һ�����»ع�
��ƪ���Ǽ����˷����ܹ�ģʽ�еļ��֣����ҽ����˷��������ü���ص���ƹ淶����ʵ����Ӧ��֪������ҵ��������ʹ������ģ����ʹ�÷������ܷ��ӳ��������ƣ����˵������ҵ�����㻹��ʹ�÷�����ģ�͵�ģʽ�������������ý������ڽ������á���ʵ��ҵ�������������ģ��ʱ������ǰ��˵�ij־û����ļ�������ʵ���ǿ���ͨ������������������ڷ�����д������������Ϣ�ij־û���������Ȼ��ƪ���ܲ����������۳־û����ľ���ʵ�֣�����ᵥ����ƪ�����������������ع�����ƪ��������ݣ�
��ͼ�����������ƪ���ǽ�������ݣ��������Ҫ��ϸ���˽������������ݣ���ο���ϵͳ�ܹ�ʦ-��������ҵӦ�üܹ�-��������������ǽ����һЩǰ�˵ķ���㻹�������չ�Ľ��⣬���������������ͽ��顣
����ժҪ
��ƪ����Ҫ��ϵͳ�������ݿ�洢���ʽ��н��������ݷ��ʲ������ϸ�Ľ��ܽ��⣬�������Ҳ�Ǵ�ұȽ���ϤҲ�Ǿ�������Ŀ��һ�����õ��IJ��֣�����֪�����ݷ��ʲ�ͨ�����Ƕ���������������������д��ͨ�õ���⣬������ǰ�潲��ķֲ�ܹ���ϵͳ�У������Ͽ���˵ҵ������е����ݶ�Ҫͨ�����ݷ��ʲ㽫ҵ�����ݳ־û����洢�����С���ʵĿǰ�кܶ�ĺõ�ORM����Ѿ��ܺõ�ʵ�������ݷ��ʲ㣬���ҵõ��˺ܹ㷺��Ӧ�ã���Ȼ���DZ�ƪҲ������Щͨ�õĿ��Ϊ������˵�����ݷ��ʲ��е�һЩ���ģʽ�����½��������м�������ע��չ��ȥ����
1�����ݷ��ʲ��ְ������������Ľ�����
2���������Լ������ݷ��ʲ㡣
3��ʵ�����ݷ��ʲ���������4������Ҫ�־û�CRUD����ѯ�����������ʵ�ֲ����ȡ�
4�����Ŀǰ���еļ����ܷ�������ṩ�����ݷ��ʲ㹦�ܵ����ӡ�
�������ǽ��������ļ�����ע������չ��ȥ˵��ϣ����ͨ�����ĵĽ��⣬���������ݿ���ʲ��и�����̵���ʶ���˽⡣
�������´��
1�����»عˡ�
2��ժҪ��
3�����´�١�
4�����ݷ��ʲ���ܡ�
5�����������ݷ��ʲ㡣
6��ʵ�����ݷ��ʵ�����ԭ��
7�������ܽᡣ
8��ϵ�н��ȡ�
9����ƪԤ�档
�ġ����ݿ���ʲ���
���ڽ�����Ҫ������ݷ��ʲ�Ĺ��ܼ�ְ����н��⣬����֮ǰ��ҵ�������е�����ģʽ�����ݷ��ʲ�֮��Ĺ�ϵ�����������������ݷ��ʲ���ҵ�������е�����ģʽ֮��Ĺ�ϵ��
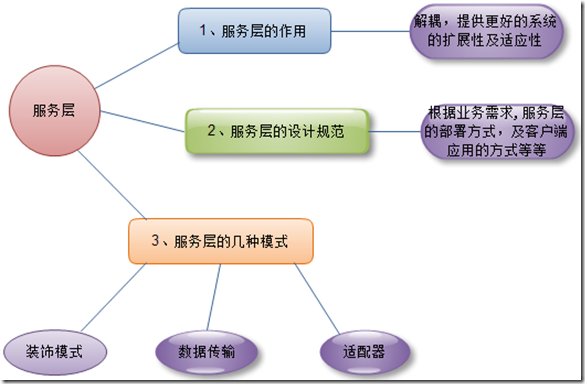
�����ڱ����еĽ�����Ҫ��������ģ��Ϊ�����з������⣬��Ϊֻ������ģ��ģʽ�����Dz��ܽ����ݷ��ʲ����������ֳɵ����IJ㣬�����ܹ������������־û������������������������ݷ��ʲ㶼��Ҫ�ṩʲôҪ�Ĺ��ܼ����ݷ��ʲ㱾����ְ����ʲô��
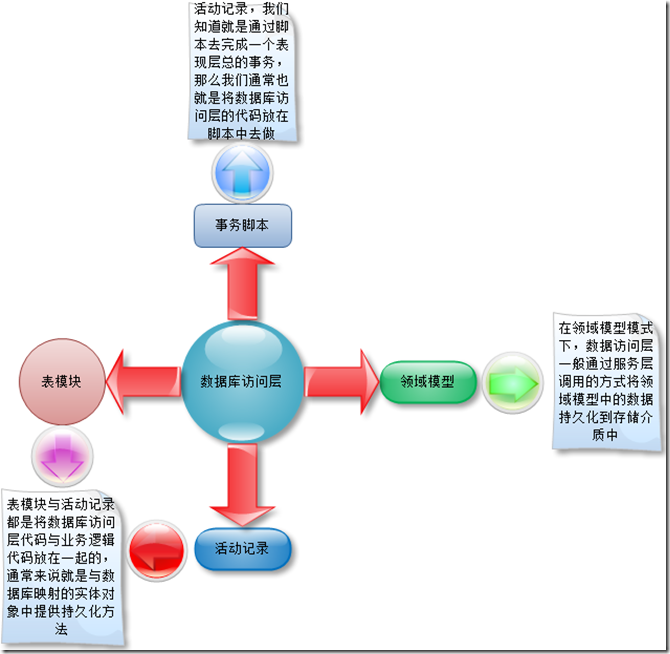
���ݿ���ʲ���Ψһ֪����β����洢���ʵ���ڣ�������ô��˵���������ݷ��ʲ�֮�ϣ����ǵ������ݿ���ʲ��ṩ�ķ��������Ǿ���������ݵĴ洢���ȡ���������ǿ���֪�������ݷ��ʲ�Ӧ���������ݿ�ֱ���Ƕ����ġ����о������ǵ����ݷ��ʲ������ʵ�ֲ�ͬ���͵����ݿ�Ķ�̬���л��������Dz���Ҫ���κεij����ܵȣ����������ڿ����Ĺ����ж����������������⡣��������ϣ�����Զ����ݷ��ʲ���ɶ�̬�����ã�ͨ����ͬ����������ɶ������ݿ���ʵ��л������������Ҷ��DZȽ���Ϥ�ģ�ͨ��XML�����ļ���������ݿ���л���ǰ������˵�����ǵ������DZ���ʵ��������ݿ���л�����ô�������ʵ���أ��������ǿ���ͨ������һ�����ݿ���ʽӿڣ�Ȼ��ͨ��ʵ�ֲ�ͬ�����ݿ��ϸ�ڣ���ʵ���������л���Ŀǰ�ܶ����еĿ�ܶ��Dz��������ķ�ʽ��ʵ�����ݿ�Ķ�̬�л�����Ȼ��ʱ�����ǵ���Ŀ�п��ܲ�������ʹ�ÿ�Դ��ͨ�ÿ�ܣ���ʱ�����ǿ��ܾ���Ҫ�Լ�ȥʵ����Щ���ݷ��ʲ�ľ���ϸ�ڡ�
��Ȼ���ݷ��ʲ㶼�����ܹ���Ӧ�ó����е����ݳ־û����洢�����У�ͨ������ʹ�õ����ݶ��ǹ�ϵ�͵����ݿ⣬��������֪�������ڳ���Ŀ����У�ͨ�����õ�ģ�Ͷ��Ƕ���ģ�ͣ���ô���ʵ�ֶ���ģ�����ϵģ��ֱ�ӵĻ����ת�����Ե÷dz�����Ҫ����Ȼ�������ݷ��ʲ����Ҫ���ܡ�ͨ����˵��ҵ�����㼰����㲻�˽����ݿ���ʵľ���ϸ�ڣ����Ƕ���Ҫͨ�����ݷ��ʲ���ʵ�����ݵĽ�����һ����˵������ģ���У����ݷ���ͨ�������ڷ�����н��е��õģ���ҵ�����㲢����ע���ݳ־û�����������ǰ��˵�ij־û����ķ�ʽҲ���ɴ˷�ʽ��ʵ�֡�
�������dž�����һ��ѣ�������˵�����ݷ��ʲ�Ļ��������ܣ�
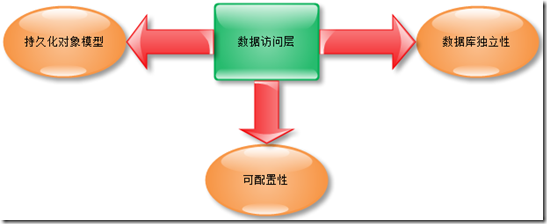
�����������������ݷ��ʲ�ļ�������ְ�����ȡ����ݷ��ʲ�Ӧ���ṩ�����ij־û�����CRUD�IJ���������֪�����ݷ��ʲ���Ψһ�ܲ������ݿ��һ�㣬��Ϊ���������ʱ��Ҫע�⣬ϵͳ�������㲻�ܰ����������ݿ����ع���
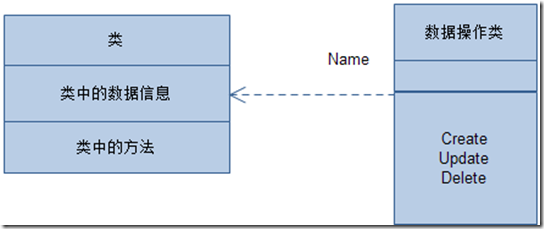
��������ͨ����ͼ���Կ�����ͨ���ṩ�����Ӧ�����ݿ���������ṩ��Ӧ�ij־û�������������Ȼ�ⲻ��Ψһ��ʽ�����еķ�ʽ�кܶࡣ���Ǻ������ϸ���ۡ�
��Ρ�Ӧ���ṩ�ܹ�����������Ϣ�Ķ�ȡ������һ���������˵���Ǿ���ʹ�õ��ǣ�����������ѯij���������Ϣ�������Dz�ѯ���еļ�¼�������Ǹ���������������ļ��ϡ�
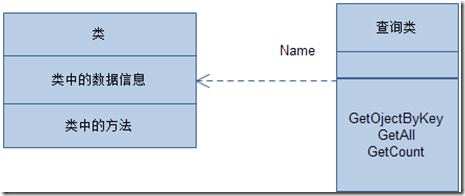
��Ȼ�������ﶨ��IJ�ѯ�������ͨ�õ���ʽ��ͨ�����͵���ʽ��������������֪������ģ���п϶��������ö�����������ô�������������������������أ�����һ����ͨ���ӳټ��ص���ʽ������������Ҫ�����Ǻ�������ν��⡣���������������ͨ����ʽ�ļ����ʽ��
01 |
public class
QueryHelper
|
06 |
///
<typeparam name="T"></typeparam>
|
07 |
///
<param name="key"></param>
|
08 |
///
<returns></returns> |
09 |
public
T GetObjectByKey<T>(object
key) |
15 |
///
��ȡָ�����Ͷ�����ܼ�¼�� |
17 |
///
<typeparam name="T"></typeparam>
|
18 |
///
<param name="key"></param>
|
19 |
///
<returns></returns> |
20 |
public
int
GetCount<T>(object
key) |
26 |
///
����ָ�����͵����ж��� |
28 |
///
<typeparam name="T"></typeparam>
|
29 |
///
<returns></returns> |
30 |
public
List<T> GetAll<T>()
|
�ٴΡ����ݿ���ʱ����ṩ����Ĺ���������˵���ṩ������������ݷ��ʲ��û�а취ʹ�ã���Ϊ���������ݷ��ʲ㹹����ϵͳ�Dz���ȫ�ġ��ر��������־�
���Ĺ����У������ܹ����������ݿ�����Ĵ��������Ҹ���������ĸ����Կ����ṩ���õİ�ȫ�ԡ��������ع���������ĸ����ԣ�
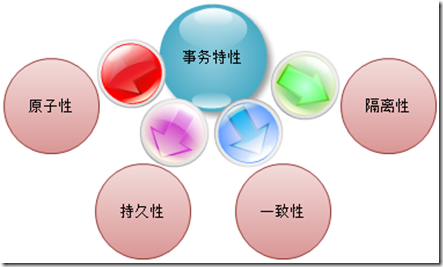
����������Ͳ���һһ�����ˣ���Ҷ����ġ����������ݷ��ʲ���������ͨ�����롰������Ԫ����ʵ����������ģ�������Ԫ����ὲ����������Ԫ���ṩ�ķ����������ԡ�
������ݷ��ʲ�����ṩ���������Ĺ��ܣ�������ϵͳ���ʵ��˽϶�����ʱ�϶�����ֲ�������������ݷ��ʲ���δ���������������Եü�����Ҫ�ˣ���һ�����û�������ϵͳ�У�ͨ��ǰ���ᵽ����������������ʱ����ܾͻ�������ݿ������Ե����⣬���������������һ���û������ڱ༭�Լ��ĸ�����Ϣ�����罫������Ϊ1985��3��20�գ�����û���Ӧ��ID��298����ʱ����ֻ�����ˣ����ǻ�û���ύ����ʱ����ԱҲ���ˣ�����˵����IDΪ298������û���Ϣ�ĵ�ַ����������Ϣ�������ύ����ʱ���û����Լ��༭�������ύ�ˣ���ô���ݿ��ж�Ӧ��IDΪ298��������Ϣ�ͻ��������ĵ�������Ϣ����ô֮ǰ����Ա�ĵ�������Ϣ�ͻᷢ����ʧ����Ȼ���ĵĿ����ֶβ���ͬһ���ֶΣ���ͺ����ǵײ�ʵ�ֵ����ݷ��ʲ��йأ���Ȼ���˵���������ݷ��ʲ�ʵ���ˣ�ֻ�����Ĺ��������е�ֵ�Ļ�����ô���ܲ�������������������Ȼ��ͺ����ǵײ�ʵ�ֵ����ݷ��ʲ�Ļ����йء�
��������ͨ��ͼ�εķ�ʽ��˵�������������⣺
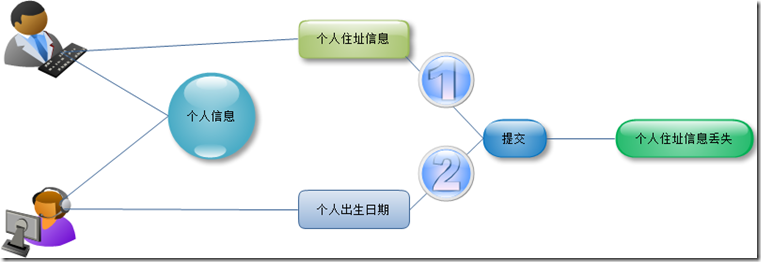
�������������ܵļ��ַ��������Զ������IJ���������Ӧ�Ĵ�����
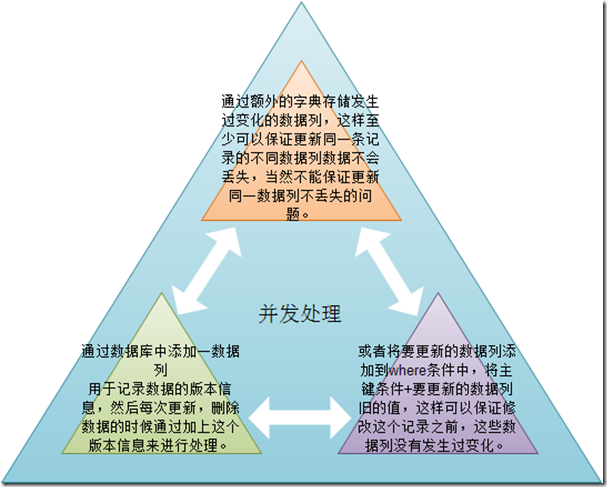
��Ȼ����ֻ���ṩ�˼������еİ취����Ȼ�����һ��и��õİ취�����Ը����ң���ʤ�м���
��Ȼ������ĸ�����ְ�������������ݷ��ʲ�����ṩ�ģ���Ӧ���ṩ������ƣ��ӳټ��صȵȰ���һЩ���ܷ�����Ż�����Ƶȣ���Щ���ں��潲��ɡ�
�����������������ݷ��ʲ���������ֱ�ӵĹ�ϵ�뽻��������ǰ��˵����������ģ���£�ҵ�������е����ݵij־û�����ͨ�����������ɵģ�������������������֮��Ĺ�ϵ������������������������ݷ��ʲ�֮��Ĺ�ϵ��
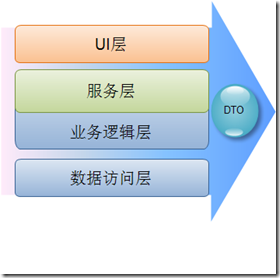
����������ݷ��ʲ�֮����н����������ͨ��DTO��UI����н����������ͨ����֯ҵ�������еĶ�����ʵ��ҵ������Ȼ��ͨ���������ݷ��ʲ㽫ҵ�����е���Ӧ���ݽ��г־û���ͨ�����ݷ��ʲ�����ʼ������ģ�͡�����ֱ���ڱ��ֲ���ʹ�����ݷ��ʲ�Ĺ��ܣ�����ͨ���Dz��Ƽ��������ģ�һ�����Dz�����ô���ģ�������Ͳ���ϸ�IJ�����
�塢���������ݷ��ʲ�
���ڽ���ϸ�Ľ��������Ƴ��Լ������ݷ��ʲ㣬���������ļ�������Ҫ����ô����˵��������˻��������ݷ��ʲ�Ĺ��ܣ���ʵ������Ǵ�ͷ��ʼ����һ�����������ݷ��ʲ㽫�Ƿdz���Ĺ�������Ŀǰ���еĺܶ��ORM����Ѿ��ṩ�˷ḻ�����ݷ��ʲ�Ĺ��ܣ��ܹ��dz��õ����������ļ���ְ�𡣵�Ȼ���ڻ��ǻ��ϴ�����˵˵���ݷ��ʲ�ľ���ʵ�֡�
����ǰ�潲�������ݷ��ʵ�3�������Ĺ����������ݿ�����ԣ��������Լ��־û�����ģʽ(����ģ�����ϵģ�͵�ת��)�����������ȿ����ʵ�����ݿ�Ķ����ԣ���������������ݿ����Ǩ�ƣ�ͨ��XML�����ļ������ò�ͬ�����ݿ�������ʵ�������Ĺ��ܣ���ô����������Ҫ������Բ�ͬ���ݿ����ʵ�֣�������ɺ����IJ�������Ȼ��������Ҫ������ϣ���ô��������ǰ��������������ԭ����淶֪���������Ƽ�ʹ������ӿڵı�̵ķ�ʽ���������Ľ�������ԡ���������������Ĵ��롣�������Ƕ���һ��ͨ�õ����ݷ��ʲ�Ľӿڡ�
04 |
public interface
IDALInterface
|
10 |
///
<param name="model"></param>
|
11 |
///
<returns></returns> |
12 |
int
Create(object
model); |
16 |
///
<param name="model"></param>
|
17 |
///
<returns></returns> |
18 |
int
Update(object
model); |
22 |
///
<param name="model"></param>
|
23 |
///
<returns></returns> |
24 |
int
Delete(object
model); |
29 |
///
<typeparam name="T">����ģ��</typeparam>
|
30 |
///
<returns></returns> |
31 |
IList<T>
GetAll<T>() where T :
class,new();
|
35 |
///
<typeparam name="T"></typeparam>
|
36 |
///
<param name="whereCondition"></param>
|
37 |
///
<returns></returns> |
38 |
IList<T>
GetListByQuery<T>(WhereCondition whereCondition)
where T :
class,new();
|
42 |
///
<typeparam name="T"></typeparam>
|
43 |
///
<returns></returns> |
46 |
///
�������������������� |
48 |
///
<typeparam name="T"></typeparam>
|
49 |
///
<param name="whereCondition"></param>
|
50 |
///
<returns></returns> |
51 |
int
GetCount<T>(WhereCondition
whereCondition); |
53 |
///
�����������ض���ģ�� |
55 |
///
<typeparam name="T"></typeparam>
|
56 |
///
<param name="key"></param>
|
57 |
///
<returns></returns> |
58 |
T
GetModelByKey<T>(object
key) where T :
class,new();
|
72 |
void
BeginTransaction();
|
���ﶨ���˻����ļ�����������Ȼ���в�û�а��������Ĵ���������ὲ�����Ĵ���������ʵ�֣� ǰ������˼��ֿ��е�ʵ�ַ�ʽ���ӿڶ������֮�����ݲ�ľ������������Ͳ�һһ�Ķ����������ˣ���Ϊÿ�ֲ�ͬ�����ݿ����;�Ҫ�ֱ�ʵ�֣��������イ��2�в�ͬ���͵�ʵ��˼·�ɣ�
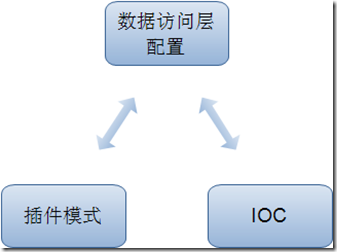
�������イ��2��ʵ�ֶ�̬�����������ݷ�������ķ�ʽ�����������������ģʽ��
���ģʽ
���ģʽ�����ģʽ����ͨ���ⲿ�����ļ��ж�ȡҪ�����������������Ϣ��Ȼ�������������ģʽ�Ĺؼ�����Ƿ��������ʵ����ϵ�����������ǵķֲ�ṹ�еĽ��;��ǣ�������е������ݷ��ʲ��е����������㲻��ϵ����ĵ��÷�ʽ�������ֻ���ķ�����������ݷ��������ͨ�������ļ�����̬�Ĵ�������Ȼ�����Ҫʹ��.NET�еķ���Ĺ��ܡ�����������ͼ�λ���������
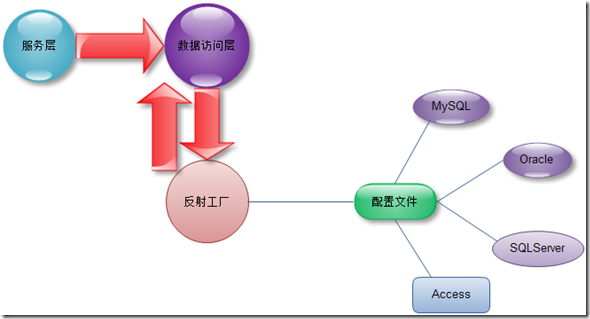
���乤��ͨ����ȡ�����ļ��о����������������ݷ��ʵľ������������ͣ�ͨ�����乤������̬�Ĵ�������������������ʵ�����뼰�����ļ���
01 |
<?xml
version="1.0"
encoding="utf-8"
?> |
03 |
<ConnectionItem
key="connectionString" |
04 |
value="Data
Source=.\SQLEXPRESS;Initial Catalog=EasyStore;User
ID=sa;Password=123456"
/> |
05 |
<DALType
key="DALType" |
06 |
value="DAL.SQLServer"
/> |
08 |
<Assembly
key="Assembly
" |
09 |
value="DAL.SQLServer"
/> |
����������ļ��е�ConnectionItem �ڵ������������ݿ���ʵ������ַ�����DALType ���������ݷ��ʲ���������͡����������������乤����ʾ������ʵ�֡�
01 |
public
class DALHelper |
03 |
private
static IDALInterface instance; |
05 |
public
static IDALInterface GetDAL() |
07 |
string
assambly = XmlHelper.getVlaue("Assembly");//����Ӧ�����Զ���Ķ�ȡXML�ڵ�ķ�ʽ
|
08 |
string
type = XmlHelper.getVlaue("DALType");
|
10 |
Assembly
asm = Assembly.Load(assambly); |
11 |
instance
= (IDALInterface)asm.CreateInstance(type);
|
17 |
���ǽ������������ʹ��������ݷ��ʲ�ȥʵ����Ӧ�ij־û�������
|
19 |
public
class TestService |
21 |
private
IDALInterface DAL; |
25 |
DAL
= DALHelper.GetDAL(); |
28 |
public
void Create(Test test) |
������ʵ�����ڷ��������ݷ��ʲ�ĵ��ò�����������ͨ���ӿڵ��õķ�ʽ��ʵ�֡����������������Ʒ�ת��ʵ�ַ�ʽ�ɡ�
���Ʒ�ת
���Ʒ�ת��������ƹ淶��ԭ�����й����⣬���Ʒ���ͨ����̬�Ľ����ע�뵽���ø�����Ķ����е���ʽ��Ȼ�������ø�����Ķ���ʹ������ķ���DI����ע����Կ����ǿ��Ʒ�ת��һ��Ӧ��ʵ�������ǿ��ѿ��Ʒ�ת������һ��ԭ��
���������������������ͨ�����Ʒ����ķ�ʽ��ʵ�����ݷ��ʲ��ƽ��Ǩ�ơ���Ȼ����֪�����϶���ͨ����̬ע��ķ�ʽ��ʵ�֣���ȻĿǰ������Ҳ�кܶ��IOC��̬ע���ܣ��������ǽ������һЩ�����˵�����ʵ�������Ĺ��ܡ�
���Ľ���Enterprise Library5.0Ϊ�����н��̬ע�����ʽ�������������������ļ�������
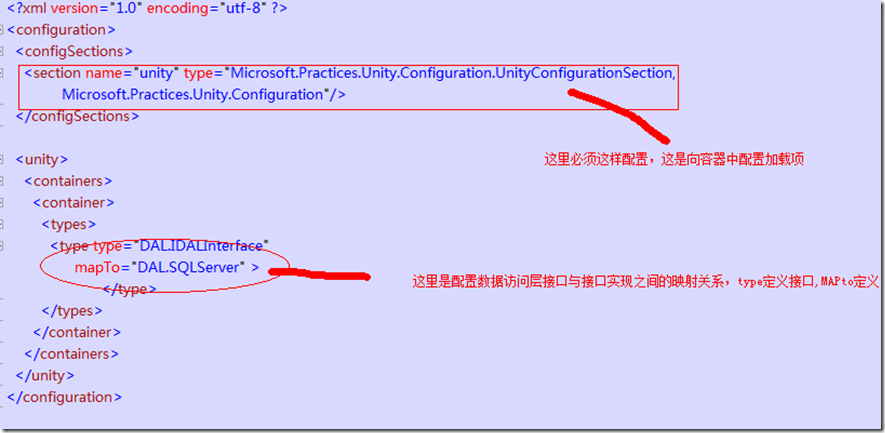
����������ͨ��һ���м���ȥʵ����Ӧ��ע����룺
02 |
///
���ڶ�̬��ɴ���ע��Ĺ����� |
04 |
public
class IOCContainer |
06 |
private
static IUnityContainer container; |
07 |
private
UnityConfigurationSection section; |
10 |
container
= new UnityContainer(); |
11 |
section
= (UnityConfigurationSection)System.Configuration.ConfigurationManager.GetSection("unity");
|
13 |
section.Configure(container);
|
16 |
public
static IDALInterface GetDAL() |
18 |
return
container.Resolve<IDALInterface>();
|
22 |
ͨ��������������ʵ���ˣ���̬�Ĵ������ݷ��ʲ����ʵ����������������������ע��ķ�ʽȥ�����Ӧ�ij־û��Ĺ��ܡ����������������Ĵ���
|
27 |
public
class TestService |
29 |
private
IDALInterface DAL; |
30 |
public
TestService(IDALInterface dal) |
35 |
public
void Save(Test test) |
���������Dz��ù��캯��ע��ķ�ʽ��ʵ�����ݷ��ʲ�Ķ�̬ע��ģ���Ȼ���˹��캯��ע�룬���������ķ�ʽ����������ֻ�Ǿ���˵����һ����˵����ע�������µļ�����ʽ
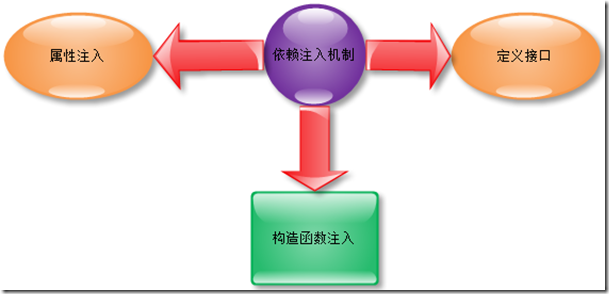
�����������Ͳ�����˵���ˣ���ҿ������ϲ���кܶ�����ӣ�����ƽʱҲ������Щ��ʽ��
����ʵ�����ݷ��ʵ�����ԭ��
�ڵ��Ľ������ǽ��������ݷ��ʲ���ĸ�ԭ����ô�������Լ������ݷ��ʲ������ʵ���⼸��ԭ���أ�������Ե�һ��ԭ��־û���ԭ������ǰ��ֻ�ǼĽ������ʵ�����ݿ�Ķ����ԣ������������������־û��IJ�����Ҳ��������˵��CUD�IJ�����������������IJ�ѯ����ѯ����Ҳ���������ݷ��ʲ�����ṩ�ĸ�ԭ��֮һ�����Ǻ��涼�ὲ�⣬������������CUD��ʵ�֡����������־û������ʱ��һ������£����ǻᶨ��һ��ͳһ�����ݷ��ʲ�ӿڣ�Ȼ���ṩ�־û���������ȵȣ�ͨ����һЩ���ݷ��ʲ㹲�ԵIJ��֣����Ƕ�ͨ��һ����������ʵ�֣������ཫʵ�ֽӿ��еIJ��ֹ��ܣ�Ȼ��ͨ������һЩ�����Ա�������þ�������ݷ��ʲ�ȥʵ����Ӧ�Ĺ��ܡ������������Ͻ����Ƕ����IDALInterfaceΪ���������ļ�ʵ�֡�
���ǽ�ԭ���Ľӿڲ������ص��Ż�������CUD����������ȡ������ͨ��ICUDMapper�ӿ�������
04 |
public
interface ICUDMapper |
10 |
///
<param
name="model"></param>
|
11 |
///
<returns></returns>
|
12 |
int
Create(object model); |
16 |
///
<param
name="model"></param>
|
17 |
///
<returns></returns>
|
18 |
int
Update(object model); |
22 |
///
<param
name="model"></param>
|
23 |
///
<returns></returns>
|
24 |
int
Delete(object model); |
27 |
Ȼ����������������ӿڲ�ļ�ʵ�֣���Ϊ�������ݷ��ʲ�ĸ���
|
29 |
public
abstract class BaseDAL : IDALInterface,IDisposable
|
31 |
protected
abstract ICUDMapper GetMapper(); |
37 |
///
<param
name="model"></param>
|
38 |
///
<returns></returns>
|
39 |
public
int Create(object model) |
41 |
return
GetMapper().Create(model); |
46 |
///
<param
name="model"></param>
|
47 |
///
<returns></returns>
|
48 |
public
int Update(object model) |
50 |
return
GetMapper().Update(model); |
55 |
///
<param
name="model"></param>
|
56 |
///
<returns></returns>
|
57 |
public
int Delete(object model) |
59 |
return
GetMapper().Delete(model); |
62 |
#region
IDisposable ��Ա |
��Ȼ����ֻ����ʵ�����롣��Ȼ�Ҳ��������ķ�ʽ��������������֮ǰ��һƪ��Step
by Step-�����Լ���ORMϵ��-��ƪ ��ƪ�еķ����˼�룬��ҿ��Կ�������+�����˼·������������ݳ־û�������Ҳ�����ƵIJ��������ܵײ��ʵ�־��������ķ�ʽ��
��������ݳ־û���������ζ�̬������SQL��䣬�����Ż��ȸ���������ݣ����DZ�ƪ���ܲ�������Ľ��⣬�һ����뽫������ORMϵ��ƪ���뽲�⡣
��Ȼ������ʵ���ܼ��˵���������Ϊÿ������ģ���еĶ�����һ�����ݳ־û�ӳ���������ӳ�䣬����������ͨ���������ݿ��ͳһģʽ���ھ����ӳ�����У�ͨ������ȡ�����ݶ����ӳ����Ϣ������������ʵ�ֵ�˼·�ɣ���������ҾͲ�����
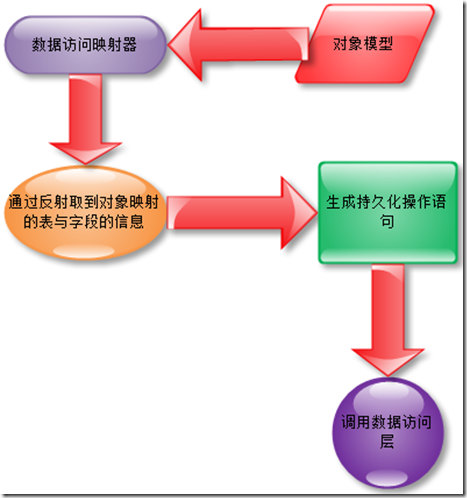
��������̾�������˵���ˣ�ϸ�ڿ϶����кܶ�Ҫע��ĵط���
����������������ѯ�����ʵ�֣�
����һ���ϵͳ80%��ʱ�����ݿ�ִ�еIJ����Dz�ѯ����20%��ʱ�������д����ĵIJ�������Ȼ�����ﲻ�Ǿ��Ե�˵��������ϣ����һ�����߰������Զ���ɻ����IJ�ѯ�������������ֶ���ȥ��д����Ϊ���Ƿ��ֶԴֵ����ݼ��϶��ԣ���һЩ���ԵIJ����������ȡij������ֵ�Ķ������Ϣ�������ǻ�ȡ���ݿ���е��������������Ƿ������ݿ�������м�¼��������ν���ϵ���ݿ��еĹ�ϵģ��ת��Ϊ����ģ�ͣ��ⶼ�Dz�ѯ������Ӧ���ṩ�Ļ������ܡ�����������������ʵ�ְɡ�
�������ǻ��Dzο�ǰ��ķ�ʽ�����ǽ�IDALInterface���еIJ�ѯ������г�����룬����ѯ������������ڽӿ�IQuery�С��������£�
01 |
public
interface IQuery |
06 |
///
<typeparam
name="T">����ģ��</typeparam>
|
07 |
///
<returns></returns>
|
08 |
IList<T>
GetAll<T>()
where T : class,new(); |
12 |
///
<typeparam
name="T"></typeparam>
|
13 |
///
<param
name="whereCondition"></param>
|
14 |
///
<returns></returns>
|
15 |
IList<T>
GetListByQuery<T>(WhereCondition
whereCondition) where T : class,new();
|
19 |
///
<typeparam
name="T"></typeparam>
|
20 |
///
<returns></returns>
|
23 |
///
�������������������� |
25 |
///
<typeparam
name="T"></typeparam>
|
26 |
///
<param
name="whereCondition"></param>
|
27 |
///
<returns></returns>
|
28 |
int
GetCount<T>(WhereCondition
whereCondition); |
30 |
///
�����������ض���ģ�� |
32 |
///
<typeparam
name="T"></typeparam>
|
33 |
///
<param
name="key"></param>
|
34 |
///
<returns></returns>
|
35 |
T
GetModelByKey<T>(object
key) where T : class,new(); |
�����������ڻ����е�ʵ�֡���ѯ��������ʵ��
04 |
/// <returns></returns>
|
05 |
protected
abstract IQuery GetQuery(); |
12 |
///
<typeparam
name="T">����ģ��</typeparam>
|
13 |
///
<returns></returns>
|
14 |
public
IList<T>
GetAll<T>()
where T : class,new() |
16 |
return
GetQuery().GetAll<T>();
|
21 |
///
<typeparam
name="T"></typeparam>
|
22 |
///
<param
name="whereCondition"></param>
|
23 |
///
<returns></returns>
|
24 |
public
IList<T>
GetListByQuery<T>(WhereCondition
whereCondition) where T : class,new()
|
26 |
return
GetQuery().GetAll<T>();
|
31 |
///
<typeparam
name="T"></typeparam>
|
32 |
///
<returns></returns>
|
33 |
public
int GetCount<T>()
|
35 |
return
GetQuery().GetCount<T>();
|
38 |
///
�������������������� |
40 |
///
<typeparam
name="T"></typeparam>
|
41 |
///
<param
name="whereCondition"></param>
|
42 |
///
<returns></returns>
|
43 |
public
int GetCount<T>(WhereCondition
whereCondition) |
45 |
return
GetQuery().GetCount<T>(whereCondition);
|
48 |
///
�����������ض���ģ�� |
50 |
///
<typeparam
name="T"></typeparam>
|
51 |
///
<param
name="key"></param>
|
52 |
///
<returns></returns>
|
53 |
public
T GetModelByKey<T>(object
key) where T : class,new() |
55 |
return
GetQuery().GetModelByKey<T>(key);
|
��Ȼ���ݲ�ͬ�����ݿ���ܶ���IJ�ѯ���ĸ�ʽ��ͬ�����Ƿ��صĽ������ʽȴ���Զ����ͨ�õ���ʽ���������ǾͿ���ʵ�ֱȽ�ͨ�õIJ�ѯ����Ҳ�кܺõ�ͨ���ͺ���չ�ԡ���Ȼ�������ﻹ�������ӷ�ҳ��֧�ֵȣ�ֻ�����ӵ����������ƣ�ʵ�ַ�ʽ������ͬ��
�����������������ݷ��ʲ㹦�ܱ���ְ��֮�����ԣ����Ƕ�֪�������Եļ������ԣ�ͨ�����������ṩ���ݵİ�ȫ�ԡ������������һ��˼·ȥʵ�������������ԣ����������ݷ��ʲ��ж���һ������Ԫ��ͨ��һ���б�ά����Щ����Ԫ����ִ���ύʱ�����ǽ��������Χ�ڵ���������Ԫ�����ύ���������������ύ�����������������ɣ�������֮ǰ��IDALInterface���Ѿ�������������صļ�����������������ͬ������������зֽ⣬�����һ�������Ľӿ�ITransation������������£�
01 |
public
interface ITransaction |
14 |
void
BeginTransaction(); |
�����еĴ������£�
06 |
public
bool IsTransaction |
10 |
return
GetTransaction().IsTransaction; |
17 |
public
void BeginTransaction() |
19 |
GetTransaction().BeginTransaction();
|
26 |
GetTransaction().Commit();
|
31 |
public
void Rollback() |
33 |
GetTransaction().Rollback();
|
39 |
List<TransationUnit>
list |
45 |
///
ִ������Ԫ�IJ�����ִ�����ݲ������ύ |
47 |
///
<param
name="unit"></param>
|
48 |
void
Excute(TransationUnit unit); |
55 |
///
<returns></returns>
|
56 |
protected
abstract ITransaction GetTransaction(); |
������������������������Ԫ�������洢����ִ�еIJ���CUD�����о���Ҫ����ִ�е����ݶ���Ȼ��������е�CRD��������ʹ��ǰ�潲���CRD�����ķ�ʽ�������������ɣ���������������Ԫ����ʽ��
04 |
public
class TransationUnit |
16 |
private
CUDEnum _cudType; |
17 |
private
object _model; |
19 |
public
TransationUnit(object model, CUDEnum cudType)
|
�������������У�����ִֻ�������б��еIJ��������ڷ������б��еĵ�Ԫ���ǽ������κδ�������������ֻҪ������ִ�е�����Ԫ�����DZ��뽫ָ���������ͣ�Ȼ���ǻ����Ը�������ͨ��������Ԫ�����������ж��Ƿ��������У�������������У�����ִ�����ݳ־û�����������������У����������ӵ������б��У���Ϊ�������ύʱ�ܻ�ѭ��ִ�������б��е�����Ԫ����Ȼ������ֻ��һ����˼·����ש����ϣ������и��õ��뷨�����Ը��ҽ��������߸���������飬�����Ҿм������ˡ������������������ݷ��ʲ��еIJ��������⣬�������ȥӦ�ԣ���û��ʲô�����ķ����أ�
ǰ�����Ǿ�����˵������3�з�ʽ�������������˵����
ͨ���ֵ�洢ֵ�����仯���У���ɸ��±仯�еIJ������������ٿ��Ա���2��ͬʱ���£����������µ����ݸ�����ǰ���µ����ݣ���Ȼ���ܸ��µ��Dz�ͬ�������У���������ֻ�ṩʵ�����룺
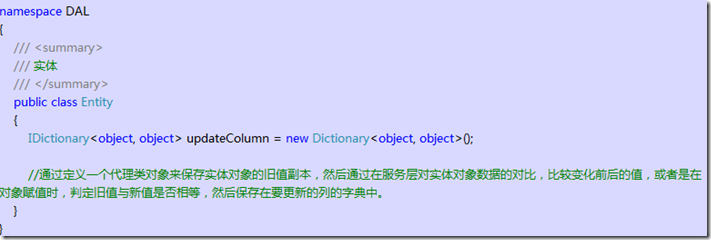
����2��ʵ�ַ�ʽҲ��࣬һ���������ݿ��������һ�а汾�ţ�Ȼ�������ݸ���ʱ�������֮ǰȡ�����Ķ���İ汾�ţ�Ȼ��һ��ͬ������Ϊ��������ɸ��£��������ٿ��Ա�֤���ݵ������ԡ�����һֱ����ͨ��������������ǽ�Ҫ���µĶ�����ֶεľ�ֵ�����ڴ����У�Ȼ�������ɸ������ʱ�����ǽ���������еľ�ֵҲ���ӵ�where��ѯ�����У���������ͨ�����������ķ�ʽ����ά�����ݵ������ԡ��������������룺
01 |
public
class EntityProxy |
��������ļ���������������Ҫ���µ����ݿ��У���ô����ֻ��Ҫ��UPdate����У��������ĸ����ݿ����ֶ������ͺ��ˣ�����������ָ��½�����ص���0����ô��������ʧ�ܡ�ͨ������ļ�����ʽ��������������������Ļ������ǻ����Ƽ������ݿ��������һ���汾�ŵ���ʽ���������£��������Ч����ʽ������ͨ��ʱ�������ʽ�����ɰ汾�š�
�ߡ������ܽ�
������Ҫ�����ˣ����ݷ��ʲ�Ļ������ܣ���Ҫ���ĸ�ְ�𣬼����ݿ���ʲ�ļ����˼·��ʵ��˼·����Ȼ������û���ṩ������ʵ�֣������ʵ�֣������һ���ORMϵ�����ṩ�����Ĵ��룬��ȻĿǰ���ܱ��뽲��ܹ���ͷ�һ�ʰ�����Dz��ֽ�����ϸ�Ľ��⣬�������뱾�ĵ����ݶ��Ƚ�dz��������Ҷ��ܹ�Ѹ�ٵ����գ�������и��õ�˼·������Ʒ�������ô��ϣ������������������⽫����Ī������ҡ�
���ߣ�CallHot
������http://www.cnblogs.com/hegezhou_hot/
���İ�Ȩ�����ߺͲ������У���ӭת�أ���δ������ͬ����뱣���˶���������������ҳ������λ�ø���ԭ�����ӣ��������⣬����ͨ��hegezhou_hot@163.com
��ϵ�ң��dz���л��
| 

