| ±ајНЖјц: |
±ѕОДїмЛЩґшБм¶БХЯБЛЅв DockerЎўKubernetes µДјЬ№№ЎўФАнЎўЧйјюј°Па№ШК№УГіЎѕ°
Ј¬ПЈНы¶ФДъµДС§П°УРЛщ°пЦъЎЈ
±ѕОДАґЧФУЪМЪС¶јјКх№¤іМЈ¬УЙAlice±ајЎўНЖјцЎЈ |
|
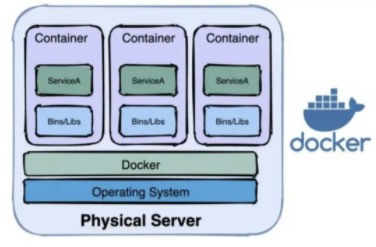
Docker
1.КІГґКЗ Docker
Docker КЗТ»ёцїЄФґµДУ¦УГИЭЖчТэЗжЈ¬КЗТ»ЦЦЧКФґРйДв»ЇјјКхЈ¬ИГїЄ·ўХЯїЙТФґт°ьЛыГЗµДУ¦УГТФј°ТААµ°ьµЅТ»ёцїЙТЖЦІµДИЭЖчЦРЈ¬И»єу·ўІјµЅИОєОБчРРµД Linux »ъЖчЙПЎЈРйДв»ЇјјКхСЭАъВ·ѕ¶їЙ·ЦОЄИэёцК±ґъЈє
- ОпАн»ъК±ґъЈ¬¶аёцУ¦УГіМРтїЙДЬЕЬФЪТ»МЁОпАн»ъЖчЙП

- РйДв»ъК±ґъЈ¬Т»МЁОпАн»ъЖчЖф¶Ї¶аёцРйДв»ъКµАэЈ¬Т»ёцРйДв»ъЕЬ¶аёцУ¦УГіМРт
- ИЭЖч»ЇК±ґъЈ¬Т»МЁОпАн»ъЙПЖф¶Ї¶аёцИЭЖчКµАэЈ¬Т»ёцИЭЖчЕЬ¶аёцУ¦УГіМРт
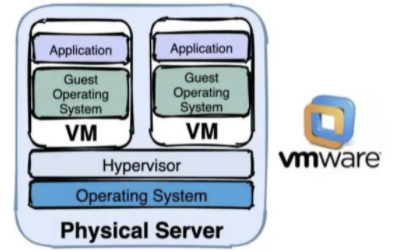
ФЪГ»УР Docker µДК±ґъЈ¬ОТГЗ»бК№УГУІјюРйДв»ЇЈЁРйДв»ъЈ©ТФМṩёфАлЎЈХвАпЈ¬РйДв»ъНЁ№эФЪІЩЧчПµНіЙПЅЁБўБЛТ»ёцЦРјдРйДвИнјюІг Hypervisor Ј¬ІўАыУГОпАн»ъЖчµДЧКФґРйДвіц¶аёцРйДвУІјю»·ѕіАґ№ІПнЛЮЦч»ъµДЧКФґЈ¬ЖдЦРµДУ¦УГФЛРРФЪРйДв»ъДЪєЛЙПЎЈµ«КЗЈ¬РйДв»ъ¶ФУІјюµДАыУГВКґжФЪЖїѕ±Ј¬ТтОЄРйДв»ъєЬДСёщѕЭµ±З°ТµОсБї¶ЇМ¬µчХыЖдХјУГµДУІјюЧКФґЈ¬јУЦ®ИЭЖч»ЇјјКхЕоІЄ·ўХ№К№ЖдµГТФБчРРЎЈ
DockerЎўРйДв»ъ¶Ф±ИЈє
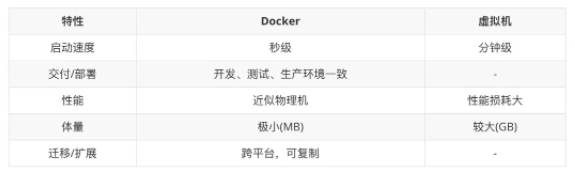
БнНвїЄ·ўИЛФ±ФЪКµјКµД№¤ЧчЦРЈ¬ѕіЈ»бУцµЅІвКФ»·ѕі»тЙъІъ»·ѕіУл±ѕµШїЄ·ў»·ѕіІ»Т»ЦВµДОКМвЈ¬ЗбФтРЮёґ±ЈіЦ»·ѕіТ»ЦВЈ¬ЦШФтїЙДЬРиТЄ·µ№¤ЎЈµ« Docker ЗЎєГЅвѕцБЛХвТ»ОКМвЈ¬ЛьЅ«ИнјюіМРтєНФЛРРµД»щґЎ»·ѕі·ЦїЄЎЈїЄ·ўИЛФ±±аВлНкіЙєуЅ«іМРтХыєП»·ѕіНЁ№э DockerFile ґт°ьµЅТ»ёцИЭЖчѕµПсЦРЈ¬ґУёщ±ѕЙПЅвѕцБЛ»·ѕіІ»Т»ЦВµДОКМвЎЈ
2.Docker µД№№іЙ
Docker УЙѕµПсЎўѕµПсІЦївЎўИЭЖчИэёцІї·ЦЧйіЙ
- ѕµПс: їзЖЅМЁЎўїЙТЖЦІµДіМРт+»·ѕі°ь
- ѕµПсІЦїв: ѕµПсµДґжґўО»ЦГЈ¬УРФЖ¶ЛІЦївєН±ѕµШІЦївЦ®·ЦЈ¬№Щ·ЅѕµПсІЦївµШЦ·ЈЁhttps://hub.docker.com/Ј©
- ИЭЖч: ЅшРРБЛЧКФґёфАлµДѕµПсФЛРРК±»·ѕі
3.Docker µДКµПЦФАн
µЅґЛ¶БХЯГЗїП¶ЁєЬєГЖж Docker КЗИзєОЅшРРЧКФґРйДв»ЇµДЈ¬ІўЗТИзєОКµПЦЧКФґёфАлµДЈ¬ЖдєЛРДјјКхФАнЦчТЄУР(ДЪИЭІї·ЦІОїјЧФ Docker єЛРДјјКхУлКµПЦФАн)Јє
(1).Namespace
ФЪИХіЈК№УГ Linux »тХЯ macOS К±Ј¬ОТГЗІўГ»УРФЛРР¶аёцНкИ«·ЦАлµД·юОсЖчµДРиТЄЈ¬µ«КЗИз№ыОТГЗФЪ·юОсЖчЙПЖф¶ЇБЛ¶аёц·юОсЈ¬ХвР©·юОсЖдКµ»бП໥ӰПмµДЈ¬ГїТ»ёц·юОс¶јДЬїґµЅЖдЛы·юОсµДЅшіМЈ¬ТІїЙТФ·ГОКЛЮЦч»ъЖчЙПµДИОТвОДјюЈ¬ХвКЗєЬ¶аК±єтОТГЗ¶јІ»ФёТвїґµЅµДЈ¬ОТГЗёьПЈНыФЛРРФЪН¬Т»МЁ»ъЖчЙПµДІ»Н¬·юОсДЬЧцµЅНкИ«ёфАлЈ¬ѕНПсФЛРРФЪ¶аМЁІ»Н¬µД»ъЖчЙПТ»СщЎЈ
ГьГыїХјд (Namespaces) КЗ Linux ОЄОТГЗМṩµДУГУЪ·ЦАлЅшіМКчЎўНшВзЅУїЪЎў№ТФШµгТФј°ЅшіМјдНЁРЕµИЧКФґµД·Ѕ·ЁЎЈLinux µДГьГыїХјд»ъЦЖМṩБЛТФПВЖЯЦЦІ»Н¬µДГьГыїХјдЈ¬НЁ№эХвЖЯёцСЎПоОТГЗДЬФЪґґЅЁРВµДЅшіМК±ЙиЦГРВЅшіМУ¦ёГФЪДДР©ЧКФґЙПУлЛЮЦч»ъЖчЅшРРёфАлЎЈ
- CLONE_NEWCGROUP
- CLONE_NEWIPC
- CLONE_NEWNET
- CLONE_NEWNS
- CLONE_NEWPID
- CLONE_NEWUSER
- CLONE_NEWUTS
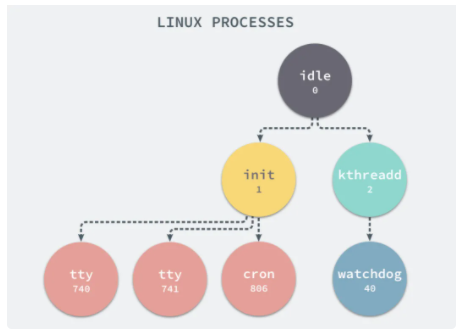
ФЪ Linux ПµНіЦРЈ¬УРБЅёцМШКвµДЅшіМЈ¬Т»ёцКЗ pid ОЄ 1 µД /sbin/init ЅшіМЈ¬БнТ»ёцКЗ pid ОЄ 2 µД kthreadd ЅшіМЈ¬ХвБЅёцЅшіМ¶јКЗ±» Linux ЦРµДЙПµЫЅшіМ idle ґґЅЁіцАґµДЈ¬ЖдЦРЗ°ХЯёєФрЦґРРДЪєЛµДТ»Ії·ЦіхКј»Ї№¤ЧчєНПµНіЕдЦГЈ¬ТІ»бґґЅЁТ»Р©АаЛЖ getty µДЧўІбЅшіМЈ¬¶шєуХЯёєФр№ЬАнєНµч¶ИЖдЛыµДДЪєЛЅшіМЎЈ
µ±ФЪЛЮЦч»ъФЛРР DockerЈ¬НЁ№э docker run »т docker start ґґЅЁРВИЭЖчЅшіМК±Ј¬»бґ«Ил CLONE_NEWPID КµПЦЅшіМЙПµДёфАлЎЈ
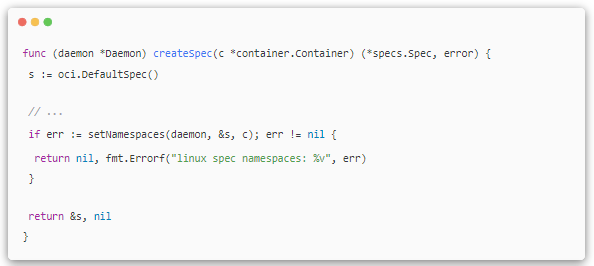
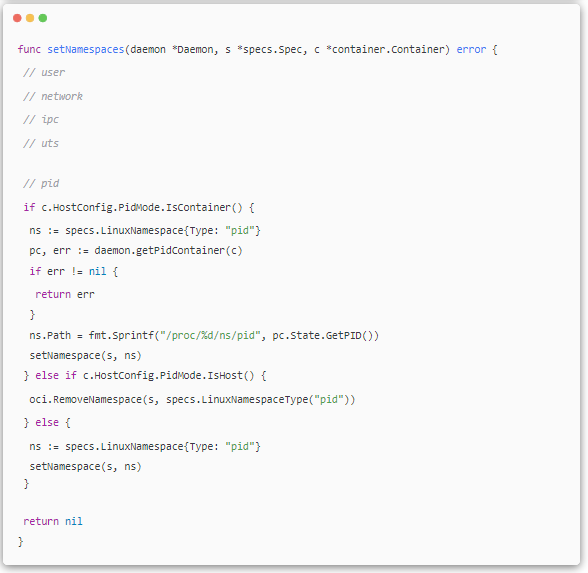
ЅУЧЕЈ¬ФЪ·Ѕ·Ё createSpec µД setNamespaces ЦРЈ¬НкіЙіэЅшіМГьГыїХјдЦ®НвУлУГ»§ЎўНшВзЎўIPC ТФј° UTS Па№ШµДГьГыїХјдµДЙиЦГЎЈ
НшВз
µ± Docker ИЭЖчНкіЙГьГыїХјдµДЙиЦГЈ¬ЖдНшВзТІ±діЙБЛ¶АБўµДГьГыїХјдЈ¬УлЛЮЦч»ъµДНшВ绥БЄ±гІъЙъБЛПЮЦЖЈ¬ХвѕНµјЦВНвІїєЬДС·ГОКµЅИЭЖчДЪµДУ¦УГіМРт·юОсЎЈDocker МṩБЛ 4 ЦЦНшВзДЈКЅЈ¬НЁ№э --net Цё¶ЁЎЈ
- host
- container
- none
- bridge
УЙУЪєуРшЅйЙЬ Kubernetes АыУГБЛ Docker µД bridge НшВзДЈКЅЈ¬ЛщТФЅцЅйЙЬёГДЈКЅЎЈLinux ЦРОЄБЛ·Ѕ±гёчНшВзГьГыїХјдµДНшВ绥Па·ГОКЈ¬ЙиЦГБЛ Veth Pair єННшЗЕАґКµПЦЈ¬Docker ТІКЗ»щУЪґЛ·ЅКЅКµПЦБЛНшВзНЁРЕЎЈ
ПВНјЦР eth0 Ул veth9953b75 КЗТ»ёц Veth PairЈ¬ eth0 Ул veth3e84d4f ОЄБнТ»ёц Veth PairЎЈVeth Pair ФЪИЭЖчДЪТ»Іа»б±»ЙиЦГОЄ eth0 ДЈДвНшїЁЈ¬БнТ»ІаБ¬ЅУ Docker0 НшЗЕЈ¬ХвСщѕНКµПЦБЛІ»Н¬ИЭЖчјдНшВзµД»ҐНЁЎЈјУЦ® Docker0 ОЄГїёцИЭЖчЕдЦГµД iptables №жФтЈ¬УЦКµПЦБЛУлЛЮЦч»ъНвІїНшВзµД»ҐНЁЎЈ
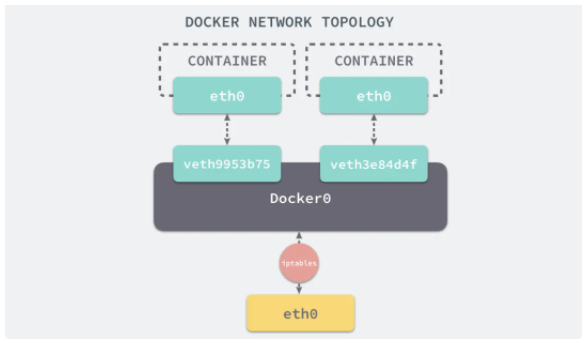
№ТФШµг
ЅвѕцБЛЅшіМєННшВзёфАлµДОКМвЈ¬µ«КЗ Docker ИЭЖчЦРµДЅшіМИФИ»ДЬ№»·ГОК»тХЯРЮёДЛЮЦч»ъЖчЙПµДЖдЛыДїВјЈ¬ХвКЗОТГЗІ»ПЈНыїґµЅµДЎЈ
ФЪРВµДЅшіМЦРґґЅЁёфАлµД№ТФШµгГьГыїХјдРиТЄФЪ clone єЇКэЦРґ«Ил CLONE_NEWNSЈ¬ХвСщЧУЅшіМѕНДЬµГµЅёёЅшіМ№ТФШµгµДїЅ±ґЈ¬Из№ыІ»ґ«ИлХвёцІОКэЧУЅшіМ¶ФОДјюПµНіµД¶БРґ¶ј»бН¬ІЅ»ШёёЅшіМТФј°ХыёцЦч»ъµДОДјюПµНіЎЈµ±Т»ёцИЭЖчРиТЄЖф¶ЇК±Ј¬ЛьТ»¶ЁРиТЄМṩһёцёщОДјюПµНіЈЁrootfsЈ©Ј¬ИЭЖчРиТЄК№УГХвёцОДјюПµНіАґґґЅЁТ»ёцРВµДЅшіМЈ¬ЛщУР¶юЅшЦЖµДЦґРР¶ј±ШРлФЪХвёцёщОДјюПµНіЦРЈ¬ІўЅЁБўТ»Р©·ыєЕБґЅУАґ±ЈЦ¤ IO І»»біцПЦОКМвЎЈ
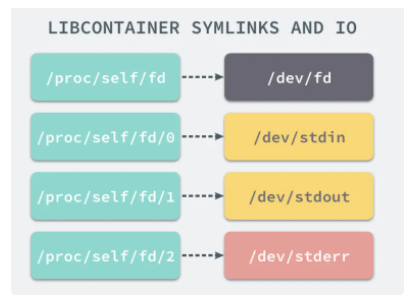
БнНвЈ¬НЁ№э Linux µД chroot ГьБоДЬ№»ёД±дµ±З°µДПµНіёщДїВјЅб№№Ј¬НЁ№эёД±дµ±З°ПµНіµДёщДїВјЈ¬ОТГЗДЬ№»ПЮЦЖУГ»§µДИЁАыЈ¬ФЪРВµДёщДїВјПВІўІ»ДЬ№»·ГОКѕЙПµНіёщДїВјµДЅб№№ёцОДјюЈ¬ТІѕНЅЁБўБЛТ»ёцУлФПµНіНкИ«ёфАлµДДїВјЅб№№ЎЈ
(2).Control Groups(CGroups)
Control Groups(CGroups) МṩБЛЛЮЦч»ъЙПОпАнЧКФґµДёфАлЈ¬АэИз CPUЎўДЪґжЎўґЕЕМ I/O єННшВзґшїнЎЈЦчТЄУЙХвјёёцЧйјю№№іЙЈє
- їШЦЖЧйЈЁCGroupЈ© Т»ёц CGroup °ьє¬Т»ЧйЅшіМЈ¬ІўїЙТФФЪХвёц CGroup ЙПФцјУ Linux Subsystem µДёчЦЦІОКэЕдЦГЈ¬Ѕ«Т»ЧйЅшіМєНТ»Чй Subsystem №ШБЄЖрАґЎЈ
- Subsystem ЧУПµНі КЗТ»ЧйЧКФґїШЦЖДЈїйЈ¬±ИИз CPU ЧУПµНіїЙТФїШЦЖ CPU К±јд·ЦЕдЈ¬ДЪґжЧУПµНіїЙТФПЮЦЖ CGroup ДЪґжК№УГБїЎЈїЙТФНЁ№э lssubsys -a ГьБоІйїґµ±З°ДЪєЛЦ§іЦДДР© SubsystemЎЈ
- Hierarchy Ігј¶Кч ЦчТЄ№¦ДЬКЗ°С CGroup ґ®іЙТ»ёцКчРНЅб№№Ј¬К№ CGruop їЙТФЧцµЅјМіРЈ¬Гїёц Hierarchy НЁ№э°у¶Ё¶ФУ¦µД Subsystem ЅшРРЧКФґµч¶ИЎЈ
- Task ФЪ CGroups ЦРЈ¬task ѕНКЗПµНіµДТ»ёцЅшіМЎЈТ»ёцИООсїЙТФјУИлДіёц CGroupЈ¬ТІїЙТФґУДіёц CGroup ЗЁТЖµЅБнНвТ»ёц CGroupЎЈ
ФЪ Linux µД Docker °ІЧ°ДїВјПВУРТ»ёц docker ДїВјЈ¬µ±Жф¶ЇТ»ёцИЭЖчК±Ј¬ѕН»бґґЅЁТ»ёцУлИЭЖч±кК¶·ыПаН¬µД CGroupЈ¬ѕЩАэАґЛµµ±З°µДЦч»ъѕН»бУРТФПВІгј¶№ШПµЈє
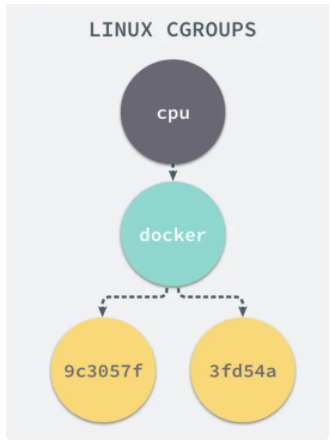
ГїТ»ёц CGroup ПВГж¶јУРТ»ёц tasks ОДјюЈ¬ЖдЦРґжґўЧЕКфУЪµ±З°їШЦЖЧйµДЛщУРЅшіМµД pidЈ¬ЧчОЄёєФр cpu µДЧУПµНіЈ¬cpu.cfs_quota_us ОДјюЦРµДДЪИЭДЬ№»¶Ф CPU µДК№УГЧчіцПЮЦЖЈ¬Из№ыµ±З°ОДјюµДДЪИЭОЄ 50000Ј¬ДЗГґµ±З°їШЦЖЧйЦРµДИ«ІїЅшіМµД CPU ХјУГВКІ»ДЬі¬№э 50%ЎЈ
µ±ОТГЗК№УГ Docker №Ш±ХµфХэФЪФЛРРµДИЭЖчК±Ј¬Docker µДЧУїШЦЖЧй¶ФУ¦µДОДјюјРТІ»б±» Docker ЅшіМТЖіэЎЈ
(3).UnionFS
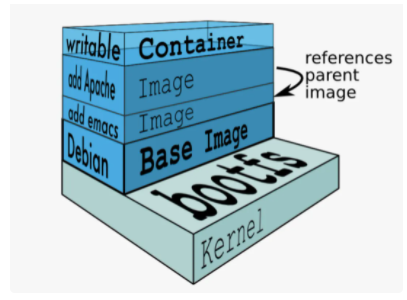
БЄєПОДјюПµНі(Union File System)Ј¬ЛьїЙТФ°С¶аёцДїВјДЪИЭБЄєП№ТФШµЅН¬Т»ёцДїВјПВЈ¬¶шДїВјµДОпАнО»ЦГКЗ·ЦїЄµДЎЈUnionFS їЙТФ°СЦ»¶БєНїЙ¶БРґОДјюПµНієПІўФЪТ»ЖрЈ¬ѕЯУРРґК±ёґЦЖ№¦ДЬЈ¬ФКРнЦ»¶БОДјюПµНіµДРЮёДїЙТФ±ЈґжµЅїЙРґОДјюПµНіµ±ЦРЎЈDocker Ц®З°К№УГµДОЄ AUFS(Advanced UnionFS)Ј¬ПЦОЄ Overlay2ЎЈ
Docker ЦРµДГїТ»ёцѕµПс¶јКЗУЙТ»ПµБРЦ»¶БµДІгЧйіЙµДЈ¬Dockerfile ЦРµДГїТ»ёцГьБо¶ј»бФЪТСУРµДЦ»¶БІгЙПґґЅЁТ»ёцРВµДІгЈє

ИЭЖчЦРµДГїТ»Іг¶јЦ»¶Фµ±З°ИЭЖчЅшРРБЛ·ЗіЈРЎµДРЮёДЈ¬ЙПКцµД Dockerfile ОДјю»б№№ЅЁТ»ёцУµУРЛДІг layer µДѕµПсЈє
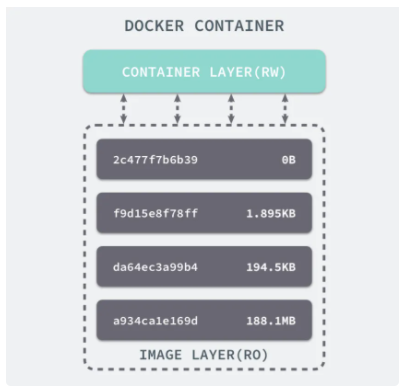
µ±ѕµПс±» ГьБоґґЅЁК±ѕН»бФЪѕµПсµДЧоЙПІгМнјУТ»ёцїЙРґµДІгЈ¬ТІѕНКЗИЭЖчІгЈ¬ЛщУР¶ФУЪФЛРРК±ИЭЖчµДРЮёДЖдКµ¶јКЗ¶ФХвёцИЭЖч¶БРґІгµДРЮёДЎЈИЭЖчєНѕµПсµДЗш±рѕНФЪУЪЈ¬ЛщУРµДѕµПс¶јКЗЦ»¶БµДЈ¬¶шГїТ»ёцИЭЖчЖдКµµИУЪѕµПсјУЙПТ»ёцїЙ¶БРґµДІгЈ¬ТІѕНКЗН¬Т»ёцѕµПсїЙТФ¶ФУ¦¶аёцИЭЖчЎЈ
Kubernetes
KubernetesЈ¬јтіЖ K8sЈ¬ЖдЦР 8 ґъЦёЦРјдµД 8 ёцЧЦ·ыЎЈKubernetes ПоДїЕУґуёґФУЈ¬ОДХВІ»ДЬГжГжѕгµЅЈ¬ТтґЛХвёцІї·ЦЅ«Пт¶БХЯМṩһЦЦЦчПЯС§П°ЛјВ·Јє
- КІГґКЗ KubernetesЈї
- Kubernetes МṩµДЧйјюј°ККУГіЎѕ°
- Kubernetes µДјЬ№№
- Kubernetes јЬ№№ДЈїйКµПЦФАн
УРёь¶аОґЅ»ґъ»тЗііўйьЦ№µДµШ·Ѕ¶БХЯїЙТФІйФДОДХВ»тКйј®ЙоИлСРѕїЎЈ
1.ОЄКІГґТЄ Kubernetes
ѕЎ№Ь Docker ОЄИЭЖч»ЇµДУ¦УГіМРтМṩБЛїЄ·Е±кЧјЈ¬µ«ЛжЧЕИЭЖчФЅАґФЅ¶аіцПЦБЛТ»ПµБРРВОКМвЈє
- µҐ»ъІ»ЧгТФЦ§іЦёь¶аµДИЭЖч
- ·ЦІјКЅ»·ѕіПВИЭЖчИзєОНЁРЕЈї
- ИзєОРµчєНµч¶ИХвР©ИЭЖчЈї
- ИзєОФЪЙэј¶У¦УГіМРтК±І»»бЦР¶П·юОсЈї
- ИзєОјаКУУ¦УГіМРтµДФЛРРЧґїцЈї
- ИзєОЕъБїЦШРВЖф¶ЇИЭЖчАпµДіМРтЈї
- ...
Kubernetes У¦ФЛ¶шЙъЎЈ
2.КІГґКЗ Kubernetes
Kubernetes КЗТ»ёцИ«РВµД»щУЪИЭЖчјјКхµД·ЦІјКЅјЬ№№·Ѕ°ёЈ¬Хвёц·Ѕ°ёЛдИ»»№єЬРВЈ¬µ«ИґКЗ Google К®јёДкАґґу№жДЈУ¦УГИЭЖчјјКхµДѕСй»эАЫєНЙэ»ЄµДЦШТЄіЙ№ыЈ¬И·ЗРµДЛµКЗ Google Т»ёцѕГёєКўГыµДДЪІїК№УГµДґу№жДЈјЇИє№ЬАнПµНіЎЄЎЄBorg µДїЄФґ°ж±ѕЈ¬ЖдДїµДКЗКµПЦЧКФґ№ЬАнµДЧФ¶Ї»ЇТФј°їзКэѕЭЦРРДµДЧКФґАыУГВКЧоґу»ЇЎЈ
Kubernetes ѕЯУРНк±ёµДјЇИє№ЬАнДЬБ¦Ј¬°ьАЁ¶аІгґОµД°ІИ«·А»¤єНЧјИл»ъЦЖЎў¶аЧ⻧ӦУГЦ§іЕДЬБ¦ЎўНёГчµД·юОсЧўІбєН·юОс·ўПЦ»ъЦЖЎўДЪЅЁµДЦЗДЬёєФШѕщєвЖчЎўЗїґуµД№КХП·ўПЦєНЧФОТРЮёґДЬБ¦Ўў·юОс№ц¶ЇЙэј¶єНФЪПЯА©ИЭДЬБ¦ЎўїЙА©Х№µДЧКФґЧФ¶Їµч¶И»ъЦЖЈ¬ТФј°¶аБ¦¶ИµДЧКФґЕд¶о№ЬАнДЬБ¦ЎЈН¬К±Ј¬Kubernetes МṩБЛНкЙЖµД№ЬАн№¤ѕЯЈ¬ХвР©№¤ѕЯєёЗБЛ°ьАЁїЄ·ўЎўІїКрІвКФЎўФЛО¬јаїШФЪДЪµДёчёц»·ЅЪЈ¬І»ЅцКЗТ»ёцИ«РВµД»щУЪИЭЖчјјКхµД·ЦІјКЅјЬ№№Ѕвѕц·Ѕ°ёЈ¬»№КЗТ»ёцТ»ХѕКЅµДНк±ё·ЦІјКЅПµНіїЄ·ўєНЦ§іЕЖЅМЁЎЈ
3.Kubernetes КхУп
(1).Pod
Pod КЗ Kubernetes ЧоЦШТЄµД»щ±ѕёЕДоЈ¬їЙУЙ¶аёцИЭЖчЈЁТ»°г¶шСФТ»ёцИЭЖчТ»ёцЅшіМЈ¬І»ЅЁТйТ»ёцИЭЖч¶аёцЅшіМЈ©ЧйіЙЈ¬ЛьКЗПµНіЦРЧКФґ·ЦЕдєНµч¶ИµДЧоРЎµҐО»ЎЈПВНјКЗ Pod µДЧйіЙКѕТвНјЈ¬ЖдЦРУРТ»ёцМШКвµД Pause ИЭЖч:
Pause ИЭЖчµДЧґМ¬±кК¶БЛТ»ёц Pod µДЧґМ¬Ј¬ТІѕНКЗґъ±нБЛ Pod µДЙъГьЦЬЖЪЎЈБнНв Pod ЦРЖдУаИЭЖч№ІПн Pause ИЭЖчµДГьГыїХјдЈ¬К№µГ Pod ДЪµДИЭЖчДЬ№»№ІПн Pause ИЭЖчµД IPЈ¬ТФј°КµПЦОДјю№ІПнЎЈТФПВКЗТ»ёц Pod µД¶ЁТеЈє
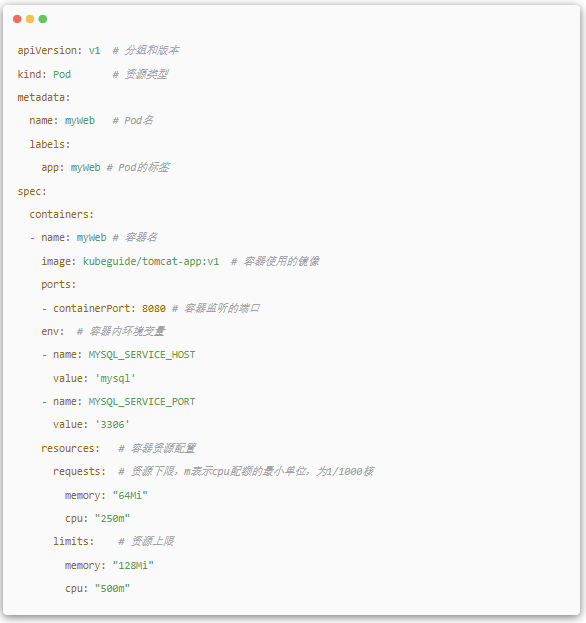
EndPoint : PodIP + containerPortЈ¬ґъ±нТ»ёц·юОсЅшіМµД¶ФНвНЁРЕµШЦ·ЎЈТ»ёц Pod ТІґжФЪѕЯУР¶аёц Endpoint µДЗй їцЈ¬±ИИзµ±ОТГЗ°С Tomcat ¶ЁТеОЄТ»ёц Pod К±Ј¬їЙТФ¶ФНⱩ¶№ЬАн¶ЛїЪУл·юОс¶ЛїЪХвБЅёц EndpointЎЈ
(2).Label
Label КЗ Kubernetes ПµНіЦРµДТ»ёцєЛРДёЕДоЈ¬Т»ёц Label ±нКѕТ»ёц key=value µДјьЦµ¶ФЈ¬keyЎўvalue µДЦµУЙУГ»§Цё¶ЁЎЈLabel їЙТФ±»ёЅјУµЅёчЦЦЧКФґ¶ФПуЙПЈ¬АэИз NodeЎўPodЎўServiceЎўRC µИЈ¬Т»ёцЧКФґ¶Ф ПуїЙТФ¶ЁТеИОТвКэБїµД LabelЈ¬Н¬Т»ёц Label ТІїЙТФ±»МнјУµЅИОТвКэБїµДЧКФґ¶ФПуЙПЎЈLabel НЁіЈФЪЧКФґ¶ФПу¶ЁТеК±И·¶ЁЈ¬ТІїЙТФФЪ¶ФПуґґЅЁєу¶ЇМ¬МнјУ»тХЯЙѕіэЎЈёшТ»ёцЧКФґ¶ФПу¶ЁТеБЛ Label єуЈ¬ОТГЗЛжєуїЙТФНЁ№э Label Selector ІйСЇєНЙёСЎУµУРХвёц Label µДЧКФґ¶ФПуЈ¬АґКµПЦ¶аО¬¶ИµДЧКФґ·ЦЧй№ЬАн№¦ДЬЈ¬ТФ±гБй»оЎў·Ѕ±гµШЅшРРЧКФґ·ЦЕдЎўµч ¶ИЎўЕдЦГЎўІїКрµИ№ЬАн№¤ЧчЎЈ
Label Selector µ±З°УРБЅЦЦ±нґпКЅЈ¬»щУЪµИКЅµДєН»щУЪјЇєПµД:
- name=redis-slave : ЖҐЕдЛщУРѕЯУР±кЗ© name=redis-slave µДЧКФґ¶ФПуЎЈ
- env!=production : ЖҐЕдЛщУРІ»ѕЯУР±кЗ© env=production µДЧКФґ¶ФПуЎЈ
- name in(redis-master, redis-slave) : name=redis-master »тХЯ name=redis-slave µДЧКФґ¶ФПуЎЈ
- name not in(php-frontend) :ЖҐЕдЛщУРІ»ѕЯУР±кЗ© name=php-frontend µДЧКФґ¶ФПуЎЈ
ТФ myWeb Pod ОЄАэ:

µ±Т»ёц Service µД selector ЦРЦёГчБЛХвёц Pod К±Ј¬ёГ Pod ѕН»бУлёГ Service °у¶Ё

(3).Replication Controller
Replication ControllerЈ¬јтіЖ RCЈ¬јтµҐАґЛµЈ¬ЛьЖдКµ¶ЁТеБЛТ»ёцЖЪНыµДіЎѕ°Ј¬јґЙщГчДіЦЦ Pod µДё±±ѕКэБїФЪИОТвК±їМ¶ј·ыєПДіёцФ¤ЖЪЦµЎЈ
RC µД¶ЁТе°ьАЁИзПВјёёцІї·ЦЈє
- Pod ЖЪґэµДё±±ѕКэБї
- УГУЪЙёСЎДї±к Pod µД Label Selector
- µ± Pod µДё±±ѕКэРЎУЪФ¤ЖЪКэБїК±Ј¬УГУЪґґЅЁРВ Pod µДДЈ°ж(template)
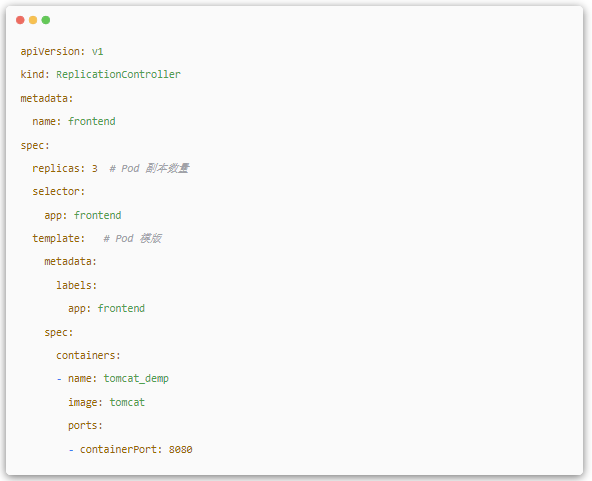
µ±МбЅ»Хвёц RC ФЪјЇИєЦРєуЈ¬Controller Manager »б¶ЁЖЪСІјмЈ¬И·±ЈДї±к Pod КµАэµДКэБїµИУЪ RC µДФ¤ЖЪЦµЈ¬№э¶аµДКэБї»б±»НЈµфЈ¬ЙЩБЛФт»бґґЅЁІ№ідЎЈНЁ№э kubectl scale їЙТФ¶ЇМ¬Цё¶Ё RC µДФ¤ЖЪё±±ѕКэБїЎЈ
ДїЗ°Ј¬RC ТСЙэј¶ОЄРВёЕДоЎЄЎЄReplica Set(RS)Ј¬БЅХЯµ±З°ОЁТ»Зш±рКЗЈ¬RS Ц§іЦБЛ»щУЪјЇєПµД Label SelectorЈ¬¶ш RC Ц»Ц§іЦ»щУЪµИКЅµД Label SelectorЎЈRS єЬЙЩµҐ¶АК№УГЈ¬ёь¶аКЗ±» Deployment ХвёцёьёЯІгµДЧКФґ¶ФПуЛщК№УГЈ¬ЛщТФїЙТФКУЧч RS+Deployment Ѕ«ЦрЅҐИЎґъ RC µДЧчУГЎЈ
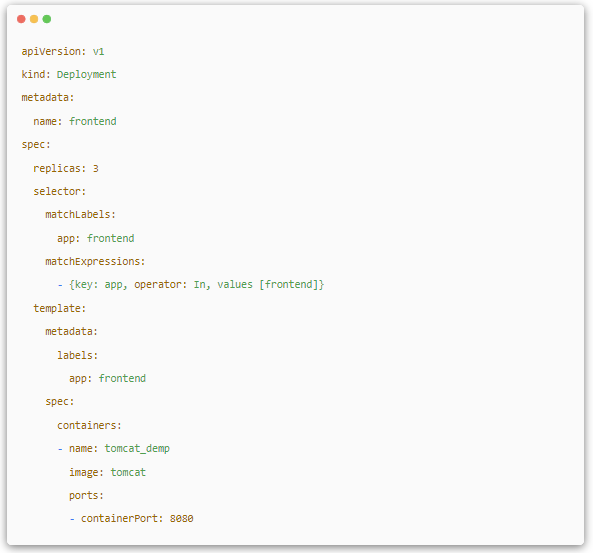
(4).Deployment
Deployment єН RC ПаЛЖ¶Иі¬№э 90%Ј¬ОЮВЫКЗЧчУГЎўДїµДЎўYaml ¶ЁТе»№КЗѕЯМеГьБоРРІЩЧчЈ¬ЛщТФїЙТФЅ«ЖдїґЧчКЗ RC µДЙэј¶ЎЈ¶ш Deployment Па¶ФУЪ RC µДТ»ёцЧоґуЗш±рКЗОТГЗїЙТФЛжК±ЦЄµАµ±З° PodЎ°ІїКрЎ±µДЅш¶ИЎЈКµјКЙПУЙУЪТ»ёц Pod µДґґЅЁЎўµч¶ИЎў°у¶ЁЅЪµгј°ФЪДї ±к Node ЙПЖф¶Ї¶ФУ¦µДИЭЖчХвТ»НкХы№эіМРиТЄТ»¶ЁµДК±јдЈ¬ЛщТФОТГЗЖЪґэПµНіЖф¶Ї N ёц Pod ё±±ѕµДДї±кЧґМ¬Ј¬КµјКЙПКЗТ»ёцБ¬Рш±д»ЇµДЎ°ІїКр№эіМЎ±µјЦВµДЧоЦХЧґМ¬ЎЈ
(5).Horizontal Pod Autoscaler
іэБЛКЦ¶ЇЦґРР kubectl scale НкіЙ Pod µДА©ЛхИЭЦ®НвЈ¬»№їЙТФНЁ№э Horizontal Pod Autoscaling(HPA)єбПтЧФ¶ЇА©ИЭАґЅшРРЧФ¶ЇА©ЛхИЭЎЈЖдФАнКЗЧ·ЧЩ·ЦОцДї±к Pod µДёєФШ±д»ЇЗйїцЈ¬АґИ·¶ЁКЗ·сРиТЄХл¶ФРФµШµчХыДї±к Pod КэБїЎЈµ±З°Ј¬HPA УРТ»ПВБЅЦЦ·ЅКЅЧчОЄ Pod ёєФШµД¶ИБїЦё±кЈє
- CPUUtilizationPercentageЈ¬Дї±к Pod ЛщУРё±±ѕЧФЙнµД CPU АыУГВКµДЖЅѕщЦµЎЈ
- У¦УГіМРтЧФ¶ЁТеµД¶ИБїЦё±кЈ¬±ИИз·юОсФЪГїГлДЪµДПаУ¦ЗлЗуКэ(TPS »т QPS)
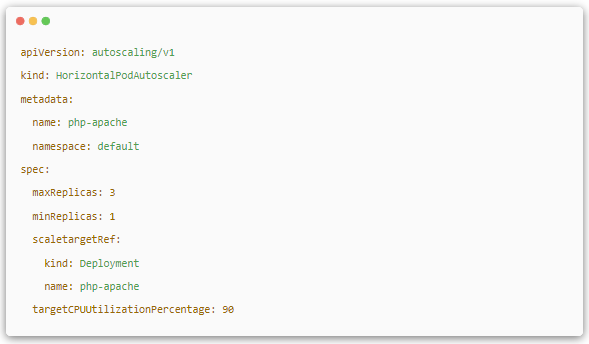
ёщѕЭЙП±Я¶ЁТеЈ¬µ± Pod ё±±ѕµД CPUUtilizationPercentage і¬№э 90%К±ѕН»біц·ўЧФ¶ЇА©ИЭРРОЄЈ¬КэБїФјКшОЄ 1 Ў« 3 ёцЎЈ
(6).StatefulSet
ФЪ Kubernetes ПµНіЦРЈ¬Pod µД№ЬАн¶ФПу RCЎўDeploymentЎўDaemonSet єН Job ¶јГжПтОЮЧґМ¬µД·юОсЎЈµ«ПЦКµЦРУРєЬ¶а·юОсКЗУРЧґМ¬µДЈ¬МШ±рКЗ Т»Р©ёґФУµДЦРјдјюјЇИєЈ¬АэИз MySQL јЇИєЎўMongoDB јЇИєЎўAkka јЇ ИєЎўZooKeeper јЇИєµИЈ¬ХвР©У¦УГјЇИєУР 4 ёц№ІН¬µгЎЈ
- ГїёцЅЪµг¶јУР№М¶ЁµДЙн·Э IDЈ¬НЁ№эХвёц IDЈ¬јЇИєЦРµДіЙФ±їЙ ТФП໥·ўПЦІўНЁРЕЎЈ
- јЇИєµД№жДЈКЗ±ИЅП№М¶ЁµДЈ¬јЇИє№жДЈІ»ДЬЛжТв±д¶ЇЎЈ
- јЇИєЦРµДГїёцЅЪµг¶јКЗУРЧґМ¬µДЈ¬НЁіЈ»біЦѕГ»ЇКэѕЭµЅУАѕГ ґжґўЦРЎЈ
- Из№ыґЕЕМЛр»µЈ¬ФтјЇИєАпµДДіёцЅЪµгОЮ·ЁХэіЈФЛРРЈ¬јЇИє№¦ ДЬКЬЛрЎЈ
ТтґЛЈ¬StatefulSet ѕЯУРТФПВМШµгЈє
(7).Service
Service ФЪ Kubernetes ЦР¶ЁТеБЛТ»ёц·юОсµД·ГОКИлїЪµШЦ·Ј¬З°¶ОµДУ¦УГЈЁPodЈ©НЁ№эХвёцИлїЪµШЦ··ГОКЖд±ієуµДТ»ЧйУЙ Pod ё±±ѕЧйіЙµДјЇИєКµАэЈ¬Service УлЖдєу¶Л Pod ё±±ѕјЇИєЦ®јдФтКЗНЁ№э Label Selector АґКµПЦОЮ·м¶ФЅУµДЎЈ
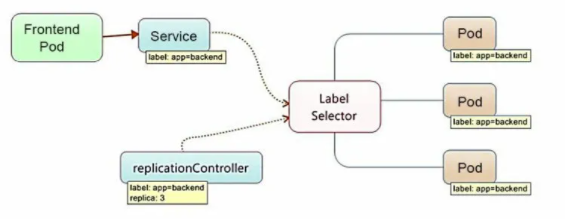
Service µДёєФШѕщєв
ФЪ Kubernetes јЇИєЦРЈ¬Гїёц Node ЙП»бФЛРРЧЕ kube-proxy ЧйјюЈ¬ХвЖдКµѕНКЗТ»ёцёєФШѕщєвЖчЈ¬ёєФр°С¶Ф Service µДЗлЗуЧЄ·ўµЅєу¶ЛµДДіёц Pod КµАэЙПЈ¬ІўФЪДЪІїКµПЦ·юОсµДёєФШѕщєвєН»ж»±ЈіЦ»ъЦЖЎЈЖдЦчТЄµДКµПЦѕНКЗГїёц Service ФЪјЇИєЦР¶ј±»·ЦЕдБЛТ»ёцИ«ѕЦОЁТ»µД Cluster IPЈ¬ТтґЛОТГЗ¶Ф Service µДНшВзНЁРЕёщѕЭДЪІїµДёєФШѕщєвЛг·ЁєН»б»°»ъЦЖЈ¬±гДЬУл Pod ё±±ѕјЇИєНЁРЕЎЈ
Service µД·юОс·ўПЦ
ТтОЄ Cluster IP ФЪ Service µДХыёцЙщГчЦЬЖЪДЪКЗ№М¶ЁµДЈ¬ЛщТФФЪ Kubernetes ЦРЈ¬Ц»РиЅ« Service µД Name єН Жд Cluster IP ЧцТ»ёц DNS УтГыУіЙдјґїЙЅвѕцЎЈ
(8).Volume
Volume КЗ Pod ЦРДЬ№»±»¶аёцИЭЖч·ГОКµД№ІПнДїВјЈ¬Kubernetes ЦРµД Volume ёЕДоЎўУГНѕЎўДїµДУл Docker ЦРµД Volumn ±ИЅПАаЛЖЈ¬µ«І»µИјЫЎЈКЧПИЈ¬ЖдїЙ±»¶ЁТеФЪ Pod ЙПЈ¬И»єу±» Т»ёц Pod АпµД¶аёцИЭЖч№ТФШµЅѕЯМеµДОДјюДїВјПВЈ»ЖдґОЈ¬Kubernetes ЦРµД Volume Ул Pod µДЙъГьЦЬЖЪПаН¬Ј¬µ«УлИЭЖчµДЙъГьЦЬЖЪІ»Па№ШЈ¬µ±ИЭЖчЦХЦ№»тХЯЦШЖфК±Ј¬Volume ЦРµДКэѕЭТІІ»»б¶ЄК§ЎЈ
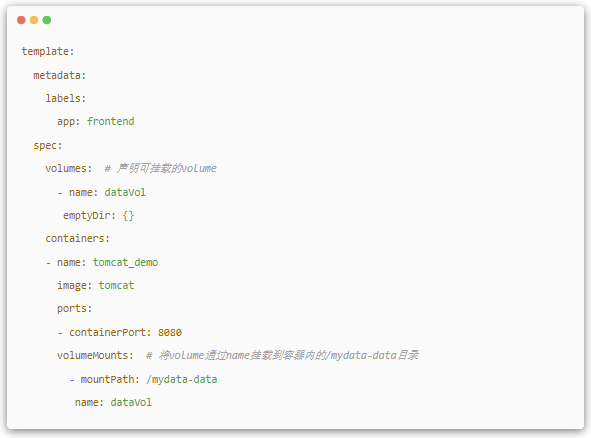
Kubernetes МṩБЛ·ЗіЈ·бё»µД Volume АаРН:
- emptyDirЈ¬ЛьµДіхКјДЪИЭОЄїХЈ¬ІўЗТОЮРлЦё¶ЁЛЮЦч»ъЙП¶ФУ¦µДДїВјОДјюЈ¬ТтОЄХвКЗ Kubernetes ЧФ¶Ї·ЦЕдµДТ»ёцДїВјЈ¬µ± Pod ґУ Node ЙПТЖіэ emptyDir ЦРµДКэѕЭТІ»б±»УАѕГЙѕіэЈ¬ККУГУЪБЩК±КэѕЭЎЈ
- hostPathЈ¬hostPath ОЄФЪ Pod ЙП№ТФШЛЮЦч»ъЙПµДОДјю»тДїВјЈ¬ККУГУЪіЦѕГ»Ї±ЈґжµДКэѕЭЈ¬±ИИзИЭЖчУ¦УГіМРтЙъіЙµДИХЦѕОДјюЎЈ
- NFSЈ¬їЙК№УГ NFS НшВзОДјюПµНіМṩµД№ІПнДїВјґжґўКэѕЭЎЈ
- ЖдЛыФЖіЦѕГ»ЇЕМµИ
(9).Persistent Volume
ФЪК№УГРйДв»ъµДЗйїцПВЈ¬ОТГЗНЁіЈ»бПИ¶ЁТеТ»ёцНшВзґжґўЈ¬И»єуґУЦР »®іцТ»ёцЎ°НшЕМЎ±Іў№ТЅУµЅРйДв»ъЙПЎЈPersistent Volume(PV) єНУлЦ®Па№ШБЄµД Persistent Volume Claim(PVC) ТІЖрµЅБЛАаЛЖµДЧчУГЎЈPV їЙТФ±»АнЅвіЙ Kubernetes јЇИєЦРµДДіёцНшВзґжґў¶ФУ¦µДТ»їйґжґўЈ¬ЛьУл Volume АаЛЖЈ¬µ«УРТФПВЗш±р:
- PV Ц»ДЬКЗНшВзґжґўЈ¬І»КфУЪИОєО NodeЈ¬µ«їЙТФФЪГїёц Node ЙП·ГОКЎЈ
- PV ІўІ»КЗ±»¶ЁТеФЪ Pod ЙПµДЈ¬¶шКЗ¶АБўУЪ Pod Ц®Нв¶ЁТеµДЎЈ
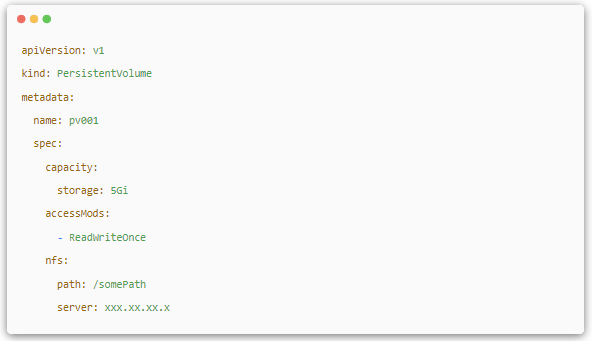
accessModesЈ¬УРјёЦЦАаРНЈ¬1.ReadWriteOnce:¶БРґИЁПЮЈ¬ІўЗТЦ»ДЬ±»µҐёц Node №ТФШЎЈ2. ReadOnlyMany:Ц»¶БИЁПЮЈ¬ФКРн±»¶аёц Node №ТФШЎЈ 3.ReadWriteMany:¶БРґИЁПЮЈ¬ФКРн±»¶аёц Node №ТФШЎЈ
Из№ы Pod ПлЙкЗлДіЦЦАаРНµД PVЈ¬КЧПИРиТЄ¶ЁТеТ»ёц PersistentVolumeClaim ¶ФПуЈ¬
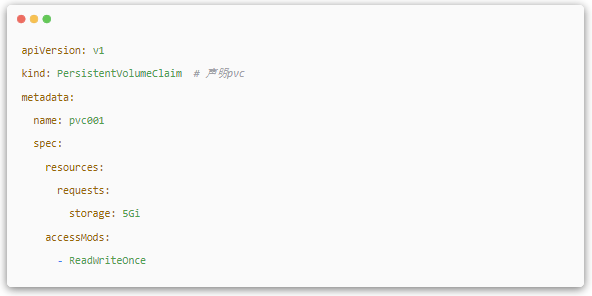
И»єуФЪ Pod µД Volume ЦРТэУГ PVC јґїЙЎЈ

PV УРТФПВјёЦЦЧґМ¬Јє
- AvailableЈєїХПР
- BoundЈєТС°у¶ЁµЅ PVC
- ReleadЈє¶ФУ¦ PVC ±»ЙѕіэЈ¬µ« PV »№Г»±»»ШКХ
- FaildЈєPV ЧФ¶Ї»ШКХК§°Ь
(10).Namespace
Namespace ФЪєЬ¶аЗйїцПВУГУЪКµПЦ¶аЧ⻧µДЧКФґёфАлЎЈ·ЦЧйµДІ»Н¬ПоДїЎўРЎЧй»тУГ»§ЧйЈ¬±гУЪІ»Н¬µД·ЦЧйФЪ№ІПнК№УГХыёцјЇИєµДЧКФґµДН¬К±»№ДЬ±»·Ц±р№ЬАнЎЈKubernetes јЇИєФЪЖф¶Їєу»бґґЅЁТ»ёцГыОЄ default µД NamespaceЈ¬НЁ№э kubectl їЙТФІйїґ:

(11).ConfigMap
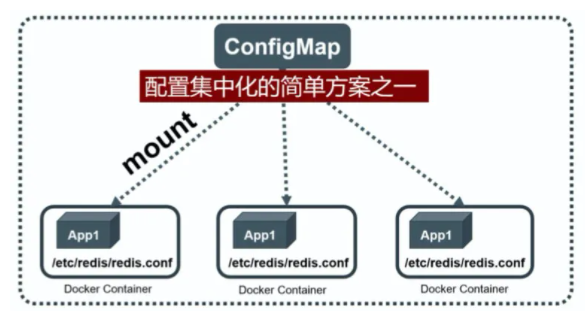
ОТГЗЦЄµАЈ¬Docker НЁ№эЅ«іМРтЎўТААµївЎўКэѕЭј° ЕдЦГОДјюЎ°ґт°ь№М»ЇЎ±µЅТ»ёцІ»±дµДѕµПсОДјюЦРµДЧц·ЁЈ¬ЅвѕцБЛУ¦УГµДІїКрµДДСМвЈ¬µ«ХвН¬К±ґшАґБЛј¬КЦµДОКМвЈ¬јґЕдЦГОДјюЦРµДІОКэФЪФЛРРЖЪИзєОРЮёДµДОКМвЎЈОТГЗІ»їЙДЬФЪЖф¶Ї Docker ИЭЖчєуФЩРЮёДИЭЖчАпµДЕдЦГ ОДјюЈ¬И»єуУГРВµДЕдЦГОДјюЦШЖфИЭЖчАпµДУГ»§ЦчЅшіМЎЈОЄБЛЅвѕцХвёцОКМвЈ¬Docker МṩБЛБЅЦЦ·ЅКЅ:
- ФЪФЛРРК±НЁ№эИЭЖчµД»·ѕі±дБїАґґ«µЭІОКэ;
- НЁ№э Docker Volume Ѕ«ИЭЖчНвµДЕдЦГОДјюУіЙдµЅИЭЖчДЪЎЈ
ФЪґу¶аКэЗйїцПВЈ¬єуТ»ЦЦ·ЅКЅёьєП ККОТГЗµДПµНіЈ¬ТтОЄґу¶аКэУ¦УГНЁіЈґУТ»ёц»т¶аёцЕдЦГОДјюЦР¶БИЎІОКэЎЈµ«ХвЦЦ·ЅКЅТІУРГчПФµДИ±ПЭ:ОТГЗ±ШРлФЪДї±кЦч»ъЙППИґґЅЁєГ¶ФУ¦ ЕдЦГОДјюЈ¬И»єуІЕДЬУіЙдµЅИЭЖчАпЎЈЙПКцИ±ПЭФЪ·ЦІјКЅЗйїцПВ±дµГёьОЄСПЦШЈ¬ТтОЄОЮВЫІЙУГДДЦЦ·ЅКЅЈ¬ РґИл(РЮёД)¶аМЁ·юОсЖчЙПµДДіёцЦё¶ЁОДјюЈ¬ІўИ·±ЈХвР©ОДјю±ЈіЦТ»ЦВЈ¬¶јКЗТ»ёцєЬДСНкіЙµДДї±кЎЈХл¶ФЙПКцОКМвЈ¬ Kubernetes ёшіцБЛТ»ёцєЬЗЙГоµДЙијЖКµПЦЎЈ
КЧПИЈ¬°СЛщУРµДЕдЦГПо¶јµ±Чч key-value ЧЦ·ыґ®Ј¬ХвР©ЕдЦГПоїЙТФ ЧчОЄ Map ±нЦРµДТ»ёцПоЈ¬Хыёц Map µДКэѕЭїЙТФ±»іЦѕГ»ЇґжґўФЪ Kubernetes µД Etcd КэѕЭївЦРЈ¬И»єуМṩ API ТФ·Ѕ±г Kubernetes Па№ШЧйјю»т їН»§У¦УГ CRUD ІЩЧчХвР©КэѕЭЈ¬ЙПКцЧЁГЕУГАґ±ЈґжЕдЦГІОКэµД Map ѕНКЗ Kubernetes ConfigMap ЧКФґ¶ФПуЎЈKubernetes МṩБЛТ»ЦЦДЪЅЁ»ъЦЖЈ¬Ѕ«ґжґўФЪ etcd ЦРµД ConfigMap НЁ№э Volume УіЙдµД·ЅКЅ±діЙДї±к Pod ДЪµДЕдЦГОДјюЈ¬І»№ЬДї±к Pod ±»µч¶ИµЅДДМЁ·юОсЖчЙПЈ¬¶ј»бНкіЙЧФ¶ЇУіЙдЎЈЅшТ»ІЅµШЈ¬Из№ы ConfigMap ЦРµД key-value КэѕЭ±»РЮёДЈ¬ФтУіЙдµЅ Pod ЦРµДЎ°ЕдЦГОДјюЎ±ТІ»бЛжЦ®ЧФ¶ЇёьРВЎЈ
4.Kubernetes µДјЬ№№
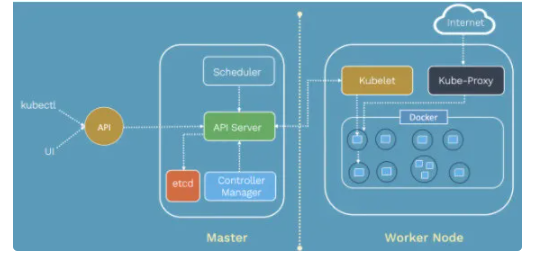
Kubernetes УЙ Master ЅЪµгЎў Node ЅЪµгТФј°НвІїµД ETCD јЇИєЧйіЙЈ¬јЇИєµДЧґМ¬ЎўЧКФґ¶ФПуЎўНшВзµИРЕПўґжґўФЪ ETCD ЦРЈ¬Mater ЅЪµг№ЬїШХыёцјЇИєЈ¬°ьАЁНЁРЕЎўµч¶ИµИЈ¬Node ЅЪµгОЄ№¤ЧчХжХэЦґРРµДЅЪµгЈ¬ІўПтЦчЅЪµг±ЁёжЎЈMaster ЅЪµгУЙТФПВЧйјю№№іЙЈє
(1).Master ЧйјюЈє
- API Server ЎЄЎЄ Мṩ HTTP Rest ЅУїЪЈ¬КЗЛщУРЧКФґФцЙѕёДІйєНјЇИєїШЦЖµДОЁТ»ИлїЪЎЈЈЁФЪјЇИєЦР±нПЦОЄГыіЖКЗ kubernetes µД serviceЈ©ЎЈїЙТФНЁ№э Dashboard µД UI »т kubectl №¤ѕЯАґУлЖдЅ»»ҐЎЈЈЁ1Ј©јЇИє№ЬАнµД API ИлїЪЈ»
ЈЁ2Ј©ЧКФґЕд¶оїШЦЖИлїЪЈ»
ЈЁ3Ј©МṩНк±ёµДјЇИє°ІИ«»ъЦЖЎЈ
- Controller Manager ЎЄЎЄ ЧКФґ¶ФПуµДїШЦЖЧФ¶Ї»ЇЦРРДЎЈјґјаїШ NodeЈ¬µ±№КХПК±ЧЄТЖЧКФґ¶ФПуЈ¬ЧФ¶ЇРЮёґјЇИєµЅЖЪНыЧґМ¬ЎЈ
- Scheduler ЎЄЎЄ ёєФр Pod µДµч¶ИЈ¬µч¶ИµЅЧоУЕµД NodeЎЈ
(2).Node ЧйјюЈє
- kubelet ЎЄЎЄ ёєФр Pod ДЪИЭЖчµДґґЅЁЎўЖфНЈЈ¬ІўУл Master ГЬЗРРЧчКµПЦјЇИє№ЬАнЈЁЧўІбЧФјєЈ¬»г±Ё Node ЧґМ¬Ј©ЎЈ
- kube-proxy ЎЄЎЄ КµПЦ k8s Service µДНЁРЕУлёєФШѕщєвЎЈ
- Docker Engine ЎЄЎЄ Docker ТэЗжЈ¬ёєФр±ѕ»ъИЭЖчµДґґЅЁєН№ЬАнЎЈ
5.Kubernetes јЬ№№ДЈїйКµПЦФАн
(1).API Server
Kubernetes API Server НЁ№эТ»ёцГыОЄ kube-apiserver µДЅшіММṩ·юОсЈ¬ёГЅшіМФЛРРФЪ Master ЙПЎЈФЪД¬ИПЗйїцПВЈ¬kube-apiserver ЅшіМФЪ±ѕ»ъµД 8080 ¶ЛїЪ(¶ФУ¦ІОКэ--insecure-port)Мṩ REST ·юОсЎЈОТГЗїЙТФН¬К±Жф¶Ї HTTPS °ІИ«¶ЛїЪ(--secure-port=6443)АґЖф¶Ї°ІИ«»ъЦЖЈ¬јУЗї REST API ·ГОКµД°ІИ«РФЎЈ
УЙУЪ API Server КЗ Kubernetes јЇИєКэѕЭµДОЁТ»·ГОКИлїЪЈ¬ТтґЛ°ІИ«РФУлёЯРФДЬѕНіЙОЄ API Server ЙијЖєНКµПЦµДБЅґуєЛРДДї±кЎЈНЁ№эІЙУГ HTTPS °ІИ«ґ«КдНЁµАУл CA З©ГыКэЧЦЦ¤КйЗїЦЖЛ«ПтИПЦ¤µД·ЅКЅЈ¬API Server µД°ІИ«РФµГТФ±ЈХПЎЈґЛНвЈ¬ОЄБЛёьПёБЈ¶ИµШїШЦЖУГ»§»тУ¦УГ¶Ф Kubernetes ЧКФґ¶ФПуµД·ГОКИЁПЮЈ¬Kubernetes ЖфУГБЛ RBAC ·ГОКїШЦЖІЯВФЎЈKubernetes µДЙијЖХЯЧЫєПФЛУГТФПВ·ЅКЅАґЧоґуіМ¶ИµШ±ЈЦ¤ API Server µДРФ ДЬЎЈ
- API Server УµУРґуБїёЯРФДЬµДµЧІгґъВлЎЈФЪ API Server ФґВлЦР К№УГРіМ(Coroutine)+¶УБР(Queue)ХвЦЦЗбБїј¶µДёЯРФДЬІў·ўґъВлЈ¬ К№µГµҐЅшіМµД API Server ѕЯ±ёБЛі¬ЗїµД¶аєЛґ¦АнДЬБ¦Ј¬ґУ¶шТФєЬїмµДЛЩ ¶ИІў·ўґ¦АнґуБїµДЗлЗуЎЈ
- ЖХНЁ List ЅУїЪЅбєПТмІЅ Watch ЅУїЪЈ¬І»µ«НкГАЅвѕцБЛ Kubernetes ЦРёчЦЦЧКФґ¶ФПуµДёЯРФДЬН¬ІЅОКМвЈ¬ТІј«ґуМбЙэБЛ Kubernetes јЇИєКµК±ПмУ¦ёчЦЦКВјюµДБйГф¶ИЎЈ
- ІЙУГБЛёЯРФДЬµД etcd КэѕЭїв¶ш·Зґ«НіµД№ШПµКэѕЭївЈ¬І»ЅцЅвѕц БЛКэѕЭµДїЙїїРФОКМвЈ¬ТІј«ґуМбЙэБЛ API Server КэѕЭ·ГОКІгµДРФДЬЎЈФЪ іЈјыµД№«УРФЖ»·ѕіЦРЈ¬Т»ёц 3 ЅЪµгµД etcd јЇИєФЪЗбёєФШ»·ѕіЦРґ¦АнТ»ёцЗл ЗуµДК±јдїЙТФµНУЪ 1msЈ¬ФЪЦШёєФШ»·ѕіЦРїЙТФГїГ봦Ані¬№э 30000 ёцЗлЗуЎЈ
(2).°ІИ«ИПЦ¤
RBAC
Role-Based Access Control(RBAC)Ј¬»щУЪЅЗЙ«µД·ГОКїШЦЖЎЈ
4 ЦЦЧКФґ¶ФПу
- Role
- RoleBinding
- ClusterRole
- ClusterRoleBinding
Role Ул ClusterRole
Т»ёцЅЗЙ«ѕНКЗТ»ЧйИЁПЮµДјЇєПЈ¬¶јКЗТФРнїЙРОКЅЈ¬І»ґжФЪѕЬѕшµД№жФтЎЈRole ЧчУГУЪТ»ёцГьГыїХјдЦРЈ¬ClusterRole ЧчУГУЪХыёцјЇИєЎЈ

RoleBinding єН ClusterRoleBinding КЗ°С Role єН ClusterRole µДИЁПЮ°у¶ЁµЅ ServiceAccount ЙПЎЈ
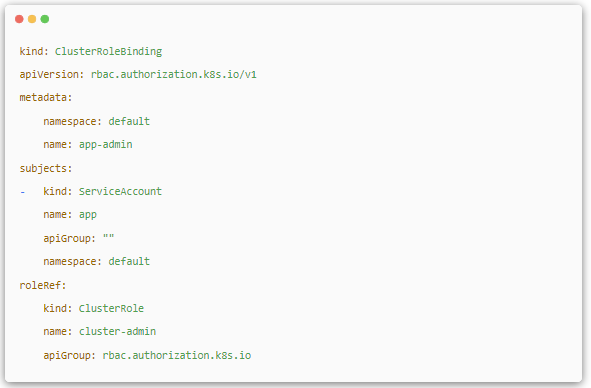
ServiceAccount
Service Account ТІКЗТ»ЦЦХЛєЕЈ¬µ«ЛьІўІ»КЗёш Kubernetes јЇИєµДУГ»§ (ПµНі№ЬАнФ±ЎўФЛО¬ИЛФ±ЎўЧ⻧УГ»§µИ)УГµДЈ¬¶шКЗёшФЛРРФЪ Pod АпµДЅшіМУГµДЈ¬ЛьОЄ Pod АпµДЅшіММṩБЛ±ШТЄµДЙн·ЭЦ¤ГчЎЈФЪГїёц Namespace ПВ¶јУРТ»ёцГыОЄ default µДД¬ИП Service Account ¶ФПуЈ¬ФЪХвёц Service Account АпГжУРТ»ёцГыОЄ Tokens µДїЙТФµ±Чч Volume ±»№ТФШµЅ Pod АпµД SecretЈ¬µ± Pod Жф¶ЇК±Ј¬Хвёц Secret »бЧФ¶Ї±»№ТФШµЅ Pod µДЦё¶ЁДїВјПВЈ¬УГАґРЦъНкіЙ Pod ЦРµДЅшіМ·ГОК API Server К±µДЙн·ЭјшИЁЎЈ
(3).Controller Manager
ПВ±ЯЅйЙЬјёЦЦ Controller Manager µДКµПЦЧйјю
ResourceQuota Controller
kubernetes µДЕд¶о№ЬАнК№УГ№э Admission Control АґїШЦЖµДЈ¬МṩБЛБЅЦЦФјКшЈ¬LimitRanger єН ResourceQuotaЎЈLimitRanger ЧчУГУЪ Pod єН Container Ц®ЙП(limit ,request)Ј¬ResourceQuota ФтЧчУГУЪ NamespaceЎЈЧКФґЕд¶оЈ¬·ЦИэёцІгґОЈє
- ИЭЖчј¶±р Ј¬¶ФИЭЖчµД CPUЎўmemory ЧцПЮЦЖ
- Pod ј¶±р Ј¬¶ФТ»ёц Pod ДЪЛщУРИЭЖчµДїЙУГЧКФґЧцПЮЦЖ
- Namespace ј¶±р Ј¬ОЄ namespace ЧцПЮЦЖЈ¬°ьАЁЈє
Namespace Controller
№ЬАн Namesoace ґґЅЁЙѕіэ.
Endpoints Controller
Endpoints ±нКѕТ»ёц service ¶ФУ¦µДЛщУР Pod ё±±ѕµД·ГОКµШЦ·Ј¬¶ш Endpoints Controller ѕНКЗёєФрЙъіЙєНО¬»¤ЛщУР Endpoints ¶ФПуµДїШЦЖЖчЎЈ
- ёєФрјаМэ Service єН¶ФУ¦ Pod ё±±ѕµД±д»ЇЈ¬Иф Service ±»ґґЅЁЎўёьРВЎўЙѕіэЈ¬ФтПаУ¦ґґЅЁЎўёьРВЎўЙѕіэУл Service Н¬ГыµД Endpoints ¶ФПуЎЈ
- EndPoints ¶ФПу±» Node ЙПµД kube-proxy К№УГЎЈ
(4).Scheduler
Kubernetes Scheduler µДЧчУГКЗЅ«ґэµч¶ИµД Pod(API РВґґ ЅЁµД PodЎўController Manager ОЄІ№Чгё±±ѕ¶шґґЅЁµД Pod µИ)°ґХХМШ¶ЁµДµч ¶ИЛг·ЁєНµч¶ИІЯВФ°у¶Ё(Binding)µЅјЇИєЦРДіёцєПККµД Node ЙПЈ¬ІўЅ«°у¶ЁРЕПўРґИл etcd ЦРЎЈKubernetes Scheduler µ±З°МṩµДД¬ИПµч¶ИБчіМ·ЦОЄТФПВБЅІЅЎЈ
- Ф¤СЎµч¶И№эіМЈ¬јґ±йАъЛщУРДї±к NodeЈ¬ЙёСЎіц·ыєПТЄЗуµДєт СЎЅЪµгЎЈОЄґЛЈ¬Kubernetes ДЪЦГБЛ¶аЦЦФ¤СЎІЯВФ(xxx Predicates)№©УГ»§СЎФсЎЈ
- И·¶ЁЧоУЕЅЪµгЈ¬ФЪµЪ 1 ІЅµД»щґЎЙПЈ¬ІЙУГУЕСЎІЯВФ(xxx Priority)јЖЛгіцГїёцєтСЎЅЪµгµД»э·ЦЈ¬»э·ЦЧоёЯХЯК¤іцЎЈ
(5).НшВз
Kubernetes µДНшВзАыУГБЛ Docker µДНшВзФАнЈ¬ІўФЪґЛ»щґЎЙПКµПЦБЛїз Node ИЭЖчјдµДНшВзНЁРЕЎЈ
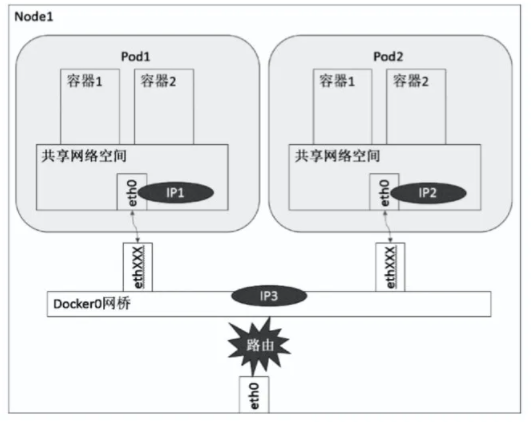
- Н¬Т»ёц Node ПВ Pod јдНЁРЕДЈРНЈє
- І»Н¬ Node ПВ Pod јдµДНЁРЕДЈРНЈЁCNI ДЈРНКµПЦЈ©Јє
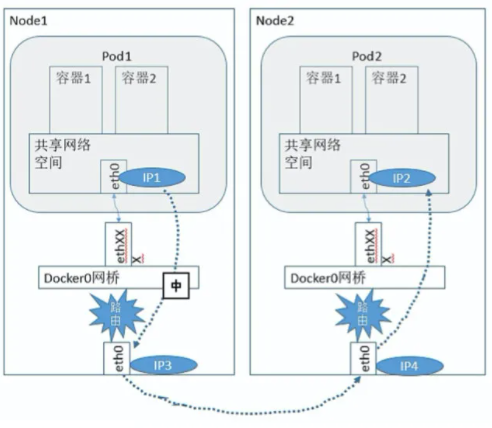
CNI МṩБЛТ»ЦЦУ¦УГИЭЖчµДІејю»ЇНшВзЅвѕц·Ѕ°ёЈ¬¶ЁТе¶ФИЭЖчНшВз ЅшРРІЩЧчєНЕдЦГµД№ж·¶Ј¬НЁ№эІејюµДРОКЅ¶Ф CNI ЅУїЪЅшРРКµПЦЈ¬ТФ Flannel ѕЩАэЈ¬НкіЙБЛ Node јдИЭЖчµДНЁРЕДЈРНЎЈ
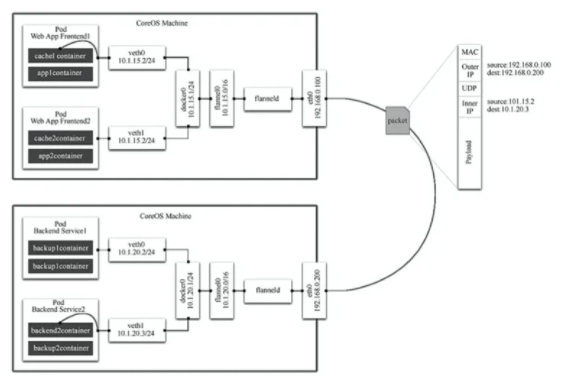
їЙТФїґµЅЈ¬Flannel КЧПИґґЅЁБЛТ»ёцГыОЄ flannel0 µДНшЗЕЈ¬¶шЗТХвёц НшЗЕµДТ»¶ЛБ¬ЅУ docker0 НшЗЕЈ¬БнТ»¶ЛБ¬ЅУТ»ёцЅРЧч flanneld µД·юОсЅшіМЎЈflanneld ЅшіМІўІ»јтµҐЈ¬ЛьЙПБ¬ etcdЈ¬АыУГ etcd Аґ№ЬАнїЙ·ЦЕдµД IP µШ Ц·¶ОЧКФґЈ¬Н¬К±јаїШ etcd ЦРГїёц Pod µДКµјКµШЦ·Ј¬ІўФЪДЪґжЦРЅЁБўБЛТ» ёц Pod ЅЪµгВ·УЙ±н;ЛьПВБ¬ docker0 єНОпАнНшВзЈ¬К№УГДЪґжЦРµД Pod ЅЪµг В·УЙ±нЈ¬Ѕ« docker0 ·ўёшЛьµДКэѕЭ°ь°ьЧ°ЖрАґЈ¬АыУГОпАнНшВзµДБ¬ЅУЅ« КэѕЭ°ьН¶µЭµЅДї±к flanneld ЙПЈ¬ґУ¶шНкіЙ Pod µЅ Pod Ц®јдµДЦ±ЅУµШЦ·НЁРЕЎЈ
(6).·юОс·ўПЦ
ґУ Kubernetes 1.11 °ж±ѕїЄКјЈ¬Kubernetes јЇИєµД DNS ·юОсУЙ CoreDNS МṩЎЈCoreDNS КЗ CNCF »щЅр»бµДТ»ёцПоДїЈ¬КЗУГ Go УпСФКµПЦµДёЯРФДЬЎўІејюКЅЎўТЧА©Х№µД DNS ·юОс¶ЛЎЈ
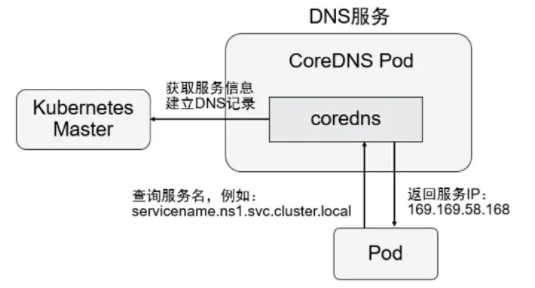
ЅбУп
ОДХВ°ьє¬µДДЪИЭЛµ¶аІ»¶аЈ¬ЛµЙЩІ»ЙЩЈ¬µ«¶ФУЪ DockerЎўKubernetes ЦЄК¶ФАнµДРЎ°ЧАґЛµКЗЧг№»µДЈ¬±КХЯ°ґХХЧФјєµДС§П°ѕСйЈ¬ТФЅйЙЬОЄіц·ўµгЈ¬ИГґујТёьДЬБЛЅвПа№ШјјКхФАнЈ¬ЛщТФКµІЩµДІї·ЦЅПЙЩЎЈ
|








