| 编辑推荐: |
| 本文来自于ju.outofmemory.cn,在docker
和 kubernetes 中怎么使用GPU资源呢?文章从多个方面讲解,希望可以为大家答疑解惑。 |
|
伴随着人工智能、机器学习、深度学习等技术的火热,GPU近年来也得到了快速的发展。GPU
可以大大加快深度学习任务的运行速度。而像 Tensflow 这样的框架的出现和应用更是离不开对GPU资源的依赖。同时,GPU资源又是十分昂贵的,需要尽可能提高
GPU 资源的利用率。为了解决上述问题,我们利用 Kubernetes 将 GPU 资源聚合成资源池来实现统一管理,并借用
Docker 交付深度学习的运行时环境。
当前 kubernetes 中还只支持 Nvidia GPU。所以,本文以 Nvidia GPU
来进行说明。
GPU in Docker
docker 本身并不原生支持GPU,但是使用docker的现有功能可以对GPU的使用进行支持。
docker run \
--device /dev/nvidia0:/dev/nvidia0 \
--device /dev/nvidiactl:/dev/nvidiactl \
--device /dev/nvidia-uvm:/dev/nvidia-uvm \
-v /usr/local/nvidia:/usr/local/nvidia \
-it --privileged nvidia/cuda |
如上所述,通过 --device 来指定挂载的GPU设备,通过 -v 来将宿主机上的 nvidia
gpu 的命令行工具和相关的依赖库挂载到容器种。这样,在容器中就可以看到和使用宿主机上的GPU设备了。
这样使用,对于GPU的可用性(哪些GPU是空闲的等)需要人为的判断,效率很低。为了提高Nvidia
GPU在 docker 中的易用性, Nvidia 通过对原生docker的封装实现了自己的 nvidia-docker
工具。
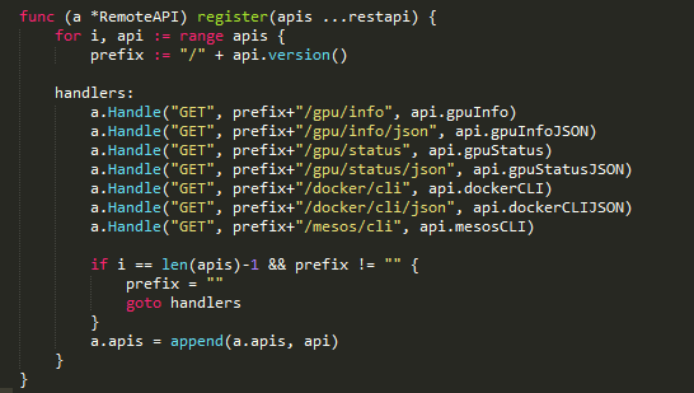
nvidia-docker 对于使用GPU资源的docker容器支持的层次关系
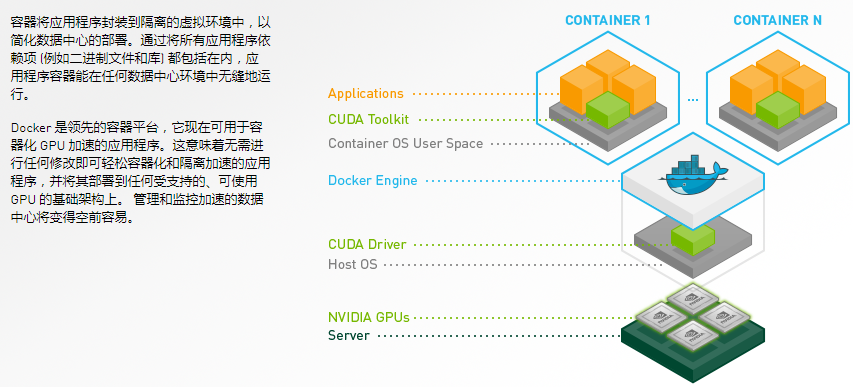
nvidia-docker 的出现使得 docker 对于 GPU 资源的使用更加容易,用户不用再去关心需要挂载哪些设备、哪块GPU卡。nvidia-docker
将这些逻辑都给隐藏掉了,用户像使用普通容器一样。截止到目前 nvidia-docker 官方经过了两次大版本的迭代,
nvidia-docker 和 nvidia-docker2。nvidia-docker2在 nvidia-docker的基础上功易用性和架构层面做了更多的优化。那么,我们来看下这两个版本的使用。
nvidia-docker

2017 年 2月19日,nvidia 发布了 nvidia-docker1.0.0 版本。在1.0.0版本里面
nvidia-docker 有两部分组成: nvidia-docker 和 nvidia-docker-plugin。
nvidia-docker是命令行工具
它兼容原生 docker 的所有命令。
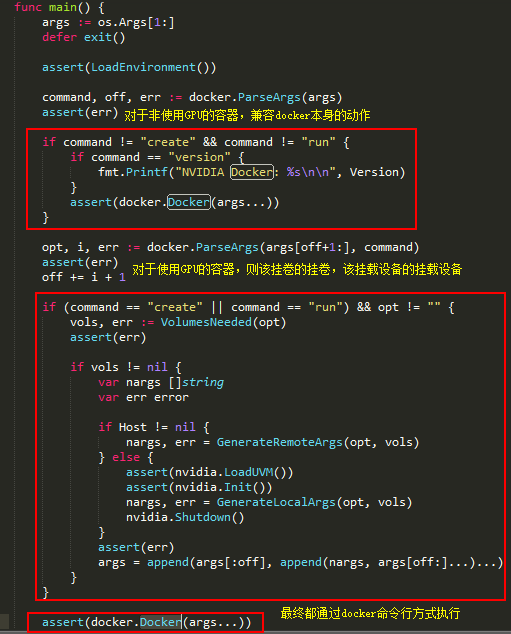
Nvidia-docker-plugin
它 是nvidia-docker 的核心,基本所有的工作(Nvidia设备、GPU卡可用性、库等的管理)都是它来完成的。看下都是干了哪些事。
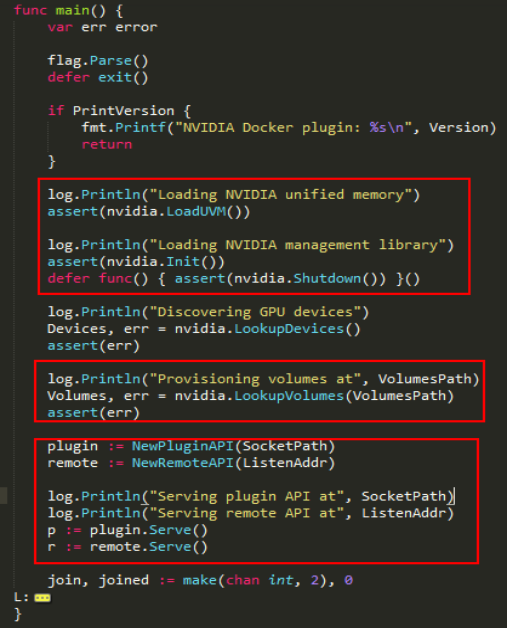
这是nvidia-docker-plugin的入口,从这里我们可以看到它做了这么几件事:加载nvidia-uvm内核模块、加载nvidia管理库、找出所有GPU设备、准备卷,最后启动两个server,一个是监听在本地unix
socket上,作为docker的plugin;还有一个是监听在3476端口的HTTP接口服务。
模块加载
Nvidia UVM 内核模块

NVML 管理库加载
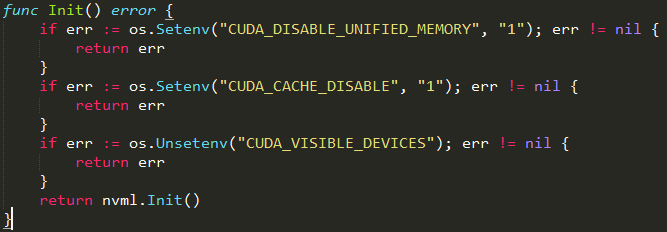
这里有几个环境变量需要在镜像里面设置,各自的功能参考:
cuda unified memory
设备的管理
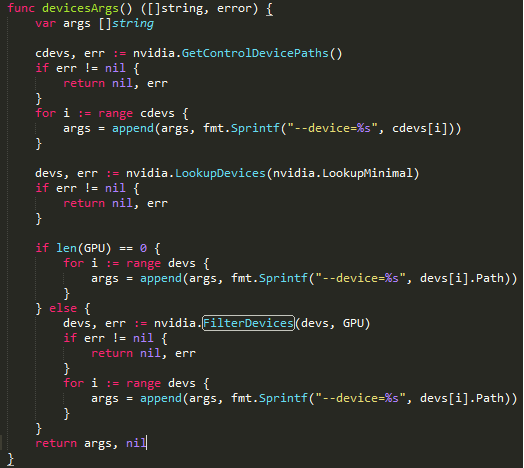
这里主要是完成对容器启动时设备参数的组装。
cdevs 指的是

devs 指的是
GPU 参数指的是指定需要哪些GPU卡,通过环境变量NV_GPU 来指定。
| V_GPU=1 nvidia-docker
run --rm nvidia/cuda nvidia-smi |
卷的管理
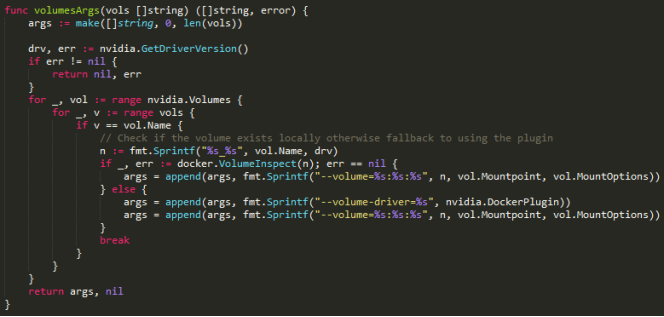
这里主要是完成对容器启动时卷参数的组装。
默认在启动 nvidia-docker 的时候,nvidia-docker-plugin 会创建1个卷,如下所示:
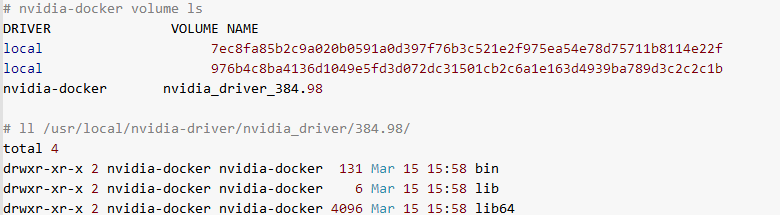
nvidia_driver_384.98 是在我的GPU机器上生成的,其中384.98后缀,是本地GPU卡能支持的驱动版本,它会自动获取。该版本信息可以通过
nvidia-detect -v 命令来获取。在该卷下会有bin、lib、lib64三个目录,bin存放的是nvidia相关命令工具,
lib一般是空的,lib64存放的是一堆nvidia的动态链接库。这些都是需要通过卷的方式挂载到容器中的。
也可以通过命令行手动创建该volume
| docker volume
create --driver =nvidia-docker --name=nvidia_driver_$(modinfo
-F version nvidia) |
HTTP接口
例如:
| # curl http://localhost:3476/docker/cli
--volume-driver=nvidia-docker --volume =nvidia_driver_384.98:/usr/local/nvidia:ro
--device=/dev/nvidiactl --device=/dev/nvidia-uvm
--device =/dev/nvidia-uvm-tools --device=/dev/nvidia0 |
可以通过下面的接口获取真正在run容器时需要的参数。 拿到这些参数后,可以直接run一个使用GPU资源的容器。
docker run -it
--rm \
--volume-driver=nvidia-docker \
--volume=nvidia_driver_384.98:/usr/local/nvidia:ro
\
--device=/dev/nvidiactl \
--device=/dev/nvidia-uvm \
--device=/dev/nvidia-uvm-tools \
--device=/dev/nvidia0 \
nvidia/cuda nvidia-smi |
其它接口不再解释,一看就知道是干什么的。
docker、nvidia-docker、nvidia-docker-plugin
的关系:
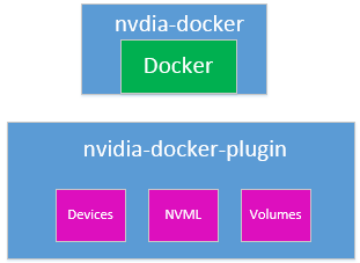
nvidia-docker2
nvidia-docker1.0.0的使用在一定程度上简化了docker对于GPU的使用,但是还不够完美,因为还是有一些工作需要我们人为去搞定。为了更加的好用和支持更多的适用场景nvidia发布了nvidia-docker2。
在nvidia-docker2中nvidia-docker命令行被简化,以shell脚本的形式进行了封装,nvidia-docker-plugin
被废弃,改为通过在 docker runc 中添加 hook 的方式进行。

将对UVM、NVML、devices等的管理提出来形成了libnvidia-container库。
它们之间的关系简单描述:
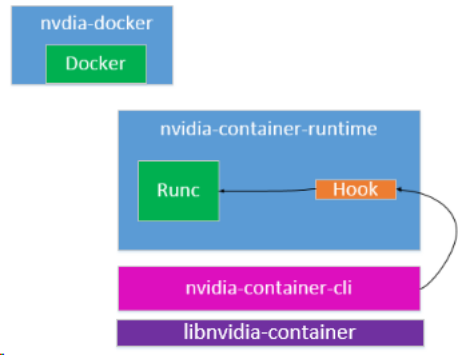
更多细节参考:
nvidia-container-runtime
libnvidia-container
GPU in Kubernetes
kubernetes 对于 GPU 的支持截止到 1.9 版本,算是经历了3个阶段:
kubernetes 1.3 版本开始支持GPU,但是只支持单个 GPU卡;
kubernetes 1.6 版本开始支持对多个GPU卡的支持;
kubernetes 1.8 版本以 device plugin 方式提供对GPU的支持。
kubernetes 1.3
k8s 1.3中开始提供了对Nvidia GPU的支持,增加了一个针对Nvidia品牌GPU的α特性:alpha.kubernetes.io/nvidia-gpu。
在kubernetes1.3版本中,GPU还是个α特性,一个node上只支持1块GPU卡。即使node上安装有多块GPU卡,也只能使用第一块GPU卡(程序硬编码实现)。
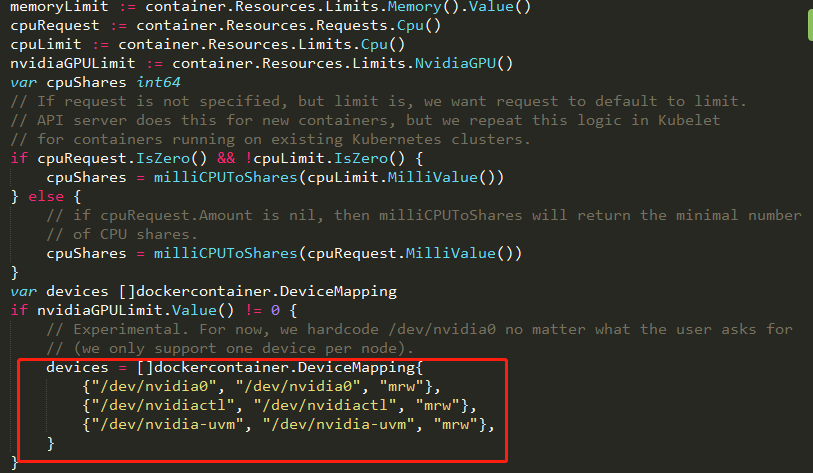
Kubernetes1.3新特性:支持GPU
kubernetes 1.6
在kubernetes1.6开始更全面的提供了对Nvidia品牌GPU的支持,会自动识别节点上的所有Nvidia
GPU,并进行调度。
Kubernetes1.6新特性:全面支持多颗GPU
kubernetes 1.8
Kubernetes 1.8~1.9,通过device plugin方式实现对GPU资源的使用和管理。
需要结合 nvidia-docker2 使用。k8s-device-plugin 也是由 nvidia
提供,在kubernetes中可以DaemonSet方式运行。kubernetes 通过 k8s-device-plugin
获取每个Node上GPU的信息,根据这些信息对GPU资源进行管理和调度。
Schedule GPUs
k8s-device-plugin
nvidia-docker2中对cuda库版本有要求,且和公司内业务使用的版本不兼容,所以,目前我们生产环境使用的还是nvidia-docker
1.0.1 版本。基于 k8s-device-plugin 和 nvidia-docker2版本等业务有高版本cuda需求的使用再配套使用。
总结
以上便是 GPU 在 Docker 和 Kuernetes 中的使用。 |








