1.
分布式队列的基本概念
在“多核编程中的条件同步模式”(链接: http://softwareblogs-zho.intel.com/2009/01/14/845/)这篇文章中,讲到了如何减少共享队列中的锁的使用次数的具体方法,在它的基础上,可以构造出一个高效的队列池。
如果采用线程分组竞争模式(参见“多核编程中的线程分组竞争模式,链接:http://blog.csdn.net/drzhouweiming/archive/2007/07/10/1684753.aspx)来实现队列池,那么每组线程对应于队列池中的一个子队列,当某个线程在操作自己所属的子队列时,如果子队列为空却进行出队操作,那么此时可以从其他组线程所属的子队列中进行出队操作,这也就是“老子”一文中所说的“偷”的方法的使用。
有没有更好的方法进一步减少同步或者锁的使用呢?答案是有的。偷别人的东西总不如掏自己口袋里的东西来得方便,之所以需要“偷”,乃是因为自己口袋里空空。如果大家都富裕了,口袋都鼓鼓的了,自然不需要去“偷”别人的了。
当然在计算机中,“富裕”的办法就是给每个线程赋予一个私有队列,这样每个线程可以大部分时间都操作自己私有队列,不需要同步操作,大大提高效率,这也就是“老子”一文中所说的“自私”方法的使用。
基于“偷”和“自私”两种方法,就可以设计出一个适应多核环境的分布式队列。在分布式队列中,每个操作队列的线程都有一个私有队列,另外为了解决私有队列间的负载均衡问题,还需要一个队列池来维护数据的负载均衡。
分布式队列的数据结构示意图如下:
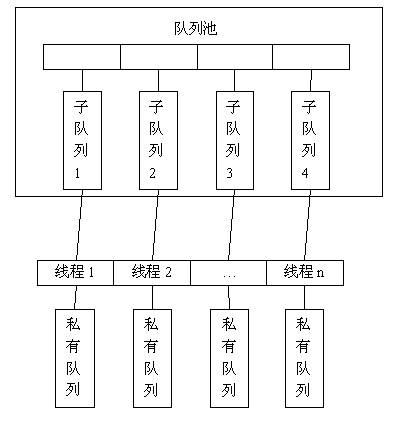
图1:分布式队列数据结构示意图
有了上面的数据结构图,具体来实现就可以分为两个步骤:
1、 实现一个队列池
2、 给每个线程赋予一个私有队列
队列池的实现可以采用前面讲过方法实现,这里就不详述了,下面主要谈谈如何给每个线程赋予一个私有队列(也称作本地化队列)的详细实现方法。
2. 本地化队列的实现思路
要给线程指定一个本地化队列,通常的做法是先将创建好的队列放入一个数组中,然后给线程编号,从0开始进行编号,编号为0的线程对应于数组下标为0位置上存放的队列,编号为1的线程对应于数组下标为1位置上存放的队列,…。
每个线程要获取自己的本地化队列时,只需要先获取线程编号,然后就可以通过线程编号去访问对应的队列,由于每个线程的编号都不相同,因此每个线程访问的队列都不相同,即每个队列只有一个线程访问它,这样就可以实现每个线程的本地化队列。
那么如何给线程编号从0开始编号呢,操作系统并没有直接提供这种功能。即使操作系统提供了线程从0开始编号的功能也没有用,因为并不一定所有的线程都会访问分布式队列。例如有8个线程,其中编号为0,3,5,7的线程会访问分布式队列,那么在创建分布式队列时,就需要创建8个本地队列,否则线程编号将无法和存放队列的数组下标对应起来。
看到这里,目标已经很明确了,那就是要给所有访问分布式队列的线程从0开始依次编号。比如有N个线程要访问分布式队列,那么需要给这N个线程依次编号为0,1,…N-1。下面就来讨论如何给线程编号的问题。
3. 给线程编号的方法
在操作系统中,通常提供了线程本地存储的API,通过API可以给每个线程设定一个数据(可以是指针,也可以是一个整数),同时也可以通过API来取出当前线程设置的那个数据。比如给一个线程A设定一个整数0,那么线程A执行的任何地方都可以调用相应的API获取到整数0,这样就可以在程序的任何地获取到线程A的编号为0。
在Windows系列操作系统中,提供了Tls_Alloc(),Tls_SetValue(),Tls_GetValue(),Tls_Free()这几个函数来实现线程本地存储操作。
pthread中,可以通过pthread_key_create(),
pthread_setspecific(), pthread_getspecific()等函数来实现线程本地存储操作,其中pthread_create_key()和Tls_Alloc()功能相同,只是参数有所不同,Tls_SetValue()和pthread_setspecific()功能等价,Tls_GetValue()和pthread_getspecific()功能等价。
下面演示一下TlsAlloc(),Tls_SetValue(),Tls_GetValue(),Tls_Free()这几个函数的基本用法。
|
DWORD
g_dwTlsIndex;
LONG volatile g_dwThreadId =
0;
int GetId()
{
//获取当前执行线程的由TlsSetValue()设置的值
int nId = (int)TlsGetValue(g_dwTlsIndex);
return (nId-1);
}
void ThreadFunc(void *args)
{
LONG Id = AtomicIncrement (&g_dwThreadId); //对g_dwThreadId进行原子加1操作
TlsSetValue(g_dwTlsIndex, (void
*)Id); //给当前执行的线程设置一个值
printf("ThreadFunc2: Thread
Id = %ld/n", GetId());
}
int main(int argc, char* argv[])
{
g_dwTlsIndex
= TlsAlloc(); //分配一个线程本地存储索引,需要在创建线程前执行
_beginthread(ThreadFunc, 0,
NULL);
_beginthread(ThreadFunc, 0,
NULL);
Sleep(100); //延时等待上面两个线程执行完
TlsFree(g_dwTlsIndex);
return 0;
}
|
需要说明一下,在ThreadFunc()函数中,使用了一个AtomicIncrement()函数,这个函数对应于Windows操作系统中的InterlockedIncrement()函数。在Widnows系统中,可以使用以下宏定义来实现AtomicIncrement()函数:
#define AtomicIncrement(x) InterlockedIncrement(x)
上面程序在运行后,会打印出以下结果:
ThreadFunc: Thread Id = 0
ThreadFunc: Thread Id = 1
从上面代码和执行结果可以看出,虽然GetValue()在ThreadFunc()函数中执行,但是两个线程执行GetValue()得到的值是不同的,一个线程得到的是0,另外一个线程得到的是1。这主要是因为两个线程调用TlsSetValue()设置的值并不相同,一个为1,另一个为2。
需要注意的是,TlsGetValue()的返回值为0表示失败,所以使用TlsSetValue()函数时,应该从1开始设置,然后在GetId()函数中,返回的是TlsGetValue()的返回值减1。
采用上面的方法,就可以设计出分布式队列中的线程Id自动编号和获取功能了。下面是详细的实现代码:
|
class CDistributedQueue {
private:
DWORD m_dwTlsIndex;
LONG volatile m_lThreadIdIndex;
public:
CDistributedQueue();
virtual ~CDistributedQueue();
LONG ThreadIdGet();
//可以添加其他成员函数在下面
};
CDistributedQueue::CDistributedQueue()
{
m_dwTlsIndex
= TlsAlloc();
m_lThreadIdIndex = 0;
}
CDistributedQueue::~CDistributedQueue()
{
TlsFree(m_dwTlsIndex);
}
LONG CDistributedQueue::ThreadIdGet()
{
LONG Id
= (LONG )TlsGetValue(m_dwTlsIndex);
if ( Id == 0 )
{
Id =
AtomicIncrement(&m_lThreadIdIndex);
TlsSetValue(Id);
}
return (Id - 1);
}
|
上面的代码中,设置或获取线程编号都在ThreadIdGet()一个成员函数内完成,先判断获取的Id是否为0,如果为0,表明线程还没有被设置Id,因此将m_lThreadIdIndex原子加1,然后再设置给对应的线程。每调用一次TlsSetValue()函数,其设置的Id值依次加1,这样就可以得到一个1,2,3,…序列。每个线程调用了TlsSetValue()函数后,下一个调用TlsGetValue()函数时,获得的值一定大于0,因此每个线程最多只能执行TlsSetValue()函数一次。
采用上面的方法来获取线程编号,必须保证创建的本地队列数量大于等于访问队列的线程数量,否则队列数量不足,将会造成没有足够的本地队列供线程使用,程序中可能会造成越界等不可预测的异常。常用的解决办法是将本地队列的数量扩大一倍。
上面这种线程编号方法,非常方便,任何访问分布式队列的线程都可以被自动编号,调用分布式队列的线程不需要为编号操心。
有了给线程自动编号的方法后,就可以实现分布式队列的各个具体操作如进队、出队等。当然在实现具体的操作代码前,有必要了解一下分布式队列中是如何进行进队和出队操作的。
4. 进队出队操作
分布式队列的进队出队操作根据不同应用类型具有不同的操作策略,但是不论何种类型的操作,其基本思想必须以本地队列操作最大化作为前提条件。下面给出分布式队列中常用的进队出队操作类型。
1) 出队操作
出队操作比较简单,通常都是先从本地队列中获取数据,如果本地队列为空,那么再从共享队列池中获取数据。
由于先从本地队列中获取数据,因此有助于实现本地队列操作的最大化。
出队操作的流程图如下:

图2:分布式队列的出队操作流程图
2) 进队操作
进队操作相比于出队操作要复杂一些,常用的操作策略有以下两种:
策略1:先判断本地队列是否为空,如果为空则将数据放入本地队列中;然后判断共享队列池中是否满,如果满则将数据放入本地队列中,否则放入共享队列中。
在这种策略的进队操作中,首先考虑的是本地队列的操作问题,本地队列至少要有一个数据,然后考虑的问题是负载平衡问题,共享队列池中的数据主要用于各线程间数据的负载均衡。共享队列池的大小必须做出限制,否则数据全部都进到共享队列池中去了,本地队列未得到有效使用。
共享队列池到底设定多大,才能使得本地队列操作最大化与负载平衡问题之间取得一个好的均衡,是在实际情况中需要考虑的问题,最好通过测试程序性能去获取一个合适的值。
进队操作策略1的操作流程图如下:

图3:分布式队列的进队操作策略1的流程图
策略2:当有多个数据需要进队时,先放入一些数据到本地队列中,然后剩下的数据再放入共享队列池中,如果队列池满的话,则仍然放入本地队列中。
本策略中,通常是进队的线程马上自己要从队列中获取数据,因此要先放入一些数据到自己的本地队列中,保证下次从队列中取数据一定是从本地队列中获取,可以大大提高本地化队列操作的频率,有效降低共享队列池的操作,大大减少了同步操作。
进队操作策略2的操作流程图如下:

图4:分布式队列的进队操作策略2的流程图
有了进队操作和出队操作的详细流程后,实现分布式队列的具体代码就容易多了。
CDistributedQueue类的各个操作的详细源代码参见CAPI开源项目中的CDistributedQueue.h。
CAPI开源项目地址:http://gforge.osdn.net.cn/projects/capi
|


