�dz���л��Ҷԡ����ϵ��֮C#ί�����¼����⡷��֧�֣�����Ҹ���Ҵ������ǡ�����ϵͳ�����Ż����ԡ��Ľ��⣬�������ֱ�Χ��SQL�Ż���IIS�Ż��������Ż�[BS�ܹ�]�����ݿ�����Ż��������Ż���
����һƪ�У����Ǿ�Χ��SQL�Ż�����ʼ��ν��⣬Ϊʲô��һ��Ҫ˵SQL�Ż�����Ϊ����Ϊ���dz���Ա�Ļ�����������Ҳ�����DZ���Ҫȥ���յģ���Ȼ��д��
SQL����������Ӧ�Ĺ��ܣ��������Ƿ��ǹ���Щ��������������ݻ��߱�������ʱ������Ч�ʵĴ���ȵļ�����Ҳ���ܶ����Ա����һ��������ϵͳ��Ӧʱ�������ʱ�ͻ�˵������ô��������������̫���ˣ���ô���������ߡ�������ô��ô���������ȴ���ٱ�Թ�Լ���д�Ĵ��롣��ʵ��Щϸ��Ҳ������ν����Ŀ�ģ�ϣ������ڱ�дSQL���ʱ���ܿ��ĸ���Զ�������ǵĸ������
һ���������ʵ�����
�����Ҳ�����������̸������������������ϣ����������ӡ�����������ϣ������ܳ�ֵ����⡰�������������ǽ���ͣ���ڡ���������������������dz����ʶ���档
�������Ǵ����˽�ʲô�ǡ����������ڰٶ��д��롰���ݿ�������ʲô����Ȼ�������ڰٶȰٿ������Ǿ��ܿ��������Ľ���
���ݿ������ñ���һ����ǰ���Ŀ¼���ܼӿ����ݿ�IJ�ѯ�ٶȡ�
��������һ����ѯ��select * from table1 where id=44�����û�����������������������ֱ��ID����44����һ�б��ҵ�Ϊֹ����������֮��(��������ID��һ���Ͻ���������)��ֱ��������������44��Ҳ������ID��һ���ң����Ϳ��Ե�֪��һ�е�λ�ã�Ҳ�����ҵ�����һ�С��ɼ���������������λ�ġ�
������Ϊ�ۼ������ͷǾۼ��������֣��ۼ����� �ǰ������ݴ�ŵ�����λ��Ϊ˳��ģ����Ǿۼ������Ͳ�һ���ˣ��۴���������߶��м������ٶȣ����Ǿ۴��������ڵ��еļ����ܿ졣
����ٶȵĽ��ͣ�Ӧ�����˳������˽⣬���ھۼ������ͷǾۼ���������ҿ��ܻ���������ģ���ʵ��ȥ�ʺܶ��ϳ���Ա�ۼ������ͷǾۼ�����������ʱ�����ǵĻش��ǡ�ȥ�ٶ��Լ���ȥ��,��ʵ���Ҳ����ȥ������������
1���ۼ�����--�ֵ���ƴ�����ң�����һ���ֵ䣬�����Dz��ҡ���ʱ�����ǻ�ֱ�ӷ���"J"��ĸ��ȥ�ң���Ϊ����Ȿ�ֵ��ǰ�A-Z������ȥ���еģ����ԭ�������ݿ���ľۼ��������룬�����һ��������Ϊ�ۼ��������Ǿ�˵������ֶ���һ��˳�����еģ������ݿ����Ҳֻ����һ���ۼ��������������ֶ�������������ֵͬ��ĵط�������ȷ���֤����˾�����е�ϵͳ��ʱ���ֶΣ���Ϊ��Щϵͳһ������ܳɽ���ǧ��������ݣ�����������ڽ���ʱ�������þۼ��������Ǿ�˵�������ѯ��2010-3-16���Ľ���¼ʱ�����ݿ⽫���϶�λ����Щ��¼�ϣ�����ȥ����������ݱ���
�ۼ���������ʹ�õ��ֶΣ��ֱ�Ϊ
a.ʹ����������� BETWEEN��>��>=�� < �� <=������һϵ��ֵ
b.���ش��ͽ������
c.ʹ�� JOIN �Ӿ䣻һ������£�ʹ�ø��Ӿ��������С�
d.ʹ�� ORDER BY �� GROUP BY �Ӿ䡣
2���Ǿۼ�����--�ֵ���ʻ���ƫ�Բ��ң�����һ���ֵ䣬�����Dz�֪��һ���ֵĶ���������������������ƫ�Ȼ���ҵ�����ֵ�ҳ�룬����ҵ�����֡������ݿ��ֶ������÷Ǿۼ��������Ǿ�˵��������Щ�ֶ��еļ�¼�ж������ǵ�������ַ���ڲ�ѯ��¼ʱ����ֱ�Ӷ�λ��������¼��
̽�����⣺
��������SQL2005�У���һ���ֶ�����������ʱ�����Ὣ�������Ĭ�����óɾۼ��������������кô������ǿ������������������ݿ��а���ID���������������Ҿ����Ⲣ���Ǻܺ������ǶԾۼ�������һ���˷ѡ��Զ������ۼ������������Ǻ����Եģ���ÿ������ֻ����һ���ۼ������Ĺ�����ʹ�þۼ�������ø����������ǰ��̸���ľۼ������Ķ������ǿ��Կ�����ʹ�þۼ����������ô������ܹ����ݲ�ѯҪ��Ѹ����С��ѯ��Χ������ȫ��ɨ�衣��ʵ��Ӧ���У���Ϊ����ID�����Զ����ɵģ����Dz���֪��ÿ����¼��ID�ţ��������Ǻ�����ʵ������ID�������в�ѯ�����ʹ��ID�����������Ϊ�ۼ�������Ϊһ����Դ�˷ѡ�
�����Ҿ��������ڶԺ������ݱ�����������ʱҪ���أ����Ҳ���Զ�������ⷢ���Լ��������
������ǻص������㣬����ΪʲôҪ��������������Ϊ�˲�ѯ��Ѹ�٣����ٳ��ֲ�ѯ��������˻�˵����������ϵͳ�У�û�н������ٶ�Ҳ�ܿ�Ŷ���������ѯ��������û�дﵽһ������һ���������ﵽ������ÿд��һ����������SQL�������������벻�����鷳��
�ǵ��ҵ�һ����ʶ����������Ҫ�Ե�ʱ�����ڿɿڿ��ֹ�˾������ʱ��ʱ�ұ����䵽STM��������Ͷ��ϵͳ���У���ʱ��ϵͳ��PHASE
ONE �Ѿ���ȫ��7����������������ʹ�ã�����������һ������ۼƣ��������һ��KPI���ݱ����У��ٶ��ر�������KPI�������ǿ��ֹ�˾�߲���Ҫ�鿴�ģ���������Ա���Ĺ���Ч�ʣ��߲��ǵ�ʱ�Ͷ����ǵ�ϵͳӡ��dz��Ҫ֪���ڴ�˾һ�������˸߲㣬�����Ժ�ĺܶ������ޣ���ʱ�ҵ�һʱ�俴������д�Ĵ洢���̲��Ҳ鿴�����ݿ��������������I/O���ֻ��3000�����ң����ݿ�Ҳֻ��10W�����ҵļ�����Щ����������һ���µ����ݱ�����ѯ�ﵽ6�ֶ��ӵģ�Ȼ���Ҳ鿴�����KPI�Ĵ洢���̣��������ǵ���SELECTǶ��ʱ��JOIN�ı�֮��������û�������������������ǵı���SQLǶ���Ǹ��˻�������Ҳ������Ƕ���������һ��ȫ������̡������Ǹղ鿴����洢���̵�ʱ�����Ƕ�û�й�ע��ֻ�������Ĺ�ϵ��������һ��ѵķ�����������Щ������ԭ�еİ汾�Ķ���̫�����ز���ˡ��������ͨ���о�SQL�IJ�ѯִ�мƻ�������Ƕ�ײ�ѯ�����ĵ���Դ�ر������ͼ��
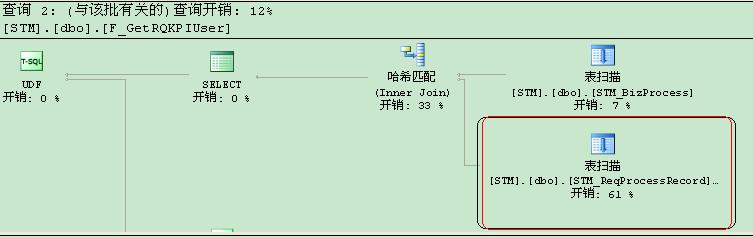
������Dzŷ���ԭ���ǹ������Ĺ�������û��������������֮��֮ǰ��6���Ӽ��ٵ���6���ӣ���ԶԶ��������Ԥ�ڵ������������֪��û������֮ǰ�����ݿ����˶��ٵ�ȫ���������
��Ȼ����֪������������Ҫ�ԣ����Ǿ�Ҫ���ճ���SQL��д��ʱ�����IJ�Ҫ�ƿ��������������Ҿ��г����ֵ�������ʧЧ��SQLд��
1���������ֶ���ʹ��OR����IN
����Select * from table1 where id in (2,3)�������ߡ���Select
* from table1 where id=2 or tid=3
��Щд��������id����ʧЧ������ȫ�����飬��Ȼ������û�дﵽ������ʱ���㰮��ôд�����ԣ�ֻҪʵ�ֹ��ܣ�һ���ﵽ������һ��ϸ�ھ����ɰ�
�������һ��
Select * from table1 where id = 2 UNION Select * from
table1 where id = 3
��Ȼ���Ҳ�����ñ��д����ʵ�ֹ��ܡ�
ע������Ľ��� �dz����ġ�
2��ͨ���%���ַ����Ŀ�ͨʹ��������ʹ��
����Select * from table1 where name like ��%�š�
�����name�ֶ�������������������д������������ʧЧ
ע��Select * from table1 where name like ����%�����ᵼ������ʧЧ
3���Dz�������������������ʹ��
����NOT��!=��<>��!<��!>��NOT EXISTS��NOT IN��NOT
LIKE�ȶ�����������ʧЧ
������������I/O����
��ʵ�ϣ��ڲ�ѯ����ȡ�������������ݼ�ʱ��Ӱ�����ݿ���Ӧʱ���������ز��������ݲ��ң�����������I/0��������ʱ��������SQL����д��Ҫע��2������
1�����⡰SELECT *������
������дSQL���ʱ����Ϊ�˷��㣬������"SELECT * FROM TABLE"
����ʵ����һ���dz����õ�ϰ�ߣ����ﵽ����������֮��һ���ֶΣ��ǽ���N���ӡ�
2��ʹ�á�TOP������������ȡ
���ǵ����Dz�ѯ�������ݵ�ʱ�����ѯ�����10W�У���ʱ�����Ǿ���Ҫ�����ҳ�ؼ������з�ҳ���������õ�ԭ������TOP��ʵ�ֵġ�
ע����Щ���۴����ý��Ű������ݱ�����֤һ�£��Ͼ����ֲ�������������һ���������ĸ��
��������һЩͳ�ƻ��߱�����ʱ��80%��Ч�����ⶼ�ǿ���ͨ������������������SQL���Ż������������Ч��Ҳ�Ƿdz������ԡ���ι���SQL���Ż��ͽ��������ʵ���Ǻܶ�ܶ�����������Ҫע�������û���о٣��ⶼ��Ҫ�������ճ��ı����ȥϸϸ����ᡣ
| 

