ДђПЊетЦЊЮФеТЕФЭЌбЇЃЌЯыБиЖд
docker ЖМВЛЛсФАЩњЁЃdocker ЪЧвЛжжащФтШнЦїММЪѕЃЌЫќЩЯЪжБШНЯМђЕЅЃЌжЛашдкЫожїЛњЩЯЦ№вЛИі docker
engineЃЌШЛКѓОЭФмгфПьЕФЭцЫЃСЫЃЌШчЃКРОЕЯёЁЂЦ№ШнЦїЁЂЙвдиЪ§ОнЁЂгГЩфЖЫПкЕШЕШЁЃЯрЖдгк KubernetesЃЈK8SЃЉЕФЩЯЪжЃЌПЩЮНМђЕЅКмЖрЁЃ
ФЧУД K8S ЪЧЪВУДЃЌгжЮЊЪВУДЩЯЪжФбЖШДѓЃПK8S ЪЧвЛИіЛљгкШнЦїММЪѕЕФЗжВМЪНМЏШКЙмРэЯЕЭГЃЌЪЧЙШИшМИЪЎФъРДДѓЙцФЃгІгУШнЦїММЪѕЕФОбщЛ§РлКЭЩ§ЛЊЕФвЛИіживЊГЩЙћЁЃЫљвдЮЊСЫФмЙЛжЇГжДѓЙцФЃЕФМЏШКЙмРэЃЌЫќГадиСЫКмЖрЕФзщМўЃЌЖјЧвЗжВМЪНБОЩэЕФИДдгЖШОЭКмИпЁЃгжвђЮЊ
K8S ЪЧЙШИшГіЦЗЕФЃЌвРРЕСЫКмЖрЙШИшздМКЕФОЕЯёЃЌЫљвдЖдгкЙњФкЕФЭЌбЇЛЗОГДюНЈЕФФбЖШгждіМгСЫвЛВуЁЃ
ЯТУцЃЌЮвУЧДјзХЮЪЬтЃЌвЛВНВНРДПД K8S жаЕНЕзгаФФаЉЖЋЮїЃП
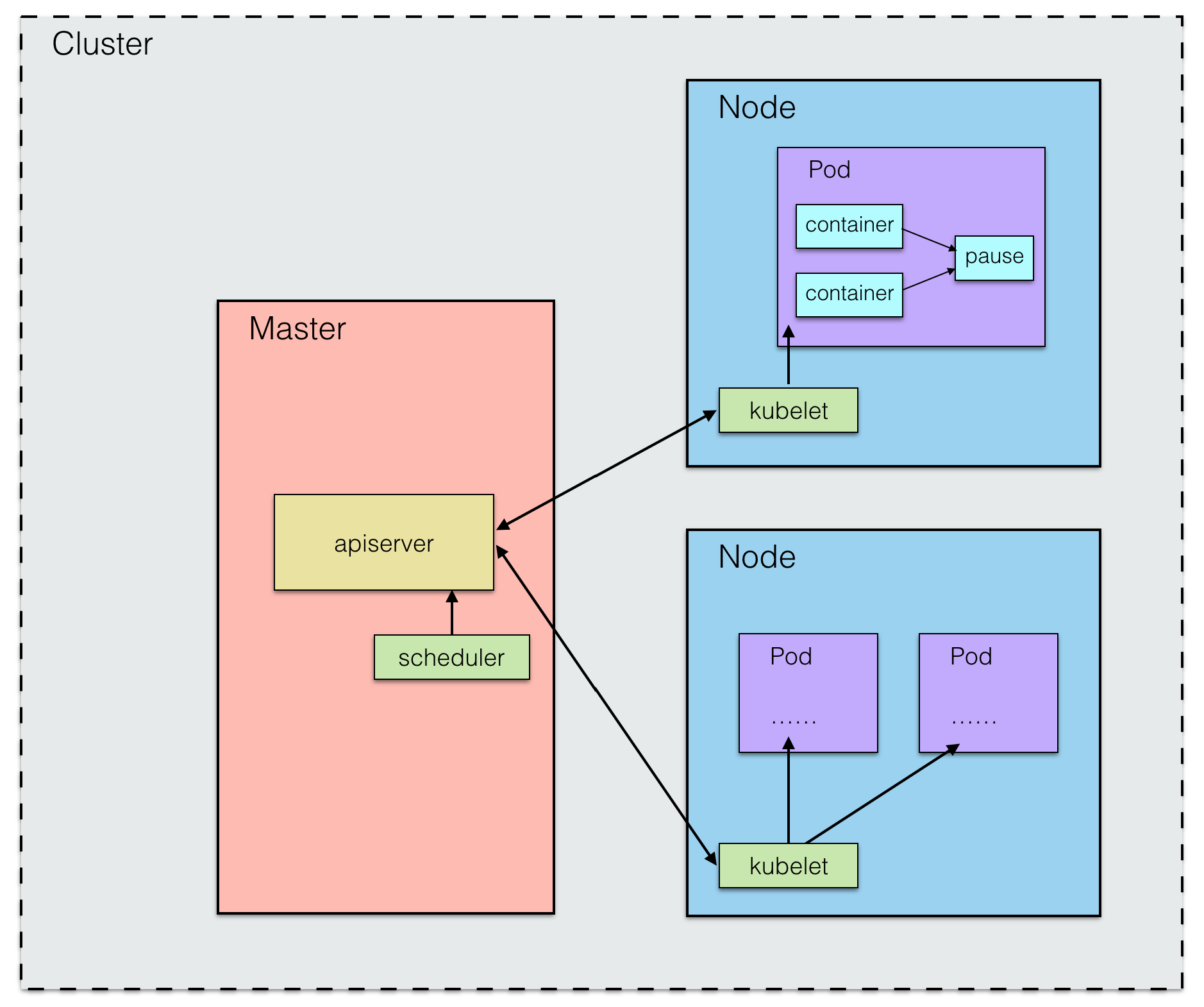
ЪзЯШЃЌМШШЛЪЧИіЗжВМЪНЯЕЭГЃЌФЧЪЦБигаЖрИі Node НкЕуЃЈЮяРэжїЛњЛђащФтЛњЃЉЃЌЫќУЧЙВЭЌзщГЩвЛИіЗжВМЪНМЏШКЃЌВЂЧветаЉНкЕужаЛсгавЛИі
Master НкЕуЃЌгЩЫќРДЭГвЛЙмРэ Node НкЕуЁЃ
ШчЭМЫљЪОЃК

ЮЪЬтвЛЃКжїНкЕуКЭЙЄзїНкЕуЪЧШчКЮЭЈаХЕФФиЃП
ЪзЯШЃЌMaster НкЕуЦєЖЏЪБЃЌЛсдЫаавЛИі kube-apiserver НјГЬЃЌЫќЬсЙЉСЫМЏШКЙмРэЕФ
API НгПкЃЌЪЧМЏШКФкИїИіЙІФмФЃПщжЎМфЪ§ОнНЛЛЅКЭЭЈаХЕФжааФЪрХІЃЌВЂЧвЫќвГЬсЙЉСЫЭъБИЕФМЏШКАВШЋЛњжЦЃЈКѓУцЛЙЛсНВЕНЃЉЁЃ
дк Node НкЕуЩЯЃЌЪЙгУ K8S жаЕФ kubelet зщМўЃЌдкУПИі Node НкЕуЩЯЖМЛсдЫаавЛИі
kubelet НјГЬЃЌЫќИКд№Яђ Master ЛуБЈздЩэНкЕуЕФдЫааЧщПіЃЌШч Node НкЕуЕФзЂВсЁЂжежЙЁЂЖЈЪБЩЯБЈНЁПЕзДПіЕШЃЌвдМАНгЪе
Master ЗЂГіЕФУќСюЃЌДДНЈЯргІ PodЁЃ
дк K8S жаЃЌPod ЪЧзюЛљБОЕФВйзїЕЅдЊЃЌЫќгы docker ЕФШнЦїгаТдЮЂЕФВЛЭЌЃЌвђЮЊ Pod
ПЩФмАќКЌвЛИіЛђЖрИіШнЦїЃЈПЩвдЪЧ docker ШнЦїЃЉЃЌетаЉФкВПЕФШнЦїЪЧЙВЯэЭјТчзЪдДЕФЃЌМДПЩвдЭЈЙ§ localhost
НјааЯрЛЅЗУЮЪЁЃ
Йигк Pod ФкЪЧШчКЮзіЕНЭјТчЙВЯэЕФЃЌУПИі Pod ЦєЖЏЃЌФкВПЖМЛсЦєЖЏвЛИі pause ШнЦїЃЈgoogleЕФвЛИіОЕЯёЃЉЃЌЫќЪЙгУФЌШЯЕФЭјТчФЃЪНЃЌЖјЦфЫћШнЦїЕФЭјТчЖМЩшжУИјЫќЃЌвдДЫРДЭъГЩЭјТчЕФЙВЯэЮЪЬтЁЃ
ШчЭМЫљЪОЃК

ЮЪЬтЖўЃКMaster ЪЧШчКЮНЋ Pod ЕїЖШЕНжИЖЈЕФ Node ЩЯЕФЃП
ИУЙЄзїгЩ kube-scheduler РДЭъГЩЃЌећИіЕїЖШЙ§ГЬЭЈЙ§жДаавЛаЉСаИДдгЕФЫуЗЈзюжеЮЊУПИі Pod
МЦЫуГівЛИізюМбЕФФПБъ NodeЃЌИУЙ§ГЬгЩ kube-scheduler НјГЬздЖЏЭъГЩЁЃГЃМћЕФгаТжбЏЕїЖШЃЈRRЃЉЁЃЕБШЛвВгаПЩФмЃЌЮвУЧашвЊНЋ
Pod ЕїЖШЕНвЛИіжИЖЈЕФ Node ЩЯЃЌЮвУЧПЩвдЭЈЙ§НкЕуЕФБъЧЉЃЈLabelЃЉКЭ Pod ЕФ nodeSelector
ЪєадЕФЯрЛЅЦЅХфЃЌРДДяЕНжИЖЈЕФаЇЙћЁЃ
ШчЭМЫљЪОЃК
ЙигкБъЧЉЃЈLabelЃЉгыбЁдёЦїЃЈSelectorЃЉЕФИХФюЃЌКѓУцЛсНјвЛВННщЩм
ЮЪЬтШ§ЃКИїНкЕуЁЂPod ЕФаХЯЂЖМЪЧЭГвЛЮЌЛЄдкФФРяЕФЃЌгЩЫРДЮЌЛЄЃП
ДгЩЯУцЕФ Pod ЕїЖШЕФНЧЖШПДЃЌЮвУЧЕУгавЛИіДцДЂжааФЃЌгУРДДцДЂИїНкЕузЪдДЪЙгУЧщПіЁЂНЁПЕзДЬЌЁЂвдМАИї
Pod ЕФЛљБОаХЯЂЕШЃЌетбљ Pod ЕФЕїЖШРДФме§ГЃНјааЁЃ
дк K8S жаЃЌВЩгУ etcd зщМў зїЮЊвЛИіИпПЩгУЧПвЛжТадЕФДцДЂВжПтЃЌИУзщМўПЩвдФкжУдк K8S
жаЃЌвВПЩвдЭтВПДюНЈЙЉ K8S ЪЙгУЁЃ
МЏШКЩЯЕФЫљгаХфжУаХЯЂЖМДцДЂдкСЫ etcdЃЌЮЊСЫПМТЧИїИізщМўЕФЯрЖдЖРСЂЃЌвдМАећЬхЕФЮЌЛЄадЃЌЖдгкетаЉДцДЂЪ§ОнЕФдіЁЂЩОЁЂИФЁЂВщЃЌЭГвЛгЩ
kube-apiserver РДНјааЕїгУЃЌapiserver вВЬсЙЉСЫ REST ЕФжЇГжЃЌВЛНіЖдИїИіФкВПзщМўЬсЙЉЗўЮёЭтЃЌЛЙЖдМЏШКЭтВПгУЛЇБЉТЖЗўЮёЁЃ
ЭтВПгУЛЇПЩвдЭЈЙ§ REST НгПкЃЌЛђеп kubectl УќСюааЙЄОпНјааМЏШКЙмРэЃЌЦфФкдкЖМЪЧгы apiserver
НјааЭЈаХЁЃ
ШчЭМЫљЪОЃК

ЮЪЬтЫФЃКЭтВПгУЛЇШчКЮЗУЮЪМЏШКФкдЫааЕФ Pod ЃП
ЧАУцНВСЫЭтВПгУЛЇШчКЮЙмРэ K8SЃЌЖјЮвУЧИќЙиаФЕФЪЧФкВПдЫааЕФ Pod ШчКЮЖдЭтЗУЮЪЁЃЪЙгУЙ§ docker
ЕФЭЌбЇгІИУжЊЕРЃЌШчЙћЪЙгУ bridge ФЃЪНЃЌдкШнЦїДДНЈЪБЃЌЖМЛсЗжХфвЛИіащФт IPЃЌИУ IP ЭтВПЪЧУЛЗЈЗУЮЪЕНЕФЃЌЮвУЧашвЊзівЛВуЖЫПкгГЩфЃЌНЋШнЦїФкЖЫПкгыЫожїЛњЖЫПкНјаагГЩфАѓЖЈЃЌетбљЭтВПЭЈЙ§ЗУЮЪЫожїЛњЕФжИЖЈЖЫПкЃЌОЭПЩвдЗУЮЪЕНФкВПШнЦїЖЫПкСЫЁЃ
ФЧУДЃЌK8S ЕФЭтВПЗУЮЪЪЧЗёвВЪЧетбљЪЕЯжЕФЃПД№АИЪЧЗёЖЈЕФЃЌK8S жаЧщПівЊИДдгвЛаЉЁЃвђЮЊЩЯУцНВЕФ
docker ЪЧЕЅЛњФЃЪНЯТЕФЃЌЖјЧввЛИіШнЦїЖдЭтОЭБЉТЖвЛИіЗўЮёЁЃдкЗжВМЪНМЏШКЯТЃЌвЛИіЗўЮёЭљЭљгЩЖрИі Application
ЬсЙЉЃЌгУРДЗжЕЃЗУЮЪбЙСІЃЌЖјЧветаЉ Application ПЩФмЛсЗжВМдкЖрИіНкЕуЩЯЃЌетбљгжЩцМАЕНСЫПчжїЛњЕФЭЈаХЁЃ
етРяЃЌK8S в§ШыСЫ service ЕФИХФюЃЌНЋЖрИіЯрЭЌЕФ Pod АќзАГЩвЛИіЭъећЕФ service
ЖдЭтЬсЙЉЗўЮёЃЌжСгкЛёШЁЕНетаЉЯрЭЌЕФ PodЃЌУПИі Pod ЦєЖЏЪБЖМЛсЩшжУ labels ЪєадЃЌдк service
жаЮвУЧЭЈЙ§бЁдёЦї selectorЃЌбЁдёОпгаЯрЭЌ name БъЧЉЪєадЕФ PodЃЌзїЮЊећЬхЗўЮёЃЌВЂНЋЗўЮёаХЯЂЭЈЙ§
apiserver ДцШы etcd жаЃЌИУЙЄзїгЩ Service Controller РДЭъГЩЁЃЭЌЪБЃЌУПИіНкЕуЩЯЛсЦєЖЏвЛИі
kube-proxy НјГЬЃЌгЩЫќРДИКд№ЗўЮёЕижЗЕН Pod ЕижЗЕФДњРэвдМАИКдиОљКтЕШЙЄзїЁЃ
ШчЭМЫљЪОЃК

ЮЪЬтЮхЃКPod ШчКЮЖЏЬЌРЉШнКЭЫѕЗХЃП
МШШЛжЊЕРСЫЗўЮёЪЧгЩ Pod зщГЩЕФЃЌФЧУДЗўЮёЕФРЉШнвВОЭвтЮЖзХ Pod ЕФРЉШнЁЃЭЈЫзЕуНВЃЌОЭЪЧдкашвЊЪБНЋ
Pod ИДжЦЖрЗнЃЌдкВЛашвЊКѓЃЌНЋ Pod ЫѕМѕжСжИЖЈЗнЪ§ЁЃK8S жаЭЈЙ§ Replication Controller
РДНјааЙмРэЃЌЮЊУПИі Pod ЩшжУвЛИіЦкЭћЕФИББОЪ§ЃЌЕБЪЕМЪИББОЪ§гыЦкЭћВЛЗћЪБЃЌОЭЖЏЬЌЕФНјааЪ§СПЕїећЃЌвдДяЕНЦкЭћжЕЁЃЦкЭћЪ§жЕПЩвдгЩЮвУЧЪжЖЏИќаТЃЌЛђздЖЏРЉШнДњРэРДЭъГЩЁЃ
ШчЭМЫљЪОЃК

ЮЪЬтСљЃКИїИізщМўжЎМфЪЧШчКЮЯрЛЅазїЕФЃП
зюКѓЃЌНВвЛЯТ kube-controller-manager етИіНјГЬЕФзїгУЁЃЮвУЧжЊЕРСЫ ectd
ЪЧзїЮЊМЏШКЪ§ОнЕФДцДЂжааФЃЌ apiserver ЪЧЙмРэЪ§ОнжааФЃЌзїЮЊЦфЫћНјГЬгыЪ§ОнжааФЭЈаХЕФЧХСКЁЃЖј
Service ControllerЁЂReplication Controller етаЉЭГвЛНЛгЩ kube-controller-manager
РДЙмРэЃЌkube-controller-manager зїЮЊвЛИіЪиЛЄНјГЬЃЌУПИі Controller
ЖМЪЧвЛИіПижЦбЛЗЃЌЭЈЙ§ apiserver МрЪгМЏШКЕФЙВЯэзДЬЌЃЌВЂГЂЪдНЋЪЕМЪзДЬЌгыЦкЭћВЛЗћЕФНјааИФБфЁЃЙигк
ControllerЃЌmanager жаЛЙАќКЌСЫ Node НкЕуПижЦЦїЃЈNode ControllerЃЉЁЂзЪдДХфЖюЙмПижЦЦїЃЈResourceQuota
ControllerЃЉЁЂУќУћПеМфПижЦЦїЃЈNamespace ControllerЃЉЕШЁЃ
ШчЭМЫљЪОЃК

змНс
БОЮФЭЈЙ§ЮЪД№ЕФЗНЪНЃЌУЛгаЩцМАШЮКЮЩюШыЕФЪЕЯжЯИНкЃЌДгећЬхЕФНЧЖШЃЌИХФюадЕФНщЩмСЫ K8S жаЩцМАЕФЛљБОИХФюЃЌЦфжаЪЙгУЯрЙиЕФАќРЈгаЃК
1.Node
2.Pod
3.Label
4.Selector
5.Replication Controller
6.Service Controller
7.ResourceQuota Controller
8.Namespace Controller
9.Node Controller
вдМАдЫааНјГЬЯрЙиЕФгаЃК
1.kube-apiserver
2.kube-controller-manager
3.kube-scheduler
4.kubelet
5.kube-proxy
6.pause
|








