本文试图将Kubernetes的基础相关知识描述清楚,让一个从来没有Kubernetes实践的开发人员,能够非常容易地理解Kubernetes是什么,能够做哪些事情,以及使用它能带来的好处是什么。
Kubernetes是什么
Kubernetes是一个开源的容器编排引擎,它支持自动化部署、大规模可伸缩、应用容器化管理。我们在完成一个应用程序的开发时,需要冗余部署该应用的多个实例,同时需要支持对应用的请求进行负载均衡,在Kubernetes中,我们可以把这个应用的多个实例分别启动一个容器,每个容器里面运行一个应用实例,然后通过内置的负载均衡策略,实现对这一组应用实例的管理、发现、访问,而这些细节都不需要应用开发和运维人员去进行复杂的手工配置和处理。
Kubernetes是Google基于内部Borg开源的容器编排引擎,关于Borg的设计,可以查看对应的论文《Large-scale cluster management at Google with Borg》。这里,我们先说一说Borg系统,它是Google内部的集群管理系统,使用它能够获得如下好处:
- 在一个分布式系统中进行资源管理是非常复杂的,构建于Borg系统之上的其他系统,无需关心这些资源管理的复杂细节
- 在大型分布式系统中处理异常也是非常困难的,Borg也屏蔽了运行于其上系统对失败或异常情况的处理,用户可以将精力集中在开发自己的应用系统上
- 支持高可靠性、高可用性
- Borg支持不同Workload,并且都能够非常高效地运行
从应用的视角来看,Google内部的很多系统都构建于Borg之上:应用框架,如MapReduce、FlumeJava、MillWheel、Pregel;存储系统,如GFS、CFS、Bigtable、Megastore。
从用户的视角来看, 运行在Borg集群之上的Workload主要分为两类:一类是long-running服务,这类服务一旦运行就不应该终止,比如Gmail、Google Docs、Google Search;另一类是批量作业,这类批量作业可能运行几秒到几天不等,比如MapReduce作业。
下面看一下,Borg系统的架构,如下图所示(来自Borg的论文):
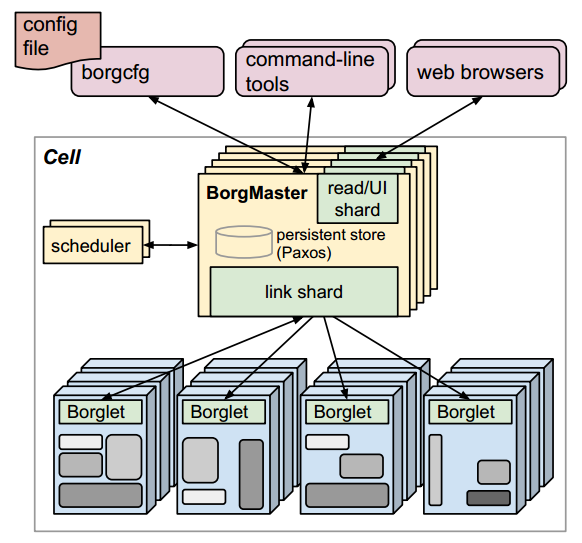
Borg集群从逻辑上看是一个主从架构风格的系统,主要由BorgMaster和Borglet两个核心组件组成。其中,BorgMaster是Borg集群的中央控制器,它由一个BorgMaster进程和一个Scheduler组成,BorgMaster进程负责处理客户端RPC调用请求,管理整个集群中所有对象的状态机,Scheduler负责调度Job到指定的节点上运行;Borglet会作为Borg Agent在每个节点上运行,负责管理启动任务、终止任务、任务失败重启等等,管理本地节点上的资源,同时将Borglet所在节点的状态报告给BorgMaster。
主要特性
自动化部署
应用部署到容器中,Kubernetes能够根据应用程序的计算资源需求和其它一些限制条件,自动地将运行应用程序的容器调度到集群中指定的Node上,在这个过程中并不会影响应用程序的可用性。
系统自愈
当Kubernetes集群中某些容器失败时,会重新启动他们。当某些Node挂掉后,Kubernetes会自动重新调度这些Node上的容器到其他可用的Node上。如果某些容器没有满足用户定义的健康检查条件,这些容器会被判定为无法正常工作的,集群会自动Kill掉这些容器,在这个过程中直到容器被重新启动或重新调度,直到可用以后才会对调用的客户端可见。
水平扩展
在Kubernetes中,通过一个命令就可以实现应用程序的水平扩展,实现这个功能的是HPA(Horizontal Pod Autoscaler)对象。HPA是通过Kubernetes API Resource和Controller的方式实现的,其中Resource决定了Controller的行为,而Controller周期性地调整Replication Controller或Deployment中的副本数,使得观察到的平均CPU使用情况与用户定义的能够匹配。
服务发现和负载均衡
Kubernetes内置实现了服务发现的功能,他会给每个容器指派一个IP地址,给一组容器指派一个DNS名称,通过这个就可以实现服务的负载均衡功能。
自动更新和回滚
当我们开发的应用程序发生变更,Kubernetes可以实现滚动更新,同时监控应用的状态,确保不会在同一时刻杀掉所有的实例,造成应用在一段时间范围内不可用。如果某些时候应用更新出错,Kubernetes能够自动地将应用恢复到原来正确的状态。
密钥和配置管理
Kubernetes提供了一种机制(ConfigMap),能够使我们的配置数据与应用对应的Docker镜像解耦合,如果配置需要变更,不需要重新构建Docker镜像,这为应用开发部署提供很大的灵活性。
同时,对于应用所依赖的一些敏感信息,如用户名和密码、令牌、秘钥等信息,Kubernetes也通过Secret对象实现了将这些敏感配置信息与应用的解耦合,这对应用的快速开发和交付提供了便利,在一定程上提供了也安全保障。
存储挂载
Kubernetes可以支持挂载不同类型存储系统,比如本地存储、公有云存储(如AWS、GCP)、网络存储系统(如NFS、iSCSI、Gluster、Ceph、Cinder、Flocker)等,我们可以进行灵活的选择。
批量作业执行
Kubernetes也支持批量作业的处理、监控、恢复。作业提交以后,直到作业运行完成即退出。如果运行失败,Kubernetes能够使失败的作业自动重新运行,直到作业运行成功为止。
总体架构
首先给出一个概念:Kubernetes Control Plane,翻译过来就是“Kubernetes控制平面”,它表示Kubernetes为了实现最终的目标而构建的一组集群范围内的进程,这组进程相互协调,保证整个集群系统达到用户所期望的目标状态,比如,容器失败自动调度并重启,应用服务的扩容缩容,等等。
Kubernetes Control Plane管理了Kubernetes集群中的所有Kubernetes对象及其状态,这些对象包括Pod、Service、Volume、Namespace、ReplicaSet、Deployment、StatefulSet、DaemonSet、Job等等。
Kubernetes集群的总体架构,如下图所示:
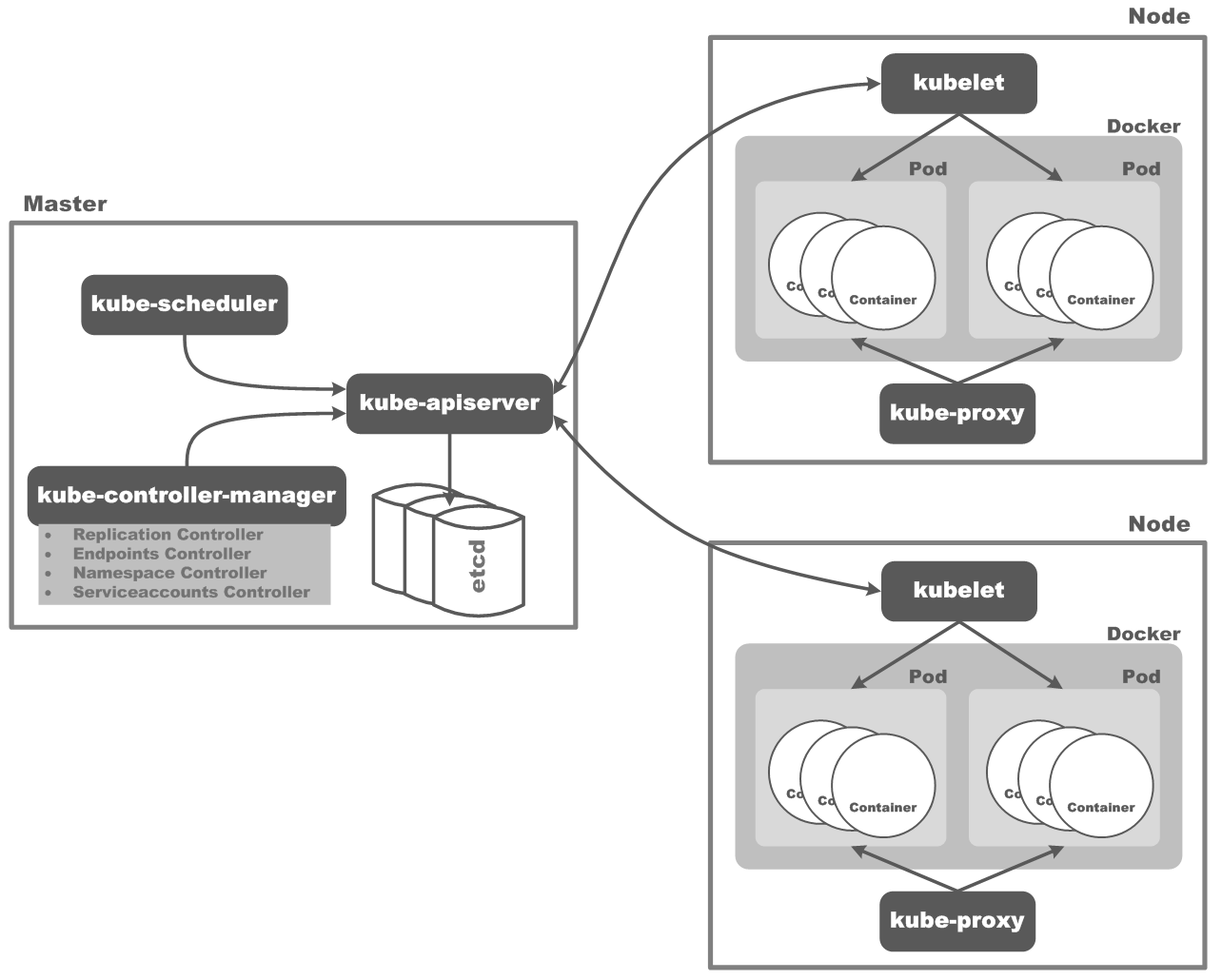
Kubernetes Control Plane主要包含两部分,一部分是Kubernetes集群Master上一组关键进程,另一个部分是在每个工作的Node节点上的一组关键进程,下面我们分别详细说明:
Kubernetes Master
Kubernetes Master主要由kube-apiserver、kube-controller-manager和kube-scheduler三个进程组成,它们运行在集群中一个单独的节点上,具体说明如下:
kube-apiserver进程:想要操作Kubernetes集群中的任何对象,都需要经过kube-apiserver,它封装了对Kubernetes对象的所有操作,以REST接口方式提供给想要与Kubernetes交互的任何客户端。经过kube-apiserver的所有对Kubernetes对象的修改操作都将持久化到etcd存储中。
kube-controller-manager进程:负责运行各种Controller,这些Controller主要包括:
- Node Controller
- Replication Controller
- Endpoints Controller
- Service Account
- Token Controller
kube-scheduler进程:负责Kubernetes集群内部的资源调度,主要负责监视Kubernetes集群内部已创建但没有被调度到某个Node上的Pod,然后将该Pod调度到一个选定的Node上面运行。
Kubernetes Node
Kubernetes集群中,每个工作的Node节点上主要运行如下两个进程:
kubelet进程:kubelet负责监视指派到它所在Node上的Pod,还负责处理如下工作:
- 为Pod挂载Volume
- 下载Pod拥有的Secret
- 运行属于Pod的容器
- 周期性地检查Pod中的容器是否存活
- 向Master报告当前Node上Pod的状态信息
- 向Master报告当前Node的状态信息
kube-proxy进程:在Kubernetes集群中,每个Node上面都有一个该网络代理进程,它主要负责为Pod对象提供代理:定期从etcd存储中获取所有的Service对象,并根据Service信息创建代理。当某个Client要访问一个Pod时,请求会经过该Node上的代理进程进行请求转发。
基本概念
Node
Node是Kubernetes集群的工作节点,它可以是物理机,也可以是虚拟机。我们创建的Pod,都运行在Kubernetes集群中的每个Node节点上。而且,在每个Node上还会存在一个运行容器的daemon进程,比如Docker daemon进程,它负责管理Docker容器的运行。
Node在Kubernetes集群中也是一种资源,内部会创建该资源,定义Node示例如下所示:
{
"kind": "Node",
"apiVersion": "v1",
"metadata": {
"name": "10.240.79.157",
"labels": {
"name": "my-first-k8s-node"
}
}
} |
Namespace
在一个Kubernetes集群中,可以使用Namespace创建多个“虚拟集群”,这些Namespace之间可以完全隔离,也可以通过某种方式,使一个Namespace中的Service可以访问到其他Namespace中的Service。
查看当前Kubernetes集群中的Namespace列表,执行如下命令:
默认情况下,会有两个系统自动创建好的Namespace:
default:Kubernetes集群中没有Namespace的对象都会放到该默认Namespace中
kube-system:Kubernetes集群自动创建的Namespace
创建一个名称为myns的Namespace,配置内容如下所示:
apiVersion: v1
kind: Namespace
metadata:
name: myns |
Pod
在Kubernetes集群中,Pod是创建、部署和调度的基本单位。一个Pod代表着集群中运行的一个进程,它内部封装了一个或多个应用的容器。在同一个Pod内部,多个容器共享存储、网络IP,以及管理容器如何运行的策略选项。Docker是Kubernetes中最常用的容器运行时。
在Kubrenetes集群中,Pod有两种使用方式,如下所示:
这种模式是最常见的用法,可以把Pod想象成是单个容器的封装,Kubernetes直接管理的是Pod,而不是Pod内部的容器。
一个Pod中也可以同时运行几个容器,这些容器之间需要紧密协作,并共享资源。这些在同一个Pod中的容器可以互相协作,逻辑上代表一个Service对象。每个Pod都是应用的一个实例,如果我们想要运行多个实例,就应该运行多个Pod。
同一个Pod中的容器,会自动的分配到同一个Node上。每个Pod都会被分配一个唯一的IP地址,该Pod中的所有容器共享网络空间,包括IP地址和端口。Pod内部的容器可以使用localhost互相通信。Pod中的容器与外界通信时,必须分配共享网络资源(例如,使用宿主机的端口映射)。
我们可以为一个Pod指定多个共享的Volume,它内部的所有容器都可以访问共享的Volume。Volume也可以用来持久化Pod中的存储资源,以防容器重启后文件丢失。
我们可以使用Kubernetes中抽象的Controller来创建和管理多个Pod,提供副本管理、滚动升级和集群级别的自愈能力。当Pod被创建后,都会被Kuberentes调度到集群的Node上,直到Pod的进程终止而被移除掉。
Service
Kubernetes Service从逻辑上定义了一个Pod的集合以及如何访问这些Pod的策略,有时也被称作是微服务,它与Pod、ReplicaSet等Kubernetes对象之间的关系,描述如下图所示:
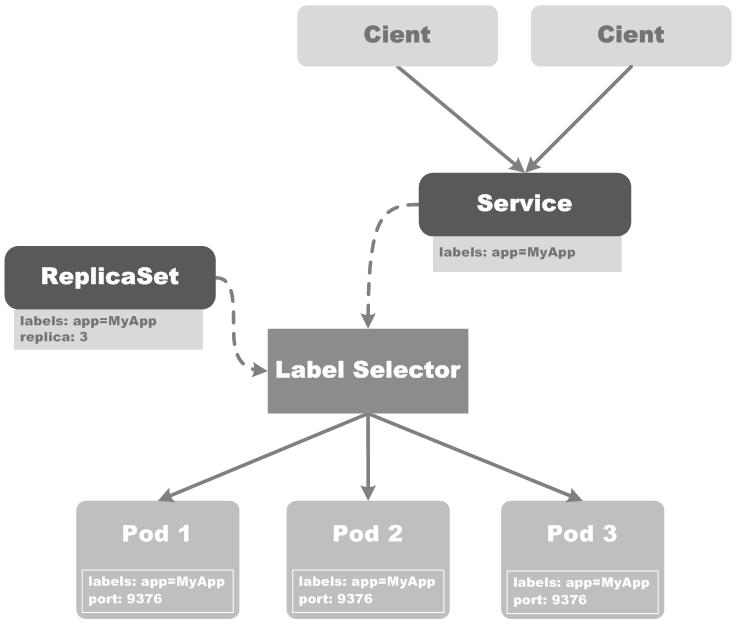
上图中,Client请求Service,Service通过Label Selector,将请求转发到对应的一组Pod上。同时,ReplicaSet会基于Label Selector来监控Service对应的Pod的数量是否满足用户设置的预期个数,最终保证Pod的数量和replica的值一致。
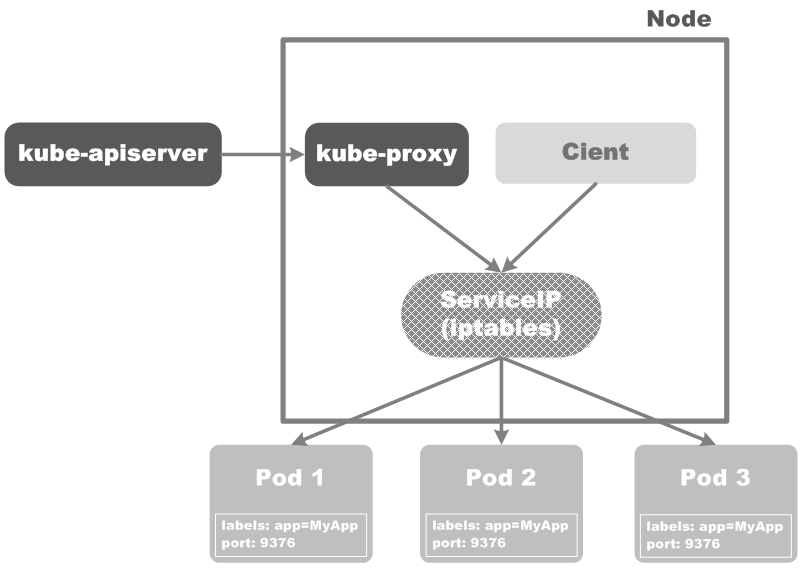
在Kubernetes集群中,每个Node都会运行一个kube-proxy,它主要负责为Service实现一种虚拟IP的代理,这种代理有两种模式:
这种模式是在Kubernetes v1.0版本加入的,工作在4层(传输层:TCPUDP over IP),称为userspace模式,如下图所示:
这种模式是在Kubernetes v1.1版本新增的,它工作在七层(应用层:HTTP),称为iptables,如下图所示:
Service定义了4种服务类型,以满足使用不同的方式去访问一个Service,这4种类型包括:ClusterIP、NodePort、LoadBalancer、ExternalName。
- ClusterIP是默认使用的类型,它表示在使用Kubernetes集群内部的IP地址,使用这种方式我们只能在该集群中访问Service。
- NodePort类型,会在Node节点上暴露一个静态的IP地址和端口,使得外部通过NodeIP:NodePort的方式就能访问到该Service。
- LoadBalancer类型,通过使用Cloud提供商提供的负载均衡IP地址,将Service暴露出去。
- ExternalName类型,会使用一个外部的域名来将Service暴露出去(Kubernetes v1.7及以上版本的kube-dns支持该种类型)。
我们可以定义一个Service,对应的配置内容,如下所示:
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 9376
- name: https
protocol: TCP
port: 443
targetPort: 9377
clusterIP: 10.0.171.239
loadBalancerIP: 78.11.24.
type: LoadBalancer
status:
loadBalancer:
ingress:
- ip: 146.148.47.155 |
定义的该服务是一个多端口服务,同时为该服务设置了一个负载均衡的IP(78.11.24.19),所有访问该服务的应用,通过该负载均衡IP地址都可以访问到该Service对应的Pod集合中的容器服务(应用服务)。
ReplicationController/ReplicaSet
在Kubernetes集群中,ReplicationController能够确保在任意时刻,指定数量的Pod副本正在运行。如果Pod副本的数量过多,则ReplicationController会Kill掉部分使其数量与预期保持一致,如果Pod数量过少,则会自动创建新的Pod副本以与预期数量相同。下面是一个ReplicationController的配置示例,如下所示:
apiVersion: v1
kind: ReplicationController
metadata:
name: nginx
spec:
replicas: 3
selector:
app: nginx
template:
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80 |
ReplicaSet是ReplicationController的下一代实现,它们之间没有本质的区别,除了ReplicaSet支持在selector中通过集合的方式进行配置。在新版本的Kubernetes中支持并建议使用ReplicaSet,而且我们应该尽量使用Deployment来管理一个ReplicaSet。下面定义一个ReplicaSet,对应的配置示例如下所示:
apiVersion: extensions/v1beta1
kind: ReplicaSet
metadata:
name: frontend
labels:
app: guestbook
tier: frontend
spec:
replicas: 3.
selector:
matchLabels:
tier: frontend
matchExpressions:
- {key: tier, operator: In, values: [frontend]}
template:
metadata:
labels:
app: guestbook
tier: frontend
spec:
containers:
- name: php-redis
image: gcr.io/google_samples/gb-frontend:v3
resources:
requests:
cpu: 100m
memory: 100Mi
env:
- name: GET_HOSTS_FROM
value: dns
ports:
- containerPort: 80 |
Volume
默认情况下容器的数据都是非持久化的,在容器销毁以后数据也会丢失,所以Docker提供了Volume机制来实现数据的持久化存储。同样,Kubernetes提供了更强大的Volume机制和丰富的插件,实现了容器数据的持久化,以及在容器之间共享数据。
Kubernetes Volume具有显式的生命周期,它与Pod的生命周期是相同的,所以只要Pod还处于运行状态,则该Pod内部的所有容器都能够访问该Volume,即使该Pod中的某个容器失败,数据也不会丢失。
Kubernetes支持多种类型的Volume,如下所示:
- emptyDir
- hostPath
- gcePersistentDisk
- awsElasticBlockStore
- nfs
- iscsi
- fc (fibre channel)
- flocker
- glusterfs
- rbd
- cephfs
- gitRepo
- secret
- persistentVolumeClaim
- downwardAPI
- projected
- azureFileVolume
- azureDisk
- vsphereVolume
- Quobyte
- PortworxVolume
- ScaleIO
- StorageOS
- local
上面各种类型的说明和示例,可以参考官方文档。Volume是与Pod有关的,所以这里我们给出一个Pod定义的配置示例,使用了hostPath类型的Volume,如下所示:
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: gcr.io/google_containers/test-webserver
name: test-container
volumeMounts:
- mountPath: /test-pd
name: test-volume
volumes:
- name: test-volume
hostPath:
# directory location on host
path: /data |
上面定义中,指定了Pod中容器使用的Node节点上的data存储路径。
Deployment
Deployment提供了声明式的方法,对Pod和ReplicaSet进行更新,我们只需要在Deployment对象中设置好预期的状态,然后Deployment就能够控制将实际的状态保持与预期状态一致。使用Deployment的典型场景,有如下几个:
- 创建ReplicaSet,进而通过ReplicaSet启动Pod,Deployment会检查启动状态是否成功
- 滚动升级或回滚应用
- 应用扩容或缩容
- 暂停(比如修改Pod模板)及恢复Deployment的运行
- 根据Deployment的运行状态,可以判断对应的应用是否hang住
- 清除掉不再使用的ReplicaSet
定义一个Deployment,示例如下所示:
apiVersion: apps/v1beta1 # for versions before 1.6.0 use extensions/v1beta1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80 |
上述配置创建一个ReplicaSet,进而启动3个Nginx Pod。
DaemonSet
DaemonSet能够保证Kubernetes集群中某些Node,或者全部Node上都运行一个Pod副本,当集群中某个Node被移除时,该Node上的Pod副本也会被清理掉。删除一个DaemonSet,也会把对应的Pod都删除掉。
通常,DaemonSet会被用于如下场景(在Kubernetes集群中每个Node上):
- 运行一个存储Daemon,如glusterd、ceph等
- 运行一个日志收集Daemon,如fluentd、logstash等
- 运行一个监控Daemon,如collectd、gmond等
定义一个DaemonSet,示例如下所示:
apiVersion: apps/v1beta1
kind: DaemonSet
metadata:
name: fluentd
spec:
template:
metadata:
labels:
app: logging
id: fluentd
name: fluentd
spec:
containers:
- name: fluentd-es
image: gcr.io/google_containers/fluentd-elasticsearch:1.3
env:
- name: FLUENTD_ARGS
value: -qq
volumeMounts:
- name: containers
mountPath: /var/lib/docker/containers
- name: varlog
mountPath: /varlog
volumes:
- hostPath:
path: /var/lib/docker/containers
name: containers
- hostPath:
path: /var/log
name: varlog |
上面例子,创建了一个基于fluentd的日志收集DaemonSet。
StatefulSet
StatefulSet是Kubernetes v1.5版本新增的,在v1.5之前的版本叫做PetSet(使用v1.4版本可以使用,具体可以查看官方文档,这里不再累述),是为了解决有状态服务的问题(对应无状态服务的Kubernetes对象:Deployment和ReplicaSet),其应用场景包括:
- 稳定的持久化存储,即Pod重新调度后还是能访问到相同的持久化数据,基于PVC来实现
- 稳定的网络标志,即Pod重新调度后其PodName和HostName不变,基于Headless Service(即没有Cluster IP的Service)来实现
- 有序部署,有序扩展,即Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次进行,基于init containers来实现
- 有序缩容,有序删除
为了说明StatefulSet,我们先定义一个名称为nginx的Headless Service,如下所示:
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx |
再定义一个名称为web的StatefulSet,定义了要在3个独立的Pod中分别创建3个nginx容器,示例如下所示:
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
terminationGracePeriodSeconds:
containers:
- name: nginx
image: gcr.io/google_containers/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
annotations:
volume.beta.kubernetes.io/storage-class: anything
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi |
上面示例,在Service中引用了名称为web的StatefulSet,该Service对应的存储信息是有状态的,通过StatefulSet能够保证Service中的Pod失败也不会丢失存储的数据,它通过PersistentVolume来提供稳定存储的。
ConfigMap
应用程序会从配置文件、命令行参数或环境变量中读取配置信息,如果将这些配置信息直接写在Docker镜像中,会非常不灵活,每次修改配置信息都要重新创建一个Docker镜像。ConfigMap的出现,能够使配置信息与Docker镜像解耦,更加方便和灵活。
在定义一个Pod的时候,可以使用ConfigMap对象中的配置数据,有很多种方式,如下所示:
- 从一个ConfigMap中读取键值对配置数据
- 从多个ConfigMap中读取键值对配置数据
- 从一个ConfigMap中读取全部的键值对配置数据
- 将一个ConfigMap中的配置数据加入到一个Volume中
下面给出其中2种使用方式:
- 定义一个环境变量,该变量值映射到一个ConfigMap对象中的配置值
创建一个名称为special-config的ConfigMap对象,执行如下命令:
| kubectl create configmap special-config --from-literal=special.how=very |
在上述ConfigMap对象special-config中创建了一个键special.how,它对应的值为very。
然后,我们定义一个Pod,将ConfigMap中的键special.how对应的值,赋值给环境变量SPECIAL_LEVEL_KEY,Pod定义文件内容,如下所示:
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: gcr.io/google_containers/busybox
command: [ "/bin/sh", "-c", "env" ]
env:
# Define the environment variable
- name: SPECIAL_LEVEL_KEY
valueFrom:
configMapKeyRef:
# The ConfigMap containing the value you want to assign to SPECIAL_LEVEL_KEY
name: special-config
# Specify the key associated with the value
key: special.how
restartPolicy: Never |
这时,Pod创建以后,就可以获取到对应的环境变量的值:SPECIAL_LEVEL_KEY=very。
创建多个ConfigMap对象,Pod从多个ConfigMap对象中读取到对应的配置值
首先,创建第一个ConfigMap对象special-config,该对象定义了配置数据special.how=very,如下所示:
apiVersion: v1
kind: ConfigMap
metadata:
name: special-config
namespace: default
data:
special.how: very |
然后,创建第二个ConfigMap对象env-config,该对象定义了配置数据log_level=INFO,如下所示:
apiVersion: v1
kind: ConfigMap
metadata:
name: env-config
namespace: default
data:
log_level: INFO |
最后,就可以在Pod中定义环境变量,如下所示:
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: gcr.io/google_containers/busybox
command: [ "/bin/sh", "-c", "env" ]
env:
- name: SPECIAL_LEVEL_KEY
valueFrom:
configMapKeyRef:
name: special-config
key: special.how
- name: LOG_LEVEL
valueFrom:
configMapKeyRef:
name: env-config
key: special.type
restartPolicy: Never |
在Pod创建后,可以分别从special-config、env-config中读取环境变量的值:SPECIAL_LEVEL_KEY=very、LOG_LEVEL=INFO。
Secret
Secret对象用来保存一些敏感信息,比如密码、OAuth令牌、ssh秘钥等,虽然这些敏感信息可以放到Pod定义中,或者Docker镜像中,但是放到Secret对象中更加安全和灵活。
使用Secret对象时,可以在Pod中引用创建的Secret对象,主要有如下两种方式:
- 挂载到一个或多个容器的Volume中的文件里面
- 当为一个Pod拉取镜像时,被kubectl使用
可以通过将Secret挂载到Volume中,或者以环境变量的形式导出,来被一个Pod中的容器使用。下面是一个示例,在一个Pod中的Volume上挂载一个Secret,如下所示:
{
"apiVersion": "v1",
"kind": "Pod",
"metadata": {
"name": "mypod",
"namespace": "myns"
},
"spec": {
"containers": [{
"name": "mypod",
"image": "redis",
"volumeMounts": [{
"name": "foo",
"mountPath": "/etc/foo",
"readOnly": true
}]
}],
"volumes": [{
"name": "foo",
"secret": {
"secretName": "mysecret"
}
}]
}
} |
通过导出环境变量,使用Secret,示例如下所示:
apiVersion: v1
kind: Pod
metadata:
name: secret-env-pod
spec:
containers:
- name: mycontainer
image: redis
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: mysecret
key: username
- name: SECRET_PASSWORD
valueFrom:
secretKeyRef:
name: mysecret
key: password
restartPolicy: Never |
其它有关Secret的更详细信息,可以参考官网文档。
Job
一个Job会创建一个或多个Pod,并确保指定数目的Pod能够运行成功。Job会跟踪每个Pod的运行,直到其运行成功,如果该Job跟踪的多个Pod都运行成功,则该Job就变为完成状态。删除一个Job,该Job创建的Pod都会被清理掉。
定义一个Job,示例如下所示:
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
metadata:
name: pi
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never |
CronJob
Crontab用来管理定时Job,主要使用场景如下:
- 在一个给定的时间点,调度Job运行
- 创建一个周期性运行的Job,例如数据库备份、发送邮件等等
定义一个CronJob,示例配置内容如下所示:
apiVersion: batch/v2alpha1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure |
上面CronJob运行,会定时执行一个Bash命令行输出字符串“Hello from the Kubernetes cluster”。
Ingress
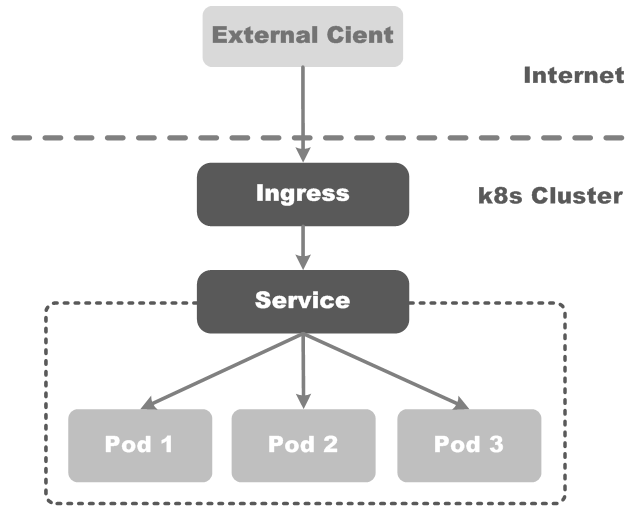
通常情况下,Service和Pod仅可在集群内部网络中通过IP地址访问。所有到达Edge router的流量或被丢弃或被转发到其它地方。一个Ingress是一组规则的集合,这些规则允许外部请求(公网访问)直接连接到Kubernetes集群内部的Service,如下图所示:
我们可以配置Ingress,为它提供外部(公网)可访问给定Service的规则,如Service URL、负载均衡、SSL、基于名称的虚拟主机等。用户想要基于POST方式请求Ingress资源,需要通过访问Kubernetes API Server来操作Ingress资源。
Ingress Controller是一个daemon进程,它是通过Kubernetes Pod来进行部署的。它负责实现Ingress,通常使用负载均衡器,还可以配置Edge router和其他前端(frontends),以高可用(HA)的方式来处理请求。为了能够使Ingress工作,Kubernetes集群中必须要有个一个Ingress Controller在运行,不同于kube-controller-manager所管理的Controller,我们必须要选择一个适合我们Kubernetes集群的Ingress Controller实现,如果没有合适的就需要开发实现一个。
定义一个Ingress,示例如下所示:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test-ingress
spec:
rules:
- http:
paths:
- path: /testpath
backend:
serviceName: test
servicePort: 80 |
上面rules配置了Ingress的规则列表,目前只支持HTTP规则,该示例使用了HTTP的paths规则,所请求URL能够匹配上paths指定的testpath,都会被转发到backend指定的Service上。
Ingress有如下5种类型:
- 单Service Ingress
- 简单扇出(fanout)
- 基于名称的虚拟主机
- TLS
- 负载均衡
想要熟悉上面5种类型的Ingress,可以查阅官方文档,这里不再详述。
Horizontal Pod Autoscaler
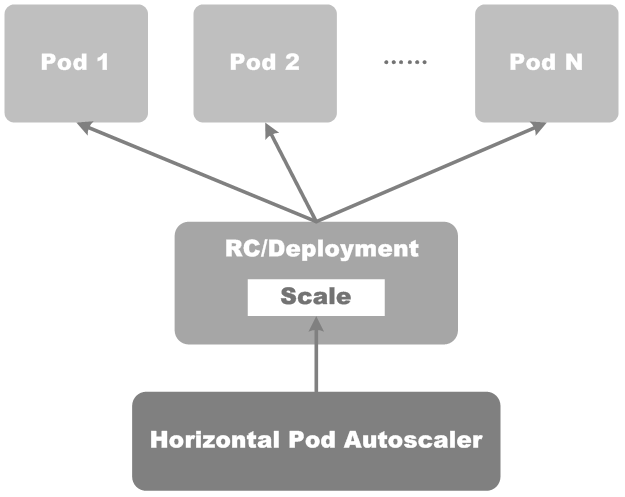
应用运行在容器中,它所依赖的资源的使用率通常并不均衡,资源使用量有时可能达到峰值,有时使用的又很少,为了提高Kubernetes集群的整体资源利用率,我们需要Service中的Pod的个数能够根据实际资源使用量来自动调整。这时我们就可以使用HPA(Horizontal Pod Autoscaling),它和Pod、Deployment等都是Kubernetes API资源,能实现Kubernetes集群内Service中Pod的水平伸缩。
HPA的工作原理,如下图所示:
通过下面命令,可以对HPA进行各种操作(创建HPA、列出所有HPA、获取HPA详细描述信息、删除HPA):
kubectl create hpa
kubectl get hpa
kubectl describe hpa
kubectl delete hpa |
另外,还可以通过kubectl autoscale 命令来创建HPA,例如,执行如下命令:
| kubectl autoscale rc foo --min=2 --max=5 --cpu-percent=80 |
上面示例的命令,要为名称为foo的ReplicationController创建一个HPA对象,使得目标CPU利率用为80%,并且副本的数量保持在2到5之间。
kubectl CLI
kubectl是一个命令行接口,通过它可以执行命令与Kubernetes集群交互。kubectl命令的语法格式,如下所示:
| kubectl [command] [TYPE] [NAME] [flags] |
上面命令说明中:
command:需要在一种或多种资源上执行的操作,比如:create、get、describe、delete等等,更详细可以参考官网文档。
TYPE:指定资源类型,大小写敏感,当前支持如下这些类型的资源:certificatesigningrequests、clusters、clusterrolebindings、clusterroles、componentstatuses、configmaps、cronjobs、daemonsets、deployments、endpoints、events、horizontalpodautoscalers、ingresses、jobs、limitranges、namespaces、networkpolicies、nodes、persistentvolumeclaims、persistentvolumes、poddisruptionbudget、pods、podsecuritypolicies、podtemplates、replicasets、replicationcontrollers、resourcequotas、rolebindings、roles、secrets、serviceaccounts、services、statefulsets、storageclasses、thirdpartyresources。
NAME:指定资源的名称,大小写敏感。
flags:可选,指定选项标志,比如:-s或-server表示Kubernetes API Server的IP地址和端口。
如果想要了解上述命令的详细用法说明,可以执行帮助命令:
另外,还可以通过官方文档,根据使用的Kubernetes的不同版本,来参考如下链接获取帮助:
https://kubernetes.io/docs/user-guide/kubectl/v1.7/
https://kubernetes.io/docs/user-guide/kubectl/v1.6/
https://kubernetes.io/docs/user-guide/kubectl/v1.5/
下面,举个常用的命令行操作,需要通过YAML文件定义一个Service(详见上文“基本概念”中给出的Service示例),创建一个Service,执行如下命令:
| kubectl create -f ./my-k8s-service.yaml |
定义任何Kubernetes对象,都是通过YAML文件去配置,使用类似上述命令进行创建。如果想要查看创建Kubernetes对象的结果,比如查看创建Service对象的结果,可通过如下命令查看:
这样,就能看到当前创建的Service对象的状态。 |








