| БрМЭЦМі: |
БОЮФЖддЦдЩњЕФНтЖСжЛЯодкећЬхадКЭШыУХМЖЕФНщЩмЃЌЭЈЙ§БОЮФФмжЊЕРдЦдЩњЪЧЪВУДЃПФмСЫНтЦфРэФюЁЂЫМЯыЁЂМлжЕКЭММЪѕеЛЁЃ
БОЮФРДздгкInfoQМмЙЙЭЗЬѕЃЌгЩAliceБрМЁЂЭЦМіЁЃ |
|
ПЊЬтЃКЫЕЪЕЛАЃЌвЛПЊЪМОіЖЈаДетЦЊЮФеТВЂАбУћзжжБНгКЭЁАдЦдЩњЁБетвЛдкЕБЯТШчДЫЛ№ШШКЭКъДѓЕФММЪѕЬхЯЕЙвЙГЃЌаФРязХЪЕгааЉьўь§ВЛАВЁЃвЛЪЧдЦдЩњРэФюКЭММЪѕЬхЯЕШчДЫКЦхЋЃЌзїЮЊвЛИіПЩФме§дкЬЄШыдЦдЩњДѓУХЕФЁАаТШЫЁБЃЈЫфШЛБОШЫЬЄШыШэМўбаЗЂаавЕвбО 11 ФъСЫЃЉЃЌЭЈЙ§вЛЦЊЮФеТЃЌНсКЯздМКвЛСНФъЕФОбщКЭЫМПМЃЌРДНВЧхГўдЦдЩњЪЧУцСйОоДѓЬєеНЕФЃЛЖўЪЧХТБЛБ№ШЫЙквдЁАВфММЪѕШШЖШЁБжЎУБЃЌММЪѕадСьгђгШЦфЪЧШэМўбаЗЂСьгђЃЌПЊЗЂепЖМгавЛжжЧПСвЕФЮЃЛњИаКЭНЙТЧИаЃЌЩњХТдкШеаТдТвьЁЂПьЫйЕќДњЕФММЪѕКщСїжаЃЌвЛВЛаЁаФОЭБЛЪБДњХзЦњСЫЁЃЫљвдЃЌетжжЮФеТБъЬтШнвзШУЭЌааОѕЕУдкЮёащЃЌЗДгГЕФЪЧФкаФНЙТЧЃЌЩњХТздМКВЛСЫНтЧАбиММЪѕЃЌНсЙћИќЖрЪЧЗЙКѓЬИзЪЁЃ
ШЛЖјЫцзХОЉЖЋвЕЮёдкПьЫйЗЂеЙЃЌДпЩњГіСЫдНРДдНЖрЕФаТвЕЮёЁЂаТШќЕРКЭаТеОЕуЃЌетаЉаТвЕЬЌКмЖрЖМЪЧМЏЭХеНТдМЖЕФЃЌЖјЧвОЉЖЋММЪѕЩЬвЕЛЏТфЕиКЭМлжЕЪфГізїЮЊМЏЭХдіГЄЕФаТЧњЯпЕФЫпЧѓгњРДгњЧПСвЁЃiPaaS зїЮЊОЉЖЋСуЪлЧАЬЈбаЗЂБъзМЃЌдкжЇГХЙЋЫОаТвЕЬЌЁЂаТШќЕРдЫгЊЬхЯЕЕФДюНЈКЭТфЕиЃЌжЇГХЙЋЫОЙњМЪЛЏеОЕуЁЂЩЬвЕЛЏЯюФПЕШЗНУцЗЂЛгСЫгњРДгњживЊЕФзїгУЁЃЕЋШчКЮНјвЛВНГщЯѓКЭЦСБЮММЪѕЪЕЪЉКЭММЪѕИДдгЖШЃЌШчКЮНјвЛВНШУПЊЗЂепОлНЙвЕЮёМлжЕЕФПьЫйНЛИЖЃЌШчКЮИќНјвЛВНЬсЩ§ПЊЗЂепПЊЗЂаЇТЪКЭашЧѓНЛИЖаЇТЪЃЌШчКЮИГгшвЕЮёИќУєНнЕФЪдДэФмСІКЭИќЧПЕФДДаТФмСІЃЌiPaaS ашвЊРДЙцЛЎКЭЗЂЛгЕФПеМфЛЙЪЧЗЧГЃДѓЕФЁЃЕБЮвУЧНсКЯ iPaaS ЕФГѕждЁЂдИОАЁЂМлжЕКЭдЦдЩњЕФРэФюКЭМлжЕНјааЫМПМЪБЃЌЗЂЯж iPaaS КЭдЦдЩњЦфРэФюКЭМлжЕЪЧВЛФБЖјКЯЕФЁЃЫљвддЦдЩњЕФРэФюКЭММЪѕЪЧ iPaaS ЮДРДвЛИіживЊЕФЗНЯђЃЌБОЮФЪЧЖддЦдЩњКЭдЦдЩњТфЕи iPaaS ЕФвЛИіГѕВНЫМПМЁЃ
iPaaS ЪЧЪВУДЃП
iPaaS ЮЊОЉЖЋСуЪлЧАЬЈбаЗЂБъзМЃЌЦфЖЈвхЮЊЃКЁАiPaaS ЪЧвЛЬзПЊЗХЁЂЙВЩњЁЂжЧФмЁЂаЭЌЕФММЪѕБъзМЬхЯЕЃЌжМдкАбБЛКЃСПвЕЮёКЭСїСПЫљГЩЙІбщжЄЙ§ЕФЦНЬЈЛЏФмСІШЋУцБъзМЛЏКЭПЊЗХЛЏЃЌВЂЬсЙЉИВИЧДѓЧАЖЫЕНДѓКѓЖЫЕФСЂЬхЪНКЭЭъећЕФММЪѕПЊЗХЬхЯЕЃЌШУПЊЗЂепДгДѓСПЭЌжЪадРЭЖЏжаНтЭбГіРДЃЌзюДѓГЬЖШОлНЙдквЕЮёПЊЗЂЩЬЃЌЪЕЯжИпаЇЁЂСщЛюПЊЗЂКЭЖЈжЦвЕЮёЕФИіадЛЏашЧѓЁЃвЕЮёдк iPaaS ГжајЗБШйЕФЩњЬЌШІжаОЁЧщЯэЪмСЫФмСІЙВЯэКЭММЪѕДДаТЕФКьРћЃЌЭЈЙ§ iPaaSЃЌвЕЮёФмЙЛМЋЫйЙЙНЈдЫгЊЬхЯЕЃЌМгЫйвЕЮёЪ§зжЛЏЩ§МЖКЭвЕЮёДДаТЁЃЁБЁЃ
iPaaS ЕФМлжЕ
iPaaS УцЯђПЊЗЂепЃЌЦфжеМЋМлжЕдкгкИпаЇжЇГХвЕЮёЃЌЦфМлжЕзмНсРДПДАќРЈЃК
a. ШУПЊЗЂепОлНЙвЕЮёЃЌЬсЩ§ПЊЗЂепЩњВњСІЁЃ
b. НЕБОЬсаЇЁЃ
c. ИГгшвЕЮёМЋЫйДДаТФмСІЁЃ
d. жњСІММЪѕЩЬвЕЛЏТфЕиЁЃ
iPaaS ЕФдИОА
iPaaS ЕФдИОАЪЧвдММЪѕКЭвЕЮёФмСІЕФБъзМЛЏЁЂЙцЗЖЛЏЮЊЛљДЁЃЌРЭЈжЧФмаЭЌСДТЗЃЌДђдьИпЖШПЩМЏГЩЁЂПЩСЌНгЭтВПЯЕЭГКЭвЕЮёЕФФмСІЃЌДяЕНгыПЊЗЂепКЭвЕЮёПЊЗХЙВЩњЃЌЪЕЯжЛЅРћЖргЎЃЌжњСІПЊЗЂепОлНЙвЕЮёМлжЕКЭИіадЛЏашЧѓЖЈжЦЃЌжЇГХвЕЮёПьЫйДюНЈдЫгЊЬхЯЕЃЌЪЕЯжПьЫйЪдДэКЭвЕЮёДДаТЁЃзмНсРДПДЃЌiPaaS ЕФзюЖЅВудИОАЪЧЭЈЙ§БъзМЛЏФмСІКЭММЪѕПЊЗХФмСІСЌНгПЊЗЂепЁЂвЕЮёКЭ iPaaS ЦНЬЈЃЌаЮГЩвЛИіВЛЖЯЗБШйЁЂСМадЗЂеЙЕФЩњЬЌШІЃЌвдЪЕЯжПЊЗЂеп-вЕЮё-iPaaS ЕФШ§гЎОжУцЁЃ

дЦдЩњ
ДгдЦдЩњвЕНчБШНЯШЯПЩЕФЖЈвхЃЈЁАдЦдЩњММЪѕгаРћгкИїзщжЏдкЙЋгадЦЁЂЫНгадЦКЭЛьКЯдЦЕШаТаЭЖЏЬЌЛЗОГжаЃЌЙЙНЈКЭдЫааПЩЕЏадРЉеЙЕФгІгУЁЃдЦдЩњЕФДњБэММЪѕАќРЈШнЦїЁЂЗўЮёЭјИёЁЂЮЂЗўЮёЁЂВЛПЩБфЛљДЁЩшЪЉКЭЩљУїЪН APIЁЃетаЉММЪѕФмЙЛЙЙНЈШнДэадКУЁЂвзгкЙмРэКЭПЩЙлВтЕФЫЩёюКЯЯЕЭГЁЃНсКЯПЩППЕФздЖЏЛЏЪжЖЮЃЌдЦдЩњММЪѕЪЙЙЄГЬЪІФмЙЛЧсЫЩЕиЖдЯЕЭГзїГіЦЕЗБКЭПЩдЄВтЕФжиДѓБфИќЁЃЁБЃЉПЩвдПДГіЃЌдЦдЩњЪЧвЛжжРэФюЃЌЩњдкдЦЩЯЃЌГЄдкдЦЩЯЃЌзюДѓЛЏЕиЗЂЛгдЦЕФФмСІКЭМлжЕЁЃвВЪЧвЛЯЕСаМмЙЙддђКЭЩшМЦФЃЪНЕФМЏКЯЃЌжМдкНЋдЦгІгУжаЕФЗЧвЕЮёДњТыЕФВПЗжНјаазюДѓЛЏЕФАўРыЃЌДгЖјШУдЦЩшЪЉЃЈIaaSЁЂPaaSЃЉНгЙмгІгУжадгаЕФДѓСПЗЧЙІФмЬиадЃЌШУПЊЗЂепОлНЙдквЕЮёМлжЕНЛИЖЩЯЁЃ
ЮвУЧЦЪЮіВЂзмНс iPaaS КЭдЦдЩњЕФРэФюКЭМлжЕЃЌЗЂЯжКмЖрЗНУцЖМЪЧЗЧГЃЦѕКЯЕФЃЌетМсЖЈСЫЮвУЧЮДРДШкКЯдЦдЩњРэФюКЭММЪѕЃЌБОЮФЫуЪЧЖддЦдЩњРэТлКЭТфЕи iPaaS ЕФвЛаЉЧГВуДЮЕФЫМПМЁЃ
зюКѓашвЊИјБОЮФЕФЖСепЁАДђвЛМСдЄЗРеыЁБЃЌБОЮФЖддЦдЩњЕФНтЖСжЛЯодкећЬхадКЭШыУХМЖЕФНщЩмЃЌЭЈЙ§БОЮФФмжЊЕРдЦдЩњЪЧЪВУДЃПФмСЫНтЦфРэФюЁЂЫМЯыЁЂМлжЕКЭММЪѕеЛЃЌШчЙћЯыЭЈЙ§БОЮФРДЩюЖШСЫНтдЦдЩњЕФММЪѕдРэКЭЗНАИЃЌФЧГМцЊАьВЛЕНАЁЃЌЛЙашвЊНсКЯММЪѕЕФЙйЭјНјааНјвЛВНЕФбЇЯАКЭбаОПЁЃзюКѓБОЮФЛсНтЖСвЛЯТ iPaaS дкдЦдЩњТфЕиЕФЗНЯђКЭЙцЛЎЃЌПЩФмДцдкЮѓЧјЃЌвВЛЖгИїЮЛЖСепФмЙЛИјЕНгавтвхЕФНЈвщКЭЬсЪОЁЃ
БОЮФНЋжиЕуНВНтвдЯТ 5 ЗНУцЃК
1. ЛиЙЫШэМўНЛИЖЕФЗЂеЙРњГЬЁЃ
2. ЪВУДЪЧдЦдЩњЃПдЦдЩњФмИјЮвУЧДјРДЪВУДЃП
3. дЦдЩњЕФМмЙЙддђКЭЩшМЦФЃЪНЁЃ
4. дЦдЩњжївЊММЪѕЁЃ
5. iPaaSЃЈОЉЖЋЧАЬЈбаЗЂБъзМЃЉдкдЦдЩњЕФЫМПМКЭЬНЫїЁЃ
1ЁЂШэМўНЛИЖЕФЗЂеЙРњГЬ
зїЮЊвЛИідкШэМўбаЗЂаавЕдњИљГЌЙ§ 11 ФъЕФЁАРЯБјЁБЃЌОРњЙ§дкжааЁЙЋЫОЭЈЙ§ shell НХБО+ХфжУЮФМў+war АќЗНЪННЛИЖПЭЛЇШэМўЃЌЕНАбГЬађКЭдЫааЪБДђАќЕНХгДѓащФтЛњШЛКѓЭЈЙ§вЦЖЏгВХЬНЛИЖИјПЭЛЇВПЪ№ЃЌдкЕНЯждкдкОЉЖЋЭЈЙ§вЛеОЪНЕФМЏГЩНЛИЖЦНЬЈжЛашвЊЕуМИИіАДХЅОЭПЩвдЙмРэКЭВПЪ№Ъ§ЧЇИігІгУЪЕР§ЃЌИпЗхЦкУПЬьЪ§ЪЎДЮЕФЦЕЗБЗЂВМНЛИЖЕФРњГЬЁЃЙ§ШЅЪЎФъЪЧЛЅСЊЭјаавЕПьЫйКЭЕпИВЪНЗЂеЙЕФЪЎФъЃЌвВЪЧдЦМЦЫуКЭШэМўНЛИЖММЪѕПьЫйЗЂеЙЕФЪЎФъЁЃШУЮвУЧАбЪгЯпРЯђЙ§ШЅЃЌЛиЙЫвЛЯТШэМўНЛИЖММЪѕЕФЗЂеЙРњГЬЁЃ
Chroot Jail
ащФтЛЏШнЦїММЪѕПЩвдзЗЫнЕНЩЯИіЪРМЭЃЌ1979 ФъЃЌБДЖћЪЕбщЪвЮЊ Unix V7 ВйзїЯЕЭГЕФЗЂВМНјаазюКѓЕФПЊЗЂКЭВтЪдЃЌЮЊСЫЬсИпЯЕЭГМЖБ№ШэМўЙЙНЈКЭВтЪдЕФаЇТЪЃЌЫћУЧПЊЪМЩшМЦКЭЙЙЫМдкЯжгаВйзїЯЕЭГЛЗОГЯТЁАИєРыЁБГівЛИіПЩЙЉШэМўНјааЙЙНЈКЭВтЪдЕФЛЗОГЃЌЭЈЙ§вЛИіМђЕЅЕФУќСюОЭПЩвдИФБфГЬађЕФЁАЪгЭМЁБЃЌУПДЮжЛвЊдкЕБЧАФПТМРяЗХжУвЛИіЭъећВйзїЯЕЭГЮФМўЯЕЭГВПЗжЃЌИУШэМўдЫааЫљашЕФЫљгавРРЕОЭЭъБИСЫЁЃетбљПЊЗЂепМфНггЕгаСЫгІгУЛљДЁЩшЪЉЁАПьЫйЯњЛйКЭжиЯжЁБЕФФмСІЃЌЖјВЛашвЊдкЛЗОГДюКУжЎКѓНјШыЕНЛЗОГРяШЅНјаагІгУЫљашЕФвРРЕАВзАКЭХфжУЁЃгкЪЧ chrootЃЈChange RootЃЉЕФММЪѕОЭЕЎЩњСЫЃЌгУРДжиЖЈЯђНјГЬМАЦфзгНјГЬЕФИљФПТМЕНвЛИіЮФМўЯЕЭГЩЯЕФаТЮЛжУЃЌБЛИєРыГіРДЕФЛЗОГБЛИГгшСЫвЛИіКмаЮЯѓЕФУћзжЃКChroot JailЃЌChroot вВЫуЪЧШЫРрЕквЛДЮНјШыЁАНјГЬИєРыЁБЕФДѓУХЁЃchroot вВж№НЅГЩЮЊСЫПЊЗЂВтЪдЛЗОГХфжУКЭгІгУвРРЕЙмРэЕФвЛИіживЊЙЄОпЁЃ2000 ФъЃЌЭЌЪє Unix МвзхЕФ FreeBSD ВйзїЯЕЭГЗЂВМСЫЁАjailЁБУќСюЃЌАбЁБ ИєРыЁАетИіИХФюРЉеЙЕНСЫНјГЬЕФЭъећЪгЭМЃЌгЕгаЖРСЂНјГЬЛЗОГКЭгУЛЇЬхЯЕЃЌЗжХфЖРСЂЕФ IP ЕижЗЁЃchroot ДђПЊНјГЬЛЗОГИєРыЕФДѓУХЃЌЕЋ FreeBSD Jails ВХЪЕЯжеце§НјГЬЕФЩГЯфЛЏЃЌетжжЩГЯфЪЧЭЈЙ§ВйзїЯЕЭГМЖБ№ЕФИєРыгыЯожЦФмСІРДЪЕЯжЖјЗЧгВМўащФтЛЏММЪѕЁЃВЛЙ§дк Jails ЪБДњЃЌЁАдЦЁБЕФИХФюЩаЮДЦеМАЃЌ НјГЬЩГЯфММЪѕвЛжБОжЯодкСЫаЁжкЕФГЁОАЪРНчРяЁЃ
LXC
Google дк 2006 ФъжЎМфЗЂВМСЫвЛИіУћЮЊ Process Container ММЪѕЃЌЬсЙЉВйзїЯЕЭГМЖБ№ЕФзЪдДЯожЦЁЂгХЯШМЖПижЦЁЂзЪдДЩѓМЦФмСІКЭНјГЬПижЦФмСІЃЌгыЩГЯфРэФюВЛФБЖјКЯЃЌетИіММЪѕвВЪЧ Google ФкВПЛљДЁЩшЪЉЕУвдЪЕЯжЕФЛљБОЫпЧѓКЭЛљДЁвРРЕЃЌвВГЩЮЊСЫ Google блжаЁАШнЦїЁБММЪѕЕФГћаЮЃЌProcess Container ЭЦГіКѓЕФЕкЖўФъОЭНјШыСЫ Linux ФкКЫжїИЩЁЃЕЋвђ Container дк Linux ФкКЫжаСэгаЫќгУЃЌProcess Container дк Linux жаБЛе§ЪНИФУћЮЊ CgroupsЁЃ2008 Фъ LXC Аб Cgroups ЕФзЪдДЙмРэКЭЯожЦФмСІКЭ Linux Namespace ЕФЪгЭМИєРыФмСІзщКЯдквЛЦ№ЃЌЬсНЛВЂе§ЪННјШы Linux ФкКЫЁЃВЂАщЫцзХ Linux OS ПЊЪМбИЫйеМСьЩЬгУЗўЮёЦїЪаГЁЕФЦѕЛњЃЌLXC ЪмЕНСЫ chroot ЕШЮДдјгаЕФЙизЂЁЃ
PaaS
2008 ФъКѓЪРНчЩЯЛЅСЊЭјОоЭЗУЧ AWSЃЌMicrosoft ПЊЪМГжајМгДѓдкЙЋгадЦЕФЭЖШыЃЌЫМПМКЭТфЕидк IaaS жЎЩЯЙЙНЈаТЕФММЪѕгыЩЬвЕМлжЕЃЌДпЩњГіСЫЮвУЧЯждкЖМЖњЪьФмЯъЕФаТаЫВњвЕЃКPaaSЁЃ2009 ФъПЊдДЯюФП Cloud Foundry ЗЂВМЃЌЕквЛДЮЖд PaaS ЕФИХФюЭъГЩСЫЧхЮњЖјЭъећЕФЖЈвхЁЃPaaS ЖЈЮЛЪЧгІгУЕФЭаЙмЗўЮёЃЌЦфРэФюЁАPaaS ЖдгІгУЕФжБНгЙмРэЁЂБрХХКЭЕїЖШШУПЊЗЂепзЈзЂгквЕЮёТпМЖјЗЧЛљДЁЩшЪЉЁБдкдЦМЦЫуаавЕЕУЕНСЫвЛжТЕФШЯЭЌЃЌНшжњ PaaS РыПЊЗЂепзуЙЛНќЕФгХЪЦЃЌДгЖјЫјЖЈдЦЗўЮёЃЌетОЭвЊЧѓ PaaS БиаыВЛвРРЕ IaaS ЕзВуММЪѕЛљДЁЪЕЪЉЃЌФмЙЛИпаЇДђАќЗтзАгУЛЇЕФгІгУЃЌПьЫйЕФВПЪ№ЕНЕЭВуЛљДЁЩшЪЉЩЯЁЃПЊдДЁЂжаСЂЁЂЧсСПЁЂУєНнЕФ Linux ШнЦїММЪѕГЩСЫ PaaS ЪЕЯжгІгУЭаЙмКЭВПЪ№ЕФОјМббЁдёЃЌLinux ШнЦївбОЬјГіСЫНјГЬЩГЯфЕФОжЯоадЃЌПЊЪМАчбнзХЁАгІгУШнЦїЁБЕФНЧЩЋЃЌШнЦїКЭгІгУЛЩЯСЫЕШКХЃЌетВХзюжеЪЙЕУЦНЬЈВуЯЕЭГФмЙЛЪЕЯжгІгУЕФШЋЩњУќжмЦкЭаЙмЁЃ
Docker
2013 ФъвЛМвНа dotCloud ЕФЙЋЫОЗЂВМСЫвЛИіЕпИВадЕФПЊдДЯюФП DockerЃЌDocker ЭЈЙ§ШнЦїОЕЯёЃЌНЋгІгУдЫааЫљашЕФЭъећЛЗОГЃЈАќРЈВйзїЯЕЭГЕФЮФМўЯЕЭГЃЉНјааећЬхДђАќЃЌЪЕЯжЁАвЛДЮЗЂВМЁЂЫцДІдЫааЁБЃЌБШЭЈЙ§ Buildpack АбвЛИігІгУПЩдЫааЮФМўШч WAR АќКЭНХБОХфжУНјааЗтзАЃЌСЌжЦзївЛИіПЊЗЂКЭВтЪдЛЗОГЖМЮоЗЈЭГвЛЕФММЪѕвЊЯШНјИпУїЕФЖрЁЃЭЌЪБ Docker НшМј Git ЕФЫМЯыЃЌЭЈЙ§ DockerHub етбљЕФОЕЯёЭаЙмВжПтЃЌФмЙЛШУИпаЇЗжЗЂКЭНЛИЖФуЕФШэМўЗўЮёЕНЪРНчШЮКЮЕиЗНЁЃ
жеМЋРДПД Docker ЦфЪЕвЛжБдкЫМПМКЭНтОіЕФвЛИіЮЪЬтЪЧЃКШэМўОПОЙгІИУЭЈЙ§ЪВУДбљЕФЗНЪННјааНЛИЖЃПШнЦїОЕЯёИјГівЛЗнЭъУРЕФД№АИЁЃОЭСЌ Docker здМКЖМЫЕздМКжЛЪЧЁАеОдкОоШЫМчАђЩЯЁБЃЌШЗЪЕУЛгаЙ§ШЅЪЎМИФъ Linux ШнЦїЕШММЪѕЕФЭъЩЦКЭЗЂеЙЃЌвЛИіДДвЕЙЋЫОЕФПЊдДЯюФПОЭФмЕпИВећИіаавЕПжХТЪЧГеШЫЫЕУЮЁЃ
Kubernetes
ШнЦїОЕЯёвбОГЩЮЊСЫдЦЪБДњШэМўНЛИЖгыЗжЗЂЕФЪТЪЕБъзМЁЃDockerЁЂMesosphereЁЂKubernetes дкЁАгІгУЁБгазХВЛЭЌРэНтКЭЖЅВуЩшМЦЃЌDocker ЬхЯЕвдЁАЕЅвЛШнЦїЁБЮЊКЫаФЕФгІгУЖЈвхЗНЪНЃЌЖј Kubernetes дђЬсГіСЫвЛећЬзШнЦїЛЏЩшМЦФЃЪНКЭЖдгІЕФПижЦФЃаЭЃЌДгЖјУїШЗСЫШчКЮеце§вдШнЦїЮЊКЫаФЙЙНЈФмЙЛеце§ИњПЊЗЂепЖдНгЦ№РДЕФгІгУНЛИЖКЭПЊЗЂЗЖЪНЃЌзюже Kubernetes ШЁЕУЕНСЫдЦЪБДњгІгУБрХХЕФЙиМќСьЕМЕиЮЛЁЃ
дЦдЩњ
Kubernetes вбЗЂеЙЮЊдЦЪБДњгІгУБрХХЕФЪТЪЕБъзМЃЌзїЮЊСЌЭЈЁАдЦЁБгыЁАгІгУЁБЕФИпЫйЙЋТЗЃЌвдБъзМЁЂИпаЇЕФЗНЪННЋЁАгІгУЁБПьЫйНЛИЖЕНЪРНчЩЯШЮКЮвЛИіЮЛжУЃЌМШПЩвдЪЧзюжегУЛЇЃЌвВПЩвдЪЧ PaaS/Serverless ДгЖјДпЩњГіИќМгЖрбљЛЏЕФгІгУЭаЙмЩњЬЌЁЃЦфБГКѓЕФЫМЯыКЭФПБъОЭЪЧзюДѓГЬЖШЕФЗЂЛгШнЦїКЭдЦЕФМлжЕЃЌете§ЪЧећИіЁАдЦдЩњЁБЕФРэФюЁЃ
2ЁЂЪВУДЪЧдЦдЩњЃП
дЦдЩњЖЈвх
CNCFЃЈCloud Native Computing FoundationЃЌГЩСЂгк 2015 ФъЃЌжТСІгкдЦдЩњММЪѕЦеМАКЭПЩГжајЗЂеЙЕФЛљН№ЛсЃЉИјГіЕФЖЈвхЃК
ЁА Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil. ЁБ
ЗвыЙ§РДЃК
ЁА дЦдЩњММЪѕгаРћгкИїзщжЏдкЙЋгадЦЁЂЫНгадЦКЭЛьКЯдЦЕШаТаЭЖЏЬЌЛЗОГжаЃЌЙЙНЈКЭдЫааПЩЕЏадРЉеЙЕФгІгУЁЃдЦдЩњЕФДњБэММЪѕАќРЈШнЦїЁЂЗўЮёЭјИёЁЂЮЂЗўЮёЁЂВЛПЩБфЛљДЁЩшЪЉКЭЩљУїЪН APIЁЃ
етаЉММЪѕФмЙЛЙЙНЈШнДэадКУЁЂвзгкЙмРэКЭПЩЙлВтЕФЫЩёюКЯЯЕЭГЁЃНсКЯПЩППЕФздЖЏЛЏЪжЖЮЃЌдЦдЩњММЪѕЪЙЙЄГЬЪІФмЙЛЧсЫЩЕиЖдЯЕЭГзїГіЦЕЗБКЭПЩдЄВтЕФжиДѓБфИќЁЃЁА
ФуШчЙћЪЧЕквЛДЮЖСетИіЖЈвхЃЌЛсВЛЛсИаОѕгаЕуЛоЩЌФбЖЎЁЃЙЙНЈЕЏадПЩРЉеЙгІгУЃЌШнДэадКУЁЂвзЙмРэЁЂПЩЙлВтЯЕЭГЃЌБэДяЕФЬЋПэЗКСЫЃЌВЂВЛДњБэвЛжжЬиЖЈЕФИХФюКЭЗНЗЈЃЌетаЉФПБъЮвУЧгУвЛЯЕСаЗНЗЈТлЁЂЩшМЦЫМЯыКЭЩшМЦФЃЪНвВПЩвдДяГЩЃЌетИіЖЈвхЛЙЪЧКмФбШУЮвУЧзЅзЁдЦдЩњЕФБОжЪЪЧЪВУДЁЃЮвУЧЯШТдЙ§ CNCF ЕФЙйЗНЖЈвхЃЌДгдЦдЩњЕФаЮЬЌКЭжеМЋМлжЕЕФНЧЖШРДНтЦЪКЭРэНтдЦдЩњЁЃ
гІгУвддЩњаЮЬЌБЛЩшМЦЩњдкЁЂГЄдкдЦЩЯЃЌвдГфЗжЗЂЛгдЦЕФгХЪЦ
дЦдЩњЃЌДгзжУцЩЯВ№ГЩ 2 ИіДЪЃЌЁАдЦЁБКЭЁАдЩњЁБЃЌдЦОЭЪЧЧПДѓЕФдЦМЦЫуФмСІЃЌвВЪЧЧАЬсЁЃдЩњЪЧЖдЦѓвЕгІгУРДНВЕФЃЌдЦдЩњЪБДњЕФгІгУБЛЩшМЦГЩЁАЩњдкдЦЩЯЃЌГЄдкдЦЩЯЁБЁЃгІгУЪЧдЩњЕФЃЌжЛАќКЌвЕЮёДњТыЃЌвтЮЖзХашвЊзюДѓЛЏАўРыгІгУжаЗЧвЕЮёЕФДњТыКЭЙІФмЃЌШУдЦЛљДЁЩшЪЉРДНгЙмЃЈАќРЈ IaaSЁЂPaaS ЕШЃЉЃЌгІгУПЩзюДѓЛЏРћгУдЦЕФгХЪЦЃЌГфЗжЯэЪмдЦМЦЫуЕФММЪѕКьРћЁЃ
ЬжТлдЦдЩњЃЌЪЧдкЬжТлвЛЯЕСаМмЙЙддђКЭФЃЪНЕФМЏКЯЁЃ
ПЊЗЂепзёбвЛжжаТЕФШэМўПЊЗЂЁЂЗЂВМКЭдЫЮЌФЃЪНЃЌЪЙЕУдЦдЩњЯТЕФгІгУПЩвдДгДѓСПЗЧвЕЮё/ЗЧЙІФмадЃЈИпПЩгУЬєеНЁЂздЖЏРЉЫѕШнЬєеНЁЂАВШЋЬєеНЁЂдЫЮЌЩ§МЖЬєеНЕШЃЉашЧѓКЭЬєеНжаНтЭбГіРДЃЌДгЖјФмЙЛзюДѓЛЏОлНЙдквЕЮёМлжЕНЛИЖЩЯЁЃгУЛЇВЩгУвЛЬѕЕЭаФжЧИКЕЃЕФЁЂУєНнЕФЃЌФмЙЛвдПЩРЉеЙЁЂПЩИДжЦКЭздЖЏЛЏЕФЗНЪНзюДѓЛЏЕиРћгУдЦЕФФмСІЁЂЗЂЛгдЦЕФМлжЕЕФзюМбТЗОЖРДЙЙНЈКЭНЛИЖгІгУЃЌПЊЗЂИДдгЖШКЭдЫЮЌЙЄзїСПЖМЕУЕНМЋДѓНЕЕЭЁЃдЦдЩњБГКѓЕФвЛИіМлжЕЙлЪЧЃКНЋИДдгСєИјдЦЃЌНЋМђЕЅСєИјгІгУЁЃ
ЫљвддЦдЩњБГКѓдЬКЌСЫвЛзщМмЙЙддђЃЌАќРЈЃКЗўЮёЛЏЁЂЕЏадЁЂПЩЙлВтадЁЂШЭадЁЂздЖЏЛЏЁЂСуаХШЮЁЂМмЙЙГжајбнНјЁЃвВАќРЈСЫвЛзщМмЙЙФЃЪНЃКЮЂЗўЮёМмЙЙФЃЪНЁЂService Mesh МмЙЙФЃЪНЁЂServerless ФЃЪНЁЂДцДЂМЦЫуЗжРыФЃЪНЁЂЗжВМЪНЪТЮёФЃЪНЁЂПЩЙлВтМмЙЙЁЂЪТМўЧ§ЖЏМмЙЙЁЃ
ЬжТлдЦдЩњЃЌЪЧдкЬжТлдЦдЩњФмИјЦѓвЕКЭгУЛЇДјРДЪВУДМлжЕЁЃ
дЦАбШэгВМўЕФФмСІЩ§МЖГЩЗўЮёЃЌаЮГЩЧПДѓЕФММЪѕЗўЮёФмСІКЭзЪдДгХЛЏФмСІЃЌШУгУЛЇвдЕЭГЩБОЁЂУєНнЕФЗНЪНЙЙНЈЪ§зжЛЏгІгУЃЌПЊЗЂепОлНЙдквЕЮёПЊЗЂЃЌЯЕЭГЬьШЛОпБИИпПЩгУЁЂИпвЦжВадЁЂИпЕЏадЕШЬиЕуЃЌДгЖјИГгшЦѓвЕКЭвЕЮёИќУєНнЕФЕќДњКЭИќИпаЇЕФШэМўНЛИЖФмСІЃЌЦѓвЕИќПьЭЦГіаТЕФВњЦЗЙІФмКЭЕузгЕНЪаГЁКЭгУЛЇЃЌАяжњвЕЮёИќПьЪдДэКЭДДаТЃЌдкШчНёШеаТдТвьЁЂОКељдНРДдНОчСвЕФЪаГЁДѓЛЗОГЯТДђдьЦѓвЕЕФКЫаФОКељСІЁЃ
дЦдЩњБОжЪЩЯвВЪЧвЛЬзЁАвдРћгУдЦМЦЫуММЪѕЮЊгУЛЇНЕБОдіаЇЁБЕФзюМбЪЕМљгыЗНЗЈТлЁЃ
ЬжТлдЦдЩњЃЌЪЧдкЬжТлдЦдЩњЕФММЪѕЁЃ
дЦдЩњПЊдДММЪѕЩњЬЌЛљБОЭГвЛСЫШэМўНЛИЖКЭдЫЮЌЕФФЃЪНЁЃШнЦїММЪѕКЭ Kubernetes ЗўЮёБрХХММЪѕЕФНсКЯЃЌНтОіСЫгІгУВПЪ№здЖЏЛЏЁЂБъзМЛЏЁЂХфжУЛЏЮЪЬтЁЃЮЂЗўЮёЭЈЙ§АбОоЪЏгІгУВ№НтЮЊШєИЩЕЅЙІФмЕФЗўЮёЃЌМѕЩйСЫЗўЮёМфЕФёюКЯадЃЌШУПЊЗЂКЭВПЪ№ИќМгБуНнКЭСщЛюЃЌПЩвдгааЇНЕЕЭПЊЗЂжмЦкЁЃService Mesh ШУжаМфМўЕФЩ§МЖКЭгІгУЯЕЭГЕФЩ§МЖЭъШЋНтёюЃЌдкдЫЮЌКЭЙмПиЗНУцЕФСщЛюадЛёЕУЬсЩ§ЁЃServerless ШУдЫЮЌЖдПЊЗЂЭИУїЃЌЖдгкгІгУЫљашзЪдДНјааздЖЏЩьЫѕЁЃFaaS ЪЧ Serverless ЕФвЛжжЪЕЯжЃЌдђИќМгМђЛЏСЫПЊЗЂдЫЮЌЕФЙ§ГЬЃЌДгПЊЗЂЕНзюКѓВтЪдЩЯЯпЖМПЩвддквЛИіМЏГЩПЊЗЂЛЗОГжаЭъГЩЁЃЫљвдЃЌдЦдЩњДњБэвЛЯЕСаЕФММЪѕЃЈШнЦїММЪѕЁЂдЦдЩњЮЂЗўЮёЁЂServerlessЁЂService Mesh ММЪѕЁЂDevOpsЃЉЃЌРДзюДѓЛЏРћгУдЦЕФФмСІЃЌЬсЩ§ПЊЗЂаЇТЪЃЌЬсЩ§гІгУНЛИЖжЪСПКЭЫйЖШЁЃ
ЫљвдЃЌЕНЕзЪВУДЪЧдЦдЩњЃП
ЮвИіШЫИќдИвтетбљРДНтЪЭдЦдЩњЃК
дЦдЩњДњБэзХвЛжжаТЕФШэМўЩшМЦРэФюЃЌгІгУДгвЛПЊЪМОЭБЛЩшМЦЮЊГЄдкдЦЩЯЁЂЩњдкдЦЩЯЃЌШУдЦЛљДЁЩшЪЉРДНгЙмгІгУжаЕФЗЧвЕЮёадДњТыКЭЙІФмЃЌгУЛЇзЈзЂгкеце§гаМлжЕЕФвЕЮёДњТыЃЌГфЗжЗЂЛгдЦЕФгХЪЦЃЌвдСщЛюЁЂЕЭГЩБОЕФЗНЪНЙЙНЈЕЏадЁЂПЩРЉеЙЕФгІгУЃЛЭЌЪБЃЌдЦдЩњвВДњБэзХвЛЯЕСаЕФЗНЗЈТлЁЂЪЕМљКЭММЪѕЃЌАќРЈШнЦїЁЂЮЂЗўЮёЁЂServerlessЁЂDevOpsЁЂЗўЮёЭјИёЕШЁЃетаЉЗНЗЈТлКЭММЪѕЃЌАяжњЮвУЧЙЙНЈШЭадЁЂЕЏадЁЂПЩвЦжВЁЂПЩРЉеЙЕФгІгУЃЌЬсЩ§ЦѓвЕЕФШэМўНЛИЖФмСІЃЌИГгшЦѓвЕУєНнЕќДњЁЂПьЫйЪдДэКЭДДаТЕФОКељСІЁЃ
ЪВУДЪЧдЦдЩњЛђаэЛсвЛжБдкБфЃЌвВЛђаэгРдЖУЛгаШЗЧаКЭБъзМЕФД№АИЃЌЕЋе§ЪЧетжжЁАгРдЖУЛгаШЗЧаЖЈвхЁБЕФЬиЕуШУдЦдЩњБЃГжСЫГжајЩњУќСІЃЌЦфРэФюКЭММЪѕВЛЖЯИяаТКЭбнНјЃЌЭЦЖЏдЦМЦЫуЯђЧАЗЂеЙЁЃ
3ЁЂдЦдЩњЕФМмЙЙддђКЭЩшМЦФЃЪН
дЦдЩњвВИјГіСЫШєИЩгІгУМмЙЙддђКЭЩшМЦФЃЪНЃЌзїЮЊгІгУЕФМмЙЙПижЦУцЃЌв§ЕМКЭЙцЗЖМмЙЙЪІЩшМЦГіИпШнДэадЁЂЕЏадКЭПЩРЉеЙЕФгІгУЁЃ
вЛЁЂдЦдЩњМмЙЙддђ
1ЁЂЗўЮёЛЏддђ
ЭЈЙ§ЗўЮёЛЏАбВЛЭЌЩњУќжмЦкЕФФЃПщЗжРыГіРДЃЌЖРСЂвЕЮёЕќДњЃЌБмУтЕќДњЦЕЗБЕФФЃПщБЛБфЛЏЕЭЕФФЃПщЭЯТ§ЃЌДгЖјЬсЩ§ећЬхЕќДњЫйЖШКЭЮШЖЈадЁЃЗўЮёЛЏМмЙЙУцЯђНгПкЦѕдМБрГЬЃЌЗўЮёФкжАд№КЭЙІФмИпЖШФкОлЃЌЭЈЙ§ЬсШЁгІгУжаЙЋЙВЙІФмФЃПщДѓДѓЬсЩ§СЫШэМўЕФИДгУадЁЃдЦдЩњМмЙЙАбЗўЮёЛЏЗХдкЪзЮЛЃЌЛЙдкгкЗўЮёЛЏДгМмЙЙВуУцГщЯѓЛЏвЕЮёФЃПщжЎМфЕФЙиЯЕЃЌБъзМЛЏЗўЮёСїСПЕФДЋЪфЃЌДгЖјАяжњвЕЮёФЃПщНјааЛљгкЗўЮёСїСПЕФВпТдПижЦКЭжЮРэЃЌЗўЮёЪЧгУЪВУДгябдБраДЕФВЂВЛЙиаФЁЃ
2ЁЂЕЏадддђ
ЕЏадЪЧжИЯЕЭГЕФВПЪ№ЙцФЃПЩвдЫцзХвЕЮёСїСПКЭШнСПБфЛЏЖјздЖЏЩьЫѕЃЌЮоаыИљОнЪТЯШЕФШнСПЙцЛЎзМБИЙЬЖЈЕФгВМўКЭШэМўзЪдДЁЃКУЕФЕЏадФмСІВЛНіЫѕЖЬСЫДгВЩЙКЕНЩЯЯпЕФЪБМфЃЌШУЦѓвЕВЛгУВйаФЖюЭтШэгВМўзЪдДЕФГЩБОжЇГіЃЌЮоаыЮЊЯажУГЩБОТђЕЅЃЌНЕЕЭСЫЦѓвЕЕФ IT ГЩБОЃЌзюживЊЕФЪЧЕБвЕЮёУцСйЭЛЗЂадЕФШнСПРЉеХКЭСїСПдіГЄЪБЃЌВЛЛсвђЮЊШэгВМўзЪдДДЂБИВЛзуЖјжЇГХВЛСЫЃЌБмУтШУЦѓвЕДэЙ§вЕЮёКЭгУЛЇдіГЄЕФКУЛњЛсЃЌБЃеЯСЫЦѓвЕЪевцЁЃ
3ЁЂПЩЙлВтддђ
НЈСЂПЩЙлВтадЕФжївЊФПБъЪЧЖдЗўЮё SLOЃЈService Level ObjectiveЃЉНјааЖШСПЃЌДгЖјгХЛЏ SLAЃЌвђДЫМмЙЙЩшМЦЩЯашвЊЮЊИїИізщМўЖЈвхЧхЮњЕФ SLOЃЌАќРЈВЂЗЂЖШЁЂКФЪБЁЂПЩгУЪБГЄЁЂШнСПЕШЁЃДѓЙцФЃМЏШКгІгУжЎМфЕФЕїгУЙиЯЕЁЂхДЛњКЭЙЪеЯдвђЪЧМЋЦфИДдгЕФЃЌПЩЙлВтадПЩЪЙдЫЮЌЁЂПЊЗЂКЭвЕЮёШЫдБЪЕЪБеЦЮеШэМўдЫааЧщПіЃЌВЂНсКЯЖрИіЮЌЖШЕФЪ§ОнжИБъЃЌЛёЕУЙиСЊЗжЮіКЭЮЪЬтЙщвђЗжЮіЕФФмСІЃЌВЛЖЯЖдвЕЮёНЁПЕЖШКЭгУЛЇЬхбщНјааЪ§зжЛЏКтСПКЭГжајгХЛЏЁЃ
4ЁЂШЭадддђ
ШЭадДњБэСЫЕБШэМўЫљвРРЕЕФШэгВМўзщМўГіЯжИїжжвьГЃЪБЃЌШэМўБэЯжГіРДЕФЕжгљФмСІЃЌетаЉвьГЃЭЈГЃАќРЈгВМўЙЪеЯЁЂгВМўзЪдДЦПОБЃЈШч CPU/ ЭјПЈДјПэКФОЁЃЉЁЂвЕЮёСїСПГЌГіШэМўЩшМЦФмСІЁЂгАЯьЛњЗПЙЄзїЕФЙЪеЯКЭджФбЁЂШэМў bugЁЂКкПЭЙЅЛїЕШЖдвЕЮёВЛПЩгУДјРДжТУќгАЯьЕФвђЫиЁЃШЭадДгЖрИіЮЌЖШкЙЪЭСЫШэМўГжајЬсЙЉвЕЮёЗўЮёЕФФмСІЁЃДгМмЙЙЩшМЦЩЯЃЌШЭадАќРЈЗўЮёвьВНЛЏФмСІЁЂжиЪд / ЯоСї / НЕМЖ /ШлЖЯ / ЗДбЙЁЂжїДгФЃЪНЁЂМЏШКФЃЪНЁЂAZ ФкЕФИпПЩгУЁЂЕЅдЊЛЏЁЂПч region ШнджЁЂвьЕиЖрЛюШнджЕШЁЃ
5ЁЂздЖЏЛЏддђ
ММЪѕЭљЭљЪЧАбЁАЫЋШаНЃЁБЃЌШнЦїЁЂЮЂЗўЮёЁЂDevOpsЁЂДѓСПЕкШ§ЗНзщМўЕФЪЙгУЃЌдкНЕЕЭЗжВМЪНИДдгадКЭЬсЩ§ЕќДњЫйЖШЕФЭЌЪБЃЌвђЮЊећЬхдіДѓСЫШэМўММЪѕеЛЕФИДдгЖШКЭзщМўЙцФЃЃЌЫљвдВЛПЩБмУтЕиДјРДСЫШэМўНЛИЖЕФИДдгадЁЃGitOpsЁЂKubernetes operator КЭДѓСПздЖЏЛЏНЛИЖЙЄОпдк CI/CD СїЫЎЯпжаЕФЪЕМљЃЌвЛЗНУцБъзМЛЏЦѓвЕФкВПЕФШэМўНЛИЖЙ§ГЬЃЌСэвЛЗНУцдкБъзМЛЏЕФЛљДЁЩЯНјааздЖЏЛЏЃЌЭЈЙ§ХфжУЪ§ОнздУшЪіКЭУцЯђжеЬЌЕФНЛИЖЙ§ГЬЃЌШУздЖЏЛЏЙЄОпРэНтНЛИЖФПБъКЭЛЗОГВювьЃЌЪЕЯжећИіШэМўНЛИЖКЭдЫЮЌЕФздЖЏЛЏЁЃ
6ЁЂСуаХШЮддђ
СуаХШЮЪЧЖдЯЕЭГАВШЋМмЙЙКЭЩшМЦЫМЯыЕФжиаТЩѓЪгЃЌдкФЌШЯЧщПіЯТВЛгІИУаХШЮЭјТчФкЭтВПЕФШЮКЮШЫ/ЩшБИ/ЯЕЭГЃЌвЊЭЈЙ§ШЯжЄКЭЪкШЈЙЙНЈЗУЮЪПижЦЕФЛљДЁЁЃВЂЧвСуаХШЮвВЬхЯжгІгУЕФИпПЩгУКЭШнДэадНЈЩшЫМЯыжаЃЌМйЩшвЛЧаЩЯЯТгЮЁЂжаМфМўЁЂЭјТчЕШЖМгаПЩФмГіЯжЙЪеЯЃЌЗДЭЦгІгУздЩэНЈСЂШлЖЯЁЂЯоСїЁЂНЕМЖЁЂЖЕЕзЕШФмСІЃЌДгЖјЙЙНЈШЭадЁЂздгњКЭИпШнДэааЕФгІгУЁЃ
7ЁЂМмЙЙГжајбнНјддђ
ММЪѕКЭвЕЮёЕФбнНјЫйЖШЗЧГЃПьЃЌКмЩйгавЛПЊЪМОЭЧхЮњЖЈвхКЭЩшМЦВЂдкећИіШэМўЩњУќжмЦкРяУцЖМЪЪгУЕФМмЙЙЃЌЯрЗДЭљЭљЛЙашвЊЖдМмЙЙНјаавЛЖЈЗЖЮЇФкЕФжиЙЙЃЌвђДЫдЦдЩњМмЙЙБОЩэвВгІИУКЭБиаыЪЧвЛИіОпБИГжајбнНјФмСІЕФМмЙЙЃЌЖјВЛЪЧвЛИіЗтБеЪНМмЙЙЁЃдіСПЕќДњЁЂФПБъбЁШЁЃЌМмЙЙжЮРэКЭЗчЯеПижЦЁЃЪЧдквЕЮёИпЫйЕќДњЧщПіЯТЕФМмЙЙЁЂвЕЮёЁЂЪЕЯжЦНКтЙиЯЕЁЃ
ЖўЁЂдЦдЩњМмЙЙФЃЪН
1ЁЂЗўЮёЛЏМмЙЙФЃЪН
ЧѓвдФЃПщЮЊПХСЃЖШЛЎЗжвЛИіШэМўЗўЮёЃЌЗжРыФЃПщКЭВПЪ№ЙиЯЕЃЌВЛЭЌЗўЮёАДашЖРСЂЫѕРЉШнЃЌАДеевЕЮёЪєадЖРСЂЩ§МЖЕќДњЃЌЬсЩ§ећЬхЕќДњаЇТЪЁЃЮЂЗўЮёвдНгПкЦѕдМЖЈвхБЫДЫвЕЮёЙиЯЕЃЌвдБъзМавщШЗБЃБЫДЫЕФЛЅСЊЛЅЭЈЃЌНсКЯ DDDЃЈСьгђФЃаЭЧ§ЖЏЃЉЁЂTDDЃЈВтЪдЧ§ЖЏПЊЗЂЃЉЁЂШнЦїЛЏВПЪ№ЬсЩ§УПИіНгПкЕФДњТыжЪСПКЭЕќДњЫйЖШЁЃ
2ЁЂMesh МмЙЙФЃЪН
Mesh ЛЏМмЙЙЪЧАбжаМфМўПђМмЃЈБШШч RPCЁЂЛКДцЁЂвьВНЯћЯЂЕШЃЉДгвЕЮёНјГЬжаЗжРыЃЌШУжаМфМў SDK гывЕЮёДњТыНјвЛВННтёюЃЌДгЖјЪЙЕУжаМфМўЩ§МЖЖдвЕЮёНјГЬУЛгагАЯьЃЌЗжРыКѓдквЕЮёНјГЬжажЛБЃСєКмЁАБЁЁБЕФ Client ВПЗжЃЌClient ЭЈГЃКмЩйБфЛЏЃЌжЛИКд№гы Mesh НјГЬЭЈбЖЃЌдРДашвЊдк SDK жаДІРэЕФСїСППижЦЁЂАВШЋЕШТпМгЩ Mesh НјГЬЭъГЩЁЃЪЕЪЉ Mesh ЛЏМмЙЙКѓЃЌДѓСПЗжВМЪНМмЙЙФЃЪНЃЈШлЖЯЁЂЯоСїЁЂНЕМЖЁЂжиЪдЁЂЗДбЙЁЂИєВж??ЃЉЖМгЩ Mesh НјГЬЭъГЩЃЌМДЪЙдквЕЮёДњТыЕФжЦЦЗжаВЂУЛгаЪЙгУетаЉШ§ЗНШэМўАќЃЛЭЌЪБЛёЕУИќКУЕФАВШЋадЃЈБШШчСуаХШЮМмЙЙФмСІЃЉЁЂАДСїСПНјааЖЏЬЌЛЗОГИєРыЁЂЛљгкСїСПзіУАбЬ / ЛиЙщВтЪдЕШЁЃ
3ЁЂServerless ФЃЪН
Serverless НЋЁАВПЪ№ЁБетИіЖЏзїДгдЫЮЌжаЁАЪезпЁБЃЌЪЙПЊЗЂепВЛгУЙиаФгІгУдкФФРядЫааЃЌИќВЛгУЙиаФзАЪВУД OSЁЂдѕУДХфжУЭјТчЁЂашвЊЖрЩй CPU ?ЁЃЪЧЗёЪЪКЯгк Serverless дЫЫуЁЃШчЙћгІгУЪЧгазДЬЌЕФЃЌдЦдкНјааЕїЖШЪБПЩФмЕМжТЩЯЯТЮФЖЊЪЇЃЌБЯОЙ Serverless ЕФЕїЖШВЛЛсАяжњгІгУзізДЬЌЭЌВНЃЛШчЙћгІгУЪЧГЄЪБМфКѓЬЈдЫааЕФУмМЏаЭМЦЫуШЮЮёЃЌЛсЕУВЛЕНЬЋЖр Serverless ЕФгХЪЦЃЛШчЙћгІгУЩцМАЕНЦЕЗБЕФЭтВП I/OЃЈЭјТчЛђепДцДЂЃЌвдМАЗўЮёМфЕїгУЃЉЃЌвВвђЮЊЗБжиЕФ I/O ИКЕЃЁЂЪБбгДѓЖјВЛЪЪКЯЁЃServerless ЗЧГЃЪЪКЯгкЪТМўЧ§ЖЏЕФЪ§ОнМЦЫуШЮЮёЁЂМЦЫуЪБМфЖЬЕФЧыЧѓ / ЯьгІгІгУЁЂУЛгаИДдгЯрЛЅЕїгУЕФГЄжмЦкШЮЮёЁЃ
4ЁЂДцДЂМЦЫуЗжРыФЃЪН
дкдЦЛЗОГжаЃЌЭЦМіАбИїРрднЬЌЪ§ОнЃЈШч sessionЃЉЁЂНсЙЙЛЏКЭЗЧНсЙЙЛЏГжОУЪ§ОнЖМВЩгУдЦЗўЮёРДБЃДцЃЌДгЖјЪЕЯжДцДЂМЦЫуЗжРыЁЃвЛаЉзДЬЌШчЙћБЃДцЕНдЖЖЫЛКДцЃЌЛсдьГЩНЛвзадФмЕФУїЯдЯТНЕЃЌБШШчНЛвзЛсЛАЪ§ОнЬЋДѓЁЂашвЊВЛЖЯИљОнЩЯЯТЮФжиаТЛёШЁЕШЃЌдђПЩвдПМТЧЭЈЙ§ВЩгУ Event Log + ПьееЃЈЛђ Check PointЃЉЕФЗНЪНЃЌЪЕЯжжиЦєКѓПьЫйдіСПЛжИДЗўЮёЃЌМѕЩйВЛПЩгУЖдвЕЮёЕФгАЯьЪБГЄЁЃ
5ЁЂЪТМўЧ§ЖЏМмЙЙ
БОжЪЩЯЪЧвЛжжгІгУ/ зщМўМфЕФМЏГЩМмЙЙФЃЪНЁЃЪТМўОпга schemaЃЌЫљвдПЩвдаЃбщ event ЕФгааЇадЃЌЭЌЪБ EDA ОпБИ QoS БЃеЯЛњжЦЃЌвВФмЙЛЖдЪТМўДІРэЪЇАмНјааЯьгІЁЃЪТМўЧ§ЖЏФЃЪНвЛАугУдкЯТУцГЁОАЯТЃК
діЧПЗўЮёШЭадЃК гЩгкЗўЮёМфЪЧвьВНМЏГЩЕФЃЌвВОЭЪЧЯТгЮЕФШЮКЮДІРэЪЇАмЩѕжСхДЛњЖМВЛЛсБЛЩЯгЮИажЊЁЃ
CQRS ЃЈCommand Query Responsibility SegregationЃЉЃКАбЖдЗўЮёзДЬЌгагАЯьЕФУќСюгУЪТМўРДЗЂЦ№ЃЌЖјЖдЗўЮёзДЬЌУЛгагАЯьЕФВщбЏВХЪЙгУЭЌВНЕїгУЕФ API НгПкЃЛНсКЯ EDA жаЕФ Event Sourcing ПЩвдгУгкЮЌЛЄЪ§ОнБфИќЕФвЛжТадЃЌЕБашвЊжиаТЙЙНЈЗўЮёзДЬЌЪБЃЌАб EDA жаЕФЪТМўжиаТЁАВЅЗХЁБвЛБщМДПЩЁЃ
ЙЙНЈПЊЗХЪННгПк ЃКдк EDA ЯТЃЌЪТМўЕФЬсЙЉепВЂВЛгУЙиаФгаФФаЉЖЉдФепЃЌВЛЯёЗўЮёЕїгУЕФГЁОА ЁЊЁЊ Ъ§ОнЕФВњЩњепашвЊжЊЕРЪ§ОнЕФЯћЗбепдкФФРяВЂЕїгУЫќЃЌвђДЫБЃГжСЫНгПкЕФПЊЗХадЃЛ
ЪТМўСїДІРэ ЃКгІгУгкДѓСПЪТМўСїЃЈЖјЗЧРыЩЂЪТМўЃЉЕФЪ§ОнЗжЮіГЁОАЃЌЕфаЭгІгУЪЧЛљгк Kafka ЕФШежОДІРэЁЃ
ЛљгкЪТМўДЅЗЂЕФЯьгІЃКдк IoT ЪБДњДѓСПДЋИаЦїВњЩњЕФЪ§ОнЃЌВЛЛсЯёШЫЛњНЛЛЅвЛбљашвЊЕШД§ДІРэНсЙћЕФЗЕЛиЃЌЬьШЛЪЪКЯгУ EDA РДЙЙНЈЪ§ОнДІРэгІгУЁЃ
Ъ§ОнБфЛЏЭЈжЊ ЃКдкЗўЮёМмЙЙЯТЃЌЭљЭљвЛИіЗўЮёжаЕФЪ§ОнЗЂЩњБфЛЏЃЌСэЭтЕФЗўЮёЛсИааЫШЄЃЌБШШчгУЛЇЖЉЕЅЭъГЩКѓЃЌЛ§ЗжЗўЮёЁЂаХгУЗўЮёЕШЖМашвЊЕУЕНЪТМўЭЈжЊВЂИќаТгУЛЇЛ§ЗжКЭаХгУЕШМЖЁЃ
6ЁЂПЩЙлВтМмЙЙ
ПЩЙлВтМмЙЙАќРЈ LoggingЁЂTracingЁЂMetrics Ш§ИіЗНУцЃЌЦфжа Logging ЬсЙЉЖрИіМЖБ№(verbose/ debug/warning/error/fatal)ЕФЯъЯИаХЯЂИњзйЃЌгЩгІгУПЊЗЂепжїЖЏЬсЙЉЃЛTracing ЬсЙЉвЛИіЧыЧѓДгЧАЖЫ ЕНКѓЖЫЕФЭъећЕїгУСДТЗИњзйЃЌЖдгкЗжВМЪНГЁОАгШЦфгагУЃЛMetrics дђЬсЙЉЖдЯЕЭГСПЛЏЕФЖрЮЌЖШЖШСПЁЃ
4ЁЂдЦдЩњжївЊММЪѕ
дЦдЩњБГКѓАќКЌСЫвЛЯЕСаЕФММЪѕЃЌЭЈЙ§дкгІгУжаВЩФЩКЭЪЕМљетаЉММЪѕЃЌРДШУЮвУЧЯэЪмдЦМЦЫуЕФгХЪЦКЭКьРћЃЌШУЮвУЧОлНЙвЕЮёМлжЕНЛИЖЃЌЬсЩ§ЦѓвЕУєНнадКЭДДаТФмСІЁЃ
вЛЁЂШнЦї
ЮЊСЫИќКУРэНтШнЦїЪЧЪВУДЃЌгаЪВУДМлжЕЃЌЮвУЧгаБивЊЛиЙЫвЛЯТШэМўВПЪ№МмЙЙКЭНЛИЖЕФРњЪЗЃЌЯТУцетеХЭМЃЈЯраХДѓМввбОПДЙ§ЮоЪ§ДЮСЫЃЉПЩвдКмКУЕФУшЪіШэМўВПЪ№ЕФЗЂеЙШ§НзЖЮЃК

1ЁЂДЋЭГВПЪ№ЪБДњ ЃК
дчЦкЃЌИїИізщжЏЛњЙЙдкЮяРэЗўЮёЦїЩЯдЫаагІгУГЬађЁЃЮоЗЈЮЊЮяРэЗўЮёЦїжаЕФгІгУГЬађЖЈвхзЪдДБпНчЃЌетЛсЕМжТзЪдДЗжХфЮЪЬтЁЃР§ШчЃЌШчЙћдкЮяРэЗўЮёЦїЩЯдЫааЖрИігІгУГЬађЃЌдђПЩФмЛсГіЯжвЛИігІгУГЬађеМгУДѓВПЗжзЪдДЕФЧщПіЃЌНсЙћПЩФмЕМжТЦфЫћгІгУГЬађЕФадФмЯТНЕЁЃвЛжжНтОіЗНАИЪЧдкВЛЭЌЕФЮяРэЗўЮёЦїЩЯдЫааУПИігІгУГЬађЃЌЕЋЪЧгЩгкзЪдДРћгУВЛзуЖјЮоЗЈРЉеЙЃЌВЂЧвЮЌЛЄаэЖрЮяРэЗўЮёЦїЕФГЩБОКмИпЁЃ
2ЁЂащФтЛЏВПЪ№ЪБДњ ЃК
зїЮЊНтОіЗНАИЃЌв§ШыСЫащФтЛЏЁЃащФтЛЏММЪѕдЪаэФудкЕЅИіЮяРэЗўЮёЦїЕФ CPU ЩЯдЫааЖрИіащФтЛњЃЈVMЃЉЁЃ ащФтЛЏдЪаэгІгУГЬађдк VM жЎМфИєРыЃЌВЂЬсЙЉвЛЖЈГЬЖШЕФАВШЋЃЌвђЮЊвЛИігІгУГЬађЕФаХЯЂ ВЛФмБЛСэвЛгІгУГЬађЫцвтЗУЮЪЁЃ
ащФтЛЏММЪѕФмЙЛИќКУЕиРћгУЮяРэЗўЮёЦїЩЯЕФзЪдДЃЌВЂЧввђЮЊПЩЧсЫЩЕиЬэМгЛђИќаТгІгУГЬађЖјПЩвдЪЕЯжИќКУЕФПЩЩьЫѕадЃЌНЕЕЭгВМўГЩБОЕШЕШЁЃУПИі VM ЪЧвЛЬЈЭъећЕФМЦЫуЛњЃЌдкащФтЛЏгВМўжЎЩЯдЫааЫљгазщМўЃЌАќРЈЦфздМКЕФВйзїЯЕЭГЁЃ
3ЁЂШнЦїВПЪ№ЪБДњ ЃК
ШнЦївВЪЧвЛжжЩГЯфЫМЯыЕФЬхЯжЃЌЦСБЮВЛЭЌЛЗОГжЎМфЕФВювьЃЌНјЖјЛљгкШнЦїзіБъзМЛЏЕФШэМўНЛИЖЁЃПЊЗЂепПЩвдДђАќЫћУЧЕФгІгУвдМАвРРЕАќЕНвЛИіПЩвЦжВЕФОЕЯёжаЃЌШЛКѓЗЂВМЕНШЮКЮСїааЕФ Linux Лђ Windows ЛњЦїЩЯЃЌЫљвдвВПЩвдГЦШнЦїЪЧвЛИіЪгЭМИєРыЁЂзЪдДПЩЯожЦЁЂЖРСЂЮФМўЯЕЭГЃЈОЕЯёЪЧШнЦїЫљашЕФЖўНјжЦЮФМўЁЂХфжУЮФМўвдМАвРРЕЕФЮФМўМЏКЯЃЉЕФНјГЬМЏКЯЁЃ
VM ЪЧЖдгВМўзЪдДЕФащФтЃЌDocker ЪЧЖдВйзїЯЕЭГЕФащФтЁЃЯрБШ VMЃЌDocker БШащФтЛЏЩйСЫСНВуЃК hypervisor ВуКЭ GuestOS ВуЃЌЪЙгУ Docker Engine НјааЕїЖШКЭИєРыЃЌЫљгагІгУЙВгУжїЛњВйзїЯЕЭГЃЌвђДЫдкЬхСПЩЯЃЌDocker НЯащФтЛњИќЧсСПМЖЃЌдкадФмЩЯгХгкащФтЛЏЃЌНгНќТуЛњадФмЁЃ
е§ШчМЏзАЯфЕФГіЯжМгЫйСЫУГвзШЋЧђЛЏНјГЬЃЌвдШнЦїЮЊДњБэЕФММЪѕзїЭЦЖЏКЭМгЫйдЦМЦЫуКЭдЦдЩњЦеМАКЭЗЂеЙЁЃКНдЫвЕЪЙгУЮяРэШнЦїЃЈМЏзАЯфЃЉРДДђАќКЭИєРыВЛЭЌЕФЛѕЮяЃЌвдБудкТжДЌЁЂЛ№ГЕЁЂПЈГЕКЭЗЩЛњЩЯдЫЪфЃЌдЦдЩњЪБДњЃЌАбгІгУГЬађЕФДњТыгыЯрЙиХфжУЮФМўЁЂПтвдМАдЫаагІгУЫљашЕФвРРЕЯюРІАѓдквЛЦ№ЃЌШУгІгУПЩвдПчдЦЦНЬЈКЭММЪѕЩшЪЉЃЌвдвЛжТКЭПЩППЕФЗНЪНдЫааЁЃетЪЙЕУПЊЗЂепКЭ IT зЈвЕШЫдБФмЙЛИќПьЁЂИќАВШЋЕиДДНЈКЭВПЪ№гІгУГЬађЁЃШнЦїММЪѕдкгІгУГЬађЕФећИіЩњУќжмЦкЙЄзїСїжаЬсЙЉСЫИпИєРыЁЂПЩвЦжВадЁЂСщЛюадЁЂПЩЩьЫѕадКЭПижЦгХЪЦЁЃ
ШнЦїОпгаШчЯТгХЪЦЃК
- УєНнгІгУГЬађЕФДДНЈКЭВПЪ№ЃКгыЪЙгУ VM ОЕЯёЯрБШЃЌЬсИпСЫШнЦїОЕЯёДДНЈЕФМђБуадКЭаЇТЪЁЃ
- ГжајПЊЗЂЁЂМЏГЩКЭВПЪ№ЃКЭЈЙ§ПьЫйМђЕЅЕФЛиЙіЃЈгЩгкОЕЯёВЛПЩБфадЃЉЃЌжЇГжПЩППЧвЦЕЗБЕФШнЦїОЕЯёЙЙНЈКЭВПЪ№ЁЃ
- ЙизЂПЊЗЂгыдЫЮЌЕФЗжРыЃКдкЙЙНЈ/ЗЂВМЪБЖјВЛЪЧдкВПЪ№ЪБДДНЈгІгУГЬађШнЦїОЕЯёЃЌ ДгЖјНЋгІгУГЬађгыЛљДЁМмЙЙЗжРыЁЃ
- ПЩЙлВьадВЛНіПЩвдЯдЪОВйзїЯЕЭГМЖБ№ЕФаХЯЂКЭжИБъЃЌЛЙПЩвдЯдЪОгІгУГЬађЕФдЫаазДПіКЭЦфЫћжИБъаХКХЁЃ
- ПчПЊЗЂЁЂВтЪдКЭЩњВњЕФЛЗОГвЛжТадЃКдкБуаЏЪНМЦЫуЛњЩЯгыдкдЦжаЯрЭЌЕидЫааЁЃ
- ПчдЦКЭВйзїЯЕЭГЗЂааАцБОЕФПЩвЦжВадЃКПЩдк UbuntuЁЂRHELЁЂCoreOSЁЂБОЕиЁЂ Google Kubernetes Engine КЭЦфЫћШЮКЮЕиЗНдЫааЁЃ
- вдгІгУГЬађЮЊжааФЕФЙмРэЃКЬсИпГщЯѓМЖБ№ЃЌДгдкащФтгВМўЩЯдЫаа OS ЕНЪЙгУТпМзЪдДдк OS ЩЯдЫаагІгУГЬађЁЃ
- ЫЩЩЂёюКЯЁЂЗжВМЪНЁЂЕЏадЁЂНтЗХЕФЮЂЗўЮёЃКгІгУГЬађБЛЗжНтГЩНЯаЁЕФЖРСЂВПЗжЃЌВЂЧвПЩвдЖЏЬЌВПЪ№КЭЙмРэ- ЖјВЛЪЧдквЛЬЈДѓаЭЕЅЛњЩЯећЬхдЫааЁЃ
- зЪдДИєРыЃКПЩдЄВтЕФгІгУГЬађадФмЁЃ
- зЪдДРћгУЃКИпаЇТЪКЭИпУмЖШЁЃ
Docker ЪЧвЛИіЕфаЭЕФПЊдДЁЂСїаагІгУШнЦїв§ЧцЃЌвбГЩЮЊдЦЪБДњгІгУЗжЗЂКЭНЛИЖЕФЪТЪЕБъзМЁЃDocker ЪЙгІгУЭЈЙ§ЁАздАќКЌЁБЕФЗНЪНДђАќгІгУЃЌЪЙгІгУвдУєНнЁЂПЩРЉеЙЁЂПЩИДжЦЕФЗНЪНЗЂВМдкдЦЩЯЃЌМЋДѓЬсЩ§гІгУЕФПЩвЦжВадЁЂВПЪ№УмЖШКЭЕЏадЃЌзюДѓЛЏЗЂЛгГідЦЕФФмСІЁЃетвВОЭЪЧШнЦїММЪѕЖддЦЗЂЛгГіЕФИяУќадгАЯьЫљдкЃЌШнЦїММЪѕШУЙмРэгІгУЕШгкЙмРэШнЦїБОЩэЃЌвђДЫШнЦїММЪѕЪЧдЦдЩњММЪѕЕФКЫаФЕзХЬЁЃ
ЖўЁЂKubernetes
1ЁЂЪВУДЪЧ KubernetesЃП
Docker ЬхЯЕЪЧвдЁАЕЅвЛШнЦїЁБЮЊКЫаФЕФгІгУЖЈвхЗНЪНЃЌЖјгІгУГЬађРЉеЙЕНПчЖрИіЗўЮёЦїВПЪ№ЕФЖрИіШнЦїЃЌвђДЫЖдЦфНјааВйзїБфЕУИќМгИДдгЁЃШчКЮаЕїКЭАВХХЖрИіШнЦїЃПгІгУГЬађжаЫљгаВЛЭЌЕФШнЦїжЎМфШчКЮЪЕЯжЯрЛЅЭЈаХЃПШчКЮЫѕЗХЖрИіШнЦїЪЕР§ЃПетОЭашвЊвЛИіПЩвдЖдгІгУНјааБрХХКЭЕїЖШЕФМЦЫуЁЃKubernetesЁЃ
DockerЁЂMesosphereЁЂKubernetes дкЁАгІгУЁБгазХВЛЭЌРэНтКЭЖЅВуЩшМЦЃЌЖј Kubernetes дђЬсГіСЫвЛећЬзШнЦїЛЏЩшМЦФЃЪНКЭЖдгІЕФПижЦФЃаЭЃЌДгЖјУїШЗСЫШчКЮеце§вдШнЦїЮЊКЫаФЙЙНЈФмЙЛеце§ИњПЊЗЂепЖдНгЦ№РДЕФгІгУНЛИЖКЭПЊЗЂЗЖЪНЃЌзюже Kubernetes ШЁЕУЕНСЫдЦЪБДњгІгУБрХХЕФЙиМќСьЕМЕиЮЛЁЃ
Kubernetes зїЮЊДѓЙцФЃЗжВМЪНзЪдДЕїЖШКЭБрХХЕФв§ЧцЃЌвбГЩЮЊдЦЪБДњШнЦїЕїЖШКЭБрХХЕФЪТЪЕБъзМЃЌЯждкКмЖрШЫвВГЦ Kubernetes ЮЊдЦдЩњЕФВйзїЯЕЭГЁЃKubernetes вдвЛжжПЩвЦжВЁЂПЩЩьЫѕЧвПЩРЉеЙЕФЗНЪНЪЕЯжЛљгкШнЦїЕФгІгУГЬађЃЌПЩЪЕЯжздЖЏЛЏЕФзЪдДЕїЖШЁЂгІгУздЖЏВПЪ№КЭЛиЙіЁЂЕЏадЩьЫѕЁЂЗўЮёЗЂЯжКЭИКдиОљКтЁЂздЮваоИД/здгњЃЌЭЈЙ§ЦСБЮСЫЕзВуМмЙЙЕФИДдгадКЭВювьадЃЌАяжњгІгУЦНЛЌдЫаадкВЛЭЌЛљДЁЩшЪЉЩЯЁЃ
змНсРДЫЕЃЌKunbernetes ПЩвдАяжњЮвУЧЃК
зЪдДЕїЖШ
ИљОнгІгУЧыЧѓЕФзЪдДСП CPUЁЂMemoryЃЌЛђеп GPU ЕШЩшБИзЪдДЃЌдкМЏШКжабЁдёКЯЪЪЕФНкЕуРДдЫаагІгУЁЃKubernetes ПЩвдИќМгГфЗжЕиРћгУгВМўЃЌзюДѓГЬЖШЛёШЁдЫааЦѓвЕгІгУЫљашЕФзЪдДЁЃ
гІгУВПЪ№КЭЙмРэ
жЇГжгІгУЕФздЖЏЗЂВМгыгІгУЕФЛиЙіЃЌвдМАгыгІгУЯрЙиЕФХфжУЕФЙмРэЁЃвВПЩвдздЖЏЛЏДцДЂОэЕФБрХХЃЌШУДцДЂОэгыШнЦїгІгУЕФЩњУќжмЦкЯрЙиСЊЁЃ
здЖЏаоИД
Kubernetes ШУгІгУЛњЦїОпБИздгњФмСІЃЌЭЈЙ§МрВтетИіМЏШКжаЫљгаЕФЫожїЛњЃЌжиаТЦєЖЏЪЇАмЕФШнЦїЁЂЬцЛЛШнЦїЁЂЩБЫРВЛЯьгІгУЛЇЖЈвхЕФдЫаазДПіМьВщЕФШнЦїЃЌЪЕааЛњЦїздЖЏаоИДЁЃетвЛЧаЖдгкПЭЛЇЖЫРДЫЕЖМЪЧЭИУїКЭздЖЏЛЏЕФЃЌМЋДѓМђЛЏСЫдЫЮЌЙмРэЕФИДдгадЁЃ
ЗўЮёЗЂЯжКЭИКд№ОљКт
ЭЈЙ§ Service зЪдДГіЯжИїжжгІгУЗўЮёЃЌНсКЯ DNS КЭЖржжИКдиОљКтЛњжЦЃЌжЇГжШнЦїЛЏ гІгУжЎМфЕФЯрЛЅЭЈаХЁЃ
ЕЏадЩьЫѕ
K8s ПЩвдМрВтвЕЮёЩЯЫљГаЕЃЕФИКдиЃЌШчЙћетИівЕЮёБОЩэЕФ CPU РћгУТЪЙ§ИпЃЌЛђепЯьгІЪБМфЙ§ГЄЃЌ ЫќПЩвдЖдетИівЕЮёНјааздЖЏРЉШнЁЃЕБЗЂЯж CPU РћгУТЪЙ§ЕЭЃЌЛђ QPS ЯТНЕЃЌK8s вВПЩвдДЅЗЂздЖЏЫѕШнЃЌБмУтзЪдДЯажУЁЃ
2ЁЂKubernetes БОжЪ
Kubernetes ЕФКЫаФФмСІЪЧШнЦїЕїЖШКЭБрХХЁЃЖЈЮЛЪЧгІгУЛљДЁЩшЪЉЃЌНщгк IaaS гы PaaS жЎМфЃЌУцЯђЦНЬЈПЊЗЂепЃЌШУУПИіШЫФмЙЛПЊЗЂздМКЕФ PaaSЁЃЖдБШ Linux гы Kubernetes ЕФИХФюФЃаЭЃЌЫћУЧЖМЪЧЖЈвхСЫПЊЗХЕФЁЂБъзМЛЏЕФЗУЮЪНгПкЃКЯђЯТЗтзАзЪдДЃЌЯђЩЯжЇГХгІгУЃЌДгФГжжвтвхЩЯРДНВЃЌKubernetes вбОГЩЮЊдЦЪБДњЕФВйзїЯЕЭГЁЃ
Kubernetes МмЙЙЕФБОжЪОЭЪЧ 2 ИіЖЋЮїЃКЩљУїЪН API гыПижЦЦїФЃЪНЁЃЩљУїЪН API ЪЧЖдЕзВуЛљДЁЪЕЪЉИїжжФмСІЕФЩљУїЪН API ЖЈвхЃЌвВОЭЪЧНЈФЃГЩвЛЗнЪ§ОнЃЌРэТлЩЯЩљУїЪН API ПЩвдЖдвЛЧагІгУЛљДЁЪЕЪЉЁАФмСІЁБНјааНЈФЃЃЌЪ§ОнжаЕФФкШнЪЧЖдИУгІгУЛљДЁЪЕЪЉЦкЭћзДЬЌЕФУшЪіЁЃЪ§ОнЕФдіЩОВщИФЛсДЅЗЂПижЦЦїжДааЖдгІЕФдЫЮЌТпМЃЌвдДЫРДЧ§ЖЏЕзВуЛљДЁЪЕЪЉЯђЪ§ОнЫљЖЈвхЕФЦкЭћзДЬЌБЦНќЁЃ
3ЁЂKubernetes МмЙЙКЭИХФю
3.1ЁЂМмЙЙ
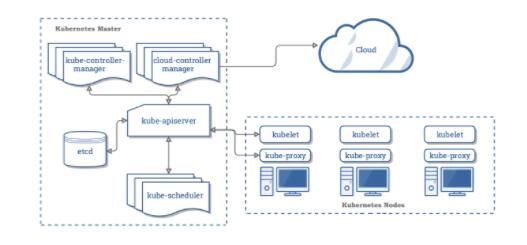
вЛИі K8s МЏШКгЩвЛзщНкЕузщГЩЃЌетаЉНкЕуПЩвдЪЧащФтЛњвВПЩвдЪЧЮяРэЛњЃЌДгжАд№РДПДетаЉНкЕуПЩвдЗжЮЊ 2 РрЁЃвЛРрЪЧИКд№ЙмРэећИі K8s МЏШКЕФПижЦЦНУцЃЌЭЈГЃдЫаадк Master НкЕуЩЯЃЌгУРДБЉТЖ API КЭНгПкРДЖЈвхЁЂ ВПЪ№ШнЦїКЭЙмРэШнЦїЕФЩњУќжмЦкЁЃПижЦЦНУцЕФзщМўЖдМЏШКзіГіШЋОжОіВп(БШШчЕїЖШ)ЃЌвдМАМьВтКЭЯьгІМЏШКЪТМўЃЈР§ШчЃЌЕБВЛТњзуВПЪ№ЕФ replicas зжЖЮЪБЃЌЦєЖЏаТЕФ podЃЉЃЌАќКЌСЫ kube-apiserverЁЂkube-controller-managerЁЂkube-scheduler КЭ ectedЃЛСэвЛРрЪЧЙЄзїНкЕуЃЈNodeЃЉЃЌNode ЪЧ Kubernetes МЏШКМмЙЙжадЫаа Pod ЕФЗўЮёНкЕуЃЌЪЧ Kubernetes МЏШКВйзїЕФЕЅдЊЃЌгУРДГадиБЛЗжХф Pod ЕФдЫааЃЌЪЧ Pod дЫааЕФЫожїЛњЁЃдЫаа Docker Eninge ЗўЮёЃЌЪиЛЄНјГЬ kunelet МАИКдиОљКтЦї kube-proxyЁЃ
3.2ЁЂе§ГЃдЫааЕФ Kubernetes МЏШКЫљашЕФИїжжзщМўЁЃ
ПижЦЦНУцзщМў
- kube-apiserver
зїЮЊ Kubernetes ЯЕЭГЕФШыПкЃЌЦфЗтзАСЫКЫаФЖдЯѓЕФдіЩОИФВщВйзїЃЌвд RESTful API НгПкЗНЪНЬсЙЉИјЭтВППЭЛЇКЭФкВПзщМўЕїгУЃЌМЏШКФкИїИіЙІФмФЃПщжЎМфЪ§ОнНЛЛЅКЭЭЈаХЕФжааФЪрХІЁЃ
жЛга API Server гыДцДЂЭЈаХЃЌЦфЫћФЃПщЭЈЙ§ API Server ЗУЮЪМЏШКзДЬЌЁЃетбљЕквЛЃЌЪЧЮЊСЫБЃжЄМЏШКзДЬЌЗУЮЪЕФАВШЋЁЃЕкЖўЃЌЪЧЮЊСЫИєРыМЏШКзДЬЌЗУЮЪЕФЗНЪНКЭКѓЖЫДцДЂЪЕЯжЕФЗНЪНЃКAPI Server ЪЧзДЬЌЗУЮЪЕФЗНЪНЃЌВЛЛсвђЮЊКѓЖЫДцДЂММЪѕ etcd ЕФИФБфЖјИФБфЁЃМгШывдКѓНЋ etcd ИќЛЛГЩЦфЫћЕФДцДЂЗНЪНЃЌВЂВЛЛсгАЯьвРРЕвРРЕ API Server ЕФЦфЫћ K8s ЯЕЭГФЃПщЁЃ
- etcd
etcd ЪЧМцОпвЛжТадКЭИпПЩгУадЕФЧсСПМЖМќжЕЪ§ОнПтЃЌetcd ЪЧ Kubernetes ЕФЙиМќзщМўЃЌЪЧ K8s МЏШКдЫааЕФДѓФдЃЌвђЮЊЫќДцДЂСЫМЏШКЕФећИізДЬЌЃКЦфХфжУЃЌЙцИёвдМАдЫаажаЕФЙЄзїИКдиЕФзДЬЌЁЃжївЊЪЙгУГЁОААќРЈЃК
- ЗўЮёЗЂЯж ЃКЗжВМЪНЯЕЭГжаЃЌашвЊГЩАйЩЯЧЇИіНјГЬРДЬсЙЉвЛзщЖдЕШЕФЗўЮёПЩвдРћгУ etc РДНтОізЪдДзЂВсЕФЮЪЬтЃЌЕБетвЛзщКѓЖЫНјГЬБЛЕїЖШЃЌдкНјГЬФкВПЦєЖЏжЎКѓЃЌПЩвдНЋздЩэЫљдкЕФЕижЗзЂВсЕН etcdЁЃAPI ЭјЙиФмЙЛЭЈЙ§ etcd МАЪБИажЊЕНКѓЖЫНјГЬЕФЕижЗЃЌетбљЕБКѓЖЫНјГЬЗЂЩњЙЪеЯЧЈвЦЕФЪБКђЃЌЛсжиаТзЂВсЕН etcd жаЃЌЪЙЕУ API ЭјЙиФмЙЛМАЪБЕиИажЊЕНаТЕФМЏШКЕижЗЁЃЭЌЪБЃЌвђЮЊ etcd ЬсЙЉЕФ Lease ВйзїЃЌПЩвдМАЪБИажЊЕННјГЬзДЬЌЕФБфЛЏЃЌШчЙћНјГЬдЫааЙ§ГЬжаЫРЕєСЫЃЌФЧУДЭјЙиПЩвдМАЪБИажЊЕННјГЬзДЬЌЕФБфЛЏЃЌДгЖјНЋСїСПздЖЏЕиЧаЕНЦфЫћЕФНјГЬЁЃЃЈзЪдДзЂВсЃЌДцЛюадМьВтЃЌAPI ЭјЙиЮозДЬЌПЩЫЎЦНРЉеЙЃЌжЇГжЩЯЭђИіНјГЬЕФЙцФЃЃЉ
- ЗжВМЪНЯЕЭГВЂЗЂПижЦ ЃКжДаавЛаЉМЦЫуШЮЮёЕФЪБКђЃЌЭЈГЃЧщПіЯТашвЊПижЦШЮЮёЕФВЂЗЂЖШЁЃвђЮЊШЮЮёЕНСЫКѓЖЫЗўЮёЃЌЭЈГЃЪЧгаШнСПЦПОБЕФЃЈЗжВМЪНаХКХСПЃЌздЖЏЬпГіЙЪеЯНкЕуЃЌДцДЂНјГЬЕФжДаазДЬЌЃЉ
- Kubernetes дЊЪ§ОнДцДЂ ЃКгУгкБЃДцМЏШКЫљгаЕФЭјТчХфжУКЭЖдЯѓЕФзДЬЌаХЯЂЁЃЭЈЙ§ watch ЛњжЦЃЌЪЕЪБЭЈжЊХфжУБфЛЏЃЌЭЈЙ§ raft ЫуЗЈБЃГжЯЕЭГЪ§ОнЕФ cp КЭЧПвЛжТадЁЃ
- kube-scheduler
Kubernetes Scheduler ШЗЖЈШчКЮдкЙЄзїЦїНкЕужЎМфВПЪ№ Pod КЭ ReplicaSetЃЌвдМАШчКЮЯђетаЉНкЕуЗжЗЂСїСПЁЃдкећИіЯЕЭГжаГаЕЃСЫЁАГаЩЯЦєЯТЁБЕФживЊЙІФмЃЌЁАГаЩЯЁБЪЧжИЫќИКд№НгЪе Controller Manager ДДНЈЕФаТ PodЃЌЮЊЦфЕїЖШжСФПБъ NodeЃЛЁАЦєЯТЁБЪЧжИЕїЖШЭъГЩКѓЃЌФПБъ Node ЩЯЕФ kubelet ЗўЮёНјГЬНгЙмКѓМЬЙЄзїЃЌИКд№ Pod НгЯТРДЩњУќжмЦкЁЃдкећИіЕїЖШЙ§ГЬжаЩцМАШ§ИіЖдЯѓЃЌЗжБ№ЪЧД§ЕїЖШ Pod СаБэЁЂПЩгУ Node СаБэЃЌвдМАЕїЖШЫуЗЈКЭВпТдЁЃKubernetes Scheduler ЭЈЙ§ЕїЖШЫуЗЈЕїЖШЮЊД§ЕїЖШ Pod СаБэжаЕФУПИі Pod Дг Node СаБэжабЁдёвЛИізюЪЪКЯЕФ Node РДЪЕЯж Pod ЕФЕїЖШЁЃЫцКѓЃЌФПБъНкЕуЩЯЕФ kubelet ЭЈЙ§ API Server МрЬ§ЕН Kubernetes Scheduler ВњЩњЕФ Pod АѓЖЈЪТМўЃЌШЛКѓЛёШЁЖдгІЕФ Pod ЧхЕЅЃЌЯТди Image ОЕЯёВЂЦєЖЏШнЦїЁЃ
- kube-controller-manager
kube-controller-manager зїЮЊМЏШКФкВПЕФЙмРэПижЦжааФЃЌИКд№МЏШКФкЕФ NodeЁЂPod ИББОЁЂЗўЮёЖЫЕуЃЈEndpointЃЉЁЂУќУћПеМфЃЈNamespaceЃЉЁЂЗўЮёеЫКХЃЈServiceAccountЃЉЁЂзЪдДЖЈЖюЃЈResourceQuotaЃЉЕФЙмРэЃЌЕБФГИі Node втЭтхДЛњЪБЃЌController Manager ЛсМАЪБЗЂЯжВЂжДааздЖЏЛЏаоИДСїГЬЃЌШЗБЃМЏШКЪМжеДІгкдЄЦкЕФЙЄзїзДЬЌЁЃУПИіПижЦЦїЖМЪЧвЛИіЕЅЖРЕФНјГЬЃЌ ЕЋЪЧЮЊСЫНЕЕЭИДдгадЃЌЫќУЧЖМБЛБрвыЕНЭЌвЛИіПЩжДааЮФМўЃЌВЂдквЛИіНјГЬжадЫааЁЃ
УПИі Controller ЭЈЙ§ API Server ЬсЙЉЕФНгПкЪЕЪБМрПиећИіМЏШКЕФУПИізЪдДЖдЯѓЕФЕБЧАзДЬЌЃЌЕБЗЂЩњИїжжЙЪеЯЕМжТЯЕЭГзДЬЌЗЂЩњБфЛЏЪБЃЌЛсГЂЪдНЋЯЕЭГзДЬЌаоИДЕНЁАЦкЭћзДЬЌЁБЁЃвЛаЉЕфаЭЕФ Controller гаЃК
- НкЕуПижЦЦїЃЈNode ControllerЃЉ: ЖЈЦкМьВщ Node ЕФНЁПЕзДЬЌЃЌБъЪЖГіЃЈЪЇаЇ|ЮДЪЇаЇЃЉЕФ Node НкЕуЃЌИКд№дкНкЕуГіЯжЙЪеЯЪБНјааЭЈжЊКЭЯьгІЁЃ
- ШЮЮёПижЦЦїЃЈJob controllerЃЉ: МрВтДњБэвЛДЮадШЮЮёЕФ Job ЖдЯѓЃЌШЛКѓДДНЈ Pods РДдЫааетаЉШЮЮёжБжСЭъГЩЁЃ
- ЖЫЕуПижЦЦїЃЈEndpoints ControllerЃЉ: ЙиСЊ Service КЭ PodЃЌДДНЈ Endpoints ЮЊ Service ЕФКѓЖЫЃЌЕБ Pod ЗЂЩњБфЛЏЪБЃЌЪЕЪБИќаТ EndpointsЁЃ
- ЗўЮёеЪЛЇКЭСюХЦПижЦЦїЃЈService Account & Token ControllersЃЉ: ЮЊаТЕФУќУћПеМфДДНЈФЌШЯеЪЛЇКЭ API ЗУЮЪСюХЦЁЃ
ПижЦЦНУцзщМў
- kubelet
дк Kubernetes МЏШКжаЃЌдкУПИі NodeЃЈгжГЦ WorkerЃЉЩЯЖМЛсЦєЖЏвЛИі kubelet ЗўЮёНјГЬЁЃИУНјГЬгУгкДІРэ Master ЯТЗЂЕНБОНкЕуЕФШЮЮёЃЌЙмРэ Pod МА Pod жаЕФШнЦїЁЃУПИі kubelet НјГЬЖМЛсдк API Server ЩЯзЂВсНкЕуздЩэЕФаХЯЂЃЌЖЈЦкЯђ Master ЛуБЈНкЕузЪдДЕФЪЙгУЧщПіЃЌВЂЭЈЙ§ cAdvisor МрПиШнЦїКЭНкЕузЪдДЁЃ
- kube-proxy
kube-proxy дЫаадкЫљгаНкЕуЩЯЃЌЫќМрЬ§ apiserver жа service КЭ endpoint ЕФБфЛЏЧщПіЃЌДДНЈТЗгЩЙцдђвдЬсЙЉЗўЮё IP КЭИКдиОљКтЙІФмЁЃМђЕЅРэНтДЫНјГЬЪЧ Service ЕФЭИУїДњРэМцИКдиОљКтЦїЃЌЦфКЫаФЙІФмЪЧНЋЕНФГИі Service ЕФЗУЮЪЧыЧѓзЊЗЂЕНКѓЖЫЕФЖрИі Pod ЪЕР§ЩЯЁЃiptables гы IPVS ЖМЪЧЛљгк Netfilter ЪЕЯжЕФЃЌЕЋвђЮЊЖЈЮЛВЛЭЌЃЌЖўепгазХБОжЪЕФВюБ№ЃКiptables ЪЧЮЊЗРЛ№ЧНЖјЩшМЦЕФЃЛIPVS дђзЈУХгУгкИпадФмИКдиОљКтЃЌВЂЪЙгУИќИпаЇЕФЪ§ОнНсЙЙЃЈHash БэЃЉЃЌдЪаэМИКѕЮоЯоЕФЙцФЃРЉеХЁЃ
- ШнЦїдЫааЪБЃЈContainer RuntimeЃЉ
ШнЦїдЫааЛЗОГЪЧИКд№дЫааШнЦїЕФШэМўЁЃKubernetes жЇГжЖрИіШнЦїдЫааЛЗОГ: DockerЁЂ containerdЁЂCRI-O вдМАШЮКЮЪЕЯж Kubernetes CRI (ШнЦїдЫааЛЗОГНгПк)ЁЃ
ДЫЭтЃЌK8s ЛЙгавЛЯЕСаЕФВхМўзщМўЃЌПЩвдВЮПМЃК Kubernetes Addons
3.3ЁЂKubernetes ЖдЯѓ
API ЖдЯѓЪЧ K8s МЏШКжаЕФЙмРэВйзїЕЅдЊЁЃK8s МЏШКЯЕЭГУПжЇГжвЛЯюаТЙІФмЃЌв§ШывЛЯюаТММЪѕЃЌвЛЖЈЛсаТв§ШыЖдгІЕФ API ЖдЯѓЃЌжЇГжЖдИУЙІФмЕФЙмРэВйзїЁЃР§ШчИББОМЏ Replica Set ЖдгІЕФ API ЖдЯѓЪЧ RSЁЃ
УПИі API ЖдЯѓЖМга 3 ДѓРрЪєадЃКдЊЪ§Он metadataЁЂЙцЗЖ spec КЭзДЬЌ statusЁЃдЊЪ§ОнЪЧгУРДБъЪЖ API ЖдЯѓЕФЃЌУПИіЖдЯѓЖМжСЩйга 3 ИідЊЪ§ОнЃКnamespaceЃЌname КЭ uidЃЛГ§ДЫвдЭтЛЙгаИїжжИїбљЕФБъЧЉ labels гУРДБъЪЖКЭЦЅХфВЛЭЌЕФЖдЯѓЁЃЙцЗЖ spec УшЪіСЫгУЛЇЦкЭћ K8s МЏШКжаЕФЗжВМЪНЯЕЭГДяЕНЕФРэЯызДЬЌЃЈDesired StateЃЉЃЌР§ШчгУЛЇПЩвдЭЈЙ§ИДжЦПижЦЦї Replication Controller ЩшжУЦкЭћЕФ Pod ИББОЪ§ЮЊ 3ЃЛstatus УшЪіСЫЯЕЭГЪЕМЪЕБЧАДяЕНЕФзДЬЌЃЈStatusЃЉЃЌР§ШчЯЕЭГЕБЧАЪЕМЪЕФ Pod ИББОЪ§ЮЊ 2ЃЛФЧУДИДжЦПижЦЦїЕБЧАЕФГЬађТпМОЭЪЧздЖЏЦєЖЏаТЕФ PodЃЌељШЁДяЕНИББОЪ§ЮЊ 3ЁЃ
K8s жаЫљгаЕФХфжУЖМЪЧЭЈЙ§ API ЖдЯѓЕФ spec ШЅЩшжУЕФЃЌвВОЭЪЧгУЛЇЭЈЙ§ХфжУЯЕЭГЕФРэЯызДЬЌРДИФБфЯЕЭГЃЌетЪЧ k8s живЊЩшМЦРэФюжЎвЛЃЌМДЫљгаЕФВйзїЖМЪЧЩљУїЪНЃЈDeclarativeЃЉЕФЖјВЛЪЧУќСюЪНЃЈImperativeЃЉЕФЁЃЩљУїЪНЕФВйзїЃЌЯрЖдгкУќСюЪНВйзїЃЌЖдгкжиИДВйзїФмЪЕЯжУнЕШаЇЙћЃЌетЖдгкШнвзГіЯжЪ§ОнЖЊЪЇЛђжиИДЕФЗжВМЪНЛЗОГРДЫЕЪЧКмживЊЕФЁЃСэЭтЃЌЩљУїЪНВйзїИќШнвзБЛгУЛЇЪЙгУЃЌПЩвдЪЙЯЕЭГЯђгУЛЇвўВиЪЕЯжЕФЯИНкЃЌвўВиЪЕЯжЕФЯИНкЕФЭЌЪБЃЌвВОЭБЃСєСЫЯЕЭГЮДРДГжајгХЛЏЕФПЩФмадЁЃДЫЭтЃЌЩљУїЪНЕФ APIЃЌЭЌЪБвўКЌСЫЫљгаЕФ API ЖдЯѓЖМЪЧУћДЪаджЪЕФЃЌР§Шч ServiceЁЂVolumn етаЉ API ЖМЪЧУћДЪЃЌетаЉУћДЪУшЪіСЫгУЛЇЫљЦкЭћЕУЕНЕФвЛИіФПБъЗжВМЪНЖдЯѓЁЃ
3.3.1ЁЂPod
Pod ЪЧ Kubernetes НјааДДНЈЁЂЕїЖШКЭЙмРэЕФзюаЁЕФдзгЕЅЮЛЃЌЪЧ Kubernetes МЏШКжаЕФвЛИігІгУЪЕР§ЁЃPod ЪЧвЛИіЛђЖрИіЯрЙиШнЦїЕФзщКЯЃЌPod ШчЙћгаЪЧЖрИіШнЦїЃЌетаЉШнЦївЛАуЪЧЁАГЌЧзУмЙиЯЕЁБЃЌВЂЙВЯэДцДЂЁЂЭјТчзЪдДЁЃвЛАу Pod га 2 жжЪЙгУЗНЪНЁЃ1 ЪЧЕЅШнЦї PodЃЌзюГЃМћЕФгІгУЗНЪНЃЛ2 ЪЧЖрШнЦї PodЃЌЖдгкЖрШнЦї PodЃЌKubernetes ЛсБЃжЄЫљгаЕФШнЦїЖМдкЭЌвЛЬЈЮяРэжїЛњЛђащФтжїЛњжадЫааЁЃЖрШнЦї Pod ЪЧЯрЖдИпНзЕФЪЙгУЗНЪНЃЌГ§ЗЧгІгУёюКЯЬиБ№бЯжиЃЌвЛАуВЛЭЦМіЪЙгУетжжЗНЪНЁЃвЛИі Pod ФкЕФШнЦїЙВЯэ IP ЕижЗКЭЖЫПкЗЖЮЇЃЌШнЦїжЎМфПЩвдЭЈЙ§ localhost ЛЅЯрЗУЮЪЁЃ
Pod ВЂВЛЬсЙЉБЃжЄе§ГЃдЫааЕФФмСІЃЌвђЮЊПЩФмдтЪм Node НкЕуЕФЮяРэЙЪеЯЁЂЭјТчЗжЧјЕШЕШЕФгАЯьЃЌећЬхЕФИпПЩгУЪЧ Kubernetes МЏШКЭЈЙ§дкМЏШКФкЕїЖШ Node РДЪЕЯжЕФЁЃЭЈГЃЧщПіЯТЮвУЧВЛвЊжБНгДДНЈ PodЃЌвЛАуЖМЪЧЭЈЙ§ Controller РДНјааЙмРэЁЃPod ЬсЙЉСЫБШШнЦїИќИпВуДЮЕФГщЯѓЃЌЪЧвЛИіащФтИХФюЃЌФмДјРДУїЯдЕФКУДІЃК
- Pod зіЮЊвЛИіПЩвдЖРСЂдЫааЕФЗўЮёЕЅдЊЃЌМђЛЏСЫгІгУВПЪ№ЕФФбЖШЃЌвдИќИпЕФГщЯѓВуДЮЮЊгІгУВПЪ№ЙмЬсЙЉСЫМЋДѓЕФЗНБуЁЃ
- Pod зіЮЊзюаЁЕФгІгУЪЕР§ПЩвдЖРСЂдЫааЃЌвђДЫПЩвдЗНБуЕФНјааВПЪ№ЁЂЫЎЦНРЉеЙКЭЪеЫѕЁЂЗНБуНјааЕїЖШЙмРэгызЪдДЕФЗжХфЁЃ
- Pod жаЕФШнЦїЙВЯэЯрЭЌЕФЪ§ОнКЭЭјТчЕижЗПеМфЃЌPod жЎМфвВНјааСЫЭГвЛЕФзЪдДЙмРэгыЗжХфЁЃ
Sidecar
ЮвУЧПЩвддквЛИі Pod жаАДееЫГађЦєЖЏвЛИіЛђЖрИіИЈжњШнЦїЃЌРДЭъГЩвЛаЉЖРСЂгкжїНјГЬЃЈжїШнЦїЃЉжЎЭтЕФЙЄзїЃЌЭъГЩЙЄзїКѓетаЉИЈжњШнЦїЛсвРДЮЭЫГіЃЌжЎКѓжїШнЦїВХЛсЦєЖЏЃЌетжжШнЦїЩшМЦФЃЪННазі sidecarЁЃБШШчЖдгкЧАЖЫ Web гІгУЃЌШчЙћАбЙЙНЈКѓЕФ Js ЯюФПЗХЕН Nginx ОЕЯёЕФ/usr/share/nginx/html ФПТМЯТЃЌNginx КЭ Js гІгУзіГЩвЛИіОЕЯёдЫааШнЦїЃЌУПДЮгІгУгаИќаТЛђеп Nginx вЊзіЩ§МЖЁЂИќаТХфжУВйзїЖМашвЊжиаТзівЛИіОЕЯёЃЌЗЧГЃТщЗГЁЃгаСЫ Pod жЎКѓЃЌетбљЕФЮЪЬтОЭКмШнвзНтОіСЫЁЃЮвУЧПЩвдАбЧАЖЫ Web гІгУКЭ Nginx ЗжБ№зіГЩОЕЯёЃЌШЛКѓАбЫќУЧзїЮЊвЛИі Pod РяЕФСНИіШнЦї"зщКЯ"дквЛЦ№ЁЃ
Ыљга spec.initContainers ЖЈвхЕФШнЦїЃЌЖМЛсБШ spec.containers ЖЈвхЕФгУЛЇШнЦїЯШЦєЖЏЁЃВЂЧвЃЌInit ШнЦїЛсАДЫГађж№вЛЦєЖЏЃЌжБЕНЫќУЧЖМЦєЖЏВЂЧвЭЫГіСЫЃЌгУЛЇШнЦїВХЛсЦєЖЏЁЃетОЭЪЧШнЦїЩшМЦФЃЪНРязюГЃгУЕФвЛжжФЃЪНЃКsidecarЁЃЙЫУћЫМвхЃЌsidecar жИЕФОЭЪЧЮвУЧПЩвддквЛИі Pod жаЃЌЦєЖЏвЛИіИЈжњШнЦїЃЌРДЭъГЩвЛаЉЖРСЂгкжїНјГЬЃЈжїШнЦїЃЉжЎЭтЕФЙЄзїЁЃ
Pod КЭПижЦЦї
ФуПЩвдЪЙгУЙЄзїИКдизЪдДРДДДНЈКЭЙмРэЖрИі PodЁЃ зЪдДЕФПижЦЦїФмЙЛДІРэИББОЕФЙмРэЁЂЩЯЯпЃЌВЂдк Pod ЪЇаЇЪБЬсЙЉздгњФмСІЁЃ Р§ШчЃЌШчЙћвЛИіНкЕуЪЇАмЃЌПижЦЦїзЂвтЕНИУНкЕуЩЯЕФ Pod вбОЭЃжЙЙЄзїЃЌ ОЭПЩвдДДНЈЬцЛЛадЕФ PodЁЃЕїЖШЦїЛсНЋЬцЩэ Pod ЕїЖШЕНвЛИіНЁПЕЕФНкЕужДааЁЃ
ЯТУцЪЧвЛаЉЙмРэвЛИіЛђепЖрИі Pod ЕФЙЄзїИКдизЪдДЕФЪОР§ЃК
- ReplicaSet
ReplicaSet ЪЧаТвЛДњЕФ ReplicationControllerЃЌгЕгаИќЧПБэДяФмСІЕФ pod БъЧЉбЁдёЦїЁЃФПЕФЪЧЮЌЛЄвЛзщдкШЮКЮЪБКђЖМДІгкдЫаазДЬЌЕФ Pod ИББОЕФЮШЖЈМЏКЯЁЃ вђДЫЃЌЫќЭЈГЃгУРДБЃжЄИјЖЈЪ§СПЕФЁЂЭъШЋЯрЭЌЕФ Pod ЕФПЩгУадЁЃ
- Deployment
вЛИі Deployment ЮЊ Pods КЭ ReplicaSets ЬсЙЉЩљУїЪНЕФИќаТФмСІЁЃФуИКд№УшЪі Deployment жаЕФ ФПБъзДЬЌЃЌЖј Deployment ПижЦЦїЃЈControllerЃЉ вдЪмПиЫйТЪИќИФЪЕМЪзДЬЌЃЌ ЪЙЦфБфЮЊЦкЭћзДЬЌЁЃФуПЩвдЖЈвх Deployment вдДДНЈаТЕФ ReplicaSetЃЌЛђЩОГ§Яжга DeploymentЃЌ ВЂЭЈЙ§аТЕФ Deployment ЪебјЦфзЪдДЁЃ
- StatefulSet
StatefulSet ЪЧгУРДЙмРэгазДЬЌгІгУЕФЙЄзїИКди API ЖдЯѓЁЃStatefulSet гУРДЙмРэФГ Pod МЏКЯЕФВПЪ№КЭРЉЫѕЃЌ ВЂЮЊетаЉ Pod ЬсЙЉГжОУДцДЂКЭГжОУБъЪЖЗћЁЃКЭ Deployment РрЫЦЃЌ StatefulSet ЙмРэЛљгкЯрЭЌШнЦїЙцдМЕФвЛзщ PodЁЃЕЋКЭ Deployment ВЛЭЌЕФЪЧЃЌ StatefulSet ЮЊЫќУЧЕФУПИі Pod ЮЌЛЄСЫвЛИігаеГадЕФ IDЁЃетаЉ Pod ЪЧЛљгкЯрЭЌЕФЙцдМРДДДНЈЕФЃЌ ЕЋЪЧВЛФмЯрЛЅЬцЛЛЃКЮоТлдѕУДЕїЖШЃЌУПИі Pod ЖМгавЛИігРОУВЛБфЕФ IDЁЃ
- DaemonSet
DaemonSet ШЗБЃШЋВПЃЈЛђепФГаЉЃЉНкЕуЩЯдЫаавЛИі Pod ЕФИББОЁЃ ЕБгаНкЕуМгШыМЏШКЪБЃЌ вВЛсЮЊЫћУЧаТдівЛИі Pod ЁЃ ЕБгаНкЕуДгМЏШКвЦГ§ЪБЃЌетаЉ Pod вВЛсБЛЛиЪеЁЃЩОГ§ DaemonSet НЋЛсЩОГ§ЫќДДНЈЕФЫљга PodЁЃDaemonSet ЕФвЛаЉЕфаЭгУЗЈЃКдкУПИіНкЕуЩЯдЫааМЏШКЪиЛЄНјГЬЃЌдкУПИіНкЕуЩЯдЫааШежОЪеМЏЪиЛЄНјГЬЃЌдкУПИіНкЕуЩЯдЫааМрПиЪиЛЄНјГЬЁЃ
3.4ЁЂkubernetes ВПЪ№дРэКЭСїГЬАИР§

ЃЈ1ЃЉДДНЈвЛИіУшЪіМЏШКЕФЫљашзДЬЌХфжУЕФ YAML ЮФМўЁЃ
ЃЈ2ЃЉЭЈЙ§ kubectlЃЈKubernetes УќСюааНгПкЃЉНЋ YAML ЮФМўгІгУЕНМЏШКЁЃ
ЃЈ3ЃЉKubectl НЋЧыЧѓЬсНЛИј kube-apiserverЃЌКѓепдкНЋИќИФМЧТМЕНЪ§ОнПт etcdЃЌ жЎЧАЛсЖдЧыЧѓНјааЩэЗнбщжЄКЭЪкШЈЁЃ
ЃЈ4ЃЉKube-controller-manager ГжајМрЪгЯЕЭГЪЧЗёгааТЕФЧыЧѓЃЌВЂХЌСІНЋЯЕЭГзДЬЌЕїНкжСЫљашзДЬЌ - дкДЫЙ§ГЬжаДДНЈ ReplicaSetЁЂВПЪ№КЭ PodЁЃ
ЃЈ5ЃЉдкЫљгаПижЦЦїЖМдЫаажЎКѓЃЌkube-scheduler ЛсПДЕНга Pod ДІгкЁАЙвЦ№ЁБзДЬЌЃЌвђЮЊЫќУЧЩаЮДБЛАВХХдкНкЕуЩЯдЫааЁЃscheduler ГЬађЛсЮЊ Pod ВщевКЯЪЪЕФНкЕуЃЌШЛКѓгыУПИіНкЕужаЕФ kubelet ЭЈаХвдПижЦВЂЦєЖЏВПЪ№ЁЃ
3.5ЁЂKubernetes МмЙЙЙиМќЩшМЦРэФю
ЃЈ1ЃЉ ЩљУїЪН API ЃКПЊЗЂепПЩвдЙизЂгкгІгУздЩэЃЌЖјЗЧЯЕЭГжДааЯИНкЁЃБШШч Deployment(ЮозДЬЌгІгУ)ЁЂ StatefulSet(газДЬЌгІгУ)ЁЂJob(ШЮЮёРргІгУ)ЕШВЛЭЌзЪдДРраЭЃЌЬсЙЉСЫЖдВЛЭЌРраЭЙЄзїИКдиЕФГщЯѓ;Жд Kubernetes ЪЕЯжЖјбдЃЌЛљгкЩљУїЪН API ПЩвдЬсЙЉИќМгНЁзГЕФЗжВМЪНЯЕЭГЪЕЯжЁЃ
ЃЈ2ЃЉ ПЩРЉеЙадМмЙЙ ЃКЫљга K8s зщМўЖМЪЧЛљгквЛжТЕФЁЂПЊЗХЕФ API ЪЕЯжКЭНЛЛЅ;Ш§ЗНПЊЗЂепвВПЩЭЈЙ§ CRD(Custom Resource Definition)/Operator ЕШЗНЗЈЬсЙЉСьгђЯрЙиЕФРЉеЙЪЕЯжЃЌМЋДѓЬсЩ§СЫ K8s ЕФФмСІЁЃ
ЃЈ3ЃЉ ПЩвЦжВад ЃКK8s ЭЈЙ§вЛЯЕСаГщЯѓШч Loadbalance Service(ИКдиОљКтЗўЮё)ЁЂCNI(ШнЦїЭјТчНгПк)ЁЂCSI(Шн ЦїДцДЂНгПк)ЃЌАяжњвЕЮёгІгУПЩвдЦСБЮЕзВуЛљДЁЩшЪЉЕФЪЕЯжВювьЃЌЪЕЯжШнЦїСщЛюЧЈвЦЕФЩшМЦФПБъЁЃ
Ш§ЁЂдЦдЩњЮЂЗўЮё
ЖрИіЁАЮЂЗўЮёЁБЙВЭЌаЮГЩСЫвЛИіЮяРэЖРСЂЕЋТпМЭъећЕФЗжВМЪНЮЂЗўЮёЬхЯЕЁЃетаЉЮЂЗўЮёЯрЖдЖРСЂЃЌЭЈЙ§НтёюбаЗЂЁЂВтЪдгыВПЪ№СїГЬЃЌЬсИпећЬхЕќДњаЇТЪЁЃЮЂЗўЮёФЃЪНЭЈЙ§ЗжВМЪНМмЙЙНЋгІгУЫЎЦНРЉеЙКЭШпгрВПЪ№ЃЌДгИљБОЩЯНтОіСЫЕЅЬхгІгУдкЭиеЙадКЭЮШЖЈадЩЯДцдкЕФЯШЬьМмЙЙШБЯнЁЃЕЋвВвЊзЂвтЕНЮЂЗўЮёФЃаЭвВУцСйзХЗжВМЪНЯЕЭГЕФЕфаЭЬєеН: ШчКЮИпаЇЕїгУдЖГЬЗНЗЈЁЂШчКЮЪЕЯжПЩППЕФЯЕЭГШнСПдЄЙРЁЂШчКЮНЈСЂИКдиОљКтЬхЯЕЁЂШчКЮУцЯђЫЩёюКЯЯЕЭГНјааМЏГЩВтЪдЁЂШчКЮУцЯђДѓЙцФЃИДдгЙиСЊгІгУЕФВПЪ№гыдЫЮЌЁЃ
дкдЦдЩњЪБДњЃЌдЦдЩњЮЂЗўЮёЬхЯЕНЋГфЗжРћгУдЦзЪдДЕФИпПЩгУКЭАВШЋЬхЯЕЃЌШУгІгУЛёЕУИќгаБЃеЯЕФЕЏадЁЂПЩгУадгыАВШЋадЁЃгІгУЙЙНЈдкдЦЫљЬсЙЉЕФЛљДЁЩшЪЉгыЛљДЁЗўЮёжЎЩЯЃЌГфЗжРћгУдЦЗўЮёЫљДјРДЕФБуНнадЁЂЮШЖЈадЃЌНЕЕЭгІгУМмЙЙЕФИДдгЖШЁЃдЦдЩњЕФЮЂЗўЮёЬхЯЕвВНЋАяжњгІгУМмЙЙШЋУцЩ§МЖЃЌШУгІгУЬьШЛОпгаИќКУЕФПЩЙлВтадЁЂПЩПижЦадЁЂПЩШнДэадЕШЬиадЁЃ
здДгЮЂЗўЮёМмЙЙРэФюдк 2011 ФъЬсГівдРДЃЌЕфаЭЕФМмЙЙФЃЪНАДГіЯжЕФЯШКѓЫГађДѓжТЗжЮЊЫФДњЁЃ
ЕквЛДњЃКгІгУздЩэашвЊНтОіЩЯЯТгЮбАжЗЁЂЭЈбЖЁЂШнДэЕШЮЪЬтЁЃЫцзХЮЂЗўЮёЙцФЃРЉДѓЃЌЗўЮёбАжЗТпМЕФДІРэБфЕУдНРДдНИДдгЃЌМДЪЙЭЌвЛБрГЬгябдЕФСэвЛИігІгУЃЌЩЯЪіЮЂЗўЮёСїСПЙмРэЕШЕФЛљДЁФмСІЮоЗЈИДгУЃЌЖМашвЊжиаТЪЕЯжвЛБщЁЃ

ЕкЖўДњЃКв§ШыСЫХдТЗЗўЮёзЂВсжааФЃЈШч ZooKeeperЃЉзїЮЊаЕїепРДЭъГЩЗўЮёЕФздЖЏзЂВсКЭЗЂЯжЁЃЗўЮёжЎМфЕФЭЈбЖвдМАШнДэЛњжЦПЊЪМФЃПщЛЏЃЌаЮГЩЖРСЂЗўЮёПђМмЁЃЕЋЫцзХЗўЮёПђМмФкЙІФмШевцдіЖрЃЌПчгябдЕФЛљДЁЙІФмИДгУЯдЕУЪЎЗжРЇФбЃЌЪЙЕУЮЂЗўЮёЕФПЊЗЂепБЛЦШБЛЯоЖЈдкФГжжЬиЖЈгябдЩЯЃЌетвВЮЅБГСЫЮЂЗўЮёЕФУєНнЕќДњддђЁЃ

ЕкШ§ДњЃКЗўЮёЭјИёЃЌдРДБЛФЃПщЛЏЕНЗўЮёПђМмРяЕФЮЂЗўЮёЛљДЁФмСІЃЌБЛНјвЛВНЕФДгвЛИі SDK бнНјГЩЮЊвЛИіЖРСЂНјГЬ - SidecarЃЈБпГЕЃЉЁЃетИіБфЛЏЪЙЕУЕкЖўДњМмЙЙжаЖргябджЇГжЮЪЬтЕУвдГЙЕзНтОіЃЌЮЂЗўЮёЛљДЁФмСІбнНјКЭвЕЮёТпМЕќДњГЙЕзНтёюЁЃетИіМмЙЙОЭЪЧдкдЦдЩњЪБДњЕФЮЂЗўЮёМмЙЙ - Cloud Native MicroservicesЃЌБпГЕЃЈSidecarЃЉНјГЬПЊЪМНгЙмЮЂЗўЮёгІгУжЎМфЕФСїСПЃЌГадиЕкЖўДњжаЗўЮёПђМмЕФЙІФмЃЌАќРЈЗўЮёЗЂЯжЁЂЕїгУШнДэЁЂЗўЮёжЮРэЙІФмЃЌР§ШчЃКШЈжиТЗгЩЁЂЛвЖШТЗгЩЁЂСїСПжиЗХЁЂЗўЮёЮБзАЕШЁЃ

ЕкЫФДњЃКServerless ЮЂЗўЮёЃЌЮЂЗўЮёНјвЛВНгЩвЛИігІгУМђЛЏЮЊЮЂТпМЃЈMicrologicЃЉЃЌДгЖјЖдБпГЕФЃЪНЬсГіСЫИќИпЫпЧѓЃЌИќЖрПЩИДгУЕФЗжВМЪНФмСІДггІгУжаАўРыЃЌБЛЯТГСЕНБпГЕжаЃЌР§ШчЃКзДЬЌЙмРэЁЂзЪдДАѓЖЈЁЂСДТЗзЗзйЁЂЪТ ЮёЙмРэЁЂАВШЋЕШЁЃЭЌЪБЃЌдкПЊЗЂВрЬсГЋУцЯђБОЕиБрГЬЕФРэФюЃЌЬсЙЉБъзМ API ЦСБЮЕєЕзВузЪдДЁЂЗўЮёЁЂ ЛљДЁЩшЪЉЕФВювьЃЌНјвЛВННЕЕЭЮЂЗўЮёПЊЗЂФбЖШЁЃвВОЭЪЧФПЧАвЕНчЬсГіЕФЖрдЫааЪБЮЂЗўЮёМмЙЙЃЈMuti-Runtime MicroservicesЃЉЁЃ

ЫФЁЂServerless
Й§ШЅвЛжБЭЈЙ§ИїжжЭООЖбЇЯАЁЂбаОП ServerlessЃЌЕБЮвЯыдкетИіеТНкИј Serverless ИјвЛИіЙйЗНЕФЖЈвхЃЌЗЂЯжАйЖШАйПЦОЙШЛУЛга Serverless етИіДЪЬѕЃЌвВЫЕУїСЫ Serverless дкаавЕЛЙЪЧвЛИіЗЧГЃаТЕФИХФюЃЌШдШЛДІгкЬНЫїКЭЗЂеЙНзЖЮЃЌВЂЧвЖдгк Serverless вВУЛгавЛИіШЈЭўЕФЖЈвхЃЌЕЋЮвУЧПЩвдДг Serverless БГКѓЕФдИОАКЭЫМЯыРДРэНт Serverless ЪЧЪВУДЃП
ЮвУЧПДЯТ AWS дѕУДЖЈвх Serverless ЕФЃК
Serverless ЕФШЋГЦЪЧ Serverless Computing ЮоЗўЮёЦїдЫЫуЃЌвдЦНЬЈМДЗўЮёЃЈPaaSЃЉЮЊЛљДЁЃЌШУгУЛЇПЩвддкВЛПМТЧЗўЮёЦїЕФЧщПіЯТЙЙНЈВЂдЫаагІгУГЬађКЭЗўЮёЃЌПЊЗЂепЮоашЙизЂЛљДЁЩшЪЉЙмРэШЮЮёЃЌР§ШчЗўЮёЦїЛђМЏШКХфжУЁЂаоВЙЁЂВйзїЯЕЭГЮЌЛЄКЭШнСПдЄжУЃЌФмЙЛЮЊМИКѕШЮКЮРраЭЕФгІгУГЬађЛђКѓЖЫЗўЮёЙЙНЈЮоЗўЮёЦїгІгУГЬађЁЃЮоЗўЮёЦїгІгУГЬађЪЧгЩЪТМўЧ§ЖЏЕФЃЌВЂЭЈЙ§гыММЪѕЮоЙиЕФ API ЛђЯћЯЂЪеЗЂЪЕЯжЫЩЩЂёюКЯЁЃЯьгІЪТМўЖјжДааЪТМўЧ§ЖЏаЭДњТыЃЌР§ШчзДЬЌИќИФЛђжеЖЫНкЕуЧыЧѓЃЌЪТМўЧ§ЖЏаЭМмЙЙНЋДњТыгызДЬЌНтёюЃЌЫЩЩЂёюКЯзщМўжЎМфЕФМЏГЩЭЈГЃЪЙгУЯћЯЂЪеЗЂвьВНЭъГЩЁЃ
ЁАServerlessЁБетИіУћзжБОЩэУшЛцСЫИУММЪѕЕФРяУцЃКЮоЗўЮёЦїЃЌетРяЕФ less ЦфКЌвхВЛЪЧЫЕгІгУЕФдЫааВЛашвЊЗўЮёЦїЃЌЖјЪЧеыЖдгУЛЇЕФаФжЧИКЕЃКЭЙизЂЕуРДЫЕЕФЃЌгУЛЇЙЙНЈвЛИігІгУЮоашЙиаФЗўЮёЦїЁЂдЫааЪБЁЂРЉЫѕШнЕШММЪѕЪЕЪЉЕФИКЕЃЃЌЭЈЙ§ Serverless ЦНЬЈЕФЭаЙмЗўЮёКЭКЏЪ§ПьЫйЙЙНЈвЛИіШЋаТЕФгІгУЁЃ
ЁАУћПЩУћЃЌЗЧГЃУћЁБЁЃServerless ПЩвдЗвыЮЊЮоЗўЮёЦїЃЌЕЋШДЮоЗЈЭъећВћЪіБГКѓЕФБОжЪЁЂдИОАКЭМлжЕЁЃ
ЮвУЧПД Serverless ИјгУЛЇДјРДСЫЪВУДЃП
зЈзЂ
ЁАLess is moreЁБ ЁЃЦѓвЕдкДюНЈЪ§зжЛЏгІгУЕФжеМЋФПЕФЪЧЪЕЯжЩЬвЕМлжЕЕФзюДѓЛЏЛиБЈЃЌЭЖШыЪ§зжЛЏгІгУДюНЈЕФзЪдДКЭГЩБОВЛЪЧЮоЯоЕФЃЌетаЉЭЖШыжаФмЙЛИјЦѓвЕДјРДеце§МлжЕЕФЪЧвЕЮёТпМ/ДњТыЃЌжиИДадЕФММЪѕадЙЄзїЃЈРЉЫѕШнЁЂВПЪ№ЁЂШнджЁЂМрПиЁЂШежОЁЂАВШЋВЙЖЁЕШЃЉЪЧРДжЇГХвЕЮёДњТыЬсЙЉЗўЮёЕФЃЌБОЩэВЛВњЩњШЮКЮвЕЮёМлжЕЁЃServerless ЕФ Less ОЭЪЧШУгУЛЇОЁПЩФм Щй ЕФЙизЂКЭжДааЗБЫіЧвжиИДадЕФММЪѕадЙЄзїЃЌMore ОЭЪЧгУЛЇОЭФмОЁПЩФм Жр ЕФАбзЪдДОлНЙЕНФмВњГіМлжЕЕФвЕЮёДњТыЩЯЁЃЫљвдвВПЩвдЫЕЃЌ Serverless вЛжжШУгУЛЇзЈзЂгквЕЮёМлжЕНЛИЖЕФЗНЗЈ ЁЃ
Пь
ЬьЯТЮфЙІЁЂЮЈПьВЛЦЦЁЃгШЦфдкЕБШеПьЫйБфИяЕФЩЬвЕЛЗОГЃЌЪЧЗёФмПьЫйПДзМЛњгіЁЂзЅзЁЛњгіЃЌЦѓвЕЕФЪдДэФмСІЪЧЙиМќЃЌЦѓвЕФмЙЛПьЫйЪдДэЃЌвтЮЖзХПЩвдПьЫйДДаТЃЌФмЙЛПьЫйДДаТФмШУЦѓвЕдкИДдгЖрБфЕФОКељЛЗОГжаЛёЕУгХЪЦКЭГЩЙІЁЃПьЫйЪдДэвРРЕгкЦѓвЕАбЙІФмКЭвЕЮёЕузгЭЦЕНЪаГЁЕФЫйЖШЃЌетИіЫйЖШгЩЦѓвЕНЛИЖШэМўЕФжмЦкОіЖЈЃЌServerless РэФюОЭЪЧШУЦѓвЕжЛЙизЂвЕЮёЃЌЭЈЙ§БрХХдЦЭаЙмЗўЮёЛђжБНгВПЪ№ДњТыМДПЩЙЙНЈжЇГХгІгУЃЌ ЫѕЖЬСЫДгДњТыПЊЗЂЕНЭЖШыЩњВњЕФЪБМф ЃЌетбљЦѓвЕПЩвдЛёЕУЧАЫљЮДгаЕФНЛИЖШэМўМлжЕЕФЫйЖШЁЃ
гУЛЇШчКЮЪЕЯжЮоашЙизЂММЪѕЩшЪЉЃЌЩѕжСЮоашВПЪ№гІгУОЭПЩвдЙЙНЈвЛИігІгУЕФФиЃПЭЈЙ§ 2 жжФмСІЃК
1ЁЂBaaSЃЈBackend as a ServiceЃЉЃЌЙЋЙВЕФЭаЙмЗўЮёЁЃЙЋЙВЕФЭаЙмЗўЮёЭЈГЃЪЧдЦГЇЩЬЬсЙЉЕФЭЈгУЕФЁЂПчГЁОАЁЂИњвЕЮёЮоНєУмЙиЯЕЕФЙВЯэЗўЮёЁЃЮвУЧжЊЕРЃЌЖдгкКмЖрГѕДДЦѓвЕРДНВЃЌ65%ЕФгІгУ QPM ЪЧаЁгк 100 ЕФЃЌЪЧЕфаЭЕФГЄЮВгІгУЃЌШчЙћгІгУвРРЕЫљгаЗўЮёЖМздНЈЕФЛАЃЌЛсЗжЩЂдкКЫаФвЕЮёЕФЭЖШыЃЌФЃК§ЫћУЧЖдгкДДдьвЕЮёМлжЕКЭЩЬвЕМлжЕЕФзЂвтСІЁЃжюШчЕЧТМЁЂЮФМўЯЕЭГЁЂЖдЯѓДцДЂКЭЪ§ОнВжПтЁЂгявєЗжЮіЁЂЩэЗнбщжЄЕШФмСІЭЈЙ§ЭаЙмаЮЪНЙВЯэИјЦѓвЕЃЌЦѓвЕВЛНіПЩвдМѕЩйДѓСПЕФГЩБОЃЌвВМгПьгІгУЕФЙЙНЈЁЃ
2ЁЂFaaSЃЈFunction as a ServiceЃЉЃЌКЏЪ§МДЗўЮёЁЃFaaS ЪЧвЛжжЙЙНЈКЭВПЪ№ЗўЮёЦїЖЫШэМўЕФаТЗНЗЈЃЌСЃЖШЯИЕНФмЙЛЖРСЂЕФВПЪ№вЛИіКЏЪ§ЁЃЮвУЧЭЈЙ§ДЋЭГЗНЪНВПЪ№ЗўЮёЦїЖЫШэМўЪБЃЌЮвУЧДгжїЛњЪЕР§ПЊЪМЃЌЭЈГЃЪЧащФтЛњЃЈVMЃЉЪЕР§ЛђШнЦїЃЌдкжїЛњжаВПЪ№ЮвУЧЕФгІгУГЬађЃЌШчЙћЮвУЧЕФжїЛњЪЧ VM ЛђШнЦїЃЌФЧУДЮвУЧЕФгІгУГЬађЪЧвЛИіВйзїЯЕЭГНјГЬЁЃFaaS ИФБфСЫетжжВПЪ№ФЃЪНЃЌ ВПЪ№ФЃаЭжаЩйСЫжїЛњЪЕР§КЭгІгУГЬађНјГЬЃЌЮвУЧжЛЙизЂЪЕЯжгІгУГЬађТпМЕФИїИіВйзїКЭКЏЪ§ЃЌЮвУЧНЋетаЉКЏЪ§ДњТыЕЅЖРЩЯДЋЕНдЦЙЉгІЩЬЬсЙЉЕФ FaaS ЦНЬЈЁЃКЏЪ§дкдЦЗўЮёЭаЙмЕФЗўЮёЦїНјГЬжаШБЪЁДІгкПеЯазДЬЌЃЌжБЕНашвЊЫќУЧдЫааЕФЪБКђВХЛсБЛМЄЛюЃЌ ЭЈЙ§ХфжУ FaaS ЦНЬЈРДМрЬ§УПИіКЏЪ§ЕФМЄЛюЪТМўЁЃ ЕБИУЪТМўЗЂЩњЪБЃЌFaaS ЦНЬЈЪЕР§ЛЏКЏЪ§ЃЌШЛКѓЪЙгУДЅЗЂЪТМўЕїгУЫќЁЃЫљвд FaaS БОжЪЩЯЪЧвЛжжЪТМўЧ§ЖЏЕФФЃаЭЃЌГ§СЫЬсЙЉЭаЙмКЭжДааДњТыЕФЦНЬЈжЎЭтЃЌFaaS ЦНЬЈЛЙМЏГЩСЫИїжжЭЌВНКЭвьВНЪТМўдДЃЌHTTP API ЭјЙиОЭЪЧвЛжжЭЌВНЪТМўдДЃЌЯћЯЂзмЯпЁЂЖдЯѓДцДЂЛђРрЫЦгкЕФЖЈЪБЦїОЭЪЧвЛжжвьВНдДЁЃ
КмЖрШЫЫЕ Serverless ОЭЪЧ BaaS+FaaSЃЌвВЪЧВЛЮоЕРРэЕФЁЃ
змНсРДПДЃЌServerless ЕФМлжЕгаЃК
1ЁЂЬсЩ§ЕќДњЫйЖШ ЃКЭЈЙ§МгПьЙЙНЈКЭЗЂВМжмЦквдМАМѕЩйдЫгЊПЊЯњЃЌПЊЗЂШЫдБПЩвдПьЫйЙЙНЈаТЙІФмЁЃздЖЏЛЏВтЪдКЭЗЂВМСїГЬПЩвдНЕЕЭДэЮѓТЪЃЌвђДЫВњЦЗФмЙЛИќПьЕиНјШыЪаГЁЁЃ
2ЁЂМгЫйДДаТ ЃКРћгУФЃПщЛЏМмЙЙЃЌПЊЗЂШЫдБПЩвдПьЫйИќИФШЮКЮЕЅИігІгУГЬађзщМўЃЌВЂНЕЕЭећИігІгУГЬађУцСйЕФЗчЯеЃЌвђДЫЭХЖгПЩвдИќЦЕЗБЕиЪдбщаТЯыЗЈЁЃ
3ЁЂНЕЕЭГЩБО ЃКАДашИЖЗбЃЌРћгУАДМлжЕИЖЗбЕФЖЈМлФЃЪНЃЌЯжДњгІгУГЬађПЩвдМѕЩйЙ§ЖШХфжУКЭЯажУзЪдДЃЌДгЖјНЕЕЭГЩБОЁЃПЊЗЂепЮоашЙизЂЭЌжЪЛЏЕФЁЂИКЕЃЗБжиЕФЛљгкЗўЮёЦїЕШЛљДЁЩшЪЉЕФПЊЗЂЁЂдЫЮЌЁЂАВШЋЁЂИпПЩгУЕШЙЄзїЃЌПЊЗЂКЭЮЌЛЄГЩБОвВБфЕУИќЕЭЁЃ
4ЁЂЕЏадЩьЫѕЃК ФњЕФгІгУГЬађПЩздЖЏРЉеЙЃЌЛђЭЈЙ§ЧаЛЛеМгУзЪдДЃЈШчЭЬЭТСПЁЂФкДцЃЉЕФЕЅЮЛЪ§ЃЈЖјВЛЪЧЧаЛЛЕЅИіЗўЮёЦїЕФЕЅЮЛЪ§ЃЉРДЕїећШнСПЃЌДгЖјЪЕЯжРЉеЙЁЃ
ЙњФкЭтБШНЯГіУћЕФ Serverless ВњЦЗгаАЂРяКЏЪ§МЦЫуЁЂЬкбЖ ServerlessЁЂAWS LambdaЁЂAzure Functions ЕШЁЃНќСНФъРД Serverless НќФъРДГЪМгЫйЗЂеЙЧїЪЦЃЌгУЛЇЪЙгУ Serverless МмЙЙдкПЩППадЁЂГЩБОКЭбаЗЂдЫЮЌаЇТЪЕШЗНУцЛёЕУЯджјЪевцЃЌФЧдкФФаЉГЁОАЪЧзюЪЪКЯ ServerlessЃПзюФмЗЂЛг Serverless гХЪЦФиЃП
1ЁЂаЁГЬађ/Web/Moible/API КѓЖЫЗўЮё ЃКдкаЁГЬађЁЂWeb/Moible гІгУЁЂAPI ЗўЮёЕШГЁОАжаЃЌвЕЮёТпМИДдгЖрБфЃЌЕќДњЩЯЯпЫйЖШвЊЧѓИпЃЌЖјЧветРрдкЯпгІгУЃЌзЪдДРћгУТЪЭЈГЃаЁгк 30%ЃЌгШЦфЪЧаЁГЬађЕШГЄЮВгІгУЃЌзЪдДРћгУТЪИќЪЧЕЭгк 10%ЁЃServerless УтдЫЮЌЃЌАДашИЖЗбЕФЬиЕуЗЧГЃЪЪКЯЙЙНЈаЁГЬађ /Web/Mobile/API КѓЖЫЯЕЭГЃЌЭЈЙ§дЄСєМЦЫузЪдД + ЪЕЪБздЖЏЩьЫѕЃЌПЊЗЂепФмЙЛПьЫйЙЙНЈбгЪБЮШЖЈЁЂФмГадиИпЦЕЗУЮЪЕФдкЯпгІгУЁЃ

2ЁЂЮяСЊЭј ЃКЮяСЊЭјвтЮЖзХГЩЧЇЩЯЭђЕФЩшБИЛсСЌШыЭјТчЃЌЪБПЬдкВЛЖЯЕФВњЩњЪ§ОнЃЌетЖдЪ§ОнЕФЗжЮіЁЂДІРэЕФМАЪБадЬсГіСЫКмИпЕФЬєеНЁЃЭЈЙ§ЪЙгУ Serverless МмЙЙЃЌЮяСЊЭјЩшБИЫљВЩМЏЕФЪ§ОнНЋПЩвдзїЮЊдЦКЏЪ§ЕФДЅЗЂЪТМўЃЌЖјЪЕЯжЪ§ОнЕФЪЕЪБДІРэЁЂЗжЮіКЭгІгУЁЃЫцзХЮяСЊЭјЩшБИМЦЫуФмСІЕФНјвЛВНЬсЩ§ЃЌдЦКЏЪ§зїЮЊзюаЁСЃЖШЕФМЦЫуЕЅдЊЃЌгаЛњЛсБЛЕїЖШЕНЩшБИЖЫдЫааЃЌЪЕЯжБпдЕМЦЫуЃЌДяЕНЁИЖЫ - дЦЁЙСЊКЯЕФ Serverless МмЙЙЁЃ
3ЁЂШЮЮёХњДІРэЃК дкЙЙНЈЕфаЭШЮЮёХњДІРэЃЈШчЭМЯёДІРэЁЂДѓЙцФЃвєЪгЦЕЮФМўзЊТыЃЉЯЕЭГЪБЃЌашвЊАќКЌМЦЫузЪдДЙмРэЁЂШЮЮёгХЯШМЖЕїЖШЁЂШЮЮёБрХХЁЂШЮЮёПЩППжДааЕШвЛЯЕСаЙІФмЁЃЭЈЙ§ Serverless МЦЫуЦНЬЈЃЌгУЛЇжЛашвЊзЈзЂгкШЮЮёДІРэТпМЕФДІРэЃЌЮоашДгЛњЦїЛђепШнЦїВуПЊЪМЙЙНЈЃЌвВЮоашПМТЧЪЙгУЯћЯЂЖгСаНјааШЮЮёаХЯЂЕФГжОУЛЏКЭМЦЫузЪдДЗжХфЃЌЖјЧв Serverless МЦЫуЕФМЋжТЕЏадПЩвдКмКУЕиТњзуЭЛЗЂШЮЮёЯТЖдЫуСІЕФашЧѓЃЌгУЛЇЮоашЪЙгУ Kubernetes ЕШШнЦїБрХХЯЕЭГЪЕЯжзЪдДЕФЩьЫѕКЭШнДэЃЌздааДюНЈЛђМЏГЩМрПиБЈОЏЯЕЭГЁЃЭЈЙ§НЋЖдЯѓДцДЂЗўЮёЛЏВЂКЭ Serverless МЦЫуЦНЬЈМЏГЩЕФЗНЪНЃЌФмЪЕЪБЯьгІЖдЯѓДДНЈЁЂЩОГ§ЕШВйзїЃЌЪЕЯжвдЖдЯѓДцДЂЮЊжааФЕФДѓЙцФЃЪ§ОнДІРэЁЃгУЛЇМШПЩвдЭЈЙ§діСПДІРэЖдЯѓДцДЂЩЯЕФаТдіЪ§ОнЃЌвВПЩвдДДНЈДѓСПКЏЪ§ЪЕР§РДВЂааДІРэДц СПЪ§ОнЁЃ

4ЁЂдЫЮЌМАМЏГЩЃК ЭЈЙ§ЖдНгдЦКЏЪ§вдМАдЦЩЯЕФИїИіВњЦЗЁЂШежОЗўЮёЁЂМрПиИцОЏЯЕЭГЃЌдЦЪБДњЕФдЫЮЌвВЖМПЩвдгУдЦКЏЪ§РДЙЙНЈЁЃЖЈЪБДЅЗЂЕФдЦКЏЪ§ЃЌНЋПЩвдЗНБуЕиЬцДњашвЊдкжїЛњЩЯРДдЫааЕФЖЈЪБШЮЮёЃЛЖјШежОЛђИцОЏДЅЗЂЕФдЦКЏЪ§ЃЌНЋПЩвдЖддЦжаЕФЪТМўзїГіСЂПЬЛигІМАДІРэЁЃ
Serverless зїЮЊвЛжжШЋаТЕФММЪѕМмЙЙЃЌОпгаКмЖрЕФгХЕуЃЌШчНЕЕЭдЫгЊГЩБОЁЂНЕЕЭдЫЮЌашЧѓЁЂНЕЕЭШЫСІГЩБОКЭМѕЩйзЪдДПЊЯњЕШЁЃЕЋММЪѕУЛгавјЕЏЃЌServerless вВДІдкЗЂеЙЦкЃЌДцдквЛаЉБзЖЫЃЌАќРЈЃК
1ЁЂВЛЪЪКЯДІРэИДдгЕФвЕЮёТпМЃЌЫќИќЪЪКЯЕїгУдЦЩЯЕФЦфЫћЗўЮёЃЌеГКЯЙиМќЕФВњЦЗЁЃ
2ЁЂРфЦєЖЏЕМжТЕФИпбгГйЮЪЬтЁЃ
3ЁЂServerless ЕїгУжЎМфВЛФмЙВЯэзДЬЌШУБраДИДдгГЬађБфЕУМЋЖШРЇФбЁЃЮозДЬЌЪЧЯжДњгІгУзЗЧѓЕФФПБъЃЌЁА12 вЊЫиЁБвВГЋЕМШчДЫЁЃЕЋ Serverless НЋЮозДЬЌНјааЕФИќМгГЙЕзЃЌдкВЛЭЌЕФЕїгУжЎМфЮоЗЈЙВЯэФкДцзДЬЌЁЃР§ШчЕЅЛњЯоСїдкБОЕиЪЧвЛИі AtomicInteger БфСПЃЌЕЋдк Serverless МмЙЙжаЫќБфГЩДцДЂдкФкДцЪ§ОнПтЃЈRedisЃЉжаЕФвЛЬѕМЧТМЃЌИќаТГЩБОЁЂБЃжЄдзгадЕШвђЫиШУЮвУЧЕФБрТыБфЕУЪ§БЖИДдгЁЃЖдгкДѓЖрдЦдЩњЕФЛЅСЊЭјгІгУРДЫЕЃЌетжжГЙЕзЕФЮозДЬЌМмЙЙЪЧвЛИіОоДѓЕФЬєеНЃЌЖјЖдгкЖЏщќгаМИЪЎЭђЁЂЩЯАйЭђааДњТыЕФЁЂГфТњСЫзДЬЌЕФЦѓвЕгІгУРДЫЕЃЌServerless ЕФЮозДЬЌИФдьМИКѕЪЧвЛИіЮоЗЈЭъГЩЕФШЮЮёЁЃ
4ЁЂ БОЕиПЊЗЂЁЂВтЪдРЇФбЃЌЭЌЪБТпМЩЂТфдкИїДІЃЌХХВщЮЪЬтРЇФбЁЃ
5ЁЂГЇЩЬЫјЖЈЁЃдЦМЦЫуЪЧгЎепЭЈГдЕФаавЕЃЌДѓЖјШЋЕФдЦГЇЩЬгХЪЦОоДѓЃЌServerless МгОчСЫетжжЧїЪЦЃЌгУЛЇЕФКЏЪ§ДњТыВПЪ№ЕН FaaS КѓЧЈвЦЙЄзїСПОоДѓЃЌЭЌЪБгІгУжавРРЕСЫДѓСПдЦЙЋЙВЗўЮёЃЌдкаТЕФдЦЦНЬЈМЋгаПЩФмевВЛЕНЬцДњЃЌзіВЛЕНЦНЛЌЧЈвЦЁЃ
ЮхЁЂService Mesh ММЪѕ
дкЩЯУцдЦдЩњЮЂЗўЮёеТНкНщЩмСЫЮЂЗўЮёСїСППижЦКЭжЮРэЕФММЪѕЗЂеЙРњГЬЃЌзмНсРДПДЗжЮЊЃК

Spring CloudЁЂDubbo ЛђОЉЖЋ JSF ЮЊДњБэЕФЕкЖўДњЮЂЗўЮёПђМмЫљУцСйЕФШ§ИіБОжЪЮЪЬтЃК
1ЁЂЧжШыадЧПЁЃЯывЊМЏГЩ SDK ЕФФмСІЃЌГ§СЫашвЊЬэМгЯрЙивРРЕЃЌЭљЭљЛЙашвЊдквЕЮёДњТыжадіМгвЛВПЗжЕФДњТыЁЂЛђзЂНтЁЂЛђХфжУЃЛвЕЮёДњТыгыжЮРэВуДњТыНчЯоВЛЧхЮњЁЃ
2ЁЂЮоЗЈПчгябдЁЃ
3ЁЂжаМфМўбнБфРЇФбЁЃгЩгкАцБОЫщЦЌЛЏбЯжиЃЌЕМжТжаМфМўЯђЧАбнНјЕФЙ§ГЬжаОЭашвЊдкДњТыжаМцШнИїжжИїбљЕФРЯАцБОТпМЃЌДјзХЁАМЯЫјЁБ ЧАааЃЌЮоЗЈЪЕЯжПьЫйЕќДњЁЃ
4ЁЂФкШнЖрЁЂУХМїИпЁЃSpring Cloud БЛГЦЮЊЮЂЗўЮёжЮРэЕФШЋМвЭАЃЌАќКЌДѓДѓаЁаЁМИЪЎИізщМўЃЌФкШнЯрЕБжЎЖрЃЌЭљЭљашвЊМИФъЪБМфШЅЪьЯЄЦфжаЕФЙиМќзщМўЁЃЖјвЊЯыЪЙгУ Spring Cloud зїЮЊЭъећЕФжЮРэПђМмЃЌдђашвЊЩюШыСЫНтЦфжадРэгыЪЕЯжЃЌЗёдђгіЕНЮЪЬтЛЙЪЧКмФбЖЈЮЛЁЃ
5ЁЂжЮРэЙІФмВЛШЋЁЃВЛЭЌгк RPC ПђМмЃЌSpring Cloud зїЮЊжЮРэШЋМвЭАЕФЕфаЭЃЌвВВЛЪЧЭђФмЕФЃЌжюШчавщзЊЛЛжЇГжЁЂЖржиЪкШЈЛњжЦЁЂЖЏЬЌЧыЧѓТЗгЩЁЂЙЪеЯзЂШыЁЂЛвЖШЗЂВМЕШИпМЖЙІФмВЂУЛгаИВИЧЕНЁЃЖјетаЉЙІФмЭљЭљЪЧЦѓвЕДѓЙцФЃТфЕиВЛПЩЛёШБЕФЙІФмЃЌвђДЫЙЋЫОЭљЭљЛЙашвЊЭЖШыЦфЫќШЫСІНјааЯрЙиЙІФмЕФздбаЛђепЕїбаЦфЫќзщМўзїЮЊВЙГфЁЃ
ЮЂЗўЮёЪБДњЃЌService Mesh гІдЫЖјЩњЃЌЦСБЮСЫЗжВМЪНЯЕЭГЕФжюЖрИДдгадЃЌШУПЊЗЂепПЩвдЛиЙщвЕЮёЃЌОлНЙеце§ЕФМлжЕЁЃ
Service Mesh вЛДЪзюдчгЩПЊЗЂ Linkerd ЕФ Buoyant ЙЋЫОЬсГіЃЌВЂгк 2016 Фъ 9 дТ 29 ШеЕквЛДЮЙЋПЊЪЙгУСЫетвЛЪѕгяЁЃWilliam MorganЃЌBuoyant CEOЃЌЖд Service Mesh етвЛИХФюЖЈвхШчЯТЃК
ЗўЮёЭјИёЃЈService MeshЃЉЪЧДІРэЗўЮёМфЭЈаХЕФЛљДЁЩшЪЉВуЁЃЫќИКд№ЙЙГЩЯжДњдЦдЩњгІгУГЬађЕФИДдгЗўЮёЭиЦЫРДПЩППЕиНЛИЖЧыЧѓЁЃдкЪЕМљжаЃЌService Mesh ЭЈГЃвдЧсСПМЖЭјТчДњРэеѓСаЕФаЮЪНЪЕЯжЃЌетаЉДњРэгыгІгУГЬађДњТыВПЪ№дквЛЦ№ЃЌЖдгІгУГЬађРДЫЕЮоашИажЊДњРэЕФДцдкЁЃ
ДгетЖЮЖЈвхжаПЩвдЖСГіЃЌService Mesh ЕФБОжЪЪЧЛљДЁЩшЪЉВуЃЌКЫаФЙІФмЪЧЧыЧѓЗжЗЂЃЌЛњжЦЪЧЭЈЙ§ЭјТчДњРэЃЌЬиЕуЪЧЖдгІгУЭИУїЁЃ
МђЕЅЕиЫЕЃЌService Mesh ЪЧвЛИізЈзЂгкДІРэЗўЮёМфЭЈаХЕФЛљДЁЩшЪЉВуЁЃService Mesh ЪЧЗжВМЪНгІгУдкЮЂЗўЮёШэМўМмЙЙжЎЩЯЗЂеЙЦ№РДЕФаТММЪѕЃЌжМдкНЋФЧаЉЮЂЗўЮёМфЕФСЌНгЁЂАВШЋЁЂСїСППижЦКЭПЩЙлВтЕШЭЈгУЙІФмЯТГСЮЊЦНЬЈЛљДЁЩшЪЉЃЌЪЕЯжгІгУгыЦНЬЈЛљДЁЩшЪЉЕФНтёюЁЃНтёюШУПЊЗЂепОлНЙгквЕЮёТпМБОЩэЖјЮоашЙизЂЮЂЗўЮёЯрЙижЮРэЮЪЬтЃЌЬсЩ§гІгУПЊЗЂаЇТЪВЂМгЫйвЕЮёЬНЫїКЭДДаТЁЃвђЮЊДѓСПЗЧЙІФмадДгвЕЮёНјГЬАўРыЕНСэЭтНјГЬжаЃЌService Mesh вдЮоЧжШыЕФЗНЪНЪЕЯжСЫгІгУЧсСПЛЏЁЃ

ЗўЮёЭјИёДгзмЬхМмЙЙЩЯРДНВБШНЯМђЕЅЃЌВЛЙ§ЪЧвЛЖбНєАЄзХИїЯюЗўЮёЕФгУЛЇДњРэЃЌЭтМгвЛзщШЮЮёЙмРэСїГЬзщГЩЁЃДњРэдкЗўЮёЭјИёжаБЛГЦЮЊЪ§ОнВуЛђЪ§ОнЦНУцЃЈdata planeЃЉЃЌЙмРэСїГЬБЛГЦЮЊПижЦВуЛђПижЦЦНУцЃЈcontrol planeЃЉЁЃЪ§ОнВуНиЛёВЛЭЌЗўЮёжЎМфЕФЕїгУВЂЖдЦфНјааЁАДІРэЁБЃЛПижЦВуаЕїДњРэЕФааЮЊЃЌВЂЮЊдЫЮЌШЫдБЬсЙЉ APIЃЌгУРДВйПиКЭВтСПећИіЭјТчЁЃ
ИќНјвЛВНЕиЫЕЃЌЗўЮёЭјИёЪЧвЛИізЈгУЕФЛљДЁЩшЪЉВуЃЌжМдкЁАдкЮЂЗўЮёМмЙЙжаЪЕЯжПЩППЁЂПьЫйКЭАВШЋЕФЗўЮёМфЕїгУЁБЁЃЫќВЛЪЧвЛИіЁАЗўЮёЁБЕФЭјИёЃЌЖјЪЧвЛИіЁАДњРэЁБЕФЭјИёЃЌЗўЮёПЩвдВхШыетИіДњРэЃЌДгЖјЪЙЭјТчГщЯѓЛЏЁЃдкЕфаЭЕФЗўЮёЭјИёжаЃЌетаЉДњРэзїЮЊвЛИі sidecarЃЈБпГЕЃЉБЛзЂШыЕНУПИіЗўЮёВПЪ№жаЁЃЗўЮёВЛжБНгЭЈЙ§ЭјТчЕїгУЗўЮёЃЌЖјЪЧЕїгУЫќУЧБОЕиЕФ sidecar ДњРэЃЌЖј sidecar ДњРэгжДњБэЗўЮёЙмРэЧыЧѓЃЌДгЖјЗтзАСЫЗўЮёМфЭЈаХЕФИДдгадЁЃЯрЛЅСЌНгЕФ sidecar ДњРэМЏЪЕЯжСЫЫљЮНЕФЪ§ОнЦНУцЃЌетгыгУгкХфжУДњРэКЭЪеМЏжИБъЕФЗўЮёЭјИёзщМўЃЈПижЦЦНУцЃЉаЮГЩЖдБШЁЃ
змЖјбджЎЃЌService Mesh ЕФЛљДЁЩшЪЉВужївЊЗжЮЊСНВПЗжЃКПижЦЦНУцгыЪ§ОнЦНУцЁЃЕБЧАСїааЕФСНПюПЊдДЗўЮёЭјИё Istio КЭ Linkerd ЪЕМЪЩЯЖМЪЧетжжЙЙдьЁЃ

вд Istio ЮЊР§
1ЁЂПижЦЦНУцЃКПижЦУцЪЧгУРДХфжУЁЂМрПиЁЂеЙЪОЪ§ОнУцЭјТчСїСПЕФвЛзщГЬађЁЃ
a) ВЛжБНгНтЮіЪ§ОнАќЁЃ
b) гыПижЦЦНУцжаЕФДњРэЭЈаХЃЌЯТЗЂВпТдКЭХфжУЁЃ
c) ИКд№ЭјТчааЮЊЕФПЩЪгЛЏЁЃ
d) ЭЈГЃЬсЙЉ API ЛђепУќСюааЙЄОпПЩгУгкХфжУАцБОЛЏЙмРэЃЌБугкГжајМЏГЩКЭВПЪ№ЁЃ
2ЁЂЪ§ОнЦНУц
a) жБНгДІРэШыеОКЭГіеОЪ§ОнАќЃЌзЊЗЂЁЂТЗгЩЁЂНЁПЕМьВщЁЂИКдиОљКтЁЂШЯжЄЁЂМјШЈЁЂВњЩњМрПиЪ§ОнЕШЁЃ
b) Service Mesh ЕФЪ§ОнУцЪЧвЛИіИі sidecar гІгУГЬађЃЌsidecar ДІРэЕФЪЧЮЂЗўЮёЕФЭјТчЪ§ОнзЊЗЂЁЃIstio ЪЙгУ Enovy ЯюФПзїЮЊ sidecar ЕФЪЕЯжЁЃ
c) ЖдгІгУРДЫЕЭИУїЃЌМДПЩвдзіЕНЮоИажЊВПЪ№ЁЃ
d) ЕБ Istio гы Kubernetes вЛЦ№гУРДЙЙНЈ Cloud Native гІгУЪБЃЌsidecar БОЩэзїЮЊ Kubernetes Pod жаЕФвЛИіШнЦїдЫааЁЃ
ФЧУД Service Mesh ДјРДЕФеце§МлжЕгаФФаЉФиЃП
1ЁЂЮЂЗўЮёжЮРэгывЕЮёТпМЕФНтёюЁЃЗўЮёЭјИёАб SDK жаЕФДѓВПЗжФмСІДггІгУжаАўРыГіРДЃЌВ№НтЮЊЖРСЂНјГЬЃЌвд sidecar ЕФФЃЪННјааВПЪ№ЁЃЗўЮёЭјИёЭЈЙ§НЋЗўЮёЭЈаХМАЯрЙиЙмПиЙІФмДгвЕЮёГЬађжаЗжРыВЂЯТГСЕНЛљДЁЩшЪЉВуЃЌЪЙЦфКЭвЕЮёЯЕЭГЭъШЋНтёюЃЌЪЙПЊЗЂШЫдБИќМгзЈзЂгквЕЮёБОЩэЁЃ
2ЁЂвьЙЙЯЕЭГЕФЭГвЛжЮРэЁЃЫцзХаТММЪѕЕФЗЂеЙКЭШЫдБИќЬцЃЌдкЭЌвЛМвЙЋЫОжаЭљЭљЛсГіЯжВЛЭЌгябдЁЂВЛЭЌПђМмЕФгІгУКЭЗўЮёЃЌЮЊСЫФмЙЛЭГвЛЙмПиетаЉЗўЮёЃЌвдЭљЕФзіЗЈЪЧЮЊУПжжгябдЁЂУПжжПђМмЖМПЊЗЂвЛЬзЭъећЕФ SDKЃЌЮЌЛЄГЩБОЗЧГЃжЎИпЃЌЖјЧвИјЙЋЫОЕФжаМфМўЭХЖгДјРДСЫКмДѓЕФЬєеНЁЃгаСЫЗўЮёЭјИёжЎКѓЃЌЭЈЙ§НЋжїЬхЕФЗўЮёжЮРэФмСІЯТГСЕНЛљДЁЩшЪЉЃЌЖргябдЕФжЇГжОЭЧсЫЩКмЖрСЫЁЃжЛашвЊЬсЙЉвЛИіЗЧГЃЧсСПМЖЕФ SDKЃЌЩѕжСКмЖрЧщПіЯТЖМВЛашвЊвЛИіЕЅЖРЕФ SDKЃЌОЭПЩвдЗНБуЕиЪЕЯжЖргябдЁЂЖравщЕФЭГвЛСїСПЙмПиЁЂМрПиЕШашЧѓЁЃ
3ЁЂПЩЙлВьадЁЃвђЮЊЗўЮёЭјИёЪЧвЛИізЈгУЕФЛљДЁЩшЪЉВуЃЌЫљгаЕФЗўЮёМфЭЈаХЖМвЊЭЈЙ§ЫќЃЌЫљвдЫќдкММЪѕЖбеЛжаДІгкЖРЬиЕФЮЛжУЃЌвдБудкЗўЮёЕїгУМЖБ№ЩЯЬсЙЉЭГвЛЕФвЃВтжИБъЁЃетвтЮЖзХЃЌЫљгаЗўЮёЖМБЛМрПиЮЊЁАКкКаЁБЁЃЗўЮёЭјИёВЖЛёжюШчРДдДЁЂФПЕФЕиЁЂавщЁЂURLЁЂзДЬЌТыЁЂбгГйЁЂГжајЪБМфЕШЯпТЗЪ§ОнЁЃетБОжЪЩЯЕШЭЌгк web ЗўЮёЦїШежОПЩвдЬсЙЉЕФЪ§ОнЃЌЕЋЪЧЗўЮёЭјИёПЩвдЮЊЫљгаЗўЮёВЖЛёетаЉЪ§ОнЃЌЖјВЛНіНіЪЧЕЅИіЗўЮёЕФ web ВуЁЃашвЊжИГіЕФЪЧЃЌЪеМЏЪ§ОнНіНіЪЧНтОіЮЂЗўЮёгІгУГЬађжаПЩЙлВьадЮЪЬтЕФвЛВПЗжЁЃДцДЂгыЗжЮіетаЉЪ§ОндђашвЊЖюЭтФмСІЕФЛњжЦЕФВЙГфЃЌШЛКѓзїгУгкОЏБЈЛђЪЕР§здЖЏЩьЫѕЕШЁЃ
4ЁЂСїСППижЦЁЃЭЈЙ§ Service MeshЃЌПЩвдЮЊЗўЮёЬсЙЉжЧФмТЗгЩЃЈРЖТЬВПЪ№ЁЂН№ЫПШИЗЂВМЁЂA/B testЃЉЁЂГЌЪБжиЪдЁЂШлЖЯЁЂЙЪеЯзЂШыЁЂСїСПОЕЯёЕШИїжжПижЦФмСІЁЃЖјвдЩЯетаЉЭљЭљЪЧДЋЭГЮЂЗўЮёПђМмВЛОпБИЃЌЕЋЪЧЖдЯЕЭГРДЫЕжСЙиживЊЕФЙІФмЁЃР§ШчЃЌЗўЮёЭјИёГадиСЫЮЂЗўЮёжЎМфЕФЭЈаХСїСПЃЌвђДЫПЩвддкЭјИёжаЭЈЙ§ЙцдђНјааЙЪеЯзЂШыЃЌФЃФтВПЗжЮЂЗўЮёГіЯжЙЪеЯЕФЧщПіЃЌЖдећИігІгУЕФНЁзГадНјааВтЪдЁЃгЩгкЗўЮёЭјИёЕФЩшМЦФПЕФЪЧгааЇЕиНЋРДдДЧыЧѓЕїгУСЌНгЕНЦфзюгХФПБъЗўЮёЪЕР§ЃЌЫљвдетаЉСїСППижЦЬиадЪЧЁАУцЯђФПЕФЕиЕФЁБЁЃете§ЪЧЗўЮёЭјИёСїСППижЦФмСІЕФвЛДѓЬиЕуЁЃ
5ЁЂАВШЋЁЃдкФГжжГЬЖШЩЯЃЌЕЅЬхМмЙЙгІгУЪмЦфЕЅЕижЗПеМфЕФБЃЛЄЁЃШЛЖјЃЌвЛЕЉЕЅЬхМмЙЙгІгУБЛЗжНтЮЊЖрИіЮЂЗўЮёЃЌЭјТчОЭЛсГЩЮЊвЛИіживЊЕФЙЅЛїУцЁЃИќЖрЕФЗўЮёвтЮЖзХИќЖрЕФЭјТчСїСПЃЌетЖдКкПЭРДЫЕвтЮЖзХИќЖрЕФЛњЛсРДЙЅЛїаХЯЂСїЁЃЖјЗўЮёЭјИёЧЁЧЁЬсЙЉСЫБЃЛЄЭјТчЕїгУЕФФмСІКЭЛљДЁЩшЪЉЁЃЗўЮёЭјИёЕФАВШЋЯрЙиЕФКУДІжївЊЬхЯждквдЯТШ§ИіКЫаФСьгђЃКЗўЮёЕФШЯжЄЁЂЗўЮёМфЭЈбЖЕФМгУмЁЂАВШЋЯрЙиВпТдЕФЧПжЦжДааЁЃ
Service Mesh КЭдЦдЩњ
ЮвУЧжЊЕРдЦдЩњЕФШ§МнТэГЕЮЊ ServerlessЁЂService MeshЁЂKubernetesЃЌЖј Istio вбГЩЮЊСЫ Sevice Mesh ЕФЪТЪЕБъзМЃЌЕБЮвУЧРэНт Kubernetes КЭ Istio УћзжЕФКЌвхЃЌЗЂЯжЦфжаЕФАТУюЃЌKubernetes УћзжвтЮЊЖцЪжЃЌЪЧдЦдЩњЕФВйзїЯЕЭГЃЌIstio ЕФвтЫМЮЊДЌЗЋЃЌвтЮЖзХЮвУЧвЊЕНДяжеМЋдЦдЩњФПБъЃЌВЛНівЊгаЖцЪжЃЌЛЙашвЊДЌЗЋЁЃетвВФмНвЪО CNCF ЕФвАаФКЭЗНЯђЁЃ
Kubernetes ЕФБОжЪЪЧгІгУЕФЩњУќжмЦкЙмРэЃЌОпЬхРДЫЕОЭЪЧВПЪ№КЭЙмРэЃЈРЉЫѕШнЁЂздЖЏЛжИДЁЂЗЂВМЃЉЃЌЮЂЗўЮёЬсЙЉСЫПЩРЉеЙЁЂИпЕЏадЕФВПЪ№КЭЙмРэЦНЬЈЁЃService Mesh ЕФЛљДЁЪЧЭИУїДњРэЃЌЭЈЙ§ sidecar proxy РЙНиЕНЮЂЗўЮёМфСїСПКѓдйЭЈЙ§ПижЦЦНУцХфжУЙмРэЮЂЗўЮёЕФааЮЊЁЃService Mesh НЋСїСПЙмРэДг Kubernetes жаНтёюЃЌService Mesh ФкВПЕФСїСПЮоаш kube-proxy зщМўЕФжЇГжЃЌЭЈЙ§ЮЊИќНгНќЮЂЗўЮёгІгУВуЕФГщЯѓЃЌЙмРэЗўЮёМфЕФСїСПЁЂАВШЋадКЭПЩЙлВьадЁЃ
ШчЙћЫЕ Kubernetes ЙмРэЕФЖдЯѓЪЧ PodЃЌФЧУД Service Mesh жаЙмРэЕФЖдЯѓОЭЪЧвЛИіИі ServiceЃЌЫљвдЫЕЪЙгУ Kubernetes ЙмРэЮЂЗўЮёКѓдйгІгУ Service Mesh ОЭЪЧЫЎЕНЧўГЩСЫЃЌШчЙћСЌ Service ФувВВЛЯыЙмСЫЃЌФЧФуОЭашвЊ Serverless СЫЁЃ
ОЭЯёжЎЧАЫЕЕФШэМўПЊЗЂУЛгавјЕЏЃЌДЋЭГЮЂЗўЮёМмЙЙгааэЖрЭДЕуЃЌЖјЗўЮёЭјИёвВВЛР§ЭтЃЌвВгаЫќЕФОжЯоадЁЃ
1ЁЂдіМгСЫИДдгЖШЁЃЗўЮёЭјИёНЋ sidecar ДњРэКЭЦфЫќзщМўв§ШыЕНвбОКмИДдгЕФЗжВМЪНЛЗОГжаЃЌЛсМЋДѓЕидіМгећЬхСДТЗКЭВйзїдЫЮЌЕФИДдгадЁЃ
2ЁЂдЫЮЌШЫдБашвЊИќзЈвЕЁЃдкШнЦїБрХХЦїЃЈШч KubernetesЃЉЩЯЬэМг Istio жЎРрЕФЗўЮёЭјИёЃЌЭЈГЃашвЊдЫЮЌШЫдБГЩЮЊетСНжжММЪѕЕФзЈМвЃЌвдБуГфЗжЪЙгУЖўепЕФЙІФмвдМАЖЈЮЛЛЗОГжагіЕНЕФЮЪЬтЁЃ
3ЁЂбгГйЁЃДгСДТЗВуУцРДНВЃЌЗўЮёЭјИёЪЧвЛжжЧжШыадЕФЁЂИДдгЕФММЪѕЃЌПЩвдЮЊЯЕЭГЕїгУдіМгЯджјЕФбгГйЁЃетИібгГйЪЧКСУыМЖБ№ЕФЃЌЕЋЪЧдкЬиЪтвЕЮёГЁОАЯТЃЌетИібгГйПЩФмвВЪЧФбвдШнШЬЕФЁЃ
4ЁЂЦНЬЈЕФЪЪХфЁЃЗўЮёЭјИёЕФЧжШыадЦШЪЙПЊЗЂШЫдБКЭдЫЮЌШЫдБЪЪгІИпЖШзджЮЕФЦНЬЈВЂзёЪиЦНЬЈЕФЙцдђЁЃ
СљЁЂDevOps
DevOps ОЭЪЧЮЊСЫЬсИпШэМўбаЗЂаЇТЪЃЌПьЫйгІЖдБфЛЏЃЌГжајНЛИЖМлжЕЕФЕФвЛЯЕСаРэФюКЭЪЕМљЃЌЦфЛљБОЫМЯыОЭЪЧГжајВПЪ№ЃЈCD)ЃЌШУШэМўЕФЙЙНЈЁЂВтЪдЁЂЗЂВМФмЙЛИќМгПьНнПЩППЃЌвдОЁСПЫѕЖЬЯЕЭГБфИќДгЬсНЛЕНзюКѓАВШЋВПЪ№ЕНЩњВњЯЕЭГЕФЪБМфЁЃ
вЊЪЕЯжГжајВПЪ№ЃЈCD)ЃЌОЭБиаыЖдвЕЮёНјааЖЫЕНЖЫЗжЮіЃЌАбЫљгаЯрЙиВПУХЕФВйзїЭГвЛПМТЧНјаагХЛЏЃЌРћгУЫљПЩгУЕФММЪѕКЭЗНЗЈЃЌгУвЛжжРэФюРДећКЯзЪдДЁЃDevOps ЬсГЋДђЦЦПЊЗЂЁЂВтЪдКЭдЫЮЌжЎМфЕФБкРнЃЌРћгУММЪѕЪжЖЮЪЕЯжИїИіШэМўПЊЗЂЛЗНкЕФздЖЏЛЏЩѕжСжЧФмЛЏЃЌБЛжЄЪЕЖдЬсИпШэМўЩњВњжЪСПЁЂАВШЋЃЌЫѕЖЬШэМўЗЂВМжмЦкЕШЖМгаЗЧГЃУїЯдЕФДйНјзїгУЃЌвВЭЦЖЏСЫ IT ММЪѕЕФЗЂеЙЁЃ
DevOps ддђ
- ЮФЛЏЃЈCultureЃЉ
вЛАуДѓМвЙизЂЕФЖМЪЧММЪѕКЭЙЄОпЃЌЕЋЪЕМЪЩЯвЊНтОіЕФКЫаФЮЪЬтЪЧКЭвЕЮёЁЂКЭШЫЯрЙиЕФЮЪЬтЁЃЬсИпаЇТЪЃЌМгЧПазїЃЌОЭашвЊВЛЭЌЕФЭХЖгжЎМфИќКУЕФЙЕЭЈЁЃШчЙћУПИіШЫФмЙЛИќКУЕФЯрЛЅРэНтЖдЗНЕФФПБъКЭЙиЧаЕФЖдЯѓЃЌФЧУДазїЕФжЪСПОЭПЩвдУїЯдЕФЬсИпЁЃ
DevOps ЪЕЪЉжаУцЖдЕФЪзвЊУЌЖмдкгкВЛЭЌЭХЖгЕФЙизЂЕуЭъШЋВЛвЛбљЁЃдЫЮЌШЫдБЯЃЭћЯЕЭГдЫааПЩППЃЌЫљвдЯЕЭГЮШЖЈадКЭАВШЋадЪЧЕквЛЮЛЁЃЖјПЊЗЂШЫдБдђЯызХШчКЮОЁПьШУаТЙІФмЩЯЯпЃЌЪЕЯжДДаТКЭЭЛЦЦЃЌЮЊПЭЛЇЬсЙЉИќДѓМлжЕЁЃВЛЭЌЕФвЕЮёЪгНЧЃЌБиШЛЕМжТЮѓЛсКЭФІВСЃЌЕМжТЫЋЗНЖМОѕЕУЖдЗНдкзшФгздМКЭъГЩЙЄзїЁЃвЊЪЕЪЉ DevOpsЃЌОЭЪзЯШвЊШУПЊЗЂКЭдЫЮЌШЫдБШЯЪЖЕНЫћУЧЕФФПБъЪЧвЛжТЕФЃЌжЛЪЧЙЄзїИкЮЛВЛЭЌЃЌашвЊЙВЕЃд№ШЮЁЃетОЭЪЧ DevOps ашвЊЪзЯШдкЮФЛЏВуУцНтОіЕФЮЪЬтЁЃжЛгаНтОіСЫШЯжЊЮЪЬтЃЌВХФмДђЦЦВЛЭЌЭХЖгжЎЕФКшЙЕЃЌЪЕЯжСїГЬздЖЏЛЏЃЌАбДѓМвЕФЙЄзїШкКЯГЩвЛЬхЁЃ
- здЖЏЛЏЃЈAutomationЃЉ
DevOps ЕФГжајМЏГЩЕФФПБъОЭЪЧаЁВНПьХмЃЌПьЫйЕќДњЃЌЦЕЗБЗЂВМЁЃвЊАбетИіРэФюТфЪЕЃЌОЭашвЊЙцЗЖЛЏКЭСїГЬЛЏЃЌШУПЩвдздЖЏЛЏЕФЛЗНкЪЕЯжздЖЏЛЏЁЃ
- ЖШСПЃЈMeasurementЃЉ
ЭЈЙ§Ъ§ОнПЩвдЖдУПИіЛюЖЏКЭСїГЬНјааЖШСПКЭЗжЮіЃЌевЕНЙЄзїжаДцдкЕФЦПОБКЭТЉЖДвдМАЖдгкЮЃМБЧщПіЕФМАЪББЈОЏЕШЁЃЭЈЙ§ЗжЮіЃЌПЩвдЖдЭХЖгЙЄзїКЭЯЕЭГНјааЕїећЃЌШУаЇТЪИФНјаЮГЩБеЛЗЁЃЖШСПЪзЯШвЊНтОіЪ§ОнзМШЗадЁЂЭъећадКЭМАЪБадЮЪЬтЃЌЦфДЮвЊНЈСЂе§ШЗЕФЗжЮіжИБъЁЃDevOps Й§ГЬПМКЫЕФБъзМгІИУЙФРјЭХЖгИќМгзЂжиЙЄОпЕФНЈЩшЃЌздЖЏЛЏЕФМгЫйКЭИїИіЛЗНкгХЛЏЃЌетбљВХФмзюДѓПЩФмЗЂЛгЖШСПЕФзїгУЁЃ
- ЙВЯэЃЈSharingЃЉ
вЊЪЕЯжеце§ЕФазїЃЌЛЙашвЊЭХЖгдкжЊЪЖВуУцДяГЩвЛжТЁЃЭЈЙ§ЙВЯэжЊЪЖЃЌШУЭХЖгЙВЭЌНјВНЁЃПЩМћЖШ visibilityЃЌЭИУїад transparencyЃЌжЊЪЖЕФДЋЕн transfer of knowledgeЁЃ
IaC
IaC ЃЈInfrastructure as CodeЃЉЬсГіЯЕЭГНЈЩшЕФКЫаФРэФюЃЌМцЙЫИпаЇКЭАВШЋЃЌШУдЫЮЌЯЕЭГЕФНЈЩшИќМггаађЁЃ
дЫЮЌЦНЬЈвЛАуЖМОРњЙ§ШчЯТМИИіЗЂеЙНзЖЮЃКЪжЙЄЁЂНХБОЁЂЙЄОпЁЂЦНЬЈЁЂжЧФмЛЏдЫЮЌЕШЃЌЕЋзмЬхРДЫЕЗжЮЊСНРрЃКжИСюЪНЃЌЩљУїЪНЁЃ
дкИДдгЕФдЫЮЌГЁОАЯТЃЌжИСюЪНЕФдЫЮЌЗНЪНОпгаБфИќВйзїИБзїгУЃКВЛЭИУїЁЂжИСюадНгПквЛАуВЛОпгаУнЕШадЁЂФбвдЪЕЯжИДдгЕФБфИќПижЦЁЂжЊЪЖФбвдЛ§РлКЭЗжЯэЁЂБфИќШБЗІВЂЗЂадЕШШБЕуЁЃ
ШЫУЧЬсГіСЫЩљУїЪНЕФБрГЬРэФюЁЃгУЛЇНіНіЭЈЙ§вЛжжЗНЪНУшЪіЦфвЊЕНДяЕФФПЕФЃЌЖјВЂВЛОпЬхЫЕУїШчКЮДяЕНФПБъЁЃЩљУїЪННгПкЪЕМЪЩЯДњБэСЫвЛжжЫМЮЌФЃЪНЃКАбЯЕЭГЕФКЫаФЙІФмНјааГщЯѓКЭЗтзАЃЌШУгУЛЇдквЛИіИќИпЕФВуДЮЩЯНјааВйзїЁЃЩљУїЪННгПкЪЧвЛжжКЭдЦМЦЫуЪБДњЯрЦѕКЯЕФЫМЮЌЗЖЪНЁЃЧАУцСаГіЕФжИСюЪНЕФШБЕуЖМПЩвдгЩЩљУїЪННгПкРДУжВЙЁЃ
GitOps
GitOps зїЮЊ IaC дЫЮЌРэФюЕФвЛжжОпЬхТфЕиЗНЪНЃЌОЭЪЧЪЙгУ Git РДДцДЂЙигкгІгУЯЕЭГЕФзюжезДЬЌЕФЩљУїЪНУшЪіЁЃGitOps ЕФКЫаФЪЧвЛИі GitOps в§ЧцЃЌЫќИКд№МрПи Git жаЕФзДЬЌЃЌУПЕБЫќЗЂЯжзДЬЌгаИФБфЃЌЫќОЭИКд№АбФПБъгІгУЯЕЭГжаЕФзДЬЌвдАВШЋПЩППЕФЗНЪНЧЈвЦЕНФПБъзДЬЌЃЌЪЕЯжВПЪ№ЁЂЩ§МЖЁЂХфжУаоИФЁЂЛиЙіЕШВйзїЁЃ
Git жаДцДЂгаЖдгкгІгУЯЕЭГЕФЭъећУшЪівдМАЫљгааоИФРњЪЗЁЃЗНБужиНЈЕФЭЌЪБЃЌвВБугкЖдЯЕЭГЕФИќаТРњЪЗНјааВщПДЃЌЗћКЯ DevOps ЫљЬсГЋЕФЭИУїЛЏддђЁЃЭЌЪБЃЌGitOps вВОпгаЩљУїЪНдЫЮЌЕФЫљгагХЕуЁЃКЭ GitOps ХфЬзЕФвЛИіЛљБОМйЩшЪЧВЛПЩБфЛљДЁЩшЪЉЃЌЫљвд GitOps КЭ Kubernetes дЫЮЌПЩвдЗЧГЃКУЕФХфКЯЁЃ
дЦдЩњПЊдДЩњЬЌЕФНЈЩшЃЌЛљБОЭГвЛСЫШэМўВПЪ№КЭдЫЮЌЕФЛљБОФЃЪНЁЃИќживЊЕФЪЧЃЌдЦдЩњММЪѕЕФПьЫйбнНјЃЌММЪѕИДдгадВЛЖЯЯТГСЕНдЦЃЌИГФмПЊЗЂепИіЬхФмСІЃЌВЛЖЯЬсЩ§СЫгІгУПЊЗЂаЇТЪЁЃ
ЪзЯШЪЧШнЦїММЪѕКЭ Kubernetes ЗўЮёБрХХММЪѕЕФНсКЯЃЌНтОіСЫгІгУВПЪ№здЖЏЛЏЁЂБъзМЛЏЁЂХфжУЛЏЮЪЬтЁЃCNCF ДђЦЦСЫдЦЩЯЦНЬЈЕФБкРнЃЌЪЙНЈЩшПчЦНЬЈЕФгІгУГЩЮЊПЩФмЃЌГЩЮЊЪТЪЕЩЯЕФдЦЩЯгІгУПЊЗЂЦНЬЈЕФБъзМЃЌМЋДѓМђЛЏСЫЖрдЦВПЪ№ЁЃ
вЛИіЭъећПЊЗЂСїГЬЩцМАЕНКмЖрВНжшЃЌЖјЛЗНкдНЖрЃЌвЛДЮбЛЗЛЈЗбЕФЪБМфдНГЄЃЌаЇТЪОЭдНЕЭЁЃЮЂЗўЮёЭЈЙ§АбОоЪЏгІгУВ№НтЮЊШєИЩЕЅЙІФмЕФЗўЮёЃЌМѕЩйСЫЗўЮёМфЕФёюКЯадЃЌШУПЊЗЂКЭВПЪ№ИќМгБуНнЃЌПЩвдгааЇНЕЕЭПЊЗЂжмЦкЃЌЬсИпВПЪ№СщЛюадЁЃService Mesh ШУжаМфМўЕФЩ§МЖКЭгІгУЯЕЭГЕФЩ§МЖЭъШЋНтёюЃЌдкдЫЮЌКЭЙмПиЗНУцЕФСщЛюадЛёЕУЬсЩ§ЁЃServerless ШУдЫЮЌЖдПЊЗЂЭИУїЃЌЖдгкгІгУЫљашзЪдДНјааздЖЏЩьЫѕЁЃFaaS ЪЧ Serverless ЕФвЛжжЪЕЯжЃЌдђИќМгМђЛЏСЫПЊЗЂдЫЮЌЕФЙ§ГЬЃЌДгПЊЗЂЕНзюКѓВтЪдЩЯЯпЖМПЩвддквЛИіМЏГЩПЊЗЂЛЗОГжаЭъГЩЁЃЮоТлФФвЛжжГЁОАЃЌКѓЬЈЕФдЫЮЌЦНЬЈЕФЙЄзїЖМЪЧВЛПЩвдШБЩйЕФЃЌжЛЪЧЭЈЙ§ММЪѕШУРЉШнЁЂШнДэЕШММЪѕЖдПЊЗЂШЫдБЭИУїЃЌШУаЇТЪИќИпЁЃ
5ЁЂiPaaSЃЈОЉЖЋЧАЬЈбаЗЂБъзМЃЉдкдЦдЩњЕФЫМПМКЭЬНЫї
вдЯТЪЧ iPaaS дИОАдкФмСІЭМЦзжаЕФЙсГЙЁЃ

ЫцзХ iPaaS ИГФмПЊЗЂепДгЪдЫЎНзЖЮе§ТѕЯђИГФмНзЖЮЃЌЮвУЧЖд iPaaS ЕФФмСІгаСЫВЛЭЌЕФРэНтКЭЫМПМЃЌДгзюГѕОлНЙЕФ 5 ДѓФмСІЃЌЕНЮвУЧДггУЛЇНЧЖШЁЂДгвЕЮёГЁОАГіЗЂЛђНтЦЪ iPaaS ЕФФкдкМлжЕРДПДЃЌПЩвдЕУГіВЛвЛбљЕФФмСІКЭМлжЕЃЌЮвАбетаЉФмСІаЮГЩВЛЭЌЕФжїЯпЃЌвдЧЃв§ЮвУЧФмНЈЩшГівЛИігаЛюСІЁЂвдвЕЮёГЁОАЮЊжааФЕФ iPaaS ЬхЯЕЁЃ
a) iPaaS ЕФКЫаФЫМЯыКЭЛљДЁЪЧБъзМЃЌИњОпЬхЪЕЯжЗНЪНЛЎЧхНчЯоЃЌвтЮЖзХЪЧГщЯѓЕФЁЂЮШЖЈЕФЃЌвВЪЧПЊЗХКЭПЩРЉеЙЕФЁЃБъзМЪЧ iPaaS аЮГЩЬхЯЕЕФРэТлЛљДЁЁЃ
b) iPaaS ЙтгаБъзМЛЙВЛааЃЌЫЖМПЩвдИувЛЬзБъзМРДЃЌШчЙћЮвУЧФмЬсЙЉПЊЗЂепЛљгкБъзМЯТЕФСЂЬхЪНКЭвЛеОЪНММЪѕПЊЗЂКЭЙВНЈЦНЬЈЃЌШУПЊЗЂепПЩвдЕЭУХМїЁЂСщЛюКЭИпаЇЖЈжЦКЭПЊЗЂЃЌетИіЖдПЊЗЂепЕФЮќв§СІЪЧЮоЧюЕФЁЃЫљвд iPaaS ММЪѕПЊЗХЬхЯЕЪЧЪѕЃЌЪЧЙЄОпЁЃ
c) ЕЋгаБъзМКЭММЪѕПЊЗХЬхЯЕвВВЛЙЛЃЌФмСІЖМЪЧЕузДЕФЃЌЮоЗЈЬхЯЕЛЏНтОівЕЮёЕФГЁОАЛЏашЧѓЁЃiPaaS ЕФБГКѓвЛИіжиДѓМлжЕЪЧвЛИіЧПДѓЕФвЕЮёЦНЬЈЃЌЮвУЧвВГЦЮЊ SaaSЃЌSaaS ЪЧЭСШРЃЌШУБъзМКЭММЪѕПЊЗХЬхЯЕПЩвдДгЪїФОБфГЩЪїСжЃЌзЬЩњГіИїжжИїбљЕФвЕЮёНтОіЗНАИЁЃ
d) iPaaS вЊаЮГЩГжајЗБШйЕФЩњЬЌЃЌвЛИіИуаІФмСІГСЕэКЭЙВЯэЕФЬхЯЕБиВЛПЩЩйЃЌГСЕэКЭЙВЯэШУ iPaaS ЩњЬЌЫЎГижаЕФЫЎдНРДдНЖрЁЃ
e) ОЉЖЋвЕЮёПьЫйЗЂеЙЃЌДпЩњГіСЫИїжжИїбљЕФаТеОЕуКЭаТШќЕРЃЌЭЈгУАцПЩвдШУ iPaaS ПьЫйЭъГЩЖРСЂВПЪ№КЭНЛИЖЁЃетвВЪЧ iPaaS УцСйЕФвЛИіДѓЕФвЕЮёГЁОАЁЃ
f) iPaaS ВЛЕЋЪЧММЪѕЃЌЧПЕїЩшМЦЁЂбаЗЂЁЂВтЪддЫЮЌДђЦЦСїГЬБкРнЃЌЭГвЛФПБъЃЌБъзМСїГЬЃЌЬсЩ§азїаЇТЪКЭжЪСПЁЃ
g) зюКѓЃЌЪЧШЋГЁОАЕФНтОіЗНАИЃЌНтОіЗНАИЦфЪЕЪЧвЛжжЗўЮёОЋЩёЃЌБъзМЁЂММЪѕЬхЯЕКмживЊЃЌЕЋШчЙћЮвУЧФмЩюШывЕЮёГЁОАЃЌаЮГЩЧхЮњЕФНтОіЗНАИОиеѓЃЌПЩвдШУгУЛЇИпаЇТњзуздМКЕФашЧѓЁЃЦНЬЈЛЏНЈЩшвЊЭбРывЕЮёЃЌНтОіЗНАИЗѕЛЏвЊЩюШывЕЮёЁЃ
ЮвУЧАб iPaaS КЫаФРэФюЁЂМлжЕЁЂЗНЯђИњдЦдЩњЬхЯЕНјааећЬхадЗжЮіЃЌЗЂЯжЖўепдкКмЖрЗНУцЪЧЯрЭЌЕФЃЌЯТУцЪЧЪсРэЕФ iPaaS КЭдЦдЩњМлжЕКЭФмСІБГКѓЪЕЯждРэКЭРэФюЕФЖдБШЃК

ЖдБШдЦдЩњЕФРэФюКЭММЪѕЃЌiPaaS дквЛаЉЗНУцЕФНЈЩшзіЕФЩаПЩЃЌАќРЈЃК
1ЁЂНЈСЂСЫЭбРыСЫОпЬхПЭЛЇКЭвЕЮёГЁОАЕФЭЈгУЬхЯЕЛЏБъзМЃЌИУБъзМШУ iPaaS БфГЩвЛИіИпЖШПЊЗХЕФЬхЯЕЃЌЭЌЪБПЩЭЈЙ§ДЎСЊЩшМЦЦНЬЈЁЂВтЪдЦНЬЈЁЂМрПиЦНЬЈЕШаЮГЩвЛИівЛеОЪНдЦЩЯПЊЗЂКЭазїЦНЬЈЃЛ
2ЁЂЧПДѓКЭСЂЬхЪНЕФММЪѕПЊЗХЙВНЈЬхЯЕЃЌШУПЊЗЂепЮоашЙизЂжиИДадРЭЖЏКЭЕзВуММЪѕЩшЪЉКЭММЪѕИДдгЖШЃЌДгЖјПЩОлНЙКЭзЈзЂдквЕЮёДњТыКЭИіадЛЏашЧѓЕФЖЈжЦЩЯЃЌПЊЗЂепЕФбаЗЂаЇТЪКЭашЧѓНЛИЖаЇТЪЕУЕНСЫУїЯдЕФЬсЩ§ЁЃИВИЧДгДѓЧАЖЫЃЈiHubЃЉЁЂLow CodeЁЂFaaSЁЂЭЈгУАцЁЂЮЂЧАЖЫЕНжаКѓЬЈЙмРэЯЕЭГНтОіЗНАИЃЈDrip ЫЎЕЮЃЉЃЛ
3ЁЂiPaaS БъзМ+ЙВЯэФмСІЕФИДгУЃЌдкХфЬзММЪѕПЊЗХЬхЯЕЃЌПЩжЇГХПьЫйТњзувЕЮёЕФИїРрашЧѓЃЌжњСІвЕЮёЦЕЗБЪдДэКЭДДаТЁЃ
4ЁЂiPaaS БГКѓЕФЯЕЭГКЭЦНЬЈжЇГХСЫ 10+ИіОЉЖЋДѓДйЃЌДѓДйЦкМфЮоЪТЙЪКЭЮЪЬтЃЌЧаИпадФмИпПЩгУЕФНгПкБЃжЄСЫДѓДйвЕЮёЕФЦНЮШдЫгЊЁЃ
5ЁЂiPaaS вбПЊЪМИГФмОЉЖЋдкИїИіКЃЭтеОЕуЃЈЬЉЙњеОЁЂгЁФсеОЃЉКЭЩЬвЕЛЏЯюФПЃЌжњСІСуЪлММЪѕКЭвЕЮёФмСІзпГіЙЋЫОЁЃ
ЕЋЭЌЪБЮвУЧЗЂЯж iPaaS ЛЙДцдкБЁШѕЕФЛЗНкЛђиНД§МгЧПЬсЩ§ЕФЕиЗНЃЌНсКЯдЦдЩњЕФРэФюКЭММЪѕЃЌвдЯТЪЧЮвУЧЕФЫМПМКЭПЩФмЕФЙцЛЎЁЃ
1ЁЂгІгУЁАдЦдЩњЛЏЁБ
дЦдЩњгІгУдкЙЙНЈжЎГѕОЭЛљгквЛИіживЊЧАЬсЃКЩњдкдЦЩЯЃЌГЄдкдЦЩЯЁЃетОЭвЊЧѓгІгУШчЭЌаТЩњЖљвЛбљЃЌГ§СЫБЃСєвЕЮёДњТыЭтЃЌЗЧЙІФмадДњТыКЭжаМфМўДњТыЖМгІАўРыГіРДЃЌНЛгЩдЦЩшЪЉРДНгЙмЃЌвдЪЕЯждЦдЩњЕФРэФюЃКгІгУЕЎЩњЦ№ОЭЩњ/ГЄдкдЦЩЯЃЌФмЙЛзюДѓЛЏЕиЗЂЛгдЦЕФгХЪЦКЭМлжЕЃЌЪЕЯжВЛдкЙизЂЗЧЙІФмадашЧѓЕФЭЌЪБЯЕЭГЬьШЛОпБИЧсСПЁЂЕЏадЁЂУєНнКЭздЖЏЛЏЬиЕуЁЃзнЙл iPaaS КѓЖЫгІгУМмЙЙЃЌгІгУЕФДцДЂЁЂЯћЯЂЁЂЗўЮёСїСПжЮРэЁЂИпПЩгУЁЂШлЖЯШнДэЁЂздЖЏЛжИДФмСІЖМЪЧЭЈЙ§ЯрЙиМЏГЩдкгІгУжаДњТыЛђжаМфМў SDK РДЪЕЯжЕФЃЌУцСйЩ§МЖРЇФбЁЂЮоЗЈПчдЦВПЪ№ЕШЮЪЬтЁЃдкдЦдЩњЪБДњЃЌдЦАбШ§ЗНШэгВМўЕФФмСІЩ§МЖГЩСЫЗўЮёЃЌБШШчЁАШчКЮЛёШЁДцДЂЁББфГЩСЫШєИЩЗўЮёЃЌАќРЈЖдЯѓДцДЂЗўЮёЁЂПщДцДЂЗўЮёЕШЃЌетаЉЗўЮёАбЗжВМЪНГЁОАжаЕФИпПЩгУЬєеНЁЂздЖЏРЉЫѕШнЬєеНЁЂАВШЋЬєеНЁЂдЫЮЌЩ§МЖЬєеНЕШЖМДІРэСЫЁЃЫљвдгІгУашвЊОЙ§ЖджаМфМўжБНгвРРЕНјааНтёюЃЌетИіЙ§ГЬВЛЪЧвЛѕэЖјОЭЕФЃЌвРРЕгІгУдЫааЕФдЦМЦЫуЛЗОГЕФЫЎЦНЃЌЕЋЪЧгІгУНјааЖдММЪѕЛљДЁЩшЪЉКЭММЪѕжаМфМўЕФжБНгвРРЕЕФНтёюЪЧБивЊЕФЃЌЭЈЙ§вЛИіБъзМММЪѕжаМфВуРДИєРыгІгУКЭОпЬхЕФММЪѕЃЌФмЙЛдкЬѕМўГЩЪьЕФЪБКђЃЌАяжњгІгУПьЫйЪЕЯждЦдЩњЛЏВЂВПЪ№дкдЦЩЯЁЃвдЯТЪЧ iPaaS ЪЕЯждЦдЩњгІгУМмЙЙЕФзЊБфЃК

2ЁЂServerless
iPaaS ЬхЯЕдкЧАЬЈЃЌУцЖдзХКмЖрТпМУмМЏаЭашЧѓЃЌетаЉашЧѓБфИќЦЕЗБЃЌШчЪ§ОнИёЪНЛЏЁЂЪ§ОнзжЖЮзЊЛЛКЭМгЙЄЁЂЪ§ОнБъзМЛЏДІРэЕШЃЌетаЉашЧѓгУДЋЭГЕФбаЗЂСїГЬШч Java НЛИЖжмЦкЛсКмГЄЃЌЦЕЗБЩЯЯпЦЕЗББфИќЕМжТЯпЩЯЯЕЭГдЫааЮШЖЈдьГЩЭўаВЃЌеыЖдетаЉГЁОАЃЌiPaaS ЬсЙЉМДаДМДгУЁЂУыМЖЩЯЯпЕФКЏЪ§БраДЦНЬЈЃЌЭЈЙ§АбКЏЪ§зЂШыЕНгІгУГЬађжаЃЌЬсЙЉБОЕиЕїгУЃЌМЋДѓЬсЩ§СЫТпМадашЧѓНЛИЖаЇТЪЃЌЭЌЪБвВЬсЙЉЪТМўДЅЗЂЕФЗНЪНжДааКЏЪ§ЃЌМДНтёюСЫММЪѕКЭЦНЬЈЃЌгжЬсЩ§СЫзЪдДРћгУТЪЁЃВЛЙ§ЯждкЕФКЏЪ§ЦНЬЈжЛЪЧУцЖдЪЧЙЋЫОЕФПЊЗЂепЃЌгУРДЪЕЯжПьЫйНЛИЖКЭИіадЛЏТпМашЧѓЕФПьЫйЖЈжЦЃЌвЊЪЕЯжеце§ЕФ FaaSЃЌБиаывЊФмзіЕНЛљгкЪТМўДЅЗЂЛњжЦЁЂздЖЏЕЏадЩьЫѕЁЂАДашИЖЗбЕШЬиЕуЁЃiPaaS дкЪЕЯж Serverless ЛЏЕФТЗЩЯЪМжеБЇзХПЊЗХЕФаФЬЌЃЌРћгУдЦЛђздбаЪЕЯжКЏЪ§ЦНЬЈЕФ Serverless ЛЏЃЌЖМЪЧЮвУЧРжМћЕФЁЃвдЯТЪЧЮДРД iPaaS КЏЪ§ЦНЬЈЕФЗНЯђКЭЙцЛЎЃК

ЩЯЭМБъзЂСЫ 2 жжКЏЪ§жДааЕФЗНЪНЃЌЕквЛеХЪЧЭЈЙ§КЏЪ§ЙмРэЦНЬЈАбКЏЪ§ЗжЗЂЕНгІгУБОЕиЃЌеыЖдЕФЪЧЖдКЏЪ§жДаабгГйУєИаЕФГЁОАЃЌгІгУжБНгЕїгУЗжЗЂЕНЭЌвЛИіНјГЬжаЕФКЏЪ§ЃЌЛёЕУЯргІНсЙћЛђЭъГЩФГИіФмСІЃЛЕкЖўжжЗНЪНЪЧ iPaaS ЮДРДашвЊЭъЩЦЕФФмСІЃЌЭЈЙ§НЁШЋЛљгкЪТМўДЅЗЂЕФКЏЪ§ЕїгУЛњжЦРДЪЕЯжАДашИЖЗбЃЌЭЈЙ§ Kubernetes+Docker ММЪѕРДЙЙНЈПЩЪЕЯжздЖЏЕЏадЩьЫѕФмСІЕФ Serverless ЛЏМмЙЙЁЃ
3ЁЂService Mesh
УцЖд RPC ЗўЮёПђМмШч JSFЁЂDubbo ДцдкЕФЧжШыадЧПЁЂЮоЗЈПчгябдЁЂжаМфМўбнБфРЇФбЁЂФкШнЖрЁЂУХМїИпЁЂжЮРэЙІФмВЛШЋЕШЮЪЬтЃЌЮЂЗўЮёЕФЗЂЯжЁЂСїСПЙмРэЁЂСїСППЩЙлВтадЕШФмСІЭъШЋПЩвдШУИњгІгУВпЕзНтёюЕФ Service Mesh ММЪѕРДЪЕЯжЁЃзїЮЊаТвЛДњ Service Mesh ВњЦЗЕФСьКНепЃЌIstio ДДаТадЕФдкдгаЭјИёВњЦЗЕФЛљДЁЩЯЃЌЬэМгСЫПижЦЦНУцетвЛНсЙЙЃЌЪЙЦфВњЦЗаЮЬЌИќМгЕФЭъЩЦЁЃетвВЪЧЮЊЪВУД Istio БЛГЦзїЕкЖўДњ Service Mesh ЕФдвђЁЃIstio ФмЬсЙЉЃК
1) ЮЊ HTTPЁЂgRPCЁЂWebSocket КЭ TCP СїСПздЖЏИКдиОљКтЁЃ
2) ЭЈЙ§ЗсИЛЕФТЗгЩЙцдђЁЂжиЪдЁЂЙЪеЯзЊвЦКЭЙЪеЯзЂШыЖдСїСПааЮЊНјааЯИСЃЖШПижЦЁЃ
3) ЬсЙЉЭъЩЦЕФПЩЙлВьадЗНУцЕФФмСІЃЌАќРЈЖдЫљгаЭјИёПижЦЯТЕФСїСПНјааздЖЏЛЏЖШСПЁЂШежОМЧТМКЭзЗзйЁЃ
4) ЬсЙЉЩэЗнбщжЄКЭЪкШЈВпТдЃЌдкМЏШКжаЪЕЯжАВШЋЕФЗўЮёМфЭЈаХЁЃ

iPaaS ЮЊСЫЪЪгІИїРрдЦЛЗОГКЭММЪѕЩшЪЉЃЌНшжњБъзМММЪѕ API РДЦСБЮгІгУКЭОпЬхММЪѕЃЌЭЈЙ§ЭГвЛЪЪХфЦїРДЪЪХфВЛЭЌЕФММЪѕЩшЪЉКЭжаМфМўЃЌЪЙ iPaaS ПЩвддкВЛЭЌЛЗОГжаЪЕЯжЕЭГЩБОвЦжВЁЃЫљвдвдЩЯЗНАИВЛНіШУ iPaaS ВЛвРРЕ IstioЃЌЭЌЪБМЏГЩ Istio ФмЙЛИјЦНЬЈДјРДжюЖрШчЖдгІгУЭИУїЁЂПЩРЉеЙадЁЂПЩвЦжВадЁЂВпТдвЛжТадгХЪЦЁЃ
4ЁЂвЛМќЪНЩЬвЕЛЏЯюФПНЛИЖЗНАИ
1ЃЉЭЈгУАц
iPaaS КѓЖЫЭЈгУАцФмСІвбООЙ§СЫНќ 1 ФъАыЕФИФдьКЭбнНјЃЌФПЧАКЫаФФмСІЭЈгУадЁЂАДашИљОн Maven ДђАќЁЂSPI & BPaaS ФмСІРЉеЙКЭЖЈжЦЕШЗНУцвбОЗЂеЙЕНвЛЖЈЕФЫЎЦНЃЌПЩвдзіЕНВЛашвЊЛЈЗбКмЖрбаЗЂзЪдДЯТНЯПьАбЬхЯЕЧЈвЦЕНаТеОЕуЃЌЧАЬсЪЧаТеОЕувЊОпБИОЉЖЋдЦММЪѕЛљДЁЩшЪЉЃЌвВОЭЪЧОЉЖЋ IaaS КЭ PaaSЁЃБОЮФЧАУцвВНВЕНММЪѕЩЬвЕЛЏзїЮЊОЉЖЋдіГЄЕФаТЧњЯпЃЌПЩвддЄМћЮДРДЛсДпЩњдНРДдНЖрЕФЩЬвЕЛЏШќЕРКЭЯюФПЃЌiPaaS ећЬхЬхЯЕНтёюОЉЖЋ TPaaS ЪЦдкБиааЁЃЫљвдЮЊСЫ iPaaS ЭЈгУАцЕФЗНЯђЪЧНјааВпЕзЕФНтёю JD TPaaS ИФдьЃЌЭЈЙ§БъзМММЪѕ API+ММЪѕЪЪХфВуРДИєРы &ЪЪХфЕзВуММЪѕЁЃ

2ЃЉвЛМќЪННЛИЖЗНАИ
ЯЕЭГгаСЫЭЈгУАцФмСІКѓЃЌЮвУЧЗЂЯждкЯьгІаТЕФеОЕуКЭЩЬвЕЛЏЯюФПЙ§ГЬжазюДѓЕФЙЄзїСПКЭФбЬтЪЧШчКЮПьЫйвЦжВЁЂВПЪ№ећЬхЦНЬЈЬхЯЕЕНПЭЛЇЛЗОГЃЌПЩФмЪЧЙЋгадЦЁЂЫНгадЦЃЌЩѕжСЛьКЯдЦЃЌетОЭашвЊЮвУЧвРОндЦдЩњММЪѕЩшМЦГівЛЬзПЩвдПьЫйВПЪ№Эъећ iPaaS ЬхЯЕЕНВЛЭЌПЭЛЇдЦЛЗОГЕФФмСІЃЌЧвЬхЯЕПЩвдзіЕНЮШЖЈКЭвЛжТадЕФЗНЪНдЫааЁЃвдЯТЪЧЮвУЧГѕВНЩшМЦЕФЗНАИЃК

5ЁЂГжајЬсЩ§ iPaaS ЦНЬЈШЭад
гІгУЭЈЙ§НгШыдЦдЩњЗўЮёПЩвдЬьШЛЛёЕУПЩЙлВтадЁЂИпПЩгУЁЂШнДэадЁЂздгњЕШФмСІЃЌДгЖјЙЙНЈШЭадгІгУЁЃЭЌЪБдЦдЩњЕФМмЙЙддђвВЭЌбљдкЮвУЧПЊЗЂепдкПЊЗЂКЭЩшМЦШэМўМмЙЙЪБЦ№ЕНЗЧГЃКУЕФжИЕМзїгУЃЌАќРЈЗўЮёЛЏЁЂЕЏадЁЂПЩЙлВьадЁЂШЭадЁЂздЖЏЛЏЁЂСуаХШЮЕШддђЃЌАяжњЮвУЧИќКУЕФНЈЩшЯЕЭГЕФИпПЩгУЛљДЁФмСІЃЌАќРЈЃКДгМмЙЙЩшМЦЩЯЃЌШЭадАќРЈЗўЮёвьВНЛЏФмСІЁЂжиЪд/ЯоСї/НЕМЖ/ШлЖЯ / ЗДбЙЁЂжїДгФЃЪНЁЂМЏШКФЃЪНЁЂAZ ФкЕФИпПЩгУЁЂЕЅдЊЛЏЁЂПч region ШнджЁЂвьЕиЖрЛюШнджЕШЁЃ
iPaaS дкдЦдЩњСьгђЛЙДІдкЫМЫїКЭЬНЫїЕФНзЖЮЃЌБОЮФжЛЪЧЯЃЭћФмЙЛХззЉв§гёЃЌЮФжаВћЪіЕФРэНтКЭЯыЗЈПЩФмДцдкчЂТЉЁЂДэЮѓЃЌвВЯЃЭћЖСепУЧБЇзХПэШнРДдФЖСКЭЛиИДЃЌгаШЮКЮЮЪЬтЁЂНЈвщЧыЛиИДБОЮФЛђЗЂЫЭгЪМўЕН i-paas@jd.comЁЃ
|








