| БрМЭЦМі: |
| БОЮФРДздгкАйЖШЃЌНщЩмСЫKubernetes
МмЙЙЃЌгІгУГЬађВПЪ№ФЃаЭЃЌЗўЮёЗЂЯжгыИКдиОљКтЃЌService ШчКЮдкФкВПЙЄзїЃЌPersistent
Volumes ЕФЪЙгУЕШЁЃ |
|
Kubernetes вбГЩЮЊдкЫНгадЦЁЂЙЋгадЦКЭЛьКЯдЦЛЗОГжаДѓЙцФЃВПЪ№ШнЦїЛЏгІгУЕФЪТЪЕБъзМЁЃAWSЁЂGoogle
CloudЁЂAzureЁЂIBM Cloud КЭ Oracle Cloud ЕШМИИізюДѓЕФЙЋгадЦЦНЬЈЖМПЩвдЮЊ
Kubernetes ЬсЙЉЭаЙмЗўЮёЁЃ
МИФъЧАЃЌRed Hat гУ Kubernetes ЭъШЋЬцДњСЫздМКЕФ OpenShift ЪЕЪЉЗНАИЃЌВЂгы
Kubernetes ЩчЧјКЯзїЭЦГіСЫЯТвЛДњШнЦїЦНЬЈЁЃMesosphere дк Kubernetes
СїааЦ№РДКѓбИЫйНЋ Kubernetes ЕФЙиМќЬиадЃЌШчШнЦїЗжзщЃЌжиЕўЭјТчЃЌ4 ВуТЗгЩЃЌSecrets
ЕШМЏГЩЕНЫќУЧЕФШнЦїЦНЬЈ DC / OS жаЁЃDC / OS ЛЙНЋ Kubernetes гы Marathon
ећКЯЮЊвЛИіШнЦїБрХХЯЕЭГЁЃPivotal зюНќЭЦГіСЫЛљгк Kubernetes ЕФ Pivotal Container
ServiceЃЈPKSЃЉЃЌгУгкдк Pivotal Cloud Foundry ЩЯВПЪ№ЕкШ§ЗНЗўЮёЁЁЪБжСНёШеЃЌШдШЛгааэЖрзщжЏКЭММЪѕЬсЙЉЩЬе§дкИњЫц
Kubernetes ЗЂеЙЕФНХВНЖдВњЦЗНјааЯргІЕїећЁЃ
2014 ФъЃЌKubernetes зпШыШЫУЧЕФЪгвА ЁЃЫќећКЯСЫЙШИшФкВПШнЦїМЏШКЙмРэЯЕЭГ Borg
КЭ Omega гХЪЦЃЌМГШЁСЫЙШИшДѓЙцФЃгІгУШнЦїММЪѕЪЎМИФъОбщ ЁЃдкЮвПДРДЃЌ Kubernetes ШУШЫУЧЖдгкжюШчЮЂЗўЮёЃЌserverless
ЙІФмЃЌService Mesh КЭ Event-driven гІгУГЬађЕШаТаЫШэМўМмЙЙФЃЪНЕФЪЪгІБфЕУШнвзЃЌВЂЮЊЙЙНЈећИідЦдЩњЩњЬЌЦЬЦНСЫЕРТЗЁЃзюживЊЕФЪЧЃЌЦф
cloud agnostic ЩшМЦШУШнЦїЛЏгІгУГЬађЮоашЖдгІгУГЬађДњТыНјааШЮКЮИќИФЃЌОЭПЩвддкШЮКЮЦНЬЈЩЯдЫааЁЃЕБЧА
Kubernetes жївЊгУдкДѓаЭЦѓвЕВПЪ№ГЁОАЯТЃЌЕЋДгГЄдЖРДПДЃЌжааЁаЭЦѓвЕвВПЩвдгІгУ Kubernetes
НкЪЁДѓСПЕФЛљДЁЩшЪЉКЭЮЌЛЄГЩБОЁЃ
НгЯТРДЃЌЮвНЋдкЮФжаНщЩм Kubernetes ЕФИпМЖМмЙЙЃЌгІгУГЬађВПЪ№ФЃаЭЃЌЗўЮёЗЂЯжКЭИКдиОљКтЃЌФкВП/ЭтВПТЗгЩЗжРыЁЂpersistent
volume ЕФЪЙгУЃЌВПЪ№НкЕуЪиЛЄГЬађЃЌВПЪ№газДЬЌЗжВМЪНЯЕЭГЃЌзївЕКѓЬЈдЫааЃЌВПЪ№Ъ§ОнПтЃЌХфжУЙмРэЃЌЦОжЄЙмРэЃЌЙіЖЏИќаТЃЌздЖЏЫѕЗХКЭАќЙмРэЁЃ
Kubernetes МмЙЙ
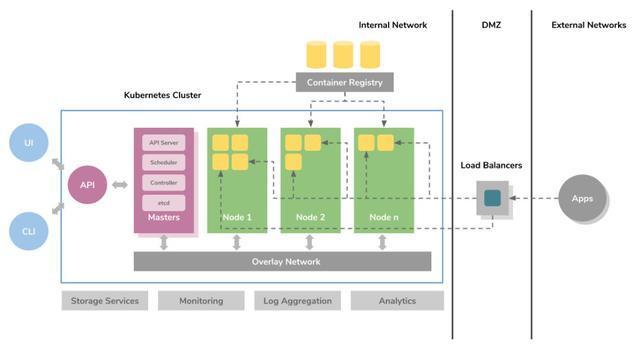
етИіМЏШКЙмРэЦїЕФЛљБОЩшМЦВпТджЎвЛОЭЪЧЃЌЮоашИќИФгІгУГЬађДњТыЃЌОЭФмВПЪ№дкащФтЛњЩЯдЫааЕФЯжгагІгУГЬађЁЃСэЭтЃЌШЮКЮдЫаадкащФтЛњЩЯЕФгІгУГЬађЖМПЩвдЭЈЙ§ШнЦїЛЏзщМўдк
Kubernetes ЩЯЪЕЯжВПЪ№ЁЃетЪЧЭЈЙ§ШнЦїЗжзщЁЂШнЦїБрХХЁЂИВИЧЭјТчЁЂЛљгкЕк 4 ВуащФт IPЁЂЗўЮёЗЂЯжЁЂжЇГжЪиЛЄГЬађдЫааЁЂВПЪ№газДЬЌгІгУГЬађзщМўЁЂвдМАРЉеЙШнЦїБрХХЯЕЭГетаЉКЫаФЙІФмЪЕЯжЕФЁЃ
СэЭтЃЌKubernetes ПЩвдЬсЙЉвЛзщПЩЖЏЬЌРЉеЙЕФжїЛњЃЌПЩвдгІгУШнЦїдЫаа workloadЃЌВЂЪЙгУвЛзщГЦЮЊ
master ЕФЙмРэжїЛњРДЬсЙЉЙмРэећИіШнЦїЛљДЁМмЙЙЕФ APIЁЃетаЉ workload АќРЈГЄЦкдЫааЗўЮё
ЃЌХњДІРэзївЕКЭШнЦїжїЛњЕФЪиЛЄГЬађЁЃЮЊСЫЬсЙЉШнЦїЕНШнЦїЕФТЗгЩЃЌЫљгаШнЦїжїЛњЖМгУИВИЧЭјТчСЌНгдквЛЦ№ЁЃВПЪ№дк
Kubernetes ЩЯЕФгІгУГЬађдкМЏШКЭјТчжаЪЧЖЏЬЌПЩМћЕФЃЌВЂПЩЭЈЙ§ДЋЭГИКдиОљКтЦїЯђЭтВПЭјТчБЉТЖЁЃМЏШКЙмРэЦїЕФзДЬЌДцДЂдквЛИіИпЖШЗжВМЕФ
key/value ДцДЂЃЈetcdЃЉжаЃЌИУДцДЂдк master ЩЯдЫааЁЃ
Kubernetes ЕїЖШГЬађПЩвдШЗБЃУПИігІгУГЬађзщМўЖМвбНјааНЁПЕМьВщЃЌПЩЬсЙЉИпПЩгУЁЃЕБИББОЕФЪ§СПЩшжУДѓгк
1 ЪБЃЌЖрИіжїЛњжаЕФЪЕР§ЖМЛсБЛЕїЖШЁЃШчЙћЦфжавЛИіжїЛњВЛПЩгУЃЌФЧУДдЫаадкИУжїЛњЩЯЕФЫљгаШнЦїЃЌЖМПЩФмБЛШЮвЛжїЛњЕїЖШЁЃ
Kubernetes ЕФУдШЫЙІФмжЎвЛОЭЪЧЬсЙЉСНМЖздЖЏЫѕЗХЁЃЪзЯШЃЌПЩвдЪЙгУвЛИіУћЮЊ Horizontal
Pod Autoscaler ЕФзЪдДРДздЖЏЕїећШнЦїЃЌЫќПЩвдМрЪгзЪдДЯћКФВЂЖдЫљашШнЦїЪ§СПНјааЯргІЕиЕїећЁЃЦфДЮЃЌЫќПЩвдЭЈЙ§ЬэМгКЭЩОГ§жїЛњЕФЗНЪНЃЌИљОнзЪдДашЧѓРЉеЙШнЦїМЏШКЁЃДЫЭтЃЌЭЈЙ§в§ШыМЏШКСЊКЯЙІФмЃЌHorizontal
Pod Autoscaler ЩѕжСПЩвдЪЙгУЕЅИі API ЖЫЕуПчЖрИіЪ§ОнжааФЙмРэ Kubernetes
МЏШКЁЃ
етжЛЪЧ Kubernetes ЁАПЊЯфМДгУЁБжкЖрЙІФмЕФБљЩНвЛНЧЁЃНгЯТРДЃЌЮвНЋНщЩм Kubernetes
ЕФКЫаФЙІФмЃЌВЂЯъНтгІИУШчКЮЩшМЦВЂВПЪ№ФуЕФШэМўгІгУГЬађЁЃ
гІгУГЬађВПЪ№ФЃаЭ
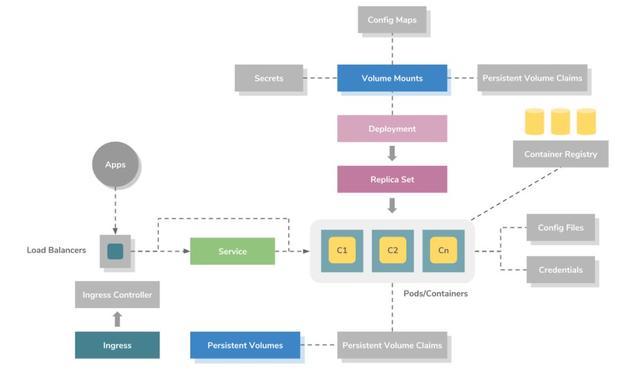
ЩЯЭМЪЧ Kubernetes ЩЯИпМЖгІгУГЬађВПЪ№ФЃаЭЁЃЫќЪЙгУ ReplicaSet РДБрХХШнЦїЁЃЮвУЧПЩвдНЋ
ReplicaSet ЪгЮЊЛљгк YAML ЛђЛљгк JSON ЕФдЊЪ§ОнЮФМўЃЌИУЮФМўПЩвдЖЈвхШнЦїОЕЯёЁЂЖЫПкЁЂИББОЪ§СПЁЂМЄЛюзДПіМьВщЁЂЛюЖЏзДПіМьВщЁЂЛЗОГБфСПЁЂЪ§ОнЙвдиКЭДДНЈВЂЙмРэШнЦїашвЊЕФАВШЋЙцдђЁЃ
ШнЦїдк Kubernetes ЩЯвдзщЕФаЮЪНДДНЈЃЌБЛГЦЮЊ PodЃЌЫќЪЧ Kubernetes ЕФвЛИідЊЪ§ОнЖЈвхЛђзЪдДЁЃУПИі
Pod ЖМПЩвдЭЈЙ§ Linux namespaceЃЌcgroup КЭЦфЫћФкКЫЙІФмдкШнЦїжЎМфЙВЯэЮФМўЯЕЭГЁЂЭјТчНгПквдМАВйзїЯЕЭГгУЛЇЁЃЖј
ReplicaSets ПЩвдгЩвЛИіНазі Deployment ЕФИпМЖзЪдДНјааЙмРэЃЌDeployment
ЬсЙЉгУгкЙіЖЏИќаТКЭДІРэЦфЛиЙіЕФЙІФмЁЃ
ЭЈЙ§жДааЯТУцетбљвЛЬѕМђЕЅЕФ CLI УќСюЃЌОЭПЩвддк Kubernetes ЩЯВПЪ№ШнЦїЛЏЕФгІгУГЬађСЫЁЃ

вЛЕЉжДааЩЯЪі CLI УќСюЃЌИјЖЈШнЦїОЕЯёНЋДДНЈвЛИіВПЪ№ЖЈвхЃЌвЛИіИББОМЏКЭвЛИі pod; СэЭтЪЙгУгІгУГЬађУћГЦНЋЬэМгвЛИі
selector labelЁЃгЩДЫДДНЈЕФУПИі pod НЋгаСНИіШнЦїЃЌвЛИігУгкИјЖЈЕФгІгУГЬађзщМўЃЌСэвЛИіНазі
Pause гУгкСЌНгЭјТчНгПкЁЃ
ЗўЮёЗЂЯжгыИКдиОљКт

Kubernetes ЕФжївЊЙІФмжЎвЛЃЌЪЧЪЙгУ SkyDNS КЭ 4 ВуащФт IP ТЗгЩЯЕЭГЃЌЬсЙЉЗўЮёЗЂЯжКЭФкВПТЗгЩФЃаЭЁЃетаЉЙІФмЮЊвЊЧѓЪЙгУ
service ЕФгІгУГЬађЬсЙЉСЫФкВПТЗгЩЁЃЭЈЙ§ИББОМЏДДНЈЕФвЛзщ Pod ПЩвдЪЙгУМЏШКЭјТчФкЕФ service
НјааИКдиОљКтЁЃservice гУбЁдёЦїБъЧЉЃЈselector labelsЃЉСЌНгЕН PodЁЃУПИі service
ЛсЗжЕНвЛИіЮЈвЛЕФ IP ЕижЗЃЌКЭвЛИігЩЦфУћГЦХЩЩњЕФжїЛњУћЃЌВЂвдбЛЗЕФЗНЪНдк Pod жаТЗгЩЧыЧѓЁЃИУ
service ЩѕжСЛЙФмЮЊашвЊЛсЛАЙиСЊЕФгІгУГЬађЬсЙЉЛљгк IP ЕФТЗгЩЛњжЦЁЃвЛИі service ПЩвдЖЈвхвЛИіЖЫПкМЏКЯЃЌЮЊИјЖЈ
service ЖЈвхЕФЪєадНЋвдЯрЭЌЕФЗНЪНгІгУгкЫљгаЖЫПкЁЃвђДЫЃЌдквЛИіГЁОАжаЃЌжЛашвЊвЛИіИјЖЈЖЫПкЕФЛсЛАЙиСЊЃЌдкИУЖЫПкжаЫљгаЦфЫћЖЫПкЖМашвЊЪЙгУЛљгкТжбЏЕФТЗгЩЃЌетПЩФмвЊгУЕНЖрИі
serviceЁЃ
Service ШчКЮдкФкВПЙЄзїЃП
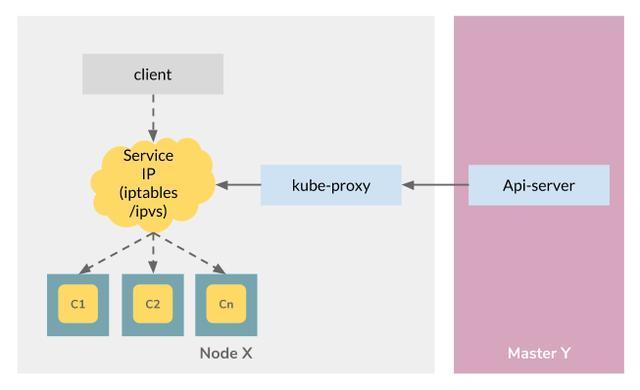
Kubernetes service ЪЙгУвЛИіУћЮЊ kube-proxy ЕФзщМўРДЪЕЯжЁЃУПИіНкЕужаЖМгавЛИі
kube-proxy ЪЕР§ЁЃKube-proxy гаШ§жжДњРэФЃЪНЃКUserspaceЃЌiptables
КЭ IPVSЁЃЕБЧАЕФФЌШЯФЃЪНЪЧ iptablesЁЃ
дкЕквЛжжДњРэФЃЪНЯТЃЌuserspaceЃЌkube-proxy БОЩэГфЕБДњРэЗўЮёЦїЃЌгЩ iptables
ЙцдђНгЪмЕФЧыЧѓЮЏЭаИјКѓЖЫ PodЁЃдкетжжФЃЪНЯТЃЌkube-proxy НЋдк userspace жадЫааЃЌВЂдіМгвЛИіЬјзЊЕНаХЯЂСїЁЃдк
iptables жаЃЌkube-proxy ДДНЈвЛзщ iptables ЙцдђЃЌгУгкНЋРДздПЭЛЇЖЫЕФДЋШыЧыЧѓжБНгзЊЗЂЕНЭјТчВуЩЯЕФКѓЖЫ
Pod ЖЫПкЃЌЖјЮоашдкжаМфЬэМгЖюЭтЕФЬјзЊЁЃетИіДњРэФЃЪНБШЕквЛжжФЃЪНПьЕУЖрЃЌвђЮЊЫќЮоашдкжаМфЬэМгЖюЭтДњРэЗўЮёЦїЃЌжБНгдк
kernel space жадЫааЁЃ
Kubernetes v1.8 АцБОдіМгСЫЕкШ§жжДњРэФЃЪНЃЌгыЕкЖўжжДњРэФЃЪНЗЧГЃЯрЫЦЃЌЫќВЛгУ iptables
ЙцдђЖјЪЧЪЙгУЛљгк IPVS ЕФащФтЗўЮёЦїРДТЗгЩЧыЧѓЁЃIPVS ЪЧвЛжжДЋЪфВуИКдиОљКтЙІФмЃЌПЩдкЛљгк Netfilter
ЕФ Linux kernel жадЫааЃЌВЂЬсЙЉвЛзщИКдиОљКтЫуЗЈЁЃЭЈЙ§ iptables ЪЙгУ IPVS
ЪЧвђЮЊЪЙгУ iptables ПЩвдЭЌВНДњРэЙцдђЕФадФмПЊЯњЁЃЕБДДНЈЪ§ЧЇИіЗўЮёЪБЃЌгы IPVS ЕФМИКСУыЯрБШЃЌИќаТ
iptables ЙцдђашвЊЯрЕБГЄЕФЪБМфЁЃДЫЭтЃЌIPVS ЪЙгУ hash table РДВщевЭЈЙ§ iptables
НјааЫГађЩЈУшЕФДњРэЙцдђЁЃ
Фк/ЭтТЗгЩЗжРы
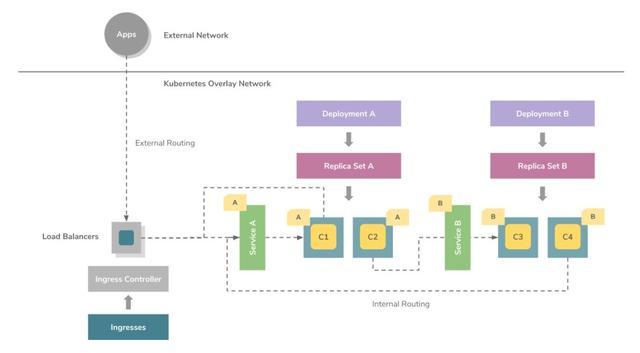
Kubernetes service ПЩвдЭЈЙ§СНжжжївЊЗНЪНБЉТЖгкЭтВПЭјТчЁЃЕквЛжжЗНЗЈЪЧЭЈЙ§БЉТЖНкЕуЩЯЕФЖЏЬЌЖЫПкРДЪЙгУНкЕуЖЫПкЃЌНЋСїСПзЊЗЂЕНЗўЮёЖЫПкЁЃЕкЖўжжЗНЗЈЪЧЭЈЙ§ЪЙгУ
ingress controller ХфжУИКдиОљКтЦїЃЌ ingress controller ПЩвдЭЈЙ§СЌНгЕНЯрЭЌЕФИВИЧЭјТчНЋЧыЧѓЮЏЭаИј
serviceЁЃ Ingress controller ЪЧвЛИіКѓЬЈНјГЬЃЌЫќПЩвддЫаадкМрЬ§ Kubernetes
API ЕФШнЦїжаЃЌИљОнИјЖЈЕФвЛзщ ingress ЖЏЬЌЕиХфжУВЂжиаТМгдиИјЖЈЕФИКдиОљКтЦїЁЃIngress
ЛљгкЪЙгУЗўЮёЕФ hostname КЭ context paths РДЖЈвхТЗгЩЙцдђЁЃ
вЛЕЉЪЙгУ kubectl run УќСюНЋгІгУГЬађВПЪ№ЕН Kubernetes ЩЯЃЌЫќОЭПЩвдЭЈЙ§ИКдиОљКтЦїБЉТЖИјЭтВПЭјТчЃЌШчЯТЫљЪОЃК

ЩЯЪіУќСюНЋДДНЈвЛИіИКдиОљКтЦїРраЭЕФ serviceЃЌВЂНЋДДНЈИУ Pod ЪБЩњГЩЕФЯрЭЌбЁдёЦїБъЧЉ(selector
label )НЋЦфгГЩфЕН PodЁЃвђДЫЃЌИљОн Kubernetes МЏШКЕФХфжУЗНЪНЃЌЛљДЁМмЙЙЩЯЕФИКдиОљКтЦїЗўЮёНЋЭЈЙ§
service ЛђжБНгЮЊИјЖЈЕФ Pod ТЗгЩЧыЧѓЖјДДНЈЁЃ
Persistent Volumes ЕФЪЙгУ

ашвЊдкЮФМўЯЕЭГЩЯБЃСєЪ§ОнЕФгІгУГЬађПЩвдЪЙгУ volume НЋДцДЂЩшБИЙвдиЕНСйЪБШнЦїжаЃЌетгыащФтЛњЪЙгУ
volumes ЕФЗНЪНРрЫЦЁЃKubernetes ЭЈЙ§в§ШыГЦЮЊ persistent volume
claimsЃЈPVCЃЉЕФжаМфзЪдДЃЌНЋЮяРэДцДЂЩшБИгыШнЦїНјааЫЩЩЂёюКЯЁЃPVC ЖЈвхСЫДХХЬДѓаЁЃЌДХХЬРраЭЃЈReadWriteOnceЃЌReadOnlyManyЃЌReadWriteManyЃЉВЂЧвПЩвдНЋДцДЂЩшБИЖЏЬЌЕиСЌНгЕНФГИі
Pod ЖЈвхЕФ volume ЩЯ ЁЃАѓЖЈЙ§ГЬМШПЩвдЪЙгУ PV ОВЬЌДІРэЃЌвВПЩвдЖЏЬЌЕиЪЙгУ persistent
storage provider ЁЃдкетСНжжЗНЗЈжаЃЌvolume НЋвЛЖдвЛЕиСЌНгЕНвЛИі PVЃЌетШЁОігкХфжУЃЌвђЮЊМДЪЙИУ
Pod БЛжежЙЃЌЪ§ОнвВНЋБЛБЃСєЁЃИљОнЫљЪЙгУЕФДХХЬРраЭЃЌЖрИі Pod НЋФмЙЛСЌНгЕНЯрЭЌЕФДХХЬВЂНјааЖСШЁЛђаДШыЁЃ
жЇГж ReadWriteOnce ЕФДХХЬжЛФмСЌНгЕНвЛИі PodЃЌВЂЧвВЛФмЭЌЪБдкЖрИі Pod жаЙВЯэЁЃЕЋЪЧЃЌжЇГж
ReadOnlyMany ЕФДХХЬПЩвддкжЛЖСФЃЪНЯТЭЌЪБдкЖрИі Pod жаЙВЯэЁЃЙЫУћЫМвхЃЌОпгаReadWriteMany
жЇГжЕФДХХЬПЩвдСЌНгЕНЖрИі PodЃЌвдЖСаДФЃЪНЙВЯэЪ§ОнЁЃKubernetes ЬсЙЉСЫвЛЯЕСа volume
pluginsЃЌгУгкжЇГж AWS EBSЃЌGCE ГжОУадДХХЬЃЌAzure FileЃЌAzure Disk
вдМАЦфЫћжкЫљжмжЊЕФДцДЂЯЕЭГЃЈШч NFSЃЌGlusterfsЃЌCinder ЕШЃЉЕШЙЋгадЦЦНЬЈЩЯЬсЙЉЕФДцДЂЗўЮёЁЃ
дкНкЕуВПЪ№ЪиЛЄГЬађ
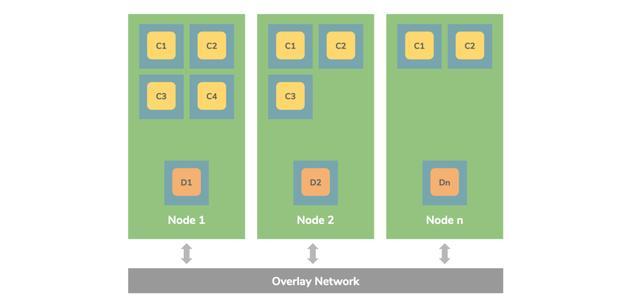
Kubernetes ЬсЙЉСЫвЛИіУћЮЊ DaemonSets ЕФзЪдДЃЌгУгкдкУПИі Kubernetes
НкЕужаНЋЪиЛЄНјГЬЕФИББОзїЮЊКѓЬЈНјГЬдЫааЁЃDaemonSet ЕФвЛаЉгУР§ШчЯТЫљЪОЃК
МЏШКДцДЂЪиЛЄГЬађЃЌШч glusterdЃЌceph вЊВПЪ№дкУПИіНкЕуЩЯвдЬсЙЉГжОУадДцДЂЃЛ
НкЕуМрЪгЪиЛЄНјГЬЃЌШч Prometheus НкЕуПЩЕМГіГЬађЃЌНЋдкУПИіНкЕуЩЯдЫааЃЌвдМрЪгШнЦїжїЛњЃЛ
ШежОЪеМЏЪиЛЄГЬађЃЌШч fluentd Лђ logstash ЃЌдкУПИіНкЕуЩЯдЫаавдЪеМЏШнЦїКЭ Kubernetes
зщМўШежОЃЛ
Ingress controller pod НЋдквЛзщНкЕуЩЯдЫааЃЌвдЬсЙЉЭтВПТЗгЩЁЃ
ВПЪ№газДЬЌЗжВМЪНЯЕЭГ
ШнЦїЛЏгІгУГЬађзюРЇФбЕФШЮЮёжЎвЛЃЌОЭЪЧЩшМЦгазДЬЌЗжВМЪНзщМўЕФВПЪ№ЬхЯЕНсЙЙЁЃгЩгкЮозДЬЌзщМўПЩФмУЛгадЄЖЈвхЕФЦєЖЏЫГађЁЂМЏШКвЊЧѓЁЂЕуЖдЕу
TCP СЌНгЁЂЮЈвЛЕФЭјТчБъЪЖЗћЁЂе§ГЃЕФЦєЖЏКЭжежЙвЊЧѓЕШЃЌвђДЫПЩвдКмШнвзЕиНјааШнЦїЛЏЁЃжюШчЪ§ОнПтЃЌДѓЪ§ОнЗжЮіЯЕЭГЃЌЗжВМЪН
key/value ДцДЂКЭ message brokers ПЩФмгаИДдгЕФЗжВМЪНЬхЯЕНсЙЙЃЌЖМПЩФмгУЕНЩЯЪіЙІФмЁЃKubernetes
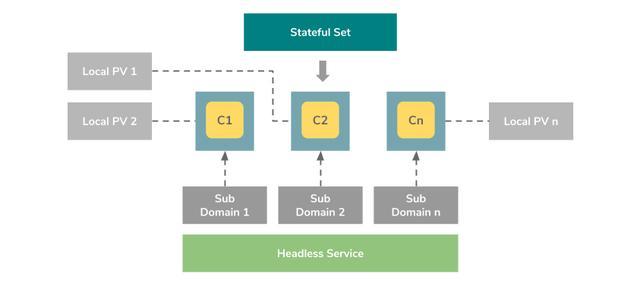
в§ШыСЫ StatefulSets зЪдДРДжЇГжетжжИДдгЕФашЧѓЁЃ
StatefulSets РрЫЦгк ReplicaSetsЃЌЕЋЪЧЫќПЩвдДІРэ Pod ЕФЦєЖЏЫГађЃЌЮЊБЃСєУПИі
Pod ЕФзДЬЌЩшжУЮЈвЛБъЪЖЃЌЭЌЪБОпгавдЯТЙІФмЃК
StableЃЌЮЈвЛЕФЭјТчБъЪЖЗћ
StableЃЌГжОУЛЏЕФДцДЂ
OrderedЃЌгХбХЕФВПЪ№КЭЫѕЗХ
OrderedЃЌгХбХЕФЩОГ§КЭжежЙ
OrderedЃЌздЖЏЙіЖЏИќаТ
Stable жИЕФЪЧНЋЭјТчБъЪЖЗћКЭГжОУДцДЂПч Pod жиаТЕїЖШЁЃШчЩЯЭМЫљЪОЃЌЪЙгУ headless
services ЬсЙЉЮЈвЛЕФЭјТчБъЪЖЗћЁЃKubernetes ЬсЙЉСЫвдЗжВМЪНЗНЪНВПЪ№ Cassandra
КЭ Zookeeper ЕФ StatefulSets ЪОР§ЁЃ
дЫааКѓЬЈзївЕ
Г§СЫ ReplicaSets КЭ StatefulSets жЎЭтЃЌKubernetes ЛЙЬсЙЉСЫСНИіЖюЭтЕФПижЦЦїЃЌгУгкдкКѓЬЈдЫааГЦЮЊ
Jobs КЭ CronJobs ЕФ workload ЁЃ Job КЭ CronJobs жЎМфЕФЧјБ№дкгкЃЌJob
жДаавЛДЮВЂжежЙЃЌЖј CronJobs гыБъзМ Linux cron job РрЫЦЃЌИљОнИјЖЈЪБМфМфИєжмЦкаджДааЁЃ
ВПЪ№Ъ§ОнПт
гЩгкДѓМвЖдМЏШКЛЏЁЂЕуЖдЕуСЌНгЁЂжїДгИДжЦЁЂЗжЧјЁЂЙмРэБИЗнЕШЖМгавЊЧѓЃЌвђДЫдкШнЦїЦНЬЈЩЯВПЪ№Ъ§ОнПтвдЙЉЩњВњЪЙгУБШВПЪ№гІгУГЬађвЊРЇФбЕФЖрЁЃШчЧАЫљЪіЃЌStatefulSets
зЈУХгІИЖетжжИДдгвЊЧѓЃЌЖјдк Kubernetes ЩЯдЫаа PostgreSQL КЭ MongoDB
МЏШКгаМИИіЯргІбЁЯюЁЃ
YouTube ЕФЪ§ОнПтМЏШКЯЕЭГ Vitess ЯждкЪЧвЛИі CNCF ЯюФПЃЌЖдгкдк Kubernetes
ЩЯДѓЙцФЃдЫаа MySQL РДЫЕЃЌЫќЪЧвЛИіКмКУЕФбЁдёЁЃжЕЕУзЂвтЕФЪЧЃЌетаЉбЁЯюЛЙДІгкЗЧГЃдчЦкЕФНзЖЮЃЌШчЙћЯжгаЕФЩњВњМЖЪ§ОнПтЯЕЭГПЩгУгкИјЖЈЕФЛљДЁМмЙЙЃЌР§Шч
AWS ЩЯЕФ RDSЃЌGCP ЩЯЕФ Cloud SQL ЛђФкВПВПЪ№Ъ§ОнПтМЏШКПМТЧЕНАВзАИДдгадКЭЮЌЛЄПЊЯњЃЌбЁдёЦфжавЛжжбЁдёПЩФмЛсИќКУЁЃ
ХфжУЙмРэ
ШнЦїЭЈГЃЪЙгУЛЗОГБфСПРДЖдЦфдЫааЪБХфжУНјааВЮЪ§ЛЏЁЃЕЋЪЧЃЌЕфаЭЕФЦѓвЕгІгУГЬађЪЙгУДѓСПЕФХфжУЮФМўРДЬсЙЉИјЖЈВПЪ№ЫљашЕФОВЬЌХфжУЁЃKubernetes
ЬсЙЉСЫвЛжжГЦЮЊ ConfigMaps ЕФМђЕЅзЪдДРДЙмРэДЫРрХфжУЮФМўЕФЗНЗЈЃЌЮоашНЋЫќУЧРІАѓЕНШнЦїОЕЯёжаЁЃжЛашвЊЪЙгУвдЯТ
CLI УќСюПЩвдЪЙгУФПТМЃЌЮФМўЛђ literal values ДДНЈ ConfigMapsЃК

вЛЕЉДДНЈ ConfigMap КѓЃЌПЩвдЪЙгУ volume mount НЋЦфЙвдиЕНвЛИіШнЦїЁЃНшжњетжжЫЩЩЂёюКЯЕФЬхЯЕНсЙЙЃЌжЛашИќаТЯрЙиЕФ
ConfigMap ВЂжДааЙіЖЏИќаТГЬађОЭПЩвдЮоЗьЕиИќаТвбдЫааЯЕЭГЕФХфжУЃЌЮвНЋдкЯТвЛНкжаЖдЦфНјааНтЪЭЁЃзЂвт
ConfigMaps ФПЧАВЛжЇГжЧЖЬзЮФМўМа; вђДЫЃЌШчЙћгІгУГЬађЕФЧЖЬзФПТМНсЙЙжагаПЩгУЕФХфжУЮФМўЃЌдђашвЊЮЊУПИіФПТММЖБ№ДДНЈвЛИі
ConfigMapЁЃ
ЦОжЄЙмРэ
гы ConfigMaps РрЫЦЃЌKubernetes ЬсЙЉСЫСэвЛИіКУЙІФмЃЌГЦЮЊ SecretsЃЌгУгкЙмРэУєИааХЯЂЃЌШчУмТыЃЌOAuth
СюХЦКЭ ssh УмдПЁЃЗёдђЃЌдквбОдЫааЕФЯЕЭГЩЯИќаТИУаХЯЂПЩФмашвЊжиНЈШнЦїОЕЯёЁЃ
ЪЙгУвдЯТЗНЗЈПЩвдДДНЈвЛИі Secret РДЙмРэЛљБОЩэЗнбщжЄЦООнЃК

вЛЕЉДДНЈСЫ secretЃЌОЭПЩвдЪЙгУЛЗОГБфСПЛђ volume mounts ЭЈЙ§ Pod НјааЖСШЁЁЃЕБШЛЃЌЦфЫћРраЭЕФУєИааХЯЂвВПЩвдЪЙгУЯрЭЌЕФЗНЗЈзЂШыЕН
Pod жаЁЃ
ЙіЖЏИќаТ

ЩЯУцЕФЖЏЛЫЕУїСЫШчКЮЭЈЙ§ЪЙгУРЖ/ТЬВПЪ№ЗНЗЈЮЊвбОдЫааЕФгІгУГЬађНјааЙіЖЏИќаТЃЌЖјВЛЛсЕМжТЯЕЭГЭЃЛњЁЃетЪЧ
Kubernetes ЕФСэвЛИіЗЧГЃАєЕФЙІФмЃЌгІгУГЬађПЩвдЮоЗьЕиЭЦГіАВШЋИќаТКЭЯђКѓМцШнЕФИќИФЁЃШчЙћИќИФВЛЯђКѓМцШнЃЌдђПЩФмашвЊЪЙгУЕЅЖРЕФВПЪ№ЖЈвхжДааЪжЖЏРЖ/ТЬВПЪ№ЁЃ
ДЫЗНЗЈдЪаэЪЙгУМђЕЅЕФ CLI УќСюжДааОэеЙРИИќаТШнЦїОЕЯёЃК
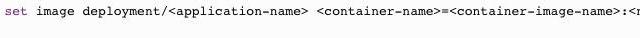
вЛЕЉжДааСЫ rolloutЃЌПЩвдАДеевдЯТЗНЪНМьВщ rollout Й§ГЬЕФзДЬЌЃК

ЪЙгУЯрЭЌЕФ CLI УќСю kubectl set image deployment ЃЌПЩвдНЋИќаТЛиЙіЕНвдЧАЕФзДЬЌЁЃ
здЖЏЫѕЗХ

Kubernetes дЪаэЪЙгУ ReplicaSets Лђ Deployments ЪжЖЏЫѕЗХ PodЁЃШчЩЯЭМЫљЪОЃЌПЩвдЭЈЙ§ЯђВПЪ№ЬэМгСэвЛИіУћЮЊ
Horizontal Pod AutoscalerЃЈHPAЃЉЕФзЪдДРДРЉеЙДЫЙІФмЃЌвдИљОнЪЕМЪзЪдДЪЙгУЧщПіЖЏЬЌЫѕЗХ
PodЁЃHPA НЋЭЈЙ§зЪдДЖШСП API МрЪгУПИі Pod ЕФзЪдДЪЙгУЧщПіЃЌВЂЭЈжЊВПЪ№ЯргІЕиИќИФИББОМЏЕФИББОМЦЪ§ЁЃKubernetes
ЪЙгУИпМЖбгГйКЭЕЭМЖбгГйРДБмУтгЩгкФГаЉЧщПіЯТЦЕЗБзЪдДЪЙгУВЈЖЏЖјПЩФмЗЂЩњЕФВЈЖЏЁЃФПЧАЃЌHPA НіжЇГжЛљгк
CPU ЪЙгУТЪЕФРЉеЙЁЃШчЙћашвЊЃЌЛЙПЩвдЭЈЙ§ИљОнгІгУГЬађЕФаджЪздЖЈвхжИБъ API ВхШыздЖЈвхжИБъЁЃ
АќЙмРэ
Kubernetes ЩчЧјЦєЖЏСЫвЛИіЕЅЖРЕФЯюФПРДЪЕЪЉ Kubernetes ЕФЙмРэЦїЃЈPackage
ManagerЃЉЃЌУћЮЊ HelmЁЃKubernetes зЪдДЃЈШч deploymentЃЌserviceЃЌconfigmapЃЌingress
ЕШЃЉПЩвдЪЙгУ chart НјааФЃАхЛЏКЭДђАќЃЌдкАВзАЪБЪЙгУЪфШыВЮЪ§ЖдЫќУЧНјааХфжУЁЃИќживЊЕФЪЧЃЌЫќдЪаэдкЪЙгУвРРЕЙиЯЕЪЕЯжАВзААќЪБжигУЯжгаЭМБэЁЃ
Helm ПтПЩвдЭаЙмдкЙЋгаКЭЫНгадЦЛЗОГжаЃЌгУгкЙмРэгІгУГЬађЭМБэЁЃHelm ЬсЙЉСЫвЛИі CLIЃЌгУгкНЋРДздИјЖЈ
Helm repo ЕФгІгУГЬађАВзАЕНбЁЖЈЕФ Kubernetes ЛЗОГжаЁЃДѓМвПЩвддк Github
repo КЭ central Helm serverЁЊЁЊKubeapps Hub евЕНетИіжкЫљжмжЊЕФШэМўгІгУГЬађ
Helm ЭМБэЁЃ
Kubernetes НсКЯ Google ДѓЙцФЃдЫааШнЦїгІгУГЬађЪЎФъОбщЁЃФПЧАЃЌЫќвбОБЛзюДѓЕФЙЋгадЦЙЉгІЩЬКЭММЪѕЬсЙЉЩЬЫљВЩгУЁЃдкзЋаДБОЮФЪБЃЌЫќе§дкБЛИќЖрЕФШэМўЙЉгІЩЬКЭЦѓвЕЫљНгЪмЁЃKubernetes
дк 2015 ФъПЊдДВЂбмЩњГі Cloud Native Computing Foundation ЃЈCNCFЃЉЃЌзюНќГЩЮЊЛљН№ЛсЦьЯТЪзИіБЯвЕЕФЯюФПЁЃCNCF
вВПЊЪМећКЯШнЦїЩњЬЌЯЕЭГвдМАЦфЫћгыШнЦїЯрЙиЕФЯюФПЃЌШч CNIЃЌContainerdЃЌEnvoy ЃЌFluentdЃЌgRPCЃЌJaggerЃЌLinkerdЃЌPrometheusЃЌrkt
КЭ VitessЁЃKubernetes жЎЫљвдЪмЕНИїДѓзщжЏЕФЛЖгКЭШЯПЩЃЌЦфЙиМќдвђЪзЯШЪЧЫќЕФЭъУРЩшМЦЃЌЦфДЮОЭЪЧЦфПЊдДЕФЬиадЁЂгывЕНчСьафЕФКЯзїЕФШШЧщвдМАЪМжеЖдДДвтКЭЙБЯзБЃГжПЊЗХЕФЬЌЖШЁЃ |








