| 编辑推荐: |
今天就想和大家一起剖析一下我们是如何帮助大家平稳的从传统架构过渡到云原生架构的
,希望对您的学习有所帮助。
本文来自于搜狐
,由Alice编辑、推荐。 |
|
众所周知在微服务架构转型过程中,企业很难做到一刀切,在某段时间内会存在 新旧架构并存 的情况,面对这种场景,我们应当如何应对?
如何将一个复杂且稳定运行的传统架构平稳迁移到云原生微服务架构呢?这方面大家讨论和关注度不高,其中也牵扯到非常多的工程细节和技术难点。就像在高速公路上换轮胎一样充满了风险和挑战。今天就想和大家一起剖析一下我们是如何帮助大家平稳的从传统架构过渡到云原生架构的?本文主要分为三个板块:
- 云原生的迁移的落地痛点
- 如何帮助大家平稳的迁移
- 如何让迁移更加的优雅

云原生落地之痛
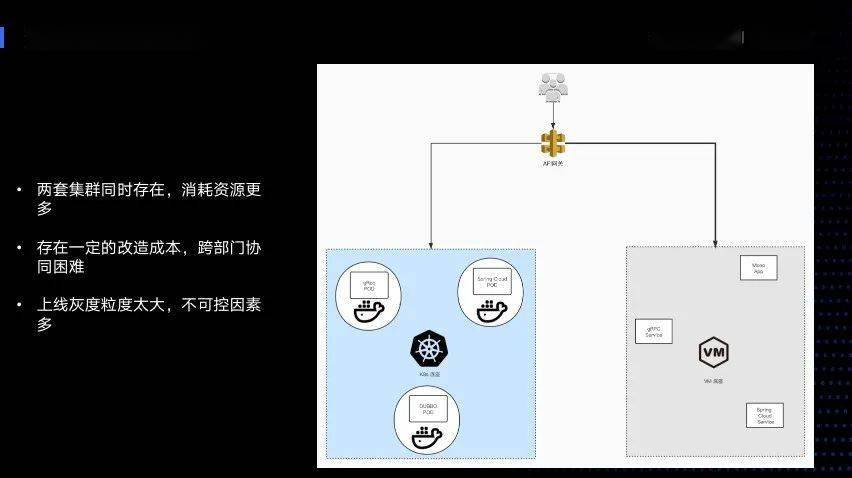
这是一种比较常见典型的迁移方案,主要运用在服务规模比较小,或者是历史包袱不太重的时候:首先保留一套老的集群,再新建一个完全新的云原生集群,然后把服务进行大量的改造,改造完之后再直接进行联调工作,把它全部迁移到云原生的集群上面。
这种情况下进行灰度和上线的发布在服务比较小的时候是可行的,但是当服务非常庞大,业务比较复杂的时候就会有很多缺点。因为它需要全量的集群,消耗的资源更多,同时存在一定的改造成本。
单体应用改造成微服务应用成本高 ,服务发现机制与案例都需要更改到符合云原生的标准。不仅仅是PaaS平台,它的改造比较小,只是需要换一个新的集群,但是业务的服务改造成本比较大。不仅需要改自己的服务,还需要上下游去适配,同时出现的跨部门协同会造成非常大的沟通和协作成本。而我们上线的力度较大,只需要把一个闭环的业务进行上线,会导致很多不可控的因素。
下图中展示的是Gartner咨询公司抽象总结出来的三种云原生架构的迁移路径。
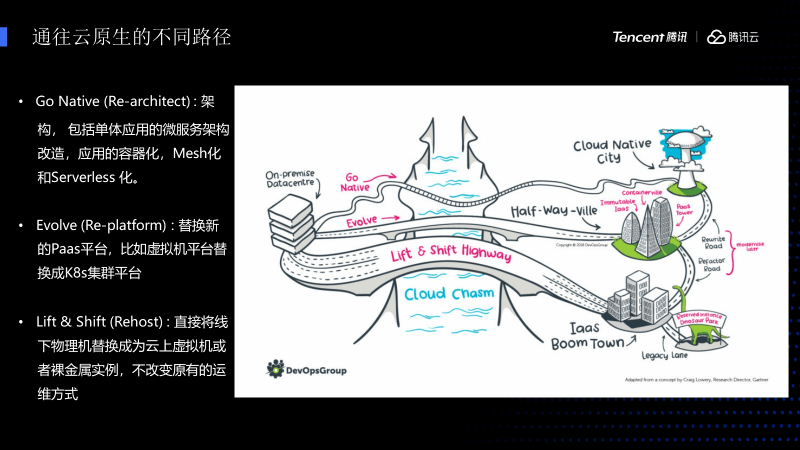
第一条路径是 Go Native ,是一种比较狭窄的整体重构的方式,它需要把整个服务全部重构,包括容器化、Mesh化、Serverless化直接上云,这种方法 因为风险较高 而不适合大的系统。
第二条路径是 Evolve ,这条路径需要替换全新的Paas平台,比如原来虚拟机架构替换成K8S集群,这样工作量会比较小,只需要把集群进行容器化就可以上线,但同时也存在一些风险,比如有些应用不适合容器化;比较大的单体应用存在消耗资源、有障碍的应用等都不适合一步到位迁移到容器集群。
第三条路径是 Lift Shift Highway ,直接将线下物理机或虚拟机替换成为云上虚拟机或者裸金属实例,在不改变原有的运维方式情况下再迁移到云原生架构。这种路径情况存在很多的中间态,比如有很多的虚拟机平台和容器平台需要同时共存,因为一些新的试点业务迁移到容器平台而老的服务还在虚拟机平台,包括单体应用和云原生应用也处于共存的状态。这种情况下如何处理共存的状态?并且帮它统一管理和统一治理呢?
渐进式云原生架构迁移
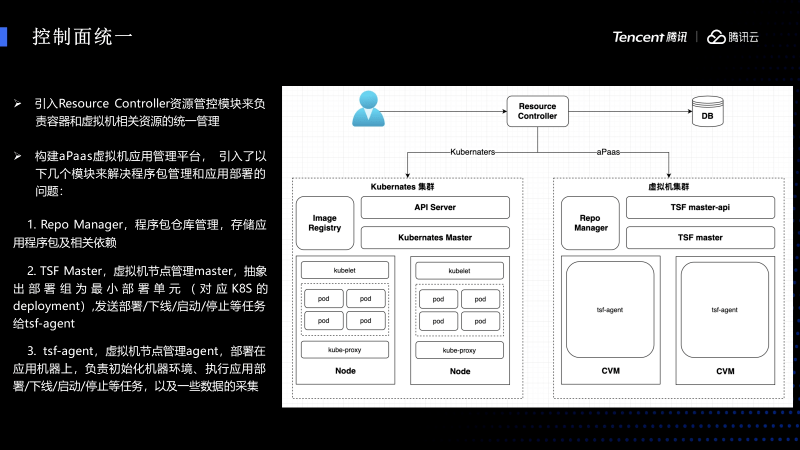
首讲一下如何统一管理虚拟机和容器。前面讲到会有一段的时间虚拟机和容器共存。在这一段时间,虚拟机和容器共存的时候需要引入一个中间层。我们引入一个叫Resource Cantrodler对其进行统一管理,它会对接容器平台的API,它的工作量不大,主要引入了一个对接虚拟机的aPaas系统,此系统分为三个组件:
-
一个是 Repo Manage r ,负责存蓄包的管理
- 一个是 TSF master-API, 主要是控制虚拟机节点的管理作用,并且抽象出一个最小的部署单元,管理虚拟机的生命周期。
- 还引入了 TSF master ,主要部署在应用的机器上负责初始化机器的环境,以及执行应用部署/下线/启动/停止等任务和一些数据的采集。由它来统一负责监控这些组件进行弹性的扩收容。
刚才讲到如何兼容一个新老的Paas平台,这个情况下还涉及到一个点,如何兼容老的服务?
我们知道Service Mesh的优点是可以让老代码在不改一行代码、一行配置的情况下,能够接入统一的治理和统一观测能力。但是有些老服务不想先容器化,或者容器化有一定的困难,这种情况下它需要实现一个统一的Mesh流量管理和服务治理功能。同时,新的一些试点应用 可以逐渐进行容器化,并且进行Mesh流量管控 。同时还要达到没有迁移的微服务和已经迁移完成的微服务能够保持互相的互通的目的。可以看到这里讲的第二点,微服务逐步容器化实现Mesh流量管控。
图中提到的第一和第三点,是开源社区暂时没有帮助我们完成的事情。因为开源的Istio不支持容器化部署,还有一些功能主要用在支持K8S的服务发现。

我们如何让Mesh运行在VM中的实现方案主要分为三个部分:
-
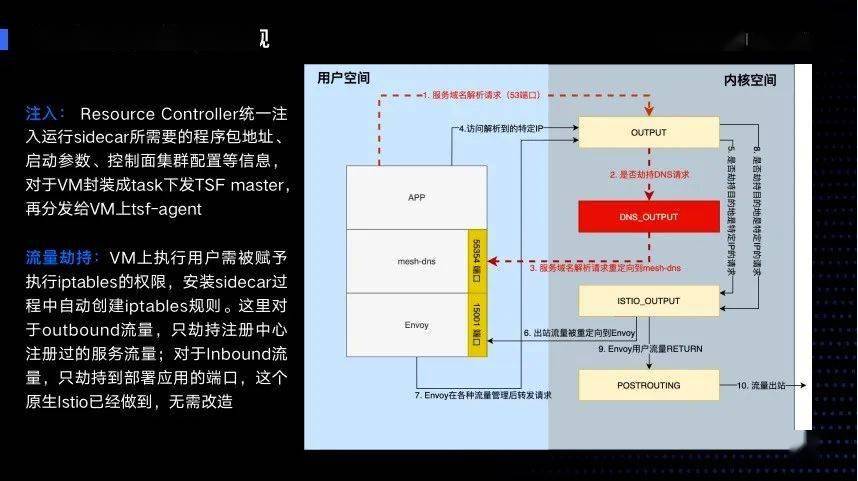
第一是如何注入Sidecar:让Resource Controller统一注入运行的Sidercar所需要的程序包地址、启动参数、控制面集群配置等信息,对于VM封装成task下发TSF master,再分发给VM上tsf-agent进行执行。
-
第二是流量劫持,VM上执行用户需被赋予执行Iptables的权限,安装Sidecar过程中自动创建iptables规则,对于outbound流量只劫持注册中心注册过的服务流量,还需要劫持DNS 53端口的流量,我们先把DNS请求引到mesh-dns,如图中红色部分。对于inbound流量,只劫持到部署应用的端口,而原生Istio已经做到所以无需改造。
- 最后是服务注册和健康检查完全由Mesh数据面接管,不依赖于K8S,对于其它注册中心,应用也无需依赖其注册中心SDK自己注册。
前面讲到如何让Mesh运行在VM虚拟机中运行,同时还涉及到新老服务会互相并存。但是用到的服务发现系统和机制不一样,之前用的是CP服务发现系统,现在想要换到更加高可用的AP服务发现系统上。
如果不更新新老服务互调和并存的能力会出现一个问题,我们设想一下如果有一个服务A依赖B,A和B都是老服务,这时B想迁移,发版到新的注册中心上面,等B全量迁移完之后,A那边就没有可用的B的节点,这时A就会爆错,这种情况是在迁移时不能忍受的。
还有一个问题A是老版本,这个时候它想发布到新的注册中心以及新的架构中, A在发布的时候没办法发现老服务注册中的B,这时A就没有办法实现迁移改造。为了解决AB 互相迁移依赖 的问题,我们做了 双注册、双发现 的功能。下图左边新的Provider提供服务,会先注册到新的注册中心,同时把自己的信息同步到原始的注册中心中。这时就可以做到新老Consumer从各自的注册中心都能发现。
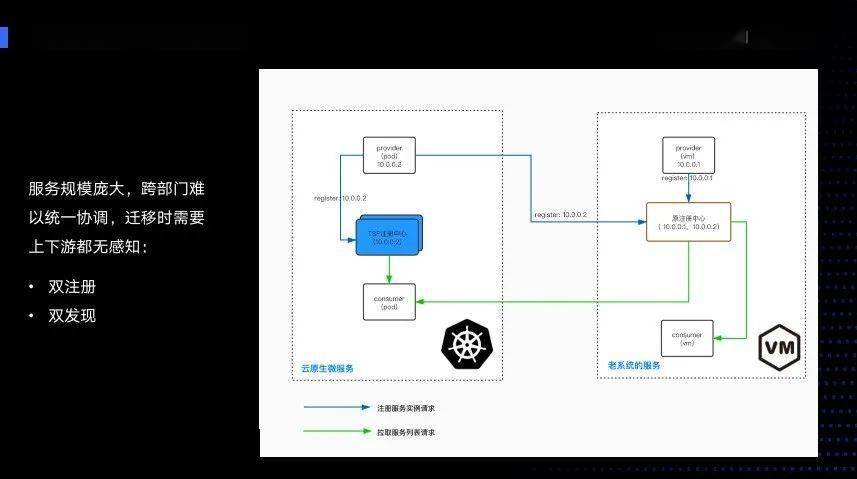
接下来讲一下长期可能存在的中间态,中间态首先是改造后的容器化微服务,它直接运行在容器平台。一些单体应用可能不想容器化,或者它的老服务不想容器化,这个时候可以 通过VM的Mesh来纳入到统一治理和观测的体系 ,同样能够享受到云原生的能力,新老服务可以长期互调,可以让我们的迁移更加的可控。同时我们的TSFMesh除了支持标准的HTTP和gRPC协议,还支持Dubbo协议,实现让老的Dubbo协议无缝接入。
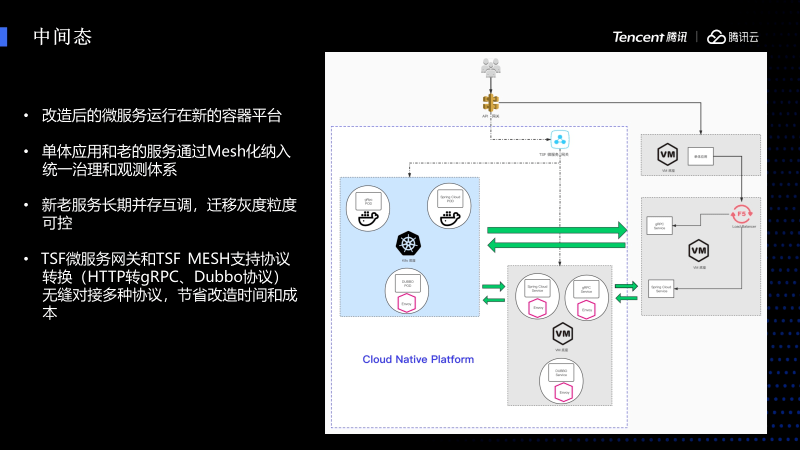
这里还有微服务网关组件和TSF Mesh支持协议转换,HTTP转gRPC和Dubbo协议转换,可以无缝对接多种协议应用,也节省了我们很多的改造和时间成本。
让迁移更加优雅和自信
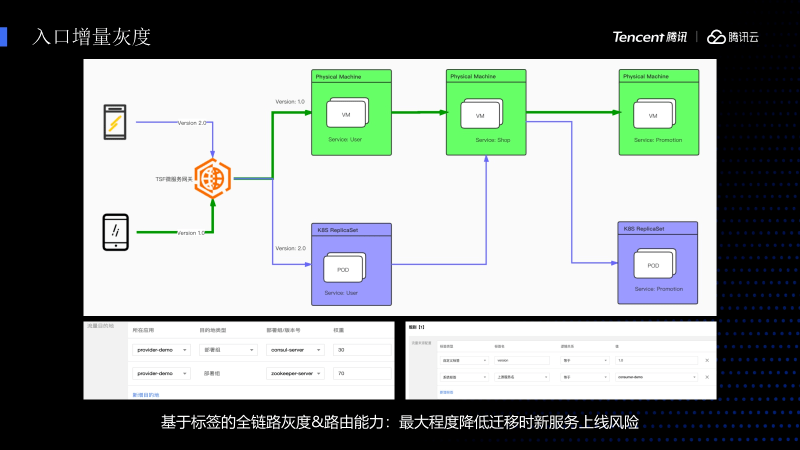
接下来介绍一下我们所做的增强功能和优势。如果在灰度的时候粒度太大,以整个业务为粒度的话风险会比较高,所以我们加了 全链路灰度和路由 的能力。下图里可以看到存在着一条调用链路,最前面是Get way,这边是User组件,中间是Shop,最后面是Promotion。这个组件里面User跟Promotion存在两个版本,一个是V1.0,一个是V2.0,Shop只有V1版本。
我们假设V1是老服务,V2是新服务,这个时候前端有一个APP请求的是V2,通过我们的网关会解析其中的参数,参数是可以在控制台配置,配置化以后可以动态下发至网关,我们的网关就可以把想要传递的V2标签,根据路由的匹配规则打到标紫色的UserV2的POD上面,这个时候发现没有V2的Shop,就会降级打到V1的Shop上面,这样依然保存了路由的链路关系,当它调用的时候会打到V2的Promotion上面,优点是 不用灰度整条闭环的业务链路,只灰度整个链路上几个微服务,保证最大程度流量平滑的迁移 。
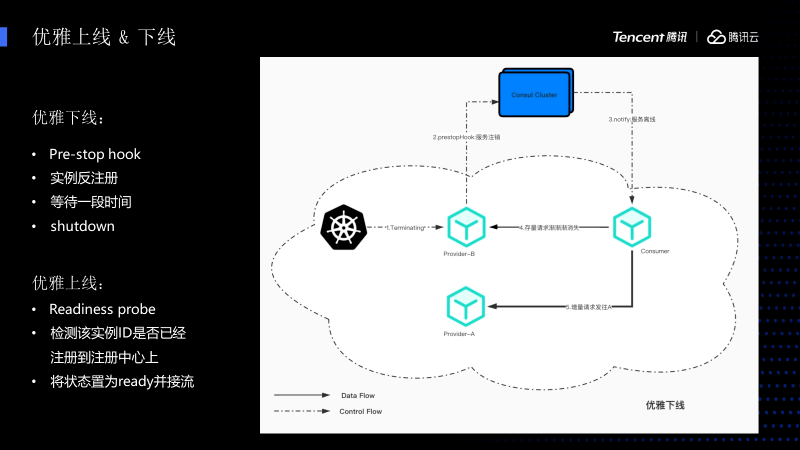
在迁移的时候也涉及到大量服务上线和下线的过程,这里主要介绍一下K8S的实现方案,我们刚才提到的虚拟机也是类似的,只不过是把里面的东西替换成TSF Agent操作。
这里主要是先在K8S上注册一个PrestopHook,这个Hook在容器进入Terminating生命周期的时候会被触发,触发之后先调用反注册接口进行反注册,在Sleep 30s完全流量都已经被上传完之后,完全生命周期就结束了,相当于 不会有任何的报错 。
优雅上线 也是类似,先注册一个Readiness probe,新的Pod启动的时候先执行脚本探测进程有没有准备好,如果准备好再进行后续的注册操作。我们还要检测是否注册到注册中心,因为有些应用生命周期比较长,可能需要好几分钟才能注册上,必须保证全部注册上了再继续滚动,否则会出现已经滚动发布,节点还为零的情况,最后再设置成Ready进行截流。
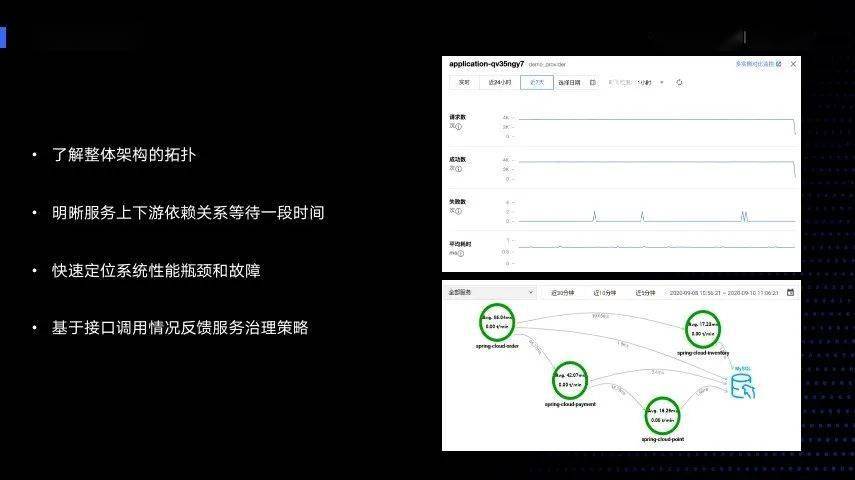
可以想象一下,我们肯定不允许以一种黑盒的状态进行迁移。所以同时引入了 全链路监控、全链路跟踪 的功能,可以了解到整体架构的拓扑,还可以明晰服务上下游依赖关系,快速定位系统性能瓶颈和故障,也可以基于接口调用情况反馈服务治理的策略。
|








