|
存储过程 - 领域驱动的反模式
Entity Framework(EF)中有一项功能,就是能够根据数据库中的存储过程生成实体的行为(或称方法,以下统称方法)。我在本系列的第一篇博文中就已经提到,这种做法并不可取!因为存储过程是技术架构中的内容,而我们所关注的却是领域模型。
Andrey Yemelyanov在其“Using ADO.NET EF in DDD: A Pattern
Approach”一文中,有下面这段话:
|
In this context, the architect also identified
the anti-pattern of using the EF (ineffective use):
the EF is used to mechanically derive
the domain model from the database schema (database-driven
approach). Therefore, the main topic of
the guidelines should be the domain-driven development
with the EF and the primary focus should be on how
to build a conceptual model over a relational model
and expose it to application programmers. |
黑体部分的意思是:(被采访的架构师)同时也指出了使用EF的一种“反模式”,即通过使用数据库结构来机械化地生成领域模型(数据库驱动的方式)。这也就证明了我在第一篇文章中指出的“只能通过领域模型来映射到数据模型,反过来则不行”的观点。
我能够理解很多做系统的朋友喜欢考虑数据库方面的事情,毕竟数据存储也是软件系统中不可或缺的部分(当然,内存数据库另当别论),数据库结构设计的好坏直接影响到系统的运行效率。比如:加不加索引、如何加索引,将对查询效率造成重大影响。但请注意:你把过多的精力放在了技术架构上,而原本更重要的业务架构却被扔到了一边。
什么时候选择存储过程?我认为存储过程的操作对象应该是数据,而不是对象,业务层也不可能把业务对象交给数据库去处理。其实,存储过程本身的意义也就是将数据放在DB服务器上处理,以减少客户程序与服务器之间的网络流量和往返次数,从而提高效率。所以,可以把查询次数较多的、与业务无关的数据处理交给存储过程(比如数据统计),而不要单纯地认为存储过程能够帮你解决业务逻辑问题,那样做只会让你的领域模型变得混乱,久而久之,你将无法应对复杂的业务逻辑与需求变更。
在做技术选型的时候还要注意一点,也就是存储过程的数据库相关性。存储过程是特定于某种关系型数据库机制的,比如,SQL
Server的存储过程与Oracle的存储过程并不通用,而有些数据库系统甚至不支持存储过程。因此过多使用存储过程将会给你带来一些不必要的麻烦。我个人对是否使用存储过程给出如下几点意见:1、根据需求来确定;2、不推荐使用;3、出于效率等技术考虑,需要使用的,酌情处理。
回过头来看实体框架,虽然现在支持从数据库存储过程生成实体方法的过程,但这是一种反模式,我也不希望今后EF还提供将实体方法映射到存储过程的功能,因为行为不同于数据,数据是状态,而行为是业务,它与领域密切相关,它不应该被放到“基础结构层”这一技术架构中。
聚合
聚合(Aggregate)是领域驱动设计中非常重要的一个概念。简单地说,聚合是这样一组领域对象(包括实体和值对象),这组领域对象联合起来表述一个完整的领域概念。比如,根据Eric
Evans《领域驱动设计》一书中的例子,一辆车包含四个轮子,轮子离开“车”就毫无意义,此时这个联合体就是聚合,而“车”就是聚合根(Aggregate
Root)。
从实践中得知,并非领域模型中的每个实体都能够完整地表述一个明确的领域概念,就比如客户与送货地址的关系。假设在某个应用中,系统需要为每个客户维护多个送货地址,此时送货地址就是一个实体,而不是值对象。那么这样一来,领域模型中至少就有了“客户”和“送货地址”两个实体,而事实上,“送货地址”是针对“客户”的,离开“客户”,“送货地址”就变得毫无意义。于是,“送货地址”就和“客户”一起,完整地表达了“客户可以有多个送货地址,并能对它们进行维护”的思想。
在《实体框架之领域驱动实践(三) - 案例:一个简易的销售系统》一文中,我们简单地设计了一个领域模型,其中包含了一些必要的实体和值对象。现在,我用不同颜色的笔在这个领域模型上圈出了三个聚合:客户、订单以及产品分类,如下图所示:

|
【额外说明】:如果像上图所示,Category-Item组成一个聚合,那么此时聚合根就应该是Item,而不是Category,因为Category对Item从概念上并没有包含/被包含的关系,而更多情况下,Category是Item的一种信息描述,即某个Item是可以归类到某个Category的。在这种情况下,我们不需要对Category进行维护,Category就以值对象的形式存在于领域模型中。如果是另一种应用场合,比如,我们的系统需要针对Category进行促销,那么我们需要维护Category的信息,由此Category和Item就分属两个不同的聚合,聚合根为各自本身。 |
首先是“客户-信用卡”聚合,这个聚合表示了一个客户可以拥有多张信用卡,类似于上面所讲的“客户-送货地址”的概念;其次是“订单-订单行”的聚合,类似地,虽然订单行也是一个实体,因为在应用中需要对每个订单行进行区分,但是订单行离开订单就变得毫无意义,它是“订单”概念的一部分;最后是“产品分类-产品”的聚合。
每个聚合都有一个根实体(聚合根,Aggregate Root),这个根实体是聚合所表述的领域概念的主体,外部对象需要访问聚合内的实体时,只能通过聚合根进行访问,而不能直接访问。从技术角度考虑,聚合确定了实体生命周期的关注范围,即当某个实体被创建时,同时需要创建以其为根的整个聚合,而当持久化某个实体时,同样也需要持久化整个聚合。比如,在从外部持久化机制重建“客户”对象的同时,也需要将其所拥有的“信用卡”赋给“客户”实体(具体如何操作,根据需求而定)。不要去关注聚合内实体的生命周期问题,如果你真的这么做了,那么你就需要考虑下你的设计是否合理。
由此引出了“领域对象生命周期”的问题,这个问题我会在后面两节单独讨论,但目前至少知道:
- 领域对象从无到有的创建,不是针对某个实体的,而是针对某个聚合的
- 领域对象的持久化(通常所说的“保存”)、重建(通常所说的“查询”)和销毁(通常所说的“删除”)也不是针对某个实体的,而是针对某个聚合的
很可惜,微软的Entity Framework(实体框架,EF)目前并不支持“聚合”的概念,所有的实体都被一股脑地塞到ObjectContext中:

为了实现聚合的概念,我们又一次地需要用到“部分类(partial class)”的功能。我们首先定义一个IAggregateRoot的接口,修改每个聚合根的实体类,使其实现IAggregateRoot接口,如下:


到这里又有问题了,接口IAggregateRoot中什么都没有定义?!我在我的技术博客中,特别解释了C#中接口的三种用途,请参考这篇文章:《C#基础:多功能的接口》。在这里,我们将IAggregateRoot接口用作泛型约束。在看完后续的两篇介绍领域对象生命周期的文章后,你就能够更好地理解这个问题了。事实上,在领域驱动设计的社区中,不少人都是这样用的。
最后说明一下,由于实体框架使所有的实体类继承于EntityObject类,而从面向对象的角度,接口是没办法去继承于类的,因此,在这里我们的IAggregateRoot接口好像跟实体没什么太大的关系,而事实上聚合根应该是一种实体。在很多领域驱动的项目中,设计人员专门设计了IEntity接口,所有实现了该接口的类都被认定为实体类,于是,IAggregateRoot接口也就很自然地继承IEntity接口,以表示“聚合根是一种实体”的概念,代码大致如下:


总的来说,领域模型需要根据领域概念分成多个聚合,每个聚合都有一个实体作为“聚合根”,通俗地说,领域对象从无到有的创建,以及CRUD操作都应该作用在聚合根上,而不是单独的某个实体。当你的代码需要直接对聚合内部的实体进行CRUD操作时,就说明你的模型设计已经存在问题了。
模型对象的生命周期 - 工厂
首先应该认识到,是对象就有生命周期。这一点无论在面向对象语言还是在领域驱动设计中都适用。在领域驱动设计中,模型对象生命周期可以简要地用下图表示:

通过上图可以看到,对象通过工厂从无到有创建,创建后处于活动状态,此时可以参与领域层的业务处理;对象通过仓储实现持久化(也就是我们常说的“保存”)和重建(也就是我们常说的“读取”)。内存中的对象通过析构而消亡,处于持久化状态的对象则通过仓储进行撤销(也就是我们常说的“删除”)。整个状态转换过程非常清晰。
现在引出了管理模型对象生命周期的两种角色:工厂和仓储。同时也需要注意的是,工厂和仓储的操作都是基于聚合根(Aggregate
Root)的,而不仅仅是针对实体的。关于仓储,内容会比较多,我在下一节单独讲述。在本节介绍一下工厂在.NET实体框架(Entity Framework)中的实现。
在打开了.NET实体框架自动生成的Entity Data Model Source Code文件后,我们发现,.NET实体框架为每一个实体添加了一个工厂方法,该方法包含了一系列原始数据类型和值类型的参数。比如,我们案例中的Customer实体就有如下的代码:
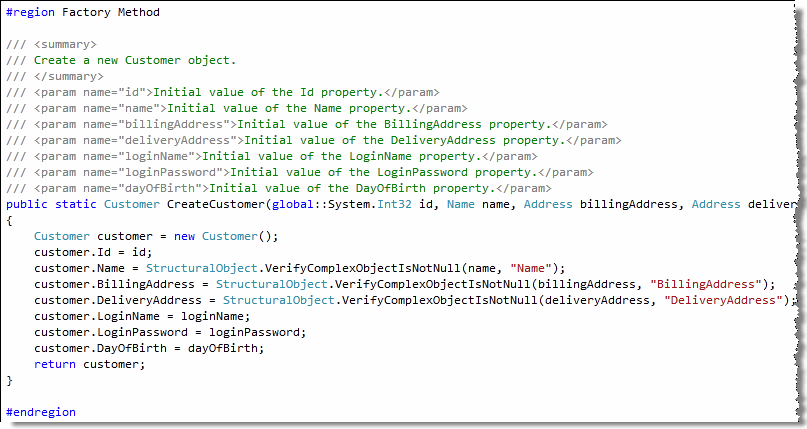
那么在创建一个Customer实体的时候,就可以使用Customer.CreateCustomer工厂方法。看来.NET实体框架已经离领域驱动设计的思想比较接近了,下面有几点需要说明:
- 使用该工厂方法创建Customer实体时,需要给第一个参数“global::System.Int32
id”赋值,而实际上这个ID值是用在持久化机制上的,在实体对象被创建的时候,这个ID值不应该由开发人员指定。因此,在这里要开发人员强行指定一个id值就显得多余。事实上,.NET实体框架中的每个实体都是继承于EntityObject类,而该类中有个EntityKey的属性,是被用作实体的Key的,因此我们这里的ID值肯定是由持久化机制进行维护的。从这里也可以看出,领域驱动设计中的实体会有两个标识符:一个是基于业务架构的,另一个是基于技术架构的。拿销售订单打比方,我们从界面上看到的更多是类似“SO0029473858”
这样的标识符,而不是一个整数或者GUID
- 该工厂方法能够创建一个Customer实体,为实体的各个成员属性赋值,并连带创建与该实体相关的值对象,聚合成员(比如Customer的CreditCards)是在使用的时候进行创建并填充的,这样做既符合“对象创建应该基于聚合”的思想,又能提高系统性能。比如,下面的单体测试用来检测使用工厂创建的Customer对象,其CreditCards属性是否为null(如果为null,则证明聚合根并没有合理地维护聚合的完整性):

- .NET实体框架仅仅为每个实体提供了一个最为简单的工厂方法。“工厂”的概念,在领域驱动设计中具有如下的最佳实践:
- 工厂可以隐藏对象创建的细节,因为对象的创建不属于业务领域需要考虑的问题
- 工厂用来创建整个聚合,从而维护聚合所代表的领域含义
- 可以在聚合根中添加工厂方法,也可以使用工厂类。也就是说,可以创建一个CustomerFactory的类,在其中定义CreateCustomer方法。具体是选用工厂方法还是工厂类,应该根据需求而定
- 当需要对被创建的实体传入参数时,应该尽可能地减小耦合性,比如可以使用抽象类或者接口作为参数类型
到这里你会发现,工厂和仓储好像有这一种联系,即它们都能够创建对象,而区别在于,工厂是对象从无到有的创建,仓储则更偏向于“重建”。仓储要比工厂更为复杂,因为仓储需要跟持久化机制这一技术架构打交道。在接下来的文章中,我会介绍一种基于.NET实体框架,但又不被实体框架制约的仓储的实现方式。 | 