.NET
ҵ���ܿ���ʵս DAL���ع�
1. ȷ��DAL�ĽӿڵĶ��塣
֮ǰ�ڿ���DAL�У������һЩ˼�룬Ҳ�����һЩ�ӿڡ����ھͰ�DAL��һЩ�������������˵�ǡ����ơ���������˵�����еĴ��붼ʵ�֣����ǰѸö���Ľӿڣ������ö�������Richard��Ϊ�����һ���ܹ�����Framework��ʱ��ʼ�ǽӿڵĶ��壬����ø���֮�佻���Ľӿڣ�Ȼ����Ǿ�������ʵ�֡�
��Ϊ�����Framework��ʱ������Ҫ�������Framework��ʹ������˭��ϣ��������ô����ʹ�ÿ������������Framework�������Richard�����ף�Framework��ʹ���߾����Լ���˾��Ŀ�����Ա�����һ�Ҫʹ�ÿ�����ʹ�þ����ķ��㣬��Ҫ����ȥ����һЩ�ĵ�����þ��ǰ�Framework�������������һ�¾�ʹ�á�
��Richard��Ƶ�Framework�У���DAL���ԣ����ϣ��DAL����DataTable,DataReader�ȸ�BLL����ô��Ҫ���õĽ���ֻ��ָ�����ݿ�������ַ��������ϣ��DAL���ص�����ʵ���BLL,��ô�͵ð�һ���ŵı�ӳ���Ϊʵ�壬Ȼ������Щʵ��̳�IDataEntity�ӿھ�����(����ʵ�������ORM���ߣ������Լ���д����)��
Richard˼����֮ǰ��DAL����ƣ��ڴ�������һЩ�Ľ���
���Ⱦ��Ƕ���IDataContext��������ƺ����⣺֮ǰ������Ƕ�����IDataContext,Ȼ���ò�ͬ�ķ�ʽʵ������ӿڣ���LinqDataContext.Provider������Linq�ķ��������ؽ��(DataResult)������Richard��ΪIDataContext��ʵ���������������ݿ�ģ����Է��صĽ����Ӧ���Dz�������֮��Ľ������Update�����ͷ�����Ӱ������������Ƿ���³ɹ��������Ƿ�Ҫ��һЩ�������Ϣ��װ���ظ�BLL���Ͳ���IDataContext��ʵ���ߵ������ˡ�����Richard�����ǵ�����Ҫ��һ���̶���֧��ԭ����ADO.NET�������ADO.NETԤ���ӿڡ�
���ڴˣ�Richard�Ͱ�IDataContext����Ϊһ���ӿ�������Ȼ���ٶ�����IDataEntityContext����IDataTableContext���̳�IDataContext,���ǵĹ�ϵͼ���£�
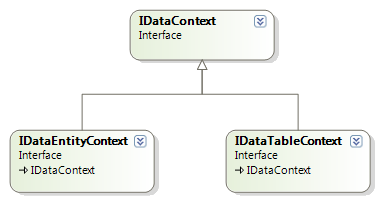
����IDataEntityContextʹ��Linq��Entity Framework��ʵ�֣���IDataTableContext������ADO.NET�ķ�ʽ��ʵ�֡�
IDataEntityContext�ӿڵĺ�ϵ�������ж����һЩ������࣬���������ġ�������һ��Ҫ��ľ��ǣ�ICriteria����������������Ҫʵ�ֵĽӿ�(��ѯ����Ҳ�����������һ��)�����磬���Ը�����Ӧ������ɾ�����������ݡ�
����
/// <summary>
/// ���е�����ʵ��ִ����ʵ��������
/// </summary>
public interface IDataEntityContext:IDataContext
{
TEntity Add<TEntity>(TEntity entity) where TEntity
: IDataEntity;
List<TEntity> Add<TEntity>(List<TEntity>
entityList) where TEntity : IDataEntity;
bool Update<TEntity>(TEntity
entity) where TEntity : IDataEntity;
bool Update<TEntity>(List<TEntity> entityList)
where TEntity : IDataEntity;
bool Update(ICriteria condiftion, object value);
bool Delete<TEntity>(TEntity
entity) where TEntity : IDataEntity;
bool Delete<TEntity>(List<TEntity> entityList)
where TEntity : IDataEntity;
bool Delete(ICriteria condition);
int GetCount(ICriteria condition);
List<TEntity> Query<TEntity>(ICriteria
condition);
List<TEntity> Query<TEntity>(ICriteria
condition, int pageIndex, int pageSize, ref int entityCount)
where TEntity : IDataEntity;
List<object> Query(ICriteria condiftion);
}
������Ƕ���һ�� List<object> Query(ICriteria
condiftion);������֮���������������Richard���ǵ������ܿ�����Ա��Ҫֱ���Լ�дSQL���ȥִ�У���select
avg(Count),sum(Name) from Customer...��������Ա����д�������䣬���Է���һ��ʵ�����ʵ���ͷ���һ��List<object>��
����һ����ǹ��ڲ�ѯ����ĸĽ�����ǰ����ֻ�Ƕ����˲�ѯ����Ľӿڣ�������ICriteria
�ӿ��ж��������������һ����������������������ڶ����ݲ����Ƿ������������档
/// <summary>
/// ���е���������Ҫ������ӿڼ̳�
/// </summary>
public interface ICriteria
{
string Name { get; set; }
bool IsCache { get; set; }
bool IsTransaction { get; set; }
}
֮��Richard�ֶ�����һ��IDataProvider���ӿڣ���������
��
����
/// <summary>
/// �����ṩ��Ҫʵ�ֵĽ��
/// </summary>
public interface IDataProvider
{
DataResult<TEntity> Add<TEntity>(TEntity
entity) where TEntity : IDataEntity;
DataResult<TEntity> Add<TEntity>(List<TEntity>
entityList) where TEntity : IDataEntity;
DataResult<TEntity> Update<TEntity>(TEntity
entity) where TEntity : IDataEntity;
DataResult<TEntity> Update<TEntity>(List<TEntity>
entityList) where TEntity : IDataEntity;
bool Update(ICriteria condiftion, object value);
DataResult<TEntity> Delete<TEntity>(TEntity
entity) where TEntity : IDataEntity;
DataResult<TEntity> Delete<TEntity>(List<TEntity>
entityList) where TEntity : IDataEntity;
bool Delete(ICriteria condiftion);
int GetCount(ICriteria condition);
DataResult<TEntity> GetOne<TEntity>(ICriteria
condition) where TEntity : IDataEntity;
DataResult<TEntity> GetList<TEntity>(ICriteria
condition) where TEntity : IDataEntity;
DataResult<TEntity> GetPageData<TEntity>(ICriteria
condition, int pageIndex, int pageSize, ref int entityCount)
where TEntity : IDataEntity;
List<object> GetCustomData(ICriteria condiftion);
}
֮����Ҫ��������ӿڣ���ʵ Richard��������ʵ����IDataContext����̤̤ʵʵ��ȥ���ײ�����ݲ������������ݲ���֮��Ľ����ʲô��ʽ��BLL������IDataContext��ʵ���������ģ�������IDataProvider��ʵ���������ġ�
��IDataProvider��ʵ�����ڵײ���ǵ�����IDataContext��ʵ���ߵķ�����Ȼ����IDataProvider�У������ṩ��һЩ�����Ѻúͷ���ʹ�õķ����������BLL��ֱ�������ľ���IDataProvider��������IDataContext��
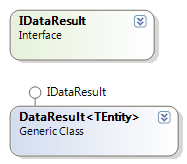
���⣬����IDataProvider���ص�DataResultҲ����һЩ�ģ�������ص�������ʵ�壬��
ʹ�õ���IDataEntityContext���ṩ�ײ�����ݲ�������ôDataResult<TEntity>��û������ģ��������ʹ�õ���IDataTableContext����ô����DataResult<TEntity>�Ͳ����ˣ���ΪIDataTableContext��ѯ�������ܷ��ص�DataTable,����DataReader.���ԣ��������ҶԤ����һ���ӿڣ���IDataProvider���صĽ��ʵ��IDataResult�ӿڣ���ôataResult<TEntity>�̳�����ӿڣ���Ҫ������������ʵ�壬���£�
.NET ҵ���ܿ��� ҵ����������
1. DAL��BLL֮ǰ��Mapping
���ȣ�ҵ���������ʵ�����һ һ��Ӧ�Ĺ�ϵ�����仰˵������һ��ҵ�����һ����Ӧ���ݿ��е�һ�ű���ҵ��������ֻ��ʹ������ʵ���е����ݶ��ѣ�����һ��ҵ�����е������������Զ������ʵ�塣
ÿ��ҵ��������Լ���һЩ���Եģ�������������ʵ�����DataTable����ʽ��DAL��ȡ֮��BLL���ʹ����Щ���ݣ�BLL�������Щԭ��������ʵ�屩¶��UI��BLL����UI��Ҫ���õ�����װ�뵽�Լ��������С�
��������������о���һ����ֵ�Ĺ��̣����߳�Ϊmappingӳ�䡣��Richard�������뷨����Ŀ���ͬ�¾�������ΪʲôҪ������ô���ӣ���Ҫһ
һ �ĸ�ֵ��Ϊʲô��ֱ�Ӱ�����ʵ���UIʹ�ã�Ϊʲôһ��Ҫ���м���ôתһ���أ�
Richard������һЩԭ��
1. ���ֱ�Ӱ�����ʵ�����UI����ôUI�Ƕ˾ͺ����DAL�ˣ��Ժ����ݷ��ʷ�ʽ��ADO.NET
����EF����ôUI �Ͷ��ˣ��ֻص���ǰ�ˡ�
2. ��BLL�п��ԶԴ�DALȡ���������ݽ���һЩ��������ת����ʽ�����㣬��ϵȡ�
Richard�뵽��BLL��DAL���Ľ��ҵ�����в���������ʵ��������á��������֮������Ծͺܴ��ˡ����ﵽ��Ч�����ǣ�ͨ�����ã�����ҵ����ÿ�����Ե����ݵ���Դ�������ҵ������ȫ��֪����Щ���ݵ�����Դ���ĸ�������Щ����ʵ�塣
����ȷʵ����Richard�˷ܲ��ѡ�
2. ���Mapping
�����뷨ͨ�������ļ�����������һ��Product��ҵ���࣬�������£�
public class ProductBL
{
public string ProductName { get; set; }
public decimal Price { get; set; }
public string Description { get; set; }
}
��ô��θ���Щ���Ը�ֵ��ͬʱҲ����������ʵ�塣Richard�������ļ���ʵ�ֵģ�����Richard��Լ���ˣ������ļ������־��ǡ�ҵ��������֡�+��Mapping.xml��.����Product�������ļ�����ProductBLMapping.xml
<?xml version="1.0" encoding="utf-8"
?>
<BusinessModel name="ProductBL" mappingTo="DAL.ProductEntity"
>
<property name="ProductName" mappingTo="Name"
type="System.String"/>
<property name="Price" mappingTo="Price"
type="System.Decimal"/>
<property name="Description" mappingTo="Description"
type="System.String"/>
</BusinessModel>
Ȼ�������е�ʱ���ͨ����������ֵ��
�������������ˣ�
1. ÿ�ζ���ͨ����������ֵ�����ܺܳ����⡣
2. ��������ļ����������Ժܲ����㡣
3. ��δ���һ��ҵ�����Ӧ�Ը�����ʵ���������磺
public class ProductBL
{
public string ProductName { get; set; }
public decimal Price { get; set; }
public string Description { get; set; }
//����CustomDAL
public string CustomerName { get; set; }
}
���Ǻô������ԣ�
1. DAL��BLL����
2. �ܱ��ڲ�ѯ�����ʵ�֡����磺��UI����д��
ICriteria condition=CriteriaFactory.Create(typeof(ProductBL).Where("ProductName",
Operation.Equal,"book");
��ȻProductName��ҵ����ProductBL�����ԣ��ڲ�ѯ����������ΪSQL����ʱ��Ϳ�������ProductBLMapping.xml������SQL��
��ע��С���������룬�����˼��������.NET���ĸ���Դ��ܣ���
�������ܷ��棬Richard�������������
�ڵ�һ��Mapping��ʱ�Ͱ���Щmapping����Ϣ�����ھ�̬�ֵ��У��´���mapping��ʱ�Ͳ����ٶ������ļ��ˣ����Ҷ��ڴ��е��ֵ䡣
��������������ҵ��������ӣ��ڴ�ʹ��Ҳ�Ӵ��Ҹ�ֵ��ʽ���Ƿ��䡣
3. �ٴι�˼
Richard���ſ��ǣ���δ���һ��ҵ�����Ӧ�Ը�����ʵ�����������������ļ���Ϊ�ˣ�
<?xml version="1.0" encoding="utf-8"
?>
<BusinessModel name="ProductBL" >
<property name="ProductName" mappingTo="DAL.ProductEntityName"
type="System.String"/>
<property name="Price" mappingTo="DAL.ProductEntityPrice"
type="System.Decimal"/>
<property name="Description" mappingTo="DAL.ProductEntityDescription"
type="System.String"/>
<property name="CustomerName" mappingTo="DAL.CustomerEntity.Name"
type="System.String"/>
</BusinessModel>
�������������ǽ���ˣ��������ܵ�������Ȼ���ڡ�
Richard�ֿ�ʼ���Ǹ��Ӻõķ�ʽ��
.NET ҵ���ܿ��� ҵ���Mapping��ѡ�����
1�� �ڶ���Mapping������
Richard˼���������ļ��ķ�ʽ����Ȼ�������ļ�ȷʵ���������Ҳ���д��۵ģ���ΪFramework��ù�˾�Ŀ�����Աʹ�ã���������ú��ߵ�ѧϰ�ɱ�ʹ��Frameworkʧȥ�˺ܴ�����塣
Richard��ʼ˼���ˣ��뵽�˻���һ�����mapping�ķ�ʽ������ֱ��һ�����ĸ�ֵ���磺
����
public class ProductBL
{
public string ProductName { get; set; }
public decimal Price { get; set; }
public string Description { get; set; }
public void Mapping(m_Product productEntity)
{
this.ProductName = productEntity.Name;
this.Price = productEntity.Price;
this.Description = productEntity.Description;
}
}
�����ԣ�������̺ܼ�ȴ�ܷ�����
��֮ǰʹ�������ļ��ķ�ʽ��ȣ�
�ŵ㣺1. ����ʹ�ú�����
2. ���ڵ���
ȱ�㣺1. ������ʵ����ϵĺܽ�(��ʵ�ⲻ����ȱ�㣬���Ǻ�֮ǰ�����ļ��ķ�ʽ�Ƚ϶�����Ϊȱ��)������Ĵ����о�ֱ��ʹ����m_Product.����ҿ��Բο�֮ǰһƪ�������������ļ�����ȱ�㣩
2. ��д�Ĺ��̺ܷ�����ȫ�����ֶ���mapping��
���һ��йؼ���һ����ǣ���ѯ������ô�������յ�SQL��䣿
���磬����Ĵ��룺
ICriteria condition=CriteriaFactory.Create(typeof(ProductBL).Where("ProductName",
Operation.Equal,"book");
������������ļ���mapping��ʽ����������������ļ���ProductBL��ProductName��Ӧm_Productʵ���Name�ֶΣ�Ҳ���Ƕ�Ӧ���ݿ��m_Product��Name�ֶΣ���Ϊ��BLL��ʹ�õ���ͨ��linq����Entity
Framework���ɵ�m_Productʵ�壩������IJ�ѯ���������������select * from
m_Product where Name=��book������䡣
Richard�뵽NHibernate��ʵ�֣���NHibernateҲ�в�ѯ������NHibernate�еIJ�ѯ�����ʵ��Ҳ������NHibernate���Ǹ�mapping�������ļ��ġ�
������˵û�в�ѯ����Ͳ��У����ò�ѯ������Linq��Entity FrameworkҲ�ǿ���ʵ�ֵġ��������ݲ��û�С��Բ���Ӧ��䡱�˵�Ч�������ҿ�����ԱҪ���ո��ֵ����ݷ��ʼ�����ADO.NET,
Linq�ȡ������Բο�.NET �ֲ�ʽ�ܹ�����ʵս֮�� ���ݷ�������һ���˼��һ�ģ���
����Richard���ٵ�������ǣ�
1. ���������ļ�mapping��������ѯ����Ͳ���ʵ�֡�
2. �ֶ����������mapping���ظ����Ͷ���
Richard˼���Ƿ���õķ�ʽ�����������⡣���ǵ����ַ�ʽ�Ͳ����ˡ�
3. ������Mapping������
������mapping�ķ��������ۺ���֮ǰ����mapping���ŵ㣬���ܿ������ǵ�ȱ�㡣
Richard�뵽����ֶ�mapping�ķ������ǣ�ͼ�λ��Ĵ���������������д���롣����Ҫ��취�������ݿ��ֶε�һЩ��Ϣ��
���ɵľ��ǣ�linq��EF���ɵ�ʵ���е��ֶ���Ϣ�ͷ�ӳ�����ݱ��ֶε���Ϣ����������������������IJ�ͼ����Visio�����ģ�������Richard���뷨����ʵRichardҲû��һ�¾Ϳ���������Ĺ��ߣ�һ�л��Ǵ�����ƽΡ�
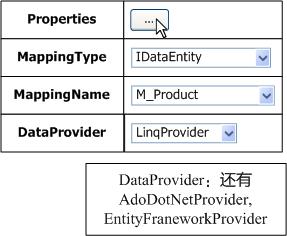
Richard��Ƴ����Զ����ɴ���Ĺ��ߣ����ߵĿ���Richard˼�����ˣ����Բ������ʵ�ַ�ʽ��һ��Windows����Ҳ�����DSL���߿���������DSL��ѧϰ���̻����е㸴�ӵģ���
ע����Ȼ˵�Ǵ������ɹ��ߣ���ʵһ��ʼRichardҲ����ĺܼ�����һ��д�ı��IJ�����
������Ľ����У�ѡ��Ҫ���ĸ�����ʵ����mapping������ͨ��ѡ��MappingName����ʵ�֡�Ȼ������Properties����ť�����������µĽ��棺
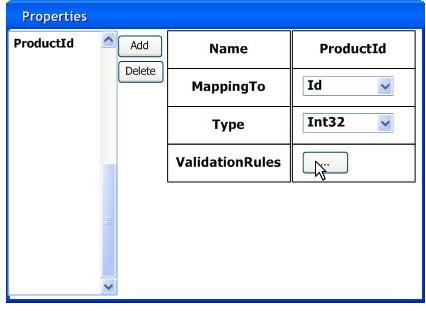
����һ��ר����������mapping�Ľ��棺�����Add����ť������һ��ҵ��������ԣ�Ȼ���á�MappingTo��������������Ե����ݴ�����ʵ������Ǹ��ֶ��л�ȡ����ѡ������ʵ���ֶε�ʱ��Ҳ�����ѡ������ʵ����ֶ���Ϣ��������������֮��IJ�ѯ����ʹ�á�
����˼·Richard�Ѿ����ˡ����ڵ�������ǰ�����ѡѡ�������ֶ���Ϣ������������һ��ú�ҵ��������Զ�Ӧ�����磬Id��Ӧҵ����Product��ProductId,���������������ԡ�
��mapping��ʱ��һ������ҵ�����ж���һ�����ԣ�Ȼ��ֵ��
public string ProductId { get; set;
}
this.ProductName = productEntity.Id;
Ϊ�˱�������ʵ���ֶε���Ϣ��ҵ���������������Ϊ�����ˣ�
public static readonly PropertyInfo<int>
ProductIdProperty = RegisterProperty(
typeof(Product),
new PropertyInfo<int>("ProductId",typeof(M_Product)","Id"));
public string ProductId
{
get { return ReadProperty(ProductIdProperty); }
set { LoadProperty(ProductIdProperty, value); }
}
����Ĵ���ͨ�����ɵķ�ʽ�ͱȽϷ��㣬��������������������и�����������;����һ����WPF���������Ժ���ȷʵ˼·Ҳ�Ǵ�WPF��������ġ������ơ�Mapping���ԡ���
�����д��������ǶԲ�ס��ң���Ϊ��ƪд�ıȽϵĆ��£����һ�û��д�ꡣ��ƪ����Mapping���Ե�ʵ��ԭ����ԭ����ΪʲôҪ����ProductIdProperty����������ʽ��
| 

