ұҫОДКФНјҪ«KubernetesөД»щҙЎПа№ШЦӘК¶ГиКцЗеіюЈ¬ИГТ»ёцҙУАҙГ»УРKubernetesКөјщөДҝӘ·ўИЛФұЈ¬ДЬ№»·ЗіЈИЭТЧөШАнҪвKubernetesКЗКІГҙЈ¬ДЬ№»ЧцДДР©КВЗйЈ¬ТФј°К№УГЛьДЬҙшАҙөДәГҙҰКЗКІГҙЎЈ
KubernetesКЗКІГҙ
KubernetesКЗТ»ёцҝӘФҙөДИЭЖчұаЕЕТэЗжЈ¬ЛьЦ§іЦЧФ¶Ҝ»ҜІҝКрЎўҙу№жДЈҝЙЙмЛхЎўУҰУГИЭЖч»Ҝ№ЬАнЎЈОТГЗФЪНкіЙТ»ёцУҰУГіМРтөДҝӘ·ўКұЈ¬РиТӘИЯУаІҝКрёГУҰУГөД¶аёцКөАэЈ¬Н¬КұРиТӘЦ§іЦ¶ФУҰУГөДЗлЗуҪшРРёәФШҫщәвЈ¬ФЪKubernetesЦРЈ¬ОТГЗҝЙТФ°СХвёцУҰУГөД¶аёцКөАэ·ЦұрЖф¶ҜТ»ёцИЭЖчЈ¬ГҝёцИЭЖчАпГжФЛРРТ»ёцУҰУГКөАэЈ¬И»әуНЁ№эДЪЦГөДёәФШҫщәвІЯВФЈ¬КөПЦ¶ФХвТ»ЧйУҰУГКөАэөД№ЬАнЎў·ўПЦЎў·ГОКЈ¬¶шХвР©ПёҪЪ¶јІ»РиТӘУҰУГҝӘ·ўәНФЛО¬ИЛФұИҘҪшРРёҙФУөДКЦ№ӨЕдЦГәНҙҰАнЎЈ
KubernetesКЗGoogle»щУЪДЪІҝBorgҝӘФҙөДИЭЖчұаЕЕТэЗжЈ¬№ШУЪBorgөДЙијЖЈ¬ҝЙТФІйҝҙ¶ФУҰөДВЫОДЎ¶Large-scale cluster management at Google with BorgЎ·ЎЈХвАпЈ¬ОТГЗПИЛөТ»ЛөBorgПөНіЈ¬ЛьКЗGoogleДЪІҝөДјҜИә№ЬАнПөНіЈ¬К№УГЛьДЬ№»»сөГИзПВәГҙҰЈә
- ФЪТ»ёц·ЦІјКҪПөНіЦРҪшРРЧКФҙ№ЬАнКЗ·ЗіЈёҙФУөДЈ¬№№ҪЁУЪBorgПөНіЦ®ЙПөДЖдЛыПөНіЈ¬ОЮРи№ШРДХвР©ЧКФҙ№ЬАнөДёҙФУПёҪЪ
- ФЪҙуРН·ЦІјКҪПөНіЦРҙҰАнТміЈТІКЗ·ЗіЈА§ДСөДЈ¬BorgТІЖБұОБЛФЛРРУЪЖдЙППөНі¶ФК§°Ь»тТміЈЗйҝцөДҙҰАнЈ¬УГ»§ҝЙТФҪ«ҫ«БҰјҜЦРФЪҝӘ·ўЧФјәөДУҰУГПөНіЙП
- Ц§іЦёЯҝЙҝҝРФЎўёЯҝЙУГРФ
- BorgЦ§іЦІ»Н¬WorkloadЈ¬ІўЗТ¶јДЬ№»·ЗіЈёЯР§өШФЛРР
ҙУУҰУГөДКУҪЗАҙҝҙЈ¬GoogleДЪІҝөДәЬ¶аПөНі¶ј№№ҪЁУЪBorgЦ®ЙПЈәУҰУГҝтјЬЈ¬ИзMapReduceЎўFlumeJavaЎўMillWheelЎўPregelЈ»ҙжҙўПөНіЈ¬ИзGFSЎўCFSЎўBigtableЎўMegastoreЎЈ
ҙУУГ»§өДКУҪЗАҙҝҙЈ¬ ФЛРРФЪBorgјҜИәЦ®ЙПөДWorkloadЦчТӘ·ЦОӘБҪАаЈәТ»АаКЗlong-running·юОсЈ¬ХвАа·юОсТ»ө©ФЛРРҫНІ»УҰёГЦХЦ№Ј¬ұИИзGmailЎўGoogle DocsЎўGoogle SearchЈ»БнТ»АаКЗЕъБҝЧчТөЈ¬ХвАаЕъБҝЧчТөҝЙДЬФЛРРјёГлөҪјёМмІ»өИЈ¬ұИИзMapReduceЧчТөЎЈ
ПВГжҝҙТ»ПВЈ¬BorgПөНіөДјЬ№№Ј¬ИзПВНјЛщКҫЈЁАҙЧФBorgөДВЫОДЈ©Јә
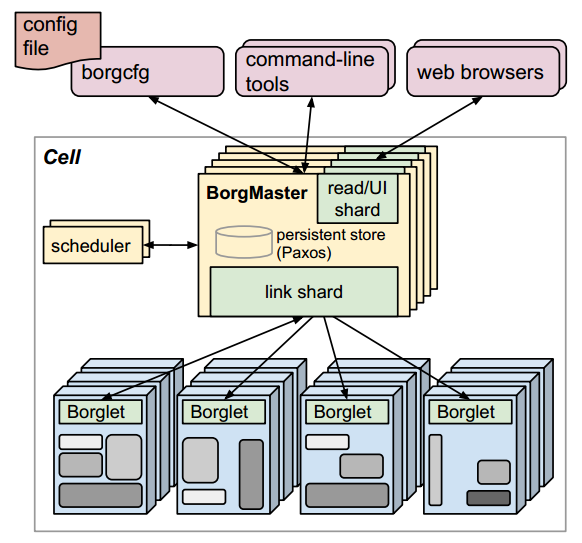
BorgјҜИәҙУВЯјӯЙПҝҙКЗТ»ёцЦчҙУјЬ№№·зёсөДПөНіЈ¬ЦчТӘУЙBorgMasterәНBorgletБҪёцәЛРДЧйјюЧйіЙЎЈЖдЦРЈ¬BorgMasterКЗBorgјҜИәөДЦРСлҝШЦЖЖчЈ¬ЛьУЙТ»ёцBorgMasterҪшіМәНТ»ёцSchedulerЧйіЙЈ¬BorgMasterҪшіМёәФрҙҰАнҝН»§¶ЛRPCөчУГЗлЗ󣬹ЬАнХыёцјҜИәЦРЛщУР¶ФПуөДЧҙМ¬»ъЈ¬SchedulerёәФрөч¶ИJobөҪЦё¶ЁөДҪЪөгЙПФЛРРЈ»Borglet»бЧчОӘBorg AgentФЪГҝёцҪЪөгЙПФЛРРЈ¬ёәФр№ЬАнЖф¶ҜИООсЎўЦХЦ№ИООсЎўИООсК§°ЬЦШЖфөИөИЈ¬№ЬАнұҫөШҪЪөгЙПөДЧКФҙЈ¬Н¬КұҪ«BorgletЛщФЪҪЪөгөДЧҙМ¬ұЁёжёшBorgMasterЎЈ
ЦчТӘМШРФ
ЧФ¶Ҝ»ҜІҝКр
УҰУГІҝКрөҪИЭЖчЦРЈ¬KubernetesДЬ№»ёщҫЭУҰУГіМРтөДјЖЛгЧКФҙРиЗуәНЖдЛьТ»Р©ПЮЦЖМхјюЈ¬ЧФ¶ҜөШҪ«ФЛРРУҰУГіМРтөДИЭЖчөч¶ИөҪјҜИәЦРЦё¶ЁөДNodeЙПЈ¬ФЪХвёц№эіМЦРІўІ»»бУ°ПмУҰУГіМРтөДҝЙУГРФЎЈ
ПөНіЧФУъ
өұKubernetesјҜИәЦРДіР©ИЭЖчК§°ЬКұЈ¬»бЦШРВЖф¶ҜЛыГЗЎЈөұДіР©Node№ТөфәуЈ¬Kubernetes»бЧФ¶ҜЦШРВөч¶ИХвР©NodeЙПөДИЭЖчөҪЖдЛыҝЙУГөДNodeЙПЎЈИз№ыДіР©ИЭЖчГ»УРВъЧгУГ»§¶ЁТеөДҪЎҝөјмІйМхјюЈ¬ХвР©ИЭЖч»бұ»ЕР¶ЁОӘОЮ·ЁХэіЈ№ӨЧчөДЈ¬јҜИә»бЧФ¶ҜKillөфХвР©ИЭЖчЈ¬ФЪХвёц№эіМЦРЦұөҪИЭЖчұ»ЦШРВЖф¶Ҝ»тЦШРВөч¶ИЈ¬ЦұөҪҝЙУГТФәуІЕ»б¶ФөчУГөДҝН»§¶ЛҝЙјыЎЈ
Л®ЖҪА©Х№
ФЪKubernetesЦРЈ¬НЁ№эТ»ёцГьБоҫНҝЙТФКөПЦУҰУГіМРтөДЛ®ЖҪА©Х№Ј¬КөПЦХвёц№ҰДЬөДКЗHPAЈЁHorizontal Pod AutoscalerЈ©¶ФПуЎЈHPAКЗНЁ№эKubernetes API ResourceәНControllerөД·ҪКҪКөПЦөДЈ¬ЖдЦРResourceҫц¶ЁБЛControllerөДРРОӘЈ¬¶шControllerЦЬЖЪРФөШөчХыReplication Controller»тDeploymentЦРөДёұұҫКэЈ¬К№өГ№ЫІмөҪөДЖҪҫщCPUК№УГЗйҝцУлУГ»§¶ЁТеөДДЬ№»ЖҘЕдЎЈ
·юОс·ўПЦәНёәФШҫщәв
KubernetesДЪЦГКөПЦБЛ·юОс·ўПЦөД№ҰДЬЈ¬Лы»бёшГҝёцИЭЖчЦёЕЙТ»ёцIPөШЦ·Ј¬ёшТ»ЧйИЭЖчЦёЕЙТ»ёцDNSГыіЖЈ¬НЁ№эХвёцҫНҝЙТФКөПЦ·юОсөДёәФШҫщәв№ҰДЬЎЈ
ЧФ¶ҜёьРВәН»Ш№ц
өұОТГЗҝӘ·ўөДУҰУГіМРт·ўЙъұдёьЈ¬KubernetesҝЙТФКөПЦ№ц¶ҜёьРВЈ¬Н¬КұјаҝШУҰУГөДЧҙМ¬Ј¬И·ұЈІ»»бФЪН¬Т»КұҝМЙұөфЛщУРөДКөАэЈ¬ФміЙУҰУГФЪТ»¶ОКұјд·¶О§ДЪІ»ҝЙУГЎЈИз№ыДіР©КұәтУҰУГёьРВіцҙнЈ¬KubernetesДЬ№»ЧФ¶ҜөШҪ«УҰУГ»ЦёҙөҪФӯАҙХэИ·өДЧҙМ¬ЎЈ
ГЬФҝәНЕдЦГ№ЬАн
KubernetesМṩБЛТ»ЦЦ»ъЦЖЈЁConfigMapЈ©Ј¬ДЬ№»К№ОТГЗөДЕдЦГКэҫЭУлУҰУГ¶ФУҰөДDockerҫөПсҪвсоәПЈ¬Из№ыЕдЦГРиТӘұдёьЈ¬І»РиТӘЦШРВ№№ҪЁDockerҫөПсЈ¬ХвОӘУҰУГҝӘ·ўІҝКрМṩәЬҙуөДБй»оРФЎЈ
Н¬КұЈ¬¶ФУЪУҰУГЛщТААөөДТ»Р©ГфёРРЕПўЈ¬ИзУГ»§ГыәНГЬВлЎўБоЕЖЎўГШФҝөИРЕПўЈ¬KubernetesТІНЁ№эSecret¶ФПуКөПЦБЛҪ«ХвР©ГфёРЕдЦГРЕПўУлУҰУГөДҪвсоәПЈ¬Хв¶ФУҰУГөДҝмЛЩҝӘ·ўәНҪ»ё¶МṩБЛұгАыЈ¬ФЪТ»¶ЁіМЙПМṩБЛТІ°ІИ«ұЈХПЎЈ
ҙжҙў№ТФШ
KubernetesҝЙТФЦ§іЦ№ТФШІ»Н¬АаРНҙжҙўПөНіЈ¬ұИИзұҫөШҙжҙўЎў№«УРФЖҙжҙўЈЁИзAWSЎўGCPЈ©ЎўНшВзҙжҙўПөНіЈЁИзNFSЎўiSCSIЎўGlusterЎўCephЎўCinderЎўFlockerЈ©өИЈ¬ОТГЗҝЙТФҪшРРБй»оөДСЎФсЎЈ
ЕъБҝЧчТөЦҙРР
KubernetesТІЦ§іЦЕъБҝЧчТөөДҙҰАнЎўјаҝШЎў»ЦёҙЎЈЧчТөМбҪ»ТФәуЈ¬ЦұөҪЧчТөФЛРРНкіЙјҙНЛіцЎЈИз№ыФЛРРК§°ЬЈ¬KubernetesДЬ№»К№К§°ЬөДЧчТөЧФ¶ҜЦШРВФЛРРЈ¬ЦұөҪЧчТөФЛРРіЙ№ҰОӘЦ№ЎЈ
ЧЬМејЬ№№
КЧПИёшіцТ»ёцёЕДоЈәKubernetes Control PlaneЈ¬·ӯТл№эАҙҫНКЗЎ°KubernetesҝШЦЖЖҪГжЎұЈ¬ЛьұнКҫKubernetesОӘБЛКөПЦЧоЦХөДДҝұк¶ш№№ҪЁөДТ»ЧйјҜИә·¶О§ДЪөДҪшіМЈ¬ХвЧйҪшіМПа»ҘРӯөчЈ¬ұЈЦӨХыёцјҜИәПөНіҙпөҪУГ»§ЛщЖЪНыөДДҝұкЧҙМ¬Ј¬ұИИзЈ¬ИЭЖчК§°ЬЧФ¶Ҝөч¶ИІўЦШЖфЈ¬УҰУГ·юОсөДА©ИЭЛхИЭЈ¬өИөИЎЈ
Kubernetes Control Plane№ЬАнБЛKubernetesјҜИәЦРөДЛщУРKubernetes¶ФПуј°ЖдЧҙМ¬Ј¬ХвР©¶ФПу°ьАЁPodЎўServiceЎўVolumeЎўNamespaceЎўReplicaSetЎўDeploymentЎўStatefulSetЎўDaemonSetЎўJobөИөИЎЈ
KubernetesјҜИәөДЧЬМејЬ№№Ј¬ИзПВНјЛщКҫЈә
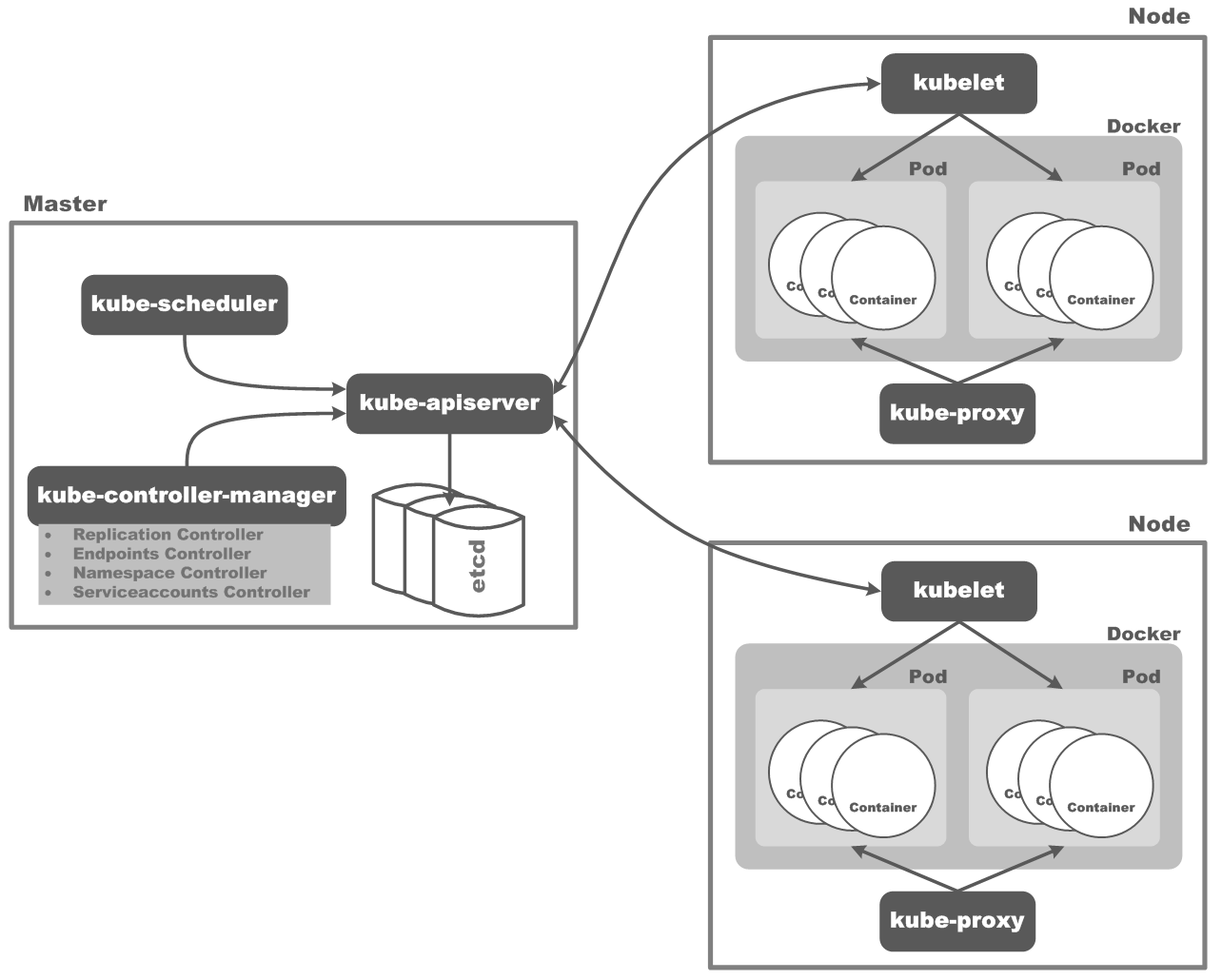
Kubernetes Control PlaneЦчТӘ°ьә¬БҪІҝ·ЦЈ¬Т»Іҝ·ЦКЗKubernetesјҜИәMasterЙПТ»Чй№ШјьҪшіМЈ¬БнТ»ёцІҝ·ЦКЗФЪГҝёц№ӨЧчөДNodeҪЪөгЙПөДТ»Чй№ШјьҪшіМЈ¬ПВГжОТГЗ·ЦұрПкПёЛөГчЈә
Kubernetes Master
Kubernetes MasterЦчТӘУЙkube-apiserverЎўkube-controller-managerәНkube-schedulerИэёцҪшіМЧйіЙЈ¬ЛьГЗФЛРРФЪјҜИәЦРТ»ёцөҘ¶АөДҪЪөгЙПЈ¬ҫЯМеЛөГчИзПВЈә
kube-apiserverҪшіМЈәПлТӘІЩЧчKubernetesјҜИәЦРөДИОәО¶ФП󣬶јРиТӘҫӯ№эkube-apiserverЈ¬Ль·вЧ°БЛ¶ФKubernetes¶ФПуөДЛщУРІЩЧчЈ¬ТФRESTҪУҝЪ·ҪКҪМṩёшПлТӘУлKubernetesҪ»»ҘөДИОәОҝН»§¶ЛЎЈҫӯ№эkube-apiserverөДЛщУР¶ФKubernetes¶ФПуөДРЮёДІЩЧч¶јҪ«іЦҫГ»ҜөҪetcdҙжҙўЦРЎЈ
kube-controller-managerҪшіМЈәёәФрФЛРРёчЦЦControllerЈ¬ХвР©ControllerЦчТӘ°ьАЁЈә
- Node Controller
- Replication Controller
- Endpoints Controller
- Service Account
- Token Controller
kube-schedulerҪшіМЈәёәФрKubernetesјҜИәДЪІҝөДЧКФҙөч¶ИЈ¬ЦчТӘёәФрјаКУKubernetesјҜИәДЪІҝТСҙҙҪЁө«Г»УРұ»өч¶ИөҪДіёцNodeЙПөДPodЈ¬И»әуҪ«ёГPodөч¶ИөҪТ»ёцСЎ¶ЁөДNodeЙПГжФЛРРЎЈ
Kubernetes Node
KubernetesјҜИәЦРЈ¬Гҝёц№ӨЧчөДNodeҪЪөгЙПЦчТӘФЛРРИзПВБҪёцҪшіМЈә
kubeletҪшіМЈәkubeletёәФрјаКУЦёЕЙөҪЛьЛщФЪNodeЙПөДPodЈ¬»№ёәФрҙҰАнИзПВ№ӨЧчЈә
- ОӘPod№ТФШVolume
- ПВФШPodУөУРөДSecret
- ФЛРРКфУЪPodөДИЭЖч
- ЦЬЖЪРФөШјмІйPodЦРөДИЭЖчКЗ·сҙж»о
- ПтMasterұЁёжөұЗ°NodeЙПPodөДЧҙМ¬РЕПў
- ПтMasterұЁёжөұЗ°NodeөДЧҙМ¬РЕПў
kube-proxyҪшіМЈәФЪKubernetesјҜИәЦРЈ¬ГҝёцNodeЙПГж¶јУРТ»ёцёГНшВзҙъАнҪшіМЈ¬ЛьЦчТӘёәФрОӘPod¶ФПуМṩҙъАнЈә¶ЁЖЪҙУetcdҙжҙўЦР»сИЎЛщУРөДService¶ФПуЈ¬ІўёщҫЭServiceРЕПўҙҙҪЁҙъАнЎЈөұДіёцClientТӘ·ГОКТ»ёцPodКұЈ¬ЗлЗу»бҫӯ№эёГNodeЙПөДҙъАнҪшіМҪшРРЗлЗуЧӘ·ўЎЈ
»щұҫёЕДо
Node
NodeКЗKubernetesјҜИәөД№ӨЧчҪЪөгЈ¬ЛьҝЙТФКЗОпАн»ъЈ¬ТІҝЙТФКЗРйДв»ъЎЈОТГЗҙҙҪЁөДPodЈ¬¶јФЛРРФЪKubernetesјҜИәЦРөДГҝёцNodeҪЪөгЙПЎЈ¶шЗТЈ¬ФЪГҝёцNodeЙП»№»бҙжФЪТ»ёцФЛРРИЭЖчөДdaemonҪшіМЈ¬ұИИзDocker daemonҪшіМЈ¬ЛьёәФр№ЬАнDockerИЭЖчөДФЛРРЎЈ
NodeФЪKubernetesјҜИәЦРТІКЗТ»ЦЦЧКФҙЈ¬ДЪІҝ»бҙҙҪЁёГЧКФҙЈ¬¶ЁТеNodeКҫАэИзПВЛщКҫЈә
{
"kind": "Node",
"apiVersion": "v1",
"metadata": {
"name": "10.240.79.157",
"labels": {
"name": "my-first-k8s-node"
}
}
} |
Namespace
ФЪТ»ёцKubernetesјҜИәЦРЈ¬ҝЙТФК№УГNamespaceҙҙҪЁ¶аёцЎ°РйДвјҜИәЎұЈ¬ХвР©NamespaceЦ®јдҝЙТФНкИ«ёфАлЈ¬ТІҝЙТФНЁ№эДіЦЦ·ҪКҪЈ¬К№Т»ёцNamespaceЦРөДServiceҝЙТФ·ГОКөҪЖдЛыNamespaceЦРөДServiceЎЈ
ІйҝҙөұЗ°KubernetesјҜИәЦРөДNamespaceБРұнЈ¬ЦҙРРИзПВГьБоЈә
Д¬ИПЗйҝцПВЈ¬»бУРБҪёцПөНіЧФ¶ҜҙҙҪЁәГөДNamespaceЈә
defaultЈәKubernetesјҜИәЦРГ»УРNamespaceөД¶ФПу¶ј»б·ЕөҪёГД¬ИПNamespaceЦР
kube-systemЈәKubernetesјҜИәЧФ¶ҜҙҙҪЁөДNamespace
ҙҙҪЁТ»ёцГыіЖОӘmynsөДNamespaceЈ¬ЕдЦГДЪИЭИзПВЛщКҫЈә
apiVersion: v1
kind: Namespace
metadata:
name: myns |
Pod
ФЪKubernetesјҜИәЦРЈ¬PodКЗҙҙҪЁЎўІҝКрәНөч¶ИөД»щұҫөҘО»ЎЈТ»ёцPodҙъұнЧЕјҜИәЦРФЛРРөДТ»ёцҪшіМЈ¬ЛьДЪІҝ·вЧ°БЛТ»ёц»т¶аёцУҰУГөДИЭЖчЎЈФЪН¬Т»ёцPodДЪІҝЈ¬¶аёцИЭЖч№ІПнҙжҙўЎўНшВзIPЈ¬ТФј°№ЬАнИЭЖчИзәОФЛРРөДІЯВФСЎПоЎЈDockerКЗKubernetesЦРЧоіЈУГөДИЭЖчФЛРРКұЎЈ
ФЪKubrenetesјҜИәЦРЈ¬PodУРБҪЦЦК№УГ·ҪКҪЈ¬ИзПВЛщКҫЈә
ХвЦЦДЈКҪКЗЧоіЈјыөДУГ·ЁЈ¬ҝЙТФ°СPodПлПуіЙКЗөҘёцИЭЖчөД·вЧ°Ј¬KubernetesЦұҪУ№ЬАнөДКЗPodЈ¬¶шІ»КЗPodДЪІҝөДИЭЖчЎЈ
- Т»ёцPodЦРН¬КұФЛРР¶аёцИЭЖч
Т»ёцPodЦРТІҝЙТФН¬КұФЛРРјёёцИЭЖчЈ¬ХвР©ИЭЖчЦ®јдРиТӘҪфГЬРӯЧчЈ¬Іў№ІПнЧКФҙЎЈХвР©ФЪН¬Т»ёцPodЦРөДИЭЖчҝЙТФ»ҘПаРӯЧчЈ¬ВЯјӯЙПҙъұнТ»ёцService¶ФПуЎЈГҝёцPod¶јКЗУҰУГөДТ»ёцКөАэЈ¬Из№ыОТГЗПлТӘФЛРР¶аёцКөАэЈ¬ҫНУҰёГФЛРР¶аёцPodЎЈ
Н¬Т»ёцPodЦРөДИЭЖчЈ¬»бЧФ¶ҜөД·ЦЕдөҪН¬Т»ёцNodeЙПЎЈГҝёцPod¶ј»бұ»·ЦЕдТ»ёцОЁТ»өДIPөШЦ·Ј¬ёГPodЦРөДЛщУРИЭЖч№ІПнНшВзҝХјдЈ¬°ьАЁIPөШЦ·әН¶ЛҝЪЎЈPodДЪІҝөДИЭЖчҝЙТФК№УГlocalhost»ҘПаНЁРЕЎЈPodЦРөДИЭЖчУлНвҪзНЁРЕКұЈ¬ұШРл·ЦЕд№ІПнНшВзЧКФҙЈЁАэИзЈ¬К№УГЛЮЦч»ъөД¶ЛҝЪУіЙдЈ©ЎЈ
ОТГЗҝЙТФОӘТ»ёцPodЦё¶Ё¶аёц№ІПнөДVolumeЈ¬ЛьДЪІҝөДЛщУРИЭЖч¶јҝЙТФ·ГОК№ІПнөДVolumeЎЈVolumeТІҝЙТФУГАҙіЦҫГ»ҜPodЦРөДҙжҙўЧКФҙЈ¬ТФ·АИЭЖчЦШЖфәуОДјю¶ӘК§ЎЈ
ОТГЗҝЙТФК№УГKubernetesЦРійПуөДControllerАҙҙҙҪЁәН№ЬАн¶аёцPodЈ¬Мṩёұұҫ№ЬАнЎў№ц¶ҜЙэј¶әНјҜИәј¶ұрөДЧФУъДЬБҰЎЈөұPodұ»ҙҙҪЁә󣬶ј»бұ»Kuberentesөч¶ИөҪјҜИәөДNodeЙПЈ¬ЦұөҪPodөДҪшіМЦХЦ№¶шұ»ТЖіэөфЎЈ
Service
Kubernetes ServiceҙУВЯјӯЙП¶ЁТеБЛТ»ёцPodөДјҜәПТФј°ИзәО·ГОКХвР©PodөДІЯВФЈ¬УРКұТІұ»іЖЧчКЗОў·юОсЈ¬ЛьУлPodЎўReplicaSetөИKubernetes¶ФПуЦ®јдөД№ШПөЈ¬ГиКцИзПВНјЛщКҫЈә
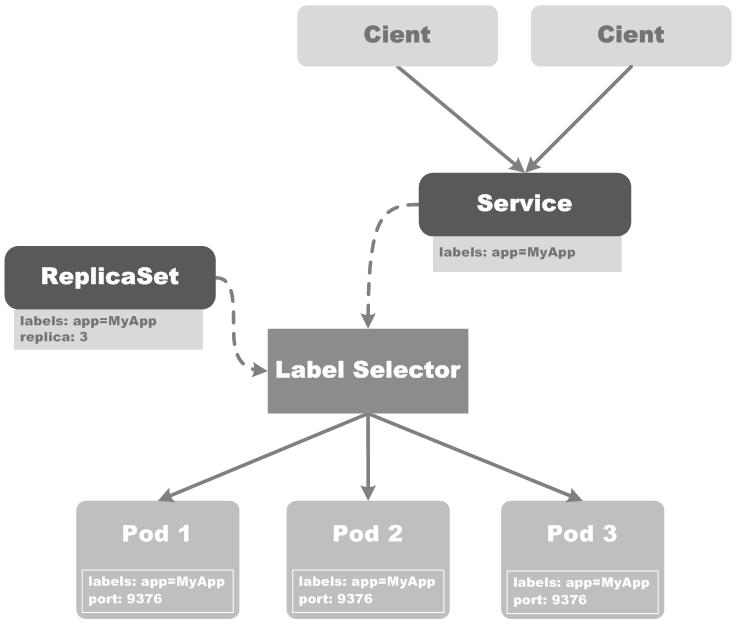
ЙПНјЦРЈ¬ClientЗлЗуServiceЈ¬ServiceНЁ№эLabel SelectorЈ¬Ҫ«ЗлЗуЧӘ·ўөҪ¶ФУҰөДТ»ЧйPodЙПЎЈН¬КұЈ¬ReplicaSet»б»щУЪLabel SelectorАҙјаҝШService¶ФУҰөДPodөДКэБҝКЗ·сВъЧгУГ»§ЙиЦГөДФӨЖЪёцКэЈ¬ЧоЦХұЈЦӨPodөДКэБҝәНreplicaөДЦөТ»ЦВЎЈ
ФЪKubernetesјҜИәЦРЈ¬ГҝёцNode¶ј»бФЛРРТ»ёцkube-proxyЈ¬ЛьЦчТӘёәФрОӘServiceКөПЦТ»ЦЦРйДвIPөДҙъАнЈ¬ХвЦЦҙъАнУРБҪЦЦДЈКҪЈә
ХвЦЦДЈКҪКЗФЪKubernetes v1.0°жұҫјУИлөДЈ¬№ӨЧчФЪ4ІгЈЁҙ«КдІгЈәTCPUDP over IPЈ©Ј¬іЖОӘuserspaceДЈКҪЈ¬ИзПВНјЛщКҫЈә
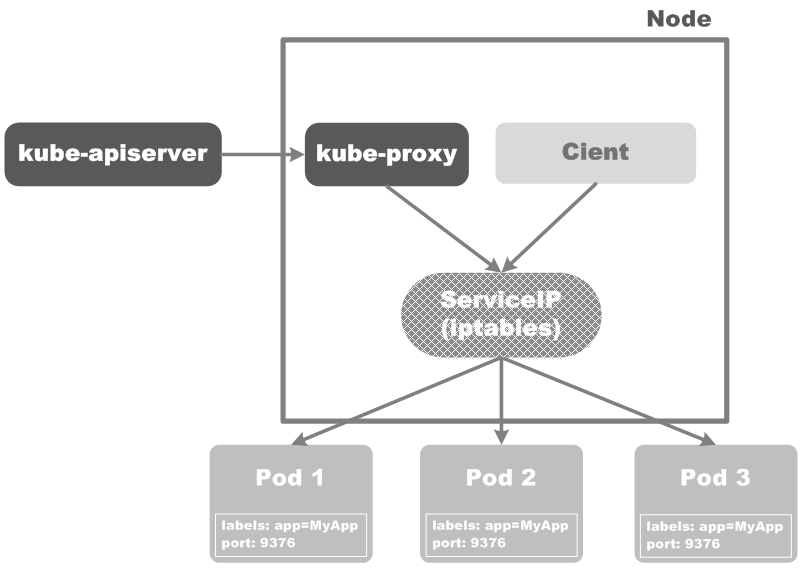
ХвЦЦДЈКҪКЗФЪKubernetes v1.1°жұҫРВФцөДЈ¬Ль№ӨЧчФЪЖЯІгЈЁУҰУГІгЈәHTTPЈ©Ј¬іЖОӘiptablesЈ¬ИзПВНјЛщКҫЈә
Service¶ЁТеБЛ4ЦЦ·юОсАаРНЈ¬ТФВъЧгК№УГІ»Н¬өД·ҪКҪИҘ·ГОКТ»ёцServiceЈ¬Хв4ЦЦАаРН°ьАЁЈәClusterIPЎўNodePortЎўLoadBalancerЎўExternalNameЎЈ
- ClusterIPКЗД¬ИПК№УГөДАаРНЈ¬ЛьұнКҫФЪК№УГKubernetesјҜИәДЪІҝөДIPөШЦ·Ј¬К№УГХвЦЦ·ҪКҪОТГЗЦ»ДЬФЪёГјҜИәЦР·ГОКServiceЎЈ
- NodePortАаРНЈ¬»бФЪNodeҪЪөгЙПұ©В¶Т»ёцҫІМ¬өДIPөШЦ·әН¶ЛҝЪЈ¬К№өГНвІҝНЁ№эNodeIP:NodePortөД·ҪКҪҫНДЬ·ГОКөҪёГServiceЎЈ
- LoadBalancerАаРНЈ¬НЁ№эК№УГCloudМṩЙММṩөДёәФШҫщәвIPөШЦ·Ј¬Ҫ«Serviceұ©В¶іцИҘЎЈ
- ExternalNameАаРНЈ¬»бК№УГТ»ёцНвІҝөДУтГыАҙҪ«Serviceұ©В¶іцИҘЈЁKubernetes v1.7ј°ТФЙП°жұҫөДkube-dnsЦ§іЦёГЦЦАаРНЈ©ЎЈ
ОТГЗҝЙТФ¶ЁТеТ»ёцServiceЈ¬¶ФУҰөДЕдЦГДЪИЭЈ¬ИзПВЛщКҫЈә
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 9376
- name: https
protocol: TCP
port: 443
targetPort: 9377
clusterIP: 10.0.171.239
loadBalancerIP: 78.11.24.
type: LoadBalancer
status:
loadBalancer:
ingress:
- ip: 146.148.47.155 |
¶ЁТеөДёГ·юОсКЗТ»ёц¶а¶ЛҝЪ·юОсЈ¬Н¬КұОӘёГ·юОсЙиЦГБЛТ»ёцёәФШҫщәвөДIPЈЁ78.11.24.19Ј©Ј¬ЛщУР·ГОКёГ·юОсөДУҰУГЈ¬НЁ№эёГёәФШҫщәвIPөШЦ·¶јҝЙТФ·ГОКөҪёГService¶ФУҰөДPodјҜәПЦРөДИЭЖч·юОсЈЁУҰУГ·юОсЈ©ЎЈ
ReplicationController/ReplicaSet
ФЪKubernetesјҜИәЦРЈ¬ReplicationControllerДЬ№»И·ұЈФЪИОТвКұҝМЈ¬Цё¶ЁКэБҝөДPodёұұҫХэФЪФЛРРЎЈИз№ыPodёұұҫөДКэБҝ№э¶аЈ¬ФтReplicationController»бKillөфІҝ·ЦК№ЖдКэБҝУлФӨЖЪұЈіЦТ»ЦВЈ¬Из№ыPodКэБҝ№эЙЩЈ¬Фт»бЧФ¶ҜҙҙҪЁРВөДPodёұұҫТФУлФӨЖЪКэБҝПаН¬ЎЈПВГжКЗТ»ёцReplicationControllerөДЕдЦГКҫАэЈ¬ИзПВЛщКҫЈә
apiVersion: v1
kind: ReplicationController
metadata:
name: nginx
spec:
replicas: 3
selector:
app: nginx
template:
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80 |
ReplicaSetКЗReplicationControllerөДПВТ»ҙъКөПЦЈ¬ЛьГЗЦ®јдГ»УРұҫЦКөДЗшұрЈ¬іэБЛReplicaSetЦ§іЦФЪselectorЦРНЁ№эјҜәПөД·ҪКҪҪшРРЕдЦГЎЈФЪРВ°жұҫөДKubernetesЦРЦ§іЦІўҪЁТйК№УГReplicaSetЈ¬¶шЗТОТГЗУҰёГҫЎБҝК№УГDeploymentАҙ№ЬАнТ»ёцReplicaSetЎЈПВГж¶ЁТеТ»ёцReplicaSetЈ¬¶ФУҰөДЕдЦГКҫАэИзПВЛщКҫЈә
apiVersion: extensions/v1beta1
kind: ReplicaSet
metadata:
name: frontend
labels:
app: guestbook
tier: frontend
spec:
replicas: 3.
selector:
matchLabels:
tier: frontend
matchExpressions:
- {key: tier, operator: In, values: [frontend]}
template:
metadata:
labels:
app: guestbook
tier: frontend
spec:
containers:
- name: php-redis
image: gcr.io/google_samples/gb-frontend:v3
resources:
requests:
cpu: 100m
memory: 100Mi
env:
- name: GET_HOSTS_FROM
value: dns
ports:
- containerPort: 80 |
Volume
Д¬ИПЗйҝцПВИЭЖчөДКэҫЭ¶јКЗ·ЗіЦҫГ»ҜөДЈ¬ФЪИЭЖчПъ»ЩТФәуКэҫЭТІ»б¶ӘК§Ј¬ЛщТФDockerМṩБЛVolume»ъЦЖАҙКөПЦКэҫЭөДіЦҫГ»ҜҙжҙўЎЈН¬СщЈ¬KubernetesМṩБЛёьЗҝҙуөДVolume»ъЦЖәН·бё»өДІејюЈ¬КөПЦБЛИЭЖчКэҫЭөДіЦҫГ»ҜЈ¬ТФј°ФЪИЭЖчЦ®јд№ІПнКэҫЭЎЈ
Kubernetes VolumeҫЯУРПФКҪөДЙъГьЦЬЖЪЈ¬ЛьУлPodөДЙъГьЦЬЖЪКЗПаН¬өДЈ¬ЛщТФЦ»ТӘPod»№ҙҰУЪФЛРРЧҙМ¬Ј¬ФтёГPodДЪІҝөДЛщУРИЭЖч¶јДЬ№»·ГОКёГVolumeЈ¬јҙК№ёГPodЦРөДДіёцИЭЖчК§°ЬЈ¬КэҫЭТІІ»»б¶ӘК§ЎЈ
KubernetesЦ§іЦ¶аЦЦАаРНөДVolumeЈ¬ИзПВЛщКҫЈә
- emptyDir
- hostPath
- gcePersistentDisk
- awsElasticBlockStore
- nfs
- iscsi
- fc (fibre channel)
- flocker
- glusterfs
- rbd
- cephfs
- gitRepo
- secret
- persistentVolumeClaim
- downwardAPI
- projected
- azureFileVolume
- azureDisk
- vsphereVolume
- Quobyte
- PortworxVolume
- ScaleIO
- StorageOS
- local
ЙПГжёчЦЦАаРНөДЛөГчәНКҫАэЈ¬ҝЙТФІОҝј№Щ·ҪОДөөЎЈVolumeКЗУлPodУР№ШөДЈ¬ЛщТФХвАпОТГЗёшіцТ»ёцPod¶ЁТеөДЕдЦГКҫАэЈ¬К№УГБЛhostPathАаРНөДVolumeЈ¬ИзПВЛщКҫЈә
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: gcr.io/google_containers/test-webserver
name: test-container
volumeMounts:
- mountPath: /test-pd
name: test-volume
volumes:
- name: test-volume
hostPath:
# directory location on host
path: /data |
ЙПГж¶ЁТеЦРЈ¬Цё¶ЁБЛPodЦРИЭЖчК№УГөДNodeҪЪөгЙПөДdataҙжҙўВ·ҫ¶ЎЈ
Deployment
DeploymentМṩБЛЙщГчКҪөД·Ҫ·ЁЈ¬¶ФPodәНReplicaSetҪшРРёьРВЈ¬ОТГЗЦ»РиТӘФЪDeployment¶ФПуЦРЙиЦГәГФӨЖЪөДЧҙМ¬Ј¬И»әуDeploymentҫНДЬ№»ҝШЦЖҪ«КөјКөДЧҙМ¬ұЈіЦУлФӨЖЪЧҙМ¬Т»ЦВЎЈК№УГDeploymentөДөдРНіЎҫ°Ј¬УРИзПВјёёцЈә
- ҙҙҪЁReplicaSetЈ¬Ҫш¶шНЁ№эReplicaSetЖф¶ҜPodЈ¬Deployment»бјмІйЖф¶ҜЧҙМ¬КЗ·сіЙ№Ұ
- №ц¶ҜЙэј¶»т»Ш№цУҰУГ
- УҰУГА©ИЭ»тЛхИЭ
- ФЭНЈЈЁұИИзРЮёДPodДЈ°еЈ©ј°»ЦёҙDeploymentөДФЛРР
- ёщҫЭDeploymentөДФЛРРЧҙМ¬Ј¬ҝЙТФЕР¶П¶ФУҰөДУҰУГКЗ·сhangЧЎ
- ЗеіэөфІ»ФЩК№УГөДReplicaSet
¶ЁТеТ»ёцDeploymentЈ¬КҫАэИзПВЛщКҫЈә
apiVersion: apps/v1beta1 # for versions before 1.6.0 use extensions/v1beta1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80 |
ЙПКцЕдЦГҙҙҪЁТ»ёцReplicaSetЈ¬Ҫш¶шЖф¶Ҝ3ёцNginx PodЎЈ
DaemonSet
DaemonSetДЬ№»ұЈЦӨKubernetesјҜИәЦРДіР©NodeЈ¬»тХЯИ«ІҝNodeЙП¶јФЛРРТ»ёцPodёұұҫЈ¬өұјҜИәЦРДіёцNodeұ»ТЖіэКұЈ¬ёГNodeЙПөДPodёұұҫТІ»бұ»ЗеАнөфЎЈЙҫіэТ»ёцDaemonSetЈ¬ТІ»б°С¶ФУҰөДPod¶јЙҫіэөфЎЈ
НЁіЈЈ¬DaemonSet»бұ»УГУЪИзПВіЎҫ°ЈЁФЪKubernetesјҜИәЦРГҝёцNodeЙПЈ©Јә
- ФЛРРТ»ёцҙжҙўDaemonЈ¬ИзglusterdЎўcephөИ
- ФЛРРТ»ёцИХЦҫКХјҜDaemonЈ¬ИзfluentdЎўlogstashөИ
- ФЛРРТ»ёцјаҝШDaemonЈ¬ИзcollectdЎўgmondөИ
¶ЁТеТ»ёцDaemonSetЈ¬КҫАэИзПВЛщКҫЈә
apiVersion: apps/v1beta1
kind: DaemonSet
metadata:
name: fluentd
spec:
template:
metadata:
labels:
app: logging
id: fluentd
name: fluentd
spec:
containers:
- name: fluentd-es
image: gcr.io/google_containers/fluentd-elasticsearch:1.3
env:
- name: FLUENTD_ARGS
value: -qq
volumeMounts:
- name: containers
mountPath: /var/lib/docker/containers
- name: varlog
mountPath: /varlog
volumes:
- hostPath:
path: /var/lib/docker/containers
name: containers
- hostPath:
path: /var/log
name: varlog |
ЙПГжАэЧУЈ¬ҙҙҪЁБЛТ»ёц»щУЪfluentdөДИХЦҫКХјҜDaemonSetЎЈ
StatefulSet
StatefulSetКЗKubernetes v1.5°жұҫРВФцөДЈ¬ФЪv1.5Ц®З°өД°жұҫҪРЧцPetSetЈЁК№УГv1.4°жұҫҝЙТФК№УГЈ¬ҫЯМеҝЙТФІйҝҙ№Щ·ҪОДөөЈ¬ХвАпІ»ФЩАЫКцЈ©Ј¬КЗОӘБЛҪвҫцУРЧҙМ¬·юОсөДОКМвЈЁ¶ФУҰОЮЧҙМ¬·юОсөДKubernetes¶ФПуЈәDeploymentәНReplicaSetЈ©Ј¬ЖдУҰУГіЎҫ°°ьАЁЈә
- ОИ¶ЁөДіЦҫГ»ҜҙжҙўЈ¬јҙPodЦШРВөч¶Иәу»№КЗДЬ·ГОКөҪПаН¬өДіЦҫГ»ҜКэҫЭЈ¬»щУЪPVCАҙКөПЦ
- ОИ¶ЁөДНшВзұкЦҫЈ¬јҙPodЦШРВөч¶ИәуЖдPodNameәНHostNameІ»ұдЈ¬»щУЪHeadless ServiceЈЁјҙГ»УРCluster IPөДServiceЈ©АҙКөПЦ
- УРРтІҝКрЈ¬УРРтА©Х№Ј¬јҙPodКЗУРЛіРтөДЈ¬ФЪІҝКр»тХЯА©Х№өДКұәтТӘТАҫЭ¶ЁТеөДЛіРтТАҙОҪшРРЈ¬»щУЪinit containersАҙКөПЦ
- УРРтЛхИЭЈ¬УРРтЙҫіэ
ОӘБЛЛөГчStatefulSetЈ¬ОТГЗПИ¶ЁТеТ»ёцГыіЖОӘnginxөДHeadless ServiceЈ¬ИзПВЛщКҫЈә
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx |
ФЩ¶ЁТеТ»ёцГыіЖОӘwebөДStatefulSetЈ¬¶ЁТеБЛТӘФЪ3ёц¶АБўөДPodЦР·ЦұрҙҙҪЁ3ёцnginxИЭЖчЈ¬КҫАэИзПВЛщКҫЈә
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
terminationGracePeriodSeconds:
containers:
- name: nginx
image: gcr.io/google_containers/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
annotations:
volume.beta.kubernetes.io/storage-class: anything
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi |
ЙПГжКҫАэЈ¬ФЪServiceЦРТэУГБЛГыіЖОӘwebөДStatefulSetЈ¬ёГService¶ФУҰөДҙжҙўРЕПўКЗУРЧҙМ¬өДЈ¬НЁ№эStatefulSetДЬ№»ұЈЦӨServiceЦРөДPodК§°ЬТІІ»»б¶ӘК§ҙжҙўөДКэҫЭЈ¬ЛьНЁ№эPersistentVolumeАҙМṩОИ¶ЁҙжҙўөДЎЈ
ConfigMap
УҰУГіМРт»бҙУЕдЦГОДјюЎўГьБоРРІОКэ»т»·ҫіұдБҝЦР¶БИЎЕдЦГРЕПўЈ¬Из№ыҪ«ХвР©ЕдЦГРЕПўЦұҪУРҙФЪDockerҫөПсЦРЈ¬»б·ЗіЈІ»Бй»оЈ¬ГҝҙОРЮёДЕдЦГРЕПў¶јТӘЦШРВҙҙҪЁТ»ёцDockerҫөПсЎЈConfigMapөДіцПЦЈ¬ДЬ№»К№ЕдЦГРЕПўУлDockerҫөПсҪвсоЈ¬ёьјУ·ҪұгәНБй»оЎЈ
ФЪ¶ЁТеТ»ёцPodөДКұәтЈ¬ҝЙТФК№УГConfigMap¶ФПуЦРөДЕдЦГКэҫЭЈ¬УРәЬ¶аЦЦ·ҪКҪЈ¬ИзПВЛщКҫЈә
- ҙУТ»ёцConfigMapЦР¶БИЎјьЦө¶ФЕдЦГКэҫЭ
- ҙУ¶аёцConfigMapЦР¶БИЎјьЦө¶ФЕдЦГКэҫЭ
- ҙУТ»ёцConfigMapЦР¶БИЎИ«ІҝөДјьЦө¶ФЕдЦГКэҫЭ
- Ҫ«Т»ёцConfigMapЦРөДЕдЦГКэҫЭјУИлөҪТ»ёцVolumeЦР
ПВГжёшіцЖдЦР2ЦЦК№УГ·ҪКҪЈә
- ¶ЁТеТ»ёц»·ҫіұдБҝЈ¬ёГұдБҝЦөУіЙдөҪТ»ёцConfigMap¶ФПуЦРөДЕдЦГЦө
ҙҙҪЁТ»ёцГыіЖОӘspecial-configөДConfigMap¶ФПуЈ¬ЦҙРРИзПВГьБоЈә
| kubectl create configmap special-config --from-literal=special.how=very |
ФЪЙПКцConfigMap¶ФПуspecial-configЦРҙҙҪЁБЛТ»ёцјьspecial.howЈ¬Ль¶ФУҰөДЦөОӘveryЎЈ
И»әуЈ¬ОТГЗ¶ЁТеТ»ёцPodЈ¬Ҫ«ConfigMapЦРөДјьspecial.how¶ФУҰөДЦөЈ¬ёіЦөёш»·ҫіұдБҝSPECIAL_LEVEL_KEYЈ¬Pod¶ЁТеОДјюДЪИЭЈ¬ИзПВЛщКҫЈә
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: gcr.io/google_containers/busybox
command: [ "/bin/sh", "-c", "env" ]
env:
# Define the environment variable
- name: SPECIAL_LEVEL_KEY
valueFrom:
configMapKeyRef:
# The ConfigMap containing the value you want to assign to SPECIAL_LEVEL_KEY
name: special-config
# Specify the key associated with the value
key: special.how
restartPolicy: Never |
ХвКұЈ¬PodҙҙҪЁТФәуЈ¬ҫНҝЙТФ»сИЎөҪ¶ФУҰөД»·ҫіұдБҝөДЦөЈәSPECIAL_LEVEL_KEY=veryЎЈ
ҙҙҪЁ¶аёцConfigMap¶ФПуЈ¬PodҙУ¶аёцConfigMap¶ФПуЦР¶БИЎөҪ¶ФУҰөДЕдЦГЦө
КЧПИЈ¬ҙҙҪЁөЪТ»ёцConfigMap¶ФПуspecial-configЈ¬ёГ¶ФПу¶ЁТеБЛЕдЦГКэҫЭspecial.how=veryЈ¬ИзПВЛщКҫЈә
apiVersion: v1
kind: ConfigMap
metadata:
name: special-config
namespace: default
data:
special.how: very |
И»әуЈ¬ҙҙҪЁөЪ¶юёцConfigMap¶ФПуenv-configЈ¬ёГ¶ФПу¶ЁТеБЛЕдЦГКэҫЭlog_level=INFOЈ¬ИзПВЛщКҫЈә
apiVersion: v1
kind: ConfigMap
metadata:
name: env-config
namespace: default
data:
log_level: INFO |
ЧоәуЈ¬ҫНҝЙТФФЪPodЦР¶ЁТе»·ҫіұдБҝЈ¬ИзПВЛщКҫЈә
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: gcr.io/google_containers/busybox
command: [ "/bin/sh", "-c", "env" ]
env:
- name: SPECIAL_LEVEL_KEY
valueFrom:
configMapKeyRef:
name: special-config
key: special.how
- name: LOG_LEVEL
valueFrom:
configMapKeyRef:
name: env-config
key: special.type
restartPolicy: Never |
ФЪPodҙҙҪЁәуЈ¬ҝЙТФ·ЦұрҙУspecial-configЎўenv-configЦР¶БИЎ»·ҫіұдБҝөДЦөЈәSPECIAL_LEVEL_KEY=veryЎўLOG_LEVEL=INFOЎЈ
Secret
Secret¶ФПуУГАҙұЈҙжТ»Р©ГфёРРЕПўЈ¬ұИИзГЬВлЎўOAuthБоЕЖЎўsshГШФҝөИЈ¬ЛдИ»ХвР©ГфёРРЕПўҝЙТФ·ЕөҪPod¶ЁТеЦРЈ¬»тХЯDockerҫөПсЦРЈ¬ө«КЗ·ЕөҪSecret¶ФПуЦРёьјУ°ІИ«әНБй»оЎЈ
К№УГSecret¶ФПуКұЈ¬ҝЙТФФЪPodЦРТэУГҙҙҪЁөДSecret¶ФПуЈ¬ЦчТӘУРИзПВБҪЦЦ·ҪКҪЈә
- №ТФШөҪТ»ёц»т¶аёцИЭЖчөДVolumeЦРөДОДјюАпГж
- өұОӘТ»ёцPodАӯИЎҫөПсКұЈ¬ұ»kubectlК№УГ
ҝЙТФНЁ№эҪ«Secret№ТФШөҪVolumeЦРЈ¬»тХЯТФ»·ҫіұдБҝөДРОКҪөјіцЈ¬Аҙұ»Т»ёцPodЦРөДИЭЖчК№УГЎЈПВГжКЗТ»ёцКҫАэЈ¬ФЪТ»ёцPodЦРөДVolumeЙП№ТФШТ»ёцSecretЈ¬ИзПВЛщКҫЈә
{
"apiVersion": "v1",
"kind": "Pod",
"metadata": {
"name": "mypod",
"namespace": "myns"
},
"spec": {
"containers": [{
"name": "mypod",
"image": "redis",
"volumeMounts": [{
"name": "foo",
"mountPath": "/etc/foo",
"readOnly": true
}]
}],
"volumes": [{
"name": "foo",
"secret": {
"secretName": "mysecret"
}
}]
}
} |
НЁ№эөјіц»·ҫіұдБҝЈ¬К№УГSecretЈ¬КҫАэИзПВЛщКҫЈә
apiVersion: v1
kind: Pod
metadata:
name: secret-env-pod
spec:
containers:
- name: mycontainer
image: redis
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: mysecret
key: username
- name: SECRET_PASSWORD
valueFrom:
secretKeyRef:
name: mysecret
key: password
restartPolicy: Never |
ЖдЛьУР№ШSecretөДёьПкПёРЕПўЈ¬ҝЙТФІОҝј№ЩНшОДөөЎЈ
Job
Т»ёцJob»бҙҙҪЁТ»ёц»т¶аёцPodЈ¬ІўИ·ұЈЦё¶ЁКэДҝөДPodДЬ№»ФЛРРіЙ№ҰЎЈJob»бёъЧЩГҝёцPodөДФЛРРЈ¬ЦұөҪЖдФЛРРіЙ№ҰЈ¬Из№ыёГJobёъЧЩөД¶аёцPod¶јФЛРРіЙ№ҰЈ¬ФтёГJobҫНұдОӘНкіЙЧҙМ¬ЎЈЙҫіэТ»ёцJobЈ¬ёГJobҙҙҪЁөДPod¶ј»бұ»ЗеАнөфЎЈ
¶ЁТеТ»ёцJobЈ¬КҫАэИзПВЛщКҫЈә
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
metadata:
name: pi
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never |
CronJob
CrontabУГАҙ№ЬАн¶ЁКұJobЈ¬ЦчТӘК№УГіЎҫ°ИзПВЈә
- ФЪТ»ёцёш¶ЁөДКұјдөгЈ¬өч¶ИJobФЛРР
- ҙҙҪЁТ»ёцЦЬЖЪРФФЛРРөДJobЈ¬АэИзКэҫЭҝвұё·ЭЎў·ўЛНУКјюөИөИ
¶ЁТеТ»ёцCronJobЈ¬КҫАэЕдЦГДЪИЭИзПВЛщКҫЈә
apiVersion: batch/v2alpha1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure |
ЙПГжCronJobФЛРРЈ¬»б¶ЁКұЦҙРРТ»ёцBashГьБоРРКдіцЧЦ·ыҙ®Ў°Hello from the Kubernetes clusterЎұЎЈ
Ingress
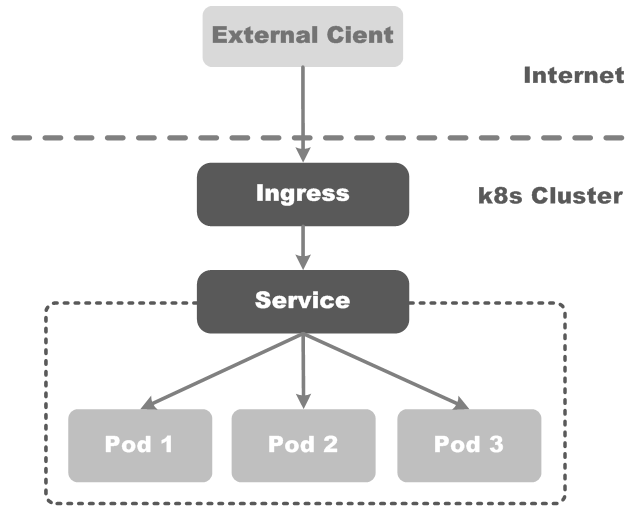
НЁіЈЗйҝцПВЈ¬ServiceәНPodҪцҝЙФЪјҜИәДЪІҝНшВзЦРНЁ№эIPөШЦ··ГОКЎЈЛщУРөҪҙпEdge routerөДБчБҝ»тұ»¶ӘЖъ»тұ»ЧӘ·ўөҪЖдЛьөШ·ҪЎЈТ»ёцIngressКЗТ»Чй№жФтөДјҜәПЈ¬ХвР©№жФтФКРнНвІҝЗлЗуЈЁ№«Нш·ГОКЈ©ЦұҪУБ¬ҪУөҪKubernetesјҜИәДЪІҝөДServiceЈ¬ИзПВНјЛщКҫЈә
ОТГЗҝЙТФЕдЦГIngressЈ¬ОӘЛьМṩНвІҝЈЁ№«НшЈ©ҝЙ·ГОКёш¶ЁServiceөД№жФтЈ¬ИзService URLЎўёәФШҫщәвЎўSSLЎў»щУЪГыіЖөДРйДвЦч»ъөИЎЈУГ»§ПлТӘ»щУЪPOST·ҪКҪЗлЗуIngressЧКФҙЈ¬РиТӘНЁ№э·ГОКKubernetes API ServerАҙІЩЧчIngressЧКФҙЎЈ
Ingress ControllerКЗТ»ёцdaemonҪшіМЈ¬ЛьКЗНЁ№эKubernetes PodАҙҪшРРІҝКрөДЎЈЛьёәФрКөПЦIngressЈ¬НЁіЈК№УГёәФШҫщәвЖчЈ¬»№ҝЙТФЕдЦГEdge routerәНЖдЛыЗ°¶ЛЈЁfrontendsЈ©Ј¬ТФёЯҝЙУГЈЁHAЈ©өД·ҪКҪАҙҙҰАнЗлЗуЎЈОӘБЛДЬ№»К№Ingress№ӨЧчЈ¬KubernetesјҜИәЦРұШРлТӘУРёцТ»ёцIngress ControllerФЪФЛРРЈ¬І»Н¬УЪkube-controller-managerЛщ№ЬАнөДControllerЈ¬ОТГЗұШРлТӘСЎФсТ»ёцККәПОТГЗKubernetesјҜИәөДIngress ControllerКөПЦЈ¬Из№ыГ»УРәПККөДҫНРиТӘҝӘ·ўКөПЦТ»ёцЎЈ
¶ЁТеТ»ёцIngressЈ¬КҫАэИзПВЛщКҫЈә
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test-ingress
spec:
rules:
- http:
paths:
- path: /testpath
backend:
serviceName: test
servicePort: 80 |
ЙПГжrulesЕдЦГБЛIngressөД№жФтБРұнЈ¬ДҝЗ°Ц»Ц§іЦHTTP№жФтЈ¬ёГКҫАэК№УГБЛHTTPөДpaths№жФтЈ¬ЛщЗлЗуURLДЬ№»ЖҘЕдЙПpathsЦё¶ЁөДtestpathЈ¬¶ј»бұ»ЧӘ·ўөҪbackendЦё¶ЁөДServiceЙПЎЈ
IngressУРИзПВ5ЦЦАаРНЈә
- өҘService Ingress
- јтөҘЙИіцЈЁfanoutЈ©
- »щУЪГыіЖөДРйДвЦч»ъ
- TLS
- ёәФШҫщәв
ПлТӘКмПӨЙПГж5ЦЦАаРНөДIngressЈ¬ҝЙТФІйФД№Щ·ҪОДөөЈ¬ХвАпІ»ФЩПкКцЎЈ
Horizontal Pod Autoscaler
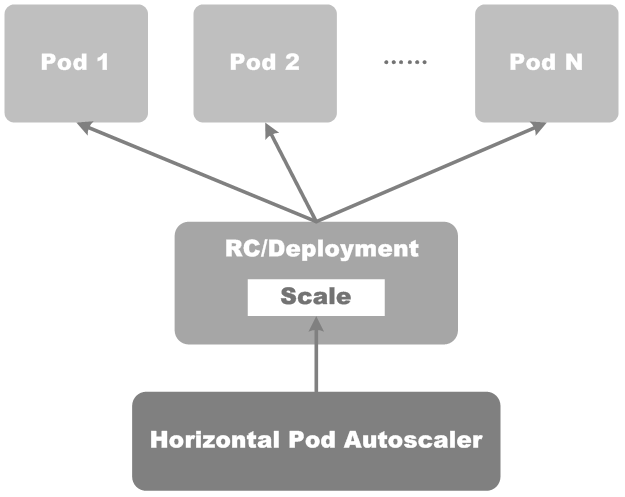
УҰУГФЛРРФЪИЭЖчЦРЈ¬ЛьЛщТААөөДЧКФҙөДК№УГВКНЁіЈІўІ»ҫщәвЈ¬ЧКФҙК№УГБҝУРКұҝЙДЬҙпөҪ·еЦөЈ¬УРКұК№УГөДУЦәЬЙЩЈ¬ОӘБЛМбёЯKubernetesјҜИәөДХыМеЧКФҙАыУГВКЈ¬ОТГЗРиТӘServiceЦРөДPodөДёцКэДЬ№»ёщҫЭКөјКЧКФҙК№УГБҝАҙЧФ¶ҜөчХыЎЈХвКұОТГЗҫНҝЙТФК№УГHPAЈЁHorizontal Pod AutoscalingЈ©Ј¬ЛьәНPodЎўDeploymentөИ¶јКЗKubernetes APIЧКФҙЈ¬ДЬКөПЦKubernetesјҜИәДЪServiceЦРPodөДЛ®ЖҪЙмЛхЎЈ
HPAөД№ӨЧчФӯАнЈ¬ИзПВНјЛщКҫЈә
НЁ№эПВГжГьБоЈ¬ҝЙТФ¶ФHPAҪшРРёчЦЦІЩЧчЈЁҙҙҪЁHPAЎўБРіцЛщУРHPAЎў»сИЎHPAПкПёГиКцРЕПўЎўЙҫіэHPAЈ©Јә
kubectl create hpa
kubectl get hpa
kubectl describe hpa
kubectl delete hpa |
БнНвЈ¬»№ҝЙТФНЁ№эkubectl autoscale ГьБоАҙҙҙҪЁHPAЈ¬АэИзЈ¬ЦҙРРИзПВГьБоЈә
| kubectl autoscale rc foo --min=2 --max=5 --cpu-percent=80 |
ЙПГжКҫАэөДГьБоЈ¬ТӘОӘГыіЖОӘfooөДReplicationControllerҙҙҪЁТ»ёцHPA¶ФПуЈ¬К№өГДҝұкCPUАыВКУГОӘ80%Ј¬ІўЗТёұұҫөДКэБҝұЈіЦФЪ2өҪ5Ц®јдЎЈ
kubectl CLI
kubectlКЗТ»ёцГьБоРРҪУҝЪЈ¬НЁ№эЛьҝЙТФЦҙРРГьБоУлKubernetesјҜИәҪ»»ҘЎЈkubectlГьБоөДУп·ЁёсКҪЈ¬ИзПВЛщКҫЈә
| kubectl [command] [TYPE] [NAME] [flags] |
ЙПГжГьБоЛөГчЦРЈә
commandЈәРиТӘФЪТ»ЦЦ»т¶аЦЦЧКФҙЙПЦҙРРөДІЩЧчЈ¬ұИИзЈәcreateЎўgetЎўdescribeЎўdeleteөИөИЈ¬ёьПкПёҝЙТФІОҝј№ЩНшОДөөЎЈ
TYPEЈәЦё¶ЁЧКФҙАаРНЈ¬ҙуРЎРҙГфёРЈ¬өұЗ°Ц§іЦИзПВХвР©АаРНөДЧКФҙЈәcertificatesigningrequestsЎўclustersЎўclusterrolebindingsЎўclusterrolesЎўcomponentstatusesЎўconfigmapsЎўcronjobsЎўdaemonsetsЎўdeploymentsЎўendpointsЎўeventsЎўhorizontalpodautoscalersЎўingressesЎўjobsЎўlimitrangesЎўnamespacesЎўnetworkpoliciesЎўnodesЎўpersistentvolumeclaimsЎўpersistentvolumesЎўpoddisruptionbudgetЎўpodsЎўpodsecuritypoliciesЎўpodtemplatesЎўreplicasetsЎўreplicationcontrollersЎўresourcequotasЎўrolebindingsЎўrolesЎўsecretsЎўserviceaccountsЎўservicesЎўstatefulsetsЎўstorageclassesЎўthirdpartyresourcesЎЈ
NAMEЈәЦё¶ЁЧКФҙөДГыіЖЈ¬ҙуРЎРҙГфёРЎЈ
flagsЈәҝЙСЎЈ¬Цё¶ЁСЎПоұкЦҫЈ¬ұИИзЈә-s»т-serverұнКҫKubernetes API ServerөДIPөШЦ·әН¶ЛҝЪЎЈ
Из№ыПлТӘБЛҪвЙПКцГьБоөДПкПёУГ·ЁЛөГчЈ¬ҝЙТФЦҙРР°пЦъГьБоЈә
БнНвЈ¬»№ҝЙТФНЁ№э№Щ·ҪОДөөЈ¬ёщҫЭК№УГөДKubernetesөДІ»Н¬°жұҫЈ¬АҙІОҝјИзПВБҙҪУ»сИЎ°пЦъЈә
https://kubernetes.io/docs/user-guide/kubectl/v1.7/
https://kubernetes.io/docs/user-guide/kubectl/v1.6/
https://kubernetes.io/docs/user-guide/kubectl/v1.5/
ПВГжЈ¬ҫЩёціЈУГөДГьБоРРІЩЧчЈ¬РиТӘНЁ№эYAMLОДјю¶ЁТеТ»ёцServiceЈЁПкјыЙПОДЎ°»щұҫёЕДоЎұЦРёшіцөДServiceКҫАэЈ©Ј¬ҙҙҪЁТ»ёцServiceЈ¬ЦҙРРИзПВГьБоЈә
| kubectl create -f ./my-k8s-service.yaml |
¶ЁТеИОәОKubernetes¶ФП󣬶јКЗНЁ№эYAMLОДјюИҘЕдЦГЈ¬К№УГАаЛЖЙПКцГьБоҪшРРҙҙҪЁЎЈИз№ыПлТӘІйҝҙҙҙҪЁKubernetes¶ФПуөДҪб№ыЈ¬ұИИзІйҝҙҙҙҪЁService¶ФПуөДҪб№ыЈ¬ҝЙНЁ№эИзПВГьБоІйҝҙЈә
ХвСщЈ¬ҫНДЬҝҙөҪөұЗ°ҙҙҪЁөДService¶ФПуөДЧҙМ¬ЎЈ |





