/heat.conf`ĶĶįłŌ¬ľ”»Ž`convergence_engine
= True`Ķń—°ŌÓ°£
Ņ™∆Űļů∂‘”ŕ≤Ŕ◊ų≤ĽĽŠ”–»őļőłńĪš£¨ Ļ”√’Ŗ»‘Ņ…“‘”√‘≠Ō»Ķń≤Ŕ◊ųń£ Ĺ”ŽĹŇĪĺĹ®ŃĘĪŗŇŇ◊ ‘ī°£‘≠Ō»“—ĺ≠Ĺ®ŃĘĶńĪŗŇŇ◊ ‘ī‘ÚĽŠő¨≥÷‘ŕ∑«Convergenceń£ ĹŌ¬ľŐ–Ý‘ň––°£∂Ý–¬Ĺ®ŃĘĶńĪŗŇŇ◊ ‘ī‘ÚĽŠ“‘Convergenceń£ Ĺő¨‘ň°£
Ō¬Õľő™Ī»ĹŌĹ®ŃĘ100łŲľÚĶ•Ķń◊ ‘ī£¨200łŲľÚĶ•Ķń◊ ‘ī£¨”Ž100łŲłī‘”◊ ‘ī Ī‘ŕConvergenceń£ ĹĽÚ «∑«Convergenceń£ ĹŌ¬Ķń–ßń‹°£Ņ…“‘ĻŘ≤žĶĹ£¨‘Ĺłī‘”Ķń◊ ‘ī‘Ĺ–Ť“™łŁ∂ŗĶń ĪľšņīÕÍ≥…£¨‘Ĺ»›“◊‘ŕConvergenceń£ ĹŌ¬ĽŮĶ√īů∑ýĶńłń…∆°£
”»∆š «’Ž∂‘ŌŮ «KubernetesĶ»–Ť“™Ĺ®ŃĘ∂ŗŐ®Nova Instance
(–ťń‚ĽķĽÚ¬„Ľķ)Ķń◊īŅŲŌ¬£¨Õ®Ļżń£ Ĺ◊™ĽĽ∂ÝĽŮĶ√Ķń–߬ łń…∆ņŪ”¶łŁŌ‘÷Ý(Kubernetes“Ľį„ľ‹ĻĻ Ű”ŕłī‘”∂»ĹŌłŖĶń◊ ‘ī£¨“ÚīňŅ…“‘≤őŅľÕľ÷–łī‘”∂»łŖĶń◊īŅŲĪ»ĹŌĪŪ)°£

≤√ī «Convergenceń£ Ĺ£Ņ
ŐłĶĹ’‚ņÔ£¨”¶ł√”–≤Ľ…ŔŅ™∑Ę’Ŗ∂‘ConvergenceŌŗĶĪńį…ķ°£ ConvergenceĪ»∆ūĺ…ľ‹ĻĻ‘ŕ∑ĢőŮ÷ģľšĶń≤Ó“ž÷Ľ”––¬‘ŲŃň“ĽłŲworker∑ĢőŮ°£Ķę « Ķľ …Ō≥Ő–ÚŃų≥ŐÕÍ»ę≤ĽÕ¨°£»ÁĻŻő“√«»ÁŌ¬÷łŃÓĹ®ŃĘ“ĽłŲKubernetes
»ļľĮ°£

»ÁĻŻ «ĺ…”–Ķńľ‹ĻĻ÷łŃÓĽŠĪĽ◊™ő™API call,‘ŔÕ®ĻżRPCĹĽ”…∆š÷–Ķń“ĽłŲļů∂ňEngine∑ĢőŮ”…Õ∑ĶĹő≤ī¶ņŪ’ŻłŲKubernetes◊ ‘īĹ®ĻĻ°£

Ķę»ÁŌ¬Õľ‘ŕConvergenceń£ ĹŌ¬£¨KubernetesĹŇĪĺĶ÷īÔļů∂ň∑ĢőŮ£®Engine£© Ī£¨ĽŠ“ņ’’◊ ‘īŃĘŅŐĪĽ∑÷≥…Ķ•“ĽĻ§◊ų£¨ĹĽł∂łÝ∆šňŻļů∂ň∑ĢőŮ≤Ę––÷ī––°£
“≤ĺÕ «ňĶ£¨»Űļů∂ň∑ĢőŮ żŃŅ‘ –Ū£¨ňý”–ĶńKubernetes master”Žminion∂ľŅ…“‘≤Ę––‘ň––‘ŕ∂ņŃĘĶńļů∂ň∑ĢőŮ£¨≤Ę«“÷Ľ–Ť“™ń„Ľ®∑—≤Ņ ū“ĽŐ®ĹŕĶ„Ķń Īľš£¨ĺÕŅ…“‘Ĺę’ŻłŲľĮ»ļ∂ľĹ®÷√ÕÍĪŌ°£
Ļż≥Ő÷–Heat∑ĢőŮĽŠ‘ŕ żĺ›Ņ‚÷–Ĺ®ŃĘ“Ľ’ŇĹ–◊ŲSyncpointĶńĪŪ£¨”√ņī»∑»Ō”Ž»°Ķ√≤Ŕ◊ųĶń»®Ōř°£≤Ę«“īś»Ž◊ ‘īŌŗ“ņ–‘ĶńѨŊ żĺ›“‘Ī£÷§”–◊ ‘īīīĹ®Ńų≥Ő£®ŌŮ «»∑Ī£Cinder
VolumeĻ“‘ō≤Ŕ◊ų£¨Īō–Ž‘ŕNovaĹęKubernetesĹŕĶ„”ŽCinder VolumeīīĹ®≥Ųņīļů≤Ňń‹÷ī––£©°£

Ķų”Ň2:Ķų’Ż`num_engine_workers`
Engine worker żŃŅĶų’Ż£¨÷łĶńĺÕ «ő“√«‘ŕĶų”Ň1 ĪŐŠľįĶńļů∂ň∑ĢőŮ żŃŅ°£Õ®ĻżŌ¬Õľľ‹ĻĻŅ…“‘ŅīĶĹ£¨ĶĪAPI∑ĢőŮ ’ĶĹ«Ž«ů£¨≤ĘÕ®ĻżRPCÕýļů∑ĹīęňÕ Ī£¨ «‘ŕ∂ŗłŲEngine
worker÷–£¨”…«ņŌ»Ĺ” ’ĶĹ’Ŗ£¨◊ųő™ī¶ņŪł√«Ž«ůĶńļů∂ň°£

∂Ý’‚łŲĶų”Ň…Ť∂®Ņ…“‘”√ņīĺŲ∂®√Ņ“ĽłŲ ĶŐŚĶńHeatļů∂ňĹŕĶ„…Ō“™Ň‹ľłłŲļů∂ň∑ĢőŮ≥Ő–Ú°£»Á»ŰĽ∑ĺ≥£®‘ŕ`/etc/heat/heat.conf`őńľĢ£©…–őī…Ť∂®īň≤ő ż£¨‘§…Ť «įī’’CPU żŃŅņīĶų’ŻĶ•“ĽĹŕĶ„…ŌHeatĶń∑ĢőŮ≥Ő–Ú żŃŅ°£
Ķę «◊Ę“‚ĶĹ£¨»Űń„ĶńĶÁń‘ő™HPC ĪĹ®“ťĹę żŃŅĶųłŖ£¨“Úő™ń„”Ķ”–ĹŌő™«ŅīůĶńÕݬÁ°Ę‘ňň„°Ę”ŽīĘīś◊ ‘ī£¨Ņ…“‘≥Ę ‘”…1:1.5£®cpu:num_engine_workers£©Ņ™ ľ≤‚ ‘–ßń‹£¨‘ŕÕý…ŌĶų’Ż£¨÷ĪĶĹń„ĶńKubernetesľĮ»ļĶń≤ľ ū–ßń‹īÔĶĹ∂•∑Ś°£
Ōŗ∂‘Ķō£¨»Űń„ĶńCPU żŃŅĻż∂ŗ£¨∆šňŻ≤Ņ∑÷Ķń◊ ‘ī≤ĘőīĻśĽģő™łŖ–ßń‹◊īŅŲ£®Ņ…ń‹∑Ę…ķ‘ŕ”√ņīŐŠĻ©‘ňň„ĶńĹŕĶ„…Ō£©£¨Ĺ®“ť≥Ę ‘1.25:1£®cpu:num_engine_workers£©Ņ™ ľ≤‚ ‘–ßń‹£¨≤ĘÕýŌ¬Ķų’Ż£®num_engine_workers żŃŅ£©£¨÷ĪĶĹń„ĶńĽ∑ĺ≥»°Ķ√łŁļ√Ķń’ŻŐŚ–ßń‹°£
◊Ę“‚ĶĹĶ•“ĽĹŕĶ„…ŌĶńĪŗŇŇ∑ĢőŮ≥Ő–Ú żŃŅ£¨≤Ę≤ĽĶ»”ŕ∂ŗĹŕĶ„…ŌĶń’ŻļŌ°£“ÚīňĶų’ŻĶĹ ĶĪĶń żŃŅ£¨“≤Ķ»Õ¨”ŕŐŠĻ©∆šňŻ≥Ő–Ú£®RPC°Ę żĺ›Ņ‚°Ę∆šňŻ∑ĢőŮ≥Ő–Ú£©łŁ∂ŗ◊ ‘īĶń Ļ”√Ņ’ľš°£
”»∆š «ŌŮ≤ľ ūKubernetesĽ∑ĺ≥£¨ĹęĽŠÕ¨ ĪĶų”√CinderĻ‹ņŪīĘīś£¨ NeutronĻ‹ņŪÕݬÁNovaĻ‹ņŪ–ťĽķĽÚ¬„Ľķ°£“Úīň◊ ‘ī∑÷ŇšłŁ”¶ł√őĘĶų“‘ĽŮ»°łŁļ√Ķń’ŻŐŚ–ßń‹°£
Ķų”Ň3:Ņ™∆ŰłŖňŔĽļīś
∂ŗ żĶńOpenStack∑ĢőŮ∂ľĺŖ”–“Ľ∂® żŃŅĶńĽļīśĽķ÷∆£¨»ŰńŕīśŅ’ľš‘ –ŪĹ®“ťŐŰ—°≤Ņ∑÷∑ĢőŮ£®Ī»»ÁĪŗŇŇ∑ĢőŮ£©Ņ™∆ŰĽļīśĽķ÷∆£¨Ņ™∆Ű∑Ĺ Ĺő™ĹęĽļīś…Ť∂®–ī»Žheat.confńŕ°£
÷Ń”ŕ–ī»Ž—°ŌÓŅ…≤őŅľÕÝ’ĺ£ļhttps:// docs .openstack.org/developer/oslo.cache/opts.html
°£»ŰőřŐōĪūŌŽ…Ť∂®Ķń≤ő ż£¨Ņ…“‘÷ĪĹ”‘ŕ[cache]Ō¬–¬‘Ųenabled=TrueľīŅ…°£
÷Ń”ŕő™ ≤√ī‘ŕīňŐōĪūŐŠľįīň…Ť∂®£¨“Úő™ĶĪń„“™≤ľ ūĽÚ «ņ©’Ļń„ĶńKubernetesľĮ»ļ Ī£¨‘ŕ◊ ‘īĪŗŇŇ…Ō∂ľĽŠ «“‘◊ ‘ī»ļ◊ťő™Ķ•őĽ£¨Ī»»ÁňĶ“™‘Ŕņ©’Ļ≥Ų–¬Ķń50Ő®Kubernetes
minionĹŕĶ„°£
‘ŕ◊ ‘īĪŗŇŇ Ī£¨’‚50Ő® Ű”ŕÕ¨“ĽKubernetesī‘ľĮĶńminionĹŕĶ„Ĺ꼊ĪĽ ”ő™Õ¨“ĽłŲ◊ ‘ī»ļľĮ£¨≤Ę‘ŕĪŗŇŇ Ī“ĽÕ¨ī¶ņŪ°£“Úīň»Űń‹ĹęłŖňŔĽļīśŅ™∆Ű£¨‘ŕ’‚įłņż…ŌĺÕŅ…“‘÷ĪĹ”Ĺŕ °49īőĶ»Õ¨”ŕ98%Ķń≤Ņ∑÷≤Ŕ◊ų°£
ńŅ«į‘ŕĪŗŇŇ∑ĢőŮńŕ£¨“‘Ō¬ľłłŲ÷ų“™Ľ∑Ĺŕ“—ĺ≠…Ť”–Ņž»°Ľķ÷∆£¨įŁļ¨Stack–ŇŌĘ żĺ›£¨Resource–ŇŌĘ żĺ›£¨Constraint żĺ›£®Õ®ĻżļŰĹ–∆šňŻŌÓńŅCLI“‘»Ō÷§≤Ņ∑÷≤ő ż°£ņż»ÁĶĪK8S
master≤ő ż”–Floating ip Ī£¨ConstraintĺÕĽŠÕ®ĻżNeutron CLI’“—įFloating
ip żĺ›◊ųő™≤ő ż»Ō÷§“ņĺ›£©Ķ»°£
Ķų”Ň4:‘ –ŪOpenStack÷ĪĹ”≤Ŕ◊ųKubernetes
‘ŕ Ķľ Ļ”√Kubernetes Ī£¨–Ū∂ŗ ĪļÚ–Ť“™ŃŔ ĪĽÚ“Ľīő–‘ĪšłŁ∂ŗłŲ KubernetesľĮ»ļ£¨ĽÚ «∂‘Ķ•“ĽłŲīů–ÕĶńKubernetesľĮ»ļĹÝ––∂ŗīő≤Ŕ◊ųĽÚłī‘”≤Ŕ◊ų£¨∆š Ķ“≤Ņ…“‘ń…»ŽOpenStackĻ‹ņŪ∑∂őß◊ų“Ľīő–‘≤Ŕ◊ų£¨ĹÝ∂ÝÕÍ≥…ňý”–»őőŮ°£
‘ŕĪŗŇŇ∑ĢőŮ÷–”–ń‹į≤◊į”ŽĻ‹ņŪ”¶”√≥Ő–ÚĶńń‹Ń¶£¨‘ŕŐŠĻ©ĺĶŌŮ Ī£¨÷Ľ–Ť“™‘ŕņÔ√ś∂ŗľ”»Žkubelet hookĺÕŅ…“‘Ńň°£ļů–Ý÷Ľ–ŤÕ®ĻżłŁłńĪŗŇŇĹŇĪĺľīŅ…ĹÝ––≤Ŕ◊ų°£
∂‘”ŕ≤Ľ÷™Ķņhook « ≤√īĶń∂Ń’Ŗ£¨Ņ…“‘ņŪĹ‚ĽýĪĺ…ŌňŁĺÕ «“ĽłŲ‘ŕos-collect-config–≠÷ķĹęőńľĢ(ņż»ÁyamlőńľĢ)◊™»ŽKubernetesĹŕĶ„…Ō÷ģļů£¨Õ®ĻżĹŕĶ„…Ōkubelet÷łŃÓ÷ī––≤Ŕ◊ų°£Ńų≥Ő»ÁŌ¬Õľňý ĺ£ļ

ĶĪń„ľ∆ĽģŅ™∑ĘKubernetes◊‘∂ĮĽĮĻ‹ņŪ Ī£¨≥żŃňĹękubelet hookľ”»ŽĺĶŌŮńŕ£¨“≤“™◊Ę“‚ĶĹkubelet÷ī––ļů£¨Īō–Ž“™ń‹ĻĽ∑ĘňÕŌŻŌĘłÝHeatĽÚZaqarĶ»Ķ»£®Ņīń„‘ŕĪŗŇŇĹŇĪĺ◊ę–ī ĪĶń…Ť∂®£©£¨“Úīň«ŽőŮĪōīÚŅ™≤Ņ∑÷∑ņĽū«Ĺ…Ť∂®£®ŌŮ «80ĽÚ8080Ķ»Ķ»£©‘ –ŪŌŻŌĘ∑ĘňÕ°£
HeatĶń◊‘∂ĮĽĮ»ŪľĢ≤ľ ū”Ž…Ť∂®£¨Õ®ĻżÕ¨“ĽłŲ”√ņī…Ť∂®K8SĶńĹŇĪĺľīŅ……Ť∂®ŌŗĻō◊ ‘ī°£»ÁĻŻń„ŌŽ“™Ĺę»ŪľĢ≤ľ ūľ”»Žń„ĶńK8SĹŇĪĺ÷–£¨Ņ…“‘≤őŅľ“‘Ō¬ĹŇĪĺ∆¨∂ő°£
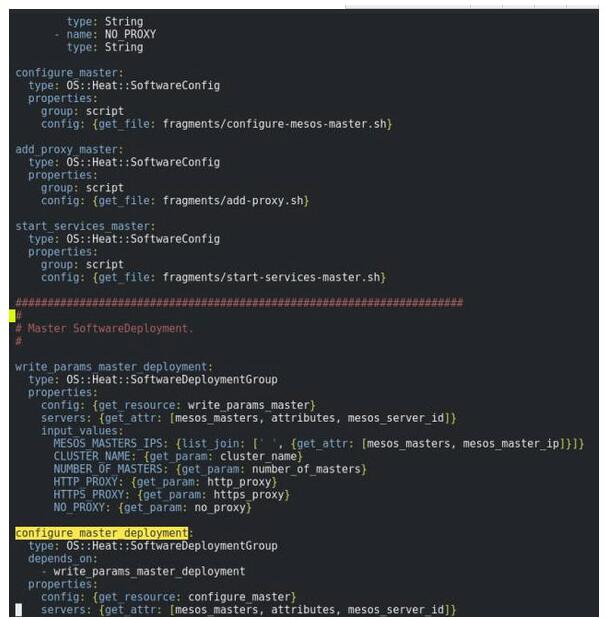
ĶĪ÷–`configure_master_deployment`ĺÕ «Ņ…“‘ĹęĶ•“Ľ≤ľ ūĹŇĪ唶”√”ŕ∂ŗłŲĹŕĶ„…ŌĶń`OS::Heat::SoftwareDeploymentGroup`◊ ‘ī°£
∆šĻ§◊ųĽŠĹę`OS::Heat::SoftwareConfig`÷–…Ť∂®ĶńĹŇĪ唎ĹŇĪĺ–őŐ¨£®Ansible,
script, Puppet, Kubelet, etc.£©Õ®ĻżK8SĹŕĶ„£®ń„ĶńOS::Nova::Server◊ ‘ī£©÷–Ķńos
-collect-configĹęĹŇĪĺ–ŇŌĘņ≠ĹÝĹŕĶ„÷–£®īňő™ňś ĪľŗŐż∂Į◊ų£¨Ņ…“‘Ķų’ŻľŗŐż«Ýľš£¨‘§…Ťő™30√Ž£©£¨‘ŔÕ®ĻżKubelet
hookļŰĹ–Kubelet÷łŃÓ£¨÷ī––ĹŇĪĺ°£
»őļő÷ī––ĹŠĻŻĽÚ «īŪőů◊īŅŲ°£∂ľĽŠÕ®ĻżŌŻŌĘĽōīęłÝHeat∑ĢőŮ°£ŃŪÕ‚”–Ļō”ŕŌÍŌłkubelet
hook–ŇŌĘŅ…“‘≤őŅľ£ļhttps : // github . com / openstack / heat-agents
/ tree / master / heat - config - kubelet °£
‘ŕĪŗŇŇĹŇĪĺ…Ōľ”»Ž£ļ

...ľīŅ…“‘≤Ŕ◊ųkubelet £¨ń„“≤Ņ…“‘Ĺęcofig≤Ņ∑÷ĽĽ≥…yamlőńľĢ š»Ž°£÷Ń”ŕ‘ŕĪŗŇŇĹŇĪĺ…ŌÕÍ’ŻĶń Ļ”√∑Ĺ Ĺ£¨Ņ…“‘≤őŅľhttps
: // github . com / openstack / heat - templates /
blob / master / hot / software - config / example
- templates / example - kubele - template . yaml
Ķų”Ň5 :Ķų”ŇĺĶŌŮ
∂‘”ŕKubernetesĶń”Ň ∆÷ģ“ĽľīĹę∑ĢőŮ∂ľ◊™ĹÝ»›∆ųńŕ÷ī––£¨»Ľ∂ÝńŅ«į–Ū∂ŗīů–ÕĽ∑ĺ≥“ŇÕŁŃň”¶ł√Ĺ®÷∆
Kubernetes ĶńĺĶŌٔҼĮ°£ńŅ«į”–ľłľ“÷™√ŻĶńŇ∑÷řīů–Õ—–ĺŅĽķĻĻ£¨ĺÕ‘ŕ∂‘ňŻ√« OpenStack
‘∆…ŌĶń Kubernetes £¨ĹÝ––’‚ŌӔҼĮ°£
”ŇĽĮ∑ĹŌÚ”–2£ļ
1. Őśīķ‘≠Ō» Ļ”√ĶńĺĶŌŮ£¨Ĺ곣 ļŌ»›∆ųĶń–°–ÕĺĶŌŮ◊ųő™’ŻŐŚĹ®÷√—°‘Ů°£
2.Ĺę…Ō√śŐŠľįĪŗŇŇ Īňý–Ť“™Ķńhooksľ”»Ž”≥ŌŮĶĶ°£‘ŕīňŐŠĻ©ŌŗĻōĶń Dockerfile
◊ųő™≤őŅľ°£
(https : // github . com / openstack
/ tripleo - common / blob / master / heat _ docker
_ agent / Dockerfile )
◊‹ĹŠ
Õ®ĻżĹę…Ō√ś5ŌÓĶų”Ň£®Ķų”Ň1:Ņ™∆Űconvergenceń£ Ĺ£ĽĶų”Ň2:Ķų’Ż`num_engine_workers`£ĽĶų”Ň3:Ņ™∆ŰłŖňŔĽļīś£ĽĶų”Ň4:‘ –ŪOpenStack÷ĪĹ”≤Ŕ◊ųKubernetes£ĽĶų”Ň5:Ķų”ŇĺĶŌŮ£©”¶”√ĶĹń„ĶńK8SĽ∑ĺ≥÷–£¨‘ŕ÷ī––≤ľ ūĽÚņ©’Ļ£®ĽÚňűĪŗ£© Ī£¨ĽŠ≤ķ…ķ√ųŌ‘Ķń–ßń‹łń…∆°£
ĶĪK8S≤ľ ūŌ¬»•ļů£¨ ĶŐŚÕݬÁĶų’ŻĪšĶ√∑«≥£ņßń—°£»Űń„—°‘Ů‘ň”√OpenStackĪŗŇŇĻ‹ņŪ£¨‘ŕ»őļőĽ∑ĺ≥÷–łńĪšĹŕĶ„–ŇŌĘ£¨įŁļ¨ÕݬÁ£¨»ļľĮ ĶŐŚŇš÷√£¨īĘīśĶ»Ķ»ĺÕĽŠĪš≥…łŁő™ľÚĶ•Ķń≤Ŕ◊ų°£
ń„“≤Ņ…“‘Õ®Ļż◊®√Ňłļ‘ū◊ ‘īĻ‹ņŪĶńĪŗŇŇ∑ĢőŮ£¨«ŅĽĮ◊ ‘ī≤ľ ū–ßń‹°£“Úő™ń„ĺÝ∂‘≤ĽŅ…ń‹Ĺęń„Ķń‘ň”™÷–Ķń»›∆ųĽĮ”¶”√≥Ő–Ú≤ľ ū‘ŕ÷Ľ”–“ĽłŲĶ•“ĽĹŕĶ„ĶńK8S£¨ń„łŁ≤ĽŌ£ÕŻ“Úő™»őļő»ň‘Ī≤Ŕ◊ų Ī–řłń“Ҭ©£¨Ķľ÷¬’ŻłŲ»ļľĮÕ£÷Ļ∑ĢőŮ°£Õ®ĻżĪŗŇŇĺÕĪš≥… «łŲĹŌő™∑ŻļŌ◊‘∂ĮĽĮńŅĪÍĶń—°ŌÓ°£
≥żŃň…Ō√ś5ŌÓĹ®“ťÕ‚£¨“≤ĻńņÝń„Ĺęń„Ķńő Ő‚°ĘŌŽ∑®°ĘĹ‚∑®°ĘĽÚ «∆šňŻ»őļőįÔ÷ķ∑ĘĶĹ…Á«Ý…ŌĽÚ «Ń™ŌĶő“√«£¨”……Á«Ý◊ųő™‘īÕ∑£¨ő“√«”–ń‹Ń¶÷ĪĹ”łńĪš‘īÕ∑“‘ľŐ–Ý«ŅĽĮKubernetes”ŽOpenStackĶń’ŻļŌ”Ž”ŇĽĮ£¨ő“√«Ň¨Ń¶Ĺę‘īÕ∑ľľ ű”ŇĽĮŃň£¨≤Ľĺ√“Ľ∂®≤ķ…ķłŁ∂ŗĶń”ŇĽĮ—°ŌÓ°£◊Óļů ‹Ľ›Ķń£¨Ōŗ–ŇĺÕ «ń„’ż‘ŕ‘ň”™ĶńĽ∑ĺ≥°£
|








