(注:本文只是简简单单的截几幅图而已,要想更深入的学习和了解hadoop框架和mapreduce模式,或者对淘宝的数据魔方感兴趣的话,尽可参考此文:从Hadhoop框架与MapReduce模式中谈海量数据处理。)
最近对海量数据处理发生了不小的兴趣,特此从一些精彩文章中摘取几幅精彩的图片或片段,拿来给大家分享。所谓奇文共欣赏,好Architecture共品之。至于各位能从图中是窥得半点经验,还是一图以窥全貌,则不在我之责任,全在于读者怎么去解读这几幅精彩的架构图了。
所以,本文在选取一些架构图之后,只配以最简单的文字,个中内容,读者自行品味之。如果有任何问题或建议,欢迎不吝指正或畅所欲言。谢谢。
1、淘宝海量数据产品技术架构
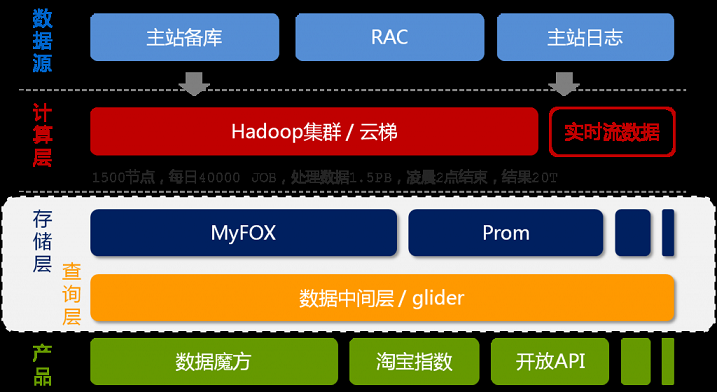
上图是淘宝的数据魔方。按照数据的流向来划分,淘宝的数据产品的技术架构分为五层(如上图所示),分别是数据源、计算层、存储层、查询层和产品层(图摘自《程序员》8月刊)。
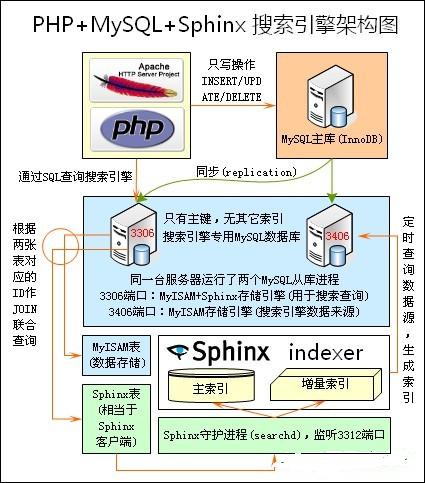
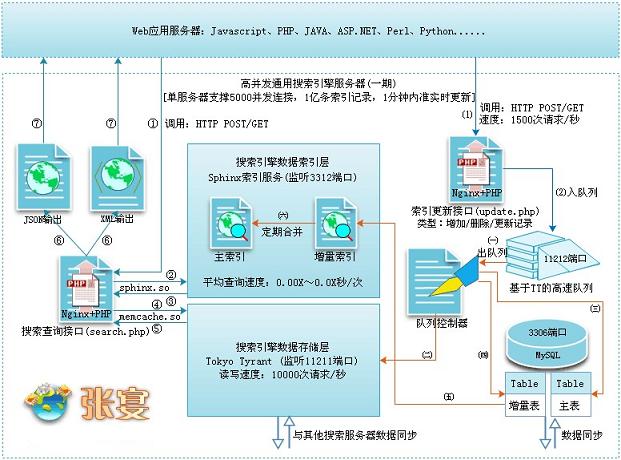
2、搜索引擎架构图
3、Facebook架构
3.1、架构概览
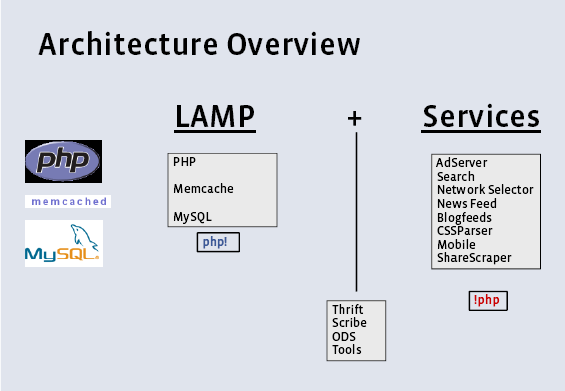
设计原则
- 尽可能的使用开源软件,并且在需要优化的时候进行优化
- Unix 哲学。包括,模块化原则;整合化原则;清晰化原则等
- 任何组件具备扩展性;最小化故障影响;简化,简化,简化(本段文字摘自DBA
nots)。
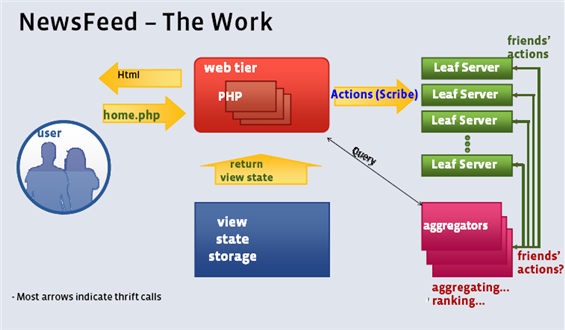
3.2、Facebook NewsFeed 的架构示意图
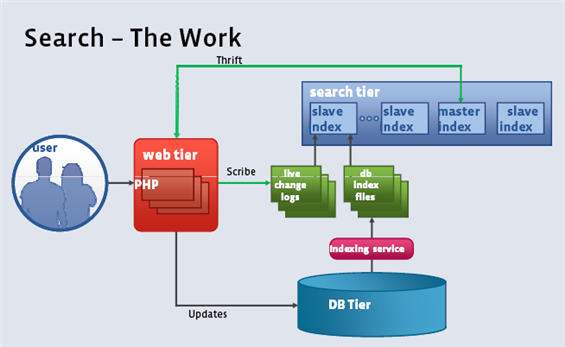
3.3、Facebook 搜索功能的架构示意图
@hawksoft:处理海量数据的基本思路就是分而治之的策略和流水线作业。虽然从单个的计算效率来说,单台计算机的计算效率应该是最高的,但单台计算机的吞吐量有限。分布式计算的优势就在于虽然牺牲了部分计算能力,但由于人多力量大,而且节点间配置灵活,可互补,比单纯的增加计算机数量的模式要具有很大的优势。分布式计算的关键点就在于切分、调度、冗余和通信.
这些东西原理容易知道,但实践很难,因为一般人很少有机会。至于更多有关Mapreduce的介绍,还可参考:从Hadhoop框架与MapReduce模式中谈海量数据处理
,与MapReduce技术的初步了解与学习。完。 | 

