��Щ��������Ϊ���������ϵIJ��쾭����ܾ����ö����ϵӳ�䣨ORM�����������κ���ʽ�ij���һ����ʹ��ORM���Ҫ��һЩ�������Ϊ���ۣ�����ʵ�ϣ�ʹ�þ���ǡ�����ŵ�ORM����дԭ�������ݷ��ʴ����������ϻ����е�һƴ�ġ���Ϊ��Ҫ���ǣ�ʹ�úõ�ORM��ܸ������ź��Ż����ܣ���дԭ�����ݷ��ʴ��������ܵ�����������ѵöࡣ
�����е�ʾ��������Mindscape��LightSpeed ORM֮�ϣ����ǽ����ʾ�����۳��������⼰����������
N+1����
������������webӦ�ó����еĹ��ڶ����б���������������������Ҫ���۵����⡣�������Dz���Ҫ�鿴������ͬʱ��Ҫ�鿴ÿ�������Ŀͻ���Ϣ�����û����������Ļ�������Ҳ����д�������Ĵ��룺
var overdues = unitOfWork.Orders.Where(o
=> o.DueDate < today);
foreach (var o in overdues) // 1
{
var customer = o.Customer; // 2
DisplayOverdueOrderInfo(o.Reference,
customer.Name);
}
��δ�����������ν��N+1���⡣��ȡ�����б���������ע��1������Ҫһ�����ݿ��ѯ���������Ŵ�����ȡ�б���ÿ��������Ӧ�Ŀͻ���Ϣ����ÿ�λ�ȡ���ý���һ�����ݿ��ѯ�����ԣ�����ܹ���100�����ڶ���������͵�ִ��101�����ݿ��ѯ������1�����ڼ��ع��ڶ������ϣ�����100�����ڼ���ÿ�������Ŀͻ���һ����˵����N�������͵�ִ��N+1�����ݿ��ѯ���������N+1�������Ƶ�������
��Ȼ�������൱���͵�Ч�ġ����ǿ���ͨ��Ԥ�ȼ��أ�eager loading��������������������⡣��������ܽ����й����ͻ��ļ�����Ϊ������ѯ������һ���֣���ͬһ�����ݿ�����н��У���ô����Կͻ���Ϣ�ķ��ʾ�ֻ�Ƿ��ʶ������Զ��ѡ�������Ҫ��ѯ���ݿ⣬Ҳ��û��N+1���⡣
ʹ��LightSpeed�����ǿ���ͨ����EagerLoading����ΪTrue�����ߣ�����дҵ��ʵ����Ӧ��EagerLoadAttribute����Ԥ�ȼ��ع��������ݡ���LightSpeed��ѯ������Ԥ�ȼ��ع�����ʵ��ʱ�����ˡ����塱ʵ�屾����������������Ӧ��SQL������Բ�ѯ������ʵ�塣
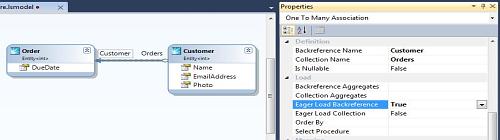
������������У����������Order.Customer������Ӧ��Ԥ�ȼ��أ���ô�����Dz�ѯOrderʵ��ʱ��LightSpeed����������ڼ���Orderʵ���Customerʵ���SQL��䣬�����������ͬ��������������ֻҪ�����Ķ����Ϳ��Խ�101�����ݿ���ʼ���Ϊ1�Ρ�
ORM��ԭ�����ݷ��ʴ���֮���ӳ��
�ܵ���˵�������ΪʲôORM��ܾ������ܵ����ϵ����ơ�������ڶ���ҳ��ʹ������д��SQL�����ֶ������ݿ���ʲ��е����ݸ��Ƶ�ʵ������У���N+1�������ʱ���㲻��Ҫ����SQL��䣬��Ҫ�������ӳ������Դ������ֽ�������������ϵ���������ǵļ����ӣ���Щ������������ܶ࣬�����ҳ��Ҫ�Ӻܶ����ݿ���ж�ȡ���ݾͲ��������ˡ���Ҫ����һ��ѡ���Ӧ��һ��attribute�鷳�ö࣡
�ӳټ��أ�Lazy Loading��
�����Ķ���ҳ���������һ��DZ�����⡣�����Ǽ���Customerʵ����һ��������ͼƬ��Photo���ԣ����������۲�������������飬�ͻᷢ�����Ǻ�������ģ������ڶ���ҳ�治��Ҫ����Customer.Photo���ԣ�����Ƭ��Customer�������������ֵһ�������ᱻ���ء������Ƭ�ܴ��⽫���ĺܶ��ڴ棬������Ҫ�ܳ�ʱ����ܴ����ݿ���ȡ��������Ƭ���ݡ����������Щʱ�䶼�˷��ˡ�
�����������ķ�������Photo�����ӳټ��ء�������˵����ֻ�����Ա�����ʱ�ż������ݣ��������ڼ���Customerʵ��ʱ�ͼ��ء���Ϊ���ڶ���ҳ�治����Photo���ԣ�Ҳ�Ͳ�����ز���Ҫ��ͼƬ��������ȷʵ��Ҫ��Ƭ��ҳ�棬����ͻ����ҳ�棬��Ȼ��ֱ�ӷ���Photo���ԡ�
��û��һ���ı�ʶ�����������������ӳټ��ػ��Ƶ����ԡ���������Խ����Ա�ʶΪnamed
aggregate��һ���֣�ͨ�������Ե�Aggregate����������ƣ�������������Ĭ�����ӳټ��صġ���һ�������ǻ���ϸ�����������

�����������Photo���Ե�AggregateΪ��WithPhoto�������ڹ��ڶ���ҳ���пͻ���Ƭ�Ͳ��ᱻ���أ��������DZ������ڴ��˷ѣ����������ݼ������������ҳ������ٶȡ�
Named Aggregates (Includes)
Named Aggregates (Includes)
������N+1���⼰��������������ķ���ʹ���ǵĹ��ڶ���ҳ�������Ѿ�������ݶ��ˡ�����������������ܻ����վ������ҳ���������Ӱ�졣�����������Ƕ�����ϸҳ����������ΪOrder.Customer��������Ԥ�ȼ��صģ����¶�����ϸҳ��ᱻ������Ҫ��Customerʵ����������ۡ������������ƺ����������Ƿ�Ԥ�ȼ���Customer������Щҳ������ܲ��ߣ�
���������ǣ�Order.Customer�����ڹ��ڶ����б�ҳ��Ӧ��Ԥ�ȼ��أ����ڶ�����ϸҳ��Ӧ���ӳټ��ء����ǿ���ͨ����Customer���Գ�Ϊnamed
aggregate��һ�������ﵽ��Ŀ�ġ�
Named aggregate��ʶ���ҳ����Ҫ�������Щ���֡�һ��named
aggregate������Ԥ�ȼ��صĶ����������������ɡ��������ѯҪ��Ԥ�ȼ�����Ԥ�ȼ��أ�������ӳټ��ء���named
aggregate��LightSpeed���õ������ЩORM����ṩ��ͬ������������includes����
Ϊ��ʹOrder.Customer��Ϊnamed aggregate��һ���֣����ǽ�Eager
Loading���û�Falseֵ����ʹ�ö�����ϸҳ���ܸ�Ч��ת�����ţ�Ϊ��ʹ���ڶ����б�ҳ��Ҳ�ܸ�Ч��ת���������ӡ�WithCustomer����Order.Customer��Aggregate���С�
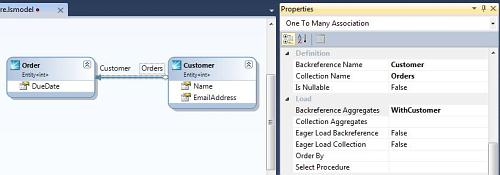
�������������Ĺ��ڶ����б�ҳ�棬ָ��WithCustomer aggregate������LINQ��ѯ�ϡ�ʵ�ַ�ʽ�ܼ�ֻҪ��LINQ��ѯ���������WithAggregate�������þͿ����ˣ�
var overdues = unitOfWork.Orders
.Where(o => o.DueDate < today)
.WithAggregate("WithCustomer");
����ʵ��ķǶ���������ԣ��˷�ʽͬ�����á�����֮ǰΪ��ʹCustomer.Photo�����ӳټ��أ������Ѿ�������Ϊ��WithPhoto��aggregate��һ���֣�������Ҫ��Ƭ�Ŀͻ����ҳ�������Dz���Ч�ġ�������ֻҪ�ڿͻ����ҳ���Customer��ѯ������WithAggregate("WithPhoto")�������ã��ͻ��ٴθ�Ч������
named aggregate������������ƿ����磬ͬʱ�㲻�ز���һ�����ַ������ñ���Ԥ�ȼ��صĸ���ϸ�ڡ�����Ը���ʵ����Ҫ�������������߸߷�������ҳ����������aggregate�Ծ�������ܡ�
������
����������ע��������ҳ������������������������ο���֮��Ķ����������ԣ�ͬʱ������������ϸ���ϡ����û��ύ��������ҳ�������ʱ��Ӧ�ó�����Ҫ����Orderʵ������ɸ�OrderLineʵ�壬Ȼ������ʵ���ϵ����ݲ��뵽���ݿ⡣
DZ�ڵ����������N+1�������ƣ�ֻ����������ͬ���������100��������ϸ���͵�ִ��101�����ݿ������������ǵ�Ȼ����������ݿ�101�Σ�
LightSpeed����������������������⡣������������ģ���ͬ��ͨ����INSERT����UPDATE��DELETE����Ϊ����������ִ�У�LightSpeed��ʮ�������Ϊһ�飬Ȼ������ִ�С������ܵ���˵�����ڴ��������ĸ��²�����LightSpeed�����ݿ���ʴ�����Ϊͨ��ɵ��ʽ������ʮ��֮һ��
���˾�ϲ�������Dz���Ϊ���������������κ�Ŭ����LightSpeedĬ�Ͻ�CUD�������������������Ǻ����������ö�������ҳ������˿��ٳ־����ݵ����ԡ�
һ������
�������������������û�����Ȩ����ص�ҳ�����ʲô�����������⡣������һ��Userʵ�壬��ʵ���Ȩ����أ���ʵ����������û��������ԣ�ͬʱ���������ڸ���Ӧ�ó���������չʾ���ݵĸ��Ի��������ԡ�ͨ��������ǣ���Щҳ����м����ط���Ҫ���ص�ǰ�û�������������controller��Ҫ����û���Ȩ�ޣ�������Ҫ��ʾ�û����ƣ�ij�����������Ҫ֪���û�ϲ������չʾ���ݡ�����������������ˣ����ʵ������ܻ������ڴ��в������õĻ�����Ҫ���ظ���ѯ���ݿ��öࡣ
��Ȼ��MVC֮�����������һЩ�����������ڻ��������ദ����ͬһ��������⣬����ͨ�õķ����Dz���һ�����漼����LightSpeedʼ��Χ���Ź�����Ԫģʽ������UnitOfWork�����ṩ��һ�����档���ء�������һ������Ԫ��ģʽ��Ӧ�ó������һ��ҳ������Χ��һ�����档�����˵���ǣ���ҳ�������ڼ䣬�������ID��Ϊ������ѯ���ݣ����������ӳټ��صĹ�����������IJ�ѯ������������Ԫ�Ѿ�������Ӧ�ڸ�ID��ʵ�������LightSpeed���ƿ����ݿ��ѯ������ֱ�ӷ����Ѿ����ڵ�ʵ�����û�б����ַ�ʽ������ˣ�
���������ORM��ܰ������������ԡ�������NHibernate��session����;���һ�����湦�ܡ�Ȼ���ܶ�Micro
ORM��������ORM��ܣ������ṩһ�����棬���ǽ���עʵ�����ļ���Ч�ʡ�����ORM��ܲ�����ͼ�ڲ�ѯʱ������Ч��Ҳ������ͼ�ܲ���ѯ���ݿ�Ͳ���ѯ���ݿ⡣
һ����������ORM�Զ����Ƶġ����ǵ�Userʵ�������Զ��ڹ�����Ԫ�ڼ䣨һ��ҳ���������ã�����Ҫ����д������档
��������
�������ǵĶ�������ϵͳ�ܹ��������ֻ������͡���֧������Ԫ��ŷԪ����Ԫ�¶�����Ϊ����ǡ����ʽչʾ�������ݣ�������Ҫ��һЩ�ֽ�������������Ϣ��������������ƣ�US
dollar�������루USD���Լ����ţ�$�������ţ����Ƕ������ʵ������Currency�Ϳ��Կ�ʼ̽�ֶ��������ˡ�
����Ԥ�ȼ��غ�һ�����棬�Ϳ���ӵ�кܸߵ������ˣ������з�����ʹ���ܸ���һ��¥����Ϊһ����������÷�Χ��������Ӧ�Ĺ�����Ԫ����������Ԫ������������һ��ҳ������֮�ڣ����Ӧ�ó���ÿ�δ�����Ҫ���ʻ�����Ϣ��ҳ�涼���ѯһ�λ������ݿ������������Ϣ�ǻ����ݡ������Ǽ�������Զ����ģ����Dz�����ı�����ÿ�δ���ҳ������ʱ��ѯ���ݿ���ܻ�ȡ�������ݡ�����Ч��������ֻ��ѯ���ݿ�һ�β���������ݣ�Ȼ����ÿ��ҳ������ʱʹ�û�������ݡ�
�����������ʹ�ö�������ʵ�֡�LightSpeed����������������ڱȵ���UnitOfWorkҪ��������Ծ�����������ʵ������ܹ����ڶ�ã�����ͨ������expiry����������ʱ�䣩��LightSpeed�������ֶ�������ʵ�ַ�ʽ��һ����ʹ��ASP.NET�Ļ�����ƣ���һ����ʹ���ܺ�缸̨��������ǿ��Դ�����memcached��������һЩORM���Ҳ�ṩ�������湦�ܣ��������ORM���ṩ��
ͨ����LightSpeed����Currencyʵ������������У����ǾͿ��Ը���Currencyʵ�����ݣ��ܿ�������ݿ��ѯ�Ŀ�����Ҫ����Currencyʵ�嵽���������У���������������ָ��һ�ֻ���ʵ�ֻ��ƣ�����ֻҪѡ��Currencyʵ�岢������Cachedѡ������ΪTrue�Ϳ����ˡ�

����õIJ�ѯ
��������ͨ�����ʾ�����������ORM���ܵļ���������һ���ط�����û�п��ǣ�����C#
LINQ����ʽ�����ղ�ѯ���ݿ��SQL���֮���ת����Ҫ���Ѷ�����ġ����ֿ�����ÿ��LINQ��ѯ�϶�����֣�����ͨ����˵���������ݿ��ѯ�Ŀ�����������������ġ��������������ķ��������ڳ����һ�����ܿռ�Ļ����Ǿ���ͨ����������ת�������ˡ�Ҳ�������ͨ��ֱ��дԭ��SQL���룬�������µ�ORM������LightSpeed���У���������LINQ�ı���ʱҲ��Ȼ�з�����������ת��������
LightSpeed������ת�������ķ�����ʹ�ñ���õIJ�ѯ������õIJ�ѯ��ͨ����LINQ��ѯ��乹��������LightSpeed��LINQ��ѯ���ת���ɿ�����ִ�еĸ�ʽ���������ָ�ʽ��������������ÿ��ִ��LINQ��ѯʱ������������ת���õĸ�ʽ��������ÿ�β�ѯʱ��ת����������Ͳ����Լ���д��ά��ԭ����SQL������������ܡ�
��ʵ�ϣ���ֱ���෴������õIJ�ѯ����д��SQL������������Ҫ��Щ��������Ϊ��LightSpeedִ����д��SQL����ʱ����˿�������ƶϽ����������ô���ġ��෴����LightSpeedִ�б���õIJ�ѯʱ�����ܹ��ƶϳ����������ʽ����ΪSQL�����������ģ��������ڲ�ѯ���������ʵ�����ʱ��Щ�Ż���
����LINQ��ѯ����Ҫ������֮ǰ���۵ļ�������Щ���е�ORM���������о����ʹ������̸�����Щ����ԭ��������뽫����õIJ�ѯ�洢�������ã�������Dz������ģ���Ҫ�ڱ����ִ��ʱ�������APIָ����̬������
��������������ȡ�ͻ������IJ�ѯ��
int id = /* get the customer ID from
somewhere */;
var customerOrders = unitOfWork.Orders.Where(o
=> o.CustomerId == id);
�������LINQ��ѯ�ᱻ���ִ�У����������þ����ܸߵ����ܣ����ǿ�����Compile()��չ������������������֮�⣬���ǻ���Ҫ���������ľֲ�����id�滻Ϊִ�б���õIJ�ѯʱ�ܶ�ָ̬��ֵ�IJ�����ʽ�������DZ���LINQ��ѯ�Ĵ��룺
var customerOrdersQuery = unitOfWork.Orders.Where(o
=> o.CustomerId == CompiledQuery.Parameter("id")).Compile();
����Կ������ǽ��ֲ�����id�滻Ϊ��CompiledQuery.Parameter(��id��)��չ��֮���ٵ���Compile()��չ����������õ�һ��CompiledQuery����ͨ�����ǻὫ��洢Ϊ���ö����̬��ij�Ա���������ǿ���ִ��CompiledQuery��ѯ���£�
int id = /* get customer ID from somewhere
*/
var results = customerOrdersQuery.Execute(unitOfWork,
CompiledQuery.Parameters(new { id }));
����������¶������ˣ������ͨ�����Ų���ֵ��������ʹ��ѯ���ܴﵽ���ޣ���ο���ƪ���¡���
����
���������Ϊ�����ϵӳ�似������������Ϊ���ۻ��ñ���ϵı�ݡ�Ȼ�����ִ�ORM��ܷ�װ��Ԥ�ȼ��غ��������µȼ�������Щ������ͨ����д���ݷ��ʲ�ʵ�ֵĻ����൱���ӵġ��������ܼ�������ORM��������ܿ��Ժ���д�����ݷ��ʲ����һ����Ч��������Ҳ���طѾ�������ά����д�ĸ���SQL�����ӳ����롣ʹ��ORM��ܣ�ֻҪ�ı�һ���ص�ֵ����һ��ӳ���ļ��Ϳ��Խ��N+1�������⣬�����SQL����ΪǶ����ʽ���Լ���ӳ������Դ������ֽ���������ˡ�
����ÿ��ORM��ܶ��ṩ�����б������۵����ԣ���������ִ�ORM��ܶ�������֧������һЩ���ԡ��ҳ�Ӧ�ó�������Щ�ط��к����ݿ���ص�����ƿ����Ȼ��ʹ��֧�ֱ������������Ե�ORM��ܣ�����ܽ��������������ݿ������ƿ�����������С�ĸ�������Ӧ�ó������ܵĴ����ߡ�
|


