| 编辑推荐: |
本文介绍我们在上云过程中一些实践和经验,以及一些思考和选择。
本文来自于腾讯云原生,由Alice编辑、推荐。 |
|
摘要
医疗资讯业务在高速发展过程中,形成了覆盖不同场景、不同用户、不同渠道的几十个业务,以及上千个服务。为了高效满足用户多样化的需求,腾讯医疗技术团队通过 TKE 上云,使用 Coding DevOps 平台,以及云上可观测技术, 来提升研发效率、降低运营运维成本 。本文介绍我们在上云过程中一些实践和经验,以及一些思考和选择。
业务背景
stage1: 腾讯医疗资讯平台主要包括了医典、医生、医药等核心业务,其中医典主要提供医疗相关内容获取、医疗知识科普传递;医生满足医生和患者的互联;医药服务了广大药企。在业务发展过程中我们原来基于 taf 平台构建了大量后台服务,完成了初期业务的快速搭建。
由于 业务数量较多,大量业务有多地域的述求, 最终我们在 taf 平台部署多个业务集群。这个时候发布、运维、问题排查纯靠人工阶段,效率较低。
业务上云
stage2: 随着业务规模的急速扩张,传统的开发、运维方式在敏捷、资源、效率方面对业务迭代形成较大的制约。随着公司自研上云项目推进, 拥抱云原生化,基于 K8s 来满足业务对不同资源多样化需求和弹性调度,基于现有成熟 devops 平台来进行敏捷迭代,越来越成为业务正确的选择。 医疗后台团队开始了整体服务上云的迁移。
上云之前,还有几个问题需要考虑
-
服务众多,代码如何管理
-
上 云后怎么快速进行问题定位、排查
-
监控告警平台如何选择
-
基础镜像怎么选择
关于服务代码管理
使用 git 做代码版本控制,按业务建立项目组,每个服务使用单独的代码仓库,仓库名使用同一命名规范。
关于问题排查
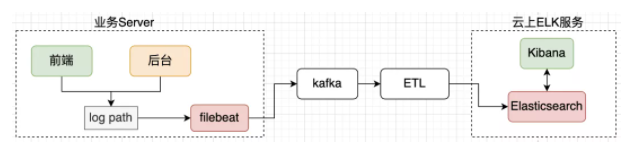
调研云上有成熟的 elk 服务,业务只需要把日志放到同一目录,通过 filebeat 采集后,通过 ETL 逻辑可以把日志方便导入 Elasticsearch。这样的做法还有个优点就是可以 同时支持前后端服务日志的采集 ,技术较为成熟,复用了组件能力,通过在请求中埋点加入 traceid,方便在全链路定位问题。
关于监控告警平台
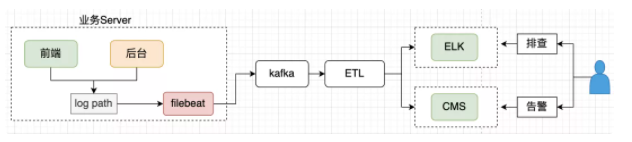
CSIG 提供了基于日志监控的 CMS 平台,将业务日志导入到 CMS 后,可以基于上报的日志配置监控和告警,监控维度、指标业务可以自己定义。我们采用了主调、被调、接口名等维度,调用量、耗时、失败率等指标,满足业务监控告警诉求。 基于日志的监控可以复用同一条数据采集链路,系统架构统一简洁。
关于基础镜像
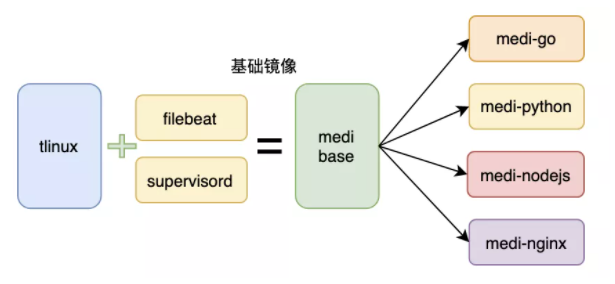
为了方便业务初期快速上云,以及统一服务启动、数据采集上报,有必要对业务的基础镜像进行处理,预先建立对应目录,提供脚本和工具,方便业务快速接入。这里我们提供了不同语言、版本的基础镜像,封装了 supervisord 和 filebeat,通过 supervisord 来拉起 filebeat 和业务服务。
Devops
stage3: 在上云过程中,也通过和质量同学逐步完善,将开发过程中原有人工操作的步骤 pipeline 化,来提高迭代效率,规范开发流程;通过单测和自动化拨测,提升服务稳定性。 采用统一的流水线后,开发、部署效率从原来的小时级别降低到分钟级别。
这里主要使用了 coding 平台,为了区分不同环境,建立了开发、测试、预发布、测试四套不同流水线模板,还引入了合流机制来加入人工 code review 阶段。 在合流阶段: 通过 MR HOOK,自动轮询 code review 结果,确保代码在 review 通过后才能进行下一步(不同团队可能要求不一样)。

在 CI 阶段: 通过代码质量分析,来提升代码规范性,通过单元测试,来保证服务质量。
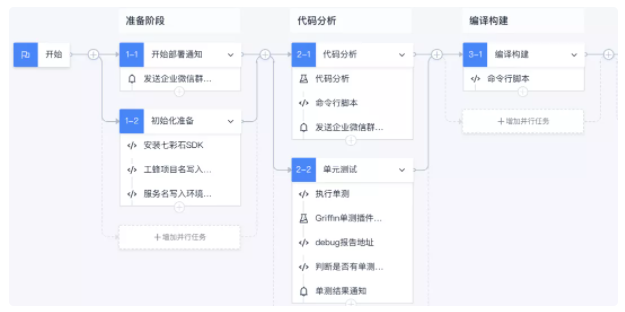
在 CD 阶段: 通过引入人工审批和自动化拨测,提高服务稳定性。

资源利用率提升
stage4: 在业务整体上云后,由于不少业务有多地域部署(广州、南京、天津、香港)的述求,加上每个服务需要四套(开发、测试、预发布、正式)不同的环境,上云后我们初步整理,一共有3000+不同 workload。由于不同业务访问量具有很大不确定性,初期基本上按照理想状态来配置资源,存在不少的浪费。
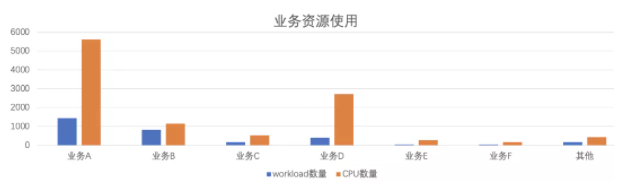
为了提高资源整体利用率,我们进行了一系列优化,大致遵循如下规范:

这里由于 HPA 会导致业务容器动态扩缩,在停止过程中如果原有流量还在访问,或者启动还未完成就导入流量,会导致业务的失败,因此 需要预先开启 TKE 上 preStop 以及就绪检测等配置 。
优雅停止,进程停止前等北极星、cl5 路由缓存过期;入口:tke->工作负载->具体业务->更新工作负载 如果使用的服务发现是 CL5,推荐 preStop70s,北极星配置 10s 足够了。
就绪、存活检测,进程启动完成后再调配流量;入口:tke->工作负载->具体业务->更新工作负载,根据不同业务配置不同探测方式和时间间隔。
通过上面一系列调整优化, 我们的资源利用率大幅提升 ,通过 TKE 上弹性升缩, 在保证业务正常访问同时,局部高峰访问资源不足的问题基本解决,避免了资源浪费,也提升了服务稳定性 ;但多环境问题还是会导致存在一定损耗。
可观测性技术
stage4: 初期使用基于日志的方式来做(log/metric/tracing),满足了业务快速上云、问题排查效率提升的初步述求,但随着业务规模增长,愈加庞大的日志流占用了越来越多的资源,日志堆积在高峰期成为常态, CMS 告警可能和实际发生时已经间隔了半个小时,ELK 的维护成本也急剧上升。 云原生的可观测技术已经成为必要 ,这里我们引入了 Coding 应用管理所推荐的可观测技术方案,通过统一的 coding-sidecar 对业务数据进行采集:
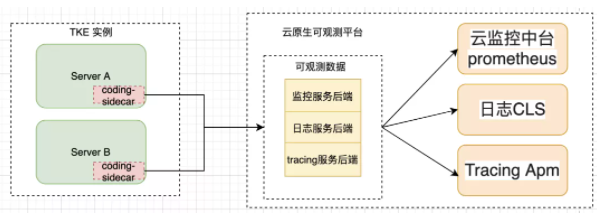
- 监控:云监控中台
- 日志:CLS
- Tracing:APM
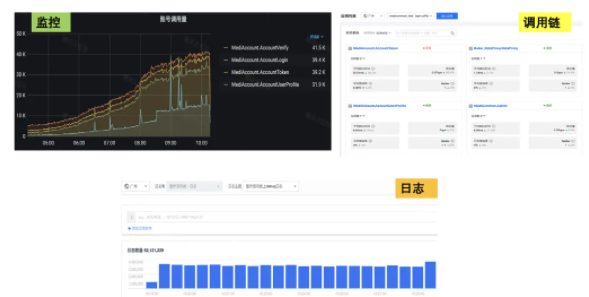
通过接入这些平台的能力,我们的 问题发现、定位、排查效率有了极大的提高,业务的运营维护成本较大降低 。通过监控、和 tracing,也发现了不少系统潜在的问题,提高了服务质量。
结尾
最后,要感谢上云过程中全体开发同学的辛勤付出,以及各位研发 leader 的大力支持。
|








