| 编辑推荐: |
本文介绍了Sandeep
Dinesh做了一个关于创建、部署、运行应用到Kubernetes里面的五个最佳实践的深度分享。随后Jordan
Pellizzari做了Weave如何在kubernetes中管理SaaS产品Weave
Cloud和经验教训的分享。
本文来自于公众号ImportNew ,由火龙果软件Linda编辑、推荐。 |
|
谷歌云的开发者布道师Sandeep Dinesh(@SandeepDinesh)做了一个演讲,给大家列举了在Kubernetes上运行应用的最佳实践清单;Jordan
Pellizzari(@jpellizzari),是来自Weaveworks的工程师,随后也做了一个分享,内容是在他们使用Kubernetes开发运行SaaS
Weave Cloud两年之后学到的经验教训。
Kubernetes最佳实践
这篇演讲中的最佳实践来源于Sandeep和团队进行的关于在Kubernetes上以多种不同方式运行同一任务的讨论。他们把讨论的结果总结为一个最佳实践的清单。
这些最佳实践被分成以下类别:
构建容器
容器内部
部署
服务
应用架构
1、构建容器
不要信任任意的基础镜像
不幸的是我们看到这个错误一直在发生, Pradeep说到。人们从DockerHub上随便拉一个某人做的基础镜像——这么做的理由仅仅是第一眼看过去这个镜像里面打包有他们需要的包——接着他们就把这个随便选的镜像推到生产环境中。
这么做是非常错误的:你使用的代码可能有很多漏洞,bug,错误版本,或者本身就被人有意把恶意软件打包进去——只是你不知道罢了。
要减轻这种风险,你可以使用静态分析工具,比如CoreOS’ Clair[2]或者Banyon Collector[3]来对容器进行漏洞扫描。
保持基础镜像尽量小
基于最简洁的可用基础镜像,然后基于它构建软件包,这样你就知道镜像里面到底有哪些东西。
越小的基础镜像开销也越小。你的应用可能只要5M, 但是如果你盲目的随便找一个镜像,比如Node.js,
它里面就包括了额外500M你根本要不到的库文件。
使用小镜像的其它优势有:
快速构建
节约存储
拉去镜像更快
更小的潜在攻击面

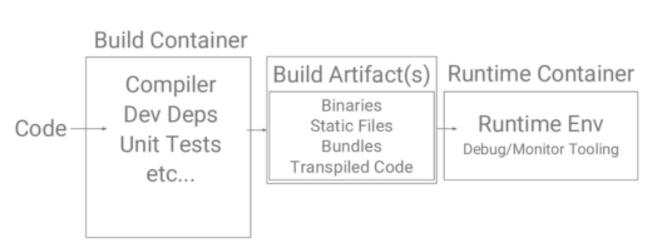
使用构建器模式
这种模式对静态语言特别有用,编译类似Go,C++或者Typescript for Node.js这些语言时。
在这种模式里你有一个构建容器,里面打包有编译器,依赖包,以及单元测试。代码通过第一步之后产出构建的artifacts,这包括所有的文件,bundles等。然后再通过一个运行时容器,包括有监控和调试工具等。
到最后, 你的Dockerfile里面将会只包含你的基础镜像以及运行时环境容器。
2、容器内部
在容器的内部使用非root用户
如果你在容器内使用root来更新包,那么你要把用户改成非root用户。
原因很简单,如果你的容器有后门被人利用了而且你还没把它的用户改成root之外的,那么一个简单的容器逃离将会导致你整个主机的root权限都被利用。但是如果你改成了非root用户,黑客就没那么容易得到root用户的权限了。
做为最佳实践,你要对你的基础设施加多层外壳保护。
在Kubernetes里面你可以通过设置安全上下文[4]runAsNonRoot: true来实现,这样会对整个集群cluster来生效。
文件系统只读
这一个最佳实践通过设置readOnlyFileSystem: true来实现。
每个容器里面跑一个进程
你当然可以在一个容器里面跑多个进程,但是推荐跑一个。这是由编排器的工作方式决定的。Kubernetes基于一个进程是否健康来管理容器。如果你在一个容器里面有20个进程,它如何知道容器是否健康呢?
不要使用 Restart on Failure, 而应当 Crash Cleanly
Kubernetes会重新启动失败的容器,因此你应该干净的做崩溃退出(给出一个错误码),这样Kubernetes就可以不用你的人工干预来成功重起了。
日志打到标准输出和标准错误输出(stdout & stderr)
Kubernetes缺省会监听这些管道,然后将输出传到日志服务上面去。在谷歌云上可以直接用StackDriver日志系统。
3、部署
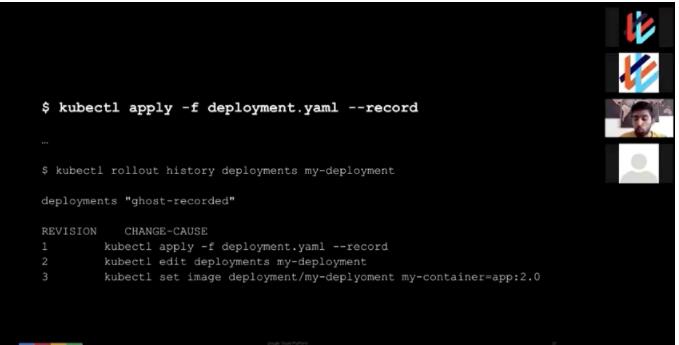
使用record选项来使回滚更方便
在引用一个yaml文件时,请使用--record选项:
| kubectl apply
-f deployment.yaml --record |
带了这个选项之后,每次升级的时都会保存到部署的日志里面,这样就提供了回滚一个变更的能力。
多使用描述性的标签label
因为标签可以是任意的键值对,其表达力非常强。参考下图,以有名字为'Nifty‘的应用部署到四个容器里面。通过选择BE标签你可以挑选出后端容器。

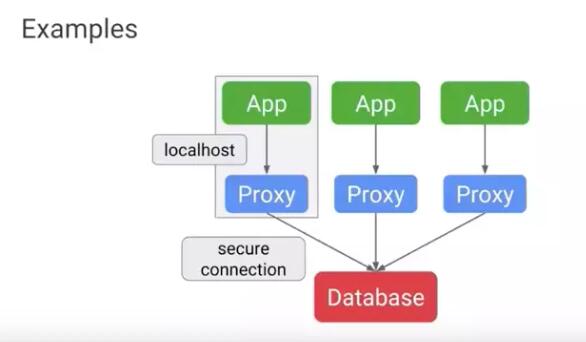
使用sidecar来做代理、监视器等
有时候你需要一组进程跟其它某个进程通讯。但是你又不希望把它们所有的都放进一个容器里面(前面提到的一个容器跑一个进程),
你希望的是把相关的进程都放到一个Pod里面。
常见情况是你需要运行进程依赖的一个代理或者监视器,比如你的进程依赖一个数据库, 而你不希望把数据库的密码硬编码进每个容器里面,这个时会你可以把密码放到一个代理程序里面当作sidecar,由它来管理数据库连接:
不要使用sidecar来做启动引导
尽管sidecar在处理集群内外的请求时非常有用,Sandeep不推荐使用它做启动。再过去,引导启动(bootstraping)是唯一选项,但是现在Kubernetes有了“init
容器”。
当容器里面的一个进程依赖于其它的一个微服务时, 你可以使用init容器来等到进程启动以后再启动你的容器。这可以避免当进程和微服务不同步时产生的很多错误。
基本原则就是:使用sidecar来处理总是发生的事件,而用init容器来处理一次性的事件。
不要使用:latest或者无标签
这个原则是很明显的而且大家基本都这么在用。如果你不给你的容器加标签,那么它会总是拉最新的,这个“最新的”并不能保证包括你认为它应该有的那些更新。
善用readiness、liveness探针
使用探针可以让Kubernetes知道节点是否正常,以此决定是否把流量发给它。缺省情况下Kubernetes检查进程是否在运行。但是通过使用探针,
你可以在缺省行为下加上你自己的逻辑。

4、服务
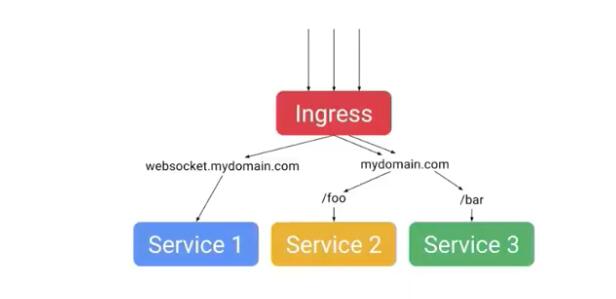
不要使用type: Loadbalancer
每次你在部署文件里面加一个公有云提供商的loadbalancer(负载均衡器)的时候,它都会创建一个。它确实是高可用,高速度,但是它也有经济成本。
使用Ingress来代替,同样可以实现通过一个end point来负载均衡多个服务。这种方式不但更简单,而且更经济。当然这个策略只有你提供http和web服务时有用,对于普通的TCP/UDP应用就没用了。
Type: Nodeport可能已经够用了
这个更多是个人喜好,并不是所有人都推荐。NodePort把你的应用通过一个VM的特定端口暴露到外网上。问题就是它没有像负载均衡器那样有高可用。比如极端情况,VM挂了你的服务也挂了。
使用静态IP, 它们免费!
在谷歌云上很简单,只需要为你的ingress来创建全局IP。类似的对你的负载均衡器可以使用Regional
IP。这样当你的服务down了之后你不必担心IP会变。
将外部服务映射到内部
Kubernetes提供的这个功能不是所有人都知道。如果您需要群集外部的服务,您可以做的是使用ExternalName类型的服务。这样你就可以通过名字来调用这个服务,Kubernetes
manager会把请求传递给它,就好像它在集群之中一样。Kubernetes对待这个服务就好像它在同一个内网里面,即使实际上它不在。
5、应用架构
使用Helm Charts
Helm基本上就是打包Kubernetes应用配置的仓库。如果你要部署一个MongoDB, 存在一个预先配置好的Helm
chart,包括了它所有的依赖,你可以十分容易的把它部署到集群中。
很多流行的软件/组件都有写好了的Helm charts, 你可以直接用,省掉大量的时间和精力。
所有下游的依赖是不可靠的
你的应用应该有逻辑和错误信息负责审计你不能控制的所有依赖。Sandeep建议说你可以使用Istio或者Linkerd这样的服务网格来做下游管理。
使用Weave Cloud
集群是很难可视化管理的。使用Weave Cloud[5]可以帮你监视集群内的情况和跟踪依赖。
确保你的微服务不要太“微小”
你需要的是逻辑组件,而不是每个单独的功能/函数都变成一个微服务。
使用命名空间来分离集群
例如, 你可以在同一个集群里面创建prod、dev、test这样不同的命名空间,同时可以对不同的命名空间分配资源,
这样万一某个进程有问题也不会用尽所有的集群资源。
基于角色的访问控制RBAC
实施时当的访问控制来限制访问量, 这也是最佳的安全实践。
从运行Weave Cloud生产环境学到的教训
接下来Jordan Pellizzari做了一个演讲,题目是在过去两年我们在Kubernetes上开发运行Weave
Cloud学到的经验。我们当前运行在AWS EC2上, 总共有72个Kubernetes部署运行在13个主机和150个容器里面。我们所有的持续性存储保存在S3,DynamoDB或者RDS里面,
我们并不在容器里面保存状态信息。关于我们如何搭建基础设施的细节可以参看这篇文档[6]。
挑战1:对基础设施做版本控制
在Weaveworks我们把所有的基础架构保存在Git中, 如果我们要对基础设施做变更,要像代码一样提Pull
request。我们把这称为GitOps,也写了多篇博文。你可以从这篇读起:GitOps - Pull
Request支撑的运维[7]。
在Weave, 所有的Terraform脚本,Ansible以及Kubernetes YAML文件都被保存在Git里面做版本控制。
把基础架构放在Git里面是一个最佳实践,这有多个原因:
发布可以很方便的回滚
对谁做了什么修改有追踪审计
灾难恢复相当简单
问题:当生产与版本控制不一致时该怎么办?
除了把所有内容保存在Git中之外,我们也有一个流程会检查生产集群中运行的状态与版本控制中的内容差异。如果检查到有不同,就会给我们的Slack频道发一个报警。
我们使用一个叫Kube-Diff[8]的开源工具来检查不同。
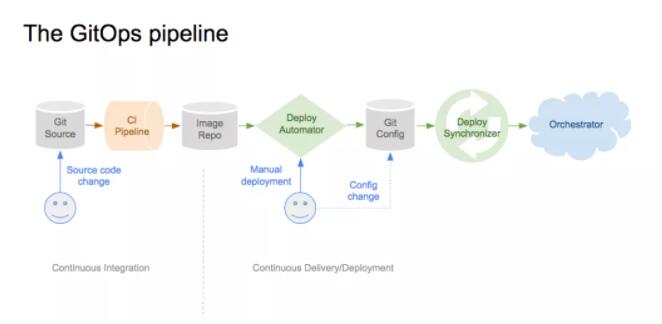
挑战2:自动化的持续交付
自动化你的CI/CD流水线,避免手工的Kubernetes部署。因为我们一天内做多次部署,这种方式节约了团队的时间也避免了手工容易发生错误的步骤。在Weaveworks,开发人员只需要做一个Git
push,然后Weave Cloud会做以下的事情:
打过标签的代码通过CircleCI的测试然后构建一个新的容器镜像,推送这个新的镜像到仓库中。
Weave Cloud的“Deploy Automator‘检测到新镜像,从库中拉取新镜像然后在配置库里面更新对应的YAML文件。
Deploy Synchronizer会检测到集群需要更改in了,然后它会从配置库里面拉更新的配置清单,最后将新的镜像部署到集群中。
GitOps流水线
这里有一篇稍长的文章[9],我们认为的构建自动化CI/CD流水线的最佳实践都在里面描述了。 |








