| ±ύΦ≠ΆΤΦω: |
±ΨΈΡΫΪΫι…ή‘ΤΦΤΥψάζ Ζ―ίΫχ”κΜυ±Ψ‘≠άμΘ§ λœΛLinuxΒΡΜυ¥Γ÷Σ ΕΘ§ ΐΨί÷––ΡΚΆΆχ¬γΜυ¥Γ÷Σ ΕΘ§ΝΥΫβΦΤΥψ–ιΡβΜ·Θ§Άχ¬γ–ιΡβΜ·Θ§‘ΤΤΫΧ®Θ§»ίΤςΤΫΧ®Θ§Μυ”ΎHadoopΚΆSparkΝΥΫβ¥σ ΐΨίΤΫΧ®Θ§œΘΆϊΡήΗχ¥σΦ“¥χά¥ΤτΖΔΓΘ
±ΨΈΡά¥Ή‘ΈΔ–≈ΙΪ÷ΎΚ≈Θ§”…Alice±ύΦ≠ΓΔΆΤΦωΓΘ |
|
“ΜΓΔΦήΙΙΒΡ»ΐΗωΈ§Ε»ΚΆΝυΗω≤ψΟφ

1.1ΓΔ»ΐ¥σΦήΙΙ
‘ΎΜΞΝΣΆχ ±¥ζΘ§“ΣΉωΚΟ“ΜΗωΚœΗώΒΡ‘ΤΦήΙΙ ΠΘ§–η“Σ λœΛ»ΐ¥σΦήΙΙΓΘ
ΒΎ“ΜΗω «ITΦήΙΙΘ§Τδ ΒΨΆ «ΦΤΥψΘ§Άχ¬γΘ§¥φ¥ΔΓΘ’β «‘ΤΦήΙΙ ΠΒΡΜυ±ΨΙΠΘ§“≤ «Ήν¥ΪΆ≥ΒΡ‘ΤΦήΙΙ Π”ΠΗΟ Ήœ»’ΤΈ’ΒΡ≤ΩΖ÷Θ§ΝΦΚΟ…ηΦΤΒΡITΦήΙΙΘ§Ω…“‘ΫΒΒΆCAPEXΚΆOPEXΘ§Φθ«α‘ΥΈ§ΒΡΗΚΒΘΓΘ ΐΨί÷––ΡΘ§–ιΡβΜ·Θ§‘ΤΤΫΧ®Θ§»ίΤςΤΫΧ®ΕΦ τ”ΎITΦήΙΙΒΡΖΕ≥κΓΘ
ΒΎΕΰΗω «”Π”ΟΦήΙΙΘ§ΥφΉ≈”Π”Ο¥”¥ΪΆ≥”Π”ΟœρΜΞΝΣΆχ”Π”ΟΉΣ–ΆΘ§ΫωΫωΗψΕ®Ή ‘¥≤ψΟφΒΡΒ·–‘ΜΙ≤ΜΙΜΘ§≥Θ≥ΘΜα≥ωœ÷¥¥Ϋ®ΝΥ¥σ≈ζΜζΤςΘ§»‘»Μ≥≈≤ΜΉΓΗΏ≤ΔΖΔΝςΝΩΓΘ“ρΕχΜυ”ΎΈΔΖΰΈώΒΡΜΞΝΣΆχΦήΙΙΘ§‘Ϋά¥‘Ϋ≥…ΈΣ‘ΤΦήΙΙ ΠΥυ±Ί–ηΒΡΦΦΡήΓΘΝΦΚΟ…ηΦΤΒΡ”Π”ΟΦήΙΙΘ§Ω…“‘ Βœ÷ΩλΥΌΒϋ¥ζΚΆΗΏ≤ΔΖΔΓΘ ΐΨίΩβΘ§ΜΚ¥φΘ§œϊœΔΕ”Ν–Β»PaaSΘ§“‘ΦΑΜυ”ΎSpringCloudΚΆDubboΒΡΈΔΖΰΈώΩρΦήΘ§ΕΦ τ”Ύ”Π”ΟΦήΙΙΒΡΖΕ≥κΓΘ
ΒΎ»ΐΗω « ΐΨίΦήΙΙΘ§ ΐΨί≥…ΈΣ»ΥΙΛ÷«Ρή ±¥ζΒΡΚΥ–ΡΉ ≤ζΘ§‘ΎΉωΜΞΝΣΆχΜ·ΉΣ–ΆΒΡΆ§ ±Θ§ΆυΆυΫχ––ΒΡ“≤ « ΐΉ÷Μ·ΉΣ–ΆΘ§≤Δ”–’Ϋ¬‘ΒΡΫχ–– ΐΨί ’Φ·Θ§’βΨΆ–η“Σ‘ΤΦήΙΙ ΠΆ§ ±”÷¥σ ΐΨίΥΦΈ§ΓΘ”–“β ΕΒΡΫ®…ηΆ≥“ΜΒΡ ΐΨίΤΫΧ®Θ§≤ΔΗχ”η ΐΨίΫχ–– ΐΉ÷Μ·‘Υ”ΣΓΘΥ―Υς“ΐ«φΘ§HadoopΘ§SparkΘ§»ΥΙΛ÷«ΡήΕΦ τ”Ύ ΐΨίΦήΙΙΒΡΖΕ≥κΓΘ
1.2ΓΔΝυΗω≤ψΟφ
…œΟφΒΡ»ΐΗωΈ§Ε» «¥”»ΥΒΡΫ«Ε»≥ωΖΔΒΡΘ§»γΙϊ¥”œΒΆ≥ΒΡΫ«Ε»≥ωΖΔΘ§ΦήΙΙΖ÷ΝυΗω≤ψ¥ΈΓΘ

ΒΎ“ΜΗω≤ψ¥Έ «Μυ¥Γ…η ©≤ψΘ§‘Ύ ΐΨί÷––ΡάοΟφΘ§Μα”–¥σΝΩΒΡΜζΦήΘ§¥σΝΩΒΡΖΰΈώΤςΘ§≤ΔΆ®ΙΐΫΜΜΜΜζΚΆ¬Ζ”…ΤςΫΪΖΰΈώΤςΝ§Ϋ”Τπά¥Θ§”–ΒΡ”Π”Οάΐ»γOracle «–η“Σ≤Ω π‘ΎΈοάμΜζ…œΒΡΓΘΈΣΝΥΙήάμΒΡΖΫ±ψΘ§‘ΎΈοάμΜζ÷°…œΜα≤Ω π–ιΡβΜ·Θ§άΐ»γVmwareΘ§Ω…“‘ΫΪΕ‘”ΎΈοάμΜζΗ¥‘”ΒΡ‘ΥΈ§ΦρΜ·ΈΣ–ιΡβΜζΝιΜνΒΡ‘ΥΈ§ΓΘ–ιΡβΜ·≤…»ΓΒΡ‘ΥΈ§ΖΫ ΫΕύ «”…‘ΥΈ§≤ΩΟ≈Ά≥“ΜΙήάμΘ§Β±“ΜΗωΙΪΥΨάοΟφ≤ΩΟ≈Ζ«≥ΘΕύΒΡ ±ΚρΘ§ΆυΆυ“Σ“ΐ»κΝΦΚΟΒΡΉβΜßΙήάμΘ§Μυ”ΎQuotaΚΆQoSΒΡΉ ‘¥ΩΊ÷ΤΘ§Μυ”ΎVPCΒΡΆχ¬γΙφΜ°Β»Θ§ Βœ÷¥”‘ΥΈ§Φ·÷–ΙήάμΒΫΉβΜßΉ‘÷ζ Ι”ΟΡΘ ΫΒΡΉΣΜΜΘ§Ά–…ζ”ΎΙΪ”–‘ΤΒΡOpenStack‘Ύ’βΖΫΟφΉωΒΡ «±»ΫœΚΟΒΡΓΘΥφΉ≈”Π”ΟΦήΙΙ‘Ϋά¥‘Ϋ÷Ί“ΣΘ§Ε‘”Ύ±ξΉΦΜ·ΫΜΗΕΚΆΒ·–‘…λΥθΒΡ–η«σ‘Ϋά¥‘Ϋ¥σΘ§»ίΤςΉνΈΣ»μΦΰΫΜΗΕΒΡΦ·ΉΑœδΘ§Ω…“‘ Βœ÷Μυ”ΎΨΒœώΒΡΩγΜΖΨ≥«®“ΤΘ§Kubernetes «»ίΤςΙήάμΤΫΧ®ΒΡ ¬ Β±ξΉΦΓΘ
ΒΎΕΰΗω≤ψ¥Έ « ΐΨί≤ψΘ§“≤Φ¥“ΜΗω”Π”ΟΒΡ÷–Ψϋ¥σ”ΣΘ§»γΙϊ «¥ΪΆ≥”Π”ΟΘ§Ω…ΡήΜα Ι”ΟOracleΘ§≤Δ Ι”Ο¥σΝΩΒΡ¥φ¥ΔΙΐ≥ΧΘ§”–¥σΝΩΒΡ±μΝΣΚœ≤ι―·Θ§≥…±Ψ“≤ΆυΆυ±»ΫœΗΏΓΘΒΪ «Ε‘”ΎΗΏ≤ΔΖΔΒΡΜΞΝΣΆχ”Π”ΟΘ§–η“ΣΫχ––ΈΔΖΰΈώΒΡ≤πΖ÷Θ§ ΐΨίΩβ ΒάΐΜα±»ΫœΕύΘ§ Ι”ΟΩΣ‘¥ΒΡMysql «≥ΘΦϊΒΡ―Γ‘ώΘ§¥σΝΩΒΡ¥φ¥ΔΙΐ≥ΧΚΆΝΣΚœ≤ι―·ΆυΆυΜα ΙΒΟΈΔΖΰΈώΈόΖ®≤πΖ÷Θ§–‘ΡήΜα±»Ϋœ≤νΘ§“ρΕχ–η“ΣΖ≈ΒΫ”Π”Ο≤ψ»ΞΉωΗ¥‘”ΒΡ“ΒΈώ¬ΏΦ≠Θ§ ΐΨίΩβ±μΚΆΥς“ΐΒΡ…ηΦΤΖ«≥Θ÷Ί“ΣΓΘΒ±≤ΔΖΔΝΩ±»Ϋœ¥σΒΡ ±ΚρΘ§–η“Σ Βœ÷Καœρά©’ΙΘ§ΨΆ–η“ΣΜυ”ΎΖ÷≤Φ Ϋ ΐΨίΩβΘ§“≤ «–η“ΣΜυ”ΎΒΞΩβΝΦΚΟΒΡ±μΚΆΥς“ΐ…ηΦΤΓΘΕ‘”ΎΫαΙΙ±»ΫœΝιΜνΒΡ ΐΨίΘ§Ω…“‘ Ι”ΟMongoDB ΐΨίΩβΘ§Καœρά©’ΙΡήΝΠ±»ΫœΚΟΓΘΕ‘”Ύ¥σΝΩΒΡΝΣΚœ≤ι―·–η«σΘ§Ω…“‘ Ι”ΟElasticSearch÷°άύΒΡΥ―Υς“ΐ«φά¥ΉωΘ§ΥΌΕ»ΩλΘ§ΗϋΦ”ΝιΜνΓΘ
ΒΎ»ΐΗω≤ψ¥Έ «÷–ΦδΦΰ≤ψΘ§“ρΈΣ ΐΨίΩβ≤ψΆυΆυ–η“Σ±Θ÷Λ ΐΨίΒΡ≤ΜΕΣ ß“‘ΦΑ“Μ–© ¬ΈώΘ§“ρΕχ≤ΔΖΔ–‘Ρή≤ΜΩ…ΡήΖ«≥Θ¥σΘ§Υυ“‘Έ“Ο«Ψ≠≥ΘΥΒΘ§ ΐΨίΩβ «÷–Ψϋ¥σ”ΣΘ§≤ΜΡήΥυ”–ΒΡ«κ«σΕΦΒΫ’βάοά¥Θ§“ρΕχ–η“Σ“Μ≤ψΜΚ¥φ≤ψΘ§”Οά¥άΙΫΊ¥σ≤ΩΖ÷ΒΡ»»Βψ«κ«σΓΘMemcached ΚœΉωΦρΒΞΒΡkey-value¥φ¥ΔΘ§ΡΎ¥φ Ι”Ο¬ ±»ΫœΗΏΘ§Εχ«“”…”Ύ «ΕύΚΥ¥ΠάμΘ§Ε‘”Ύ±»Ϋœ¥σΒΡ ΐΨίΘ§–‘ΡήΫœΚΟΓΘΒΪ «»±Βψ“≤±»ΫœΟςœ‘Θ§Memcached―œΗώά¥Ϋ≤ΟΜ”–Φ·»ΚΜζ÷ΤΘ§Καœρά©’ΙΆξ»ΪΩΩΩΆΜßΕΥά¥ Βœ÷ΓΘΝμΆβMemcachedΈόΖ®≥÷ΨΟΜ·Θ§“ΜΒ©Ι“ΝΥ ΐΨίΨΆΕΦΕΣ ßΝΥΘ§»γΙϊœκ Βœ÷ΗΏΩ…”ΟΘ§“≤ «–η“ΣΩΆΜßΕΥΫχ––ΥΪ–¥≤≈Ω…“‘ΓΘRedisΒΡ ΐΨίΫαΙΙ±»ΫœΖαΗΜΘ§ΧαΙ©≥÷ΨΟΜ·ΒΡΙΠΡήΘ§ΧαΙ©≥… λΒΡ÷ς±ΗΆ§≤ΫΘ§Ι ’œ«–ΜΜΒΡΙΠΡήΘ§¥”Εχ±Θ÷ΛΝΥΗΏΩ…”Ο–‘ΓΘΝμΆβΈΔΖΰΈώ≤πΖ÷“‘ΚσΘ§”– ±Κρ¥Πάμ“ΜΗωΕ©ΒΞ“ΣΨ≠ΙΐΖ«≥ΘΕύΒΡΖΰΈώΘ§¥ΠάμΙΐ≥ΧΜα±»Ϋœ¬ΐΘ§’βΗω ±Κρ–η“Σ Ι”ΟœϊœΔΕ”Ν–Θ§»ΟΖΰΈώ÷°ΦδΒΡΒς”Ο±δ≥…Ε‘”ΎœϊœΔΒΡΕ©‘ΡΘ§ Βœ÷“λ≤Ϋ¥ΠάμΓΘRabbitMQΚΆKafka «≥Θ”ΟΒΡœϊœΔΕ”Ν–Θ§Β± ¬Φΰ±»Ϋœ÷Ί“ΣΒΡ ±ΚρΘ§ΜαΫαΚœ ΐΨίΩβ Βœ÷Ω…ΩΩœϊœΔΕ”Ν–ΓΘ
ΒΎΥΡΗω≤ψ¥Έ «Μυ¥ΓΖΰΈώ≤ψΘ§”–ΒΡ ±Κρ≥…ΈΣ÷–Χ®≤ψΘ§ΫΪΆ®”ΟΒΡΡήΝΠ≥ιœσΈΣΖΰΈώΕ‘ΆβΧαΙ©‘≠Ή”Μ·Ϋ”ΩΎΓΘ’β―υ…œ≤ψΩ…“‘ΗυΨί“ΒΈώ–η«σΘ§Ά®ΙΐΝιΜνΒΡΉιΚœ’β–©‘≠Ή”Μ·Ϋ”ΩΎΘ§ΝιΜνΒΡ”ΠΕ‘“ΒΈώ–η«σΒΡ±δΜ·Θ§ Βœ÷ΡήΝΠΒΡΗ¥”ΟΘ§“‘ΦΑ ΐΨίΒΡΆ≥“ΜΙήάμΘ§άΐ»γ”ΟΜß ΐΨίΘ§÷ßΗΕ ΐΨίΘ§≤ΜΜαΖ÷…ΔΒΫΗςΗω”Π”Ο÷–ΓΘΝμΆβΜυ¥ΓΖΰΈώ≤ψ≥ΤΈΣ”Π”ΟΚΆ ΐΨίΩβΚΆΜΚ¥φΒΡ“ΜΗωΖ÷ΫγœΏΘ§≤Μ”ΠΗΟΥυ”–ΒΡ”Π”ΟΕΦ÷±Ϋ”Ν§ ΐΨίΩβΘ§“ΜΒ©≥ωœ÷Ζ÷ΩβΖ÷±μΘ§ ΐΨίΩβ«®“ΤΘ§ΜΚ¥φ―Γ–ΆΗΡ±δΒ»Θ§”ΑœλΟφΜαΖ«≥Θ¥σΘ§ΦΗΚθΈόΖ®÷¥––ΓΘ»γΙϊΫΪ’β–©ΒΉ≤ψΒΡ±δΗϋάΙΫΊ‘ΎΜυ¥ΓΖΰΈώ≤ψΘ§…œ≤ψΫωΫω Ι”ΟΜυ¥ΓΖΰΈώ≤ψΒΡΫ”ΩΎΘ§’β―υΒΉ≤ψΒΡ±δΜ·ΜαΕ‘…œ≤ψΆΗΟςΘ§Ω…“‘÷π≤Ϋ―ίΫχΓΘ
ΒΎΈεΗω≤ψ¥Έ «“ΒΈώΖΰΈώ≤ψΘ§Μρ’ΏΉιΚœΖΰΈώ≤ψΘ§¥σ≤ΩΖ÷ΒΡ“ΒΈώ¬ΏΦ≠ΕΦ «‘Ύ’βΗω≤ψΟφ Βœ÷Θ§“ΒΈώ¬ΏΦ≠±»ΫœΟφœρ”ΟΜßΘ§“ρΕχΜαΨ≠≥ΘΗΡ±δΘ§Υυ“‘–η“ΣΉιΚœΜυ¥ΓΖΰΈώΒΡΫ”ΩΎΫχ–– Βœ÷ΓΘ‘Ύ’β“Μ≤ψΘ§ΜαΨ≠≥ΘΫχ––ΖΰΈώΒΡ≤πΖ÷Θ§ Βœ÷ΩΣΖΔΕάΝΔΘ§…œœΏΕάΝΔΘ§ά©»ίΕάΝΔΘ§»ί‘÷ΫΒΦΕΕάΝΔΓΘΈΔΖΰΈώΒΡ≤πΖ÷≤Μ”ΠΗΟ «“ΜΗω‘ΥΕ·Θ§Εχ”ΠΗΟ «“ΜΗω”ωΒΫώνΚœΆ¥ΒψΒΡ ±ΚρΘ§≤ΜΕœΫβΨωΘ§≤ΜΕœ―ίΫχΒΡ“ΜΗωΙΐ≥ΧΓΘΈΔΖΰΈώ≤πΖ÷÷°ΚσΘ§”– ±Κρ–η“ΣΆ®ΙΐΖ÷≤Φ Ϋ ¬ΈώΘ§±Θ÷ΛΕύΗω≤ΌΉςΒΡ‘≠Ή”–‘Θ§“≤ «‘ΎΉιΚœΖΰΈώ≤ψά¥ Βœ÷ΒΡΓΘ
ΒΎΝυΗω≤ψ¥Έ «”ΟΜßΫ”ΩΎ≤ψΘ§“≤Φ¥Ε‘÷’ΕΥΩΆΜß≥ œ÷≥ωά¥ΒΡΫγΟφΚΆAPPΘ§ΒΪ «»¥≤ΜΫωΫω «ΫγΟφ’βΟ¥ΦρΒΞΓΘ’β“Μ≤ψ”– ±Κρ≥ΤΈΣΫ”»κ≤ψΓΘ‘Ύ’β“Μ≤ψΘ§Ε·Χ§Ή ‘¥ΚΆΨ≤Χ§Ή ‘¥”ΠΗΟΖ÷άκΘ§Ψ≤Χ§Ή ‘¥”ΠΗΟ‘ΎΫ”»κ≤ψΉωΜΚ¥φΘ§ Ι”ΟCDNΫχ––ΜΚ¥φΓΘ“≤”ΠΗΟUIΚΆAPIΖ÷άκΘ§ΫγΟφ”ΠΗΟΆ®ΙΐΉιΚœAPIΫχ–– ΐΨίΤ¥ΉΑΓΘAPIΜαΆ®ΙΐΆ≥“ΜΒΡAPIΆχΙΊΫχ––Ά≥“ΜΒΡΙήάμΚΆ÷ΈάμΘ§“ΜΖΫΟφΚσΕΥΉιΚœΖΰΈώ≤ψΒΡ≤πΖ÷Ε‘APP «ΆΗΟςΒΡΘ§“ΜΖΫΟφΒ±≤ΔΖΔΝΩ±»Ϋœ¥σΒΡ ±ΚρΘ§Ω…“‘‘Ύ’β“Μ≤ψ Βœ÷œόΝςΚΆΫΒΦΕΓΘ
ΈΣΝΥ÷ß≥≈’βΝυΗω≤ψ¥ΈΘ§‘Ύ…œΆΦΒΡΉσ≤ύ «“Μ–©ΙΪΙ≤ΡήΝΠΓΘ
≥÷–χΦ·≥…ΚΆ≥÷–χΖΔ≤Φ «±Θ÷ΛΈΔΖΰΈώ≤πΖ÷Ιΐ≥Χ÷–ΒΡΩλΥΌΒϋ¥ζΘ§“‘ΦΑ±δΗϋΚσ±Θ÷ΛΙΠΡή≤Μ±δΒΡΘ§≤Μ“ΐ»κ–¬ΒΡBugΓΘ
ΖΰΈώΖΔœ÷ΚΆΖΰΈώ÷Έάμ «ΈΔΖΰΈώ÷°ΦδΜΞœύΒΡΒς”ΟΘ§“‘ΦΑΒς”ΟΙΐ≥Χ÷–≥ωœ÷“λ≥Θ«ιΩωœ¬ΒΡ»έΕœΘ§œόΝςΘ§ΫΒΦΕ≤Ώ¬‘ΓΘ
¥σ ΐΨίΚΆ»ΥΙΛ÷«Ρή «Ά®Ιΐ ’Φ·ΗςΗω≤ψΟφΒΡ ΐΨίΘ§άΐ»γ”ΟΜßΖΟΈ ΐΨίΘ§”ΟΜßœ¬ΒΞ ΐΨίΘ§ΩΆΖΰ―·Έ ΐΨίΒ»Θ§ΫαΚœΆ≥“ΜΒΡ÷–Χ®Θ§Ε‘ ΐΨίΫχ––Ζ÷ΈωΘ§ Βœ÷÷«ΡήΆΤΦωΓΘ
ΦύΩΊ”κAPM «Μυ¥Γ…η ©ΒΡΦύΩΊΚΆ”Π”ΟΒΡΦύΩΊΘ§ΖΔœ÷Ή ‘¥≤ψΟφΒΡΈ Χβ“‘ΦΑ”Π”ΟΒς”ΟΒΡΈ ΧβΓΘ
ΉςΈΣ“ΜΗω‘ΤΦήΙΙ ΠΜΙ «ΚήΗ¥‘”ΒΡΘ§«ßάο÷°––Θ§ Φ”ΎΉψœ¬Θ§»ΟΈ“Ο«¬ΐ¬ΐά¥ΓΘ
ΕΰΓΔΝΥΫβ‘ΤΦΤΥψΒΡάζ Ζ―ίΫχ”κΜυ±Ψ‘≠άμ
‘Ύ“ΜΆΖ‘ζΫχ‘ΤΦΤΥψΒΡΆτ―σ¥σΚΘ÷°«ΑΘ§Έ“Ο«”ΠΗΟœ»”–“ΜΗω»ΪΟ≤ΒΡΝΥΫβΘ§”–»ΥΥΒΝΥΫβ“ΜΗω÷Σ ΕΒΡΤπΒψΘ§ΨΆ «ΝΥΫβΥϊΒΡάζ ΖΘ§“≤ΨΆ «÷ΣΒάΥϊ «»γΚΈ“Μ≤Ϋ“Μ≤ΫΒΫΫώΧλΒΡΘ§’β―υ»γ¥Υ≈”¥σΒΡ“ΜΗωΧεœΒΘ§Τδ Β «÷π≤ΫΦ”Ϋχά¥ΒΡΘ§’β―υΒΡ÷Σ ΕΧεœΒΕ‘Έ“Ο«ά¥ΥΒΘ§ΨΆ≤Μ «“ΜΗωάδ±υ±υΒΡ÷Σ ΕΆχΘ§Εχ «“ΜΗω”–―Σ”–»βΒΡ»ΥΘ§Έ“Ο«÷Μ“Σ―ΊΉ≈―ίΫχΒΡœΏΥςΘ§“Μ≤Ϋ“Μ≤ΫΟΰ«ε≥ΰΥϊΒΡΤΔΤχΨΆΩ…“‘ΝΥΓΘ
»γΚΈΑ―‘ΤΦΤΥψΫ≤ΒΡΆ®ΥΉ“ΉΕ°Θ§Έ“±Ψ»ΥΥΦΩΦΝΥΑκΧλΘ§Ήν÷’–¥œ¬ΝΥœ¬Οφ’βΤΣΈΡ’¬ΓΘ
÷’”Ύ”–»ΥΑ―‘ΤΦΤΥψΓΔ¥σ ΐΨίΚΆ»ΥΙΛ÷«ΡήΫ≤ΟςΑΉΝΥΘΓ
‘Ύ’βάοΘ§Έ“Α―ΚΥ–ΡΒΡ“ΣΒψ‘Ύ’βάο–¥“Μœ¬ΘΚ
ΒΎ“ΜΘΚ‘ΤΦΤΥψΒΡ±Ψ÷ « Βœ÷¥”Ή ‘¥ΒΫΦήΙΙΒΡ»ΪΟφΒ·–‘ΓΘΥυΈΫΒΡΒ·–‘ΨΆ « ±ΦδΝιΜν–‘ΚΆΩ’ΦδΝιΜν–‘Θ§“≤Φ¥œκ ≤Ο¥ ±Κρ“ΣΨΆ ≤Ο¥ ±Κρ“ΣΘ§œκ“ΣΕύ…ΌΨΆ“ΣΕύ…ΌΓΘ
Ή ‘¥≤ψΟφΒΡΒ·–‘“≤Φ¥ Βœ÷ΦΤΥψΓΔΆχ¬γΓΔ¥φ¥ΔΉ ‘¥ΒΡΒ·–‘ΓΘ’βΗωΙΐ≥ΧΨ≠άζΝΥ¥”ΈοάμΜζΘ§ΒΫ–ιΡβΜ·Θ§ΒΫ‘ΤΦΤΥψΒΡ“ΜΗω―ίΫχΙΐ≥ΧΓΘ

ΦήΙΙ≤ψΟφΒΡΒ·–‘“≤Φ¥ Βœ÷Ά®”Ο”Π”ΟΚΆΉ‘”–”Π”ΟΒΡΒ·–‘ά©’ΙΓΘΕ‘”ΎΆ®”ΟΒΡ”Π”ΟΘ§ΕύΦ·≥…ΈΣPaaSΤΫΧ®ΓΘΕ‘”ΎΉ‘ΦΚΒΡ”Π”ΟΘ§Ά®ΙΐΜυ”ΎΫ≈±ΨΒΡPuppet,
Chef, AnsibleΒΫΜυ”Ύ»ίΤςΨΒœώΒΡ»ίΤςΤΫΧ®CaaSΓΘ

ΒΎΕΰΘΚ¥σ ΐΨίΑϋΚ§ ΐΨίΒΡ ’Φ·Θ§ ΐΨίΒΡ¥Ϊ δΘ§ ΐΨίΒΡ¥φ¥ΔΘ§ ΐΨίΒΡ¥ΠάμΚΆΖ÷ΈωΘ§ ΐΨίΒΡΦλΥςΚΆΆΎΨρΒ»ΦΗΗωΙΐ≥ΧΓΘ

Β± ΐΨίΝΩΚή–Γ ±Θ§Κή…ΌΒΡΦΗΧ®ΜζΤςΨΆΡήΫβΨωΓΘ¬ΐ¬ΐΒΡΘ§Β± ΐΨίΝΩ‘Ϋά¥‘Ϋ¥σΘ§Ήν≈ΘΒΡΖΰΈώΤςΕΦΫβΨω≤ΜΝΥΈ Χβ ±Θ§‘θΟ¥ΑλΡΊΘΩ’β ±ΨΆ“ΣΨέΚœΕύΧ®ΜζΤςΒΡΝΠΝΩΘ§¥σΦ“Τκ–Ρ–≠ΝΠ“ΜΤπΑ―’βΗω ¬ΗψΕ®Θ§÷Ύ»Υ Α≤ώΜπ―φΗΏΓΘ
ΒΎ»ΐΘΚ»ΥΙΛ÷«ΡήΨ≠άζΝΥΜυ”ΎΉ®Φ“œΒΆ≥ΒΡΦΤΜ°Ψ≠ΦΟΘ§Μυ”ΎΆ≥ΦΤΒΡΚξΙέΒςΩΊΘ§Μυ”Ύ…ώΨ≠Άχ¬γΒΡΈΔΙέΨ≠ΦΟ―ß»ΐΗωΫΉΕΈΓΘ

»ΐΓΔΩΣ‘¥»μΦΰ «ΫχΫΉΒΡάϊΤς
ΦήΙΙ Π≥ΐΝΥ“Σ’ΤΈ’¥σΒΡΦήΙΙΚΆάμ¬έ÷°ΆβΘ§÷ΗΒΦ¬δΒΊ“≤ «±Ί±ΗΒΡΦΦΡήΘ§ΥυΈΫΦ»“ΣΕ°…ηΦΤΡΘ ΫΘ§“≤“ΣΕ°¥ζ¬κΓΘΡ«¥”ΡΡάο»Ξ―ßœΑ’β–©ΝΦΚΟΒΡΘ§”–ΫηΦχ“β“εΒΡΘ§Ω…“‘¬δΒΊΒΡΦήΙΙ ΒΦυΡΊΘΩ
’βΗω άΫγ…œΜΙ «”–ΚήΕύ”–«ιΜ≥ΒΡ¥σ≈ΘΒΡΘ§”»Τδ «≥Χ–ρ‘±άοΟφΘ§ΥϊΟ«œ≤ΜΕΉω“ΜΦΰ ≤Ο¥ ¬«ιΡΊΘΩΩΣ‘¥ΓΘΚήΕύ»μΦΰΕΦ «”–±’‘¥ΨΆ”–ΩΣ‘¥Θ§‘¥ΨΆ «‘¥¥ζ¬κΓΘΒ±Ρ≥Ηω»μΦΰΉωΒΡΚΟΘ§Υυ”–»ΥΕΦΑ°”ΟΘ§’βΗω»μΦΰΒΡ¥ζ¬κΡΊΘ§Έ“Ζβ±’Τπά¥÷Μ”–Έ“ΙΪΥΨ÷ΣΒάΘ§ΤδΥϊ»Υ≤Μ÷ΣΒάΘ§»γΙϊΤδΥϊ»Υœκ”Ο’βΗω»μΦΰΘ§ΨΆ“ΣΗΕΈ“«°Θ§’βΨΆΫ–±’‘¥ΓΘΒΪ « άΫγ…œΉή”–“Μ–©¥σ≈ΘΩ¥≤ΜΙΏ«°ΕΦ»Ο“ΜΦ“Ή§ΝΥ»ΞΓΘ¥σ≈ΘΟ«ΨθΒΟΘ§’βΗωΦΦ θΡψΜαΈ““≤ΜαΘ§ΡψΡήΩΣΖΔ≥ωά¥Θ§Έ““≤ΡήΘ§Έ“ΩΣΖΔ≥ωά¥ΨΆ «≤Μ ’«°Θ§Α―¥ζ¬κΡΟ≥ωά¥Ζ÷œμΗχ¥σΦ“Θ§»Ϊ άΫγΥ≠”ΟΕΦΩ…“‘Θ§Υυ”–ΒΡ»ΥΕΦΩ…“‘œμ ήΒΫΚΟ¥ΠΘ§’βΗωΫ–ΉωΩΣ‘¥ΓΘ
Ζ«≥ΘΫ®“ι¥σΦ“ΝΥΫβΘ§…ν»κ―–ΨΩΘ§…θ÷Ν≤Έ”κΙ±œΉΩΣ‘¥»μΦΰΘ§“ρΈΣ ’“φΖΥ«≥ΓΘ
ΒΎ“ΜΘΚΆ®ΙΐΩΣ‘¥»μΦΰΘ§Έ“Ο«Ω…“‘ΝΥΫβ¥σ≈ΘΟ«ΒΡΦήΙΙ‘≠‘ρΘ§…ηΦΤΡΘ ΫΓΘ
Τδ Β‘έΟ«ΤΫ ±ΒΡΙΛΉς÷–Θ§ «ΚήΡ―≈ωΒΫ¥σ≈ΘΒΡΘ§ΥϊΩ…Ρή «ΡψΩ ΆϊΕχ≤ΜΩ…ΦΑΒΡΙΪΥΨΒΡ‘±ΙΛΘ§…θ÷Ν‘ΎΙζΆβΘ§Ρψ“ΣœκΫχ’β÷÷ΙΪΥΨΘ§≤ΜΥΔΗωΦΗΡξΧβΡΩΘ§Οφ ‘ΗωN¬÷ «Ϋχ≤Μ»ΞΒΡΓΘΦ¥±ψΫχ»ΞΝΥΘ§ΥϊΩ…Ρή «ΙΪΥΨΒΡΗΏ≤ψΘ§ΟΩΧλΚήΟΠΘ§≤Μ‘θΟ¥ΦϊΒΟΒΫΥϊΘ§ΨΆΥψΒ±ΟφΧ÷ΫΧΘ§ ±Φδ“≤≤ΜΜαΚή≥ΛΘ§ΚήΡ―…ν»κΫΜΝςΓΘ“≤”–ΒΡ¥σ≈ΘΜα―Γ‘ώΉ‘÷ς¥¥“ΒΘ§Μρ’Ώ «Ή‘”…÷Α“Β’ΏΘ§…ώΝζΦϊ Ή≤ΜΦϊΈ≤Θ§ΒΫΝΥ¥σΙΪΥΨΕΦΦϊ≤ΜΒΫΓΘ
ΒΪ «Η––ΜΜΞΝΣΆχΚΆΩΣ‘¥…γ«χΘ§ΫΪ¥σ≈ΘΟ«ά≠ΒΫΝΥΈ“Ο«…μ±ΏΘ§ΡψΩ…“‘Ε©‘Ρ” ΦΰΉιΘ§Ω…“‘Φ”»κΧ÷¬έ»ΚΘ§Ω…“‘Ω¥ΒΫ¥σ≈ΘΟ«ΒΡ…ηΦΤΘ§Ω¥ΒΫΚήΕύ»ΥΒΡΤά¬έΘ§ΧαΈ Θ§ΜΙ”–¥σ≈ΘΒΡΜΊ¥πΘ§Ω…“‘Ω¥ΒΫ¥σ≈ΘΒΡ…ηΦΤ“≤≤Μ «“ΜθμΕχΨΆΆξΟάΒΡΘ§Ω¥ΒΫ÷πΫΞ―ίΫχΒΡΙΐ≥Χȧ»»ΓΘ’β–©ΕΦ «ΡήΙΜΑο÷ζΈ“Ο«ΩλΥΌΧα…ΐΥ°ΤΫΒΡΒΊΖΫΘ§”–ΒΡ ±ΚρΘ§ΡΟΒΫ“ΜΤΣ…ηΦΤΘ§ΕΦ“Σ≤ιΉ ΝœΩ¥ΑκΧλΘ§“ΜΩΣ ΦΕΦΩ…ΡήΚΟΕύΒΡ θ”οΕΦΩ¥≤ΜΕ°Θ§ΟΜΙΊœΒΩœœ¬ΥϊΘ§Β±ΡψΩ¥blueprints‘Ϋά¥‘ΫΥ≥≥©ΒΡ ±ΚρΘ§ΡψΨΆΫχ≤ΫΝΥΓΘ
ΒΎΕΰΘΚΆ®ΙΐΩΣ‘¥»μΦΰΘ§Έ“Ο«Ω…“‘―ßœΑΒΫ¥ζ¬κΦΕΒΡ¬δΒΊ ΒΦυΓΘ
”– ±ΚρΈ“Ο«ΡήΩ¥ΒΫΚήΕύ¥σ≈Θ–¥ΒΡ ιΚΆΈΡ’¬Θ§“≤ΡήΩ¥ΒΫΚήΕύάμ¬έΒΡ ιΦ°Θ§ΒΪ «¥φ‘Ύ“ΜΗωΈ Χβ «Θ§άμ¬έΕΦΕ°Θ§ΒΪ «ΜΙ «Ήω≤ΜΚΟΦήΙΙΓΘ’β «“ρΈΣΟΜ”–Ω¥ΒΫ¥ζ¬κΘ§Υυ”–ΒΡάμ¬έΕΦ «Ω’÷–¬ΞΗσΘ§Β±ΡψΒΫΝΥΨΏΧεΒΡ¥ζ¬κ…ηΦΤ≤ψΟφΘ§Ρ«–©―ßΜαΒΡ…ηΦΤΡΘ ΫΘ§ΈόΖ®ΉΣΜ·ΈΣΡψΉ‘ΦΚΒΡ ΒΦυΓΘ
ΚΟ‘ΎΩΣ‘¥»μΦΰΒΡ¥ζ¬κΕΦ «ΙΪΩΣΒΡΘ§ΡΐΫαΝΥ¥σ≈ΘΒΡ–Ρ―ΣΘ§“≤ΡήΙΜΩ¥ΒΫ¥σ≈Θ‘ΎΨΏΧε¬δΒΊ ±ΚρΒΡ»Γ…αΘ§“Μ«–Ρ«Ο¥’φ ΒΘ§Ω¥ΒΟΦϊΘ§ΟΰΒΟΉ≈ΓΘΆ®Ιΐ¥ζ¬κΫχ––―ßœΑΘ§≈δΚœάμ¬έ÷Σ ΕΘ§Ηϋ»ί“ΉΜώΒΟΒΎ“Μ ÷ΒΡΨ≠―ιΘ§≤Δ«“‘ΎΉ‘ΦΚΉω…ηΦΤΚΆ–¥¥ζ¬κΒΡ ±ΚρΘ§¬μ…œΡήΙΜ”≥…δΒΫΩ…“‘≤ΈΩΦΒΡ≥ΓΨΑΘ§»ΟΈ“Ο«‘ΎΉωΉ‘ΦΚΒΡœΒΆ≥ΒΡ ±ΚρΘ§…ΌΉΏΆδ¬ΖΓΘ
ΒΎ»ΐΘΚΆ®ΙΐΩΣ‘¥»μΦΰΘ§Έ“Ο«Ω…“‘Φ”»κ…γ«χΘ§ΚΆΤδΥϊΦΦ θ»Υ‘±‘ΎΆ§“Μ±≥ΨΑœ¬Ι≤Ά§Ϋχ≤Ϋ
¥σ≈ΘΈ“Ο«ΆυΆυ≤Μ»ί“ΉΫ”¥ΞΒΫΘ§’ΐΟφΧ÷¬έΦΦ θΈ ΧβΒΡ ±ΦδΗϋ «Ρ―ΡήΩ…ΙσΘ§ΒΪ «ΟΜ”–ΙΊœΒΘ§ΩΣ‘¥»μΦΰΙΙΫ®ΝΥ“ΜΗω…γ«χΘ§¥σΦ“Ω…“‘‘Ύ“ΜΤπΧ÷¬έΘ§Ρψ «‘θΟ¥άμΫβΒΡΘ§±π»Υ «‘θΟ¥άμΫβΒΡΘ§‘ΫΧ÷¬έ‘ΫΫΜΝςΘ§‘ΫΟςΈζΘ§”– ±ΚρΚΆ±»ΡψΨ≠―ι…‘ΈΔΖαΗΜ“ΜΒψΒΡΦΦ θ»Υ‘±ΫΜΝςΘ§Ω…Ρή±»÷±Ϋ”ΚΆ¥σ≈ΘΕ‘ΜΑΗϋΦ””–÷±Ϋ”Ής”ΟΓΘ¥σ≈ΘΒΡΜΑΩ…Ρή»ΟΡψœϊΜ·ΑκΧλΘ§“ά»Μ≤Μ÷ΣΥυ‘ΤΘ§¥σ≈ΘΩ…ΡήΨθΒΟΚήΕύΤ’Ά®»ΥΨθΒΟΒΡΡ―Βψ «œ‘Εχ“ΉΦϊΒΡΘ§≤Μ–Φ»ΞΫβ ΆΓΘΒΪ «…γ«χάοΟφΒΡΦΦ θ»Υ‘±Θ§Ω…ΡήΚΆΡψ“Μ―υ¬ΐ¬ΐΫχ≤ΫΙΐά¥ΒΡΘ§÷ΣΒάΡΡ–©Βψ «Β±ΡξΉ‘ΦΚάßΜσΒΡΘ§»γΙϊ≤»Ιΐ’β“ΜΗωΗωΒΡΩ”Θ§ΥϊΟ«“ΜΒψ≤ΠΘ§ΡψΨΆΜαΜμ»ΜΩΣά ΓΘ
Εχ«“ΟΩΗω»Υ”ωΒΫΒΡΨΏΧε«ιΩω≤ΜΆ§Θ§¥” ¬ΒΡ––“Β≤ΜΆ§Θ§ΩΆΜßΒΡ–η«σ≤ΜΆ§Θ§“ρΕχ»μΦΰ…ηΦΤΒΡ ±ΚρΩΦ¬«ΒΡ“ρΥΊ≤ΜΆ§Θ§¥σ≈Θ «≈ΘΘ§ΒΪ «≤Μ“ΜΕ®ΡήΙΜ”ωΒΫΚΆΡψ“Μ―υΒΡ≥ΓΨΑΘ§ΒΪ «…γ«χάοΟφΘ§”–ΡψΒΡΆ§––“ΒΒΡΘ§±≥ΨΑœύΫϋΒΡΦΦ θ»Υ‘±Θ§ΡψΟ«Ω…“‘Χ÷¬έ≥ωΖϊΚœΡψΟ«ΧΊΕ®≥ΓΨΑΒΡΫβΨωΖΫΑΗΓΘ
ΒΎΥΡΘΚΆ®ΙΐΩΣ‘¥»μΦΰΘ§Έ“Ο«ΉςΈΣΗω»ΥΘ§±»Ϋœ»ί“Ή’“ΒΫΙΛΉς
Έ“Ο«Οφ ‘ΒΡ ±ΚρΘ§≥Θ≥Θ”ωΒΫΒΡΈ Χβ «Θ§‘θΟ¥ΡήΙΜΑ―‘Ύ‘≠ά¥ΙΛΉς÷–Ή‘ΦΚΒΡΙ±œΉΘ§άμΫβΘ§…ηΦΤΘ§ΦΦ θΡήΝΠΓΘΤδ ΒΈ“ΖΔœ÷ΚήΕύ≥Χ–ρ‘±≤ΜΡήΚήΚΟΒΡΉωΒΡ’β“ΜΒψΘ§Υυ“‘‘λ≥…ΚήΕύ»ΥΟφ ‘Κή≥‘ΩςΓΘ‘≠“ρ÷°“Μ «±≥ΨΑ–≈œΔ≤ΜΕ‘≥ΤΘ§άΐ»γ‘≠ά¥ΟφΝΌΒΡ“ΒΈώ…œΚήΡ―ΒΡΈ ΧβΘ§Οφ ‘ΙΌ”…”Ύ≤ΜάμΫβ±≥ΨΑΘ§Εχ«“ΕΧ ±ΦδΫβ Ά≤Μ«ε≥ΰΘ§Εχ«α ”Κρ―Γ»ΥΒΡΥ°ΤΫΘ§Έ““≤”ωΒΫΙΐΚήΕύΟφ ‘ΙΌ≤≈ΧΐΝΥΦΗΖ÷÷”Θ§ΨΆΜαΥΒΘ§’β≤ΜΆΠΦρΒΞΒΡΘ§Ρψ’β―υ’β―υ≤ΜΨΆ––ΝΥΘ§»ΜΚσ≥ΙΒΉΖώΕ®ΡψΟ«“ΜΗωΆ≈Ε”ΟΠΝΥ»ΐΡξΒΡ ¬«ιΓΘ‘≠“ρ÷°Εΰ «ΚήΕύ”–ΡήΝΠΒΡ≥Χ–ρ‘±≤ΜΜα±μ¥οΘ§ΒΦ÷¬’φ’ΐ–¥¥ζ¬κΒΡΥΒ≤ΜΟςΑΉΘ§Ω…Ρή‘≠ά¥‘ΎΙΪΥΨάοΟφ“ΜΗωΦ®–ßΖ«≥ΘΚΟΘ§“ΜΗωΦ®–ßΖ«≥Θ≤νΘ§ΒΪ «ΒΫΝΥΟφ ‘ΙΌΡ«άοΨΆά≠ΤΫΝΥΓΘ‘≠“ρ÷°»ΐ «–¬ΒΡΙΪΥΨ≤ΜΡή»ΖΕ®Ρψ‘Ύ…œΦ“ΙΪΥΨΉωΒΡΙΛΉςΘ§ΒΫ’β“ΜΦ“ΕΦΡή”ΟΒΡΘ§άΐ»γΡψΉωΒΡΙΛΉς”–30% «ΚΆΨΏΧε“ΒΈώ≥ΓΨΑœύΙΊΒΡΘ§70% «Ά®”ΟΦΦ θΘ§Ω…Ρήœ¬Φ“ΙΪΥΨ÷ΜΜαΈΣΡψΒΡΆ®”ΟΦΦ θ≤ΩΖ÷¬ρΒΞΓΘ
ΩΣ‘¥»μΦΰΒΡΚΟ¥ΠΨΆ «Θ§≤Έ”κΒΡ»ΥΥυ’ΤΈ’ΒΡΦΦΡήΕΦ «Ά®ΒΡΘ§Εχ«“¥σΦ“‘ΎΆ§“ΜΗω…œœ¬ΈΡάοΟφΕ‘ΜΑΘ§Οφ ‘ΙΌΚΆΚρ―Γ»Υ÷°ΦδΒΡ–≈œΔ≤ν±»Ϋœ…ΌΓΘ’ΤΈ’Ρ≥ΗωΩΣ‘¥»μΦΰ”–ΕύΡ―Θ§≤Μ”ΟΚρ―Γ»ΥΉ‘ΦΚΥΒΘ§¥σΦ“–ΡάοΕΦ”– ΐΓΘ
Ε‘”ΎΚήΕύΦΦ θΡήΝΠ«ΩΘ§ΒΪ «±μ¥οΡήΝΠΫœ»θΒΡΦΪ…Ό ΐ»Υ‘±ά¥Ϋ≤Θ§talk is
cheap, show me the codeΘ§¥ζ¬κ≥ …œ»ΞΘ§ΨΆΡήΙΜ±μœ÷≥ω ΒΝΠά¥ΝΥΘ§Εχ«“Οφ ‘ΙΌ“≤≤Μ–η“ΣΗυΨίΕΧΕΧΒΡΑκΗω–Γ ±ΝΥΫβ“ΜΗω»ΥΘ§Ω…“‘ΉωΚήΕύ±≥ΨΑΒς≤ιΓΘ
ΝμΆβ”…”Ύ’ΤΈ’ΒΡΦΦ θΒΡΆ®”ΟΒΡΘ§ΡψΒΫœ¬“ΜΦ“ΙΪΥΨΘ§¬μ…œΨΆΡήΙΜ…œ ÷Θ§ΦΗΚθ≤Μ–η“Σ‘Λ»» ±ΦδΘ§Ε‘”ΎΥΪΖΫΕΦ”–ΚΟ¥ΠΓΘ
ΒΎΈεΘΚΆ®ΙΐΩΣ‘¥»μΦΰΘ§Έ“Ο«ΉςΈΣ’–ΤΗΖΫΘ§±»Ϋœ»ί“Ή’–ΒΫœύ”Π»Υ‘±ΓΘ
»γΙϊ‘Ύ¥¥“ΒΙΪΥΨ¥ΐΙΐΒΡ≈σ”―ΜαΝΥΫβΒΫ¥¥“ΒΙΪΥΨ’–»ΥΚήΡ―Θ§»Υ‘±Νς ßΚήΩλΘ§Εχ«“¥¥“ΒΙΪΥΨΆυΆυΕ‘”ΎΩΣΖΔΫχΕ»“Σ«σΚήΩλΘ§“ρΈΣ¥σΦ“ΕΦ‘Ύ«ά ±ΦδΓΘ“ρΕχΩΣ‘¥»μΦΰΕ‘”Ύ’–ΤΗΖΫά¥Ϋ≤Θ§“≤ «ΚΟœϊœΔΓΘ Ήœ»¥¥“ΒΙΪΥΨΟΜΑλΖ®œώ¥σΙΪΥΨ“Μ―υΘ§≈Σ’βΟ¥ΕύΒΡΦΦ θ¥σ≈ΘΘ§Ή‘ΦΚΆξ»Ϊ¬δΒΊ“ΜΧΉΉ‘ΦΚΒΡΧεœΒΘ§ Ι”ΟΩΣ‘¥»μΦΰΩλΥΌ¥νΫ®“ΜΧΉΤΫΧ®œ»…œœΏ «ΉνΚΟΒΡ―Γ‘ώΓΘΤδ¥Έ Ι”ΟΩΣ‘¥»μΦΰΘ§Μα ΙΒΟ’–ΤΗœύΕ‘»ί“ΉΘ§ –≥Γ…œΜπΒΡΩΣ‘¥»μΦΰΜα”–¥σ≈ζΒΡ¥”“Β’ΏΘ§≤Έ”κΗς÷÷¬έΧ≥ΚΆ…γ«χΘ§±»Ϋœ»ί“ΉΆΎΒΫ»ΥΓΘΉνΚσΘ§ΩΣ‘¥»μΦΰΒΡ Ι”Ο ΙΒΟ–¬»Υά¥ΝΥ÷°ΚσΟΜ”–‘Λ»» ±ΦδΘ§ά¥ΝΥΨΆ…œ ÷Θ§±Θ÷ΛΩΣΖΔΥΌΕ»ΓΘ
Ρ«»γΚΈΩλΥΌ…œ ÷“ΜΩνΩΣ‘¥»μΦΰΡΊΘΩΈ“–¥ΝΥ“ΜΤΣΈΡ’¬
»γΚΈΩλΥΌ…œ ÷“ΜΩνΩΣ‘¥»μΦΰ
‘Ύ’βΤΣΈΡ’¬÷–Θ§Έ“ΉήΫαΝΥΨ≈Ηω≤Ϋ÷ηΓΘ
“ΜΓΔ ÷Ε·Α≤ΉΑΤπά¥Θ§“ΜΕ®“Σ ÷Ε·
ΕΰΓΔ Ι”Ο“Μœ¬Θ§ΆΤΦωXXX in ActionœΒΝ–
»ΐΓΔΕΝΈΡΒΒΘ§ΕΝΥυ”–ΒΡΙΌΖΫΈΡΒΒΘ§Φ«≤ΜΉΓΘ§Ω¥≤ΜΕ°“≤“ΣΕΝœ¬ά¥
ΥΡΓΔΝΥΫβΚΥ–ΡΒΡ‘≠άμΚΆΥψΖ®Θ§ΆΤΦωXXX the definitive guideœΒΝ–
ΈεΓΔΩ¥“Μ±Ψ‘¥¬κΖ÷ΈωΒΡ ιΘ§Μα»ΟΡψΒΡ‘¥¬κ‘ΡΕΝ÷°¬Ο ¬ΑκΙΠ±Ε
ΝυΓΔΩΣ Φ‘ΡΕΝΚΥ–Ρ¬ΏΦ≠‘¥¥ζ¬κ
ΤΏΓΔ±ύ“κ≤ΔDebug‘¥¥ζ¬κ
ΑΥΓΔΩΣΖΔ“ΜΗω≤εΦΰΘ§Μρ’ΏΕ‘ΉιΦΰΉω…ΌΝΩΒΡ–όΗΡ
Ψ≈ΓΔ¥σΝΩΒΡ‘ΥΈ§ ΒΦυΨ≠―ιΚΆΟφœρ’φ Β≥ΓΨΑΒΡΕ®÷ΤΩΣΖΔ
Υυ“‘Ήω“ΜΗω‘ΤΦήΙΙ ΠΘ§“ΜΕ®≤ΜΡήΆ―άκ¥ζ¬κΘ§Ζ¥Εχ“Σ≤ΜΕœΒΡ”Β±ßΩΣ‘¥»μΦΰΓΘ
ΥΡΓΔΝΥΫβLinuxΜυ¥Γ÷Σ Ε
ΉςΈΣ“ΜΗω‘ΤΦήΙΙ ΠΘ§ Ή“ΣΒΡ“ΜΒψΘ§ΨΆ «“Σ λœΛLinuxΒΡΜυ¥Γ÷Σ ΕΘ§Μυ±Ψ‘≠άμΝΥΓΘ
ΥΒΒΫ≤ΌΉςœΒΆ≥Θ§“ΜΑψ”–»ΐΗωΈ§Ε»Θ§“ΜΗω «ΉάΟφ≤ΌΉςœΒΆ≥Θ§“ΜΗω «“ΤΕ·≤ΌΉςœΒΆ≥Θ§“ΜΗω «ΖΰΈώΤς≤ΌΉςœΒΆ≥ΓΘ
Stack Overflow Developer Survey 2018”–’β―υ“ΜΗωΆ≥ΦΤΘ§Ε‘”ΎΩΣΖΔ»Υ‘±ά¥ΥΒΘ§ΉάΟφ≤ΌΉςœΒΆ≥ΒΡ≈≈Οϊ «WindowsΘ§MacOSΘ§LinuxΘ§Υυ“‘¥σ≤ΩΖ÷»ΥΤΫ ±ΒΡΑλΙΪœΒΆ≥ΕΦ «windowsΓΘ

Β±»Μ“ρΈΣΑλΙΪΒΡ‘≠“ρΘ§ΤΫ ± Ι”ΟwindowsΒΡ±»ΫœΕύΘ§Υυ“‘‘Ύ―ß–ΘάοΘ§ΚήΕύΆ§―ßΫ”¥ΞΒΫΒΡ≤ΌΉςœΒΆ≥Μυ±Ψ…œΕΦ «WindowsΘ§ΒΪ «“ΜΒ©¥” ¬ΦΤΥψΜζ––“ΒΘ§ΨΆ“ΜΕ®“ΣΩγΙΐLinux’βΒάΩ≤ΓΘ
ΗυΨίΫώΡξW3TechsΒΡΆ≥ΦΤΘ§Ε‘”ΎΖΰΈώΤςΕΥΘ§Unix-Like OS’ΦΒΫΒΡ±»άΐΈΣΫϋ70%ΓΘΥυΈΫUnix-Like
OS Αϋά®œ¬ΆΦΒΡLinuxΘ§BSDΒ»“ΜœΒΝ–ΓΘ


¥”’βΗωΆ≥ΦΤΩ…“‘Ω¥≥ωΘ§ΥφΉ≈‘ΤΦΤΥψΒΡΖΔ’ΙΘ§»μΦΰSaaSΜ·Θ§ΖΰΈώΜ·Θ§…θ÷ΝΈΔΖΰΈώΜ·Θ§¥σ≤ΩΖ÷ΒΡΦΤΥψΕΦ «‘ΎΖΰΈώΕΥΉωΒΡΘ§“ρΕχ“Σ≥…ΈΣ‘ΤΦήΙΙ ΠΘ§ΨΆ±Ί–κΕ°LinuxΓΘ
ΥφΉ≈“ΤΕ·ΜΞΝΣΆχΒΡΖΔ’ΙΘ§ΩΆΜßΕΥΜυ±Ψ…œ“‘AndroidΚΆiOSΈΣ÷ςΘ§œ¬ΆΦ «GartnerΒΡΆ≥ΦΤΓΘAndroid «Μυ”ΎLinuxΡΎΚΥΒΡΓΘ“ρΕχΩΆΜßΕΥ“≤Ϋχ»κΝΥLinux’σ”ΣΘ§ΚήΕύ÷«Ρή÷’ΕΥΘ§÷«Ρή…η±ΗΒ»ΩΣΖΔ÷ΑΈΜΘ§ΕΦ–η“ΣΕ°LinuxΒΡ»Υ‘±ΓΘ

―ßœΑLinux÷ς“ΣΑϋΚ§ΝΫ≤ΩΖ÷Θ§“ΜΗω «‘θΟ¥”ΟΘ§“ΜΗω «‘θΟ¥±ύ≥ΧΘ§±≥Κσ‘≠άμ « ≤Ο¥ΓΘ
Ε‘”Ύ‘θΟ¥”ΟΘ§…œ ÷ΒΡΜΑΘ§ΆΤΦωΓΕΡώΗγΒΡLinuxΥΫΖΩ≤ΥΓΖΘ§Α¥Ή≈’βΗω ÷≤αΘ§ΨΆΡήΙΜ―ßΜαΜυ±ΨΒΡLinuxΒΡ Ι”ΟΘ§»γΙϊ‘Ό…ν»κ“ΜΒψΘ§ΆΤΦωΓΕLinuxœΒΆ≥ΙήάμΦΦ θ ÷≤αΓΖΘ§Ή©ΆΖΚώΒΡ“Μ±Ψ ιΘ§ «Linux‘ΥΈ§ ÷±Ώ±Ί±ΗΓΘ
Ε‘”Ύ‘θΟ¥±ύ≥ΧΘ§…œ ÷ΒΡΜΑΘ§ΆΤΦωΓΕUNIXΜΖΨ≥ΗΏΦΕ±ύ≥ΧΓΖΘ§”–¥ζ¬κΘ§”–Ϋι…ήΘ§”–‘≠άμΘ§»γΙϊΕ‘ΡΎΚΥΒΡ‘≠άμΗ––Υ»ΛΘ§ΆΤΦωΓΕ…ν»κάμΫβLINUXΡΎΚΥΓΖΓΘ
LinuxΒΡΦήΙΙ»γœ¬ΆΦ

Έ“Ο«÷ΣΒάΘ§“ΜΧ®ΈοάμΜζ…œ”–ΚήΕύΒΡ”≤ΦΰΘ§Ήν÷Ί“ΣΒΡ «CPUΘ§ΡΎ¥φΘ§”≤≈ΧΘ§Άχ¬γΘ§ΒΪ «“ΜΗωΈοάμΜζ…œ“Σ≈ήΚήΕύΒΡ≥Χ–ρΘ§’β–©Ή ‘¥”ΠΗΟΗχΥ≠”ΟΡΊΘΩΒ±»Μ «¥σΦ“¬÷Ή≈”ΟΘ§Υ≠“≤±πΕά’ΦΘ§Υ≠“≤±πΕωΥάΓΘΈΣΝΥΆξ≥…’βΦΰ ¬«ιΘ§≤ΌΉςœΒΆ≥ΒΡΡΎΚΥΨΆΤπΒΫΝΥ¥σΙήΦ“ΒΡΉς”ΟΘ§ΫΪ”≤ΦΰΉ ‘¥Ζ÷≈δΗχ≤ΜΆ§ΒΡ”ΟΜß≥Χ–ρ Ι”ΟΘ§≤Δ«“‘Ύ Β±ΒΡ ±ΦδΫΪΉ ‘¥ΡΟΜΊά¥Θ§‘ΌΖ÷≈δΗχΤδΥϊΒΡ”ΟΜßΫχ≥ΧΘ§’βΗωΙΐ≥Χ≥ΤΈΣΒςΕ»ΓΘ
≤ΌΉςœΒΆ≥ΒΡΙΠΡή÷°“Μ «œΒΆ≥Βς”Ο
Β±”ΟΜß≥Χ–ρœκ«κ«σΉ ‘¥ΒΡ ±ΚρΘ§–η“ΣΒς”Ο≤ΌΉςœΒΆ≥ΒΡœΒΆ≥Βς”ΟΫ”ΩΎΘ§’β «ΡΎΚΥΚΆ”ΟΜßΧ§≥Χ–ρΒΡΖ÷ΫγœΏΘ§ΨΆœώΡψ“Σ¥ρ≥ΒΘ§“ΣΆ®Ιΐ¥ρ≥Β»μΦΰΒΡΫγΟφΘ§œ¬ΖΔ¥ρ≥Β÷ΗΝν“Μ―υΘ§’β―υ¥ρ≥Β»μΦΰ≤≈ΜαΗχΡψΒςΕ»“ΜΝΨ≥ΒΓΘ
≤ΌΉςœΒΆ≥ΒΡΙΠΡή÷°Εΰ «Ϋχ≥ΧΙήάμ
Β±“ΜΗω”ΟΜßΫχ≥Χ‘Υ––ΒΡ ±ΚρΘ§ΡΎΚΥΈΣΥϊΖ÷≈δΒΡΉ ‘¥Θ§Ήή“Σ”–“ΜΗω ΐΨίΫαΙΙ±Θ¥φΘ§ΡΡ–©Ή ‘¥Ζ÷≈δΗχΝΥ’βΗωΫχ≥ΧΓΘΖ÷≈δΗχ’βΗωΫχ≥ΧΒΡΉ ‘¥ΆυΆυΑϋά®¥ρΩΣΒΡΈΡΦΰΘ§ΡΎ¥φΩ’ΦδΒ»ΓΘ

≤ΌΉςœΒΆ≥ΒΡΙΠΡή÷°»ΐ «ΡΎ¥φΙήάμ
ΟΩΗωΫχ≥Χ”–ΕάΝΔΒΡΡΎ¥φΩ’ΦδΘ§ΡΎ¥φΩ’Φδ «Ϋχ≥Χ”Οά¥¥φΖ≈ ΐΨίΒΡΘ§ΨΆœώ“ΜΦδ“ΜΦδΒΡ≤÷ΩβΓΘΈΣΝΥΫχ≥Χ Ι”ΟΖΫ±ψΘ§ΟΩΗωΫχ≥ΧΡΎ¥φΩ’ΦδΘ§‘ΎΫχ≥ΧΒΡΫ«Ε»ά¥Ω¥ΕΦ «ΕάΝΔΒΡΘ§“≤Φ¥ΕΦ «¥”0Κ≈≤÷ΩβΘ§1Κ≈≤÷ΩβΘ§“Μ÷±ΒΫNΚ≈≤÷ΩβΘ§ΕΦ «ΕάœμΒΡΓΘΒΪ «¥”≤ΌΉςœΒΆ≥ΡΎΚΥΒΡΫ«Ε»ά¥Ω¥Θ§Β±»Μ≤ΜΩ…ΡήΕάœμΘ§Εχ «¥σΦ“Ι≤œμΘ§MΚ≈≤÷Ωβ÷Μ”–“ΜΗωΘ§Ρψ”ΟΥϊΨΆ≤ΜΡή”ΟΘ§’βΨΆ–η“Σ“ΜΗω≤÷ΩβΒςΕ»œΒΆ≥Θ§ΫΪ”ΟΜßΫχ≥ΧΒΡ≤÷ΩβΚ≈ΚΆ ΒΦ Ι”ΟΒΡ≤÷ΩβΚ≈Ε‘”ΠΤπά¥Θ§άΐ»γΫχ≥Χ1ΒΡ10Κ≈≤÷ΩβΘ§Ε‘”ΠΒΫ’φ ΒΒΡ≤÷Ωβ «110Κ≈Θ§Ϋχ≥Χ2ΒΡ20Κ≈≤÷ΩβΘ§Ε‘”ΠΒΫ’φ ΒΒΡ≤÷Ωβ «120Κ≈ΓΘ
≤ΌΉςœΒΆ≥ΙΠΡή÷°ΥΡ «ΈΡΦΰœΒΆ≥
Ε‘”ΎLinuxά¥Ϋ≤Θ§ΚήΕύΕΪΈςΕΦ «ΈΡΦΰΘ§άΐ»γΫχ≥ΧΚ≈ΜΊΕ‘”Π“ΜΗωΈΡΦΰΘ§Ϋ®ΝΔ“ΜΗωΆχ¬γΝ§Ϋ”“≤Ε‘”Π“ΜΗωΈΡΦΰΓΘΈΡΦΰœΒΆ≥Εύ÷÷Εύ―υΘ§ΈΣΝΥΡήΙΜΆ≥“Μ ≈δΘ§”–“ΜΗω–ιΡβΈΡΦΰœΒΆ≥ΒΡ÷–Φδ≤ψVFSΓΘ
≤ΌΉςœΒΆ≥ΙΠΡή÷°Έε «…η±ΗΙήάμ
…η±ΗΖ÷ΝΫ÷÷Θ§“Μ÷÷ «Ωι…η±ΗΘ§“Μ÷÷ «Ή÷Ζϊ…η±ΗΘ§άΐ»γ”≤≈ΧΨΆ «Ωι…η±ΗΘ§Ω…“‘Ηώ ΫΜ·ΈΣΈΡΦΰœΒΆ≥Θ§‘Ό»γ σ±ξΚΆΦϋ≈ΧΒΡ δ»κ δ≥ω «Ή÷Ζϊ…η±ΗΓΘ
≤ΌΉςœΒΆ≥ΙΠΡή÷°Νυ «Άχ¬γΙήάμ
Τδ ΒΕ‘”ΎLinuxά¥Ϋ≤Θ§Άχ¬γ“≤ «Μυ”Ύ…η±ΗΚΆΈΡΦΰœΒΆ≥ΒΡΘ§ΒΪ «”…”ΎΆχ¬γ”–Ή‘ΦΚΒΡ–≠“ι’ΜΘ§“ΣΉώ―≠TCP/IP–≠“ι’Μ±ξΉΦΓΘ

ΈεΓΔΝΥΫβ ΐΨί÷––ΡΚΆΆχ¬γΜυ¥Γ÷Σ Ε
‘ΤΤΫΧ®Β±»ΜΜα≤Ω π‘Ύ ΐΨί÷––ΡάοΟφΘ§”…”Ύ ΐΨί÷––ΡάοΟφΒΡ”≤Φΰ…η±Η“≤ «Ζ«≥ΘΉ®“ΒΒΡΘ§“ρΕχΚήΕύΒΊΖΫΜζΖΩ≤ΩΟ≈ΚΆ‘ΤΦΤΥψ≤ΩΟ≈ «ΝΫΗω≤ΩΟ≈Θ§ΒΪ «ΉςΈΣ“ΜΗω‘ΤΦήΙΙ ΠΘ§–η“ΣΚΆΜζΖΩ≤ΩΟ≈Ϋχ––ΙΒΆ®Θ§“ρΕχ–η“Σ“ΜΕ®ΒΡ ΐΨί÷––Ρ÷Σ ΕΘ§‘Ύ ΐΨί÷––ΡάοΟφΘ§ΉνΡ―ΗψΕ®ΒΡ «Άχ¬γΘ§“ρΕχ’βάοΟφΆχ¬γ÷Σ Ε «÷Ί÷–÷°÷ΊΓΘ
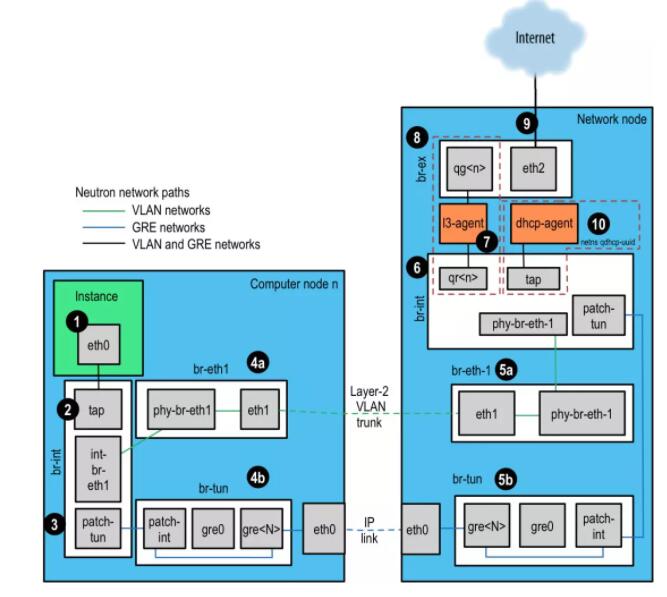
œ¬Οφ’βΗωΆΦ «“ΜΗωΒδ–ΆΒΡ ΐΨί÷––ΡΆΦΓΘ

ΉνΆβ≤ψ «Internet EdgeΘ§“≤Ϋ–Edge RouterΘ§“≤Ϋ–Border
RouterΘ§ΥϋΧαΙ© ΐΨί÷––Ρ”κInternetΒΡΝ§Ϋ”ΓΘ
ΒΎ“Μ≤ψcore networkΘ§ΑϋΚ§ΚήΕύΒΡcore switches
Available ZoneΆ§Edge router÷°ΦδΆ®–≈
Available Zone÷°ΦδΒΡΆ®–≈ΧαΙ©
ΧαΙ©ΗΏΩ…”Ο–‘Ν§Ϋ”HA
ΧαΙ©Intrusion Prevention Services
ΧαΙ©Distributed Denial of Service Attack Analysis and
Mitigation
ΧαΙ©Tier 1 Load Balancer
ΒΎΕΰ≤ψ“≤Φ¥ΟΩΗωAZΒΡΉν…œ≤ψΘ§Έ“Ο«≥ΤΈΣAggregation layerΓΘ
ΒΎ»ΐ≤ψ «access layerΘ§ΨΆ «“ΜΗωΗωΜζΦήΒΡΖΰΈώΤςΘ§”ΟΫ”»κΫΜΜΜΜζΝ§Ϋ”‘Ύ“ΜΤπΓΘ
’β «“ΜΗωΒδ–ΆΒΡ»ΐ≤ψΆχ¬γΫαΙΙΘ§“≤Φ¥Ϋ”»κ≤ψΓΔΜψΨέ≤ψΓΔΚΥ–Ρ≤ψ»ΐ≤ψΓΘ
Ε‘”Ύ ΐΨί÷––ΡΘ§Έ“–¥ΝΥΦΗΤΣΈΡ’¬
ΐΨί÷––Ρ≥Λ…Ε―υΘΩ
ΗΏΩ…”Ο–‘ΒΡΦΗΗωΦΕ±π
Β±ΩΆΜß‘ΎΥΒ“ΣΑ≤»ΪΒΡ ±ΚρΘ§ΩΆΜß‘Ύœκ ≤Ο¥ΘΩ
≥ΐΝΥ ΐΨί÷––Ρ“‘ΆβΘ§ΡΡ≈¬ «Ήω”Π”ΟΦήΙΙΘ§Ε‘”ΎΆχ¬γΒΡΝΥΫβ“≤ «±Ί–κΒΡΓΘ
‘ΤΦήΙΙΥΒΒΫΒΉ «Ζ÷≤Φ ΫΦήΙΙΘ§Φ»»Μ «Ζ÷≤Φ ΫΘ§ΨΆ «»Ξ÷––ΡΜ·ΒΡΘ§“ρΕχΨΆ–η“ΣœΒΆ≥÷°ΦδΆ®ΙΐΆχ¬γΫχ––ΜΞΆ®Θ§“ρΕχΆχ¬γ «ΉςΈΣ¥σΙφΡΘœΒΆ≥ΦήΙΙ»Τ≤ΜΙΐ»ΞΒΡ“ΜΗωΩ≤ΓΘ
Ε‘”ΎΆχ¬γΒΡΜυ±Ψ‘≠άμΘ§ΆΤΦω ιΦ°ΓΕΦΤΥψΜζΆχ¬γ-―œΈΑ”κ≈ΥΑ°Οώ“κΓΖΘ§ΓΕΦΤΥψΜζΆχ¬γΘΚΉ‘ΕΞœρœ¬ΖΫΖ®ΓΖΓΘ
Τδ÷–”–ΗωΉέΚœ≥ΓΨΑΘ§¥°Τπά¥Υυ”–ΒΡΆχ¬γ–≠“ιΓΘ

ΝυΓΔΜυ”ΎKVMΝΥΫβΦΤΥψ–ιΡβΜ·
Β±ΈοάμΜζ¥νΫ®Άξ±œ÷°ΚσΘ§Ϋ”œ¬ά¥ΨΆ «Μυ”ΎΈοάμΜζ…œΟφ¥νΫ®–ιΡβΜζΝΥΓΘ
ΟΜ”–ΝΥΫβ–ιΡβΜζΒΡΆ§―ßΘ§Ω…“‘‘ΎΉ‘ΦΚΒΡ± Φ«±ΨΒγΡ‘…œ”ΟVirtualBoxΜρ’ΏVmware¥¥Ϋ®–ιΡβΜζΘ§ΡψΜαΖΔœ÷Θ§Κή»ί“ΉΨΆΡή‘ΎΈοάμΜζΒΡ≤ΌΉςœΒΆ≥÷°ΡΎ‘ΌΑ≤ΉΑΕύΗω≤ΌΉςœΒΆ≥Θ§Ά®Ιΐ’β÷÷ΖΫ ΫΘ§ΡψΩ…“‘ΚήΖΫ±ψΒΡ‘ΎwindowsΑλΙΪœΒΆ≥÷°ΡΎΑ≤ΉΑ“ΜΗωLinuxœΒΆ≥ΓΘ¥”Εχ±Θ≥÷LInuxœΒΆ≥ΒΡ≥÷–χ―ßœΑΓΘ

«ΑΟφΫ≤linux≤ΌΉςœΒΆ≥ΒΡ ±ΚρΘ§ΥΒΒΫ≤ΌΉςœΒΆ≥Θ§ΨΆ «’ϊΗωœΒΆ≥ΒΡΙήΦ“ΓΘ”Π”Ο≥Χ–ρ“Σ…ξ«κΉ ‘¥Θ§ΕΦ–η“ΣΆ®Ιΐ≤ΌΉςœΒΆ≥ΒΡœΒΆ≥Βς”ΟΫ”ΩΎΘ§œρ≤ΌΉςœΒΆ≥ΡΎΚΥ…ξ«κΫΪCPUΘ§ΡΎ¥φΘ§Άχ¬γΘ§”≤≈ΧΒ»Ή ‘¥Ζ÷≈δΗχΥϊΓΘ
’β ±ΚρΡψΜαΖΔœ÷Θ§–ιΡβΜζ“≤ «ΈοάμΜζ…œΒΡ“ΜΗωΤ’Ά®Ϋχ≥ΧΘ§Β±–ιΡβΜζΡΎ≤ΩΒΡ”Π”Ο≥Χ–ρ…ξ«κΉ ‘¥ΒΡ ±ΚρΘ§–η“Σœρ–ιΡβΜζΒΡ≤ΌΉςœΒΆ≥«κ«σΓΘ»ΜΕχ–ιΡβΜζΒΡ≤ΌΉςœΒΆ≥Ή‘ΦΚ±Ψ…μ“≤ΟΜ”–»®œό≤ΌΉςΉ ‘¥Θ§“ρΕχ”÷–η“ΣœώΈοάμΜζΒΡ≤ΌΉςœΒΆ≥…ξ«κΉ ‘¥ΓΘ’β÷–Φδ“ΣΕύ“Μ¥ΈΖ≠“κΒΡΙΛΉςΘ§Άξ≥…’βΦΰ ¬«ιΒΡ≥ΤΈΣ–ιΡβΜ·»μΦΰΓΘάΐ»γ…œΟφΥΒΒΡVirtualBoxΚΆVmwareΕΦ «–ιΡβΜ·»μΦΰΓΘ
ΒΪ «Εύ“Μ≤ψΖ≠“κΘ§ΨΆΕύ“Μ≤ψ–‘ΡήΥπΚΡΘ§»γΙϊ–ιΡβΜζάοΟφΒΡΟΩ“ΜΗω≤ΌΉςΕΦ“ΣΖ≠“κΘ§ΕΦ≤ΜΡή÷±Ϋ”≤ΌΉς”≤ΦΰΘ§–‘ΡήΨΆΜα≤νΚήΕύΘ§Φρ÷±ΟΜΑλΖ®”ΟΘ§”Ύ «ΨΆ≥ωœ÷ΝΥ…œΆΦ÷–ΒΡ”≤ΦΰΗ®÷ζ–ιΡβΜ·Θ§“≤Φ¥Ά®Ιΐ”≤ΦΰΒΡΧΊ β≈δ÷ΟΘ§άΐ»γVT-xΚΆVT-dΒ»Θ§»Ο–ιΡβΜζάοΟφΒΡ≤ΌΉςœΒΆ≥÷ΣΒάΘ§Υϊ≤Μ «“ΜΗω‘≠…ζΒΡ≤ΌΉςœΒΆ≥ΝΥΘ§ «“ΜΗω–ιΡβΜζΒΡ≤ΌΉςœΒΆ≥Θ§≤ΜΡήΑ¥’’‘≠ά¥ΒΡΡΘ Ϋ≤ΌΉςΉ ‘¥ΝΥΘ§Εχ «Ά®ΙΐΧΊ βΒΡ«ΐΕ·“‘”≤ΦΰΗ®÷ζΒΡΖΫ Ϋ≥≠ΫϋΒά≤ΌΉςΈοάμΉ ‘¥ΓΘ
Η’≤≈ΥΒΒΡ «ΉάΟφ–ιΡβΜ·Θ§“≤ΨΆ «‘ΎΡψΒΡ± Φ«±ΨΒγΡ‘…œΘ§‘Ύ ΐΨί÷––ΡάοΟφΘ§“≤Ω…“‘ Ι”ΟVmwareΫχ–––ιΡβΜ·Θ§ΒΪ «ΦέΗώ±»ΫœΙσΘ§»γΙϊΙφΡΘ±»Ϋœ¥σΘ§Μα≤…»ΓΩΣ‘¥ΒΡ–ιΡβΜ·»μΦΰqemu-kvmΓΘ
Ε‘”Ύqemu-kvmά¥ΥΒΘ§ΚΆ…œΟφΒΡ‘≠άμ «“Μ―υΒΡΘ§Τδ÷–qemuΒΡemu «emulatorΒΡ“βΥΦΘ§“≤Φ¥ΡΘΡβΤςΘ§ΨΆ «Ζ≠“κΒΡ“βΥΦΓΘKVM «“ΜΗωΩ…“‘ Ι”ΟCPUΒΡ”≤ΦΰΗ®÷ζ–ιΡβΜ·ΒΡΖΫ ΫΘ§ΕχΆχ¬γΚΆ¥φ¥ΔΒΡΘ§–η“ΣΆ®ΙΐΧΊ βΒΡvirtioΒΡΖΫ ΫΘ§ΧαΙ©ΗΏ–‘ΡήΒΡ…η±Η–ιΡβΜ·ΙΠΡήΓΘ
“ΣΝΥΫβ–ιΡβΜ·ΒΡΜυ±Ψ‘≠άμΘ§ΆΤΦω ιΦ°ΓΕœΒΆ≥–ιΡβΜ·ΓΣΓΣ‘≠άμ”κ Βœ÷ΓΖ
“ΣΝΥΫβKVMΘ§ΆΤΦωΝΫ±Ψ ιΦ°ΓΕKVM Virtualization CookbookΓΖΚΆΓΕMastering
KVM VirtualizationΓΖΓΘ
ΝμΆβKVMΚΆqemuΒΡΙΌΖΫΈΡΒΒ“≤ «±Ί–κ“ΣΩ¥ΒΡΘ§ΜΙ”–RedhatΒΡΙΌΆχΚήΕύΈΡ’¬Ζ«≥Θ÷ΒΒΟ―ßœΑΓΘ
Ε‘”Ύ–ιΡβΜ·ΖΫΟφΘ§Έ“–¥ΝΥ“‘œ¬ΒΡΈΡ’¬ΓΘ
Έ“ «–ιΡβΜζΡΎΚΥΈ“άßΜσΘΩΘΓ
QemuΘ§KVMΘ§Virsh…Β…ΒΒΡΖ÷≤Μ«ε
¬ψ”ΟKVM¥¥Ϋ®–ιΡβΜζΘ§Χε―ιvirtualboxΈΣΡψΉωΒΡ10Φΰ ¬«ι
KVM–ιΡβΜζΨΒœώΡ«ΒψΕυ ¬Θ§qcow2Νυ¥σΙΠΡήΘ§ΡΎ≤ΩΩλ’’ΚΆΆβ≤ΩΩλ’’”–…Ε«χ±πΘΩ
KVMΑκ–ιΡβΜ·…η±ΗvirtioΦΑ–‘ΡήΒς”≈ΉνΦ― ΒΦυ
Έ“ΒΡ–ιΡβΜζΙ“ΝΥΘΓ‘θΟ¥Α―ΨΒœώάοΟφΒΡ ΐΨί’“ΜΊά¥ΘΩ
≤ΜΫωDocker”–ΨΒœώΘ§KVM“≤”–Εύ÷÷ΖΫ Ϋ≤ΌΉςΨΒœώ
ΤΏΓΔΜυ”ΎOpenvswitchΝΥΫβΆχ¬γ–ιΡβΜ·
Β±–ιΡβΜζ¥¥Ϋ®≥ωά¥ΝΥΘ§Ήν÷ς“ΣΒΡΥΏ«σΨΆ «“ΣΡή…œΆχΘ§ΥϊΡήΖΟΈ ΒΫΆχ…œΒΡΉ ‘¥Θ§»γΙϊ–ιΡβΜζάοΟφ≤Ω π“ΜΗωΆχ’ΨΘ§“≤œΘΆϊ±π»ΥΡήΙΜΖΟΈ ΒΫΥϊΓΘ
’β“ΜΖΫΟφ“άάΒ”Ύqemu-KVMΒΡΆχ¬γ–ιΡβΜ·Θ§ΫΪΆχ¬γΑϋ¥”–ιΡβΜζάοΟφ¥Ϊ≤ΞΒΫ–ιΡβΜζΆβΟφΘ§’β–η“ΣΈοάμΜζΡΎΚΥΉΣΜΜ“ΜΑ―Θ§–Έ≥…–ιΡβΜζΡΎ≤ΩΒΡΆχΩ®ΚΆ–ιΡβΜζΆβ≤ΩΒΡ–ιΡβΆχΩ®ΓΘ

ΝμΆβ“ΜΖΫΟφΨΆ «–ιΡβΜζΒΡΆχ¬γ»γΚΈΡήΙΜΝ§Ϋ”ΒΫΈοάμΆχ¬γάοΟφΓΘΈοάμΆχ¬γ≥Θ≥Θ≥ΤΈΣunderlay networkΘ§–ιΡβΆχ¬γ≥Θ≥Θ≥ΤΈΣoverlay
networkΘ§¥”ΈοάμΆχ¬γΒΫ–ιΡβΆχ¬γ≥ΤΈΣΆχ¬γ–ιΡβΜ·Θ§ΡήΖ«≥ΘΚΟΒΡΆξ≥…’βΦΰ ¬«ιΒΡ «“ΜΗωΫ–OpenvswitchΒΡ–ιΡβΫΜΜΜΜζ»μΦΰΓΘ

OpenvswitchΜα”–“ΜΗωΡΎΚΥ«ΐΕ·Θ§ΦύΧΐΈοάμΆχΩ®Θ§Ω…“‘ΫΪΈοάμΆχΩ®…œ ’ΒΫΒΡΑϋΡΟΫχά¥ΓΘ–ιΡβΜζ¥¥Ϋ®≥ωά¥ΒΡΆβ≤ΩΒΡ–ιΡβΆχΩ®“≤Ω…“‘ΧμΦ”ΒΫOpenvswitch…œΘ§ΕχOpenvswitchΩ…“‘…ηΕ®Ης÷÷ΒΡΆχ¬γΑϋ¥Πάμ≤Ώ¬‘Θ§ΫΪΆχ¬γΑϋ‘Ύ–ιΡβΜζΚΆΈοάμΜζ÷°ΦδΫχ––¥ΪΒίΘ§¥”Εχ Βœ÷ΝΥΆχ¬γ–ιΡβΜ·ΓΘ

ΑΥΓΔΜυ”ΎOpenStackΝΥΫβ‘ΤΤΫΧ®
Β±”–ΝΥ–ιΡβΜζΘ§≤Δ«“–ιΡβΜζΡήΙΜ…œΆχΝΥ÷°ΚσΘ§Ϋ”œ¬ά¥ΨΆ «¥νΫ®‘ΤΤΫΧ®ΒΡ ±ΚρΝΥΓΘ
‘Τ «Μυ”ΎΦΤΥψΘ§Άχ¬γΘ§¥φ¥Δ–ιΡβΜ·ΦΦ θΒΡΘ§‘ΤΚΆ–ιΡβΜ·ΒΡ÷ς“Σ«χ±π‘Ύ”ΎΘ§Ιήάμ‘±ΒΡΙήάμΡΘ Ϋ≤ΜΆ§Θ§”ΟΜßΒΡ Ι”ΟΡΘ Ϋ“≤≤ΜΆ§ΓΘ
–ιΡβΜ·ΤΫΧ®ΟΜ”–Εύ≤ψ¥ΈΒΡΖαΗΜΒΡΉβΜßΙήάμΘ§ΟΜ”–ΝιΜνquota≈δΕνΒΡœό÷ΤΘ§ΟΜ”–ΝιΜνΒΡQoSΒΡœό÷ΤΘ§Εύ≤…”Ο–ιΡβΆχ¬γΚΆΈοάμΆχ¬γ¥ρΤΫΒΡ«≈Ϋ”ΡΘ ΫΘ§–ιΡβΜζ÷±Ϋ” Ι”ΟΜζΖΩΆχ¬γΘ§ΟΜ”––ιΡβΉ”ΆχVPCΒΡΗ≈ΡνΘ§–ιΡβΆχ¬γΒΡΙήάμΚΆΗτάκ≤ΜΡήΚΆΉβΜßΗτάκΆξ»Ϊ”≥…δΤπά¥ΓΘΕ‘”Ύ¥φ¥Δ“≤ «Θ§ΙΪΥΨ≤…ΙΚΝΥΆ≥“ΜΒΡ¥φ¥ΔΘ§“≤≤ΜΡήΚΆΉβΜßΒΡΗτάκΆξ»Ϊ”≥…δΤπά¥ΓΘ
Ι”Ο–ιΡβΜ·ΤΫΧ®ΒΡΧΊΒψ «Θ§Ε‘”Ύ’βΗωΤΫΧ®ΒΡ≤ΌΉςΆξ»Ϊ”…‘ΥΈ§≤ΩΟ≈Ά≥“ΜΙήάμΘ§Εχ≤ΜΡήΫΪ»®œόœ¬Ζ≈Ηχ“ΒΈώ≤ΩΟ≈Ή‘ΦΚΫχ––≤ΌΉςΓΘ“ρΈΣ“ΜΒ©‘ –μ≤ΜΆ§ΒΡ≤ΩΟ≈Ή‘ΦΚ≤ΌΉςΘ§¥σΦ“ΕΦ”ΟΜζΖΩΆχ¬γΘ§‘ΎΟΜ”–Ά≥“ΜΙήΩΊΒΡ«ιΩωœ¬Θ§Κή»ί“ΉΆχΕΈ≥εΆΜΝΥΓΘ»γΙϊ“ΒΈώ≤ΩΟ≈œρ…ξ«κ–ιΡβΜζΘ§–η“ΣΆ®ΙΐΙΛΒΞœρ‘ΥΈ§≤ΩΟ≈Ά≥“ΜΒΡ…ξ«κΓΘΒ±»Μ’βΗω‘ΥΈ§≤ΩΟ≈Κή ”Π’β÷÷ΖΫ ΫΘ§“ρΈΣ‘≠ά¥ΈοάμΜζΨΆ «’β―υΙήάμΒΡΓΘ
ΒΪ «ΙΪ”–‘ΤΘ§άΐ»γawsΨΆΟΜΑλΖ®’β―υΘ§ΉβΜß«ß«ßΆρΆρΘ§÷ΜΡήΥϊΟ«Ή‘ΦΚ≤ΌΉςΓΘ‘ΎΥΫ”–‘ΤάοΟφΘ§ΥφΉ≈ΖΰΈώΜ·…θ÷ΝΈΔΖΰΈώΜ·ΒΡΫχ––Θ§ΖΰΈώ ΐΡΩ‘Ϋά¥‘ΫΕύΘ§Βϋ¥ζΥΌΕ»‘Ϋά¥‘ΫΩλΘ§“ΒΈώ≤ΩΟ≈–η“ΣΗϋΦ”ΤΒΖ±ΒΡ¥¥Ϋ®ΚΆœϊΚΡ–ιΡβΜζΘ§»γΙϊΜΙ «”…‘ΥΈ§≤ΩΆ≥“Μ…σ≈ζΘ§Ά≥“Μ≤ΌΉςΘ§Μα ΙΒΟ‘ΥΈ§≤ΩΟ≈―ΙΝΠΖ«≥Θ¥σΘ§Εχ«“ΦΪ¥σœό÷ΤΝΥΒϋ¥ζΥΌΕ»Θ§“ρΕχ“Σ“ΐ»κ
ΉβΜßΙήάμΘ§‘ΥΈ§≤ΩΝιΜν≈δ÷ΟΟΩΗωΉβΜßΒΡ≈δΕνquotaΚΆQoSΘ§‘Ύ’βΗω≈δΕνάοΟφΘ§“ΒΈώ≤ΩΟ≈Υφ ±Ω…“‘Α¥’’Ή‘ΦΚΒΡ–η“ΣΘ§¥¥Ϋ®ΚΆ…Ψ≥ΐ–ιΡβΜζΘ§Έό–η÷ΣΜα‘ΥΈ§≤ΩΟ≈ΓΘΟΩΗω≤ΩΟ≈ΕΦΩ…“‘¥¥Ϋ®Ή‘ΦΚΒΡ–ιΡβΆχ¬γVPCΘ§≤ΜΆ§ΉβΜßΒΡVPC÷°«ΑΆξ»ΪΗτάκΘ§Υυ“‘ΆχΕΈΩ…“‘≥εΆΜΘ§ΟΩΗω“ΒΈώ≤ΩΟ≈Ή‘ΦΚΙφΜ°Ή‘ΦΚΒΡΆχ¬γΦήΙΙΘ§÷Μ”–…Ό ΐΒΡΜζΤς–η“Σ±ΜΆβΆχΜρ’ΏΜζΖΩΖΟΈ ΒΡ ±ΚρΘ§–η“Σ…Ό ΐΒΡΜζΖΩIPΘ§’βΗω“≤ «ΚΆΉβΜß”≥…δΤπά¥ΒΡΘ§Ω…“‘Ζ÷≈δΗχ“ΒΈώ≤ΩΟ≈ΜζΖΩΆχIPΒΡΗω ΐΖΕΈßΡΎΘ§Ή‘”…ΒΡ Ι”ΟΓΘ’β―υΟΩΗω≤ΩΟ≈Ή‘÷ς≤ΌΉςΘ§Βϋ¥ζΥΌΕ»ΨΆΡήΙΜΦ”ΩλΝΥΓΘ
‘ΤΤΫΧ®÷–ΒΡΩΣ‘¥»μΦΰΒΡ¥ζ±μ «OpenStackΘ§Ϋ®“ι¥σΦ“―–ΨΩOpenStackΒΡ…ηΦΤΜζ÷ΤΘ§ «‘Ύ‘ΤάοΟφΆ®”ΟΒΡΘ§ΝΥΫβΝΥOpenStackΘ§Ε‘”ΎΙΪ”–‘ΤΘ§»ίΤς‘ΤΘ§ΕΦΡήΖΔœ÷œύΥΤΒΡΗ≈ΡνΚΆΜζ÷ΤΓΘ
―ΊΉ≈OpenStack¥¥Ϋ®–ιΡβΜζΒΡΙΐ≥ΧΘ§Έ“ΉήΫαΝΥ100Ηω÷Σ ΕΒψΘ§–¥œ¬ΝΥœ¬ΟφΒΡΈΡ’¬ΓΘ
OpenStack–ιΡβΜζ¥¥Ϋ®ΒΡ50Ηω≤Ϋ÷ηΚΆ100Ηω÷Σ ΕΒψ
”ΟOpenStackΫγΟφ«αΥ…¥¥Ϋ®–ιΡβΜζΒΡΡψΘ§Ω¥ΒΟΕ°–ιΡβΜζΤτΕ·ΒΡ’β24Ηω≤Έ ΐΟ¥ΘΩ
ΨθΒΟOpenStackΒΡΆχ¬γΗ¥‘”ΘΩΤδ ΒΡψΦ“άοΨΆ”–Ά§―υ“ΜΗωΆχ¬γ
Β±ΖΔœ÷ΡψΒΡOpenStack–ιΡβΜζΆχ¬γ”–Έ ΧβΘ§≤ΜΖΝœ» ‘“Μœ¬’β16Ηω≤Ϋ÷η
÷Ε·”ΟKVMΡΘΡβOpenStack CinderΙ“‘ΊiSCSIΨμ
≤ΜΫωDockerΜα Ι”ΟControl GroupΘ§KVM“≤Μα Ι”ΟCgroupά¥ΩΊ÷ΤΉ ‘¥Ζ÷≈δ
Ά®ΙΐΈ“Ο«―–ΨΩOpenStackΘ§Έ“Ο«ΜαΖΔœ÷ΚήΕύΖ«≥ΘΚΟΒΡ‘ΤΤΫΧ®…ηΦΤΡΘ ΫΓΘ
ΒΎ“ΜΘΚΜυ”ΎPKI TokenΒΡ»œ÷ΛΡΘ Ϋ
»γΙϊΈ“Ο«“Σ Βœ÷“ΜΗωRestful APIΘ§œΘΆϊ”–ΗωΆ≥“ΜΒΡ»œ÷Λ÷––ΡΒΡΜΑΘ§KeystoneΒΡ»ΐΫ«–ΈΙΛΉςΡΘ Ϋ «≥Θ”ΟΒΡΓΘ
Β±Έ“Ο«“ΣΖΟΈ “ΜΗωΉ ‘¥Θ§Ά®Ιΐ”ΟΜßΟϊΟή¬κΜρ’ΏAK/SKΒ«¬Φ÷°ΚσΘ§»γΙϊ»œ÷ΛΆ®ΙΐΘ§Ϋ”œ¬ά¥Ε‘”ΎΉ ‘¥ΒΡΖΟΈ Θ§≤Μ”ΠΗΟΉή¥χΉ≈”ΟΜßΟϊΟή¬κΘ§Εχ «Β«¬ΦΒΡ ±Κρ–Έ≥…“ΜΗωTokenΘ§»ΜΚσΖΟΈ Ή ‘¥ΒΡ ±Κρ¥χΉ≈TokenΘ§ΖΰΈώΕΥΆ®ΙΐToken»Ξ»œ÷Λ÷––ΡΫχ––―ι÷ΛΦ¥Ω…ΓΘ

»γΙϊΟΩ¥Έ―ι÷ΛΕΦ»Ξ»œ÷Λ÷––ΡΘ§–߬ ±»Ϋœ≤νΘ§Κσά¥ΨΆ”–ΝΥPKI TokenΘ§“≤Φ¥TokenΫβΟή≥ωά¥ «“ΜΗω”–œξœΗΉβΜß–≈œΔΒΡΉ÷Ζϊ¥°Θ§’β―υ±ΨΒΊΨΆΩ…“‘Ϋχ––»œ÷ΛΚΆΦχ»®ΓΘ

ΒΎΕΰΘΚΜυ”ΎRole Based Access ControlΒΡΦχ»®ΡΘ Ϋ
Ε‘”Ύ»®œόΩΊ÷ΤΘ§Έ“Ο«―ßΜα±»ΫœΆ®”ΟΒΡRole Based Access ControlΒΡ»®œόΩΊ÷ΤΡΘ ΫΘ§
–Έ≥…ΓΑ”ΟΜß-Ϋ«…Ϊ-»®œόΓ±ΒΡ Ύ»®ΡΘ–ΆΓΘ‘Ύ’β÷÷ΡΘ–Ά÷–Θ§”ΟΜß”κΫ«…Ϊ÷°ΦδΘ§Ϋ«…Ϊ”κ»®œό÷°ΦδΘ§“ΜΑψ’Ώ «ΕύΕ‘ΕύΒΡΙΊœΒΘ§Ω…“‘Ζ«≥ΘΝιΜνΒΡΩΊ÷Τ»®œόΓΘ

ΒΎ»ΐΘΚΜυ”ΎQuotaΒΡ≈δΕνΙήάμ
Ω…“‘Ά®Ιΐ…η÷ΟΦΤΥψΘ§Άχ¬γΘ§¥φ¥ΔΒΡquotaΘ§…η÷ΟΡ≥ΗωΉβΜßΉ‘ΦΚΩ…“‘Ή‘÷ς≤ΌΉςΒΡΉ ‘¥ΝΩΓΘ
ΒΎΥΡΘΚΜυ”Ύ‘Λ―ΓΚΆ”≈―ΓΝΫΫΉΕΈΒΡSchedulerΜζ÷Τ
Β±–η“Σ¥”“ΜΗωΉ ‘¥≥ΊάοΟφΘ§―Γ‘ώ“ΜΗωΫΎΒψΘ§ Ι”Ο’βΗωΫΎΒψ…œΒΡΉ ‘¥ΒΡ ±ΚρΘ§“ΜΗωΆ®”ΟΒΡSchedulerΜζ÷Τ «ΘΚ
Ήœ»Ϋχ––‘Λ―ΓΘ§“≤Φ¥Ά®ΙΐFilterΘ§ΫΪ≤Μ¬ζΉψΧθΦΰΒΡΙΐ¬ΥΒτΓΘ
»ΜΚσΫχ––”≈―ΓΘ§“≤Φ¥Ε‘”ΎΙΐ¬ΥΚσΘ§¬ζΉψΧθΦΰΒΡΚρ―Γ»ΥΘ§Ά®ΙΐΦΤΥψ»®÷ΊΘ§―Γ‘ώΤδ÷–Ήν”≈ΒΡΓΘ

ΒΎΈεΘΚΜυ”ΎΕάΝΔ–ιΡβΉ”ΆχΒΡΆχ¬γΡΘ Ϋ
ΈΣΝΥΟΩΗωΉβΜßΩ…“‘ΕάΝΔ≤ΌΉςΘ§“ρΕχ–ιΡβΆχ¬γ”ΠΗΟ «ΕάΝΔ”ΎΈοάμΆχ¬γΒΡΘ§’β―υ≤ΜΆ§ΒΡΉβΜßΩ…“‘Ϋχ––ΕάΝΔΒΡΆχ¬γΙφΜ°ΕχΜΞ≤Μ”ΑœλΘ§“≤≤Μ”ΑœλΈοάμΆχ¬γΘ§Β±–η“ΣΩγΉβΜßΖΟΈ Θ§Μρ’Ώ“ΣΖΟΈ ΈοάμΆχ¬γΒΡ ±ΚρΘ§–η“ΣΆ®Ιΐ¬Ζ”…ΤςΓΘ

ΒΎΝυΘΚΜυ”ΎCopy on WriteΒΡΨΒœώΜζ÷Τ
”– ±ΚρΈ“Ο«‘Ύ–ιΡβΜζάοΟφΉωΝΥ“Μ–©≤ΌΉς“‘ΚσΘ§œΘΆϊΡήΙΜΑ―’βΗω ±ΚρΒΡΨΒœώ±Θ¥φœ¬ά¥Θ§ΚΟΥφ ±Μ÷Η¥ΒΫ’βΗω ±ΦδΒψΘ§“ΜΗωΉνΉνΦρΒΞΒΡΖΫΖ®ΨΆ «Άξ»ΪΗ¥÷Τ“ΜΖίΘ§ΒΪ «”…”ΎΨΒœώΧΪ¥σΝΥΘ§’β―υ–߬ Κή≤νΓΘ“ρΕχ≤…»ΓCopy
on writeΒΡΜζ÷ΤΘ§Β±¥ρΨΒœώΒΡ ±ΩΧΘ§≤ΔΟΜ”––¬ΒΡ¥φ¥ΔœϊΚΡΘ§Εχ «Β±–¥»κ–¬ΒΡΕΪΈςΒΡ ±ΚρΘ§ΫΪ‘≠ά¥ΒΡ ΐΨί’““ΜΗωΒΊΖΫΗ¥÷Τ±Θ¥φœ¬ά¥Θ§’βΨΆ «Copy
on WriteΓΘ
Ε‘”ΎOpenstackΘ§”–“Μ÷÷ΨΒœώqcow2ΨΆ «≤…»ΓΒΡ’β―υΒΡΜζ÷ΤΓΘ

’β―υΨΒœώΨΆœώΖ÷≤ψ“Μ―υΘ§“Μ≤ψ“Μ≤ψΒΡ¬ό…œ»ΞΓΘ
ΒΎΤΏΘΚΜυ”ΎnamespaceΚΆcgroupΒΡΗτάκΚΆQosΜζ÷Τ
‘ΎOpenStackάοΟφΘ§Άχ¬γΫΎΒψΒΡ¬Ζ”…Τς «”…network namespaceά¥ΗτάκΒΡΓΘ
KVMΒΡ’Φ”ΟΒΡCPUΚΆΡΎ¥φΘ§ Ι”ΟCgroupά¥ΗτάκΒΡΓΘ

Άχ¬γΒΡQoS Ι”ΟTCά¥ΗτάκΒΡΓΘ

ΒΎΑΥΘΚΜυ”ΎiptablesΒΡΑ≤»ΪΜζ÷Τ
”– ±ΚρΘ§Έ“Ο«œΘΆϊΆχ¬γ÷–ΒΡΫΎΒψ÷°Φδ≤ΜΡήœύΜΞΖΟΈ Θ§ΉςΈΣΉνΦρΒΞΒΡΖάΜπ«ΫΘ§iptablesΤπΒΫΝΥΚή÷Ί“ΣΒΡΉς”ΟΘ§“‘Κσ Βœ÷ACLΜζ÷ΤΒΡΘ§ΕΦΩ…“‘ΩΦ¬« Ι”ΟiptablesΓΘ
Ψ≈ΓΔΜυ”ΎMesosΚΆKubernetesΝΥΫβ»ίΤςΤΫΧ®
¥νΫ®Άξ±œ–ιΡβΜ·≤ψΚΆ‘ΤΤΫΧ®≤ψΘ§Ϋ”œ¬ά¥ΨΆ «»ίΤς≤ψΝΥΓΘ
Docker”–ΦΗΗωΚΥ–ΡΦΦ θΘ§“ΜΗω «ΨΒœώΘ§“ΜΗω «‘Υ–– ±Θ§‘Υ–– ±”÷Ζ÷Ω¥Τπά¥ΗτάκΒΡnamespaceΚΆ”ΟΤπά¥ΗτάκΒΡcgroupΓΘ
DockerΒΡΨΒœώ“≤ «“Μ÷÷Copy on WriteΒΡΨΒœώΗώ ΫΘ§œ¬ΟφΒΡ≤ψΦΕ «÷ΜΕΝΒΡΘ§Υυ”–ΒΡ–¥»κΕΦ‘ΎΉν…œ≤ψΓΘ

Ε‘”Ύ‘Υ–– ±Θ§Docker Ι”ΟΒΡnamespace≥ΐΝΥnetwork namespaceΆβΘ§ΜΙ”–ΚήΕύΘ§»γœ¬±μΗώΥυ ΨΓΘ

DockerΕ‘”ΎcgroupΒΡ Ι”Ο «‘Ύ‘Υ––DockerΒΡ ±ΚρΘ§‘Ύ¬ΖΨΕ/sys/fs/cgroup/cpu/docker/œ¬ΟφΩΊ÷Τ»ίΤς‘Υ–– Ι”ΟΒΡΉ ‘¥ΓΘ
Ω…Φϊ»ίΤς≤ΔΟΜ”– Ι”ΟΗϋ–¬ΒΡΦΦ θΘ§Εχ «“Μ÷÷–¬–ΆΒΡΫΜΗΕΖΫ ΫΘ§“≤Φ¥”Π”ΟΒΡΫΜΗΕ”ΠΗΟ «“Μ»ίΤςΨΒœώΒΡΖΫ ΫΫΜΗΕΘ§»ίΤς“ΜΒ©ΤτΕ·Τπά¥Θ§ΨΆ≤Μ”ΠΗΟΫχ»κ»ίΤςΉωΗς÷÷–όΗΡΘ§’βΨΆ «≤ΜΩ…ΗΡ±δΜυ¥Γ…η ©ΓΘ
”…”Ύ»ίΤςΒΡΨΒœώ≤ΜΑϋΚ§≤ΌΉςœΒΆ≥ΡΎΚΥΘ§“ρΕχ–ΓΒΡΕύΘ§Ω…“‘Ϋχ––ΩγΜΖΨ≥ΒΡ«®“ΤΚΆΒ·–‘…λΥθΓΘ
Έ“–¥œ¬ΝΥœ¬ΟφΒΡΈΡ’¬Θ§ΉήΫαΝΥΦΗΒψ»ίΤςΒΡ’ΐ»Ζ Ι”ΟΉΥ ΤΓΘ
»ίΤςΜ·ΒΡ±Ψ÷ ΘΩΜυ”ΎΨΒœώΒΡΩγΜΖΨ≥«®“Τ
”–ΙΊ»ίΤςΒΡΝυ¥σΈσ«χΚΆΑΥ¥σ’ΐ»Ζ≥ΓΨΑ
”–ΝΥ»ίΤς÷°ΚσΘ§Ϋ”œ¬ά¥ΨΆ «»ίΤςΤΫΧ®ΒΡ―Γ–ΆΘ§Τδ Βswarm, mesos, kubernetesΗς”–”≈ ΤΘ§“≤Ω…“‘‘Ύ≤ΜΆ§ΒΡΫΉΕΈΘ§―Γ‘ώ Ι”Ο≤ΜΆ§ΒΡ»ίΤςΤΫΧ®ΓΘ
Docker, Kubernetes, DCOS ≤ΜΧΗ–≈―ωΧΗΦΦ θ
»ίΤςΤΫΧ®―Γ–ΆΒΡ °¥σΡΘ ΫΘΚDockerΓΔDC/OSΓΔK8SΥ≠”κΒ±œ»ΘΩ
Μυ”ΎMesosΒΡDCOSΗϋœώ «“ΜΗω ΐΨί÷––ΡΙήάμΤΫΧ®Θ§ΕχΖ«ΫωΫω»ίΤςΙήάμΤΫΧ®Θ§ΥϊΩ…“‘Φφ»ίKubernetesΒΡ±ύ≈≈Θ§Ά§ ±“≤Ρή≈ήΗς÷÷¥σ ΐΨί”Π”ΟΓΘ
DC/OSΒΡΜυ±ΨΥΦœκΓΣΓΣΈΣ ≤Ο¥ΥΒΥϊ « ΐΨί÷––Ρ≤ΌΉςœΒΆ≥
Κ≈≥ΤΝΥΫβmesosΥΪ≤ψΒςΕ»ΒΡΡψΘ§œ»ά¥ΜΊ¥πœ¬Οφ’βΈεΗωΈ ΧβΘΓ
DC/OSΒΡ»ίΤςΙΠΡή
DC/OSΒΡΆχ¬γΙΠΡή
DC/OSΒΡ¥φ¥ΔΙΠΡή
DC/OSΒΡΖΰΈώΖΔœ÷”κΗΚ‘ΊΨυΚβΙΠΡή
‘Ύ»ίΤςΝλ”ρΘ§Μυ”ΎKubernetesΒΡ»ίΤς±ύ≈≈“―Ψ≠≥…ΈΣ ¬ Β±ξΉΦΓΘ
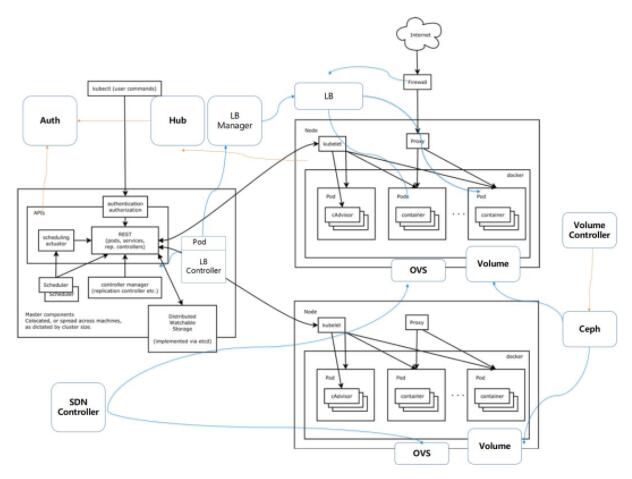
Μυ”ΎΆρΫΎΒψKubernetes÷ß≥≈¥σΙφΡΘ‘Τ”Π”Ο ΒΦυ
÷ß≥≈¥σΙφΡΘΙΪ”–‘ΤΒΡKubernetesΗΡΫχ”κ”≈Μ· (1)
÷ß≥≈¥σΙφΡΘΙΪ”–‘ΤΒΡKubernetesΗΡΫχ”κ”≈Μ· (2)
÷ß≥≈¥σΙφΡΘΙΪ”–‘ΤΒΡKubernetesΗΡΫχ”κ”≈Μ· (3)
ΈΣ÷ß≥≈ΗΏ≤ΔΖΔ”Π”ΟΒΡ Kubernetes ΒΡ–‘Ρή”≈Μ·
Β±Έ“Ο«…ν»κΖ÷ΈωKubernetesΙήάμ»ίΤςΡΘ ΫΒΡ ±ΚρΘ§Έ“Ο«“≤ΡήΩ¥ΒΫ λœΛΒΡΟφΩΉΓΘ
‘ΎKubernetesάοΟφΘ§ΉβΜß÷°ΦδΩΩnamespaceΫχ––ΗτάκΘ§’βΗω≤Μ «DockerΒΡnamespaceΘ§Εχ «KubernetesΒΡΗ≈ΡνΓΘ
API ServerΒΡΦχ»®Θ§“≤ «Μυ”ΎRole Based Access ControlΡΘ ΫΓΘ
KubernetesΕ‘”ΎnamespaceΘ§“≤”–Quota≈δ÷ΟΘ§ Ι”ΟResourceQuotaΓΘ

Β±Kubernetesœκ―Γ‘ώ“ΜΗωΫΎΒψ‘Υ––podΒΡ ±ΚρΘ§―Γ‘ώΒΡΙΐ≥Χ“≤ «Ά®Ιΐ‘Λ―ΓΚΆ”≈―ΓΝΫΗωΫΉΕΈΓΘ
‘Λ―Γ(Filtering)
PodFitsResources¬ζΉψΉ ‘¥
PodSelectorMatchesΖϊΚœ±ξ«©
PodFitsHostΖϊΚœΫΎΒψΟϊ≥Τ
”≈―Γ(Weighting)
LeastRequestedPriorityΉ ‘¥œϊΚΡΉν–Γ
BalancedResourceAllocationΉ ‘¥ Ι”ΟΉνΨυΚβ
KubernetesΙφΕ®ΝΥ“‘œ¬ΒΡΆχ¬γΡΘ–ΆΕ®“εΓΘ
Υυ”–ΒΡ»ίΤςΕΦΩ…“‘‘Ύ≤Μ Ι”ΟNATΒΡ«ιΩωœ¬Ά§±πΒΡ»ίΤςΆ®–≈
Υυ”–ΒΡΫΎΒψΕΦΩ…“‘‘Ύ≤Μ Ι”ΟNATΒΡ«ιΩωœ¬Ά§Υυ”–ΒΡ»ίΤςΆ®–≈
»ίΤςΒΡΒΊ÷ΖΚΆ±π»ΥΩ¥ΒΫΒΡΒΊ÷Ζ“Μ―υ
“≤Φ¥»ίΤςΤΫΧ®”ΠΗΟ”–Ή‘ΦΚΒΡΥΫ”–Ή”ΆχΘ§≥Θ”ΟΒΡ”–Flannel, Calico, OpenvswitchΕΦ «Ω…“‘ΒΡΓΘ
Φ»Ω…“‘ Ι”ΟOverlayΒΡΖΫ ΫΘ§»γΆΦflannel.

“≤Ω…“‘ Ι”ΟBGPΒΡΖΫ ΫΘ§»γΆΦCalico

°ΓΔΜυ”ΎHadoopΚΆSparkΝΥΫβ¥σ ΐΨίΤΫΧ®
Ε‘”Ύ ΐΨίΦήΙΙΒΡ≤ΩΖ÷Θ§Τδ ΒΨ≠άζΝΥ»ΐΗωΙΐ≥ΧΘ§Ζ÷±π «Hadoop Map-Reduce 1.0Θ§Μυ”ΎYarnΒΡMap-Reduce
2.0, ΜΙ”–SparkΓΘ
»γœ¬ΆΦ «Map-Reduce 1.0ΒΡΙΐ≥ΧΓΘ

Map-ReduceΒΡΙΐ≥ΧΫΪ“ΜΗω¥σ»ΈΈώΘ§split≥ΤΈΣΕύΗωMap TaskΘ§Ζ÷…ΔΒΫΕύΧ®ΜζΤς≤Δ––¥ΠάμΘ§ΫΪ¥ΠάμΒΡΫαΙϊ±Θ¥φΒΫ±ΨΒΊΘ§ΒΎΕΰΗωΫΉΕΈΘ§Reduce
TaskΫΪ÷–ΦδΫαΙϊΩΫ±¥Ιΐά¥Θ§ΫΪΫαΙϊΦ·÷–¥ΠάμΘ§»ΓΒΟΉν÷’ΫαΙϊΓΘ
‘ΎMap-Reduce 1.0ΒΡ ±ΚρΘ§≈ή»ΈΈώΒΡΖΫ Ϋ÷Μ”–’β“Μ÷÷Θ§ΈΣΝΥ”ΠΕ‘Η¥‘”ΒΡ≥ΓΨΑΘ§ΫΪ»ΈΈώΒΡΒςΕ»ΚΆΉ ‘¥ΒΡΒςΕ»Ζ÷≥…ΝΫ≤ψΓΘΤδ÷–Ή ‘¥ΒΡΒς”Ο”…YarnΫχ––Θ§Yarn≤ΜΙή «MapΜΙ «ReduceΘ§÷Μ“ΣœρΥϊ«κ«σΘ§ΥϊΨΆ’“ΒΫΩ’œ–ΒΡΉ ‘¥Ζ÷≈δΗχΥϊΓΘ
ΟΩΗω»ΈΈώΤτΕ·ΒΡ ±ΚρΘ§Ή®Ο≈ΤτΕ·“ΜΗωApplication MasterΘ§Ιήάμ»ΈΈώΒΡΒςΕ»Θ§Υϊ «÷ΣΒάMapΚΆReduceΒΡΓΘ’βΨΆ «Map-Reduce
2.0»γœ¬ΆΦΓΘ

’βάοYarnœύΒ±”ΎΆβΑϋΙΪΥΨΒΡάœΑεΘ§Υυ”–ΒΡ‘±ΙΛΕΦ «workerΘ§ΕΦ «ΥϊΒΡΉ ‘¥Θ§ΆβΑϋΙΪΥΨΒΡάœΑε «≤Μ«ε≥ΰΫ”ΒΡΟΩ“ΜΗωœνΡΩΒΡΓΘ
Application MasterœύΒ±”ΎΫ”ΒΡΟΩΗωœνΡΩΒΡœνΡΩΨ≠άμΘ§Υϊ «÷ΣΒάœνΡΩΒΡΨΏΧε«ιΩωΒΡΘ§Υϊ‘Ύ÷¥––œνΡΩΒΡ ±ΚρΘ§»γΙϊ–η“Σ‘±ΙΛΗ…ΜνΘ§–η“ΣœρΆβΑϋΙΪΥΨάœΑε…ξ«κΓΘ
Yarn «ΗωΆ®”ΟΒΡΒςΕ»ΤΫΧ®Θ§ΡήΙΜ≈ήMap-Reduce 2Θ§ΨΆΡή≈ήSparkΓΘ

Spark“≤ «¥¥Ϋ®SparkΉ‘ΦΚΒΡApplication MasterΘ§”Ο”ΎΒςΕ»»ΈΈώΓΘ
Spark÷°Υυ“‘±»ΫœΩλΘ§ «“ρΈΣ«ΑΤΎΙφΜ°ΉωΒΡΚΟΘ§≤Μ «œώMap-Reduce“Μ―υΘ§ΟΩ“Μ¥ΈΖ÷≈δ»ΈΈώΚΆΨέΚœ»ΈΈώΕΦ“Σ–¥“Μ¥Έ”≤≈ΧΘ§Εχ «ΫΪ»ΈΈώΖ÷≥…ΕύΗωΫΉΕΈΘ§ΫΪΥυ”–‘Ύ“ΜΗωMapΕΦΉωΝΥΒΡΚœ≥…“ΜΗωΫΉΕΈΘ§’β―υ÷–Φδ≤Μ”Ο¬δ≈ΧΘ§ΒΪ «ΒΫΝΥ–η“ΣΚœ≤ΔΒΡΒΊΖΫΘ§ΜΙ «–η“Σ¬δ≈ΧΒΡΓΘ
Ε‘”ΎHadoopΚΆSparkΒΡΜυ±Ψ‘≠άμΘ§Έ“–¥ΝΥœ¬ΟφΒΡΈΡ’¬ΓΘ
Ά®ΥΉΥΒΜυ”ΎYarnΒΡMap-ReduceΙΐ≥Χ
Ά®ΥΉΥΒSpark
’φ’ΐ–¥Map-Reduce≥Χ–ρΒΡ ±ΚρΘ§”–ΚήΕύΒΡΖΫΖ®¬έΘ§’βάοΈ“ΉήΫαΝΥΦΗΗωΘ§Ι©Ρζ≤ΈΩΦΓΘ
¥σ ΐΨίΖΫΖ®¬έ÷°”≈Μ·Map-ReduceΙΐ≥Χ
¥σ ΐΨίΖΫΖ®¬έ÷°Άχ“≥œϊ÷ΊΒΡMap-ReduceΥψΖ®
¥σ ΐΨίΖΫΖ®¬έ÷°PageRankΒΡMap-ReduceΦΤΥψ
¥σ ΐΨίΖΫΖ®¬έ÷°NutchΜυ”ΎMap-ReduceΒΡ≈ά»ΓΖΫΖ®
°“ΜΓΔΜυ”ΎLuceneΚΆElasticSearchΝΥΫβΥ―Υς“ΐ«φ

Β±¥σ ΐΨίΫΪ ’Φ·ΚΟΒΡ ΐΨί¥ΠάμΆξ±œ÷°ΚσΘ§“ΜΑψΜα±Θ¥φ‘ΎΝΫΗωΒΊΖΫΘ§“ΜΗω «’ΐœρΥς“ΐΘ§Ω…“‘”ΟHbaseΘ§CassandraΒ»ΈΡΒΒ¥φ¥ΔΘ§“ΜΗω «Ζ¥œρΥς“ΐΘ§ΖΫ±ψΥ―ΥςΘ§ΨΆΜα±Θ¥φ‘ΎΜυ”ΎLuceneΒΡElasticSearchάοΟφΓΘ
Ε‘”ΎLuceneΘ§‘Ύ÷Α“Β…ζ―ΡΒΡ‘γΤΎΘ§–¥Ιΐ“ΜΗωΓΕLucene ‘≠άμ”κ¥ζ¬κΖ÷ΈωΆξ’ϊΑφΓΖ”–500Εύ“≥ΓΘ
Ε‘”ΎΥ―Υς“ΐ«φΒΡΆ®”Ο‘≠άμΘ§–¥ΝΥœ¬ΟφΒΡΈΡ’¬ΓΘ
≤Μ «ΦΦ θ“≤ΡήΩ¥Ε°Υ―Υς“ΐ«φ
Υ―Υς“ΐ«φΒΡ…ηΦΤ(1)ΘΚ¥ ΒδΒΡ…ηΦΤ
Υ―Υς“ΐ«φΒΡ…ηΦΤ(2)ΘΚΒΙ≈≈±μΒΡ…ηΦΤ…œ
Υ―Υς“ΐ«φΒΡ…ηΦΤ(3)ΘΚΒΙ≈≈±μΒΡ…ηΦΤœ¬
°ΕΰΓΔΜυ”ΎSpringCloudΝΥΫβΈΔΖΰΈώ
ΉνΚσΒΫΝΥ”Π”ΟΦήΙΙΘ§“≤Φ¥ΈΔΖΰΈώΓΘ

Ϋ”œ¬ά¥œΗΥΒΈΔΖΰΈώΦήΙΙ…ηΦΤ÷–≤ΜΒΟ≤Μ÷ΣΒΡ °¥σ“ΣΒψΓΘ
…ηΦΤ“ΣΒψ“ΜΘΚΗΚ‘ΊΨυΚβ + API ΆχΙΊ

‘Ύ Β ©ΈΔΖΰΈώΒΡΙΐ≥Χ÷–Θ§≤ΜΟβ“ΣΟφΝΌΖΰΈώΒΡΨέΚœ”κ≤πΖ÷ΓΘ
Β±ΚσΕΥΖΰΈώΒΡ≤πΖ÷œύΕ‘±»ΫœΤΒΖ±ΒΡ ±ΚρΘ§ΉςΈΣ ÷Μζ App ά¥Ϋ≤Θ§ΆυΆυ–η“Σ“ΜΗωΆ≥“ΜΒΡ»κΩΎΘ§ΫΪ≤ΜΆ§ΒΡ«κ«σ¬Ζ”…ΒΫ≤ΜΆ§ΒΡΖΰΈώΘ§Έό¬έΚσΟφ»γΚΈ≤πΖ÷”κΨέΚœΘ§Ε‘”Ύ ÷ΜζΕΥά¥Ϋ≤ΕΦ «ΆΗΟςΒΡΓΘ
”–ΝΥ API ΆχΙΊ“‘ΚσΘ§ΦρΒΞΒΡ ΐΨίΨέΚœΩ…“‘‘ΎΆχΙΊ≤ψΆξ≥…Θ§’β―υΨΆ≤Μ”Ο‘Ύ ÷Μζ App ΕΥΆξ≥…Θ§¥”Εχ ÷Μζ
App ΚΡΒγΝΩΫœ–ΓΘ§”ΟΜßΧε―ιΫœΚΟΓΘ
”–ΝΥΆ≥“ΜΒΡ API ΆχΙΊΘ§ΜΙΩ…“‘Ϋχ––Ά≥“ΜΒΡ»œ÷ΛΚΆΦχ»®Θ§ΨΓΙήΖΰΈώ÷°ΦδΒΡœύΜΞΒς”Ο±»ΫœΗ¥‘”Θ§Ϋ”ΩΎ“≤Μα±»ΫœΕύΓΘ
API ΆχΙΊΆυΆυ÷Μ±©¬Ε±Ί–κΒΡΕ‘ΆβΫ”ΩΎΘ§≤Δ«“Ε‘Ϋ”ΩΎΫχ––Ά≥“ΜΒΡ»œ÷ΛΚΆΦχ»®Θ§ ΙΒΟΡΎ≤ΩΒΡΖΰΈώœύΜΞΖΟΈ ΒΡ ±ΚρΘ§≤Μ”Ο‘ΌΫχ––»œ÷ΛΚΆΦχ»®Θ§–߬ Μα±»ΫœΗΏΓΘ
”–ΝΥΆ≥“ΜΒΡ API ΆχΙΊΘ§Ω…“‘‘Ύ’β“Μ≤ψ…ηΕ®“ΜΕ®ΒΡ≤Ώ¬‘Θ§Ϋχ–– A/B ≤β ‘Θ§άΕ¬ΧΖΔ≤ΦΘ§‘ΛΖΔΜΖΨ≥ΒΦΝς»»ΓΘ
API ΆχΙΊΆυΆυ «ΈόΉ¥Χ§ΒΡΘ§Ω…“‘Καœρά©’ΙΘ§¥”Εχ≤ΜΜα≥…ΈΣ–‘ΡήΤΩΨ±ΓΘ
…ηΦΤ“ΣΒψΕΰΘΚΈόΉ¥Χ§Μ·”κΕάΝΔ”–Ή¥Χ§Φ·»Κ

”Αœλ”Π”Ο«®“ΤΚΆΚαœρά©’ΙΒΡ÷Ί“Σ“ρΥΊΨΆ «”Π”ΟΒΡΉ¥Χ§ΓΘΈόΉ¥Χ§ΖΰΈώΘ§ «“ΣΑ―’βΗωΉ¥Χ§ΆυΆβ“ΤΘ§ΫΪ Session
ΐΨίΘ§ΈΡΦΰ ΐΨίΘ§ΫαΙΙΜ· ΐΨί±Θ¥φ‘ΎΚσΕΥΆ≥“ΜΒΡ¥φ¥Δ÷–Θ§¥”Εχ”Π”ΟΫωΫωΑϋΚ§…ΧΈώ¬ΏΦ≠ΓΘ
Ή¥Χ§ «≤ΜΩ…±ήΟβΒΡΘ§άΐ»γ ZooKeeperΘ§DBΘ§Cache Β»Θ§Α―’β–©Υυ”–”–Ή¥Χ§ΒΡΕΪΈς ’Ν≤‘Ύ“ΜΗωΖ«≥ΘΦ·÷–ΒΡΦ·»ΚάοΟφΓΘ
’ϊΗω“ΒΈώΨΆΖ÷ΝΫ≤ΩΖ÷Θ§“ΜΗω «ΈόΉ¥Χ§ΒΡ≤ΩΖ÷Θ§“ΜΗω «”–Ή¥Χ§ΒΡ≤ΩΖ÷ΓΘ
ΈόΉ¥Χ§ΒΡ≤ΩΖ÷Ρή Βœ÷ΝΫΒψΘΚ
ΩγΜζΖΩΥφ“βΒΊ≤Ω πΘ§“≤Φ¥«®“Τ–‘ΓΘ
Β·–‘…λΥθΘ§Κή»ί“ΉΒΊΫχ––ά©»ίΓΘ
”–Ή¥Χ§ΒΡ≤ΩΖ÷Θ§»γ ZooKeeperΘ§DBΘ§Cache ”–Ή‘ΦΚΒΡΗΏΩ…”ΟΜζ÷ΤΘ§“Σάϊ”ΟΒΫΥϋΟ«Ή‘ΦΚΗΏΩ…”ΟΒΡΜζ÷Τά¥ Βœ÷’βΗωΉ¥Χ§ΒΡΦ·»ΚΓΘ
ΥδΥΒΈόΉ¥Χ§Μ·Θ§ΒΪ «Β±«Α¥ΠάμΒΡ ΐΨίΘ§ΜΙ «Μα‘ΎΡΎ¥φάοΟφΒΡΘ§Β±«ΑΒΡΫχ≥ΧΙ“Βτ ΐΨίΘ§ΩœΕ®“≤ «”–“Μ≤ΩΖ÷ΕΣ ßΒΡΓΘ
ΈΣΝΥ Βœ÷’β“ΜΒψΘ§ΖΰΈώ“Σ”–÷Ί ‘ΒΡΜζ÷ΤΘ§Ϋ”ΩΎ“Σ”–ΟίΒ»ΒΡΜζ÷ΤΘ§Ά®ΙΐΖΰΈώΖΔœ÷Μζ÷ΤΘ§÷Ί–¬Βς”Ο“Μ¥ΈΚσΕΥΖΰΈώΒΡΝμ“ΜΗω ΒάΐΨΆΩ…“‘ΝΥΓΘ
…ηΦΤ“ΣΒψ»ΐΘΚ ΐΨίΩβΒΡΚαœρά©’Ι

ΐΨίΩβ «±Θ¥φΉ¥Χ§Θ§ «Ήν÷Ί“ΣΒΡ“≤ «Ήν»ί“Ή≥ωœ÷ΤΩΨ±ΒΡΓΘ”–ΝΥΖ÷≤Φ Ϋ ΐΨίΩβΩ…“‘ Ι ΐΨίΩβΒΡ–‘ΡήΥφΉ≈ΫΎΒψ‘ωΦ”œΏ–‘ΒΊ‘ωΦ”ΓΘ
Ζ÷≤Φ Ϋ ΐΨίΩβΉνΉνœ¬Οφ « RDSΘ§ «÷ς±ΗΒΡΘ§Ά®Ιΐ MySQL ΒΡΡΎΚΥΩΣΖΔΡήΝΠΘ§Έ“Ο«ΡήΙΜ Βœ÷÷ς±Η«–ΜΜ ΐΨίΝψΕΣ ßΓΘ
Υυ“‘ ΐΨί¬δ‘Ύ’βΗω RDS άοΟφΘ§ «Ζ«≥ΘΖ≈–ΡΒΡΘ§ΡΡ≈¬ «Ι“ΝΥ“ΜΗωΫΎΒψΘ§«–ΜΜΆξΝΥ“‘ΚσΘ§ΡψΒΡ ΐΨί“≤ «≤ΜΜαΕΣΒΡΓΘ
‘ΌΆυ…œΨΆ «Καœρ‘θΟ¥≥–‘Ί¥σΒΡΆΧΆ¬ΝΩΒΡΈ ΧβΘ§…œΟφ”–“ΜΗωΗΚ‘ΊΨυΚβ NLBΘ§”Ο LVSΘ§HAProxyΘ§KeepalivedΘ§œ¬ΟφΫ”ΝΥ“Μ≤ψ
Query ServerΓΘ
Query Server «Ω…“‘ΗυΨίΦύΩΊ ΐΨίΫχ––Καœρά©’ΙΒΡΘ§»γΙϊ≥ωœ÷ΝΥΙ ’œΘ§Ω…“‘Υφ ±Ϋχ––ΧφΜΜΒΡ–όΗ¥Θ§Ε‘”Ύ“ΒΈώ≤ψ «ΟΜ”–»ΈΚΈΗ–÷ΣΒΡΓΘ
ΝμΆβ“ΜΗωΨΆ «ΥΪΜζΖΩΒΡ≤Ω πΘ§DDB ΩΣΖΔΝΥ“ΜΗω ΐΨί‘ΥΚ” NDC ΒΡΉιΦΰΘ§Ω…“‘ ΙΒΟ≤ΜΆ§ΒΡ DDB ÷°Φδ‘Ύ≤ΜΆ§ΒΡΜζΖΩάοΟφΫχ––Ά§≤ΫΓΘ
’β ±Κρ≤ΜΒΪ‘Ύ“ΜΗω ΐΨί÷––ΡάοΟφ «Ζ÷≤Φ ΫΒΡΘ§‘ΎΕύΗω ΐΨί÷––ΡάοΟφ“≤Μα”–“ΜΗωάύΥΤΥΪΜνΒΡ“ΜΗω±ΗΖίΘ§ΗΏΩ…”Ο–‘”–Ζ«≥ΘΚΟΒΡ±Θ÷ΛΓΘ
…ηΦΤ“ΣΒψΥΡΘΚΜΚ¥φ

‘ΎΗΏ≤ΔΖΔ≥ΓΨΑœ¬ΜΚ¥φ «Ζ«≥Θ÷Ί“ΣΒΡΓΘ“Σ”–≤ψ¥ΈΒΡΜΚ¥φΘ§ ΙΒΟ ΐΨίΨΓΝΩΩΩΫϋ”ΟΜßΓΘ ΐΨί‘ΫΩΩΫϋ”ΟΜßΡή≥–‘ΊΒΡ≤ΔΖΔΝΩ“≤‘Ϋ¥σΘ§œλ”Π ±Φδ‘ΫΕΧΓΘ
‘Ύ ÷ΜζΩΆΜßΕΥ App …œΨΆ”ΠΗΟ”–“Μ≤ψΜΚ¥φΘ§≤Μ «Υυ”–ΒΡ ΐΨίΕΦΟΩ ±ΟΩΩΧ¥”ΚσΕΥΡΟΘ§Εχ «÷ΜΡΟ÷Ί“ΣΒΡΘ§ΙΊΦϋΒΡΘ§ ±≥Θ±δΜ·ΒΡ ΐΨίΓΘ
”»ΤδΕ‘”ΎΨ≤Χ§ ΐΨίΘ§Ω…“‘Ιΐ“ΜΕΈ ±Φδ»Ξ»Γ“Μ¥ΈΘ§Εχ«““≤ΟΜ±Ί“ΣΒΫ ΐΨί÷––Ρ»Ξ»ΓΘ§Ω…“‘Ά®Ιΐ CDNΘ§ΫΪ ΐΨίΜΚ¥φ‘ΎΨύάκΩΆΜßΕΥΉνΫϋΒΡΫΎΒψ…œΘ§Ϋχ––ΨΆΫϋœ¬‘ΊΓΘ
”– ±Κρ CDN άοΟφΟΜ”–Θ§ΜΙ «“ΣΜΊΒΫ ΐΨί÷––Ρ»Ξœ¬‘ΊΘ§≥ΤΈΣΜΊ‘¥Θ§‘Ύ ΐΨί÷––ΡΒΡΉνΆβ≤ψΘ§Έ“Ο«≥ΤΈΣΫ”»κ≤ψΘ§Ω…“‘…η÷Ο“Μ≤ψΜΚ¥φΘ§ΫΪ¥σ≤ΩΖ÷ΒΡ«κ«σάΙΫΊΘ§¥”Εχ≤ΜΜαΕ‘ΚσΧ®ΒΡ ΐΨίΩβ‘λ≥…―ΙΝΠΓΘ
»γΙϊ «Ε·Χ§ ΐΨίΘ§ΜΙ «–η“ΣΖΟΈ ”Π”ΟΘ§Ά®Ιΐ”Π”Ο÷–ΒΡ…ΧΈώ¬ΏΦ≠…ζ≥…Θ§Μρ’Ώ»Ξ ΐΨίΩβΕΝ»ΓΘ§ΈΣΝΥΦθ«α ΐΨίΩβΒΡ―ΙΝΠΘ§”Π”ΟΩ…“‘ Ι”Ο±ΨΒΊΒΡΜΚ¥φΘ§“≤Ω…“‘ Ι”ΟΖ÷≤Φ ΫΜΚ¥φΓΘ
»γ Memcached Μρ’Ώ RedisΘ§ ΙΒΟ¥σ≤ΩΖ÷«κ«σΕΝ»ΓΜΚ¥φΦ¥Ω…Θ§≤Μ±ΊΖΟΈ ΐΨίΩβΓΘ
Β±»ΜΕ·Χ§ ΐΨίΜΙΩ…“‘Ήω“ΜΕ®ΒΡΨ≤Χ§Μ·Θ§“≤Φ¥ΫΒΦΕ≥…Ψ≤Χ§ ΐΨίΘ§¥”ΕχΦθ…ΌΚσΕΥΒΡ―ΙΝΠΓΘ
…ηΦΤ“ΣΒψΈεΘΚΖΰΈώ≤πΖ÷”κΖΰΈώΖΔœ÷

Β±œΒΆ≥ΩΗ≤ΜΉΓΘ§”Π”Ο±δΜ·ΩλΒΡ ±ΚρΘ§ΆυΆυ“ΣΩΦ¬«ΫΪ±»Ϋœ¥σΒΡΖΰΈώ≤πΖ÷ΈΣ“ΜœΒΝ––ΓΒΡΖΰΈώΓΘ
’β―υΒΎ“ΜΗωΚΟ¥ΠΨΆ «ΩΣΖΔ±»ΫœΕάΝΔΘ§Β±Ζ«≥ΘΕύΒΡ»Υ‘ΎΈ§ΜΛΆ§“ΜΗω¥ζ¬κ≤÷ΩβΒΡ ±ΚρΘ§ΆυΆυΕ‘¥ζ¬κΒΡ–όΗΡΨΆΜαœύΜΞ”ΑœλΓΘ
≥Θ≥ΘΜα≥ωœ÷Έ“ΟΜΗΡ ≤Ο¥≤β ‘ΨΆ≤ΜΆ®ΙΐΝΥΘ§Εχ«“¥ζ¬κΧαΫΜΒΡ ±ΚρΘ§Ψ≠≥ΘΜα≥ωœ÷≥εΆΜΘ§–η“ΣΫχ––¥ζ¬κΚœ≤ΔΘ§¥σ¥σΫΒΒΆΝΥΩΣΖΔΒΡ–ß¬ ΓΘ
Νμ“ΜΗωΚΟ¥ΠΨΆ «…œœΏΕάΝΔΘ§ΈοΝςΡΘΩιΕ‘Ϋ”ΝΥ“ΜΦ“–¬ΒΡΩλΒίΙΪΥΨΘ§–η“ΣΝ§Ά§œ¬ΒΞ“ΜΤπ…œœΏΘ§’β «Ζ«≥Θ≤ΜΚœάμΒΡ––ΈΣΓΘ
Έ“ΟΜΗΡΜΙ“ΣΈ“÷ΊΤτΘ§Έ“ΟΜΗΡΜΙ»ΟΈ“ΖΔ≤ΦΘ§Έ“ΟΜΗΡΜΙ“ΣΈ“ΩΣΜαΘ§ΕΦ «”ΠΗΟ≤πΖ÷ΒΡ ±ΜζΓΘ
‘ΌΨΆ «ΗΏ≤ΔΖΔ ±ΕΈΒΡά©»ίΘ§ΆυΆυ÷Μ”–ΉνΙΊΦϋΒΡœ¬ΒΞΚΆ÷ßΗΕΝς≥Χ «ΚΥ–ΡΘ§÷Μ“ΣΫΪΙΊΦϋΒΡΫΜ“ΉΝ¥¬ΖΫχ––ά©»ίΦ¥Ω…Θ§»γΙϊ’β ±ΚρΗΫ¥χΚήΕύΤδΥϊΒΡΖΰΈώΘ§ά©»ίΦ» «≤ΜΨ≠ΦΟΒΡΘ§“≤ «Κή”–Ζγœ’ΒΡΓΘ
ΝμΆβΒΡ»ί‘÷ΚΆΫΒΦΕΘ§‘Ύ¥σ¥ΌΒΡ ±ΚρΘ§Ω…Ρή–η“ΣΈΰ…ϋ“Μ≤ΩΖ÷ΒΡ±ΏΫ«ΙΠΡήΘ§ΒΪ «»γΙϊΥυ”–ΒΡ¥ζ¬κώνΚœ‘Ύ“ΜΤπΘ§ΚήΡ―ΫΪ±ΏΫ«ΒΡ≤ΩΖ÷ΙΠΡήΫχ––ΫΒΦΕΓΘ
Β±»Μ≤πΖ÷Άξ±œ“‘ΚσΘ§”Π”Ο÷°ΦδΒΡΙΊœΒΨΆΗϋΦ”Η¥‘”ΝΥΘ§“ρΕχ–η“ΣΖΰΈώΖΔœ÷ΒΡΜζ÷ΤΘ§ά¥Ιήάμ”Π”ΟœύΜΞΒΡΙΊœΒΘ§ Βœ÷Ή‘Ε·ΒΡ–όΗ¥Θ§Ή‘Ε·ΒΡΙΊΝΣΘ§Ή‘Ε·ΒΡΗΚ‘ΊΨυΚβΘ§Ή‘Ε·ΒΡ»ί¥μ«–ΜΜΓΘ
…ηΦΤ“ΣΒψΝυΘΚΖΰΈώ±ύ≈≈”κΒ·–‘…λΥθ

Β±ΖΰΈώ≤πΖ÷ΝΥΘ§Ϋχ≥ΧΨΆΜαΖ«≥ΘΒΡΕύΘ§“ρΕχ–η“ΣΖΰΈώ±ύ≈≈ά¥ΙήάμΖΰΈώ÷°ΦδΒΡ“άάΒΙΊœΒΘ§“‘ΦΑΫΪΖΰΈώΒΡ≤Ω π¥ζ¬κΜ·Θ§“≤ΨΆ «Έ“Ο«≥ΘΥΒΒΡΜυ¥Γ…η ©Φ¥¥ζ¬κΓΘ
’β―υΕ‘”ΎΖΰΈώΒΡΖΔ≤ΦΘ§Ηϋ–¬Θ§ΜΊΙωΘ§ά©»ίΘ§Υθ»ίΘ§ΕΦΩ…“‘Ά®Ιΐ–όΗΡ±ύ≈≈ΈΡΦΰά¥ Βœ÷Θ§¥”Εχ‘ωΦ”ΝΥΩ…ΉΖΥί–‘Θ§“ΉΙήάμ–‘Θ§ΚΆΉ‘Ε·Μ·ΒΡΡήΝΠΓΘ
Φ»»Μ±ύ≈≈ΈΡΦΰ“≤Ω…“‘”Ο¥ζ¬κ≤÷ΩβΫχ––ΙήάμΘ§ΨΆΩ…“‘ Βœ÷“ΜΑΌΗωΖΰΈώ÷–Θ§Ηϋ–¬Τδ÷–ΈεΗωΖΰΈώΘ§÷Μ“Σ–όΗΡ±ύ≈≈ΈΡΦΰ÷–ΒΡΈεΗωΖΰΈώΒΡ≈δ÷ΟΨΆΩ…“‘ΓΘ
Β±±ύ≈≈ΈΡΦΰΧαΫΜΒΡ ±ΚρΘ§¥ζ¬κ≤÷ΩβΉ‘Ε·¥ΞΖΔΉ‘Ε·≤Ω π…ΐΦΕΫ≈±ΨΘ§¥”ΕχΗϋ–¬œΏ…œΒΡΜΖΨ≥ΓΘ
Β±ΖΔœ÷–¬ΒΡΜΖΨ≥”–Έ Χβ ±Θ§Β±»ΜœΘΆϊΫΪ’βΈεΗωΖΰΈώ‘≠Ή”–‘ΒΊΜΊΙωΘ§»γΙϊΟΜ”–±ύ≈≈ΈΡΦΰΘ§–η“Σ»ΥΙΛΦ«¬Φ’β¥Έ…ΐΦΕΝΥΡΡΈεΗωΖΰΈώΓΘ
”–ΝΥ±ύ≈≈ΈΡΦΰΘ§÷Μ“Σ‘Ύ¥ζ¬κ≤÷ΩβάοΟφ RevertΘ§ΨΆΜΊΙωΒΫ…œ“ΜΗωΑφ±ΨΝΥΓΘΥυ”–ΒΡ≤ΌΉς‘Ύ¥ζ¬κ≤÷ΩβάοΕΦ «Ω…“‘Ω¥ΒΫΒΡΓΘ
…ηΦΤ“ΣΒψΤΏΘΚΆ≥“Μ≈δ÷Ο÷––Ρ

ΖΰΈώ≤πΖ÷“‘ΚσΘ§ΖΰΈώΒΡ ΐΝΩΖ«≥ΘΕύΘ§»γΙϊΥυ”–ΒΡ≈δ÷ΟΕΦ“‘≈δ÷ΟΈΡΦΰΒΡΖΫ ΫΖ≈‘Ύ”Π”Ο±ΨΒΊΒΡΜΑΘ§Ζ«≥ΘΡ―“‘ΙήάμΓΘ
Ω…“‘œκœσΒ±”–ΦΗΑΌ…œ«ßΗωΫχ≥Χ÷–”–“ΜΗω≈δ÷Ο≥ωœ÷ΝΥΈ ΧβΘ§ «ΚήΡ―ΫΪΥϋ’“≥ωά¥ΒΡΘ§“ρΕχ–η“Σ”–Ά≥“ΜΒΡ≈δ÷Ο÷––ΡΘ§ά¥ΙήάμΥυ”–ΒΡ≈δ÷ΟΘ§Ϋχ––Ά≥“ΜΒΡ≈δ÷Οœ¬ΖΔΓΘ
‘ΎΈΔΖΰΈώ÷–Θ§≈δ÷ΟΆυΆυΖ÷ΈΣ“‘œ¬ΦΗάύΘΚ
“Μάύ «ΦΗΚθ≤Μ±δΒΡ≈δ÷ΟΘ§’β÷÷≈δ÷ΟΩ…“‘÷±Ϋ”¥ρ‘Ύ»ίΤςΨΒœώάοΟφΓΘ
ΒΎΕΰάύ «ΤτΕ· ±ΨΆΜα»ΖΕ®ΒΡ≈δ÷ΟΘ§’β÷÷≈δ÷ΟΆυΆυΆ®ΙΐΜΖΨ≥±δΝΩΘ§‘Ύ»ίΤςΤτΕ·ΒΡ ±Κρ¥ΪΫχ»ΞΓΘ
ΒΎ»ΐάύΨΆ «Ά≥“ΜΒΡ≈δ÷ΟΘ§–η“ΣΆ®Ιΐ≈δ÷Ο÷––ΡΫχ––œ¬ΖΔΓΘάΐ»γ‘Ύ¥σ¥ΌΒΡ«ιΩωœ¬Θ§”––©ΙΠΡή–η“ΣΫΒΦΕΘ§ΡΡ–©ΙΠΡήΩ…“‘ΫΒΦΕΘ§ΡΡ–©ΙΠΡή≤ΜΡήΫΒΦΕΘ§ΕΦΩ…“‘‘Ύ≈δ÷ΟΈΡΦΰ÷–Ά≥“Μ≈δ÷ΟΓΘ
…ηΦΤ“ΣΒψΑΥΘΚΆ≥“Μ»’÷Ψ÷––Ρ

Ά§―υ «Ϋχ≥Χ ΐΡΩΖ«≥ΘΕύΒΡ ±ΚρΘ§ΚήΡ―Ε‘≥…«ß…œΑΌΗω»ίΤςΘ§“ΜΗω“ΜΗωΒ«¬ΦΫχ»Ξ≤ιΩ¥»’÷ΨΘ§Υυ“‘–η“ΣΆ≥“ΜΒΡ»’÷Ψ÷––Ρά¥ ’Φ·»’÷ΨΓΘ
ΈΣΝΥ Ι ’Φ·ΒΫΒΡ»’÷Ψ»ί“ΉΖ÷ΈωΘ§Ε‘”Ύ»’÷ΨΒΡΙφΖΕΘ§–η“Σ”–“ΜΕ®ΒΡ“Σ«σΘ§Β±Υυ”–ΒΡΖΰΈώΕΦΉώ ΊΆ≥“ΜΒΡ»’÷ΨΙφΖΕΒΡ ±ΚρΘ§‘Ύ»’÷Ψ÷––ΡΨΆΩ…“‘Ε‘“ΜΗωΫΜ“ΉΝς≥ΧΫχ––Ά≥“ΜΒΡΉΖΥίΓΘ
άΐ»γ‘ΎΉνΚσΒΡ»’÷ΨΥ―Υς“ΐ«φ÷–Θ§Υ―ΥςΫΜ“ΉΚ≈Θ§ΨΆΡήΙΜΩ¥ΒΫ‘ΎΡΡΗωΙΐ≥Χ≥ωœ÷ΝΥ¥μΈσΜρ’Ώ“λ≥ΘΓΘ
…ηΦΤ“ΣΒψΨ≈ΘΚ»έΕœΘ§œόΝςΘ§ΫΒΦΕ

ΖΰΈώ“Σ”–»έΕœΘ§œόΝςΘ§ΫΒΦΕΒΡΡήΝΠΘ§Β±“ΜΗωΖΰΈώΒς”ΟΝμ“ΜΗωΖΰΈώΘ§≥ωœ÷≥§ ±ΒΡ ±ΚρΘ§”ΠΦΑ ±ΖΒΜΊΘ§ΕχΖ«Ήη»ϊ‘ΎΡ«ΗωΒΊΖΫΘ§¥”Εχ”ΑœλΤδΥϊ”ΟΜßΒΡΫΜ“ΉΘ§Ω…“‘ΖΒΜΊΡ§»œΒΡΆ–ΒΉ ΐΨίΓΘ
Β±“ΜΗωΖΰΈώΖΔœ÷±ΜΒς”ΟΒΡΖΰΈώΘ§“ρΈΣΙΐ”ΎΖ±ΟΠΘ§œΏ≥Χ≥Ί¬ζΘ§Ν§Ϋ”≥Ί¬ζΘ§Μρ’ΏΉή «≥ω¥μΘ§‘ρ”ΠΗΟΦΑ ±»έΕœΘ§Ζά÷Ι“ρΈΣœ¬“ΜΗωΖΰΈώΒΡ¥μΈσΜρΖ±ΟΠΘ§ΒΦ÷¬±ΨΖΰΈώΒΡ≤Μ’ΐ≥ΘΘ§¥”Εχ÷πΫΞΆυ«Α¥ΪΒΦΘ§ΒΦ÷¬’ϊΗω”Π”ΟΒΡ―©±άΓΘ
Β±ΖΔœ÷’ϊΗωœΒΆ≥ΒΡ»ΖΗΚ‘ΊΙΐΗΏΒΡ ±ΚρΘ§Ω…“‘―Γ‘ώΫΒΦΕΡ≥–©ΙΠΡήΜρΡ≥–©Βς”ΟΘ§±Θ÷ΛΉν÷Ί“ΣΒΡΫΜ“ΉΝς≥ΧΒΡΆ®ΙΐΘ§“‘ΦΑΉν÷Ί“ΣΒΡΉ ‘¥»Ϊ≤Ω”Ο”Ύ±Θ÷ΛΉνΚΥ–ΡΒΡΝς≥ΧΓΘ
ΜΙ”–“Μ÷÷ ÷ΕΈΨΆ «œόΝςΘ§Β±Φ»…η÷ΟΝΥ»έΕœ≤Ώ¬‘Θ§”÷…η÷ΟΝΥΫΒΦΕ≤Ώ¬‘Θ§Ά®Ιΐ»ΪΝ¥¬ΖΒΡ―ΙΝΠ≤β ‘Θ§”ΠΗΟΡήΙΜ÷ΣΒά’ϊΗωœΒΆ≥ΒΡ÷ß≥≈ΡήΝΠΓΘ
“ρΕχΨΆ–η“Σ÷ΤΕ®œόΝς≤Ώ¬‘Θ§±Θ÷ΛœΒΆ≥‘Ύ≤β ‘ΙΐΒΡ÷ß≥≈ΡήΝΠΖΕΈßΡΎΫχ––ΖΰΈώΘ§≥§≥ω÷ß≥≈ΡήΝΠΖΕΈßΒΡΘ§Ω…ΨήΨχΖΰΈώΓΘ
Β±Ρψœ¬ΒΞΒΡ ±ΚρΘ§œΒΆ≥Β·≥ωΕ‘ΜΑΩρΥΒ ΓΑœΒΆ≥ΟΠΘ§«κ÷Ί ‘Γ±Θ§≤Δ≤Μ¥ζ±μœΒΆ≥Ι“ΝΥΘ§Εχ «ΥΒΟςœΒΆ≥ «’ΐ≥ΘΙΛΉςΒΡΘ§÷Μ≤ΜΙΐœόΝς≤Ώ¬‘ΤπΒΫΝΥΉς”ΟΓΘ
…ηΦΤ“ΣΒψ °ΘΚ»ΪΖΫΈΜΒΡΦύΩΊ

Β±œΒΆ≥Ζ«≥ΘΗ¥‘”ΒΡ ±ΚρΘ§“Σ”–Ά≥“ΜΒΡΦύΩΊΘ§÷ς“Σ”–ΝΫΗωΖΫΟφΘ§“ΜΗω « «ΖώΫΓΩΒΘ§“ΜΗω «–‘ΡήΤΩΨ±‘ΎΡΡάοΓΘ
Β±œΒΆ≥≥ωœ÷“λ≥ΘΒΡ ±ΚρΘ§ΦύΩΊœΒΆ≥Ω…“‘≈δΚœΗφΨ·œΒΆ≥Θ§ΦΑ ±ΒΊΖΔœ÷Θ§Ά®÷ΣΘ§Η…‘ΛΘ§¥”Εχ±Θ’œœΒΆ≥ΒΡΥ≥άϊ‘Υ––ΓΘ
Β±―ΙΝΠ≤β ‘ΒΡ ±ΚρΘ§ΆυΆυΜα‘β”ωΤΩΨ±Θ§“≤–η“Σ”–»ΪΖΫΈΜΒΡΦύΩΊά¥’“≥ωΤΩΨ±ΒψΘ§Ά§ ±ΡήΙΜ±ΘΝτœ÷≥ΓΘ§¥”ΕχΩ…“‘ΉΖΥίΚΆΖ÷ΈωΘ§Ϋχ––»ΪΖΫΈΜΒΡ”≈Μ·ΓΘ |








