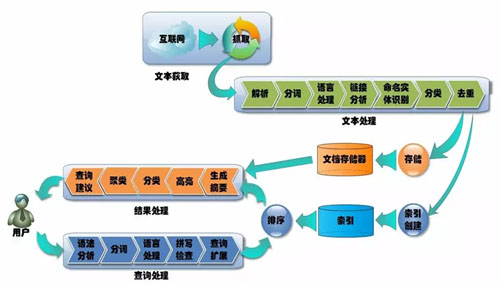
| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌжївЊЮЊДѓМвНВЪіСЫдЦМЦЫуЁЂДѓЪ§ОнКЭШЫЙЄжЧФмШ§епЕФвтвхКЭЫћУЧжЎМфЕФЙиЯЕЁЃ |
|
НёЬьИњДѓМвНВНВдЦМЦЫуЁЂДѓЪ§ОнКЭШЫЙЄжЧФмЁЃетШ§ИіДЪЯждкЗЧГЃЛ№ЃЌВЂЧвЫќУЧжЎМфКУЯёЛЅЯргаЙиЯЕЁЃ

вЛАуЬИдЦМЦЫуЕФЪБКђЛсЬсЕНДѓЪ§ОнЁЂЬИШЫЙЄжЧФмЕФЪБКђЛсЬсДѓЪ§ОнЁЂЬИШЫЙЄжЧФмЕФЪБКђЛсЬсдЦМЦЫуЁЁИаОѕШ§епжЎМфЯрИЈЯрГЩгжВЛПЩЗжИюЁЃ
ЕЋШчЙћЪЧЗЧММЪѕЕФШЫдБЃЌОЭПЩФмБШНЯФбРэНтетШ§епжЎМфЕФЯрЛЅЙиЯЕЃЌЫљвдгаБивЊНтЪЭвЛЯТЁЃ
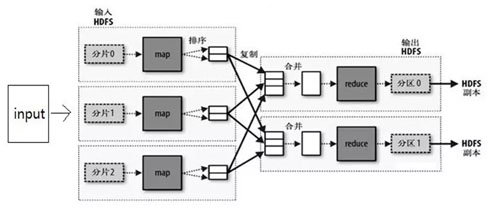
дЦМЦЫузюГѕЕФФПБъ
ЮвУЧЪзЯШРДЫЕдЦМЦЫуЁЃдЦМЦЫузюГѕЕФФПБъЪЧЖдзЪдДЕФЙмРэЃЌЙмРэЕФжївЊЪЧМЦЫузЪдДЁЂЭјТчзЪдДЁЂДцДЂзЪдДШ§ИіЗНУцЁЃ
ЙмЪ§ОнжааФОЭЯёХфЕчФд
ЪВУДНаМЦЫуЁЂЭјТчЁЂДцДЂзЪдДЃП
БШШчФувЊТђЬЈБЪМЧБОЕчФдЃЌЪЧВЛЪЧвЊЙиаФетЬЈЕчФдЪЧЪВУДбљЕФ CPUЃПЖрДѓЕФФкДцЃПетСНИіОЭБЛЮвУЧГЦЮЊМЦЫузЪдДЁЃ
етЬЈЕчФдвЊЩЯЭјЃЌОЭашвЊгаИіПЩвдВхЭјЯпЕФЭјПкЃЌЛђепгаПЩвдСЌНгЮвУЧМвТЗгЩЦїЕФЮоЯпЭјПЈЁЃ
ФњМввВашвЊЕНдЫгЊЩЬБШШчСЊЭЈЁЂвЦЖЏЛђепЕчаХПЊЭЈвЛИіЭјТчЃЌБШШч 100M ЕФДјПэЁЃШЛКѓЛсгаЪІИЕХЊвЛИљЭјЯпЕНФњМвРДЃЌЪІИЕПЩФмЛсАяФњНЋФњЕФТЗгЩЦїКЭЫћУЧЙЋЫОЕФЭјТчСЌНгХфжУКУЁЃ
етбљФњМвЕФЫљгаЕФЕчФдЁЂЪжЛњЁЂЦНАхОЭЖМПЩвдЭЈЙ§ФњЕФТЗгЩЦїЩЯЭјСЫЁЃетОЭЪЧЭјТчзЪдДЁЃ
ФњПЩФмЛЙЛсЮЪгВХЬЖрДѓЃПЙ§ШЅЕФгВХЬЖМКмаЁЃЌДѓаЁШч 10G жЎРрЕФЃЛКѓРДМДЪЙ 500GЁЂ1TЁЂ2T ЕФгВХЬвВВЛаТЯЪСЫЁЃ(1T
ЪЧ 1000G)ЃЌетОЭЪЧДцДЂзЪдДЁЃ
ЖдгквЛЬЈЕчФдЪЧетИібљзгЕФЃЌЖдгквЛИіЪ§ОнжааФвВЪЧЭЌбљЕФЁЃЯыЯѓФугавЛИіЗЧГЃЗЧГЃДѓЕФЛњЗПЃЌРяУцЖбСЫКмЖрЕФЗўЮёЦїЃЌетаЉЗўЮёЦївВЪЧга
CPUЁЂФкДцЁЂгВХЬЕФЃЌвВЪЧЭЈЙ§РрЫЦТЗгЩЦїЕФЩшБИЩЯЭјЕФЁЃ
етЪБЕФЮЪЬтОЭЪЧЃКдЫгЊЪ§ОнжааФЕФШЫЪЧдѕУДАбетаЉЩшБИЭГвЛЕФЙмРэЦ№РДЕФФиЃП
СщЛюОЭЪЧЯыЩЖЪБвЊЖМгаЃЌЯывЊЖрЩйЖМаа
ЙмРэЕФФПБъОЭЪЧвЊДяЕНСНИіЗНУцЕФСщЛюадЁЃОпЬхФФСНИіЗНУцФиЃП
ОйИіР§згРДРэНтЃКБШШчгаИіШЫашвЊвЛЬЈКмаЁЕФЕчФдЃЌжЛгавЛИі CPUЁЂ1G ФкДцЁЂ10G ЕФгВХЬЁЂвЛезЕФДјПэЃЌФуФмИјЫћТ№ЃП
ЯёетУДаЁЙцИёЕФЕчФдЃЌЯждкЫцБувЛИіБЪМЧБОЕчФдЖМБШетИіХфжУЧПСЫЃЌМвРяЫцБуРвЛИіПэДјЖМвЊ 100MЁЃШЛЖјШчЙћШЅвЛИідЦМЦЫуЕФЦНЬЈЩЯЃЌЫћЯывЊетИізЪдДЪБЃЌжЛвЊвЛЕуОЭгаСЫЁЃ
етжжЧщПіЯТЫќОЭФмДяЕНСНИіЗНУцЕФСщЛюадЃК
ЪБМфСщЛюадЃКЯыЪВУДЪБКђвЊОЭЪВУДЪБКђвЊЃЌашвЊЕФЪБКђвЛЕуОЭГіРДСЫЁЃ
ПеМфСщЛюадЃКЯывЊЖрЩйОЭгаЖрЩйЁЃашвЊвЛИіПеМфКмаЁЕФЕчФдЃЌПЩвдТњзуЃЛашвЊвЛИіЬиБ№ДѓЕФПеМфР§ШчдЦХЬЃЌдЦХЬИјУПИіШЫЗжХфЕФПеМфЖЏВЛЖЏОЭКмДѓКмДѓЃЌЫцЪБЩЯДЋЫцЪБгаПеМфЃЌгРдЖгУВЛЭъЃЌвВЪЧПЩвдТњзуЕФЁЃ
ПеМфСщЛюадКЭЪБМфСщЛюадЃЌМДЮвУЧГЃЫЕЕФдЦМЦЫуЕФЕЏадЁЃЖјНтОіетИіЕЏадЕФЮЪЬтЃЌОРњСЫТўГЄЪБМфЕФЗЂеЙЁЃ
ЮяРэЩшБИВЛСщЛю
ЕквЛИіНзЖЮЪЧЮяРэЩшБИЪБЦкЁЃетИіЪБЦкПЭЛЇашвЊвЛЬЈЕчФдЃЌЮвУЧОЭТђвЛЬЈЗХдкЪ§ОнжааФРяЁЃ
ЮяРэЩшБИЕБШЛЪЧдНРДдНХЃЃК
Р§ШчЗўЮёЦїЃЌФкДцЖЏВЛЖЏОЭЪЧАй G ФкДцЁЃ
Р§ШчЭјТчЩшБИЃЌвЛИіЖЫПкЕФДјПэОЭФмгаМИЪЎ G ЩѕжСЩЯАй GЁЃ
Р§ШчДцДЂЃЌдкЪ§ОнжааФжСЩйЪЧ PB МЖБ№ЕФ(вЛИі P ЪЧ 1000 Иі TЃЌвЛИі T ЪЧ 1000 Иі
G)ЁЃ
ШЛЖјЮяРэЩшБИВЛФмзіЕНКмКУЕФСщЛюадЃК
ЪзЯШЪЧЫќШБЗІЪБМфСщЛюадЁЃВЛФмЙЛДяЕНЯыЪВУДЪБКђвЊОЭЪВУДЪБКђвЊЁЃБШШчТђЬЈЗўЮёЦїЁЂТђИіЕчФдЃЌЖМвЊгаВЩЙКЕФЪБМфЁЃ
ШчЙћЭЛШЛгУЛЇИцЫпФГИідЦГЇЩЬЃЌЫЕЯывЊПЊЬЈЕчФдЃЌЪЙгУЮяРэЗўЮёЦїЃЌЕБЪБШЅВЩЙКОЭКмФбЁЃгыЙЉгІЩЬЙиЯЕКУЕФПЩФмашвЊвЛИіаЧЦкЃЌгыЙЉгІЩЬЙиЯЕвЛАуЕФОЭПЩФмашвЊВЩЙКвЛИідТЁЃ
гУЛЇЕШСЫКмОУЕчФдВХЕНЮЛЃЌетЪБгУЛЇЛЙвЊЕЧТМЩЯШЅТ§Т§ПЊЪМВПЪ№здМКЕФгІгУЁЃЪБМфСщЛюадЗЧГЃВюЁЃ
ЦфДЮЪЧЫќЕФПеМфСщЛюадвВВЛааЁЃР§ШчЩЯЪіЕФгУЛЇашвЊвЛИіКмаЁКмаЁЕФЕчФдЃЌЕЋЯждкФФЛЙгаетУДаЁаЭКХЕФЕчФдЃПВЛФмЮЊСЫТњзугУЛЇжЛвЊвЛИі G ЕФФкДцЁЂ80G гВХЬЕФЃЌОЭШЅТђвЛИіетУДаЁЕФЛњЦїЁЃ
ЕЋЪЧШчЙћТђвЛИіДѓЕФЃЌгжЛсвђЮЊЕчФдДѓЃЌашвЊЯђгУЛЇЖрЪеЧЎЃЌПЩгУЛЇашвЊгУЕФжЛгаФЧУДаЁвЛЕуЃЌЫљвдЖрИЖЧЎОЭКмдЉЁЃ
ащФтЛЏСщЛюЖрСЫ
гаШЫОЭЯыАьЗЈСЫЁЃЕквЛИіАьЗЈОЭЪЧащФтЛЏЁЃгУЛЇВЛЪЧжЛвЊвЛИіКмаЁЕФЕчФдУДЃП
Ъ§ОнжааФЕФЮяРэЩшБИЖМКмЧПДѓЃЌЮвПЩвдДгЮяРэЕФ CPUЁЂФкДцЁЂгВХЬжаащФтГівЛаЁПщРДИјПЭЛЇЃЌЭЌЪБвВПЩвдащФтГівЛаЁПщРДИјЦфЫћПЭЛЇЁЃ
УПИіПЭЛЇжЛФмПДЕНздМКЕФФЧвЛаЁПщЃЌЕЋЦфЪЕУПИіПЭЛЇгУЕФЪЧећИіДѓЕФЩшБИЩЯЕФвЛаЁПщЁЃ
ащФтЛЏЕФММЪѕЪЙЕУВЛЭЌПЭЛЇЕФЕчФдПДЦ№РДЪЧИєРыЕФЁЃвВОЭЪЧЮвПДзХКУЯёетПщХЬОЭЪЧЮвЕФЃЌФуПДзХетПщХЬОЭЪЧФуЕФЃЌЕЋЪЕМЪЧщПіПЩФмЮвЕФетИі
10G КЭФуЕФетИі 10G ЪЧТфдкЭЌбљвЛИіКмДѓКмДѓЕФДцДЂЩЯЁЃ
ЖјЧвШчЙћЪТЯШЮяРэЩшБИЖМзМБИКУЃЌащФтЛЏШэМўащФтГівЛИіЕчФдЪЧЗЧГЃПьЕФЃЌЛљБОЩЯМИЗжжгОЭФмНтОіЁЃЫљвддкШЮКЮвЛИідЦЩЯвЊДДНЈвЛЬЈЕчФдЃЌвЛЕуМИЗжжгОЭГіРДСЫЃЌОЭЪЧетИіЕРРэЁЃ
етбљПеМфСщЛюадКЭЪБМфСщЛюадОЭЛљБОНтОіСЫЁЃ
ащФтЪРНчЕФзЌЧЎгыЧщЛГ
дкащФтЛЏНзЖЮЃЌзюХЃЕФЙЋЫОЪЧ VMwareЁЃЫќЪЧЪЕЯжащФтЛЏММЪѕБШНЯдчЕФвЛМвЙЋЫОЃЌПЩвдЪЕЯжМЦЫуЁЂЭјТчЁЂДцДЂЕФащФтЛЏЁЃ
етМвЙЋЫОКмХЃЃЌадФмзіЕУЗЧГЃКУЃЌащФтЛЏШэМўТєЕУвВЗЧГЃКУЃЌзЌСЫКУЖрЕФЧЎЃЌКѓРДШУ EMC(ЪРНчЮхАйЧПЃЌДцДЂГЇЩЬЕквЛЦЗХЦ)ИјЪеЙКСЫЁЃ
ЕЋетИіЪРНчЩЯЛЙЪЧгаКмЖргаЧщЛГЕФШЫЕФЃЌгШЦфЪЧГЬађдБРяУцЁЃгаЧщЛГЕФШЫЯВЛЖзіЪВУДЪТЧщЃППЊдДЁЃ
етИіЪРНчЩЯКмЖрШэМўЖМЪЧгаБедДОЭгаПЊдДЃЌдДОЭЪЧдДДњТыЁЃвВОЭЪЧЫЕЃЌФГИіШэМўзіЕФКУЃЌЫљгаШЫЖМАЎгУЃЌЕЋетИіШэМўЕФДњТыБЛЮвЗтБеЦ№РДЃЌжЛгаЮвЙЋЫОжЊЕРЃЌЦфЫћШЫВЛжЊЕРЁЃ
ШчЙћЦфЫћШЫЯыгУетИіШэМўЃЌОЭвЊЯђЮвИЖЧЎЃЌетОЭНаБедДЁЃЕЋЪРНчЩЯзмгавЛаЉДѓХЃПДВЛЙпЧЎЖМШУвЛМвзЌСЫШЅЕФЧщПіЁЃДѓХЃУЧОѕЕУЃЌетИіММЪѕФуЛсЮввВЛсЃЛФуФмПЊЗЂГіРДЃЌЮввВФмЁЃ
ЮвПЊЗЂГіРДОЭЪЧВЛЪеЧЎЃЌАбДњТыФУГіРДЗжЯэИјДѓМвЃЌШЋЪРНчЫгУЖМПЩвдЃЌЫљгаЕФШЫЖМПЩвдЯэЪмЕНКУДІЃЌетИіНазіПЊдДЁЃ
БШШчзюНќЕФЕйФЗЁЄВЎФЩЫЙЁЄРюОЭЪЧИіЗЧГЃгаЧщЛГЕФШЫЁЃ2017 ФъЃЌЫћвђЁАЗЂУїЭђЮЌЭјЁЂЕквЛИіфЏРРЦїКЭЪЙЭђЮЌЭјЕУвдРЉеЙЕФЛљБОавщКЭЫуЗЈЁБЖјЛёЕУ
2016 ФъЖШЕФЭМСщНБЁЃ
ЭМСщНБОЭЪЧМЦЫуЛњНчЕФХЕБДЖћНБЁЃШЛЖјЫћзюСюШЫОДХхЕФЪЧЃЌЫћНЋЭђЮЌЭјЃЌвВОЭЪЧЮвУЧГЃМћЕФ WWW ММЪѕЮоГЅЙБЯзИјШЋЪРНчУтЗбЪЙгУЁЃ
ЮвУЧЯждкдкЭјЩЯЕФЫљгаааЮЊЖМгІИУИааЛЫћЕФЙІРЭЃЌШчЙћЫћНЋетИіММЪѕФУРДЪеЧЎЃЌгІИУКЭБШЖћИЧДФВюВЛЖргаЧЎЁЃ
ПЊдДКЭБедДЕФР§зггаКмЖрЃКР§ШчдкБедДЕФЪРНчРяга WindowsЃЌДѓМвгУ Windows ЖМЕУИјЮЂШэИЖЧЎЃЛПЊдДЕФЪРНчРяУцОЭГіЯжСЫ
LinuxЁЃ
БШЖћИЧДФПП WindowsЁЂOffice етаЉБедДЕФШэМўзЌСЫКмЖрЧЎЃЌГЦЮЊЪРНчЪзИЛЃЌОЭгаДѓХЃПЊЗЂСЫСэЭтвЛжжВйзїЯЕЭГ
LinuxЁЃ
КмЖрШЫПЩФмУЛгаЬ§ЫЕЙ§ LinuxЃЌКмЖрКѓЬЈЕФЗўЮёЦїЩЯХмЕФГЬађЖМЪЧ Linux ЩЯЕФЃЌБШШчДѓМвЯэЪмЫЋЪЎвЛЃЌЮоТлЪЧЬдБІЁЂОЉЖЋЁЂПМРЁЁжЇГХЫЋЪЎвЛЧРЙКЕФЯЕЭГЖМЪЧХмдк
Linux ЩЯЕФЁЃ
дйШчга Apple ОЭгаАВзПЁЃApple ЪажЕКмИпЃЌЕЋЪЧЦЛЙћЯЕЭГЕФДњТыЮвУЧЪЧПДВЛЕНЕФЃЌгкЪЧОЭгаДѓХЃаДСЫАВзПЪжЛњВйзїЯЕЭГЁЃ
ЫљвдДѓМвПЩвдПДЕНМИКѕЫљгаЕФЦфЫћЪжЛњГЇЩЬЃЌРяУцЖМзААВзПЯЕЭГЁЃдвђОЭЪЧЦЛЙћЯЕЭГВЛПЊдДЃЌЖјАВзПЯЕЭГДѓМвЖМПЩвдгУЁЃ
дкащФтЛЏШэМўвВвЛбљЃЌгаСЫ VMwareЃЌетИіШэМўЗЧГЃЙѓЁЃФЧОЭгаДѓХЃаДСЫСНИіПЊдДЕФащФтЛЏШэМўЃЌвЛИіНазі
XenЃЌвЛИіНазі KVMЃЌШчЙћВЛзіММЪѕЕФЃЌПЩвдВЛгУЙметСНИіУћзжЃЌЕЋЪЧКѓУцЛЙЪЧЛсЬсЕНЁЃ
ащФтЛЏЕФАыздЖЏКЭдЦМЦЫуЕФШЋздЖЏ
вЊЫЕащФтЛЏШэМўНтОіСЫСщЛюадЮЪЬтЃЌЦфЪЕВЂВЛШЋЖдЁЃвђЮЊащФтЛЏШэМўвЛАуДДНЈвЛЬЈащФтЕФЕчФдЃЌЪЧашвЊШЫЙЄжИЖЈетЬЈащФтЕчФдЗХдкФФЬЈЮяРэЛњЩЯЕФЁЃ
етвЛЙ§ГЬПЩФмЛЙашвЊБШНЯИДдгЕФШЫЙЄХфжУЁЃЫљвдЪЙгУ VMware ЕФащФтЛЏШэМўЃЌашвЊПМвЛИіКмХЃЕФжЄЪщЃЌЖјФмФУЕНетИіжЄЪщЕФШЫЃЌаНзЪЪЧЯрЕБИпЃЌвВПЩМћЦфИДдгГЬЖШЁЃ
ЫљвдНіНіЦОащФтЛЏШэМўЫљФмЙмРэЕФЮяРэЛњЕФМЏШКЙцФЃЖМВЛЪЧЬиБ№ДѓЃЌвЛАудкЪЎМИЬЈЁЂМИЪЎЬЈЁЂзюЖрАйЬЈетУДвЛИіЙцФЃЁЃ
етвЛЗНУцЛсгАЯьЪБМфСщЛюадЃКЫфШЛащФтГівЛЬЈЕчФдЕФЪБМфКмЖЬЃЌЕЋЪЧЫцзХМЏШКЙцФЃЕФРЉДѓЃЌШЫЙЄХфжУЕФЙ§ГЬдНРДдНИДдгЃЌдНРДдНКФЪБЁЃ
СэвЛЗНУцвВгАЯьПеМфСщЛюадЃКЕБгУЛЇЪ§СПЖрЪБЃЌетЕуМЏШКЙцФЃЃЌЛЙдЖДяВЛЕНЯывЊЖрЩйвЊЖрЩйЕФГЬЖШЃЌКмПЩФметЕузЪдДКмПьОЭгУЭъСЫЃЌЛЙЕУШЅВЩЙКЁЃ
ЫљвдЫцзХМЏШКЕФЙцФЃдНРДдНДѓЃЌЛљБОЖМЪЧЧЇЬЈЦ№ВНЃЌЖЏщќЩЯЭђЬЈЁЂЩѕжСМИЪЎЩЯАйЭђЬЈЁЃШчЙћШЅВщвЛЯТ BATЃЌАќРЈЭјвзЁЂЙШИшЁЂбЧТэбЗЃЌЗўЮёЦїЪ§ФПЖМДѓЕФЯХШЫЁЃ
етУДЖрЛњЦївЊППШЫШЅбЁвЛИіЮЛжУЗХетЬЈащФтЛЏЕФЕчФдВЂзіЯргІЕФХфжУЃЌМИКѕЪЧВЛПЩФмЕФЪТЧщЃЌЛЙЪЧашвЊЛњЦїШЅзіетИіЪТЧщЁЃ
ШЫУЧЗЂУїСЫИїжжИїбљЕФЫуЗЈРДзіетИіЪТЧщЃЌЫуЗЈЕФУћзжНазіЕїЖШ(Scheduler)ЁЃ
ЭЈЫзвЛЕуЫЕЃЌОЭЪЧгавЛИіЕїЖШжааФЃЌМИЧЇЬЈЛњЦїЖМдквЛИіГизгРяУцЃЌЮоТлгУЛЇашвЊЖрЩй CPUЁЂФкДцЁЂгВХЬЕФащФтЕчФдЃЌЕїЖШжааФЛсздЖЏдкДѓГизгРяУцеввЛИіФмЙЛТњзугУЛЇашЧѓЕФЕиЗНЃЌАбащФтЕчФдЦєЖЏЦ№РДзіКУХфжУЃЌгУЛЇОЭжБНгФмгУСЫЁЃ
етИіНзЖЮЮвУЧГЦЮЊГиЛЏЛђепдЦЛЏЁЃЕНСЫетИіНзЖЮЃЌВХПЩвдГЦЮЊдЦМЦЫуЃЌдкетжЎЧАЖМжЛФмНаащФтЛЏЁЃ
дЦМЦЫуЕФЫНгагыЙЋга
дЦМЦЫуДѓжТЗжСНжжЃКвЛИіЪЧЫНгадЦЃЌвЛИіЪЧЙЋгадЦЃЌЛЙгаШЫАбЫНгадЦКЭЙЋгадЦСЌНгЦ№РДГЦЮЊЛьКЯдЦЃЌетРяднЧвВЛЫЕетИіЁЃ
ЫНгадЦЃКАбащФтЛЏКЭдЦЛЏЕФетЬзШэМўВПЪ№дкБ№ШЫЕФЪ§ОнжааФРяУцЁЃЪЙгУЫНгадЦЕФгУЛЇЭљЭљКмгаЧЎЃЌздМКТђЕиНЈЛњЗПЁЂздМКТђЗўЮёЦїЃЌШЛКѓШУдЦГЇЩЬВПЪ№дкздМКетРяЁЃ
VMware КѓРДГ§СЫащФтЛЏЃЌвВЭЦГіСЫдЦМЦЫуЕФВњЦЗЃЌВЂЧвдкЫНгадЦЪаГЁзЌЕФХшТњВЇТњ
ЙЋгадЦЃКАбащФтЛЏКЭдЦЛЏШэМўВПЪ№дкдЦГЇЩЬздМКЪ§ОнжааФРяУцЕФЃЌгУЛЇВЛашвЊКмДѓЕФЭЖШыЃЌжЛвЊзЂВсвЛИіеЫКХЃЌОЭФмдквЛИіЭјвГЩЯЕувЛЯТДДНЈвЛЬЈащФтЕчФдЁЃ
Р§Шч AWS МДбЧТэбЗЕФЙЋгадЦЃЛЙњФкЕФАЂРядЦЁЂЬкбЖдЦЁЂЭјвздЦЕШЁЃ
бЧТэбЗЮЊЪВУДвЊзіЙЋгадЦФиЃПЮвУЧжЊЕРбЧТэбЗдРДЪЧЙњЭтБШНЯДѓЕФвЛИіЕчЩЬЃЌЫќзіЕчЩЬЪБвВПЯЖЈЛсгіЕНРрЫЦЫЋЪЎвЛЕФГЁОАЃКдкФГвЛИіЪБПЬДѓМвЖМГхЩЯРДТђЖЋЮїЁЃ
ЕБДѓМвЖМГхЩЯТђЖЋЮїЪБЃЌОЭЬиБ№ашвЊдЦЕФЪБМфСщЛюадКЭПеМфСщЛюадЁЃвђЮЊЫќВЛФмЪБПЬзМБИКУЫљгаЕФзЪдДЃЌФЧбљЬЋРЫЗбСЫЁЃЕЋвВВЛФмЪВУДЖМВЛзМБИЃЌПДзХЫЋЪЎвЛетУДЖргУЛЇЯыТђЖЋЮїЕЧВЛЩЯШЅЁЃ
ЫљвдашвЊЫЋЪЎвЛЪБЃЌОЭДДНЈвЛДѓХњащФтЕчФдРДжЇГХЕчЩЬгІгУЃЌЙ§СЫЫЋЪЎвЛдйАбетаЉзЪдДЖМЪЭЗХЕєШЅИЩБ№ЕФЁЃвђДЫбЧТэбЗЪЧашвЊвЛИідЦЦНЬЈЕФЁЃ
ШЛЖјЩЬгУЕФащФтЛЏШэМўЪЕдкЪЧЬЋЙѓСЫЃЌбЧТэбЗзмВЛФмАбздМКдкЕчЩЬзЌЕФЧЎШЋВПИјСЫащФтЛЏГЇЩЬЁЃ
гкЪЧбЧТэбЗЛљгкПЊдДЕФащФтЛЏММЪѕЃЌШчЩЯЫљЪіЕФ Xen Лђеп KVMЃЌПЊЗЂСЫвЛЬзздМКЕФдЦЛЏШэМўЁЃУЛЯыЕНбЧТэбЗКѓРДЕчЩЬдНзідНХЃЃЌдЦЦНЬЈвВдНзідНХЃЁЃ
гЩгкЫќЕФдЦЦНЬЈашвЊжЇГХздМКЕФЕчЩЬгІгУЃЛЖјДЋЭГЕФдЦМЦЫуГЇЩЬЖрЮЊ IT ГЇЩЬГіЩэЃЌМИКѕУЛгаздМКЕФгІгУЃЌЫљвдбЧТэбЗЕФдЦЦНЬЈЖдгІгУИќМггбКУЃЌбИЫйЗЂеЙГЩЮЊдЦМЦЫуЕФЕквЛЦЗХЦЃЌзЌСЫКмЖрЧЎЁЃ
дкбЧТэбЗЙЋВМЦфдЦМЦЫуЦНЬЈВЦБЈжЎЧАЃЌШЫУЧЖМВТВтЃЌбЧТэбЗЕчЩЬзЌЧЎЃЌдЦвВзЌЧЎТ№ЃПКѓРДвЛЙЋВМВЦБЈЃЌЗЂЯжВЛЪЧвЛАуЕФзЌЧЎЁЃНіНіШЅФъЃЌбЧТэбЗ
AWS ФъгЊЪеДя 122 вкУРдЊЃЌдЫгЊРћШѓ 31 вкУРдЊЁЃ
дЦМЦЫуЕФзЌЧЎгыЧщЛГ
ЙЋгадЦЕФЕквЛУћбЧТэбЗЙ§ЕУКмЫЌЃЌЕкЖўУћ Rackspace Й§ЕУОЭвЛАуСЫЁЃУЛАьЗЈЃЌетОЭЪЧЛЅСЊЭјаавЕЕФВаПсадЃЌЖрЪЧгЎепЭЈГдЕФФЃЪНЁЃЫљвдЕкЖўУћШчЙћВЛЪЧдЦМЦЫуаавЕЕФЃЌКмЖрШЫПЩФмЖМУЛЬ§Й§СЫЁЃ
ЕкЖўУћОЭЯыЃЌЮвИЩВЛЙ§РЯДѓдѕУДАьФиЃППЊдДАЩЁЃШчЩЯЫљЪіЃЌбЧТэбЗЫфШЛЪЙгУСЫПЊдДЕФащФтЛЏММЪѕЃЌЕЋдЦЛЏЕФДњТыЪЧБедДЕФЁЃ
КмЖрЯызігжзіВЛСЫдЦЛЏЦНЬЈЕФЙЋЫОЃЌжЛФмблАЭАЭЕФПДзХбЧТэбЗеѕДѓЧЎЁЃRackspace АбдДДњТывЛЙЋПЊЃЌећИіаавЕОЭПЩвдвЛЦ№АбетИіЦНЬЈдНзідНКУЃЌажЕмУЧДѓМввЛЦ№ЩЯЃЌКЭРЯДѓЦДСЫЁЃ
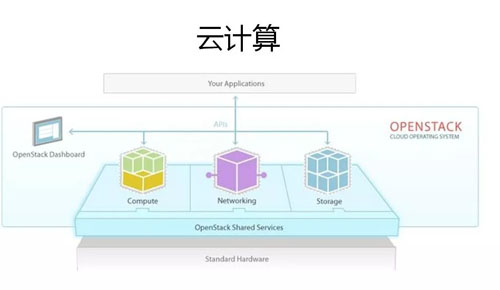
гкЪЧ Rackspace КЭУРЙњКНПеКНЬьОжКЯзїДДАьСЫПЊдДШэМў OpenStackЃЌШчЩЯЭМЫљЪО OpenStack
ЕФМмЙЙЭМЃЌВЛЪЧдЦМЦЫуаавЕЕФВЛгУХЊЖЎетИіЭМЁЃ
ЕЋФмЙЛПДЕНШ§ИіЙиМќзжЃКCompute МЦЫуЁЂNetworking ЭјТчЁЂStorage ДцДЂЁЃЛЙЪЧвЛИіМЦЫуЁЂЭјТчЁЂДцДЂЕФдЦЛЏЙмРэЦНЬЈЁЃ
ЕБШЛЕкЖўУћЕФММЪѕвВЪЧЗЧГЃАєЕФЃЌгаСЫ OpenStack жЎКѓЃЌЙћецЯё Rackspace ЯыЕФвЛбљЃЌЫљгаЯызідЦЕФДѓЦѓвЕЖМЗшСЫЃЌФуФмЯыЯѓЕНЕФЫљгаШчРзЙсЖњЕФДѓаЭ
IT ЦѓвЕЃКIBMЁЂЛнЦеЁЂДїЖћЁЂЛЊЮЊЁЂСЊЯыЕШЖМЗшСЫЁЃ
дРДдЦЦНЬЈДѓМвЖМЯызіЃЌПДзХбЧТэбЗКЭ VMware зЌСЫетУДЖрЧЎЃЌблАЭАЭПДзХУЛАьЗЈЃЌЯыздМКзівЛИіКУЯёФбЖШЛЙЭІДѓЁЃ
ЯждкКУСЫЃЌгаСЫетбљвЛИіПЊдДЕФдЦЦНЬЈ OpenStackЃЌЫљгаЕФ IT ГЇЩЬЖММгШыЕНетИіЩчЧјжаРДЃЌЖдетИідЦЦНЬЈНјааЙБЯзЃЌАќзАГЩздМКЕФВњЦЗЃЌСЌЭЌздМКЕФгВМўЩшБИвЛЦ№ТєЁЃ
гаЕФзіСЫЫНгадЦЃЌгаЕФзіСЫЙЋгадЦЃЌOpenStack вбОГЩЮЊПЊдДдЦЦНЬЈЕФЪТЪЕБъзМЁЃ
IaaSЃЌзЪдДВуУцЕФСщЛюад
ЫцзХ OpenStack ЕФММЪѕдНРДдНГЩЪьЃЌПЩвдЙмРэЕФЙцФЃвВдНРДдНДѓЃЌВЂЧвПЩвдгаЖрИі OpenStack
МЏШКВПЪ№ЖрЬзЁЃ
БШШчББОЉВПЪ№вЛЬзЁЂКМжнВПЪ№СНЬзЁЂЙужнВПЪ№вЛЬзЃЌШЛКѓНјааЭГвЛЕФЙмРэЁЃетбљећИіЙцФЃОЭИќДѓСЫЁЃ
дкетИіЙцФЃЯТЃЌЖдгкЦеЭЈгУЛЇЕФИажЊРДНВЃЌЛљБОФмЙЛзіЕНЯыЪВУДЪБКђвЊОЭЪВУДЪБКђвЊЃЌЯывЊЖрЩйОЭвЊЖрЩйЁЃ
ЛЙЪЧФУдЦХЬОйР§згЃЌУПИігУЛЇдЦХЬЖМЗжХфСЫ 5T ЩѕжСИќДѓЕФПеМфЃЌШчЙћга 1 вкШЫЃЌФЧМгЦ№РДПеМфЖрДѓАЁЁЃ
ЦфЪЕБГКѓЕФЛњжЦЪЧетбљЕФЃКЗжХфФуЕФПеМфЃЌФуПЩФмжЛгУСЫЦфжаКмЩйвЛЕуЃЌБШШчЫЕЫќЗжХфИјФуСЫ 5 Иі TЃЌетУДДѓЕФПеМфНіНіЪЧФуПДЕНЕФЃЌЖјВЛЪЧецЕФОЭИјФуСЫЁЃ
ФуЦфЪЕжЛгУСЫ 50 Иі GЃЌдђецЪЕИјФуЕФОЭЪЧ 50 Иі GЃЌЫцзХФуЮФМўЕФВЛЖЯЩЯДЋЃЌЗжИјФуЕФПеМфЛсдНРДдНЖрЁЃ
ЕБДѓМвЖМЩЯДЋЃЌдЦЦНЬЈЗЂЯжПьТњСЫЕФЪБКђ(Р§ШчгУСЫ 70%)ЃЌЛсВЩЙКИќЖрЕФЗўЮёЦїЃЌРЉГфБГКѓЕФзЪдДЃЌетИіЖдгУЛЇЪЧЭИУїЕФЁЂПДВЛЕНЕФЁЃ
ДгИаОѕЩЯРДНВЃЌОЭЪЕЯжСЫдЦМЦЫуЕФЕЏадЁЃЦфЪЕгаЕуЯёвјааЃЌИјДЂЛЇЕФИаОѕЪЧЪВУДЪБКђШЁЧЎЖМгаЃЌжЛвЊВЛЭЌЪБМЗЖвЃЌвјааОЭВЛЛсПхЁЃ
змНс
ЕНСЫетИіНзЖЮЃЌдЦМЦЫуЛљБОЩЯЪЕЯжСЫЪБМфСщЛюадКЭПеМфСщЛюадЃЛЪЕЯжСЫМЦЫуЁЂЭјТчЁЂДцДЂзЪдДЕФЕЏадЁЃ
МЦЫуЁЂЭјТчЁЂДцДЂЮвУЧГЃГЦЮЊЛљДЁЩшЪЉ Infranstracture, вђЖјетИіНзЖЮЕФЕЏадГЦЮЊзЪдДВуУцЕФЕЏадЁЃ
ЙмРэзЪдДЕФдЦЦНЬЈЃЌЮвУЧГЦЮЊЛљДЁЩшЪЉЗўЮёЃЌвВОЭЪЧЮвУЧГЃЬ§ЕНЕФ IaaSЃЈInfranstracture
As A ServiceЃЉЁЃ
дЦМЦЫуВЛЙтЙмзЪдДЃЌвВвЊЙмгІгУ
гаСЫ IaaSЃЌЪЕЯжСЫзЪдДВуУцЕФЕЏадОЭЙЛСЫТ№ЃПЯдШЛВЛЪЧЃЌЛЙгагІгУВуУцЕФЕЏадЁЃ
етРяОйИіР§згЃКБШШчЫЕЪЕЯжвЛИіЕчЩЬЕФгІгУЃЌЦНЪБЪЎЬЈЛњЦїОЭЙЛСЫЃЌЫЋЪЎвЛашвЊвЛАйЬЈЁЃФуПЩФмОѕЕУКмКУАьАЁЃЌгаСЫ
IaaSЃЌаТДДНЈОХЪЎЬЈЛњЦїОЭПЩвдСЫАЁЁЃ
ЕЋ 90 ЬЈЛњЦїДДНЈГіРДЪЧПеЕФЃЌЕчЩЬгІгУВЂУЛгаЗХЩЯШЅЃЌжЛФмШУЙЋЫОЕФдЫЮЌШЫдБвЛЬЈвЛЬЈЕФХЊЃЌашвЊКмГЄЪБМфВХФмАВзАКУЕФЁЃ
ЫфШЛзЪдДВуУцЪЕЯжСЫЕЏадЃЌЕЋУЛгагІгУВуЕФЕЏадЃЌвРШЛСщЛюадЪЧВЛЙЛЕФЁЃгаУЛгаЗНЗЈНтОіетИіЮЪЬтФиЃП
ШЫУЧдк IaaS ЦНЬЈжЎЩЯгжМгСЫвЛВуЃЌгУгкЙмРэзЪдДвдЩЯЕФгІгУЕЏадЕФЮЪЬтЃЌетвЛВуЭЈГЃГЦЮЊ PaaSЃЈPlatform
As A ServiceЃЉЁЃ
етвЛВуЭљЭљБШНЯФбРэНтЃЌДѓжТЗжСНВПЗжЃКвЛВПЗжБЪепГЦЮЊЁАФуздМКЕФгІгУздЖЏАВзАЁБЃЌвЛВПЗжБЪепГЦЮЊЁАЭЈгУЕФгІгУВЛгУАВзАЁБЁЃ
здМКЕФгІгУздЖЏАВзАЃКБШШчЕчЩЬгІгУЪЧФуздМКПЊЗЂЕФЃЌГ§СЫФуздМКЃЌЦфЫћШЫЪЧВЛжЊЕРдѕУДАВзАЕФЁЃ
ЯёЕчЩЬгІгУЃЌАВзАЪБашвЊХфжУжЇИЖБІЛђепЮЂаХЕФеЫКХЃЌВХФмЪЙБ№ШЫдкФуЕФЕчЩЬЩЯТђЖЋЮїЪБЃЌИЖЕФЧЎЪЧДђЕНФуЕФеЫЛЇРяУцЕФЃЌГ§СЫФуЃЌЫвВВЛжЊЕРЁЃ
ЫљвдАВзАЕФЙ§ГЬЦНЬЈАяВЛСЫУІЃЌЕЋФмЙЛАяФузіЕУздЖЏЛЏЃЌФуашвЊзівЛаЉЙЄзїЃЌНЋздМКЕФХфжУаХЯЂШкШыЕНздЖЏЛЏЕФАВзАЙ§ГЬжаЗНПЩЁЃ
БШШчЩЯУцЕФР§згЃЌЫЋЪЎвЛаТДДНЈГіРДЕФ 90 ЬЈЛњЦїЪЧПеЕФЃЌШчЙћФмЙЛЬсЙЉвЛИіЙЄОпЃЌФмЙЛздЖЏдкетаТЕФ 90
ЬЈЛњЦїЩЯНЋЕчЩЬгІгУАВзАКУЃЌОЭФмЙЛЪЕЯжгІгУВуУцЕФеце§ЕЏадЁЃ
Р§Шч PuppetЁЂChefЁЂAnsibleЁЂCloud Foundary ЖМПЩвдИЩетМўЪТЧщЃЌзюаТЕФШнЦїММЪѕ
Docker ФмИќКУЕФИЩетМўЪТЧщЁЃ
ЭЈгУЕФгІгУВЛгУАВзАЃКЫљЮНЭЈгУЕФгІгУЃЌвЛАужИвЛаЉИДдгадБШНЯИпЃЌЕЋДѓМвЖМдкгУЕФЃЌР§ШчЪ§ОнПтЁЃМИКѕЫљгаЕФгІгУЖМЛсгУЪ§ОнПтЃЌЕЋЪ§ОнПтШэМўЪЧБъзМЕФЃЌЫфШЛАВзАКЭЮЌЛЄБШНЯИДдгЃЌЕЋЮоТлЫАВзАЖМЪЧвЛбљЁЃ
етбљЕФгІгУПЩвдБфГЩБъзМЕФ PaaS ВуЕФгІгУЗХдкдЦЦНЬЈЕФНчУцЩЯЁЃЕБгУЛЇашвЊвЛИіЪ§ОнПтЪБЃЌвЛЕуОЭГіРДСЫЃЌгУЛЇОЭПЩвджБНггУСЫЁЃ
гаШЫЮЪЃЌМШШЛЫАВзАЖМвЛИібљЃЌФЧЮвздМКРДКУСЫЃЌВЛашвЊЛЈЧЎдкдЦЦНЬЈЩЯТђЁЃЕБШЛВЛЪЧЃЌЪ§ОнПтЪЧвЛИіЗЧГЃФбЕФЖЋЮїЃЌЙт
Oracle етМвЙЋЫОЃЌППЪ§ОнПтОЭФмзЌетУДЖрЧЎЁЃТђ Oracle вВЪЧвЊЛЈКмЖрЧЎЕФЁЃ
ШЛЖјДѓЖрЪ§дЦЦНЬЈЛсЬсЙЉ MySQL етбљЕФПЊдДЪ§ОнПтЃЌгжЪЧПЊдДЃЌЧЎВЛашвЊЛЈетУДЖрСЫЁЃ
ЕЋЮЌЛЄетИіЪ§ОнПтЃЌШДашвЊзЈУХеавЛИіКмДѓЕФЭХЖгЃЌШчЙћетИіЪ§ОнПтФмЙЛгХЛЏЕНФмЙЛжЇГХЫЋЪЎвЛЃЌвВВЛЪЧвЛФъСНФъФмЙЛИуЖЈЕФЁЃ
БШШчФњЪЧвЛИізіЕЅГЕЕФЃЌЕБШЛУЛБивЊеавЛИіЗЧГЃДѓЕФЪ§ОнПтЭХЖгРДИЩетМўЪТЧщЃЌГЩБОЬЋИпСЫЃЌгІИУНЛИјдЦЦНЬЈРДзіетМўЪТЧщЁЃ
зЈвЕЕФЪТЧщзЈвЕЕФШЫРДзіЃЌдЦЦНЬЈзЈУХбјСЫМИАйШЫЮЌЛЄетЬзЯЕЭГЃЌФњжЛвЊзЈзЂгкФњЕФЕЅГЕгІгУОЭПЩвдСЫЁЃ
вЊУДЪЧздЖЏВПЪ№ЃЌвЊУДЪЧВЛгУВПЪ№ЃЌзмЕФРДЫЕОЭЪЧгІгУВуФувВвЊЩйВйаФЃЌетОЭЪЧ PaaS ВуЕФживЊзїгУЁЃ
ЫфЫЕНХБОЕФЗНЪНФмЙЛНтОіздМКЕФгІгУЕФВПЪ№ЮЪЬтЃЌШЛЖјВЛЭЌЕФЛЗОГЧЇВюЭђБ№ЃЌвЛИіНХБОЭљЭљдквЛИіЛЗОГЩЯдЫаае§ШЗЃЌЕНСэвЛИіЛЗОГОЭВЛе§ШЗСЫЁЃ
ЖјШнЦїЪЧФмИќКУЕиНтОіетИіЮЪЬтЁЃ
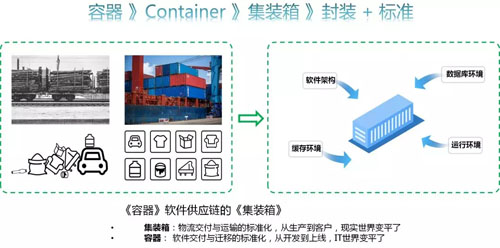
ШнЦїЪЧ ContainerЃЌContainer СэвЛИівтЫМЪЧМЏзАЯфЃЌЦфЪЕШнЦїЕФЫМЯыОЭЪЧвЊБфГЩШэМўНЛИЖЕФМЏзАЯфЁЃМЏзАЯфЕФЬиЕуЃКвЛЪЧЗтзАЃЌЖўЪЧБъзМЁЃ

дкУЛгаМЏзАЯфЕФЪБДњЃЌМйЩшНЋЛѕЮяДг A дЫЕН BЃЌжаМфвЊОЙ§Ш§ИіТыЭЗЁЂЛЛШ§ДЮДЌЁЃ
УПДЮЖМвЊНЋЛѕЮяаЖЯТДЌРДЃЌАкЕУЦпСуАЫТфЃЌШЛКѓАсЩЯДЌжиаТећЦыАкКУЁЃвђДЫдкУЛгаМЏзАЯфЪБЃЌУПДЮЛЛДЌЃЌДЌдБУЧЖМвЊдкАЖЩЯД§МИЬьВХФмзпЁЃ
гаСЫМЏзАЯфвдКѓЃЌЫљгаЕФЛѕЮяЖМДђАќдквЛЦ№СЫЃЌВЂЧвМЏзАЯфЕФГпДчШЋВПвЛжТЃЌЫљвдУПДЮЛЛДЌЪБЃЌвЛИіЯфзгећЬхАсЙ§ШЅОЭааСЫЃЌаЁЪБМЖБ№ОЭФмЭъГЩЃЌДЌдБдйвВВЛгУЩЯАЖГЄЪБМфЕЂИщСЫЁЃ
етЪЧМЏзАЯфЁАЗтзАЁБЁЂЁАБъзМЁБСНДѓЬиЕудкЩњЛюжаЕФгІгУЁЃ

ФЧУДШнЦїШчКЮЖдгІгУДђАќФиЃПЛЙЪЧвЊбЇЯАМЏзАЯфЁЃЪзЯШвЊгаИіЗтБеЕФЛЗОГЃЌНЋЛѕЮяЗтзАЦ№РДЃЌШУЛѕЮяжЎМфЛЅВЛИЩШХЁЂЛЅЯрИєРыЃЌетбљзАЛѕаЖЛѕВХЗНБуЁЃКУдк
Ubuntu жаЕФ LXC ММЪѕдчОЭФмзіЕНетвЛЕуЁЃ
ЗтБеЕФЛЗОГжївЊЪЙгУСЫСНжжММЪѕЃК
ПДЦ№РДЪЧИєРыЕФММЪѕЃЌГЦЮЊ NamespaceЃЌвВМДУПИі Namespace жаЕФгІгУПДЕНЕФЪЧВЛЭЌЕФ
IP ЕижЗЁЂгУЛЇПеМфЁЂГЬКХЕШЁЃ
гУЦ№РДЪЧИєРыЕФММЪѕЃЌГЦЮЊ CgroupsЃЌвВМДУїУїећЬЈЛњЦїгаКмЖрЕФ CPUЁЂФкДцЃЌЖјвЛИігІгУжЛФмгУЦфжаЕФвЛВПЗжЁЃ
ЫљЮНЕФОЕЯёЃЌОЭЪЧНЋФуКИКУМЏзАЯфЕФФЧвЛПЬЃЌНЋМЏзАЯфЕФзДЬЌБЃДцЯТРДЃЌОЭЯёЫяЮђПеЫЕЃКЁАЖЈЁБЃЌМЏзАЯфРяУцОЭЖЈдкСЫФЧвЛПЬЃЌШЛКѓНЋетвЛПЬЕФзДЬЌБЃДцГЩвЛЯЕСаЮФМўЁЃ
етаЉЮФМўЕФИёЪНЪЧБъзМЕФЃЌЫПДЕНетаЉЮФМўЖМФмЛЙдЕБЪБЖЈзЁЕФФЧИіЪБПЬЁЃНЋОЕЯёЛЙдГЩдЫааЪБЕФЙ§ГЬЃЈОЭЪЧЖСШЁОЕЯёЮФМўЃЌЛЙдФЧИіЪБПЬЕФЙ§ГЬЃЉЃЌОЭЪЧШнЦїдЫааЕФЙ§ГЬЁЃ
гаСЫШнЦїЃЌЪЙЕУ PaaS ВуЖдгкгУЛЇздЩэгІгУЕФздЖЏВПЪ№БфЕУПьЫйЖјгХбХЁЃ
ДѓЪ§ОнгЕБЇдЦМЦЫу
дк PaaS ВужавЛИіИДдгЕФЭЈгУгІгУОЭЪЧДѓЪ§ОнЦНЬЈЁЃДѓЪ§ОнЪЧШчКЮвЛВНвЛВНШкШыдЦМЦЫуЕФФиЃП
Ъ§ОнВЛДѓвВАќКЌжЧЛл
вЛПЊЪМетИіДѓЪ§ОнВЂВЛДѓЁЃдРДВХгаЖрЩйЪ§ОнЃПЯждкДѓМвЖМШЅПДЕчзгЪщЃЌЩЯЭјПДаТЮХСЫЃЌдкЮвУЧ 80 КѓаЁЪБКђЃЌаХЯЂСПУЛгаФЧУДДѓЃЌвВОЭПДПДЪщЁЂПДПДБЈЃЌвЛИіаЧЦкЕФБЈжНМгЦ№РДВХгаЖрЩйзжЃП
ШчЙћФуВЛдквЛИіДѓГЧЪаЃЌвЛИіЦеЭЈЕФбЇаЃЕФЭМЪщЙнМгЦ№РДвВУЛМИИіЪщМмЃЌЪЧКѓРДЫцзХаХЯЂЛЏЕФЕНРДЃЌаХЯЂВХЛсдНРДдНЖрЁЃ
ЪзЯШЮвУЧРДПДвЛЯТДѓЪ§ОнРяУцЕФЪ§ОнЃЌОЭЗжШ§жжРраЭ:
НсЙЙЛЏЕФЪ§ОнЃКМДгаЙЬЖЈИёЪНКЭгаЯоГЄЖШЕФЪ§ОнЁЃР§ШчЬюЕФБэИёОЭЪЧНсЙЙЛЏЕФЪ§ОнЃЌЙњМЎЃКжаЛЊШЫУёЙВКЭЙњЃЌУёзхЃКККЃЌадБ№ЃКФаЃЌетЖМНаНсЙЙЛЏЪ§ОнЁЃ
ЗЧНсЙЙЛЏЕФЪ§ОнЃКЯждкЗЧНсЙЙЛЏЕФЪ§ОндНРДдНЖрЃЌОЭЪЧВЛЖЈГЄЁЂЮоЙЬЖЈИёЪНЕФЪ§ОнЃЌР§ШчЭјвГЃЌгаЪБКђЗЧГЃГЄЃЌгаЪБКђМИОфЛАОЭУЛСЫЃЛР§ШчгявєЃЌЪгЦЕЖМЪЧЗЧНсЙЙЛЏЕФЪ§ОнЁЃ
АыНсЙЙЛЏЪ§ОнЃКЪЧвЛаЉ XML Лђеп HTML ЕФИёЪНЕФЃЌВЛДгЪТММЪѕЕФПЩФмВЛСЫНтЃЌЕЋвВУЛгаЙиЯЕЁЃ
ЦфЪЕЪ§ОнБОЩэВЛЪЧгагУЕФЃЌБиаывЊОЙ§вЛЖЈЕФДІРэЁЃР§ШчФуУПЬьХмВНДјИіЪжЛЗЪеМЏЕФвВЪЧЪ§ОнЃЌЭјЩЯетУДЖрЭјвГвВЪЧЪ§ОнЃЌЮвУЧГЦЮЊ
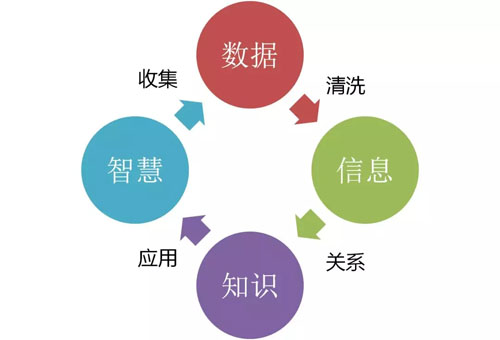
DataЁЁЁЃ
Ъ§ОнБОЩэУЛгаЪВУДгУДІЃЌЕЋЪ§ОнРяУцАќКЌвЛИіКмживЊЕФЖЋЮїЃЌНазіаХЯЂЃЈInformationЃЉЁЃ
Ъ§ОнЪЎЗждгТвЃЌОЙ§ЪсРэКЭЧхЯДЃЌВХФмЙЛГЦЮЊаХЯЂЁЃаХЯЂЛсАќКЌКмЖрЙцТЩЃЌЮвУЧашвЊДгаХЯЂжаНЋЙцТЩзмНсГіРДЃЌГЦЮЊжЊЪЖЃЈKnowledgeЃЉЃЌЖјжЊЪЖИФБфУќдЫЁЃ
аХЯЂЪЧКмЖрЕФЃЌЕЋгаШЫПДЕНСЫаХЯЂЯрЕБгкАзПДЃЌЕЋгаШЫОЭДгаХЯЂжаПДЕНСЫЕчЩЬЕФЮДРДЃЌгаШЫПДЕНСЫжБВЅЕФЮДРДЃЌЫљвдШЫМвОЭХЃСЫЁЃ
ШчЙћФуУЛгаДгаХЯЂжаЬсШЁГіжЊЪЖЃЌЬьЬьПДХѓгбШІвВжЛФмдкЛЅСЊЭјЙіЙіДѓГБжазіИіПДПЭЁЁЁЃ
гаСЫжЊЪЖЃЌШЛКѓРћгУетаЉжЊЪЖШЅгІгУгкЪЕеНЃЌгаЕФШЫЛсзіЕУЗЧГЃКУЃЌетИіЖЋЮїНазіжЧЛлЃЈIntelligenceЃЉЁЃ
гажЊЪЖВЂВЛвЛЖЈгажЧЛлЃЌР§ШчКУЖрбЇепКмгажЊЪЖЃЌвбОЗЂЩњЕФЪТЧщПЩвдДгИїИіНЧЖШЗжЮіЕУЭЗЭЗЪЧЕРЃЌЕЋвЛЕНЪЕИЩОЭаЊВЫЃЌВЂВЛФмзЊЛЏГЩЮЊжЧЛлЁЃ
ЖјКмЖрЕФДДвЕМвжЎЫљвдЮАДѓЃЌОЭЪЧЭЈЙ§ЛёЕУЕФжЊЪЖгІгУгкЪЕМљЃЌзюКѓзіСЫКмДѓЕФЩњвтЁЃ
ЫљвдЪ§ОнЕФгІгУЗжетЫФИіВНжшЃКЪ§ОнЁЂаХЯЂЁЂжЊЪЖЁЂжЧЛлЁЃ
зюжеЕФНзЖЮЪЧКмЖрЩЬМвЖМЯывЊЕФЁЃФуПДЮвЪеМЏСЫетУДЖрЕФЪ§ОнЃЌФмВЛФмЛљгкетаЉЪ§ОнРДАяЮвзіЯТвЛВНЕФОіВпЃЌИФЩЦЮвЕФВњЦЗЁЃ
Р§ШчШУгУЛЇПДЪгЦЕЕФЪБКђХдБпЕЏГіЙуИцЃЌе§КУЪЧЫћЯыТђЕФЖЋЮїЃЛдйШчШУгУЛЇЬ§вєРжЪБЃЌСэЭтЭЦМівЛаЉЫћЗЧГЃЯыЬ§ЕФЦфЫћвєРжЁЃ
гУЛЇдкЮвЕФгІгУЛђепЭјеОЩЯЫцБуЕуЕуЪѓБъЃЌЪфШыЮФзжЖдЮвРДЫЕЖМЪЧЪ§ОнЃЌЮвОЭЪЧвЊНЋЦфжаФГаЉЖЋЮїЬсШЁГіРДЁЂжИЕМЪЕМљЁЂаЮГЩжЧЛлЃЌШУгУЛЇЯнШыЕНЮвЕФгІгУРяУцВЛПЩздАЮЃЌЩЯСЫЮвЕФЭјОЭВЛЯыРыПЊЃЌЪжВЛЭЃЕиЕуЁЂВЛЭЃЕиТђЁЃ
КмЖрШЫЫЕЫЋЪЎвЛЮвЖМЯыЖЯЭјСЫЃЌЮвРЯЦХдкЩЯУцВЛЖЯЕиТђТђТђЃЌТђСЫ A гжЭЦМі BЃЌРЯЦХДѓШЫЫЕЃЌЁААЅбНЃЌB
вВЪЧЮвЯВЛЖЕФАЁЃЌРЯЙЋЮввЊТђЁБЁЃ
ФуЫЕетИіГЬађдѕУДетУДХЃЃЌетУДгажЧЛлЃЌБШЮвЛЙСЫНтЮвРЯЦХЃЌетМўЪТЧщЪЧдѕУДзіЕНЕФФиЃП
Ъ§ОнШчКЮЩ§ЛЊЮЊжЧЛл
Ъ§ОнЕФДІРэЗжвдЯТМИИіВНжшЃЌЭъГЩСЫВХзюКѓЛсгажЧЛл:
Ъ§ОнЪеМЏ
Ъ§ОнДЋЪф
Ъ§ОнДцДЂ
Ъ§ОнДІРэКЭЗжЮі
Ъ§ОнМьЫїКЭЭкОђ
Ъ§ОнЪеМЏ
ЪзЯШЕУгаЪ§ОнЃЌЪ§ОнЕФЪеМЏгаСНИіЗНЪН:
ФУЃЌзЈвЕЕуЕФЫЕЗЈНазЅШЁЛђепХРШЁЁЃР§ШчЫбЫїв§ЧцОЭЪЧетУДзіЕФЃКЫќАбЭјЩЯЕФЫљгаЕФаХЯЂЖМЯТдиЕНЫќЕФЪ§ОнжааФЃЌШЛКѓФувЛЫбВХФмЫбГіРДЁЃ
БШШчФуШЅЫбЫїЕФЪБКђЃЌНсЙћЛсЪЧвЛИіСаБэЃЌетИіСаБэЮЊЪВУДЛсдкЫбЫїв§ЧцЕФЙЋЫОРяУцЃПОЭЪЧвђЮЊЫћАбЪ§ОнЖМФУЯТРДСЫЃЌЕЋЪЧФувЛЕуСДНгЃЌЕуГіРДетИіЭјеООЭВЛдкЫбЫїв§ЧцЫќУЧЙЋЫОСЫЁЃ
БШШчЫЕаТРЫгаИіаТЮХЃЌФуФУАйЖШЫбГіРДЃЌФуВЛЕуЕФЪБКђЃЌФЧвЛвГдкАйЖШЪ§ОнжааФЃЌвЛЕуГіРДЕФЭјвГОЭЪЧдкаТРЫЕФЪ§ОнжааФСЫЁЃ
ЭЦЫЭЃЌгаКмЖржеЖЫПЩвдАяЮвЪеМЏЪ§ОнЁЃБШШчЫЕаЁУзЪжЛЗЃЌПЩвдНЋФуУПЬьХмВНЕФЪ§ОнЃЌаФЬјЕФЪ§ОнЃЌЫЏУпЕФЪ§ОнЖМЩЯДЋЕНЪ§ОнжааФРяУцЁЃ
Ъ§ОнДЋЪф
вЛАуЛсЭЈЙ§ЖгСаЗНЪННјааЃЌвђЮЊЪ§ОнСПЪЕдкЪЧЬЋДѓСЫЃЌЪ§ОнБиаыОЙ§ДІРэВХЛсгагУЁЃПЩЯЕЭГДІРэВЛЙ§РДЃЌжЛКУХХКУЖгЃЌТ§Т§ДІРэЁЃ
Ъ§ОнДцДЂ
ЯждкЪ§ОнОЭЪЧН№ЧЎЃЌеЦЮеСЫЪ§ОнОЭЯрЕБгкеЦЮеСЫЧЎЁЃвЊВЛШЛЭјеОдѕУДжЊЕРФуЯыТђЪВУДЃП
ОЭЪЧвђЮЊЫќгаФуРњЪЗЕФНЛвзЪ§ОнЃЌетИіаХЯЂПЩВЛФмИјБ№ШЫЃЌЪЎЗжБІЙѓЃЌЫљвдашвЊДцДЂЯТРДЁЃ
Ъ§ОнДІРэКЭЗжЮі
ЩЯУцДцДЂЕФЪ§ОнЪЧдЪМЪ§ОнЃЌдЪМЪ§ОнЖрЪЧдгТвЮоеТЕФЃЌгаКмЖрРЌЛјЪ§ОндкРяУцЃЌвђЖјашвЊЧхЯДКЭЙ§ТЫЃЌЕУЕНвЛаЉИпжЪСПЕФЪ§ОнЁЃ
ЖдгкИпжЪСПЕФЪ§ОнЃЌОЭПЩвдНјааЗжЮіЃЌДгЖјЖдЪ§ОнНјааЗжРрЃЌЛђепЗЂЯжЪ§ОнжЎМфЕФЯрЛЅЙиЯЕЃЌЕУЕНжЊЪЖЁЃ
БШШчЪЂДЋЕФЮжЖћТъГЌЪаЕФЦЁОЦКЭФђВМЕФЙЪЪТЃЌОЭЪЧЭЈЙ§ЖдШЫУЧЕФЙКТђЪ§ОнНјааЗжЮіЃЌЗЂЯжСЫФаШЫвЛАуТђФђВМЕФЪБКђЃЌЛсЭЌЪБЙКТђЦЁОЦЁЃ
етбљОЭЗЂЯжСЫЦЁОЦКЭФђВМжЎМфЕФЯрЛЅЙиЯЕЃЌЛёЕУжЊЪЖЃЌШЛКѓгІгУЕНЪЕМљжаЃЌНЋЦЁОЦКЭФђВМЕФЙёЬЈХЊЕФКмНќЃЌОЭЛёЕУСЫжЧЛлЁЃ
Ъ§ОнМьЫїКЭЭкОђ
МьЫїОЭЪЧЫбЫїЃЌЫљЮНЭтЪТВЛОіЮЪ GoogleЃЌФкЪТВЛОіЮЪАйЖШЁЃФкЭтСНДѓЫбЫїв§ЧцЖМЪЧНЋЗжЮіКѓЕФЪ§ОнЗХШыЫбЫїв§ЧцЃЌвђДЫШЫУЧЯыбАеваХЯЂЕФЪБКђЃЌвЛЫбОЭгаСЫЁЃ
СэЭтОЭЪЧЭкОђЃЌНіНіЫбЫїГіРДвбОВЛФмТњзуШЫУЧЕФвЊЧѓСЫЃЌЛЙашвЊДгаХЯЂжаЭкОђГіЯрЛЅЕФЙиЯЕЁЃ
БШШчВЦОЫбЫїЃЌЕБЫбЫїФГИіЙЋЫОЙЩЦБЕФЪБКђЃЌИУЙЋЫОЕФИпЙмЪЧВЛЪЧвВгІИУБЛЭкОђГіРДФиЃП
ШчЙћНіНіЫбЫїГіетИіЙЋЫОЕФЙЩЦБЗЂЯжеЧЕФЬиБ№КУЃЌгкЪЧФуОЭШЅТђСЫЃЌЦфЪБЦфИпЙмЗЂСЫвЛИіЩљУїЃЌЖдЙЩЦБЪЎЗжВЛРћЃЌЕкЖўЬьОЭЕјСЫЃЌетВЛПгКІЙуДѓЙЩУёУДЃПЫљвдЭЈЙ§ИїжжЫуЗЈЭкОђЪ§ОнжаЕФЙиЯЕЃЌаЮГЩжЊЪЖПтЃЌЪЎЗжживЊЁЃ
ДѓЪ§ОнЪБДњЃЌжкШЫЪАВёЛ№бцИп
ЕБЪ§ОнСПКмаЁЪБЃЌКмЩйЕФМИЬЈЛњЦїОЭФмНтОіЁЃТ§Т§ЕФЃЌЕБЪ§ОнСПдНРДдНДѓЃЌзюХЃЕФЗўЮёЦїЖМНтОіВЛСЫЮЪЬтЪБЃЌдѕУДАьФиЃП
етЪБОЭвЊОлКЯЖрЬЈЛњЦїЕФСІСПЃЌДѓМвЦыаФаСІвЛЦ№АбетИіЪТИуЖЈЃЌжкШЫЪАВёЛ№бцИпЁЃ
ЖдгкЪ§ОнЕФЪеМЏЃКОЭ IoT РДНВЃЌЭтУцВПЪ№зХГЩЧЇЩЯЭђЕФМьВтЩшБИЃЌНЋДѓСПЕФЮТЖШЁЂЪЊЖШЁЂМрПиЁЂЕчСІЕШЪ§ОнЭГЭГЪеМЏЩЯРДЃЛОЭЛЅСЊЭјЭјвГЕФЫбЫїв§ЧцРДНВЃЌашвЊНЋећИіЛЅСЊЭјЫљгаЕФЭјвГЖМЯТдиЯТРДЁЃ
етЯдШЛвЛЬЈЛњЦїзіВЛЕНЃЌашвЊЖрЬЈЛњЦїзщГЩЭјТчХРГцЯЕЭГЃЌУПЬЈЛњЦїЯТдивЛВПЗжЃЌЭЌЪБЙЄзїЃЌВХФмдкгаЯоЕФЪБМфФкЃЌНЋКЃСПЕФЭјвГЯТдиЭъБЯЁЃ
ЖдгкЪ§ОнЕФДЋЪфЃКвЛИіФкДцРяУцЕФЖгСаПЯЖЈЛсБЛДѓСПЕФЪ§ОнМЗБЌЕєЃЌгкЪЧОЭВњЩњСЫЛљгкгВХЬЕФЗжВМЪНЖгСаЃЌетбљЖгСаПЩвдЖрЬЈЛњЦїЭЌЪБДЋЪфЃЌЫцФуЪ§ОнСПЖрДѓЃЌжЛвЊЮвЕФЖгСазуЙЛЖрЃЌЙмЕРзуЙЛДжЃЌОЭФмЙЛГХЕУзЁЁЃ
ЖдгкЪ§ОнЕФДцДЂЃКвЛЬЈЛњЦїЕФЮФМўЯЕЭГПЯЖЈЪЧЗХВЛЯТЕФЃЌЫљвдашвЊвЛИіКмДѓЕФЗжВМЪНЮФМўЯЕЭГРДзіетМўЪТЧщЃЌАбЖрЬЈЛњЦїЕФгВХЬДђГЩвЛПщДѓЕФЮФМўЯЕЭГЁЃ
ЖдгкЪ§ОнЕФЗжЮіЃКПЩФмашвЊЖдДѓСПЕФЪ§ОнзіЗжНтЁЂЭГМЦЁЂЛузмЃЌвЛЬЈЛњЦїПЯЖЈИуВЛЖЈЃЌДІРэЕНКяФъТэдТвВЗжЮіВЛЭъЁЃ
гкЪЧОЭгаЗжВМЪНМЦЫуЕФЗНЗЈЃЌНЋДѓСПЕФЪ§ОнЗжГЩаЁЗнЃЌУПЬЈЛњЦїДІРэвЛаЁЗнЃЌЖрЬЈЛњЦїВЂааДІРэЃЌКмПьОЭФмЫуЭъЁЃ
Р§ШчжјУћЕФ Terasort Жд 1 Иі TB ЕФЪ§ОнХХађЃЌЯрЕБгк 1000GЃЌШчЙћЕЅЛњДІРэЃЌдѕУДвВвЊМИИіаЁЪБЃЌЕЋВЂааДІРэ
209 УыОЭЭъГЩСЫЁЃ
ЫљвдЫЕЪВУДНазіДѓЪ§ОнЃПЫЕАзСЫОЭЪЧвЛЬЈЛњЦїИЩВЛЭъЃЌДѓМввЛЦ№ИЩЁЃ
ПЩЪЧЫцзХЪ§ОнСПдНРДдНДѓЃЌКмЖрВЛДѓЕФЙЋЫОЖМашвЊДІРэЯрЕБЖрЕФЪ§ОнЃЌетаЉаЁЙЋЫОУЛгаетУДЖрЛњЦїПЩдѕУДАьФиЃП
ДѓЪ§ОнашвЊдЦМЦЫуЃЌдЦМЦЫуашвЊДѓЪ§Он
ЫЕЕНетРяЃЌДѓМвЯыЦ№дЦМЦЫуСЫАЩЁЃЕБЯывЊИЩетаЉЛюЪБЃЌашвЊКмЖрЕФЛњЦївЛПщзіЃЌецЕФЪЧЯыЪВУДЪБКђвЊОЭЪВУДЪБКђвЊЃЌЯывЊЖрЩйОЭвЊЖрЩйЁЃ
Р§ШчДѓЪ§ОнЗжЮіЙЋЫОЕФВЦЮёЧщПіЃЌПЩФмвЛжмЗжЮівЛДЮЃЌШчЙћвЊАбетвЛАйЬЈЛњЦїЛђепвЛЧЇЬЈЛњЦїЖМдкФЧЗХзХЃЌвЛжмгУвЛДЮЗЧГЃРЫЗбЁЃ
ФЧФмВЛФмашвЊМЦЫуЕФЪБКђЃЌАбетвЛЧЇЬЈЛњЦїФУГіРДЃЛВЛЫуЕФЪБКђЃЌШУетвЛЧЇЬЈЛњЦїШЅИЩБ№ЕФЪТЧщЃП
ЫФмзіетИіЪТЖљФиЃПжЛгадЦМЦЫуЃЌПЩвдЮЊДѓЪ§ОнЕФдЫЫуЬсЙЉзЪдДВуЕФСщЛюадЁЃ
ЖјдЦМЦЫувВЛсВПЪ№ДѓЪ§ОнЗХЕНЫќЕФ PaaS ЦНЬЈЩЯЃЌзїЮЊвЛИіЗЧГЃЗЧГЃживЊЕФЭЈгУгІгУЁЃ
вђЮЊДѓЪ§ОнЦНЬЈФмЙЛЪЙЕУЖрЬЈЛњЦївЛЦ№ИЩвЛИіЪТЖљЃЌетИіЖЋЮїВЛЪЧвЛАуШЫФмПЊЗЂГіРДЕФЃЌвВВЛЪЧвЛАуШЫЭцЕУзЊЕФЃЌдѕУДвВЕУЙЭИіМИЪЎЩЯАйКХШЫВХФмАбетИіЭцЦ№РДЁЃ
ЫљвдЫЕОЭЯёЪ§ОнПтвЛбљЃЌЛЙЪЧашвЊгавЛАязЈвЕЕФШЫРДЭцетИіЖЋЮїЁЃЯждкЙЋгадЦЩЯЛљБОЩЯЖМЛсгаДѓЪ§ОнЕФНтОіЗНАИСЫЁЃ
вЛИіаЁЙЋЫОашвЊДѓЪ§ОнЦНЬЈЕФЪБКђЃЌВЛашвЊВЩЙКвЛЧЇЬЈЛњЦїЃЌжЛвЊЕНЙЋгадЦЩЯвЛЕуЃЌетвЛЧЇЬЈЛњЦїЖМГіРДСЫЃЌВЂЧвЩЯУцвбОВПЪ№КУСЫЕФДѓЪ§ОнЦНЬЈЃЌжЛвЊАбЪ§ОнЗХНјШЅЫуОЭПЩвдСЫЁЃ
дЦМЦЫуашвЊДѓЪ§ОнЃЌДѓЪ§ОнашвЊдЦМЦЫуЃЌЖўепОЭетбљНсКЯСЫЁЃ
ШЫЙЄжЧФмгЕБЇДѓЪ§Он
ЛњЦїЪВУДЪБКђВХФмЖЎШЫаФ
ЫфЫЕгаСЫДѓЪ§ОнЃЌШЫЕФгћЭћШДВЛФмЙЛТњзуЁЃЫфЫЕдкДѓЪ§ОнЦНЬЈРяУцгаЫбЫїв§ЧцетИіЖЋЮїЃЌЯывЊЪВУДЖЋЮївЛЫбОЭГіРДСЫЁЃ
ЕЋвВДцдкетбљЕФЧщПіЃКЮвЯывЊЕФЖЋЮїВЛЛсЫбЃЌБэДяВЛГіРДЃЌЫбЫїГіРДЕФгжВЛЪЧЮвЯывЊЕФЁЃ
Р§ШчвєРжШэМўЭЦМіСЫвЛЪзИшЃЌетЪзИшЮвУЛЬ§Й§ЃЌЕБШЛВЛжЊЕРУћзжЃЌвВУЛЗЈЫбЁЃЕЋЪЧШэМўЭЦМіИјЮвЃЌЮвЕФШЗЯВЛЖЃЌетОЭЪЧЫбЫїзіВЛЕНЕФЪТЧщЁЃ
ЕБШЫУЧЪЙгУетжжгІгУЪБЃЌЛсЗЂЯжЛњЦїжЊЕРЮвЯывЊЪВУДЃЌЖјВЛЪЧЫЕЕБЮвЯывЊЪБЃЌШЅЛњЦїРяУцЫбЫїЁЃетИіЛњЦїецЯёЮвЕФХѓгбвЛбљЖЎЮвЃЌетОЭгаЕуШЫЙЄжЧФмЕФвтЫМСЫЁЃ
ШЫУЧКмдчОЭдкЯыетИіЪТЧщСЫЁЃзюдчЕФЪБКђЃЌШЫУЧЯыЯѓЃЌвЊЪЧгавЛЖТЧНЃЌЧНКѓУцЪЧИіЛњЦїЃЌЮвИјЫќЫЕЛАЃЌЫќОЭИјЮвЛигІЁЃ
ШчЙћЮвИаОѕВЛГіЫќФЧБпЪЧШЫЛЙЪЧЛњЦїЃЌФЧЫќОЭецЕФЪЧвЛИіШЫЙЄжЧФмЕФЖЋЮїСЫЁЃ
ШУЛњЦїбЇЛсЭЦРэ
дѕУДВХФмзіЕНетвЛЕуФиЃПШЫУЧОЭЯыЃКЮвЪзЯШвЊИцЫпМЦЫуЛњШЫРрЭЦРэЕФФмСІЁЃФуПДШЫживЊЕФЪЧЪВУДЃПШЫКЭЖЏЮяЕФЧјБ№дкЪВУДЃПОЭЪЧФмЭЦРэЁЃ
вЊЪЧАбЮветИіЭЦРэЕФФмСІИцЫпЛњЦїЃЌШУЛњЦїИљОнФуЕФЬсЮЪЃЌЭЦРэГіЯргІЕФЛиД№ЃЌетбљЖрКУЃП
ЦфЪЕФПЧАШЫУЧТ§Т§ЕиШУЛњЦїФмЙЛзіЕНвЛаЉЭЦРэСЫЃЌР§ШчжЄУїЪ§бЇЙЋЪНЁЃетЪЧвЛИіЗЧГЃШУШЫОЊЯВЕФвЛИіЙ§ГЬЃЌЛњЦїОЙШЛФмЙЛжЄУїЪ§бЇЙЋЪНЁЃ
ЕЋТ§Т§гжЗЂЯжетИіНсЙћвВУЛгаФЧУДСюШЫОЊЯВЁЃвђЮЊДѓМвЗЂЯжСЫвЛИіЮЪЬтЃКЪ§бЇЙЋЪНЗЧГЃбЯНїЃЌЭЦРэЙ§ГЬвВЗЧГЃбЯНїЃЌЖјЧвЪ§бЇЙЋЪНКмШнвзФУЛњЦїРДНјааБэДяЃЌГЬађвВЯрЖдШнвзБэДяЁЃ
ШЛЖјШЫРрЕФгябдОЭУЛетУДМђЕЅСЫЁЃБШШчНёЬьЭэЩЯЃЌФуКЭФуХЎХѓгбдМЛсЃЌФуХЎХѓгбЫЕЃКШчЙћФудчРДЃЌЮвУЛРДЃЌФуЕШзХЃЛШчЙћЮвдчРДЃЌФуУЛРДЃЌФуЕШзХЃЁ
етИіЛњЦїОЭБШНЯФбРэНтСЫЃЌЕЋШЫЖМЖЎЁЃЫљвдФуКЭХЎХѓгбдМЛсЃЌЪЧВЛИвГйЕНЕФЁЃ
НЬИјЛњЦїжЊЪЖ
вђДЫЃЌНіНіИцЫпЛњЦїбЯИёЕФЭЦРэЪЧВЛЙЛЕФЃЌЛЙвЊИцЫпЛњЦївЛаЉжЊЪЖЁЃЕЋИцЫпЛњЦїжЊЪЖетИіЪТЧщЃЌвЛАуШЫПЩФмОЭзіВЛРДСЫЁЃПЩФмзЈМвПЩвдЃЌБШШчгябдСьгђЕФзЈМвЛђепВЦОСьгђЕФзЈМвЁЃ
гябдСьгђКЭВЦОСьгђжЊЪЖФмВЛФмБэЪОГЩЯёЪ§бЇЙЋЪНвЛбљЩдЮЂбЯИёЕуФиЃПР§ШчгябдзЈМвПЩФмЛсзмНсГіжїЮНБіЖЈзДВЙетаЉгяЗЈЙцдђЃЌжїгяКѓУцвЛЖЈЪЧЮНгяЃЌЮНгяКѓУцвЛЖЈЪЧБігяЃЌНЋетаЉзмНсГіРДЃЌВЂбЯИёБэДяГіРДВЛОЭааСЫТ№ЃП
КѓРДЗЂЯжетИіВЛааЃЌЬЋФбзмНсСЫЃЌгябдБэДяЧЇБфЭђЛЏЁЃОЭФУжїЮНБіЕФР§згЃЌКмЖрЪБКђдкПкгяРяУцОЭЪЁТдСЫЮНгяЃЌБ№ШЫЮЪЃКФуЫАЁЃПЮвЛиД№ЃКЮвСѕГЌЁЃ
ЕЋФуВЛФмЙцЖЈдкгявєгявхЪЖБ№ЪБЃЌвЊЧѓЖдзХЛњЦїЫЕБъзМЕФЪщУцгяЃЌетбљЛЙЪЧВЛЙЛжЧФмЃЌОЭЯёТогРКЦдквЛДЮбнНВжаЫЕЕФФЧбљЃЌУПДЮЖдзХЪжЛњЃЌгУЪщУцгяЫЕЃКЧыАяЮвКєНаФГФГФГЃЌетЪЧвЛМўКмоЯоЮЕФЪТЧщЁЃ
ШЫЙЄжЧФметИіНзЖЮНазізЈМвЯЕЭГЁЃзЈМвЯЕЭГВЛвзГЩЙІЃЌвЛЗНУцЪЧжЊЪЖБШНЯФбзмНсЃЌСэвЛЗНУцзмНсГіРДЕФжЊЪЖФбвдНЬИјМЦЫуЛњЁЃ
вђЮЊФуздМКЛЙУдУдК§К§ЃЌОѕЕУЫЦКѕгаЙцТЩЃЌОЭЪЧЫЕВЛГіРДЃЌгждѕУДФмЙЛЭЈЙ§БрГЬНЬИјМЦЫуЛњФиЃП
ЫуСЫЃЌНЬВЛЛсФуздМКбЇАЩ
гкЪЧШЫУЧЯыЕНЃКЛњЦїЪЧКЭШЫЭъШЋВЛвЛбљЕФЮяжжЃЌИЩДрШУЛњЦїздМКбЇЯАКУСЫЁЃ
ЛњЦїдѕУДбЇЯАФиЃПМШШЛЛњЦїЕФЭГМЦФмСІетУДЧПЃЌЛљгкЭГМЦбЇЯАЃЌвЛЖЈФмДгДѓСПЕФЪ§зжжаЗЂЯжвЛЖЈЕФЙцТЩЁЃ
ЦфЪЕдкгщРжШІгаКмКУЕФвЛИіР§згЃЌПЩПњвЛАпЃК
гавЛЮЛЭјгбЭГМЦСЫжЊУћИшЪждкДѓТНЗЂааЕФ 9 еХзЈМжа 117 ЪзИшЧњЕФИшДЪЃЌЭЌвЛДЪгядквЛЪзИшГіЯжжЛЫувЛДЮЃЌаЮШнДЪЁЂУћДЪКЭЖЏДЪЕФЧАЪЎУћШчЯТБэЫљЪОЃЈДЪгяКѓУцЕФЪ§зжЪЧГіЯжЕФДЮЪ§ЃЉЃК
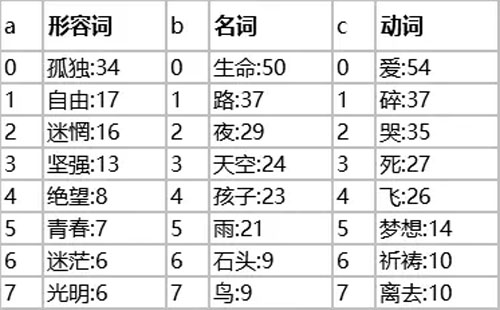
ШчЙћЮвУЧЫцБуаДвЛДЎЪ§зжЃЌШЛКѓАДееЪ§ЮЛвРДЮдкаЮШнДЪЁЂУћДЪКЭЖЏДЪжаШЁГівЛИіДЪЃЌСЌдквЛЦ№ЛсдѕУДбљФиЃП
Р§ШчШЁдВжмТЪ 3.1415926ЃЌЖдгІЕФДЪгяЪЧЃКМсЧПЃЌТЗЃЌЗЩЃЌздгЩЃЌгъЃЌТёЃЌУдуЏЁЃ
ЩдЮЂСЌНгКЭШѓЩЋвЛЯТЃК
МсЧПЕФКЂзг
вРШЛЧАаадкТЗЩЯ
еХПЊГсАђЗЩЯђздгЩ
ШУгъЫЎТёдсЫћЕФУдуЏ
ЪЧВЛЪЧгаЕуИаОѕСЫЃПЕБШЛЃЌеце§ЛљгкЭГМЦЕФбЇЯАЫуЗЈБШетИіМђЕЅЕФЭГМЦИДдгЕУЖрЁЃ
ШЛЖјЭГМЦбЇЯАБШНЯШнвзРэНтМђЕЅЕФЯрЙиадЃКР§ШчвЛИіДЪКЭСэвЛИіДЪзмЪЧвЛЦ№ГіЯжЃЌСНИіДЪгІИУгаЙиЯЕЃЛЖјЮоЗЈБэДяИДдгЕФЯрЙиадЁЃ
ВЂЧвЭГМЦЗНЗЈЕФЙЋЪНЭљЭљЗЧГЃИДдгЃЌЮЊСЫМђЛЏМЦЫуЃЌГЃГЃзіГіИїжжЖРСЂадЕФМйЩшЃЌРДНЕЕЭЙЋЪНЕФМЦЫуФбЖШЃЌШЛЖјЯжЪЕЩњЛюжаЃЌОпгаЖРСЂадЕФЪТМўЪЧЯрЖдНЯЩйЕФЁЃ
ФЃФтДѓФдЕФЙЄзїЗНЪН
гкЪЧШЫРрПЊЪМДгЛњЦїЕФЪРНчЃЌЗДЫМШЫРрЕФЪРНчЪЧдѕУДЙЄзїЕФЁЃ

ШЫРрЕФФдзгРяУцВЛЪЧДцДЂзХДѓСПЕФЙцдђЃЌвВВЛЪЧМЧТМзХДѓСПЕФЭГМЦЪ§ОнЃЌЖјЪЧЭЈЙ§ЩёОдЊЕФДЅЗЂЪЕЯжЕФЁЃ
УПИіЩёОдЊгаДгЦфЫћЩёОдЊЕФЪфШыЃЌЕБНгЪеЕНЪфШыЪБЃЌЛсВњЩњвЛИіЪфГіРДДЬМЄЦфЫћЩёОдЊЁЃгкЪЧДѓСПЕФЩёОдЊЯрЛЅЗДгІЃЌзюжеаЮГЩИїжжЪфГіЕФНсЙћЁЃ
Р§ШчЕБШЫУЧПДЕНУРХЎЭЋПзЛсЗХДѓЃЌОјВЛЪЧДѓФдИљОнЩэВФБШР§НјааЙцдђХаЖЯЃЌвВВЛЪЧНЋШЫЩњжаПДЙ§ЕФЫљгаЕФУРХЎЖМЭГМЦвЛБщЃЌЖјЪЧЩёОдЊДгЪгЭјФЄДЅЗЂЕНДѓФддйЛиЕНЭЋПзЁЃ
дкетИіЙ§ГЬжаЃЌЦфЪЕКмФбзмНсГіУПИіЩёОдЊЖдзюжеЕФНсЙћЦ№ЕНСЫФФаЉзїгУЃЌЗДе§ОЭЪЧЦ№зїгУСЫЁЃ
гкЪЧШЫУЧПЊЪМгУвЛИіЪ§бЇЕЅдЊФЃФтЩёОдЊЁЃ
етИіЩёОдЊгаЪфШыЃЌгаЪфГіЃЌЪфШыКЭЪфГіжЎМфЭЈЙ§вЛИіЙЋЪНРДБэЪОЃЌЪфШыИљОнживЊГЬЖШВЛЭЌ(ШЈжи)ЃЌгАЯьзХЪфГіЁЃ
гкЪЧНЋ n ИіЩёОдЊЭЈЙ§ЯёвЛеХЩёОЭјТчвЛбљСЌНгдквЛЦ№ЁЃn етИіЪ§зжПЩвдКмДѓКмДѓЃЌЫљгаЕФЩёОдЊПЩвдЗжГЩКмЖрСаЃЌУПвЛСаКмЖрИіХХСаЦ№РДЁЃ
УПИіЩёОдЊЖдгкЪфШыЕФШЈжиПЩвдЖМВЛЯрЭЌЃЌДгЖјУПИіЩёОдЊЕФЙЋЪНвВВЛЯрЭЌЁЃЕБШЫУЧДгетеХЭјТчжаЪфШывЛИіЖЋЮїЕФЪБКђЃЌЯЃЭћЪфГівЛИіЖдШЫРрРДНВе§ШЗЕФНсЙћЁЃ
Р§ШчЩЯУцЕФР§згЃЌЪфШывЛИіаДзХ 2 ЕФЭМЦЌЃЌЪфГіЕФСаБэРяУцЕкЖўИіЪ§зжзюДѓЃЌЦфЪЕДгЛњЦїРДНВЃЌЫќМШВЛжЊЕРЪфШыЕФетИіЭМЦЌаДЕФЪЧ
2ЃЌвВВЛжЊЕРЪфГіЕФетвЛЯЕСаЪ§зжЕФвтвхЃЌУЛЙиЯЕЃЌШЫжЊЕРвтвхОЭПЩвдСЫЁЃ
е§ШчЖдгкЩёОдЊРДЫЕЃЌЫћУЧМШВЛжЊЕРЪгЭјФЄПДЕНЕФЪЧУРХЎЃЌвВВЛжЊЕРЭЋПзЗХДѓЪЧЮЊСЫПДЕФЧхГўЃЌЗДе§ПДЕНУРХЎЃЌЭЋПзЗХДѓСЫЃЌОЭПЩвдСЫЁЃ
ЖдгкШЮКЮвЛеХЩёОЭјТчЃЌЫвВВЛИвБЃжЄЪфШыЪЧ 2ЃЌЪфГівЛЖЈЪЧЕкЖўИіЪ§зжзюДѓЃЌвЊБЃжЄетИіНсЙћЃЌашвЊбЕСЗКЭбЇЯАЁЃ
БЯОЙПДЕНУРХЎЖјЭЋПзЗХДѓвВЪЧШЫРрКмЖрФъНјЛЏЕФНсЙћЁЃбЇЯАЕФЙ§ГЬОЭЪЧЃЌЪфШыДѓСПЕФЭМЦЌЃЌШчЙћНсЙћВЛЪЧЯывЊЕФНсЙћЃЌдђНјааЕїећЁЃ
ШчКЮЕїећФиЃПОЭЪЧУПИіЩёОдЊЕФУПИіШЈжиЖМЯђФПБъНјааЮЂЕїЃЌгЩгкЩёОдЊКЭШЈжиЪЕдкЪЧЬЋЖрСЫЃЌЫљвдећеХЭјТчВњЩњЕФНсЙћКмФбБэЯжГіЗЧДЫМДБЫЕФНсЙћЃЌЖјЪЧЯђзХНсЙћЮЂЮЂЕиНјВНЃЌзюжеФмЙЛДяЕНФПБъНсЙћЁЃ
ЕБШЛЃЌетаЉЕїећЕФВпТдЛЙЪЧЗЧГЃгаММЧЩЕФЃЌашвЊЫуЗЈЕФИпЪжРДзаЯИЕФЕїећЁЃе§ШчШЫРрМћЕНУРХЎЃЌЭЋПзвЛПЊЪМУЛгаЗХДѓЕНФмПДЧхГўЃЌгкЪЧУРХЎИњБ№ШЫХмСЫЃЌЯТДЮбЇЯАЕФНсЙћЪЧЭЋПзЗХДѓвЛЕуЕуЃЌЖјВЛЪЧЗХДѓБЧПзЁЃ
УЛЕРРэЕЋзіЕУЕН
Ь§Ц№РДвВУЛгаФЧУДгаЕРРэЃЌЕЋЕФШЗФмзіЕНЃЌОЭЪЧетУДШЮадЃЁ
ЩёОЭјТчЕФЦеБщадЖЈРэЪЧетбљЫЕЕФЃЌМйЩшФГИіШЫИјФуФГжжИДдгЦцЬиЕФКЏЪ§ЃЌf(x)ЃК

ВЛЙметИіКЏЪ§ЪЧЪВУДбљЕФЃЌзмЛсШЗБЃгаИіЩёОЭјТчФмЙЛЖдШЮКЮПЩФмЕФЪфШы xЃЌЦфжЕ f(x)ЃЈЛђепФГИіФмЙЛзМШЗЕФНќЫЦЃЉЪЧЩёОЭјТчЕФЪфГіЁЃ
ШчЙћдкКЏЪ§ДњБэзХЙцТЩЃЌвВвтЮЖзХетИіЙцТЩЮоТлЖрУДЦцУюЃЌЖрУДВЛФмРэНтЃЌЖМЪЧФмЭЈЙ§ДѓСПЕФЩёОдЊЃЌЭЈЙ§ДѓСПШЈжиЕФЕїећЃЌБэЪОГіРДЕФЁЃ
ШЫЙЄжЧФмЕФОМУбЇНтЪЭ
етШУЮвЯыЕНСЫОМУбЇЃЌгкЪЧБШНЯШнвзРэНтСЫЁЃ

ЮвУЧАбУПИіЩёОдЊЕБГЩЩчЛсжаДгЪТОМУЛюЖЏЕФИіЬхЁЃгкЪЧЩёОЭјТчЯрЕБгкећИіОМУЩчЛсЃЌУПИіЩёОдЊЖдгкЩчЛсЕФЪфШыЃЌЖМгаШЈжиЕФЕїећЃЌзіГіЯргІЕФЪфГіЁЃ
БШШчЙЄзЪеЧСЫЁЂВЫМлеЧСЫЁЂЙЩЦБЕјСЫЃЌЮвгІИУдѕУДАьЁЂдѕУДЛЈздМКЕФЧЎЁЃетРяУцУЛгаЙцТЩУДЃППЯЖЈгаЃЌЕЋЪЧОпЬхЪВУДЙцТЩФиЃПКмФбЫЕЧхГўЁЃ
ЛљгкзЈМвЯЕЭГЕФОМУЪєгкМЦЛЎОМУЁЃећИіОМУЙцТЩЕФБэЪОВЛЯЃЭћЭЈЙ§УПИіОМУИіЬхЕФЖРСЂОіВпБэЯжГіРДЃЌЖјЪЧЯЃЭћЭЈЙ§зЈМвЕФИпЮнНЈъВКЭдЖМћзПЪЖзмНсГіРДЁЃЕЋзЈМвгРдЖВЛПЩФмжЊЕРФФИіГЧЪаЕФФФИіНжЕРШБЩйвЛИіТєЬ№ЖЙИЏФдЕФЁЃ
гкЪЧзЈМвЫЕгІИУВњЖрЩйИжЬњЁЂВњЖрЩйТјЭЗЃЌЭљЭљОрРыШЫУёЩњЛюЕФеце§ашЧѓгаНЯДѓЕФВюОрЃЌОЭЫуећИіМЦЛЎЪщаДИіМИАйвГЃЌвВЮоЗЈБэДявўВидкШЫУёЩњЛюжаЕФаЁЙцТЩЁЃ
ЛљгкЭГМЦЕФКъЙлЕїПиОЭППЦзЖрСЫЃЌУПФъЭГМЦОжЖМЛсЭГМЦећИіЩчЛсЕФОЭвЕТЪЁЂЭЈеЭТЪЁЂGDP ЕШжИБъЁЃетаЉжИБъЭљЭљДњБэзХКмЖрФкдкЙцТЩЃЌЫфШЛВЛФмОЋШЗБэДяЃЌЕЋЪЧЯрЖдППЦзЁЃ
ШЛЖјЛљгкЭГМЦЕФЙцТЩзмНсБэДяЯрЖдБШНЯДжВкЁЃБШШчОМУбЇМвПДЕНетаЉЭГМЦЪ§ОнЃЌПЩвдзмНсГіГЄЦкРДПДЗПМлЪЧеЧЛЙЪЧЕјЁЂЙЩЦБГЄЦкРДПДЪЧеЧЛЙЪЧЕјЁЃ
ШчЙћОМУзмЬхЩЯбяЃЌЗПМлКЭЙЩЦБгІИУЖМЪЧеЧЕФЁЃЕЋЛљгкЭГМЦЪ§ОнЃЌЮоЗЈзмНсГіЙЩЦБЃЌЮяМлЕФЮЂаЁВЈЖЏЙцТЩЁЃ
ЛљгкЩёОЭјТчЕФЮЂЙлОМУбЇВХЪЧЖдећИіОМУЙцТЩзюзюзМШЗЕФБэДяЃЌУПИіШЫЖдгкздМКдкЩчЛсжаЕФЪфШыНјааИїздЕФЕїећЃЌВЂЧвЕїећЭЌбљЛсзїЮЊЪфШыЗДРЁЕНЩчЛсжаЁЃ
ЯыЯѓвЛЯТЙЩЪаааЧщЯИЮЂЕФВЈЖЏЧњЯпЃЌе§ЪЧУПИіЖРСЂЕФИіЬхИїздВЛЖЯНЛвзЕФНсЙћЃЌУЛгаЭГвЛЕФЙцТЩПЩбЁЃ
ЖјУПИіШЫИљОнећИіЩчЛсЕФЪфШыНјааЖРСЂОіВпЃЌЕБФГаЉвђЫиОЙ§ЖрДЮбЕСЗЃЌвВЛсаЮГЩКъЙлЩЯЭГМЦадЕФЙцТЩЃЌетвВОЭЪЧКъЙлОМУбЇЫљФмПДЕНЕФЁЃ
Р§ШчУПДЮЛѕБвДѓСПЗЂааЃЌзюКѓЗПМлЖМЛсЩЯеЧЃЌЖрДЮбЕСЗКѓЃЌШЫУЧвВОЭЖМбЇЛсСЫЁЃ
ШЫЙЄжЧФмашвЊДѓЪ§Он
ШЛЖјЃЌЩёОЭјТчАќКЌетУДЖрЕФНкЕуЃЌУПИіНкЕугжАќКЌЗЧГЃЖрЕФВЮЪ§ЃЌећИіВЮЪ§СПЪЕдкЪЧЬЋДѓСЫЃЌашвЊЕФМЦЫуСПЪЕдкЬЋДѓЁЃ
ЕЋУЛгаЙиЯЕЃЌЮвУЧгаДѓЪ§ОнЦНЬЈЃЌПЩвдЛуОлЖрЬЈЛњЦїЕФСІСПвЛЦ№РДМЦЫуЃЌОЭФмдкгаЯоЕФЪБМфФкЕУЕНЯывЊЕФНсЙћЁЃ
ШЫЙЄжЧФмПЩвдзіЕФЪТЧщЗЧГЃЖрЃЌР§ШчПЩвдМјБ№РЌЛјгЪМўЁЂМјБ№ЛЦЩЋБЉСІЮФзжКЭЭМЦЌЕШЁЃ
етвВЪЧОРњСЫШ§ИіНзЖЮЕФЃК
вРРЕгкЙиМќДЪКкАзУћЕЅКЭЙ§ТЫММЪѕЃЌАќКЌФФаЉДЪОЭЪЧЛЦЩЋЛђепБЉСІЕФЮФзжЁЃЫцзХетИіЭјТчгябддНРДдНЖрЃЌДЪвВВЛЖЯЕиБфЛЏЃЌВЛЖЯЕиИќаТетИіДЪПтОЭгаЕуЙЫВЛЙ§РДЁЃ
ЛљгквЛаЉаТЕФЫуЗЈЃЌБШШчЫЕБДвЖЫЙЙ§ТЫЕШЃЌФуВЛгУЙмБДвЖЫЙЫуЗЈЪЧЪВУДЃЌЕЋЪЧетИіУћзжФугІИУЬ§Й§ЃЌетЪЧвЛИіЛљгкИХТЪЕФЫуЗЈЁЃ
ЛљгкДѓЪ§ОнКЭШЫЙЄжЧФмЃЌНјааИќМгОЋзМЕФгУЛЇЛЯёЁЂЮФБОРэНтКЭЭМЯёРэНтЁЃ
гЩгкШЫЙЄжЧФмЫуЗЈЖрЪЧвРРЕгкДѓСПЕФЪ§ОнЕФЃЌетаЉЪ§ОнЭљЭљашвЊУцЯђФГИіЬиЖЈЕФСьгђ(Р§ШчЕчЩЬЃЌгЪЯф)НјааГЄЦкЕФЛ§РлЁЃ
ШчЙћУЛгаЪ§ОнЃЌОЭЫугаШЫЙЄжЧФмЫуЗЈвВАзДюЃЌЫљвдШЫЙЄжЧФмГЬађКмЩйЯёЧАУцЕФ IaaS КЭ PaaS вЛбљЃЌНЋШЫЙЄжЧФмГЬађИјФГИіПЭЛЇАВзАвЛЬзЃЌШУПЭЛЇШЅгУЁЃ
вђЮЊИјФГИіПЭЛЇЕЅЖРАВзАвЛЬзЃЌПЭЛЇУЛгаЯрЙиЕФЪ§ОнзібЕСЗЃЌНсЙћЭљЭљЪЧКмВюЕФЁЃ
ЕЋдЦМЦЫуГЇЩЬЭљЭљЪЧЛ§РлСЫДѓСПЪ§ОнЕФЃЌгкЪЧОЭдкдЦМЦЫуГЇЩЬРяУцАВзАвЛЬзЃЌБЉТЖвЛИіЗўЮёНгПкЁЃ
БШШчФњЯыМјБ№вЛИіЮФБОЪЧВЛЪЧЩцМАЛЦЩЋКЭБЉСІЃЌжБНггУетИідкЯпЗўЮёОЭПЩвдСЫЁЃетжжаЮЪЦЕФЗўЮёЃЌдкдЦМЦЫуРяУцГЦЮЊШэМўМДЗўЮёЃЌSaaS
(Software AS A Service)
гкЪЧЙЄжЧФмГЬађзїЮЊ SaaS ЦНЬЈНјШыСЫдЦМЦЫуЁЃ
ЛљгкШ§епЙиЯЕЕФУРКУЩњЛю
жегкдЦМЦЫуЕФШ§ажЕмДеЦыСЫЃЌЗжБ№ЪЧ IaaSЁЂPaaS КЭ SaaSЁЃЫљвдвЛАудквЛИідЦМЦЫуЦНЬЈЩЯЃЌдЦЁЂДѓЪ§ОнЁЂШЫЙЄжЧФмЖМФмевЕУЕНЁЃ
вЛИіДѓЪ§ОнЙЋЫОЃЌЛ§РлСЫДѓСПЕФЪ§ОнЃЌЛсЪЙгУвЛаЉШЫЙЄжЧФмЕФЫуЗЈЬсЙЉвЛаЉЗўЮёЃЛвЛИіШЫЙЄжЧФмЙЋЫОЃЌвВВЛПЩФмУЛгаДѓЪ§ОнЦНЬЈжЇГХЁЃ
ЫљвдЃЌЕБдЦМЦЫуЁЂДѓЪ§ОнЁЂШЫЙЄжЧФметбљећКЯЦ№РДЃЌБуЭъГЩСЫЯргіЁЂЯрЪЖЁЂЯржЊЕФЙ§ГЬЁЃ
|








