| Īŗľ≠Õ∆ľŲ: |
| Īĺőńņī◊‘”ŕcsdn,÷ų“™Ĺ≤Ĺ‚ŃňŅÁ∂ŗ÷ųĽķ»›∆ųÕݬÁĽ∑ĺ≥ĶńīÓĹ®“‘ľį‘≠ņŪĶńĹ≤Ĺ‚Ķ»÷™ ∂£¨Ō£ÕŻń‹łÝīůľ“Ķń—ßŌįīÝņīįÔ÷ķ
°£ |
|
‘ŕDocker 1.9 ≥Ų ņ«į£¨ŅÁ∂ŗ÷ųĽķĶń»›∆ųÕ®–Ň∑Ĺįłīů÷¬”–»ÁŌ¬»ż÷÷£ļ
1°Ę∂ňŅŕ”≥…š
Ĺęňř÷ųĽķAĶń∂ňŅŕP”≥…šĶĹ»›∆ųCĶńÕݬÁŅ’ľšľŗŐżĶń∂ňŅŕP°Į…Ō£¨ĹŲŐŠĻ©ňń≤„ľį“‘…Ō”¶”√ļÕ∑ĢőŮ Ļ”√°£’‚—ý∆šňŻ÷ųĽķ…ŌĶń»›∆ųÕ®Ļż∑√ő ňř÷ųĽķAĶń∂ňŅŕP Ķ
Ō÷”Ž»›∆ųCĶńÕ®–Ň°£Ō‘»Ľ’‚łŲ∑ĹįłĶń”¶”√≥°ĺįļ‹”–ĺ÷Ōř°£
2°ĘĹęőÔņŪÕÝŅ®«ŇĹ”ĶĹ–ťń‚ÕÝ«Ň£¨ ĻĶ√»›∆ų”Žňř÷ųĽķŇš÷√‘ŕÕ¨“ĽÕÝ∂őŌ¬
‘ŕłųłŲňř÷ųĽķ…Ō∂ľĹ®ŃĘ“ĽłŲ–¬–ťń‚ÕÝ«Ň…ŤĪłbr0£¨Ĺęłų◊‘őÔņŪÕÝŅ®eth0«ŇĹ”br0…Ō£¨eth0ĶńIPĶō÷∑ł≥łÝbr0£ĽÕ¨ Ī–řłńDocker
daemonĶńDOCKER_OPTS£¨…Ť÷√-b=br0£®Őśīķdocker0£©£¨≤ĘŌř÷∆Container
IPĶō÷∑Ķń∑÷Ňš∑∂őßő™Õ¨őÔņŪ∂őĶō÷∑£®®Cfixed-cidr£©°£÷ō∆ŰłųłŲ÷ųĽķĶńDocker Daemonļů£¨ī¶”ŕ”Žňř÷ųĽķ‘ŕÕ¨“ĽÕÝ∂őĶńDocker»›∆ųĺÕŅ…“‘ ĶŌ÷ŅÁ÷ųĽķ∑√ő Ńň°£’‚łŲ∑ĹįłÕ¨—ýīś‘ŕĺ÷ŌřļÕņ©’Ļ–‘≤ÓĶńő Ő‚£ļĪ»»Á–ŤĹęőÔņŪÕÝ∂őĶńĶō÷∑Ľģ∑÷
≥…–°Ņť£¨∑÷≤ľĶĹłųłŲ÷ųĽķ…Ō£¨∑ņ÷ĻIP≥ŚÕĽ£Ľ◊”ÕÝĽģ∑÷“ņņĶőÔņŪĹĽĽĽĽķ…Ť÷√£ĽDocker»›∆ųĶń÷ųĽķĶō÷∑Ņ’ľšīů–°“ņņĶőÔņŪÕݬÁĽģ∑÷Ķ»°£
3°Ę Ļ”√Ķ໿∑ĹĶńĽý”ŕSDNĶń∑Ĺįł£ļĪ»»Á Ļ”√Open vSwitch ®C OVS ĽÚCoreOSĶńFlannel
Ķ»°£
Ļō”ŕ’‚–©Ķ໿∑Ĺ∑ĹįłĶńŌłĹŕīůľ“Ņ…“‘≤őŅľO°ĮReillyĶń°∂Docker Cookbook°∑ “Ľ ť°£
Docker‘ŕ1.9įśĪĺ÷–łÝīůľ“īÝņīŃň“Ľ÷÷‘≠…ķĶńŅÁ∂ŗ÷ųĽķ»›∆ųÕݬÁĶńĹ‚ĺŲ∑Ĺįł£¨ł√∑ĹįłĶń Ķ÷ «≤…”√ŃňĽý”ŕVXLAN
Ķńł≤ł«ÕÝľľ ű°£∑ĹįłĶń Ļ”√”–“Ľ–©«įŐŠŐűľĢ£ļ
1°ĘLinux KernelįśĪĺ >= 3.16£Ľ
2°Ę–Ť“™“ĽłŲÕ‚≤ŅKey-value Store£®ĻŔ∑Ĺņż◊”÷– Ļ”√Ķń «consul£©£Ľ
3°ĘłųőÔņŪ÷ųĽķ…ŌĶńDocker Daemon–Ť“™“Ľ–©Őō∂®Ķń∆Ű∂Į≤ő ż£Ľ
4°ĘőÔņŪ÷ųĽķ‘ –Ūń≥–©Őō∂®TCP/UDP∂ňŅŕŅ…”√°£
ĪĺőńĹęīÝ◊Ňīůľ““Ľ∆ūņŻ”√Docker 1.9.1īīĹ®“ĽłŲŅÁ∂ŗ÷ųĽķ»›∆ųÕݬÁ£¨≤Ę∑÷őŲĽý”ŕł√ÕݬÁĶń»›∆ųľšÕ®–Ň‘≠ņŪ°£
“Ľ°Ę Ķ—ťĽ∑ĺ≥Ĺ®ŃĘ
1°Ę…żľ∂Linux Kernel
”…”ŕ Ķ—ťĽ∑ĺ≥≤…”√Ķń «Ubuntu 14.04 server amd64£¨∆škernelįśĪĺ≤Ľń‹¬ķ◊„Ĺ®ŃĘŅÁ∂ŗ÷ųĽķ»›∆ųÕݬÁ“™«ů£¨“Úīň–Ť“™∂‘ńŕļňįśĪĺĹÝ––…żľ∂°£‘ŕUbuntuĶńńŕļň’ĺĶ„
Ō¬‘ō3.16.7 utopicńŕļň Ķń»żłŲőńľĢ£ļ
linux-headers-3.16.7-031607_3.16.7-031607.201410301735_all.deb
linux-image-3.16.7-031607-generic_3.16.7-031607.201410301735_amd64.deb
linux-headers-3.16.7-031607-generic_3.16.7-031607.201410301735_amd64.deb |
‘ŕĪĺĶō÷ī––Ō¬√ś√ŁŃÓį≤◊į£ļ
| sudo dpkg -i linux-headers-3.16.7-*.deb linux-image-3.16.7-*.deb |
–Ť“™◊Ę“‚Ķń «£ļkernel mainline…ŌĶń3.16.7ńŕļň√Ľ”–īÝlinux-image-extra£¨“≤ĺÕ√Ľ”–Ńňaufs
Ķń«ż∂Į£¨“ÚīňDocker DaemonĹę≤Ľ÷ß≥÷ń¨»ŌĶńīśīĘ«ż∂Į£ļ®Cstorage-driver=aufs£¨ő“√«–Ť“™Ĺęstorage
driverłŁĽĽő™devicemapper°£
ńŕļň…żľ∂ «“ĽłŲ”–∑ÁŌ’Ķń≤Ŕ◊ų£¨≤Ę«“ «∑Ůń‹…żľ∂≥…Ļ¶ĽĻ“™ŅīĶ„°į‘ň∆Ý°Ī£ļő“ĶńŃĹŐ®Ķ∂∆¨∑ĢőŮ∆ų£¨ĺÕ «“ĽŐ®…żľ∂≥…Ļ¶“ĽŐ®…żľ∂ ßį‹£®“Ľ÷ĪĪ®ÕÝŅ®ő Ő‚£©°£
2°Ę…żľ∂DockerĶĹ1.9.1įśĪĺ
ī”ĻķńŕŌ¬‘ōDockerĻŔ∑ĹĶńį≤◊įįŁĪ»ĹŌ¬ż£¨’‚ņÔņŻ”√daocloud.ioŐŠĻ©Ķń∑Ĺ∑® ŅžňŔį≤◊įDocker◊Ó–¬įśĪĺ£ļ
| $ curl -sSL https://get.daocloud.io/docker | sh |
3°ĘÕō∆ň
ĪĺīőĶńŅÁ∂ŗ÷ųĽķ»›∆ųÕݬÁĽý”ŕŃĹŐ®‘ŕ≤ĽÕ¨◊”ÕÝÕÝ∂őńŕĶńőÔņŪĽķ≥–‘ō£¨Ľý”ŕőÔņŪĽķīÓĹ®£¨ńŅĶń «ľÚĽĮļů–ÝÕݬÁÕ®–Ň‘≠ņŪ∑÷őŲ°£
Õō∆ňÕľ»ÁŌ¬£ļ
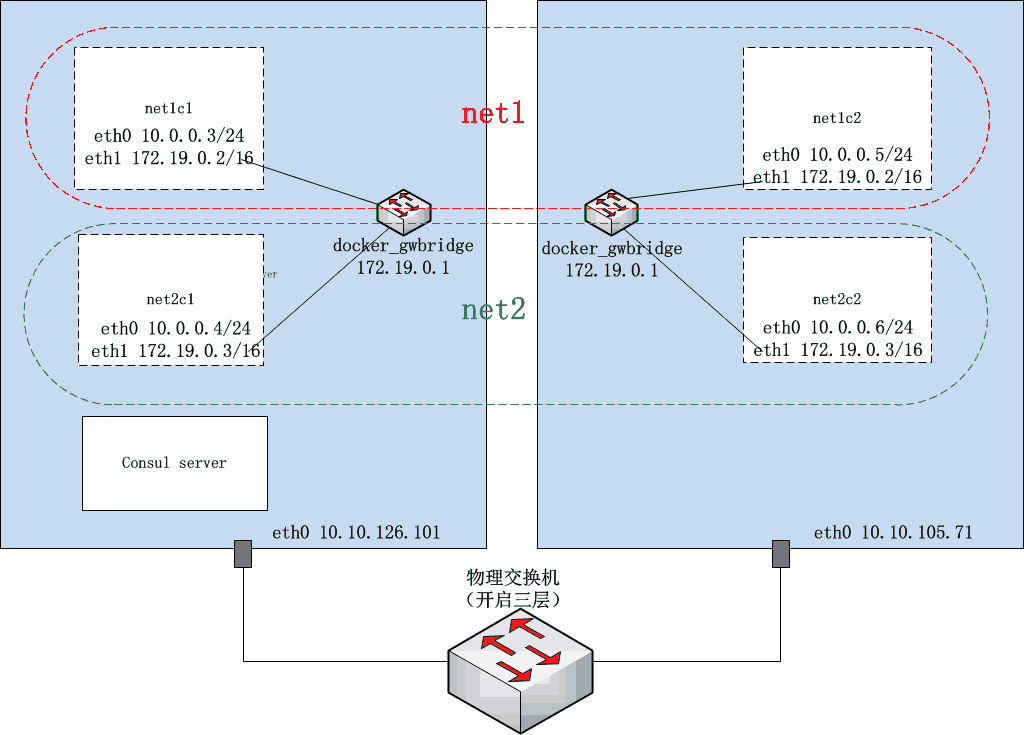
∂Ģ°ĘŅÁ∂ŗ÷ųĽķ»›∆ųÕݬÁīÓĹ®
1°ĘīīĹ®consul ∑ĢőŮ
Ņľ¬«ĶĹkv store‘ŕĪĺőń≤Ę∑«ĻōľŁ£¨ĹŲ◊ųŅÁ∂ŗ÷ųĽķ»›∆ųÕݬÁīīĹ®∆Ű∂ĮĶń«įŐŠŐűľĢ÷ģ”√£¨“ÚīňĹŲ”√įŁļ¨“ĽłŲserverĹŕĶ„Ķń°Īcluster°Ī°£
≤ő’’Õō∆ňÕľ£¨ő“√«‘ŕ10.10.126.101…Ō∆Ű∂Į“ĽłŲconsul£¨Ļō”ŕconsulľĮ»ļ“‘ľį∑ĢőŮ◊Ę≤Š°Ę∑ĢőŮ∑ĘŌ÷Ķ»ŌłĹŕŅ…“‘≤őŅľő“÷ģ«įĶń“Ľ
∆™őń’¬£ļ
| $./consul -d agent -server -bootstrap-expect 1 -data-dir ./data -node=master -bind=10.10.126.101 -client=0.0.0.0 & |
2°Ę–řłńDocker Daemon DOCKER_OPTS≤ő ż
«į√śŐŠĶĹĻż£¨Õ®ĻżDocker 1.9īīĹ®ŅÁ∂ŗ÷ųĽķ»›∆ųÕݬÁ–Ť“™÷ō–¬Ňš÷√√ŅłŲ÷ųĽķĹŕĶ„…ŌĶńDocker
DaemonĶń∆Ű∂Į≤ő ż£ļ
ubuntuŌĶÕ≥’‚łŲŇš÷√‘ŕ/etc/default/dockerŌ¬£ļ
DOCKER_OPTS="--dns 8.8.8.8 --dns 8.8.4.4 -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock --cluster-advertise eth0:2375 --cluster-store consul://10.10.126.101:8500/network --storage-driver=devicemapper" |
’‚ņÔ∂ŗňĶľłĺš£ļ
-H(ĽÚ®Chost)Ňš÷√Ķń «Docker client(įŁņ®ĪĺĶōļÕ‘∂≥ŐĶńclient)”ŽDocker
DaemonĶńÕ®–Ň√ĹĹť£¨“≤ «Docker REST apiĶń∑ĢőŮ∂ňŅŕ°£ń¨»Ō «/var/run/docker.sock£®ĹŲ”√”ŕĪĺĶō£©£¨ĶĪ»Ľ“≤Ņ…“‘Õ®Ļżtcp–≠“ťÕ®–Ň“‘∑ĹĪ„‘∂≥ŐClient∑√ő £¨ĺÕŌŮ…Ō√ś
Ňš÷√Ķńń«—ý°£∑«ľ”√‹ÕÝÕ®–Ň≤…”√2375∂ňŅŕ£¨∂ÝTLSľ”√‹Ń¨Ĺ”‘Ú”√2376∂ňŅŕ°£’‚ŃĹłŲ∂ňŅŕ“—ĺ≠…Í«Ž‘ŕIANA◊Ę≤Š≤ĘĽŮŇķ£¨Īš≥…Ńň÷™√Ż∂ňŅŕ°£-HŅ…“‘Ňš÷√∂ŗłŲ£¨ĺÕŌŮ…Ō√śŇš÷√Ķńń«—ý°£
unix socketĪ„”ŕĪĺĶōdocker client∑√ő ĪĺĶōdocker daemon£Ľtcp∂ňŅŕ‘Ú”√”ŕ‘∂≥Őclient∑√ő °£’‚—ý“Ľņī£ļdocker
pull ubuntu£¨◊Ŗdocker.sock£Ľ∂Ýdocker -H 10.10.126.101:2375
pull ubuntu‘Ú◊Ŗtcp socket°£
®Ccluster-advertise Ňš÷√Ķń «ĪĺDocker Daemon Ķņż‘ŕcluster÷–ĶńĶō÷∑£Ľ
®Ccluster-storeŇš÷√Ķń «ClusterĶń∑÷≤ľ ĹKV storeĶń∑√ő Ķō÷∑£Ľ
»ÁĻŻń„÷ģ«į ÷Ļ§–řłńĻżiptablesĶńĻś‘Ú£¨Ĺ®“ť÷ō∆ŰDocker Daemon÷ģ«į«ŚņŪ“ĽŌ¬iptablesĻś‘Ú£ļsudo
iptables -t nat -F, sudo iptables -t filter -FĶ»°£
3°Ę∆Ű∂ĮłųĹŕĶ„…ŌĶńDocker Daemon
“‘10.10.126.101ő™ņż£ļ
$ sudo service docker start
$ ps -ef|grep docker
root 2069 1 0 Feb02 ? 00:01:41 /usr/bin/docker -d --dns 8.8.8.8 --dns 8.8.4.4 --storage-driver=devicemapper -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock --cluster-advertise eth0:2375 --cluster-store consul://10.10.126.101:8500/network |
∆Ű∂ĮļůiptablesĶńnat, filterĻś‘Ú”ŽĶ•ĽķDockerÕݬÁ≥ű ľ«ťŅŲ≤Ęőř∂Ģ÷¬°£
101ĹŕĶ„…Ō≥ű ľÕݬÁdriverņŗ–Õ£ļ
$docker network ls
NETWORK ID NAME DRIVER
47e57d6fdfe8 bridge bridge
7c5715710e34 none null
19cc2d0d76f7 host host |
4°ĘīīĹ®overlayÕݬÁnet1ļÕnet2
‘ŕ101ĹŕĶ„…Ō£¨īīĹ®net1£ļ
| $ sudo docker network create -d overlay net1 |
‘ŕ71ĹŕĶ„…Ō£¨īīĹ®net2:
| $ sudo docker network create -d overlay net2 |
÷ģļůőř¬Ř‘ŕ71ĹŕĶ„ĽĻ «101ĹŕĶ„£¨ő“√«≤ťŅīĶĪ«įÕݬÁ“‘ľį«ż∂Įņŗ–Õ∂ľ «»ÁŌ¬ĹŠĻŻ£ļ
$ docker network ls
NETWORK ID NAME DRIVER
283b96845cbe net2 overlay
da3d1b5fcb8e net1 overlay
00733ecf5065 bridge bridge
71f3634bf562 none null
7ff8b1007c09 host host |
īň Ī£¨iptablesĻś‘Ú“≤≤ĘőřĪšĽĮ°£
5°Ę∆Ű∂ĮŃĹłŲoverlay netŌ¬Ķńcontainers
ő“√«∑÷Īū‘ŕnet1ļÕnet2Ō¬√ś∆Ű∂ĮŃĹłŲcontainer£¨√ŅłŲĹŕĶ„…Ōłų÷÷net1ļÕnet2Ķńcontainerłų“ĽłŲ£ļ
101:
sudo docker run -itd --name net1c1 --net net1 ubuntu:14.04
sudo docker run -itd --name net2c1 --net net2 ubuntu:14.04
71:
sudo docker run -itd --name net1c2 --net net1 ubuntu:14.04
sudo docker run -itd --name net2c2 --net net2 ubuntu:14.04 |
∆Ű∂Įļů£¨ő“√«ĺÕĶ√ĶĹ»ÁŌ¬ÕݬÁ–ŇŌĘ£®»›∆ųĶńipĶō÷∑Ņ…ń‹”Ž«į√śÕō∆ňÕľ÷–Ķń≤Ľ“Ľ÷¬£¨√Ņīő»›∆ų∆Ű∂ĮipĶō÷∑∂ľŅ…ń‹ĪšĽĮ£©£ļ
net1:
net1c1 - 10.0.0.7
net1c2 - 10.0.0.5
net2:
net2c1 - 10.0.0.4
net2c2 - 10.0.0.6 |
6°Ę»›∆ųŃ¨Õ®–‘
‘ŕnet1c1÷–£¨ő“√«ņīŅīŅī∆šĶĹnet1ļÕnet2ĶńŃ¨Õ®–‘£ļ
root@021f14bf3924:/#
ping net1c2
PING 10.0.0.5 (10.0.0.5) 56(84) bytes of data.
64 bytes from 10.0.0.5: icmp_seq=1 ttl=64 time=0.670
ms
64 bytes from 10.0.0.5: icmp_seq=2 ttl=64 time=0.387
ms
^C
--- 10.0.0.5 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss,
time 999ms
rtt min/avg/max/mdev = 0.387/0.528/0.670/0.143
ms
root@021f14bf3924:/# ping 10.0.0.4
PING 10.0.0.4 (10.0.0.4) 56(84) bytes of data.
^C
--- 10.0.0.4 ping statistics ---
2 packets transmitted, 0 received, 100% packet
loss, time 1008ms |
Ņ…ľŻ£¨net1÷–Ķń»›∆ų «Ľ•Õ®Ķń£¨Ķęnet1ļÕnet2’‚ŃĹłŲoverlay net÷ģľš «łŰņŽĶń°£
»ż°ĘŅÁ∂ŗ÷ųĽķ»›∆ųÕݬÁÕ®–Ň‘≠ņŪ
‘ŕ°įĶ•Ľķ»›∆ųÕݬÁ°Ī“Ľőń÷–£¨ő“√«ňĶĻż»›∆ųľšĶńÕ®–Ň“‘ľį»›∆ųĶĹÕ‚≤ŅÕݬÁĶńÕ®–Ň «Õ®Ļżdocker0ÕÝ«Ň≤ĘĹŠļŌiptables ĶŌ÷Ķń°£ń«√ī‘ŕ…Ō√ś“—ĺ≠Ĺ®ŃĘĶńŅÁ∂ŗ÷ųĽķ»›∆ųÕݬÁņÔ£¨»›∆ųĶńÕ®–Ň”÷ «»Áļő ĶŌ÷Ķńńō£ŅŌ¬√śő“√«“Ľ∆ūņīņŪĹ‚“ĽŌ¬°£◊Ę“‚£ļ”–ŃňĶ•Ľķ»›∆ųÕݬÁĽýī°ļů£¨’‚ņÔļ‹∂ŗÕݬÁŌłĹŕĺÕ≤Ľ‘Ŕ◊ł ŲŃň°£
ő“√«Ō»ņīŅīŅī£¨‘ŕnet1Ō¬Ķń»›∆ųĶńÕݬÁŇš÷√£¨“‘101…ŌĶńnet1c1»›∆ųő™ņż£ļ
$ sudo docker
attach net1c1
root@021f14bf3924:/# ip route
default via 172.19.0.1 dev eth1
10.0.0.0/24 dev eth0 proto kernel scope link
src 10.0.0.4
172.19.0.0/16 dev eth1 proto kernel scope link
src 172.19.0.2
root@021f14bf3924:/# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536
qdisc noqueue state UNKNOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
8: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP>
mtu 1450 qdisc noqueue state UP group default
link/ether 02:42:0a:00:00:04 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.4/24 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::42:aff:fe00:4/64 scope link
valid_lft forever preferred_lft forever
10: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP>
mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:13:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.19.0.2/16 scope global eth1
valid_lft forever preferred_lft forever
inet6 fe80::42:acff:fe13:2/64 scope link
valid_lft forever preferred_lft forever |
Ņ…“‘Ņī≥Ųnet1c1”–ŃĹłŲÕÝŅŕ£ļeth0(10.0.0.4)ļÕeth1(172.19.0.2)£Ľī”¬∑”…ĪŪņīŅī£¨ńŅĶńĶō÷∑‘ŕ172.19.0.0/16∑∂őßńŕĶń£¨◊Ŗeth1£ĽńŅĶńĶō÷∑‘ŕ10.0.0.0/8∑∂őßńŕĶń£¨◊Ŗeth0°£
ő“√«ŐÝ≥Ų»›∆ų£¨ĽōĶĹ÷ųĽķÕݬÁ∑∂≥Ž£ļ
‘ŕ101…Ō£ļ
$ ip a
... ...
5: docker_gwbridge: <BROADCAST,MULTICAST,UP,LOWER_UP>
mtu 1500 qdisc noqueue state UP
link/ether 02:42:52:35:c9:fc brd ff:ff:ff:ff:ff:ff
inet 172.19.0.1/16 scope global docker_gwbridge
valid_lft forever preferred_lft forever
inet6 fe80::42:52ff:fe35:c9fc/64 scope link
valid_lft forever preferred_lft forever
6: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP>
mtu 1500 qdisc noqueue state DOWN
link/ether 02:42:4b:70:68:9a brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 scope global docker0
valid_lft forever preferred_lft forever
11: veth26f6db4: <BROADCAST,MULTICAST,UP,LOWER_UP>
mtu 1500 qdisc noqueue master docker_gwbridge
state UP
link/ether b2:32:d7:65:dc:b2 brd ff:ff:ff:ff:ff:ff
inet6 fe80::b032:d7ff:fe65:dcb2/64 scope link
valid_lft forever preferred_lft forever
16: veth54881a0: <BROADCAST,MULTICAST,UP,LOWER_UP>
mtu 1500 qdisc noqueue master docker_gwbridge
state UP
link/ether 9e:45:fa:5f:a0:15 brd ff:ff:ff:ff:ff:ff
inet6 fe80::9c45:faff:fe5f:a015/64 scope link
valid_lft forever preferred_lft forever |
ő“√«ŅīĶĹ≥żŃňő“√« žŌ§Ķńdocker0ÕÝ«ŇÕ‚£¨ĽĻ∂ŗ≥ŲŃň“ĽłŲdocker_gwbridgeÕÝ«Ň£ļ
$ brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.02424b70689a no
docker_gwbridge 8000.02425235c9fc no veth26f6db4
veth54881a0 |
≤Ę«“ī”brctlĶń š≥ŲĹŠĻŻņīŅī£¨ŃĹłŲveth∂ľ«ŇĹ”‘ŕdocker_gwbridge…Ō£¨∂Ý≤Ľ «docker0…Ō£Ľdocker0‘ŕŅÁ∂ŗ÷ųĽķ»›∆ųÕݬÁ÷–≤Ę√Ľ”–ĪĽ”√ĶĹ°£docker_gwbridgeŐśīķŃňdocker0£¨”√ņī ĶŌ÷101…ŌŃ• Ű”ŕnet1ÕݬÁĽÚnet2ÕݬÁ÷–»›∆ųľšĶńÕ®–Ň“‘ľį»›∆ųĶĹÕ‚≤ŅĶńÕ®–Ň£¨∆š÷įń‹ĺÕļÕĶ•Ľķ»›∆ųÕݬÁ÷–docker0“Ľ—ý°£
ĶęőĽ”ŕ≤ĽÕ¨host«“Ń• Ű”ŕnet1ĶńŃĹłŲ»›∆ųnet1c1ļÕnet1c2ľšĶńÕ®–ŇŌ‘»Ľ≤Ę√Ľ”–Õ®Ļżdocker_gwbridgeÕÍ≥…£¨ī”net1c1¬∑”…ĪŪņīŅī£¨ĶĪnet1c1
ping net1c2 Ī£¨ŌŻŌĘ «Õ®Ļżeth0£¨ľī10.0.0.4’‚łŲip≥Ų»•Ķń°£ī”hostĶń ”Ĺ«£¨net1c1Ķńeth0ň∆ļű√Ľ”–ÕݬÁ…ŤĪł”Ž÷ģѨŔ£¨ń«ÕݬÁÕ®–Ň «»ÁļőÕÍ≥…Ķńńō£Ņ
’‚“Ľ«– «ī”īīĹ®networkŅ™ ľĶń°£«į√śő“√«÷ī––docker network create -d
overlay net1ņīīīĹ®net1 overlay network£¨’‚łŲ√ŁŃÓĽŠīīĹ®“ĽłŲ–¬Ķńnetwork
namespace°£
ő“√«÷™Ķņ√ŅłŲ»›∆ų∂ľ”–◊‘ľļĶńÕݬÁnamespace£¨ī”»›∆ųĶń ”Ĺ«Ņī∆šÕݬÁ√Ż◊÷Ņ’ľš£¨ő“√«ń‹ŅīĶĹÕݬÁ…ŤĪł÷Ó»Á£ļlo°Ęeth0°£’‚łŲeth0”Ž÷ųĽķÕݬÁ√Ż◊÷Ņ’ľš÷–Ķńvethx «“ĽłŲ–ťń‚ÕÝŅ®pair°£overlay
network“≤”–◊‘ľļĶńnet ns£¨∂Ýoverlay networkĶńnet ns”Ž»›∆ųĶńnet
ns÷ģľš“≤”–◊Ň“Ľ–©ÕݬÁ…ŤĪł∂‘”¶ĻōŌĶ°£
ő“√«Ō»ņī≤ťŅī“ĽŌ¬network namespaceĶńid°£ő™Ńňń‹ņŻ”√iproute2Ļ§ĺŖ∂‘network
nsĹÝ––Ļ‹ņŪ£¨ő“√«–Ť“™◊Ų»ÁŌ¬≤Ŕ◊ų£ļ
$cd /var/run
$sudo ln -s /var/run/docker/netns netns
|
’‚ «“Úő™iproute2÷Ľń‹≤Ŕ◊ų/var/run/netnsŌ¬Ķńnet ns£¨∂Ýdockerń¨»ŌĶńnet
ns»ī∑Ň‘ŕ/var/run/docker/netnsŌ¬°£…Ō√śĶń≤Ŕ◊ų≥…Ļ¶÷ī––ļů£¨ő“√«ĺÕŅ…“‘Õ®Ļżip√ŁŃÓ≤ťŅīļÕĻ‹ņŪnet
nsŃň£ļ
$ sudo ip netns
29170076ddf6
1-283b96845c
5ae976d9dc6a
1-da3d1b5fcb |
ő“√«ŅīĶĹ‘ŕ101÷ųĽķ…Ō£¨”–4łŲ“—ĺ≠Ĺ®ŃĘĶńnet ns°£ő“√«īůĶ®≤¬≤‚“ĽŌ¬£¨’‚ňńłŲnet ns∑÷Īū «ŃĹłŲcontainerĶńnet
nsļÕŃĹłŲoverlay networkĶńnet ns°£ī”netnsĶńIDłŮ Ĺ“‘ľįĹŠļŌŌ¬√ś√ŁŃÓ š≥ŲĹŠĻŻ÷–Ķńnetwork
idņīŅī£ļ
$ docker network
ls
NETWORK ID NAME DRIVER
283b96845cbe net2 overlay
da3d1b5fcb8e net1 overlay
dd84da8e80bf host host
3295c22b22b8 docker_gwbridge bridge
b96e2d8d4068 bridge bridge
23749ee4292f none null
|
ő“√«īů÷¬Ņ…“‘≤¬≤‚≥Ųņī£ļ
1-da3d1b5fcb
« net1Ķńnet ns£Ľ
1-283b96845c « net2Ķńnet ns£Ľ
29170076ddf6ļÕ5ae976d9dc6a‘Ú∑÷ Ű”ŕŃĹłŲcontainerĶńnet ns°£ |
”…”ŕő“√«“‘net1ő™ņż£¨“ÚīňŌ¬√śő“√«ĺÕņī∑÷őŲnet1Ķńnet ns ®C 1-da3d1b5fcb°£Õ®Ļżip√ŁŃÓő“√«Ņ…“‘Ķ√ĶĹ»ÁŌ¬ĹŠĻŻ£ļ
$ sudo ip netns
exec 1-da3d1b5fcb ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536
qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: br0: <BROADCAST,MULTICAST,UP,LOWER_UP>
mtu 1450 qdisc noqueue state UP
link/ether 06:b0:c6:93:25:f3 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.1/24 scope global br0
valid_lft forever preferred_lft forever
inet6 fe80::b80a:bfff:fecc:a1e0/64 scope link
valid_lft forever preferred_lft forever
7: vxlan1: <BROADCAST,MULTICAST,UP,LOWER_UP>
mtu 1500 qdisc noqueue master br0 state UNKNOWN
link/ether ea:0c:e0:bc:19:c5 brd ff:ff:ff:ff:ff:ff
inet6 fe80::e80c:e0ff:febc:19c5/64 scope link
valid_lft forever preferred_lft forever
9: veth2: <BROADCAST,MULTICAST,UP,LOWER_UP>
mtu 1450 qdisc noqueue master br0 state UP
link/ether 06:b0:c6:93:25:f3 brd ff:ff:ff:ff:ff:ff
inet6 fe80::4b0:c6ff:fe93:25f3/64 scope link
valid_lft forever preferred_lft forever
$ sudo ip netns exec 1-da3d1b5fcb ip route
10.0.0.0/24 dev br0 proto kernel scope link
src 10.0.0.1
$ sudo ip netns exec 1-da3d1b5fcb brctl show
bridge name bridge id STP enabled interfaces
br0 8000.06b0c69325f3 no veth2
vxlan1
|
ŅīĶĹbr0°Ęveth2£¨ő“√«–ńņÔ÷’”ŕ”–ŃňĶ◊∂ýŃň°£ő“√«≤¬≤‚net1c1»›∆ų÷–Ķńeth0”Žveth2 «“ĽłŲveth
pair£¨≤Ę«ŇĹ”‘ŕbr0…Ō£¨Õ®Ļżethtool≤ť’“veth–ÚļŇĶń∂‘”¶ĻōŌĶŅ…“‘÷§ Ķ’‚Ķ„£ļ
$ sudo docker
attach net1c1
root@021f14bf3924:/# ethtool -S eth0
NIC statistics:
peer_ifindex: 9
101÷ųĽķ£ļ
$ sudo ip netns exec 1-da3d1b5fcb ip -d link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536
qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: br0: <BROADCAST,MULTICAST,UP,LOWER_UP>
mtu 1450 qdisc noqueue state UP
link/ether 06:b0:c6:93:25:f3 brd ff:ff:ff:ff:ff:ff
bridge
7: vxlan1: <BROADCAST,MULTICAST,UP,LOWER_UP>
mtu 1500 qdisc noqueue master br0 state UNKNOWN
link/ether ea:0c:e0:bc:19:c5 brd ff:ff:ff:ff:ff:ff
vxlan
9: veth2: <BROADCAST,MULTICAST,UP,LOWER_UP>
mtu 1450 qdisc noqueue master br0 state UP
link/ether 06:b0:c6:93:25:f3 brd ff:ff:ff:ff:ff:ff
veth
|
Ņ…“‘ŅīĶĹnet1c1Ķńeth0Ķńpair peer indexő™9£¨’żļ√”Žnet ns 1-da3d1b5fcb÷–Ķńveth2Ķń–ÚļŇ“Ľ÷¬°£
ń«√īvxlan1ńō£Ņ◊Ę“‚’‚łŲvxlan1≤Ę∑« «veth…ŤĪł£¨‘ŕip -d link š≥ŲĶń–ŇŌĘ÷–£¨ňŁĶń…ŤĪłņŗ–Õő™vxlan°£«į√śňĶĻżDockerĶńŅÁ∂ŗ÷ųĽķ»›∆ųÕݬÁ «Ľý”ŕvxlanĶń£¨’‚ņÔĶńvxlan1ĺÕ «net1’‚łŲoverlay
networkĶń“ĽłŲ VTEP£¨ľīVXLAN Tunnel End Point ®C VXLANňŪĶņ∂ňĶ„°£ňŁ «VXLANÕݬÁĶńĪŖ‘Ķ…ŤĪł°£VXLANĶńŌŗĻōī¶ņŪ∂ľ‘ŕVTEP…ŌĹÝ––£¨ņż»Á ∂Īū“‘ŐęÕÝ żĺ›÷°ňý ŰĶńVXLAN°ĘĽý”ŕ
VXLAN∂‘ żĺ›÷°ĹÝ––∂Ģ≤„◊™∑Ę°Ę∑‚◊į/Ĺ‚∑‚◊įĪ®őńĶ»°£
÷Ńīň£¨ő“√«Ņ…“‘īů÷¬Ľ≠≥Ų“Ľ∑ýŅÁ∂ŗ÷ųĽķÕݬÁĶń‘≠ņŪÕľ£ļ
»ÁĻŻ‘ŕnet1c1÷–ping net1c2£¨ żĺ›įŁĶń––◊Ŗ¬∑ĺ∂ «‘ű—ýĶńńō£Ņ
1°Ęnet1c1(10.0.0.4)÷–ping net1c2(10.0.0.5)£¨łýĺ›net1c1Ķń¬∑”…ĪŪ£¨ żĺ›įŁŅ…Õ®Ļż÷ĪѨÕݬÁĶĹīÔnet1c2°£”ŕ «arp«Ž«ůĽŮ»°net1c2ĶńMACĶō÷∑£®‘ŕvxlan…ŌĶńarp’‚ņÔ≤ĽŌÍ ŲŃň£©£¨Ķ√ĶĹmacĶō÷∑ļů£¨∑‚įŁ£¨ī”eth0∑Ę≥Ų£Ľ
2°Ęeth0«ŇĹ”‘ŕnet ns 1-da3d1b5fcb÷–Ķńbr0…Ō£¨’‚łŲbr0 «łŲÕÝ«Ň(ĹĽĽĽĽķ)–ťń‚…ŤĪł£¨–Ť“™Ĺęņī◊‘eth0ĶńįŁ◊™∑Ę≥Ų»•£¨”ŕ «ĹęįŁ◊™łÝŃňvxlan…ŤĪł£Ľ’‚łŲŅ…“‘Õ®Ļżarp
-aŅīĶĹ“Ľ–©∂ňńŖ£ļ
$ sudo ip netns
exec 1-da3d1b5fcb arp -a
? (10.0.0.5) at 02:42:0a:00:00:05 [ether] PERM
on vxlan1 |
3°Ęvxlan «łŲŐō ‚…ŤĪł£¨ ’ĶĹįŁļů£¨”…vxlan…ŤĪłīīĹ® Ī◊Ę≤ŠĶń…ŤĪłī¶ņŪ≥Ő–Ú∂‘įŁĹÝ––ī¶ņŪ£¨ľīĹÝ––VXLAN∑‚įŁ£®’‚∆ŕľšĽŠ≤ť—Įconsul÷–īśīĘĶńnet1–ŇŌĘ£©£¨ĹęICMPįŁ’ŻŐŚ◊ųő™UDPįŁĶńpayload∑‚◊į∆ūņī£¨≤ĘĹęUDPįŁÕ®Ļżňř÷ųĽķĶńeth0∑ĘňÕ≥Ų»•°£
4°Ę71ňř÷ųĽķ ’ĶĹUDPįŁļů£¨∑ĘŌ÷ «VXLANįŁ£¨łýĺ›VXLANįŁ÷–ĶńŌŗĻō–ŇŌĘ£®Ī»»ÁVxlan Network
Identifier£¨VNI=256)’“ĶĹvxlan…ŤĪł£¨≤Ę◊™łÝł√vxlan…ŤĪłī¶ņŪ°£vxlan…ŤĪłĶńī¶ņŪ≥Ő–ÚĹÝ––Ĺ‚įŁ£¨≤ĘĹęUDP÷–Ķńpayload»°≥Ų£¨’ŻŐŚÕ®Ļżbr0◊™łÝvethŅŕ£¨net1c2ī”eth0 ’ĶĹICMP żĺ›įŁ£¨Ľōłīicmp
reply°£
ő“√«Ņ…“‘Õ®Ļżwireshark◊•»°ŌŗĻōvxlanįŁ£¨łŖįśĪĺwiresharkńŕ÷√VXLAN–≠“ť∑÷őŲ∆ų£¨Ņ…“‘÷ĪĹ” ∂ĪūļÕ’Ļ ĺVXLANįŁ£¨’‚ņÔį≤◊įĶń «2.0.1įśĪĺ£®◊Ę“‚£ļ“Ľ–©ĶÕįśĪĺwireshark≤Ľ÷ß≥÷VXLAN∑÷őŲ∆ų£¨Ī»»Á1.6.7įśĪĺ£©£ļ
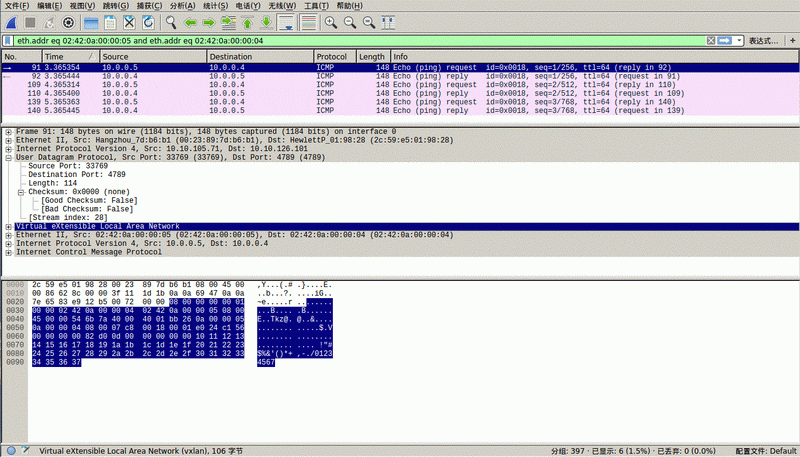
Ļō”ŕVXLAN–≠“ťĶńŌłĹŕ£¨Ļż”ŕłī‘”£¨‘ŕļů–ÝĶńőń’¬÷–maybeĽŠ”–ĹÝ“Ľ≤ĹņŪĹ‚°£
|






