¥”‘ΤΦΤΥψΒΫΈΔΖΰΈώ‘ΌΒΫ‘Τ‘≠…ζΦΤΥψ
œ¬ΟφΫΪ¥”‘ΤΦΤΥψΒΡΖΔ’Ιάζ≥Χ“ΐ»κ‘Τ‘≠…ζΦΤΥψΘ§«κœ»Ω¥œ¬ΆΦΘΚ
‘ΤΦΤΥψΫι…ή
‘ΤΦΤΥψΑϋΚ§ΒΡΡΎ»ί °Ζ÷Ζ±‘”Θ§“≤”–ΚήΕύΦΦ θΚΆΙΪΥΨ«Θ«ΩΗΑΜαΥΒΉ‘ΦΚ «‘ΤΦΤΥψΙΪΥΨΘ§ΥΒΉ‘ΦΚ «Ήω‘ΤΒΡΘ§ ΒΦ …œΩ…ΡήΖγ¬μ≈Θ≤ΜœύΦΑΓΘΥΒΑΉΝΥΘ§‘ΤΦΤΥψΨΆ «“Μ÷÷≈δ÷ΟΉ ‘¥ΒΡΖΫ ΫΘ§ΗυΨίΉ ‘¥≈δ÷ΟΖΫ ΫΒΡ≤ΜΆ§Έ“Ο«Ω…“‘Α―‘ΤΦΤΥψ¥”ΚξΙέ…œΖ÷ΈΣ“‘œ¬»ΐ÷÷άύ–ΆΘΚ
1.IaaSΘΚ’β «ΈΣΝΥœκ“ΣΫ®ΝΔΉ‘ΦΚΒΡ…Χ“ΒΡΘ Ϋ≤ΔΫχ––Ή‘Ε®“εΒΡΩΆΜßΘ§άΐ»γ―«¬μ―ΖΒΡEC2ΓΔS3¥φ¥ΔΓΔRackspace–ιΡβΜζΒ»ΕΦ «IaaSΓΘ
2.PaaSΘΚΙΛΨΏΚΆΖΰΈώΒΡΦ·ΚœΘ§Ε‘”Ύœκ”ΟΥϋά¥ΙΙΫ®Ή‘ΦΚΒΡ”Π”Ο≥Χ–ρΜρ’ΏœκΩλΥΌΒΟΫΪ”Π”Ο≥Χ–ρ≤Ω πΒΫ…ζ≤ζΜΖΨ≥Εχ≤Μ±ΊΙΊ–ΡΒΉ≤ψ”≤ΦΰΒΡ”ΟΜßΚΆΩΣΖΔ’Ώά¥ΥΒ «ΧΊ±π”–”ΟΒΡΘ§±»»γCloud
FoundryΓΔGoogle App EngineΓΔHerokuΒ»ΓΘ
3.SaaSΘΚ÷’ΕΥ”ΟΜßΩ…“‘÷±Ϋ” Ι”ΟΒΡ”Π”Ο≥Χ–ρΓΘ’βΗωΨΆΧΪΕύΘ§Έ“Ο«…ζΜν÷–”ΟΒΫΒΡΚήΕύ»μΦΰΕΦ «SaaSΖΰΈώΘ§÷Μ“ΣΜυ”ΎΜΞΝΣΆχά¥ΧαΙ©ΒΡΖΰΈώΜυ±ΨΕΦ «SaaSΖΰΈώΘ§”–ΒΡΖΰΈώ «ΟβΖ―ΒΡΘ§±»»γGoogle
DocsΘ§ΜΙ”–ΗϋΕύΒΡ «ΗυΨίΈ“Ο«ΙΚ¬ρΒΡPlanΚΆ Ι”ΟΝΩΗΕΖ―Θ§±»»γGitHubΓΔΗς÷÷‘Τ¥φ¥ΔΓΘ
ΈΔΖΰΈώΫι…ή
ΈΔΖΰΈώΘ®MicroservicesΘ©’βΗω¥ ±»Ϋœ–¬”±Θ§ΒΪ «Τδ Β’β÷÷ΦήΙΙ…ηΦΤάμΡν‘γΨΆ”–ΝΥΓΘΈΔΖΰΈώ «“Μ÷÷Ζ÷≤Φ ΫΦήΙΙ…ηΦΤάμΡνΘ§ΈΣΝΥΆΤΕ·œΗΝΘΕ»ΖΰΈώΒΡ Ι”ΟΘ§’β–©ΖΰΈώ“ΣΡή–≠Ά§ΙΛΉςΘ§ΟΩΗωΖΰΈώΕΦ”–Ή‘ΦΚΒΡ…ζΟϋ÷ήΤΎΓΘ“ΜΗωΈΔΖΰΈώΨΆ «“ΜΗωΕάΝΔΒΡ ΒΧεΘ§Ω…“‘ΕάΝΔΒΡ≤Ω π‘ΎPAASΤΫΧ®…œΘ§“≤Ω…“‘ΉςΈΣ“ΜΗωΕάΝΔΒΡΫχ≥Χ‘Ύ÷ςΜζ÷–‘Υ––ΓΘΖΰΈώ÷°ΦδΆ®ΙΐAPIΖΟΈ Θ§–όΗΡ“ΜΗωΖΰΈώ≤ΜΜα”ΑœλΤδΥϋΖΰΈώΓΘ
“ΣœκΝΥΫβΈΔΖΰΈώΒΡœξœΗΡΎ»ίΆΤΦω‘ΡΕΝΓΕΈΔΖΰΈώ…ηΦΤΓΖΘ®Sam Newman÷χΘ©Θ§Έ“–¥Ιΐ’β±Ψ ιΒΡΕΝ ι± Φ«
- ΈΔΖΰΈώ…ηΦΤΕΝ ι± Φ«ΓΘ
œ¬ΈΡ÷–ΜαΧΗΒΫkubernetes”κΈΔΖΰΈώΒΡΙΊœΒΘ§Τδ÷–kubernetesΒΡserviceΧλ…ζΨΆ Κœ”κΈΔΖΰΈώΓΘ
‘Τ‘≠…ζΗ≈ΡνΫι…ή
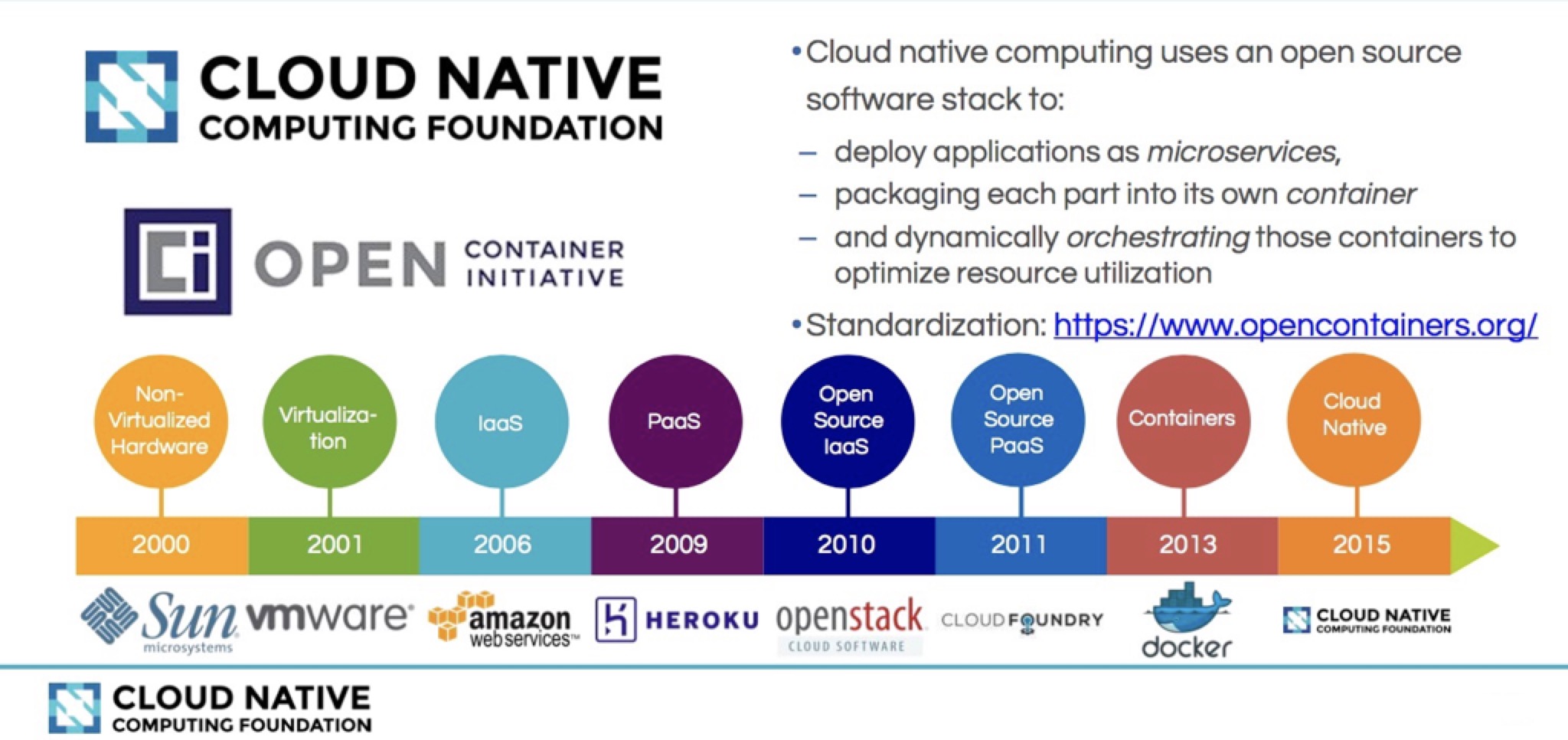
œ¬Οφ «Cloud NativeΗ≈ΡνΥΦΈ§ΒΦΆΦ
‘Τ‘≠…ζΉΦ»Ζά¥ΥΒ «“Μ÷÷ΈΡΜ·Θ§Ηϋ «“Μ÷÷≥±ΝςΘ§Υϋ «‘ΤΦΤΥψΒΡ“ΜΗω±Ί»ΜΒΦœρΓΘΥϋΒΡ“β“ε‘Ύ”Ύ»Ο‘Τ≥…ΈΣ‘ΤΜ·’Ϋ¬‘≥…ΙΠΒΡΜυ ·Θ§Εχ≤Μ «ΉηΑ≠Θ§»γΙϊ“ΒΈώ”Π”Ο…œ‘Τ÷°ΚσΩΣΖΔΚΆ‘ΥΈ§»Υ‘±±»‘≠œ»ΜΙΆ¥ΩύΘ§≥…±ΨΗΏΤσΒΡΜΑΘ§’β―υΒΡ‘ΤΈ“Ο«Ρΰ‘Η≤Μ≤Μ…œΓΘ
Ή‘¥”‘ΤΒΡΗ≈ΡνΩΣ ΦΤ’ΦΑΘ§–μΕύΙΪΥΨΕΦ≤Ω πΝΥ Β ©‘ΤΜ·ΒΡ≤Ώ¬‘Θ§ΖΉΖΉ¥νΫ®Τπ‘ΤΤΫΧ®Θ§œΘΆϊΆξ≥…¥ΪΆ≥”Π”ΟΒΫ‘ΤΕΥΒΡ«®“ΤΓΘΒΪ «’βΗωΙΐ≥Χ÷–Μα”ωΒΫ“Μ–©ΦΦ θΡ―ΧβΘ§…œ‘Τ“‘ΚσΘ§–߬ ≤ΔΟΜ”–±δΒΟΤφΗΏΘ§Ι ’œ“≤ΟΜ”–―ΗΥΌΕ®ΈΜΓΘ
ΈΣΝΥΫβΨω¥ΪΆ≥”Π”Ο…ΐΦΕΜΚ¬ΐΓΔΦήΙΙ”Ζ÷ΉΓΔ≤ΜΡήΩλΥΌΒϋ¥ζΓΔΙ ’œ≤ΜΡήΩλΥΌΕ®ΈΜΓΔΈ ΧβΈόΖ®ΩλΥΌΫβΨωΒ»Έ ΧβΘ§‘Τ‘≠…ζ’β“ΜΗ≈ΡνΚαΩ’≥ω άΓΘ‘Τ‘≠…ζΩ…“‘ΗΡΫχ”Π”ΟΩΣΖΔΒΡ–ß¬ Θ§ΗΡ±δΤσ“ΒΒΡΉι÷·ΫαΙΙΘ§…θ÷ΝΜα‘ΎΈΡΜ·≤ψΟφ…œ÷±Ϋ””Αœλ“ΜΗωΙΪΥΨΒΡΨω≤ΏΓΘ
ΝμΆβΘ§‘Τ‘≠…ζ“≤ΚήΚΟΒΊΫβ ΆΝΥ‘Τ…œ‘Υ––ΒΡ”Π”Ο”ΠΗΟΨΏ±Η ≤Ο¥―υΒΡΦήΙΙΧΊ–‘ΓΣΓΣΟτΫί–‘ΓΔΩ…ά©’Ι–‘ΓΔΙ ’œΩ…Μ÷Η¥–‘ΓΘ
Ήέ…œΥυ ωΘ§‘Τ‘≠…ζ”Π”Ο”ΠΗΟΨΏ±Η“‘œ¬ΦΗΗωΙΊΦϋ¥ ΘΚ
1.ΟτΫί
2.Ω…ΩΩ
3.ΗΏΒ·–‘
4.“Ήά©’Ι
5.Ι ’œΗτάκ±ΘΜΛ
6.≤Μ÷–Εœ“ΒΈώ≥÷–χΗϋ–¬
“‘…œΧΊ–‘“≤ «‘Τ‘≠…ζ«χ±π”Ύ¥ΪΆ≥‘Τ”Π”ΟΒΡ”≈ ΤΧΊΒψΓΘ
¥”ΚξΙέΗ≈Ρν…œΫ≤Θ§‘Τ‘≠…ζ «≤ΜΆ§ΥΦœκΒΡΦ·ΚœΘ§Φ·ΡΩ«ΑΗς÷÷»»Ο≈ΦΦ θ÷°¥σ≥…Θ§ΨΏΧεΑϋά®»γœ¬ΆΦΥυ ΨΒΡΦΗΗω≤ΩΖ÷ΓΘ
Kubernetes”κ‘Τ‘≠…ζΒΡΙΊœΒ
KuberentesΩ…“‘ΥΒ «≥ΥΉ≈dockerΚΆΈΔΖΰΈώΒΡΕΪΖγΘ§“―Ψ≠ΆΤ≥ω±ψ―ΗΥΌ¥ΎΚλΘ§ΥϋΒΡΚήΕύ…ηΦΤΥΦœκΕΦΤθΚœΝΥΈΔΖΰΈώΚΆ‘Τ‘≠…ζ”Π”ΟΒΡ…ηΦΤΖ®‘ρΘ§’βΤδ÷–Ήν÷χΟϊΒΡΨΆ «ΩΣΖΔΝΥHeroku
PaaSΤΫΧ®ΒΡΙΛ≥Χ ΠΟ«ΉήΫαΒΡ Twelve-factor AppΝΥΓΘ
œ¬ΟφΈ“ΫΪΫ≤ΫβKubernetes…ηΦΤ ± «»γΚΈΑ¥’’ΝΥ °Εΰ“ρΥΊ”Π”ΟΖ®‘ρΘ§≤ΔΗχ≥ωkubernetes÷–ΒΡ”Π”Ο ΨάΐΘ§≤ΔΗΫ…œ“ΜΨδΜΑΦρΕΧΒΡΫι…ήΓΘ
KubernetesΫι…ή
Kubernetes «GoogleΜυ”ΎBorgΩΣ‘¥ΒΡ»ίΤς±ύ≈≈ΒςΕ»“ΐ«φΘ§ΉςΈΣCNCFΘ®Cloud Native
Computing FoundationΘ©Ήν÷Ί“ΣΒΡΉιΦΰ÷°“ΜΘ§ΥϋΒΡΡΩ±ξ≤ΜΫωΫω «“ΜΗω±ύ≈≈œΒΆ≥Θ§Εχ «ΧαΙ©“ΜΗωΙφΖΕΘ§Ω…“‘»ΟΡψά¥Οη ωΦ·»ΚΒΡΦήΙΙΘ§Ε®“εΖΰΈώΒΡΉν÷’Ή¥Χ§Θ§kubernetesΩ…“‘ΑοΡψΫΪœΒΆ≥Ή‘Ε·ΒΟ¥οΒΫΚΆΈ§≥÷‘Ύ’βΗωΉ¥Χ§ΓΘ
Ηϋ÷±ΑΉΒΡΥΒΘ§Kubernetes”ΟΜßΩ…“‘Ά®Ιΐ±ύ–¥“ΜΗωyamlΜρ’ΏjsonΗώ ΫΒΡ≈δ÷ΟΈΡΦΰΘ§“≤Ω…“‘Ά®ΙΐΙΛΨΏ/¥ζ¬κ…ζ≥…Μρ÷±Ϋ”«κ«σkubernetes
API¥¥Ϋ®”Π”ΟΘ§ΗΟ≈δ÷ΟΈΡΦΰ÷–ΑϋΚ§ΝΥ”ΟΜßœκ“Σ”Π”Ο≥Χ–ρ±Θ≥÷ΒΡΉ¥Χ§Θ§≤Μ¬έ’ϊΗωkubernetesΦ·»Κ÷–ΒΡΗω±π÷ςΜζΖΔ…ζ ≤Ο¥Έ ΧβΘ§ΕΦ≤ΜΜα”Αœλ”Π”Ο≥Χ–ρΒΡΉ¥Χ§Θ§ΡψΜΙΩ…“‘Ά®ΙΐΗΡ±δΗΟ≈δ÷ΟΈΡΦΰΜρ«κ«σkubernetes
APIά¥ΗΡ±δ”Π”Ο≥Χ–ρΒΡΉ¥Χ§ΓΘ
12“ρΥΊ”Π”Ο
12“ρΥΊ”Π”ΟΧα≥ω“―Ψ≠”–ΦΗΡξΒΡ ±ΦδΝΥΘ§ΟΩΗω»ΥΕ‘ΤδΩ…ΡήΕΦ”–Ή‘ΦΚΒΡάμΫβΘ§«–≤ΜΩ……ζΑα”≤ΧΉΘ§“≤≤Μ“ΜΕ®Υυ”–‘Τ‘≠…ζ”Π”ΟΕΦ±Ί–κΖϊΚœ’β12ΧθΖ®‘ρΘ§Τδ÷–”–ΦΗΧθΖ®‘ρΩ…ΡήΜΙ”–Βψ’υ“ιΘ§”–»ΥΕ‘ΤδΒΡΫβ ΆΚΆΩ¥Ζ®≤ΜΆ§ΓΘ
¥σΦ“≤Μ“ΣΙ¬ΝΔΒΡά¥Ω¥’βΟΩ“ΜΗω“ρΥΊΘ§ΫΪΤδ”κΉ‘ΦΚ»μΦΰΩΣΖΔΝς≥ΧΝΣœΒΤπά¥Θ§’β12Ηω“ρΥΊ¥σ÷¬ΨΆ «Α¥’’»μΦΰ¥”ΩΣΖΔΒΫΫΜΗΕΒΡΝς≥ΧΥ≥–ρά¥–¥ΒΡΓΘ

1.ΜυΉΦ¥ζ¬κ
ΟΩΗω¥ζ¬κ≤÷ΩβΘ®repoΘ©ΕΦ…ζ≥…docker image±Θ¥φΒΫΨΒœώ≤÷Ωβ÷–Θ§≤Δ Ι”ΟΈ®“ΜΒΡIDΙήάμΘ§‘ΎJenkins÷– Ι”Ο±ύ“κ ±ΒΡIDΓΘ
2.“άάΒ
œ‘ ΫΒΟ…υΟς¥ζ¬κ÷–ΒΡ“άάΒΘ§ Ι”Ο»μΦΰΑϋΙήάμΙΛΨΏ…υΟςΘ§±»»γGo÷–ΒΡGlideΓΘ
3.≈δ÷Ο
ΫΪ≈δ÷Ο”κ¥ζ¬κΖ÷άκΘ§”Π”Ο≤Ω πΒΫkubernete÷–Ω…“‘ Ι”Ο»ίΤςΒΡΜΖΨ≥±δΝΩΜρConfigMapΙ“‘ΊΒΫ»ίΤς÷–ΓΘ
4.ΚσΕΥΖΰΈώ
Α―ΚσΕΥΖΰΈώΒ±ΉςΗΫΦ”Ή ‘¥Θ§ Β÷ …œ «ΦΤΥψ¥φ¥ΔΖ÷άκΚΆΫΒΒΆΖΰΈώώνΚœΘ§Ζ÷ΫβΒΞΧε”Π”ΟΓΘ
5.ΙΙΫ®ΓΔΖΔ≤ΦΓΔ‘Υ––
―œΗώΖ÷άκΙΙΫ®ΚΆ‘Υ––Θ§ΟΩ¥Έ–όΗΡ¥ζ¬κ…ζ≥…–¬ΒΡΨΒœώΘ§÷Ί–¬ΖΔ≤ΦΘ§≤ΜΡή÷±Ϋ”–όΗΡ‘Υ–– ±ΒΡ¥ζ¬κΚΆ≈δ÷ΟΓΘ
6.Ϋχ≥Χ
”Π”Ο≥Χ–ρΫχ≥Χ”ΠΗΟ «ΈόΉ¥Χ§ΒΡΘ§’β“βΈΕΉ≈‘Ό¥Έ÷ΊΤτΚσΜΙΩ…“‘ΦΤΥψ≥ω‘≠œ»ΒΡΉ¥Χ§ΓΘ
7.ΕΥΩΎΑσΕ®
‘Ύkubernetes÷–ΟΩΗωPodΕΦ”–ΕάΝΔΒΡIPΘ§ΟΩΗω‘Υ––‘ΎPod÷–ΒΡ”Π”Ο≤Μ±ΊΙΊ–ΡΕΥΩΎ «Ζώ÷ΊΗ¥Θ§÷Μ–η‘Ύservice÷–÷ΗΕ®ΕΥΩΎΘ§Φ·»ΚΡΎΒΡserviceΆ®Ιΐ≈δ÷ΟΜΞœύΖΔœ÷ΓΘ
8.≤ΔΖΔ
ΟΩΗω»ίΤςΕΦ «“ΜΗωΫχ≥ΧΘ§Ά®Ιΐ‘ωΦ”»ίΤςΒΡΗ±±Ψ ΐ Βœ÷≤ΔΖΔΓΘ
9.“Ή¥Πάμ
ΩλΥΌΤτΕ·ΚΆ”≈―≈÷’÷ΙΩ…Ήν¥σΜ·ΫΓΉ≥–‘Θ§kuberentes”≈–ψΒΡPod…ζ¥φ÷ήΤΎΩΊ÷ΤΓΘ
10.ΩΣΖΔΜΖΨ≥”κœΏ…œΜΖΨ≥Β»Φέ
‘Ύkubernetes÷–Ω…“‘¥¥Ϋ®ΕύΗωnamespaceΘ§ Ι”ΟœύΆ§ΒΡΨΒœώΩ…“‘ΚήΖΫ±ψΒΡΗ¥÷Τ“ΜΧΉΜΖΨ≥≥ωά¥Θ§ΨΒœώΒΡ Ι”ΟΩ…“‘ΚήΖΫ±ψΒΡ≤Ω π“ΜΗωΚσΕΥΖΰΈώΓΘ
11.»’÷Ψ
Α―»’÷ΨΒ±Ής ¬ΦΰΝςΘ§ Ι”Οstdout δ≥ω≤Δ ’Φ·ΜψΨέΤπά¥Θ§άΐ»γΒΫES÷–Ά≥“Μ≤ιΩ¥ΓΘ
12.ΙήάμΫχ≥Χ
ΚσΧ®Ιήάμ»ΈΈώΒ±Ής“Μ¥Έ–‘Ϋχ≥Χ‘Υ––Θ§kubectl execΫχ»κ»ίΤςΡΎ≤Ω≤ΌΉςΓΘ
ΝμΆβΘ§Cloud Native Go ’β±Ψ ιΒΡΉς’ΏΘ§CapitalOneΙΪΥΨΒΡKevin Hoffman‘ΎTalkingData
T11ΖεΜα…œΒΡHigh Level Cloud NativeΒΡ―ίΫ≤÷–Ϋ≤ ωΝΥ‘Τ‘≠…ζ”Π”ΟΒΡ15Ηω“ρΥΊΘ§‘Ύ‘≠œ»ΒΡ12“ρΥΊ”Π”ΟΒΡΜυ¥Γ…œ”÷‘ωΦ”ΝΥ»γœ¬»ΐΗω“ρΥΊΘΚ
API”≈œ»
1.ΖΰΈώΦδΒΡΚœ‘Φ
2.Ά≈Ε”–≠ΉςΒΡΙφ‘Φ
3.ΈΡΒΒΜ·ΓΔΙφΖΕΜ·
4.RESTfulΜρRPC
ΦύΩΊ
1. Β ±ΦύΩΊ‘Ε≥Χ”Π”Ο
2.”Π”Ο–‘ΡήΦύΩΊΘ®APMΘ©
3.”Π”ΟΫΓΩΒΦύΩΊ
4.œΒΆ≥»’÷Ψ
5.≤ΜΫ®“ι‘ΎœΏDebug
»œ÷Λ Ύ»®
1.≤Μ“ΣΒ»ΉνΚσ≤≈»ΞΩΦ¬«”Π”ΟΒΡΑ≤»Ϊ–‘
2.œξœΗ…ηΦΤΓΔΟς»Ζ…υΟςΓΔΈΡΒΒΜ·
3.Bearer tokenΓΔOAuthΓΔOIDC»œ÷Λ
4.≤ΌΉς…σΦΤ
œξΦϊHigh Level Cloud Native From Kevin HoffmanΓΘ
Kubernetes÷–ΒΡΉ ‘¥Ιήάμ”κ»ίΤς…ηΦΤΡΘ Ϋ
KubernetesΆ®Ιΐ…υΟς Ϋ≈δ÷ΟΘ§’φ’ΐ»ΟΩΣΖΔ»Υ‘±ΡήΙΜάμΫβ”Π”ΟΒΡΉ¥Χ§Θ§≤ΔΆ®ΙΐΆ§“ΜΖί≈δ÷ΟΩ…“‘ΝΔ¬μΤτΕ·“ΜΗω“ΜΡΘ“Μ―υΒΡΜΖΨ≥Θ§¥σ¥σΧαΗΏΝΥ”Π”ΟΩΣΖΔΚΆ≤Ω πΒΡ–ß¬ Θ§Τδ÷–kubernetes…ηΦΤΒΡΕύ÷÷Ή ‘¥άύ–ΆΩ…“‘Αο÷ζΈ“Ο«Ε®“ε”Π”ΟΒΡ‘Υ––Ή¥Χ§Θ§≤Δ Ι”ΟΉ ‘¥≈δ÷Οά¥œΗΝΘΕ»ΒΟΟς»Ζœό÷Τ”Π”ΟΒΡΉ ‘¥ Ι”ΟΓΘ
»ίΤςΒΡ…ηΦΤΡΘ Ϋ
KubernetesΧαΙ©ΝΥΕύ÷÷Ή ‘¥Ε‘œσΘ§”ΟΜßΩ…“‘ΗυΨίΉ‘ΦΚ”Π”ΟΒΡΧΊ–‘Φ”“‘―Γ‘ώΓΘ’β–©Ε‘œσ”–ΘΚ
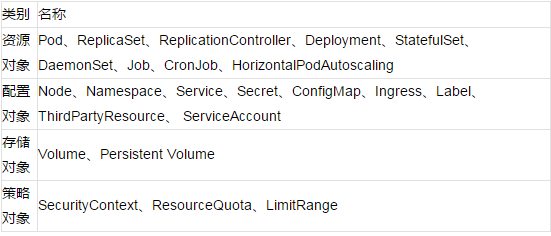
‘Ύ Kubernetes œΒΆ≥÷–Θ§Kubernetes Ε‘œσ «≥÷ΨΟΜ·ΒΡΧθΡΩΓΘKubernetes
Ι”Ο’β–©ΧθΡΩ»Ξ±μ Ψ’ϊΗωΦ·»ΚΒΡΉ¥Χ§ΓΘΧΊ±πΒΊΘ§ΥϋΟ«Οη ωΝΥ»γœ¬–≈œΔΘΚ
1. ≤Ο¥»ίΤςΜ·”Π”Ο‘Ύ‘Υ––Θ®“‘ΦΑ‘ΎΡΡΗω Node …œΘ©
2.Ω…“‘±Μ”Π”Ο Ι”ΟΒΡΉ ‘¥
3.ΙΊ”Ύ”Π”Ο»γΚΈ±μœ÷ΒΡ≤Ώ¬‘Θ§±»»γ÷ΊΤτ≤Ώ¬‘ΓΔ…ΐΦΕ≤Ώ¬‘Θ§“‘ΦΑ»ί¥μ≤Ώ¬‘
Kubernetes Ε‘œσ « ΓΑΡΩ±ξ–‘Φ«¬ΦΓ± ΓΣΓΣ “ΜΒ©¥¥Ϋ®Ε‘œσΘ§Kubernetes œΒΆ≥ΫΪ≥÷–χΙΛΉς“‘»Ζ±ΘΕ‘œσ¥φ‘ΎΓΘΆ®Ιΐ¥¥Ϋ®Ε‘œσΘ§Ω…“‘”––ßΒΊΗφ÷Σ
Kubernetes œΒΆ≥Θ§Υυ–η“ΣΒΡΦ·»ΚΙΛΉςΗΚ‘ΊΩ¥Τπά¥ « ≤Ο¥―υΉ”ΒΡΘ§’βΨΆ « Kubernetes Φ·»ΚΒΡ
ΤΎΆϊΉ¥Χ§ΓΘ
œξΦϊKubernetes Handbook - ObjectsΓΘ
Ή ‘¥œό÷Τ”κ≈δΕν
ΝΫ≤ψΒΡΉ ‘¥œό÷Τ”κ≈δ÷Ο
1.PodΦΕ±πΘ§Ήν–ΓΒΡΉ ‘¥ΒςΕ»ΒΞΈΜ
2.NamespaceΦΕ±πΘ§œό÷ΤΉ ‘¥≈δΕνΚΆΟΩΗωPodΒΡΉ ‘¥ Ι”Ο«χΦδ
«κ≤ΈΩΦKubernetes÷–ΒΡResourceQuotaΚΆLimitRange≈δ÷ΟΉ ‘¥œόΕν
ΙήάμKubernetesΦ·»Κ
÷ΙΛ≤Ω πKubernetes «“ΜΗωΚήΦηΨόΒΡΜνΘ§Ρψ–η“ΣΝΥΫβΆχ¬γ≈δ÷ΟΓΔdockerΒΡΑ≤ΉΑ”κ Ι”ΟΓΔΨΒœώ≤÷ΩβΒΡΙΙΫ®ΓΔΫ«…Ϊ÷Λ ιΒΡ¥¥Ϋ®ΓΔkubernetesΒΡΜυ±Ψ‘≠άμΚΆΙΙ≥…ΓΔkubernetes”Π”Ο≥Χ–ρΒΡyamlΈΡΦΰ±ύ–¥Β»ΓΘ
Έ“±ύ–¥ΝΥ“Μ±Ψkubernetes-handbookΩ…Ι©¥σΦ“ΟβΖ―‘ΡΕΝΘ§ΗΟ ιΦ«¬ΦΝΥ±Ψ»Υ¥”ΝψΩΣ Φ―ßœΑΚΆ Ι”ΟKubernetesΒΡ–Ρ¬Ζάζ≥ΧΘ§Ή≈÷Ί”ΎΨ≠―ιΖ÷œμΚΆΉήΫαΘ§Ά§ ±“≤Μα”–œύΙΊΒΡΗ≈ΡνΫβΈωΘ§œΘΆϊΡήΙΜΑο÷ζ¥σΦ“…Ό≤»Ω”Θ§…ΌΉΏΆδ¬ΖΓΘ
≤Ω πKubernetesΦ·»Κ
Ι”ΟΕΰΫχ÷Τ≤Ω π kubernetes Φ·»ΚΒΡΥυ”–ΉιΦΰΚΆ≤εΦΰΘ§Εχ≤Μ « Ι”Ο kubeadm Β»Ή‘Ε·Μ·ΖΫ Ϋά¥≤Ω πΦ·»ΚΘ§Ά§ ±ΩΣΤτΝΥΦ·»ΚΒΡTLSΑ≤»Ϊ»œ÷ΛΘ§’β―υΩ…“‘Αο÷ζΈ“Ο«ΫβœΒΆ≥ΗςΉιΦΰΒΡΫΜΜΞ‘≠άμΘ§ΫχΕχΡήΩλΥΌΫβΨω ΒΦ Έ ΧβΓΘœξΦϊKubernetes
Handbook - ‘ΎCentOS…œ≤Ω πkubernetes1.6Φ·»ΚΓΘ
Φ·»Κœξ«ι
1.Kubernetes 1.6.0
2.Docker 1.12.5Θ® Ι”ΟyumΑ≤ΉΑΘ©
3.Etcd 3.1.5
4.Flanneld 0.7 vxlan Άχ¬γ
5.TLS »œ÷ΛΆ®–≈ (Υυ”–ΉιΦΰΘ§»γ etcdΓΔkubernetes
master ΚΆ node)
6.RBAC Ύ»®
7.kublet TLS BootStrapping
8.kubednsΓΔdashboardΓΔheapster(influxdbΓΔgrafana)ΓΔEFK(elasticsearchΓΔfluentdΓΔkibana)
Φ·»Κ≤εΦΰ
9.ΥΫ”–dockerΨΒœώ≤÷ΩβharborΘ®«κΉ‘––≤Ω πΘ§harborΧαΙ©άκœΏΑ≤ΉΑΑϋΘ§÷±Ϋ” Ι”Οdocker-composeΤτΕ·Φ¥Ω…Θ©
≤Ϋ÷ηΫι…ή
1 ¥¥Ϋ® TLS ÷Λ ιΚΆΟΊ‘Ω
2 ¥¥Ϋ®kubeconfig ΈΡΦΰ
3 ¥¥Ϋ®ΗΏΩ…”ΟetcdΦ·»Κ
4 Α≤ΉΑkubectlΟϋΝν––ΙΛΨΏ
5 ≤Ω πmasterΫΎΒψ
6 ≤Ω πnodeΫΎΒψ
7 Α≤ΉΑkubedns≤εΦΰ
8 Α≤ΉΑdashboard≤εΦΰ
9 Α≤ΉΑheapster≤εΦΰ
10 Α≤ΉΑEFK≤εΦΰ
ΖΰΈώΖΔœ÷”κΗΚ‘ΊΨυΚβ
Kubernetes‘Ύ…ηΦΤ÷°≥θΨΆ≥δΖ÷ΩΦ¬«ΝΥ’κΕ‘»ίΤςΒΡΖΰΈώΖΔœ÷”κΗΚ‘ΊΨυΚβΜζ÷ΤΘ§ΧαΙ©ΝΥServiceΉ ‘¥Θ§≤ΔΆ®Ιΐkube-proxy≈δΚœcloud
providerά¥ ”Π≤ΜΆ§ΒΡ”Π”Ο≥ΓΨΑΓΘΥφΉ≈kubernetes”ΟΜßΒΡΦΛ‘ωΘ§”ΟΜß≥ΓΨΑΒΡ≤ΜΕœΖαΗΜΘ§”÷≤ζ…ζΝΥ“Μ–©–¬ΒΡΗΚ‘ΊΨυΚβΜζ÷ΤΓΘΡΩ«ΑΘ§kubernetes÷–ΒΡΗΚ‘ΊΨυΚβ¥σ÷¬Ω…“‘Ζ÷ΈΣ“‘œ¬ΦΗ÷÷Μζ÷ΤΘ§ΟΩ÷÷Μζ÷ΤΕΦ”–ΤδΧΊΕ®ΒΡ”Π”Ο≥ΓΨΑΘΚ
1.ServiceΘΚ÷±Ϋ””ΟServiceΧαΙ©clusterΡΎ≤ΩΒΡΗΚ‘ΊΨυΚβΘ§≤ΔΫη÷ζcloud
providerΧαΙ©ΒΡLBΧαΙ©Άβ≤ΩΖΟΈ
2.IngressΘΚΜΙ «”ΟServiceΧαΙ©clusterΡΎ≤ΩΒΡΗΚ‘ΊΨυΚβΘ§ΒΪ «Ά®ΙΐΉ‘Ε®“εLBΧαΙ©Άβ≤ΩΖΟΈ
3.Service Load BalancerΘΚΑ―load balancer÷±Ϋ”≈ή‘Ύ»ίΤς÷–Θ§ Βœ÷Bare
MetalΒΡService Load Balancer
4.Custom Load BalancerΘΚΉ‘Ε®“εΗΚ‘ΊΨυΚβΘ§≤ΔΧφ¥ζkube-proxyΘ§“ΜΑψ‘ΎΈοάμ≤Ω πKubernetes ± Ι”ΟΘ§ΖΫ±ψΫ”»κΙΪΥΨ“―”–ΒΡΆβ≤ΩΖΰΈώ
œξΦϊKubernetes Handbook - ΖΰΈώΖΔœ÷”κΗΚ‘ΊΨυΚβΓΘ
≥÷–χΦ·≥…”κΖΔ≤Φ
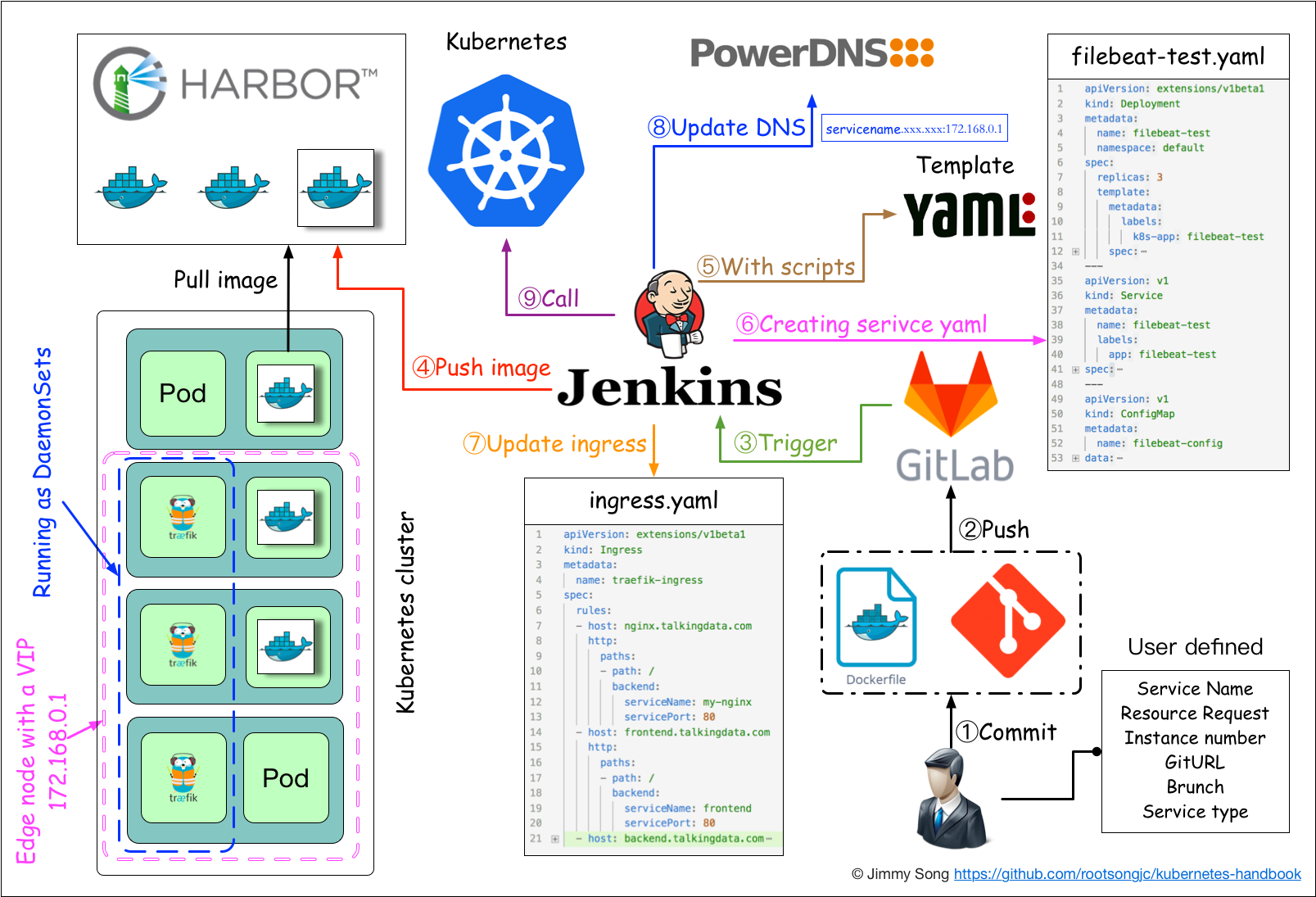
”Π”ΟΙΙΫ®ΚΆΖΔ≤ΦΝς≥ΧΥΒΟςΘΚ
1.”ΟΜßœρGitlabΧαΫΜ¥ζ¬κΘ§¥ζ¬κ÷–±Ί–κΑϋΚ§Dockerfile
2.ΫΪ¥ζ¬κΧαΫΜΒΫ‘Ε≥Χ≤÷Ωβ
3.”ΟΜß‘ΎΖΔ≤Φ”Π”Ο ±–η“ΣΧν–¥git≤÷ΩβΒΊ÷ΖΚΆΖ÷÷ßΓΔΖΰΈώάύ–ΆΓΔΖΰΈώΟϊ≥ΤΓΔΉ ‘¥ ΐΝΩΓΔ ΒάΐΗω ΐΘ§»ΖΕ®Κσ¥ΞΖΔJenkinsΉ‘Ε·ΙΙΫ®
4.JenkinsΒΡCIΝςΥ°œΏΉ‘Ε·±ύ“κ¥ζ¬κ≤Δ¥ρΑϋ≥…dockerΨΒœώΆΤΥΆΒΫHarborΨΒœώ≤÷Ωβ
5.JenkinsΒΡCIΝςΥ°œΏ÷–Αϋά®ΝΥΉ‘Ε®“εΫ≈±ΨΘ§ΗυΨίΈ“Ο«“―ΉΦ±ΗΚΟΒΡkubernetesΒΡYAMLΡΘΑεΘ§ΫΪΤδ÷–ΒΡ±δΝΩΧφΜΜ≥…”ΟΜß δ»κΒΡ―Γœν
6.…ζ≥…”Π”ΟΒΡkubernetes YAML≈δ÷ΟΈΡΦΰ
7.Ηϋ–¬IngressΒΡ≈δ÷ΟΘ§ΗυΨί–¬≤Ω πΒΡ”Π”ΟΒΡΟϊ≥ΤΘ§‘ΎingressΒΡ≈δ÷ΟΈΡΦΰ÷–‘ωΦ”“ΜΧθ¬Ζ”…–≈œΔ
8.Ηϋ–¬PowerDNSΘ§œρΤδ÷–≤ε»κ“ΜΧθDNSΦ«¬ΦΘ§IPΒΊ÷Ζ «±Ώ‘ΒΫΎΒψΒΡIPΒΊ÷ΖΓΘΙΊ”Ύ±Ώ‘ΒΫΎΒψΘ§«κ≤ιΩ¥±Ώ‘ΒΫΎΒψ≈δ÷Ο
9.JenkinsΒς”ΟkubernetesΒΡAPIΘ§≤Ω π”Π”Ο
»’÷Ψ ’Φ·”κΦύΩΊ
Μυ”Ύœ÷”–ΒΡELK»’÷Ψ ’Φ·ΖΫΑΗΘ§…‘ΉςΗΡ‘λΘ§―Γ”Οfilebeatά¥ ’Φ·»’÷ΨΘ§Ω…“‘ΉςΈΣsidecarΒΡ–Έ ΫΗζ”Π”Ο‘Υ––‘ΎΆ§“ΜΗωPod÷–Θ§±»Ϋœ«αΝΩΦΕœϊΚΡΉ ‘¥±»Ϋœ…ΌΓΘ
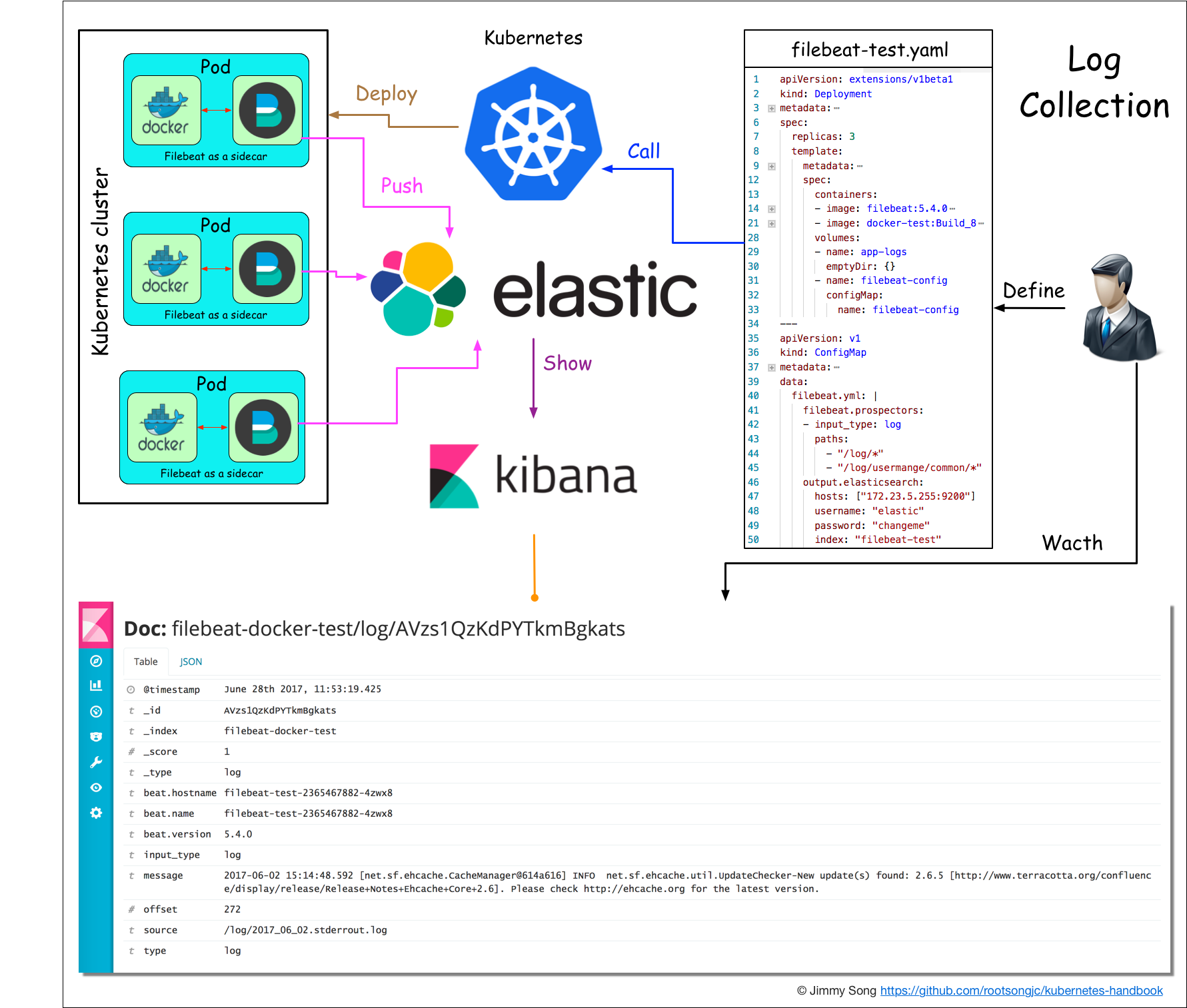
œξΦϊKubernetes Handbook - ”Π”Ο»’÷Ψ ’Φ·ΓΘ
Α≤»Ϊ–‘”κ»®œόΙήάμ
Kubernetes «“ΜΗωΕύΉβΜßΒΡ‘ΤΤΫΧ®Θ§“ρ¥Υ±Ί–κΕ‘”ΟΜßΒΡ»®œόΦ”“‘œό÷ΤΘ§Ε‘”ΟΜßΩ’ΦδΫχ––ΗτάκΓΘKubernetes÷–ΒΡΗτάκ÷ς“ΣΑϋά®’βΦΗ÷÷ΘΚ
1.Άχ¬γΗτάκΘΚ–η“Σ Ι”ΟΆχ¬γ≤εΦΰΘ§±»»γcalicoΓΘ
2.Ή ‘¥ΗτάκΘΚkubernetes‘≠…ζ÷ß≥÷Ή ‘¥ΗτάκΘ§podΨΆ «Ή ‘¥ΨΆ «ΗτάκΚΆΒςΕ»ΒΡΉν–ΓΒΞΈΜΘ§Ά§ ± Ι”Οnamespaceœό÷Τ”ΟΜßΩ’ΦδΚΆΉ ‘¥œόΕνΓΘ
3.…μΖίΗτάκΘΚ Ι”ΟRBAC-Μυ”ΎΫ«…ΪΒΡΖΟΈ ΩΊ÷ΤΘ§ΕύΉβΜßΒΡ…μΖί»œ÷ΛΚΆ»®œόΩΊ÷ΤΓΘ
»γΚΈΩΣΖΔKubernetes‘≠…ζ”Π”Ο≤Ϋ÷ηΫι…ή
Β±Έ“Ο«”–ΝΥ“ΜΗωkubernetesΦ·»ΚΚσΘ§»γΚΈ‘Ύ…œΟφΩΣΖΔΚΆ≤Ω π”Π”ΟΘ§”ΠΗΟΉώ―≠‘θ―υΒΡΝς≥ΧΘΩœ¬ΟφΈ“ΫΪ’Ι Ψ»γΚΈ Ι”Οgo”ο―‘ΩΣΖΔΚΆ≤Ω π“ΜΗωkubernetes
native”Π”ΟΘ§ Ι”ΟwerckerΫχ––≥÷–χΦ·≥…”κ≥÷–χΖΔ≤ΦΘ§Έ“ΫΪ“‘“ΜΗωΚήΦρΒΞΒΡ«ΑΚσΕΥΖΟΈ Θ§Μώ»ΓΈ±‘λ ΐΨί≤Δ’Ι ΨΒΡάΐΉ”ά¥ΥΒΟςΓΘ
‘Τ‘≠…ζ”Π”ΟΩΣΖΔ Ψάΐ
Έ“Ο«ΫΪΑ¥’’»γœ¬≤Ϋ÷ηά¥ΩΣΖΔ≤Ω π“ΜΗωkubernetes‘≠…ζ”Π”Ο≤ΔΫΪΥϋ≤Ω πΒΫkubernetesΦ·»Κ…œΩΣΖ≈ΗχΦ·»ΚΆβΖΟΈ ΘΚ
1.ΖΰΈώAPIΒΡΕ®“ε
2. Ι”ΟGo”ο―‘ΩΣΖΔkubernetes‘≠…ζ”Π”Ο
3.“ΜΗω≥÷–χΙΙΫ®”κΖΔ≤ΦΙΛΨΏ”κΜΖΨ≥
4. Ι”ΟtraefikΚΆVIPΉω±Ώ‘ΒΫΎΒψΧαΙ©Άβ≤ΩΖΟΈ ¬Ζ”…
Έ“–¥ΝΥΝΫΗω Ψάΐ”Ο”Ύ―ί ΨΘ§ΩΣΖΔ≤Ω π“ΜΗωΈ±‘λΒΡ metric ≤Δœ‘ Ψ‘Ύ web “≥Οφ…œΘ§Αϋά®ΝΫΗωserviceΘΚ
1.k8s-app-monitor-testΘΚ…ζ≥…ΡΘΡβΒΡΦύΩΊ ΐΨίΘ§ΖΔΥΆhttp«κ«σΘ§Μώ»ΓjsonΖΒΜΊ÷Β
2.K8s-app-monitor-agentΘΚΜώ»ΓΦύΩΊ ΐΨί≤ΔΜφΆΦΘ§ΖΟΈ δ·άάΤςΜώ»ΓΆΦ±μ
Ε®“εAPI…ζ≥…APIΈΡΒΒ
Ι”ΟAPI blueprintΗώ ΫΘ§Ε®“εAPIΈΡΒΒΘ§Ηώ ΫάύΥΤ”ΎmarkdownΘ§‘Ό Ι”Οaglio…ζ≥…HTMLΈΡΒΒΓΘ
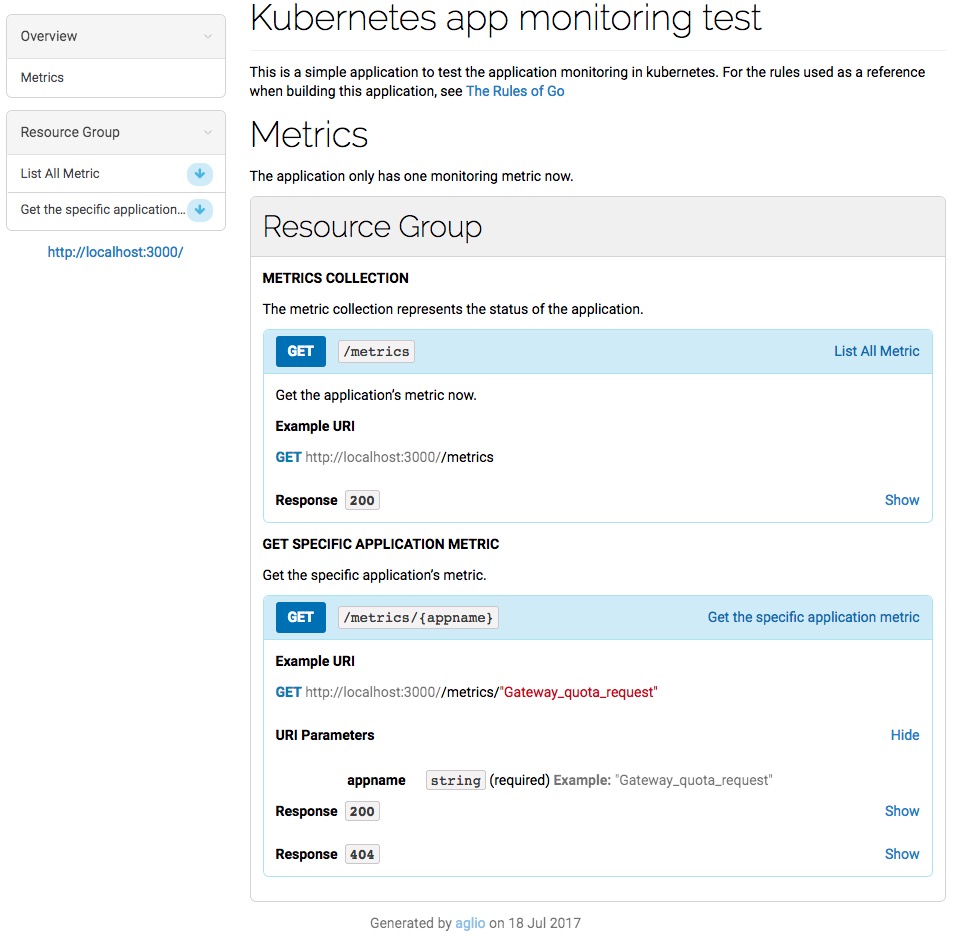
œξΦϊΘΚ»γΚΈΩΣΖΔ≤Ω πkubernetes native”Π”ΟΓΘ
»γΚΈ«®“ΤΒΫ‘Τ‘≠…ζ”Π”ΟΦήΙΙ
Pivotal «‘Τ‘≠…ζ”Π”ΟΒΡΧα≥ω’ΏΘ§≤ΔΆΤ≥ωΝΥ Pivotal Cloud Foundry ‘Τ‘≠…ζ”Π”ΟΤΫΧ®ΚΆ
Spring ΩΣ‘¥ Java ΩΣΖΔΩρΦήΘ§≥…ΈΣ‘Τ‘≠…ζ”Π”ΟΦήΙΙ÷–œ»«ΐ’ΏΚΆΧΫ¬Ζ’ΏΓΘ
‘≠ ιΉς”Ύ2015ΡξΘ§Τδ÷–ΒΡ Ψάΐ÷ς“Σ’κΕ‘ Java ”Π”ΟΘ§ ΒΦ …œ“≤ ”Ο”Ύ»ΈΚΈ”Π”Οάύ–ΆΘ§‘Τ‘≠…ζ”Π”ΟΦήΙΙ ”Ο”Ύ“λΙΙ”ο―‘ΒΡ≥Χ–ρΩΣΖΔΘ§≤ΜΫωΫω «’κΕ‘
Java ”ο―‘ΒΡ≥Χ–ρΩΣΖΔΓΘΫΊ÷ΙΒΫ±Ψ»ΥΖ≠“κ±Ψ ι ±Θ§‘Τ‘≠…ζ”Π”Ο…ζΧ§œΒΆ≥“―Ψ≠≥θΨΏΙφΡΘΘ§CNCF ≥…‘±≤ΜΕœΖΔ’ΙΉ≥¥σΘ§Μυ”Ύ
Cloud Native ΒΡ¥¥“ΒΙΪΥΨ≤ΜΕœ”Ωœ÷Θ§kubernetes “ΐΝλ»ίΤς±ύ≈≈≥±ΝςΘ§ΚΆ Service
Mesh ΦΦ θΘ®»γ Linkerd ΚΆ IstioΘ© ΒΡ≥ωœ÷Θ§Go ”ο―‘ΒΡ–ΥΤπΘ®≤ΈΩΦΝμ“Μ±Ψ ι Cloud
Native GoΘ©Β»ΈΣΈ“Ο«ΫΪ”Π”Ο«®“ΤΒΫ‘Τ‘≠…ζΦήΙΙΒΡΧαΙ©ΝΥΗϋΕύΒΡΖΫΑΗ―Γ‘ώΓΘ
«®“ΤΒΫ‘Τ‘≠…ζ”Π”ΟΦήΙΙ÷ΗΡœ
÷Η≥ωΝΥ«®“ΤΒΫ‘Τ‘≠…ζ”Π”ΟΦήΙΙ–η“ΣΉω≥ωΒΡΤσ“ΒΈΡΜ·ΓΔΉι÷·ΦήΙΙΚΆΦΦ θ±δΗοΘ§≤ΔΗχ≥ωΝΥ«®“Τ÷ΗΡœΓΘ
÷ς“ΣΧ÷¬έΒΡ”Π”Ο≥Χ–ρΦήΙΙΑϋά®ΘΚ
1. °Εΰ“ρΥΊ”Π”Ο≥Χ–ρΘΚ‘Τ‘≠…ζ”Π”Ο≥Χ–ρΦήΙΙΡΘ ΫΒΡΦ·Κœ
2.ΈΔΖΰΈώΘΚΕάΝΔ≤Ω πΒΡΖΰΈώΘ§÷ΜΉω“ΜΦΰ ¬«ι
3.Ή‘÷ζΖΰΈώΒΡΟτΫίΜυ¥Γ…η ©ΘΚΩλΥΌΘ§Ω…÷ΊΗ¥ΚΆ“Μ÷¬ΒΊΧαΙ©”Π”ΟΜΖΨ≥ΚΆΚσΧ®ΖΰΈώΒΡΤΫΧ®
4.Μυ”ΎAPIΒΡ–≠ΉςΘΚΖΔ≤ΦΚΆΑφ±ΨΜ·ΒΡAPIΘ§‘ –μ‘Ύ‘Τ‘≠…ζ”Π”Ο≥Χ–ρΦήΙΙ÷–ΒΡΖΰΈώ÷°ΦδΫχ––ΫΜΜΞ
5.ΩΙ―Ι–‘ΘΚΗυΨί―ΙΝΠ±δ«ΩΒΡœΒΆ≥
œξΦϊΘΚ«®“ΤΒΫ‘Τ‘≠…ζ”Π”ΟΦήΙΙ
«®“ΤΑΗάΐΫβΈω
«®“Τ≤Ϋ÷η Ψ“βΆΦ»γœ¬ΘΚ

≤Ϋ÷ηΥΒΟςΘΚ
1.ΫΪ‘≠”–”Π”Ο≤πΫβΈΣΖΰΈώ
2.»ίΤςΜ·ΓΔ÷ΤΉςΨΒœώ
3.ΉΦ±Η”Π”Ο≈δ÷ΟΈΡΦΰ
4.ΉΦ±Ηkubernetes YAMLΈΡΦΰ
5.±ύ–¥bootstarpΫ≈±Ψ
¥¥Ϋ®ConfigMaps6.
œξΦϊΘΚ«®“Τ¥ΪΆ≥”Π”ΟΒΫKubernetes≤Ϋ÷ηœξΫβΓΣΓΣ“‘Hadoop YARNΈΣάΐΓΘ
Service meshΜυ±Ψ‘≠άμΚΆ ΨάΐΫι…ή
Service meshœ÷‘Ύ“ΜΑψ±ΜΖ≠“κΉςΖΰΈώΆχΗώΘ§ΡΩ«Α÷ςΝςΒΡService mesh”–»γœ¬ΝΫΩνΘΚ
1.IstioΘΚIBMΓΔGoogleΓΔLyftΙ≤Ά§ΩΣ‘¥Θ§œξœΗΈΡΒΒΦϊIstioΙΌΖΫΈΡΒΒ÷–ΈΡΑφ
2.LinkerdΘΚ‘≠TwitterΙΛ≥Χ ΠΩΣΖΔΘ§œ÷ΈΣCNCF÷–ΒΡœνΡΩ÷°“Μ
≤Ο¥ «Service mesh
»γΙϊ”Ο“ΜΨδΜΑά¥Ϋβ Ά ≤Ο¥ « Service MeshΘ§Ω…“‘ΫΪΥϋ±»Ής «”Π”Ο≥Χ–ρΜρ’ΏΥΒΈΔΖΰΈώΦδΒΡ TCP/IPΘ§ΗΚ‘πΖΰΈώ÷°ΦδΒΡΆχ¬γΒς”ΟΓΔœόΝςΓΔ»έΕœΚΆΦύΩΊΓΘΕ‘”Ύ±ύ–¥”Π”Ο≥Χ–ρά¥ΥΒ“ΜΑψΈό–κΙΊ–Ρ
TCP/IP ’β“Μ≤ψΘ®±»»γΆ®Ιΐ HTTP –≠“ιΒΡ RESTful ”Π”ΟΘ©Θ§Ά§―υ Ι”Ο Service
Mesh “≤ΨΆΈό–κΙΊœΒΖΰΈώ÷°ΦδΒΡΡ«–©‘≠ά¥ «Ά®Ιΐ”Π”Ο≥Χ–ρΜρ’ΏΤδΥϊΩρΦή Βœ÷ΒΡ ¬«ιΘ§±»»γ Spring CloudΓΔOSSΘ§œ÷‘Ύ÷Μ“ΣΫΜΗχ
Service Mesh ΨΆΩ…“‘ΝΥΓΘ
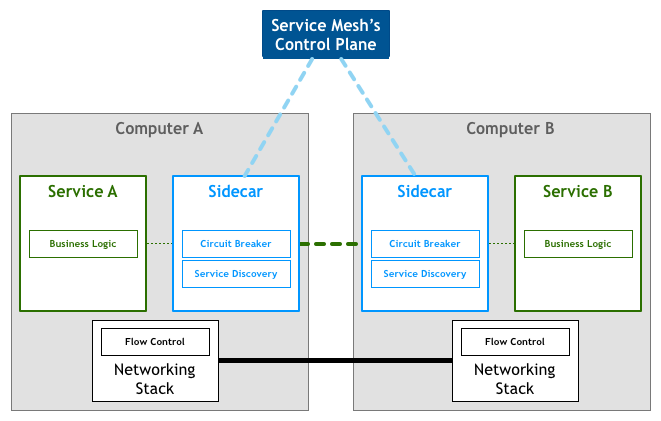
œξΦϊ ≤Ο¥ « service mesh - jimmysong.ioΓΘ
Service mesh Ι”Ο÷ΗΡœ
ΝΫΩνService meshΗς”–«ß«οΘ§Έ“Ζ÷±π–¥ΝΥΥϊΟ«ΒΡ Ι”ΟΑΗάΐ÷ΗΡœΘΚ
1.ΈΔΖΰΈώΙήάμΩρΦήservice meshΓΣΓΣLinkerdΑ≤ΉΑ ‘”Ο± Φ«
2.ΈΔΖΰΈώΙήάμΩρΦήservice meshΓΣΓΣIstioΑ≤ΉΑ ‘”Ο± Φ«
Ι”ΟΑΗάΐ
KubernetesΉςΈΣ‘Τ‘≠…ζΦΤΥψΒΡΜυ±ΨΉιΦΰ÷°“ΜΘ§ΩΣ‘¥2Ρξ ±Φδ“‘ά¥»»Ε»”κ»’Ψψ‘ωΘ§ΥϋΩ…“‘ΗζΈ“Ο«ΒΡ…ζ≤ζΫαΚœΘ§≤Ν≥ωΚήΕύΜπΜ®Θ§±»»γFaaSΚΆServerlessάύ”Π”ΟΘ§ΕΦΚή Κœ‘Υ––‘Ύkubernetes…œΓΘ
ΙΊ”ΎCloud NativeΩΣ‘¥»μΦΰ…ζΧ§«κ≤ΈΩΦ Awesome Cloud Native - jimmysong.ioΓΘ
DevOps
œ¬Οφ «…γ«χ÷–kubernetesΩΣ‘¥Α°ΚΟ’ΏΒΡΖ÷œμΡΎ»ίΘ§Έ“ΨθΒΟ «Ε‘kubernetes‘ΎDevOps÷–”Π”ΟΒΡΚήΚΟΒΡ–Έ Ϋ÷ΒΒΟ¥σΦ“ΫηΦχΓΘ
’φ’ΐΦυ––DevOpsΘ§»ΟΩΣΖΔ»Υ‘±‘Ύ’ΤΈ’Ή‘ΦΚΒΡΩΣΖΔΚΆ≤β ‘ΜΖΨ≥Θ§»ΟΜΖΨ≥“Μ÷¬Θ§»ΟΩΣΖΔ–ß¬ Χα…ΐΘ§»Ο‘ΥΈ§ΟΜ”–Ε―Μΐ»γ…ΫΒΡticketsΘ§»ΟΦύΩΊΗϋΦ”ΨΪΉΦΘ§¥”kubernetesΤΫΧ®ΩΣ ΦΓΘ
––Ε·÷ΗΡœ
1.ΗυΨίΜΖΨ≥Θ®±»»γΩΣΖΔΓΔ≤β ‘ΓΔ…ζ≤ζΘ©Μ°Ζ÷namespaceΘ§“≤Ω…“‘ΗυΨίœνΡΩά¥Μ°Ζ÷
2.‘ΌΈΣΟΩΗω”ΟΜßΜ°Ζ÷“ΜΗωnamespaceΓΔ¥¥Ϋ®“ΜΗωserviceaccountΚΆkubeconfigΈΡΦΰΘ§≤ΜΆ§namespaceΦδΒΡΉ ‘¥ΗτάκΘ§ΡΩ«Α≤ΜΗτάκΆχ¬γΘ§≤ΜΆ§namespaceΦδΒΡΖΰΈώΩ…“‘ΜΞœύΖΟΈ
3.¥¥Ϋ®yamlΡΘΑεΘ§ΫΒΒΆ±ύ–¥kubernetes yamlΈΡΦΰ±ύ–¥Ρ―Ε»
4.‘ΎkubectlΟϋΝν…œ‘ΌΖβΉΑ“Μ≤ψΘ§‘ωΦ””ΟΜß…μΖί…η÷ΟΚΆΜΖΨ≥≥θ ΦΜ·≤ΌΉςΘ§ΦρΜ·kubectlΟϋΝνΚΆ≥Θ”ΟΙΠΡή
5.Ιήάμ‘±Ά®Ιΐdashboard≤ιΩ¥≤ΜΆ§namespaceΒΡΉ¥Χ§Θ§“≤Ω…“‘ Ι”ΟΥϋά¥ Ι≤ΌΉςΗϋ±ψΫί
6.Υυ”–”Π”ΟΒΡ»’÷ΨΆ≥“Μ ’Φ·ΒΫElasticSearch÷–Θ§Ά≥“Μ»’÷ΨΖΟΈ »κΩΎ
7.Ω…“‘Ά®ΙΐGrafana≤ιΩ¥Υυ”–namespace÷–ΒΡ”Π”ΟΒΡΉ¥Χ§ΚΆkubernetesΦ·»Κ±Ψ…μΒΡΉ¥Χ§
8.–η“Σ≥÷ΨΟΜ·ΒΡ ΐΨί±Θ¥φ‘ΎΖ÷≤Φ Ϋ¥φ¥Δ÷–Θ§άΐ»γGlusterFSΜρCeph÷–
Ι”ΟKibana≤ιΩ¥»’÷Ψ
»’÷ΨΉ÷ΕΈ÷–Αϋά®ΝΥ”Π”ΟΒΡ±ξ«©ΓΔ»ίΤςΟϊ≥ΤΓΔ÷ςΜζΟϊ≥ΤΓΔΥό÷ςΜζΟϊ≥ΤΓΔIPΒΊ÷ΖΓΔ ±ΦδΓΔ
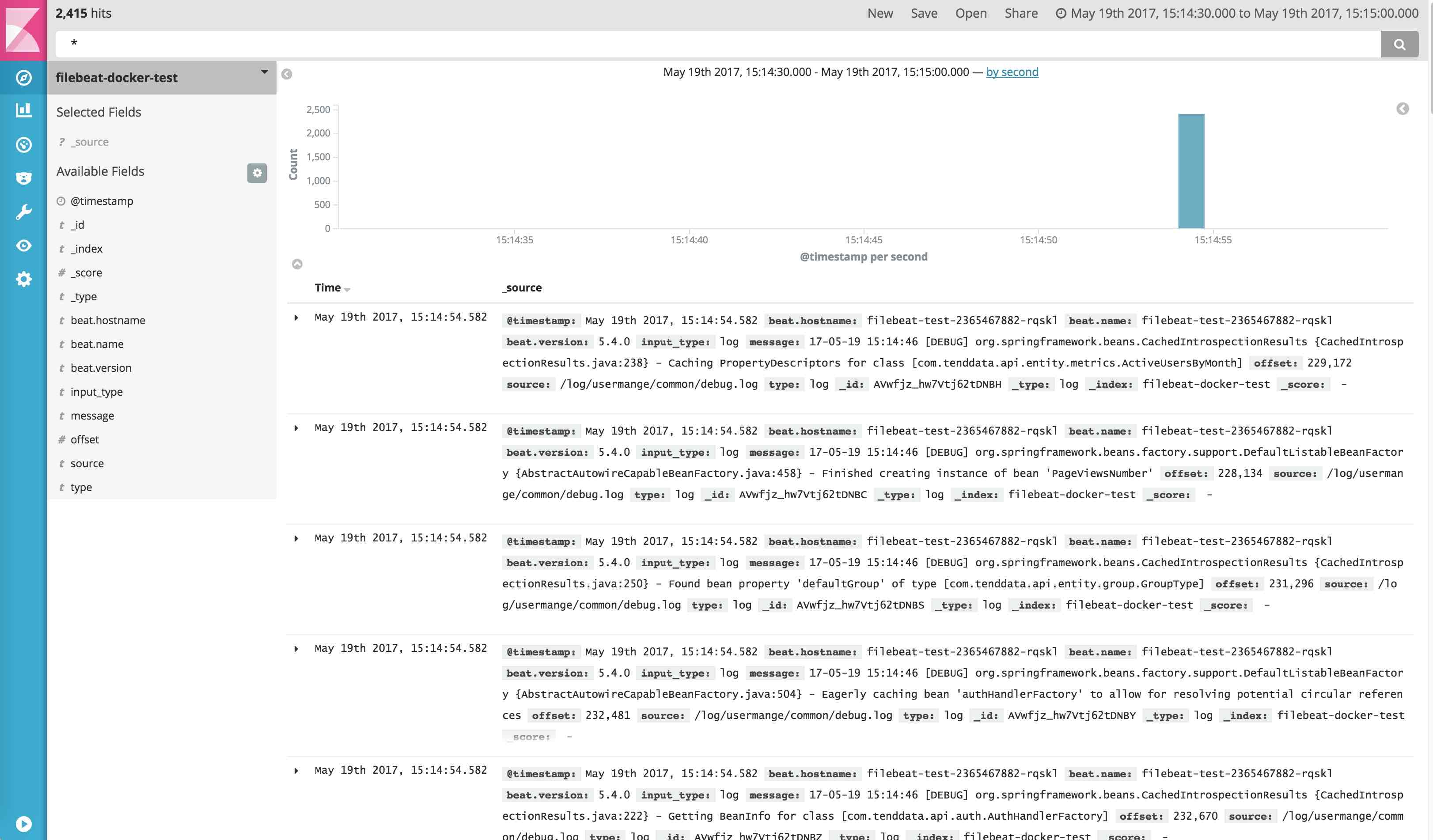
Ι”ΟGrafana≤ιΩ¥”Π”ΟΉ¥Χ§
ΉΔΘΚΗ––ΜΓΨK8S Cloud Native Β’Ϋ»ΚΓΩΉπΙσΒΡΜΤΫπΜα‘±–ΓΗ’Ά§―ßΧαΙ©œ¬ΟφΒΡGrafanaΦύΩΊΆΦ
ΦύΩΊΖ÷άύ Ψ“βΆΦΘΚ
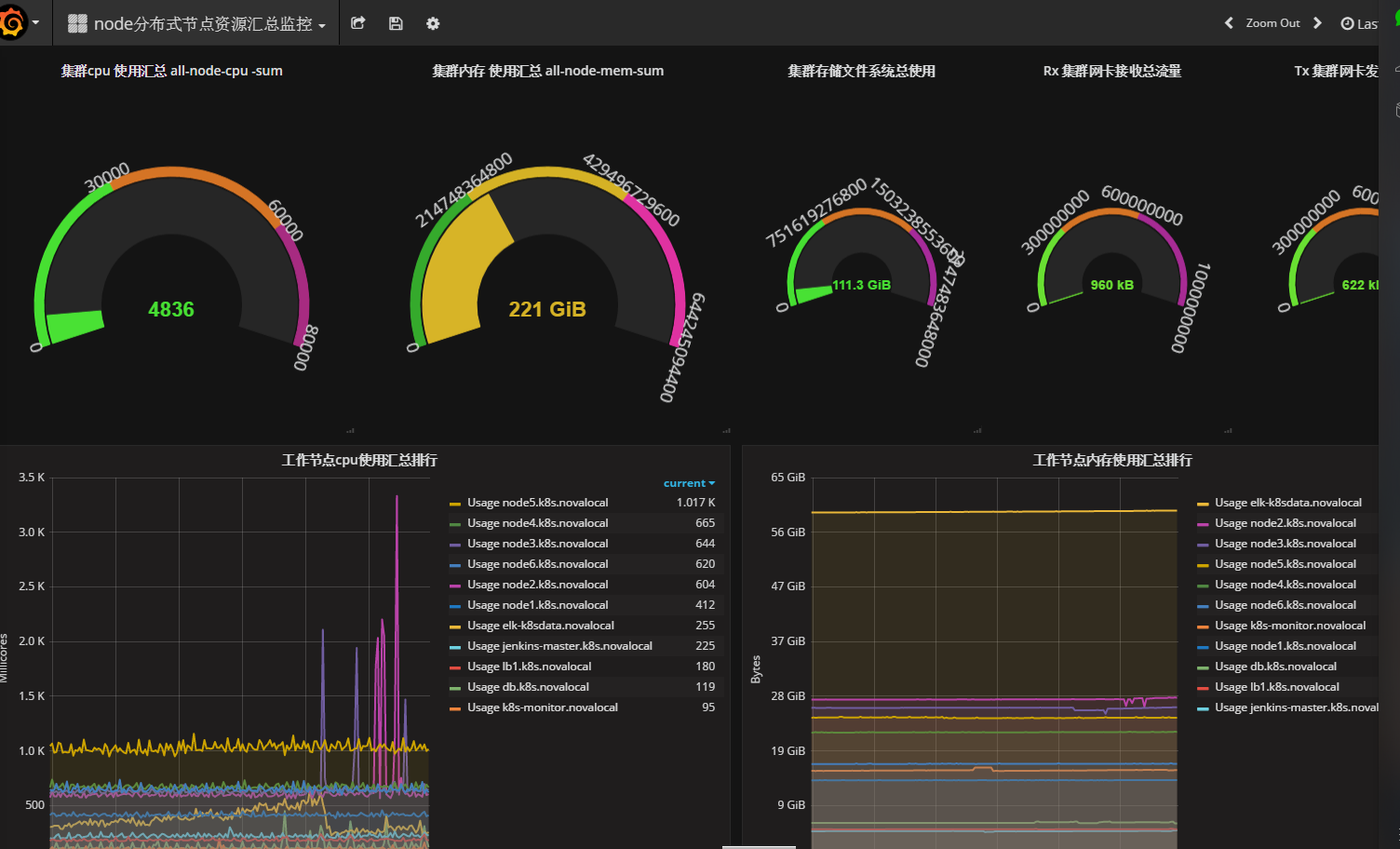
KubernetesΦ·»Κ»ΪΨ÷ΦύΩΊΆΦ1
ΗΟΦύΩΊΆΦΩ…“‘Ω¥ΒΫΦ·»Κ”≤Φΰ Ι”Ο«ιΩωΓΘ
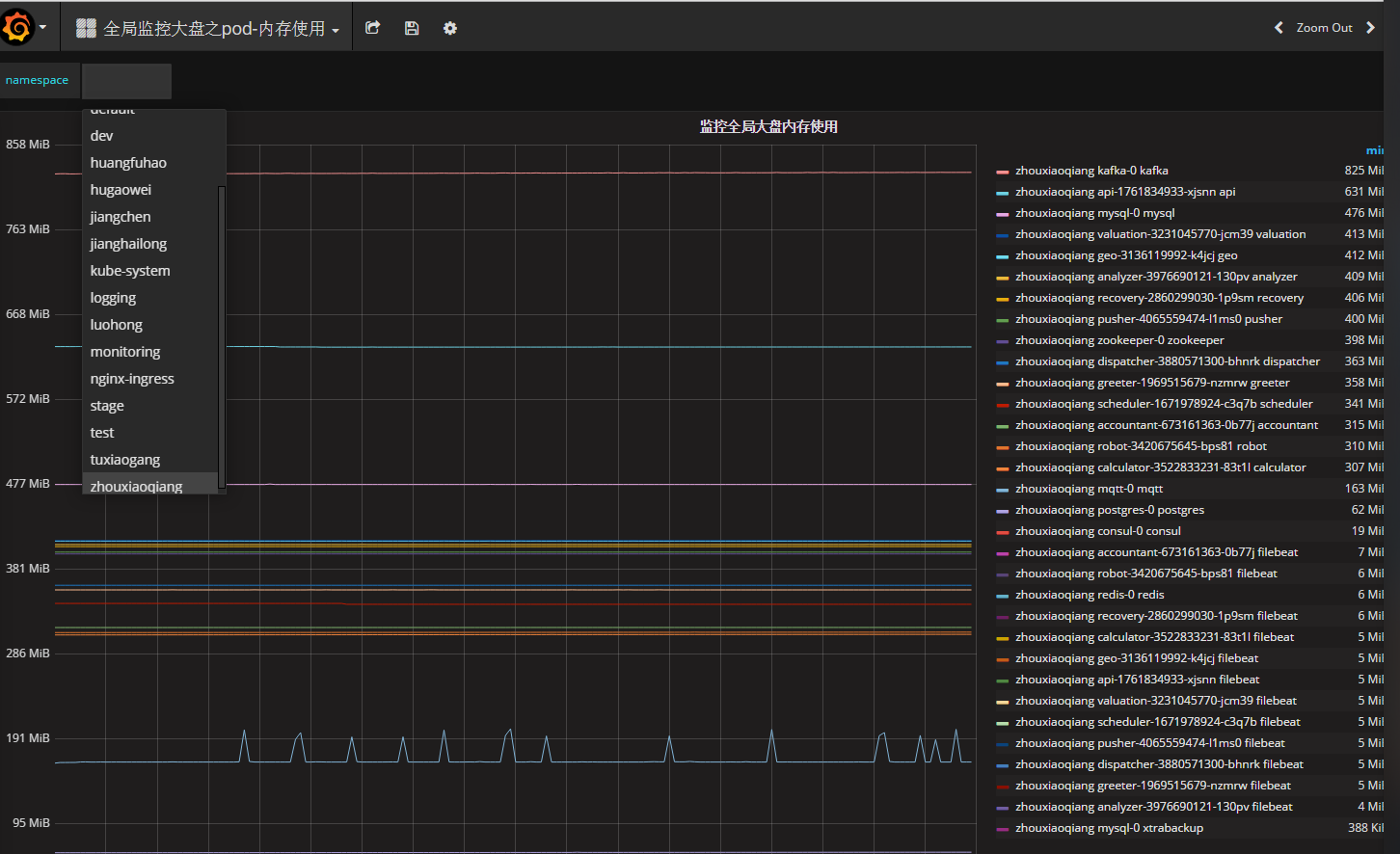
Kubernetes»ΪΨ÷ΦύΩΊΆΦ2
ΗΟΦύΩΊΩ…“‘Ω¥ΒΫΒΞΗω”ΟΜßΒΡnamespaceœ¬ΒΡΥυ”–Ή ‘¥ΒΡ Ι”Ο«ιΩωΓΘ
Spark on Kubernetes
TL;DR https://jimmysong.io/spark-on-k8s
Spark‘≠…ζ÷ß≥÷standaloneΓΔmesosΚΆYARNΉ ‘¥ΒςΕ»Θ§œ÷“―÷ß≥÷Kubernetes‘≠…ζΒςΕ»Θ§œξΦϊ‘Υ––÷ß≥÷kubernetes‘≠…ζΒςΕ»ΒΡspark≥Χ–ρ-Spark
on KubernetesΓΘ
ΈΣΚΈ“Σ Ι”Οspark on kubernetes
Ι”Οkubernetes‘≠…ζΒςΕ»ΒΡspark on kubernetes «Ε‘‘≠œ»ΒΡspark
on yarnΚΆyarn on dockerΒΡΗΡ±δ «ΗοΟϋ–‘ΒΡΘ§÷ς“Σ±μœ÷‘Ύ“‘œ¬ΦΗΒψΘΚ
1.Kubernetes‘≠…ζΒςΕ»ΘΚ≤Μ‘Ό–η“ΣΕΰ≤ψΒςΕ»Θ§÷±Ϋ” Ι”ΟkubernetesΒΡΉ ‘¥ΒςΕ»ΙΠΡήΘ§ΗζΤδΥϊ”Π”ΟΙ≤”Ο’ϊΗωkubernetesΙήάμΒΡΉ ‘¥≥ΊΘΜ
2.Ή ‘¥ΗτάκΘ§ΝΘΕ»ΗϋœΗΘΚ‘≠œ»yarn÷–ΒΡqueue‘Ύspark on
kubernetes÷–“―≤Μ¥φ‘ΎΘ§»ΓΕχ¥ζ÷°ΒΡ «kubernetes÷–‘≠…ζΒΡnamespaceΘ§Ω…“‘ΈΣΟΩΗω”ΟΜßΖ÷±π÷ΗΕ®“ΜΗωnamespaceΘ§œό÷Τ”ΟΜßΒΡΉ ‘¥quotaΘΜ
3.œΗΝΘΕ»ΒΡΉ ‘¥Ζ÷≈δΘΚΩ…“‘ΗχΟΩΗωspark»ΈΈώ÷ΗΕ®Ή ‘¥œό÷ΤΘ§ ΒΦ ÷ΗΕ®Εύ…ΌΉ ‘¥ΨΆ Ι”ΟΕύ…ΌΉ ‘¥Θ§“ρΈΣΟΜ”–ΝΥœώyarnΡ«―υΒΡΕΰ≤ψΒςΕ»Θ®»ΠΒΊ ΫΒΡΘ©Θ§Υυ“‘Ω…“‘ΗϋΗΏ–ßΚΆœΗΝΘΕ»ΒΡ Ι”ΟΉ ‘¥ΘΜ
4.ΦύΩΊΒΡ±δΗοΘΚ“ρΈΣΉωΒΫΝΥœΗΝΘΕ»ΒΡΉ ‘¥Ζ÷≈δΘ§Υυ“‘Ω…“‘Ε‘”ΟΜßΧαΫΜΒΡΟΩ“ΜΗω»ΈΈώΉωΒΫΉ ‘¥ Ι”ΟΒΡΦύΩΊΘ§¥”Εχ≈–Εœ”ΟΜßΒΡΉ ‘¥ Ι”Ο«ιΩωΘ§Υυ”–ΒΡmetricΕΦΦ«¬Φ‘Ύ ΐΨίΩβ÷–Θ§…θ÷ΝΩ…“‘ΈΣΟΩΗω”ΟΜßΒΡΟΩ¥Έ»ΈΈώΧαΫΜΦΤΝΩΘΜ
5.»’÷ΨΒΡ±δΗοΘΚ”ΟΜß≤Μ‘ΌΆ®ΙΐyarnΒΡweb“≥Οφά¥≤ιΩ¥»ΈΈώΉ¥Χ§Θ§Εχ «Ά®ΙΐpodΒΡlogά¥≤ιΩ¥Θ§Ω…ΫΪΥυ”–ΒΡkuberentes÷–ΒΡ”Π”ΟΒΡ»’÷ΨΒ»Ά§Ω¥¥ΐ ’Φ·Τπά¥Θ§»ΜΚσΩ…“‘ΗυΨί±ξ«©≤ιΩ¥Ε‘”Π”Π”ΟΒΡ»’÷ΨΘΜ
»γΚΈΧαΫΜ»ΈΈώ
»‘»Μ Ι”Οspark-submitΧαΫΜspark»ΈΈώΘ§Ω…“‘÷±Ϋ”÷ΗΕ®kubernetes API serverΒΊ÷ΖΘ§œ¬ΟφΒΡΟϋΝνΧαΫΜ±ΨΒΊjarΑϋΒΫkubernetesΦ·»Κ…œ‘Υ––Θ§Ά§ ±÷ΗΕ®ΝΥ‘Υ––»ΈΈώΒΡ”ΟΜßΓΔΧαΫΜΟϋΟϊΒΡ”ΟΜßΓΔ‘Υ––ΒΡexcutor Βάΐ ΐΓΔdriverΚΆexecutorΒΡΉ ‘¥œό÷ΤΓΔ Ι”ΟΒΡsparkΑφ±ΨΒ»–≈œΔΓΘ
œξœΗ Ι”ΟΥΒΟςΦϊApache Spark on Kubernetes”ΟΜß÷ΗΡœ - jimmysong.ioΓΘ
ΦύΩΊ
œ¬ΆΦ «¥”Kubernetes dashboard…œΩ¥ΒΫΒΡspark-cluster’βΗωnamespace…œ‘Υ––ΒΡ”Π”Ο«ιΩωΓΘ
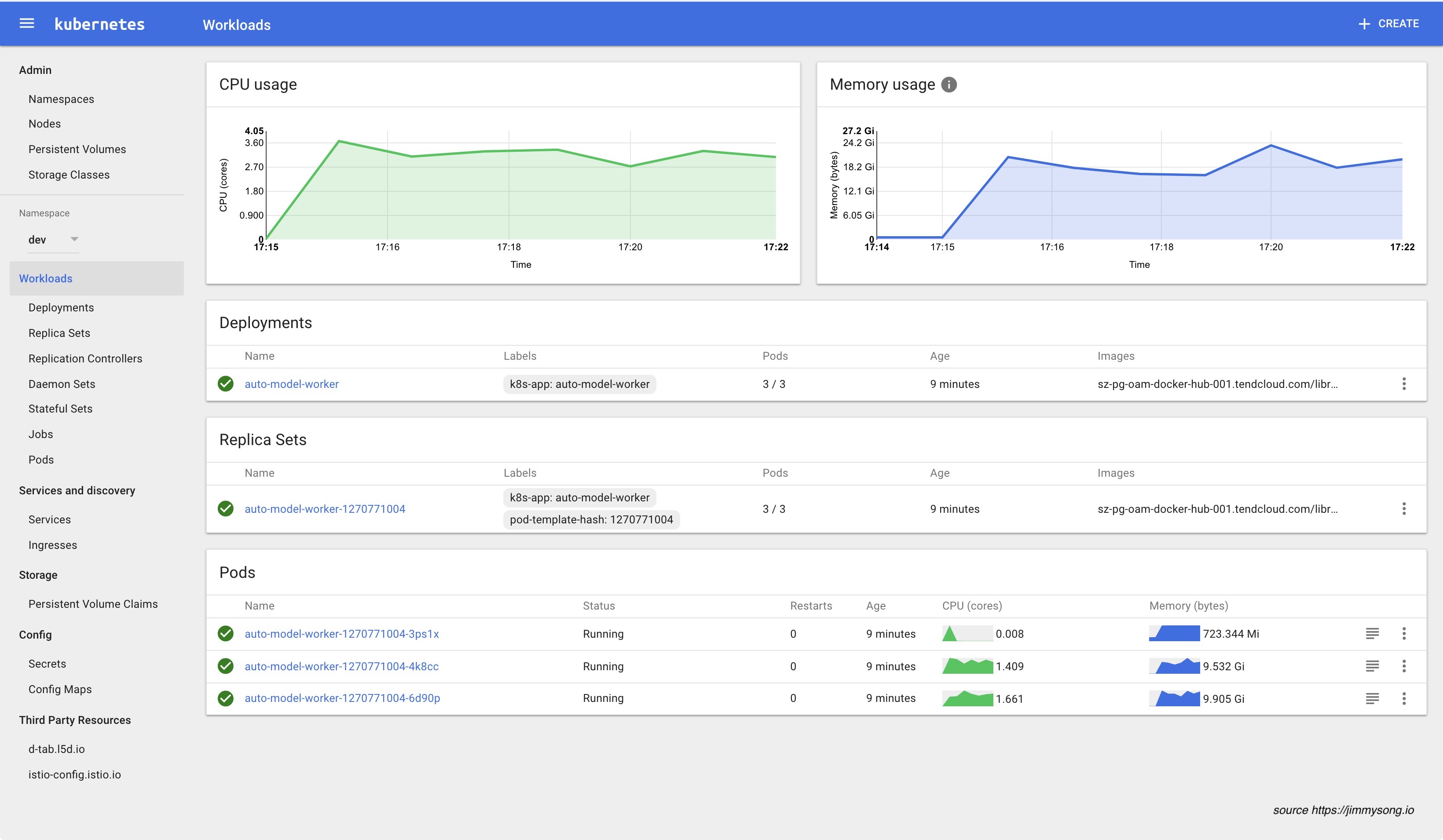
œ¬ΆΦ «¥”GrafanaΦύΩΊ“≥Οφ…œ≤ιΩ¥ΒΫΒΡΡ≥ΗωexecutorΉ ‘¥’Φ”Ο«ιΩωΓΘ

|








