| Ŀ¼��
Microsoft NLayerApp����������ʵ��
- ��Ŀ����뻷���
Microsoft NLayerApp����������ʵ��
- ���ܹ���Ӧ��ϵͳ���ԭ��
Microsoft NLayerApp����������ʵ��
- DDD���ֲ�ʽDDD����ֲ�
Microsoft NLayerApp����������ʵ��
- �����ṹ�㣨Cross-Cutting���֣�
Microsoft NLayerApp����������ʵ��
- �����ṹ�㣨���ݷ��ʲ��֣�
Microsoft NLayerApp����������ʵ��
- ����ģ�Ͳ�
Microsoft NLayerApp����������ʵ��
- Ӧ�ò�
Microsoft NLayerApp����������ʵ��
- �ֲ�ʽ����
Microsoft NLayerApp����������ʵ�� - ��Ŀ����뻷���
��Ŀ���
Microsoft �C Spain�Ŷ���һ���ܲ����ġ�����������ֲ�ʽ��Ŀ��������Microsoft
�C Domain Oriented N-Layered .NET 4.0 App Sample���ڱ�ϵ�������У���ʹ��NLayerApp��Ϊ����Ŀ�����ƽ��н��ܣ�����codeplex�ϵĵ�ַ�ǣ�http://microsoftnlayerapp.codeplex.com/������ѧϰ����������ƣ�DDD����һ���dz������İ�����Ŀ������Ŀ���õ��Ǿ����DDD�ܹ���������CQRS�ܹ������Ҿ��������������ķdz������������ϰ����˻���DDD�ļܹ�ʵ���ĸ������档��ˣ�Ӧ�����������ѵ�Ҫ���Ҵ��㻨һ���־�����дһ�����ܸ���Ŀ������ʵ����ϵ�����¡��ⲿ��ϵ�����½���Ϊ�������֣�
1.ԭ�����֣��ⲿ�ֽ���Microsoft NLayerApp��һЩ�������ݣ������ܹ����ԭ�ֲ�ܹ���DDD��Distributed
DDD����������������Ƶȡ���ʵ�ϣ�microsoftnlayerapp.codeplex.comվ�����Ѿ���һЩ�ĵ����ⲿ���������˽��ܣ���ˣ�ԭ�����ֵ������ҽ��������Ƕ���ЩӢ���ĵ����з���������Ȼ��������һЩ�Լ���ע�ͣ��������ĺô��ǣ��ܹ���������ҵ����Ŀ�Ŀ��������Ϊ�����ṩһ�����ϵͳȫ���ѧϰ���ϡ�NLayerApp�Ĺٷ�վ�㱾��Ҳ�����������ﵽӢ��ķ��빤���������ⲿ��Ӣ���ĵ�Ҳ����ȫ�棬�һ�����Ӣ�İ��ĵ��������ڴ���Ӧ��������ȱʧ�IJ���
2.ʵ�����֣��ⲿ�ֽ�������NLayerApp Solution�Ľṹ���������㡢�����õ��ļ������������ͽ��ܡ���ԭ�����ֲ�ͬ���˲������ݸ���ע�����ľ���ʵ��ϸ�ڣ�������ȥ����ʲô���������ʲô�Ƿֲ�ܹ��Ȼ���������
ע�⣺Microsoft �C Spain�Ŷ�һֱ�ԡ�Domain Oriented��һ�������������Ŀ���������á�Domain
Driven Design����ԭ���ǣ�Domain Driven Design���������ݣ���������ijһ�ּܹ���������������������Ŀ�Ŀ�����ʽ�������Ŷӵ�Э����������������ר�Һ�������Ա֮��ġ�ͨ�����ԡ��Ĵ��������ݡ�Ȼ����������NLayerApp��Ŀ�У���û���õ�DDD��������Щ���ݣ���Ŀ�ķ�Χ��������/��������ļܹ���ơ�
NLayerApp��Ŀ�����
�ڿ�ʼ���ϵ������֮ǰ���������ǰ�NLayerApp����Ŀ������á��ڴ����֮ǰ��������ĵ����Ƿ�����������Ⱦ�������
- Visual Studio 2010 RTM �� .NET 4.0 RTM
- Expression Blend 4�������������ٷ���վû��ֱ�ӵ����ص�ַ��ֻ��MSDN�����û��������ص������汾������ʹ��Expression
Blend SDK for Silverlight 4Ӧ��Ҳ�ǿ��Եġ����ص�ַ�ǣ�http://www.microsoft.com/downloads/en/details.aspx?FamilyID=d197f51a-de07-4edf-9cba-1f1b4a22110d��
- SQL Server 2008 R2 Express/Standard/Enterprise����ϵ������ʹ�õ���Express�汾��
- Unity Application Block 2.0 �C 5/5/2010���������ص�ַ��http://www.microsoft.com/downloads/en/details.aspx?FamilyID=2D24F179-E0A6-49D7-89C4-5B67D939F91B&displaylang=en��
- Pex & Moles 0.94.51023.0, Visual Studio 2010
Power Tools, 10/29/2010��������ַ��http://research.microsoft.com/en-us/projects/pex/downloads.aspx#PexMSDN��
- WPF Toolkit��http://wpf.codeplex.com/releases/view/40535
- Silverlight 4 Tools for Visual Studio 2010: http://www.microsoft.com/downloads/en/details.aspx?displaylang=en&FamilyID=b3deb194-ca86-4fb6-a716-b67c2604a139
- Silverlight 4.0 Toolkit (4/15/2010): http://silverlight.codeplex.com/releases/view/43528
- Windows Server AppFabric����ѡ����ϵ�������ò�������http://www.microsoft.com/downloads/en/details.aspx?FamilyID=467e5aa5-c25b-4c80-a6d2-9f8fb0f337d2
- Windows Azure SDK & Azure Tools for VS2010,
Nov. 2010����ѡ����ϵ�������ò�������http://www.microsoft.com/downloads/en/details.aspx?FamilyID=7a1089b6-4050-4307-86c4-9dadaa5ed018
�밴����IJ��谲װ������NLayerApp��
1.��������������İ�װ�����ã����������Բ���װ����ϵ������û����Windows
Server AppFabric��Azure�Ĺ��ܣ�
2.����NLayerApp v1.0��ѹ��������ַ�ǣ�http://microsoftnlayerapp.codeplex.com/releases/view/56660��ѡ��V1.0
- N-Layer DDD Sample App NET4.0����ϵ�����½�ʹ������汾���н���

3.��ѹ���������zip�������������ļ��У�CORE��CORE-APPFABRIC��CORE-AZURE����ϵ������ûʹ��AppFabric��Azure�����ԣ�ֱ�ӽ���COREĿ¼
4.��ʱֱ������Tests�����ԣ�˫����NLayerAppWithoutTesting.sln�������
5.����������û�н�Infrastructure.Data.MainModule.Mock��Ŀ���ӽ�������ᵼ��Infrastructure.CrossCutting.IoC��Ŀ������ͨ������Visual
Studio�У����������չ����1.5.1 Data�ڵ㣬�ڸýڵ����Ҽ�������ѡ��Add | Existing
Project��Ȼ����CORE��Infrastructure.Data.MainModule.MockĿ¼��ѡ��Infrastructure.Data.MainModule.Mock.csproj��Ŀ�ļ���������Open��ť
6.��Server Explorer�У��Ҽ�����Data Connections�ڵ㣬ѡ��Create
New SQL Server Databaseѡ��

7.�ڴ�Create New SQL Server Database�Ի����У��������Server��ַ��Ȼ���������ݿ����ƣ��ٵ���OK��ť��������ʹ��SQL
Express��with Windows Authentication����ʹ��Ĭ�ϵ����ݿ�����NLayerApp

����ȫ����ѡ���Լ������SQL Server�����ݿ����ƣ��������ʹ���Լ������SQL
Server�����ݿ�Ļ�����ͬʱ��2 �C Database�ڵ���NLayerAppDatabase��Ŀ�����ԣ��Ҽ�����NLayerAppDatabase��Ŀ��ѡ��Properties����Propertyҳ��Deployѡ�������ز�����

8.�Ҽ�����NLayerAppDatabase��Ŀ��Ȼ��Deploy���⽫�������ݿ�Schema
9.���������������
10.��1.2 �C Distributed Services�ڵ��£��ҵ�DistributedServices.Deployment��Ŀ���Ҽ�������Ŀ�µ�MainModule.svc�ļ���ѡ��View
in Browser��������WCF����

11.�����û����档NLayerApp v1.0�ṩ���¼����û����棺����RIA��Silverlight
4.0 Client������Web��ASP.NET MVC Client������Windows��WPF Client
����RIA��Silverlight 4.0 Client
�Ҽ�����Silverlight.Client.Web��Ŀ�µ�Silverlight.Client.Web.html�ļ���ѡ��View
in Browser������������RIA��Silverlight 4.0 Client

����Web��ASP.NET MVC Client
��MVC.Client��Ŀ����Ϊ������Ŀ��ֱ�����У�������������Web��ASP.NET
MVC Client

��������������汾�͵�Ե�ʣ��õ���ASP.NET MVCҳ�沼���е���
����Windows��WPF Client
��WPF.Client��Ŀ����Ϊ������Ŀ��ֱ�����У�������������Windows��WPF
Client

���Ľ�����NLayerApp��Ŀ�Ļ�������ͻ����������һ����ʼ�����ǽ�����ܹ���Ƶ�����ѧϰ���֣��������ֲ�ܹ���SOLID�����ԭ����������������ƣ�DDD���ļܹ������Լ��ֲ�ʽDDD��Distributed
DDD��DDDD�����ⲿ�����ݽ���Ҫ������NLayerApp������microsoftnlayerapp.codeplex.com���ṩ��Ӣ���ĵ���daxnet���ڴ������롢������ע�⡣
Microsoft NLayerApp����������ʵ�� - ���ܹ���Ӧ��ϵͳ���ԭ��
�ڶ�NLayerAppʵ����Ŀ��������֮ǰ������������ѧϰһ�£�����Ӧ��˵����һ�£��ֲ�/���ܹ���Ӧ��ϵͳ���ԭ�ܶ����ѻ���Ϊ��Щ�����ϵ��������ݣ�ֻҪ��������ҵ��Ա���������Щ���ݷdz���Ϥ��Ȼ��������������������������ⲿ�����ݣ�һ������Ϊ����NLayerApp���»���������һ���棬����ϣ����˻��Ὣ��Щ�����ԵĶ����������ɣ�Ҳϣ�����������ܹ������Ķ����Ͼ��¹�֪���
��Ҫ˵�����ǣ��ӱ��½ڿ�ʼ������������ԵĶ�����Դ��Microsoft
Spain�Ŷ����NLayerApp����д�ġ�Architecture Guide Book������ʵ���ⱾGuideline��Ӣ�İ�����Ҳ��û����ɣ��һ���г�������½���Щ������ɣ�����Ȥ��������ֱ����microsoftnalyerapp.codeplex.comվ��������Ӣ�İ��Ķ���
Layers��Tiers
��Layers��Tiers���������ʽ��������Ƿdz���Ҫ�ġ������ķ��뿴�����߶��ǡ��㡱����˼��������������Ὣ����������Ū�졣Layerһ�ʸ�����DZ�ʾ��ϵͳ������ܵ������֣�����û�а���������ֲ�����ͬ������ͬ�ķ������ϵ���˼����Tier���DZ�ʾϵͳ��������ڷ����������绷���Լ�Զ��λ�õ��������𡣾�������������ͬʱʹ���߷dz������һЩ������硰չʾ������������ҵ�͡����ݡ��ȣ������DZ����˽�����֮��IJ���������ͼ�����˶�㣨N-Layer�����ܹ������㣨3-Tier�������ṹ֮��IJ��죺

��Ҫע����ǣ����ھ���һ�����Ӷȵ�Ӧ�ó�����ԣ����ö�㣨N-Layer�����ܹ���ʵ�ַ�ʽ�Ƿdz���Ҫ�ģ���ή��ϵͳ�ĸ��Ӷȣ�������ơ����������ԡ�����ά���ȸ�������ΪӦ��ϵͳ�����߿����ԡ�����չ�Ե�����ЧӦ��Ȼ�����������е�Ӧ�ó�����������㣨3-Tier��/��㣨N-Tier�������ṹ���в������ǿ��Խ�������㲿����ͬһ̨�����ϣ�Ҳ���Ը���������Щ���㲿���������еIJ�ͬ�����ϡ�
���ֲ㣨Layer�������
������DDD�ķֲ�֮ǰ���������ǿ�����ͳ�ķֲ㷽ʽ��������������������Ӧ�ø�����Ŀ��ʵ���������/����ģ������ػ��ֵ������㡱�С�ͬһ���е������Ӧ���Ǹ��ھ۵ģ���������ͬ�ij����Ρ������֮��Ӧ�õ���ϡ������Էֲ���Ƶ�Ӧ�ó�����ԣ���ؼ������������δ��������֮���������ϵ�����촫ͳ�Ķ��ܹ�Ӧ�ã�����ij��������ֻ�ܶ�ͬ����²������������з��ʣ�������������Ч�ؽ��Ͳ����֮���������ϵ��ͨ���������ֲַ���ƣ��ϸ�ֲ������ֲ�
1.���ϸ�ֲ㡱��ʹ���ֻ�ܷ���ͬ����������������ֻ�ܷ���ֱ���²��������������ǣ���N������ֻ�ܷ��ʵ�N��N-1������������N-1������ֻ�ܷ��ʵ�N-1��N-2���������Դ�����
2.�����ֲ㡱�����������ͬ�������������Լ������²��������������ǣ���N���������Է��ʵ�N��N-1��N-2��������
ʹ�á����ֲ㡱�ļܹ��������ϵͳ���ܣ���Ϊ�����Ľṹ����������������/�����Ĵ��ݲ�������Ϊһ�������ֱ�ӷ���λ�����µ��κβ㣻�����ϸ�ֲ㡱ȴ�����˲����֮�������ԣ��ԵͲ���IJ��������ϵͳ��ɹ㷺��Ӱ�졣����Eric
Evans���䡶�����������-�������ĸ�����Ӧ��֮����һ���е�������DDD�ķֲ�ѡ�õ��ǡ����ֲ㡱ģʽ��
�������ٰ����۵�����ϸ�������������е���������֮��Ĺ�ϵ����ʵ�ϣ��ںܶิ�ӵ�Ӧ���У�λ��ͬһ�������������Ȼ������ͬ�ij����Σ�����Ҳ��һ���Ǹ��ھ۵ġ���ˣ����ǿ������롰ģ�飨Module�����ĸ����ͬһ���и��ھ۵��������ͬһ��ģ���У����ǣ�ÿ�����ֻ���һ���������ھ۵���ϵͳ��ģ�飩����ɣ�����UML���ͼ��ʾ��

ʹ�÷ֲ�ܹ��������¼���ô���
- ���ϵͳ�Ŀɲ�����
- �Խ��������ά��������ø��Ӽ����ڸ��ھۡ�������ϵĽṹ��ʹ��ϵͳʵ����ֲ���֯��ʽ��÷dz�����
- �����ⲿӦ�ó����ܹ��dz������ʹ�ò�ͬ�IJ����ṩ���ض�����
- ��ϵͳ�Բ�ķ�ʽ������֯ʱ���ֲ�ʽ����Ҳ��÷dz�������
- ��ijЩ����£��ֲ�ϵͳ����������ʽ�ܹ���ϵͳ������չ�ԣ���Ȼ��Ӧ����Ч�����������ʵ����ʽ����Ϊ���������п�������ϵͳ����
Ӧ��ϵͳ�������ԭ�� - SOLID
Ӧ��ϵͳ�����Ӧ����ѭһЩ���������ԭ�����ܰ�������Ч�ش���һ���ͳɱ����߿��á��߿���չ��Ӧ�ó����������������һ��SOLID���ԭ��SOLID�����¼��㹹�ɣ�
- Single Responsibility Principle����һְ��ԭ��
- Open Close Principle����-��ԭ��
- Liskov Substitution Principle�������滻ԭ��
- Interface Segregation Principle���ӿڷ���ԭ��
- Dependency Inversion Principle��������תԭ��
�����Ҫ����һ���⼸����ԭ��
- ��һְ��ԭ��ÿ����Ӧ��ֻ��һ����һ����ְ�𣬻���˵ÿ����ֻ����һ����Ҫ���ܣ��ɴ�������һ�����ۣ�ÿ����Ӧ�þ������ٵ�������������
- ��-��ԭ��ÿ���࣬Ӧ�öԡ���չ�����п��ţ����ԡ��ġ����з�գ�Ҳ����֧����չ��������֧���ģ����еķ�������ͨ���̳й�ϵ������չ��������ı��౾���Ĵ���
- �����滻ԭ��������Ա������ͣ�������߽ӿڣ��滻��Ӧ�ó��������������У�����Ϊ������Ϊ����ʵ�ֵĸı�����ģ�Ӧ�ó���Ӧ�������ڳ�������߽ӿڣ��������Ǿ���ʵ�֡���������Ҫ���۵��ġ�����ע�루Dependency
Injection������������ԭ���й�
- �ӿڷ���ԭ�ӿڵ�ְ��ҲӦ���ǵ�һ�ģ��ӿ���Ӧ�ð�����Щ��������Ҫ�����ϸ���������������ijЩ������ְ����ӿڵı������岻����ϣ���Ӧ�ý�����뵽�����ӿ��С�����Ҫ���������������Ҫ�IJ�ͬ�ӿ����ͣ�����¶��ͬ�Ľӿ�
- ������תԭ�����������ھ��壬��������Ӧ�������ڳ�����֮���ֱ������Ӧ���ó�����ȡ������������һ���ŵ��ǣ����ǿ���ʵ�����϶��µ���Ʒ�ʽ�����²�ľ���ʵ�ֻ�û��ȷ��������£�ֻҪ�ܹ��ڳ�����潫�ӿ�ȷ�������ܹ�����ϲ������뿪������ͬ�����ɲ����Դ������
��������������SOLIDԭ��֮�⣬�������¼����ؼ������ԭ��ɹ��ο���
- ������Ӧ���Ǹ��ھ۵ģ����Ŵ�Ҷ�����Ϥ����ˣ��Ͳ���˵�ˡ����磺��Ҫ�����ݷ�����д������ģ�͵�ҵ�����У�������������һְ��ԭ����������ص�
- ��Cross-Cutting�Ĵ�����ض���Ӧ�ó�������з��뿪����Cross-Cutting�Ĵ�����һЩ�������Ĵ��룬���簲ȫ��������������־�Լ�����/����ϵͳ�ȡ�����Щ������Ӧ��ϵͳҵ��������һ�������ϵͳ�ĸ����ԣ�����������չ��ά����ɺܴ���鷳�����롰�������̣�Aspect-Oriented
Programming��AOP�����й�
- ��ע����루Separation of Concerns��SoC������Ӧ��ϵͳ�ֳɶ���Ӳ��֣���ϵͳ������������֮��Ĺ��ܾ�����Ҫ�ظ�����Ŀ�ľ���Ϊ�˼��ٽ����㣬��ʵ�ָ��ھۺ͵����
- Don��t Repeat Yourself��DRY����һ���ض��Ĺ���ֻ����ij���ض��������ʵ��һ�Σ�ͬ���Ĺ��ܲ�Ҫ�ڶ��������ظ����
- ����YAGNI��You Ain��t Gonna Need It��ЧӦ��ֻ���Ǻ���Ʊ���Ĺ��ܣ�����������
���ˣ������ͽ��ܵ�������ƶԴ�����Ӵ����ܹ�������������˵�������IJ������ݶ��Ƿϻ�����һ����ʼ���һỨ���ֱ�ī��DDD/DDDD�ķֲ�����ϣ���Ȼ�п��ܻ��Ƿϻ����������������NLayerApp�Ľ��������֯�ṹ�����൱�İ�����
Microsoft NLayerApp����������ʵ�� - DDD���ֲ�ʽDDD����ֲ�
���ʱ��һֱ��æ�������Ѿ���һ����û���²����ˡ������ڿ�ʼ���ҽ���������Microsoft
NLayerApp������ϣ����λ����Microsoft NLayerApp�������ܹ�����Լ�DDD���������ܹ�������ע��
�Ӽܹ��Ͽ���Microsoft NLayerApp�ԡ����ӵ�ҵ��ϵͳӦ�ó�������һ��Ӧ�ó���ļܹ�����ṩ��һϵ�е��������ν�����ӵ�ҵ��ϵͳӦ�ó�����ָ����һ��ҵ��ϵͳӦ�ó�������Ӧ�ó��������Խϳ����������ڣ��������������У�������һЩ��Ԥ�ڵġ������Ա���������磬��ʹ�õļ���/��ܵİ汾���������滻������˺���ά�����÷dz���Ҫ�����ǣ������������Ӧ�ó������ƣ�����Ӧ�����������������Ա��������ʱ�������ֱ����Ӧ�ó����������ֵ�Ӱ����ٵ���С�̶ȣ����磬����Ҫȷ�����ڻ����ṹ�����ʩ�������Ӱ�쵽���ϲ�ĸ������֡���ȷ�е�˵��Ӧ�ó��������ģ�Ͳ���Ӧ��ֻ��ע�����������Ӧ�ó�����������֣�����Ӱ�쵽����ģ�͡��ڡ����ӵ�ҵ��ϵͳӦ�ó����У�ҵ��������Ϊ��ʽ��Ҳ���ǡ����������������Ǿ����仯�ģ���ˣ�ʹ����кܺõĿ����ԺͿɲ����Խ���dz���Ҫ��Ҫ�ﵽ������Ч��������Ҫʵ������ģ�Ͳ�����ϵͳ�������ֵĽ����Ϊ����������ƣ�DDD����һ���ֵ���������Ķ��ֲ�ʽ�ܹ�����ע�ľ������������⡣
�����Ǿ仰��DDD������ֻ�Ǽܹ�+ģʽ��DDD�ǿ���Ӧ�ó����һ�ַ�ʽ�����Ŷ�����Ŀ�й�����һ�ַ�ʽ������DDD����Ŀ�Ŷ���Ҫ��һ������ķ�ʽ���к�����Ӧ���ܹ�ֱ��������ר�ң�ͨ�����ǿͻ������й�ͨ�������Ŷ���Ҫʹ�á�ͨ�����ԡ���һ�ܹ��������˽��ܵ����ԣ��ȵȡ�Ȼ����������û�а�����Щ���ݣ���Ϊ����һ�֡����̡���һ��ALM�����ԣ���������ϣ��100%ʵ��DDD������Ҫ�Ķ�Eric
Evansд�ġ������������-�������ĸ�����Ӧ��֮����һ�飬����������һЩ����DDD���̵��鼮����Щ�鼮���DDD���̡���Ŀ���Ŷ����Ƚ���ϸ�Ľ��ܣ�����������̸�ۼܹ���ģʽ���ܹ���ģʽ������DDD�к�С��һ���֣�������������չʾ�ľ�ǡ������һ���֡���֮�����DZ���ǿ����DDD�������Ǽܹ�+ģʽ��
�������У��������Ѿ���DDD���ļܹ�ģʽ�������Ҳ�ã�CQRSҲ�ã���ʵ����Ŀ��Ӧ�����ƹ��д���һ�������⣬�������ϵͳ����ϵͳ�Ĺ��ɹ����У�DDD���ܹ������ҵ�����㣬�ٱ��磬����CQRS�ܹ���Ӧ��ϵͳ�ѶȽϴ��Ӷȸߣ���ͨ�Ŀ�����Ա�����ڶ������������֪ʶ��һ�������Ŷ���Ա�������¼�����Ŷӳ�Ա���ڶ�������ʤ�ο���ְλ������Ŀ�������Ӱ�졣�������Ѷ��ڹ�ע������������Լ�CQRS�ܹ�������Ҳ���ҵIJ���ϵ���������ܵ�������������ϣ���ܹ���ʵ�ʹ�������Ŀ���ܹ�Ӧ��DDD������ͼ������п�������ȴ��Ӧ�õĹ����������������谭����ò���������������˵����רע��.NET�����Լ�DDD����ֻ������һֱ��̽��ijһ�����͵�Ӧ�ó���ļܹ���ʽ������ͼ���������˼��ͼܹ����չʾ����ҡ�ע�����ijһ�֡��Ĵ�ǣ�DDD���ܹ��������������е�ʵ����Ŀ��Ӧ��ϵͳ���������Ŷӱ������ԣ�����DDD�Ŀ�������Ҳ��һ��һϦ֮�¡��ܹ�ʦ����Ҫ����Ŀʵ��������з����������Ӧ��ϵͳ�ļܹ��������Լ��Ŷӽ���ĸ��������أ����磬�Ŷ��Ƿ��ܹ���������Agile�������̣�����ȥ��ӦDDD�Ŀ���ģʽ���ȵȣ���DDD�����Լ�DDD���ļܹ�ģʽֻ�����ǰ�������ǰ����һ��ѡ��������Ľ��ܻ����ܹ���������ȷ����������
��ѡ����������Ķ��ֲ�ʽ�ܹ���DDD���ܹ���������
���Ӧ�ó�����Լ����������������ڵ����������У������ṹ��ʹ�õļ����Ϳ���Լ�ҵ������ȸ����涼������̫��ı������ô��Ͳ���Ҫѡ�û���DDD�Ķ��ֲ�ʽ�ܹ��������ѡ��һЩRAD��Rapid
Application Development���ļ���������WCF RIA Services����Visual
Studio Lightswitch�ȣ�����ʹ�ÿ�����Ӧ�ó����÷dz���Ч����Щ��Ӧ�ó����ע����Time
to Market��TTM���������ں����Ľṹ���ֲ����ȸ���ȴ�����Ǻܹ�ע��ͨ�������ǰ�������Ӧ�ó����Ϊ������������Ӧ�ó���
ѡ����������Ķ��ֲ�ʽ�ܹ���DDD���ܹ���������
�����ϣ�����Ӧ�ó����ڽϳ���һ��ʱ���ڶ��ܹ���Ӧҵ�����ı仯����ô��ǿ�ҽ�����ѡ����������Ķ��ֲ�ʽ�ܹ�������������£�����ģ�ͽ�������ҵ�����仯������ĸ߶���ۣ����֮�䡢�����֮�����ϵĽṹ��ʹ����ÿ�γ���ҵ���������ʱ���㶼�ܹ�������ģ����������е����Ͳ��ԣ�������Ҫ����Ӧ�ó�����������֣�������Ч�ؽ����������������Ŀ������գ�����ʡ����Ŀ��֧��
�ֲ�ʽDDD��Distributed DDD, DDDD��
���������Microsoft NLayerApp����Guide Book���ἰ�ģ�������DDD���ܹ��Ļ����ϣ����ֲ�ʽ����������������Eric
Evans�ġ������������-�������ĸ�����Ӧ��֮����һ���У�����û���ἰ̫����йطֲ�ʽ���������ݣ�����Web
Service�����ȣ�����ҪҲ����Ϊ���DDD�����۱���Ҳ��������Domain�ġ�Ȼ������ʵ�ʵ�Ӧ�ó���ʵ�ֺͲ�������У��ֲ�ʽ�����DZز����ٵġ���ʵ�ϣ�Microsoft
NLayerApp������ֲ�ʽDDD�ģ���ʵ�֡��ֲ�ʽ���Ĺ����У������������еļ���������WCF�ȡ�DDDDҲʹ��Ӧ�ó����ܹ����õ���Ӧ�ֲ�ʽ��������������ʹӦ�ó��������ز����Ƽ���Ļ����С�
��������Ķ��ܹ�
���ڡ�EntityFramework֮�����������ʵ�� ���������ֲ�ܹ���һ���У��ҾͶԻ���DDD���ķֲ�ܹ����˽��ܡ����ڻع�һ�£�DDD���ܹ���Ҫ��Ϊ�IJ㣺���ֲ㡢Ӧ�ò㡢�����ͻ����ṹ�㣺

�������������Ա�һ��Microsoft NLayerApp�ļܹ��ֲ㷽ʽ����Microsoft
NLayerApp��Guide Book���ṩ������ķֲ�ܹ�ͼ����ֲ㷽ʽ�ڴ���������������������ͬ��ͬʱ����ͼ���Ը�������ڲ�����ϸ�����������ڶ����ܹ���������˽ÿ�������������������֮���Э����ʽ��
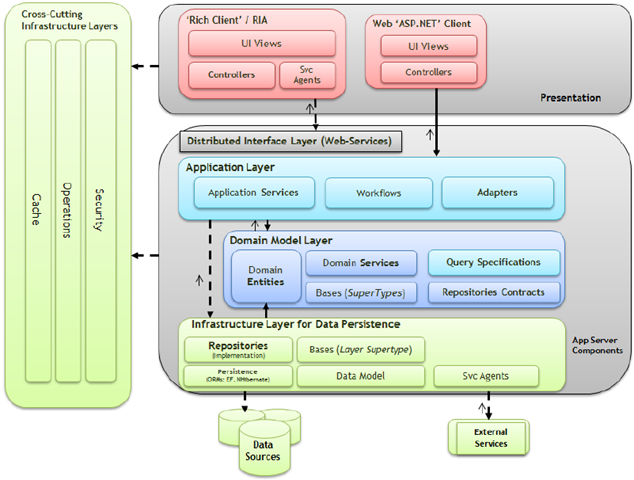
�˽�������Ŀ������ܹ�������������ϵͳ��������ʽ���źܴ�İ��������棬�ҽ��������ܹ��е�ÿ������н��ܣ������ǿ�����Щ�㶼��������Щ������Լ���Щ��������Э���ġ�
- ���ֲ㣨Presentation�����ò����Ҫְ����ͨ���û��������û�չʾ��Ҫ��������Ϣ��ͬʱ�����û��ķ������ò��е������Ҫʵ������ͼ�ν��桢�û�������������ת�����û����湦�ܡ����������Ŀ��ʵ�������ѡ����ص�ģʽ������MVC��MVP����MVVM�ȣ�����Щ���ϸ�ֵ���С�IJ��С�
- �ֲ�ʽ����㣨Distributed Service Layer������Ӧ�ó����Է����ṩ�̣�Service
Provider���ķ�ʽ������Զ��Ӧ�ó����ṩҵ����ʱ������Ӧ�ó���Ŀͻ��˱����DZ���������һ��Զ��λ��ʱ����ҵ�����ͱ���ͨ���ֲ�ʽ���������緢�����ֲ�ʽ����㣨ͨ����ʵ��ΪWeb
Service�����Ը��ݿ����õ�ͨ��ͨ����������Ϣ��ʽ��ΪӦ�ó����ṩԶ�̷��ʵĹ��ܡ���Ҫע����ǣ��ֲ�ʽ������в�Ӧ�ð����κ�ҵ������ʵ�֡�
- Ӧ�ò㣨Application Layer����Ӧ�ò�����Э������ģ��������Ӧ������Ĺ����������һ���ض��ġ���ȷ��ϵͳ��������Э����������������ȡ�UoW��Unit
Of Work��PoEAA����ִ�У��Լ�����һЩϵͳ����Ĵ�������ȡ�Ӧ�ò�ͬʱ��������Ӧ�ó�����Ż������ݵ�ת����ʽת���ȹ�������Ȼ�����ǽ���Щ����ͳ��Ϊ��������ȡ�������ÿ������ĺ��IJ��֣�Ӧ�ò㶼�Ὣ��ת�����²�ȥ������Ӧ�ò�ͨ���ᱻ������һ�֡�ҵ�����ۣ�Business
Facade����������ȴ��������ת������ģ�Ͳ�Ĵ�������/������ô����ͨ��������������Щ���ݣ�
- ͨ���ִ���Լ��Repository Contract�������ʳ־ò���ƣ��Զ�ȡ���������ע��������ʵ��Dzִ���Լ�������Dzִ��ľ���ʵ�֡��ִ��ľ���ʵ���ǻ����ṹ�������
- �������ڲ�ͬ�����������ݽ�����֯���������Ա��ܹ��÷ֲ�ʽ��������Ч�ش�����Щ���ݡ�ͨ�������ǻὫ�������������ݴ������Data
Transfer Object��PoEAA��������WCF��Data Contracts
- ������ά��Ӧ�ó����״̬������������ģ������������״̬��
- Э���������֮�䡢����ģ��������ṹ�����֮���Э����ϵ������������ת��ϵͳ�У��ʽ��һ���˻�ת�Ƶ���һ���˻���������Ҫͨ���ִ���ȡ���˻����������Ȼ������������Ͻ���ת�˲����������ǡ��˻�����������Ϊ��Ҳ�����ǣ���Evans�ľ�����ʹ���������Domain
Service���������������ת�˺����۳ɹ������Ҫ���ⷢ�͵����ʼ��������Ҫ�����ṹ��ĵ����ʼ����Э�����
- Ӧ�÷���Application Services����������Ҫע�⣬DDD���ᵽ�ķ�����ƽʱ��˵��Web
Service�Ȳ�����һ����������Դ�����Ӧ�ò㡢����ģ�Ͳ����������ṹ�㡣DDD��Service�������ĸ����ʵ�ǡ�����ᵽ�κ�һ������һϵ�в����ļ��ϣ���ˣ�Serviceͨ������Э����ͬ����֮��Ĺ�����Ӧ�÷���Ҳ����ˣ�����������²��������������ģ�Ͳ�������ṹ�㣩����Э��
- ҵ��������Business Workflow����ҵ���������DZ���ģ�����ijЩ���ض�������ɵ�ҵ����̣�����ҵ��������ʹ�����ü�
- ����ģ�Ͳ㣨Domain Model Layer�����ò����Ҫְ����չ��ҵ��/��������ҵ����״̬���Լ�ʵ��ҵ�������ͬʱҲ��������������״̬��Ϣ����һ��������Ӧ�ó���ĺ��IJ��֣���������������Щ��������ݣ�
- ʵ�壨Entities��
- ֵ����Value Objects��
- �������Domain Services��
- �ִ���Լ/�ӿڣ�Repository Contracts/Interfaces��
- �ۺϼ��乤����Aggregates and Factories��
- �ۺϸ���Aggregate Roots��
- ��Լ����Specifications��
- �����ṹ�㣨���ݳ־û����֣���Data Persistence Infrastructure
Layer�����ò�ΪӦ�ó�������ݴ�ȡ�ṩ������������Ӧ�ó������ij־û����ƣ�Ҳ�������ⲿϵͳ�ṩ�����ݷ��ʵ�Web
Service�ȡ����ݷֲ�ܹ������ԭ�ò�Ӧ���ԡ�����ϡ��ķ�ʽ���ϲ��ṩ���ݳ־û�������ˣ��ò������������Щ���ݣ�
- �ִ��ľ���ʵ�֣��Ӹ����Ͽ������ִ�����ζ�Ŷ�һ����ͬ���Ͷ���ļ��й������ͺ����Ǵ�ȡͬһ���Ͷ���IJֿ⡣Ȼ����ʵ���У��ִ���Ҫ�������ض��ij־û�����/������ִ�ж���Ķ�ȡ�ͱ����������Щ�־û�����/����������Entity
Framework��NHibernate���������ijһ���ݿ������ADO.NET�����Ϊ�˼���������ǽ����ݷ��ʲ������е��ִ��У�����Բ�ͬ�ij־û�����/��������һ���ִ��ľ���ʵ�֣��⽫���Ӧ�ó����ά���Ͳ��������ݡ�����Ʋִ�ʱ��ͨ���������ǣ����ȶ�����ģ�ͻ��־ۺϲ����־ۺϸ���Ȼ�����ÿһ���ۺ����һ���ִ����ִ�ͨ���ۺϸ��ԾۺϽ��й�����������ģ�Ͳ��У��������ͨ���ִ���Լ���ӿڣ���ʵ�ֶԲִ��ķ��ʵģ���������ʹ������ģ�Ͳ������˽��κβִ��ľ���ʵ�ֺͳ־û�ϸ�ڣ�Persistence
Ignorance�������߿��Բο���ǰ��д�ġ�EntityFramework֮�����������ʵ�����ˣ���һ�ġ����⣬����ͨ�������ġ����ݷ��ʶ���Data
Access Object���������Dzִ������ȣ��ִ�ͨ���ۺϸ������������ۺϵĶ�ȡ�ʹ洢������һ�������������ݷ��ʶ������ǶԵ�������ȷ�е�˵Ӧ���ǵ������ݽṹ��ֱ�ӽ������ݿ��������Σ�������ʽҲ��ͬ���ִ������ύǰ�ȶ��ڴ��еĶ�����б�ǣ�����һ���ύ���̣�Unit
Of Work��PoEAA���������ϲ������������Ӧ�ò㣩����ɵ�
- �㳬���ͣ�Layer Supertype��PoEAA����ͨ������ʵ��ij����ض�����ʱ�����ǻὫһϵ�ж���Ĺ�������ȡ������Ȼ����Щ������һ�����������У�ͬʱʹ���������Ͷ��̳��ڸó��������Ա������ظ��������ij������ͱ���Ϊ�㳬���͡���������ݷ����������ʹ�ò㳬�����Լ��������ٴ���ά���ɱ������磬��ʵ������ADO.NET�����ݿ�������ʱ�����ǿ����ڲ㳬������ʹ��DbConnection��DbCommand�ȶ���ʵ�ֹ�������Ȼ���������м̳���Щ�����ṩ�����SqlConnection��SqlCommand����OleDbConnection��OleDbCommandʵ��
- ����ģ�ͣ�Data Model�������ʹ��ORM��ʵ�ֲִ�����ôͨ�������ORM����ʹ��һ������ģ�ͣ�����Entity
Framework����ʵ����Ҫ�Ĺ��ܣ�����������ģ���е���ʵ��ģ�ͣ����������ݴ������һ����������ģ�Ͳ��ʵ��ģ������ȫ��ͬ�ġ�����ģ��������һ�ֿ��ӻ���ͼ����������ר�ŵĿ��ӻ���ƹ��߸���ά��
- Զ��/�ⲿ����������������ⲿϵͳ��ʵ�����ݳ־û�����ʱ��Զ��/�ⲿ����������������ⲿϵͳ��ת�����ݲ���������Ӧ��Ϣ
- �����ṹ�㣨Cross-Cutting�����ò��ṩ���ܱ�����������ʵ�ͨ�ü�����ܣ������쳣�����봦������־����֤����Ȩ����֤�����١����ӡ�����ȵȡ���Щ����ͨ�������ɢ����Ӧ�ó���ĸ������棬����ƽʱ���۵��������̣�AOP����ע�ľ�������ڲ�Ӱ��������������Ļ�������ʵ����Щ���е�ȴ�ֱز����ٵĹ��ܵ㡣��ʵ���У�ͨ��ʹ��һЩ���е�Interception��ܣ�����Microsoft
Unity��Castle DynamicProxy�ȣ����������Ƿ����ʵ��AOP
�ܽ�
��������������Ϊ�������Microsoft NLayerApp��Ŀ������ϸ�ض�DDD����ֲ�ܹ����˽��ܣ�����Ҳ�����˲���������Martin
Fowler����ҵӦ�üܹ�ģʽ��PoEAA����һ���������ܵĸ�����ģʽ���ƣ������������Ѹ��õ�����DDD�ֲ�ܹ��и������Ҫְ���롶Microsoft
NLayerApp����������ʵ�� - ���ܹ���Ӧ��ϵͳ���ԭ��һ��һ��ͨ������ƪ���µ�ѧϰ�������Ѿ���Ӧ�ó���������ܹ����Լ�DDD���ܹ�����ֲ�����һ�����˽⡣�����½ڿ�ʼ�����ǻ�ѱ����������ķֲ�ܹ���Microsoft
NLayerApp��Ŀ�����������һ��ѧϰMicrosoft NLayerApp��Ŀ�ľ���ʵ�֡�
Microsoft NLayerApp����������ʵ�� - �����ṹ�㣨Cross-Cutting���֣�
����ƪ���¿�ʼ���ҽ�����NLayerApp�Ļ����ṹ�㡢����㡢Ӧ�ò��Լ��ֲ�ʽ����㡣�������ؽ��ܻ����ṹ�㣬�������Ķ�NLayerApp�ļܹ������������������ֵ����ݣ��������ݷ��ʵĻ����ṹ�������Cross-Cutting�Ļ����ṹ��������������ݷ��ʵĻ����ṹ�������Ҫ�����˲ִ��ľ���ʵ�֡�Unit
Of Work��PoEAA��Martin Fowler����ʵ�֡�NLayerApp��ʵ��ģ�Ͷ��壬�Լ�Ϊ�������������Service
Stubs��PoEAA��Martin Fowler����Cross-Cutting�Ļ����ṹ���������Ҫ������IoC��Inversion
of Control�������Լ�����Ӧ�ó���ִ�й��̵�Trace���ߡ���Ȼ��Щ���ǻ����ṹ����������Ҳ�����˺ܶ༼��ϸ�����������Ҫ�㣬��������һ�����Щ������һ����ϸ�Ľ����
NLayerApp��IoC������ʵ��
��Ӧ�ó�����ƵĹ����У����ǻ��������һ�������������֮��Ĺ���Ӧ�������ڽӿڻ��߳����Ǿ����ʵ�֡�������ʹ�������ܹ��ڱ�֤��������ṹ���������£��ܷ�����滻����ľ���ʵ�ַ�ʽ���ⲻ��ʹ��Service
Stubģʽ��Ӧ�ó�Ϊ���ܣ��Ӷ������ϵͳ�Ŀɲ����ԣ����ҽ��������֮���������ϵ��������Ӧ�ó����ά���ɱ���IoC����������һ�ֶ�������Ӧ�ó����ִ�л�����ά���Žӿ�����ʵ��֮���ӳ���ϵ���Լ�����ʵ�ֶ���֮���������ϵ���Ա㵱�ͻ�������IoC�����������ʱ���ܹ�������������Ľӿڻ������������Ӧ�ľ���ʵ�֣��ͻ�������Ҫȥ���ķ��صľ���ʵ�־�����ʲô���Լ����ȥ��ʼ���������ʵ�֡����IJ����IoC������Ľ��ܣ�����Ȥ�����ѿ����Ķ���Inversion
of Control Containers and the Dependency Injection pattern����ƪ���¡�
NLayerApp��IoC������ʵ��������Microsoft Patterns&Practices
Unity����ʵ�����Ӧ�ó��������ǿ�����ܶ��������ڵ������������ʵ��IoC��������ΪIoC�����漰�����ݾͱȽ϶࣬�ܺõؽ������֮�临�ӵ�������ϵҲ����һ�����������顣Unity����IoC��Ψһѡ����Unity֮�⣬Spring.NET��Castle
Windsor��Ninject��StructureMap�ȶ����Գ�ΪIoC����������ѡ��NLayerApp����IoC����ʵ���йص��༰��֮��Ĺ�ϵ����ͼ��ʾ��

����ͼ�У�IContainer�ӿڶ�����IoC������صķ���������������ʵ�ּ����صĽӿڣ��ӿڵIJ�νṹ�������ж���ķ����IJ����Լ�����ֵ�ȶ������������κε����������������ˣ����������ǿ���ͨ���̳�IContainer�ӿ�Ȼ���������Լ��ļ�����ʽ��ʵ��IoC������NLayerApp��ʹ��Unity��ΪIoC�����ģ���ˣ���ͼ��IoCUnityContainer��ʵ����IContainer�ӿڣ�Ȼ����IoCFactory�ĵ���ʵ����ͨ��new�ؼ��ִ�����IoCUnityContainer��ʵ����
#region Constructor
/// <summary>
/// Only for singleton pattern, remove before field init IL anotation
/// </summary>
static IoCFactory() { }
IoCFactory()
{
_CurrentContainer = new IoCUnityContainer();
}
#endregion |
��Ȼ������NLayerApp��һ�ض���Ӧ�ó��������ԣ���������ûʲô����ģ����������Ŀǰ��Ƶ���һ��������ܵĻ���ֱ��ʹ��new�ؼ���������IoCUnityContainer��ʵ�����ͻ�ʹ��IoCFactoryǿ��������IoCUnityContainer���ͣ�����Ҳ��Υ���ˡ�����Ӧ�������ڽӿڻ��߳����Ǿ���ʵ�֡�������������°��Apworks��ܵĴ����У�������Ա����ͨ��Ӧ�ó����������Ϣ��ѡ����ʵ�IoC�����������������Ӧ�ó���������ʱ��;�����ʹ��Unity����Castle
Windsor�����ʹ�ÿ�ܱ������и��õ���չ�ԡ��ղ�����Ҳ���۹������ҪʹNLayerApp�ܹ�ʹ�������Զ����IoC��������Ҫ�̳�IContainer�ӿڣ���ô�������ǻ���Ҫ��IoCFactory��˽�й��캯������ʹ�������Լ���IoC��������ʼ��_CurrentContainer˽�г�Ա��
Unity������һ���dz�ʵ�õ��ص㣬���ǡ����������롰���������ĸ���ڡ�����������ͨ������CreateChildContainer�������ɴ�����֮���������������������������������Խ��ܳ������͵�ע�ᡣÿ���ͻ��������������������ͣ�Resolve
Type��ʱ��Unity���ȼ�����������Ƿ�������������ͣ�����У���ֱ�ӷ��ظ����͵ľ���ʵ�֣����û�У���Ὣ������ת�����丸����������Unity���������ԣ����ǿ��Խ���Բ�ͬ������IoC��������ͳһ���������罫���ֲ�������ͬ������ӳ��ע���ڸ������У�Ȼ��Ϊÿ����������һ�������������벿����ص��ض�����ӳ��ע���ڸ��Ե��������С���ͼչʾ��NLayerApp��Unity
IoC�����Ļ��������

ͨ���Ķ�IoCUnityContainer��Դ�������ǿ����˽����IoCUnityContainer�Ĺ��캯���У�������rootContainer������rootContainer��ʹ��CreateChildContainer������������ʵ���л�����realAppContainer�Լ����ڵ�����Ե�fakeAppContainer��֮�����ʹ�������˽�з��������ʼ����Щ������
/// <summary>
/// Configure root container.Register types and life time managers for unity builder process
/// </summary>
/// <param name="container">Container to configure</param>
void ConfigureRootContainer(IUnityContainer container)
{
// Omitted... Please refer to the source code for details.
}
/// <summary>
/// Configure real container. Register types and life time managers for unity builder process
/// </summary>
/// <param name="container">Container to configure</param>
void ConfigureRealContainer(IUnityContainer container)
{
container.RegisterType<IMainModuleUnitOfWork, MainModuleUnitOfWork>(new PerExecutionContextLifetimeManager(),
new InjectionConstructor());
}
/// <summary>
/// Configure fake container.Register types and life time managers for unity builder process
/// </summary>
/// <param name="container">Container to configure</param>
void ConfigureFakeContainer(IUnityContainer container)
{
//Note: Generic register type method cannot be used here,
//MainModuleFakeContext cannot have implicit conversion to IMainModuleContext
container.RegisterType(typeof(IMainModuleUnitOfWork),
typeof(FakeMainModuleUnitOfWork), new PerExecutionContextLifetimeManager());
} |
��ConfigureRootContainer�����У������л�������ʵ���л����Լ�������Ի�������Ҫ�õ������ͽ�����ע�ᣬȻ��IMainModuleUnitOfWork���ԣ�������ʵ���л����͵�����Ի�����ʹ�õ�Unit
Of Work����ʵ�ֲ�ͬ����ʵ���л���ʹ�õ���MainModuleUnitOfWorkʵ�֣������Ի�������ʹ�õ�FakeMainModuleUnitOfWork�����ǣ�Ҳ����ConfigureRealContainer��ConfigureFakeContainer�����зֱ�����ע�ᡣ
���ÿ��IContainer.Resolve����������ʱ��ϵͳ��ͨ����ȡ�����ļ�������ĿǰӦ��ʹ���ĸ��������������ͣ���ˣ�����ֻ��Ҫ�������ļ�����ȷ�������������ƣ�������NLayerApp��ʹ��ָ����Unity
IoC�������������������Ϣ������DistributedServices.Deployment��Ŀ���������ǿ��Կ�����NLayerApp��Distributed
Servicesʹ�õ���realAppContainer��
<appSettings>
<!--RealAppContext - Real Container-->
<!--FakeAppContext - Fake Container-->
<!--<add key="defaultIoCContainer" value="FakeAppContext" />-->
<add key="defaultIoCContainer" value="RealAppContext" />
</appSettings> |
NLayerApp�����ڸ��ٳ���ִ�й��̵�Trace����
NLayerApp��Trace���ߵ�ʵ�ַdz�����Infrastructure.CrossCutting��Ŀ�ж�����ITraceManager��Ȼ����Infrastructure.CrossCutting.NetFramework��Ŀ�ж�����ITraceManager�ľ���ʵ�֡�TraceManagerʹ����System.Diagnostics�����ռ�����Trace��ص�����ʵ���书�ܣ�Ӧ�ó�����ͨ��IoCFactory�����ITraceManager�ľ���ʵ�֡�
���������۵�ConfigureRootContainer�����У�NLayerApp��ITraceManager���ͽ�����ע�
//Register crosscuting mappings
container.RegisterType<ITraceManager, TraceManager>(new TransientLifetimeManager()); |
��ˣ�������Ӧ�ó����У��Ϳ���ʹ������ķ�ʽ����ȡITraceManager�ľ���ʵ�֣��Ա����Trace���ܣ�
ITraceManager traceManager = IoCFactory.Instance.CurrentContainer.Resolve<ITraceManager>();
traceManager.TraceError(/* error message*/); |
�ܽ�
���Ķ�NLayerApp�Ļ����ṹ�㣨Cross-Cutting���֣��������о���̽�֣����ⲿ����ص���Ŀ�У�Infrastructure.CrossCutting��Infrastructure.CrossCutting.IoC�Լ�Infrastructure.CrossCutting.NetFramework����һ�����ǽ������о�NLayerApp�Ļ����ṹ�㣨���ݷ��ʲ��֣���
Microsoft NLayerApp����������ʵ�� - �����ṹ�㣨���ݷ��ʲ��֣�
��ƪ���½�����NLayerApp�����Ļ����ṹ�㣨Cross-Cutting���֣������ڣ������Ǽ������NLayerApp�Ļ����ṹ�㣨���ݷ��ʲ��֣���NLayerApp�Ļ����ṹ�㣨���ݷ��ʲ��֣������������ݣ�Unit
Of Work��PoEAA�����ִ��ľ���ʵ�֡�NLayerApp������ģ���Լ��������ص��ࡣ���棬���ǽ���ǰ�������ֽ������ۣ��������ص����ݣ��Ҵ������һ�½��н��ܡ�
Unit Of Work��PoEAA��
Unit Of Work��UoW��ģʽ����ҵӦ�üܹ��б��㷺ʹ�ã����ܹ���Domain
Model�ж���״̬�ı仯�ռ������������ʵ���ʱ����ͬһ���ݿ����Ӻ���������������һ���Խ�����ı���ύ�������С���û������UoW֮ǰ���������ÿ�����ӡ�ɾ��������߸��Ķ���״̬��ֱ�ӵ������ݿ��Ա������ı仯�����������ᵼ��Ӧ�ó�������ݿ���һ�ⲿ�����ܹ���Ƶ�����ʣ�����Ӱ����ϵͳ���ܡ���ͺ������Ǵ�Notepad�������ֱ༭һ����������ȫ����ÿ����һ���ַ����Ͱ���Ctrl+S����һ�Σ����������dz���ʱ��Ҳû��Ҫ��������ͨ�������������ǣ�ÿ���һ������ı༭�������ַ���ɾ���ַ����߸����ַ��ȣ��ٱ���һ�Σ���ôNotepad�ͻ������DZ༭�����ʱ����ٶ��估�����ַ��ı仯��������һ���Խ���Щ���д��Ӳ���ϡ���UoW��ģʽ�����Ͽ������е������ݿ�����Transaction������Ϊ���Ƕ����С��ύ���͡��ع����IJ��������������Ͻ����������ܵ�ͬ�����ݿ������Ҿ���Ӧ���������⣺���ǿ��Խ�UoW������һ������������������ݿ����������������������ܹ���һ��ԭ�Ӳ����н�����һ�����ύ���־û����ƣ�����������ύ�����г������⣬�����ܽ����ص��ύǰ��״̬��������ˣ�UoW�����и����������仯�Ĺ��ܣ����ܹ�����ijһ��ҵ���跶Χ���������ı仯�������������������У�ÿ������ı༭�Ϳ��Կ�����һ��ҵ���裬��ô�����ҵ�����У��༭����Ĺ����У���UoW������������и��٣�����ҵ�������֮ʱ����ɶ���༭֮ʱ����UoW�ͻ�Ը��ٵ��ı����һ�����ύ��
������ķ��������Ǵ����˽��UoW��ִ�һ��������Ӧ��������Domain
Model�ģ��������Ӧ���Ǽ����صģ�Ҳ���dz�˵��POCO����IPOCO������Ϊ�����ٵ���Domain
Model���������ı仯�������Ȼ��һ�����õ����Ӧ����ʹ��Separated Interface��PoEAA��ģʽ����UoW�ӿ���ִ��Ľӿ�һ�������Domain
Model�С���UoW��ʵ����������NLayerApp������Entity Framework��һЩ���ԣ�������Entity
Framework��ģ�ͣ�����T4�Զ����������롣Ŀǰ���Dz�Ҫȥ������NLayerApp�������ʹ��T4������Щ����ģ�������Ҫ���ĵ���Ϊʲô��Ҫ������Щ���롣�й�Visual
Studio�е�ģ����Ŀ��Domain Specific Language��DSL���Լ�T4�����Զ������ɣ������ڴ˽��������ۡ�����Ȥ�����ѿ��Բο���ǰ������¡���Visual
Studio 2010��ʹ��Modeling Project����DSL�Լ��Զ����������ɡ���������NLayerApp����UoW��ص����ϵͼ��

���˽�NLayerApp��UoWִ�л���֮ǰ�������������˽�һ��NLayerApp����UoW��ص������ӿڡ�
- IObjectWithChangeTracker�ӿ�
�ýӿ���ֻ������һ��ObjectChangeTracker�����ԣ���NLayerApp�У����е�ʵ�嶼Ҫʵ��IObjectWithChangeTracker�ӿڣ�������磨��Ҫ��UoW�Ͳִ����ṩObjectChangeTrackerʵ����ObjectChangeTracker����Ҫ���ܾ��Ǽ�¼��ǰʵ���е�״̬�仯�����磬ʵ��ĵ�ǰ״̬�����ǰ�������Ե�ԭʼ���ݡ����������ӵ����ж��Ӽ���������ɾ�������ж���ȵȡ����ִ�ͨ��Unit
Of Work��ע���ѱ����ʵ��ʱ��Unit Of Work��ʹ��ObjectChangeTracker���ṩ����Ϣ����Entity
Framework���б��ע�ᡣ
- INotifyPropertyChanged�ӿ�
NLayerApp��ʵ�岻��ʵ����IObjectWithChangeTracker�ӿڣ�ͬʱ��ʵ����INotifyPropertyChanged�ӿڡ�ʵ������ӿڵ���ҪĿ�ľ���Ϊ����ʵ���ij�����Է����仯ʱ���ܼ�ʱ�ؽ����ֱ仯��¼��ObjectChangeTracker�С���ˣ�ֻҪ�ͻ�����ͨ��ʵ����������ı�ʵ���״̬ʱ��ʵ�屾���ͻὫ״̬�仯��¼��ObjectChangeTracker�С�
- IRepository�ӿ�
IRepository�ӿ��Ƕ�����Domain Model��Ľӿڣ�֮�����ڴ��ἰ������Ϊ����ij־û�������ͨ���ִ���ɵģ����־û����벻��UoW����NLayerApp�У�IRepository�ӿ���һ��IUnitOfWork�����ԣ�������еIJִ�������ʵ��������ԣ��Ա�Repository�ܹ���UoW�м�¼����ı����Ϣ����NLayerApp��Դ������Կ�������ʵ�ִ�������������ʵ�屣�浽���ݿ����һ����������ֻ��ͨ��IObjectWithChangeTracker�ӿڣ�����Ҫ����Ķ�������Ϊ��Ӧ��״̬������UoWע���������ʣ�µ������ݿ��������������UoW��ɵ�
ͨ����Щ��Ϣ���ǿ����˽��NLayerApp�е�ʵ�嶼�Ǹ��Թ����Լ��ı����¼����֮Ϊ���Ը���ʵ�塱��Self-Tracking
Entities��STE������ʵ��DDD�ĽǶ�������STE������һ���ܺõ���ƣ���Ϊ����Domain Model������̫�༼����ע�㡣������ʵ��STE��ʱ������Customer����һ��Orderʱ������Ҫ�����ж�Customer��ObjectChangeTracker���Ƿ��Ѿ�����Order���Ϊ��ɾ����״̬�ˣ�����������Ļ�����ô����Ҫ�����Order��ObjectChangeTracker�ġ�ɾ�����б�����ȥ������������ҵ��������Ӧ�÷���Domain
Model�С����⣬NLayerAppΪ��ӭ��Entity Framework��������ʵ�ֵ�STEҲ���Ǵ�����뼼���صġ�UoW��ʵ��Ҳ����ˣ��������������ͼ�У����ǿ��Ժ����Եؿ�����MainModuleUnitOfWork��ObjectContext�����ࡣ
�������ǽ�˼·��������������CustomerΪ�����������ܹ�����˵����ϲ㣨Distributed
Service�㣩��ʼ������Unit Of Work��ִ������Э���ġ�
1��DistributedServices.MainModule��Ŀ��MainModuleService��ͨ��ʹ��λ��Ӧ�ò��CustomerManagementServiceʵ��Customer��Ϣ�ı����
public void ChangeCustomer(Customer customer)
{
try
{
//Resolve root dependency and perform operation
ICustomerManagementService customerService = IoCFactory
.Instance
.CurrentContainer.Resolve<ICustomerManagementService>();
customerService.ChangeCustomer(customer);
}
catch (ArgumentNullException ex)
{
// ......
}
} |
��������ͨ��IoCFactory��IoC�����л��ICustomerManagementService�ľ���ʵ�֣��й�NLayerApp��IoC������ʵ�֣���ο�ǰһƪ���¡�
2��Application.MainModule��Ŀ��CustomerManagementService��ʵ����ICustomerManagementService�ӿڣ�ͬʱʵ����ChangeCustomer�������ڸ÷����У�����ͨ��CustomerRepository��UnitOfWork���Ի��UoW��Ȼ����òִ���Modify�����Խ�Ҫ���ĵ�Customerʵ��ע�ᵽUoW�У�ͬʱ�ı���Customerʵ���״̬�����ʹ��UoW��CommitAndRefreshChanges�����������ʵ������ύ�����ݿ⣺
public void ChangeCustomer(Customer customer)
{
if (customer == (Customer)null)
throw new ArgumentNullException("customer");
IUnitOfWork unitOfWork = _customerRepository.UnitOfWork as IUnitOfWork;
_customerRepository.Modify(customer);
unitOfWork.CommitAndRefreshChanges();
} |
ֵ��һ����ǣ���CustomerManagementService�У�CustomerRepository�Թ�����ע��ķ�ʽ���ʵ�����ģ�
/// <summary>
/// Create new instance
/// </summary>
/// <param name="customerRepository">Customer repository dependency,
/// intented to be resolved with dependency injection</param>
/// <param name="countryRepository">Country repository dependency,
/// intended to be resolved with dependency injection</param>
public CustomerManagementService(ICustomerRepository customerRepository,
ICountryRepository countryRepository)
{
if (customerRepository == (ICustomerRepository)null)
throw new ArgumentNullException("customerRepository");
if (countryRepository == (ICountryRepository)null)
throw new ArgumentNullException("countryRepository");
_customerRepository = customerRepository;
_countryRepository = countryRepository;
} |
3��Infrastructure.Data.Core��Ŀ��Repository���Modify�������Ƚ���ǰ״̬����Deleted��ʵ������Ϊ��Modified����ͬʱ��UoW�У�ͨ��RegisterChanges��������UoWע���ʵ�壺
public virtual void Modify(TEntity item)
{
//check arguments
if (item == (TEntity)null)
throw new ArgumentNullException("item", Resources.Messages.exception_ItemArgumentIsNull);
//Set modifed state if change tracker is enabled and state is not deleted
if (item.ChangeTracker != null
&&
((item.ChangeTracker.State & ObjectState.Deleted) != ObjectState.Deleted)
)
{
item.MarkAsModified();
}
//apply changes for item object
_CurrentUoW.RegisterChanges(item);
_TraceManager.TraceInfo(
string.Format(CultureInfo.InvariantCulture,
Resources.Messages.trace_AppliedChangedItemRepository,
typeof(TEntity).Name));
} |
4��Infrastructure.Data.MainModule��Ŀ��MainModuleUnitOfWork���RegisterChanges����������Entity
Framework���ṩ�Ļ��ƣ���Entity Frameworkע�����״̬���������Entity Framework����ʵ�ֵ�ϸ�����ݣ������ڴ�Ҳ��ȥ����������е�ʵ�ַ�ʽ�ˣ�
public void RegisterChanges<TEntity>(TEntity item)
where TEntity : class, IObjectWithChangeTracker
{
this.CreateObjectSet<TEntity>().ApplyChanges(item);
} |
5��Infrastructure.Data.MainModule��Ŀ��MainModuleUnitOfWork���CommitAndRefreshChanges����ͨ��Entity
Framework������ύ�����ݿ⣬ͬʱ��ʵ������״̬����Ϊ��δ���ġ���
public void CommitAndRefreshChanges()
{
try
{
//Default option is DetectChangesBeforeSave
base.SaveChanges();
//accept all changes in STE entities attached in context
IEnumerable<IObjectWithChangeTracker> steEntities = (from entry in
this.ObjectStateManager
.GetObjectStateEntries(~EntityState.Detached) where
entry.Entity != null &&
(entry.Entity as IObjectWithChangeTracker != null)
select
entry.Entity as IObjectWithChangeTracker);
steEntities.ToList().ForEach(ste => ste.MarkAsUnchanged());
}
catch (OptimisticConcurrencyException ex)
{
//......
}
} |
����ִ�й������ǿ���ʹ�����������ͼ����ʾ��

NLayerApp�е�Unit Of Work�����Ƚ��ܵ���������ʵ����ѿ��������۵ķ�ʽ������
�ִ��ľ���ʵ��
NLayerApp�еIJִ�ʵ��Ҳ�ǻ����ṹ�㣨���ݷ��ʲ��֣���һ����Ҫ�������һ����DDD�ľ���ܹ����������ġ���Ϊ�������Ͻ����ִ��ľ���ʵ����Ҫ�������ⲿϵͳ�����ⲿ�������Dz��ܱ�¶��Domain
Model��ģ�Ҳ��������ƽʱ��˵�ģ���Ҫ����Persistence Ignorance��NLayerApp����Ϊ����ʵ�壨ȷ�е�˵Ӧ���Ǿۺϸ��������һ��ͨ�õķ��Ͳִ����������Infrastructure.Data.Core��Ŀ���ҵ�������Ͳִ���Դ���룬��ʵ����һ���ִ�Ӧ���е����л������ܣ��������ӡ�ɾ������ʵ������Լ����ڹ�Լ��һЩ��ѯ�����ȣ�Ȼ�����ijЩ�ۺϸ���NLayerApp�������Ŀ��ʵ�������ڲִ���ʵ��һЩ�ض��IJ��������磺CustomerRepository�̳���Repository���ͨ�òִ���ͬʱʵ����ICustomerRepository�ӿڣ���������ṩͨ����Լ��Specification��������Customer��Ϣ�Ĺ��ܡ������������һ���̶��������˹�ע����룬���統���Ƕ�ʵ�����ͨ�õIJִ�����ʱ������ֻ��Ҫ���IRepository�ӿڵľ���ʵ�ּ��ɣ�������ʹ��ICustomerRepository�������Customer�йصIJִ�ʵ�֡��й�ICustomerRepository���ע������������ݣ��ҽ�����һ��������ģ�Ͳ㣩���н��⡣
������NLayerApp�вִ������ϵͼ���ڴ������Թ����߲ο���

NLayerApp�IJִ�ʵ��Ҳʹ���˲�����Entity Framework��صļ���ϸ�ڣ�����ObjectSet�ȣ���Щ���Ǿ��弼��ʵ���ϵ����ݣ��ڴ˾Ͳ����������ˡ�����Ȥ�Ķ�����ο���Entity
Framework������ص������ĵ���
NLayerApp������ģ��
NLayerAppʹ��Entity Framework��ADO.NET
Entity Data Model��������������ģ�ͣ���ʹ�������ܹ�������Domain Model�Ķ���ṹ��һ����ֱ�۵���ʶ��������ģ��λ��Infrastructure.Data.MainModule��Ŀ�£�ֱ��˫��MainModuleDataModel.edmx�Ϳ�����������д�����ṹ����֮��Ĺ�ϵ���ܺ������չ��������ǰ����ᷢ�֣���ʵ���������ģ�͵ĺ�̨�����ļ��У�����һЩע�����⣬��û���κ�ʵ�������ݣ�������ΪNLayerApp���������������������������ģ�ͣ���������Domain
Model�Ĵ��������Domain Model���У����ݸ�����ģ�ͣ�����T4�����Զ������ɣ��������Domain.MainModule.Entities��Ŀ����Ҳʹ�����ǻ�ȥ˼������һ����������⣺Entity
FrameworkΪ�����ṩ�ģ�������һ���������ݿ���Ƶ�����ģ�ͣ�����������������������ģ�ͣ�������ʵ��Ӧ���У����Ǹ�����ǽ������ORM��λ���ϣ�����Entity
Data Model�ͱ����λ��Domain Modelʵ����������ݿ�֮�����������ڣ�Row Data
Gateway��PoEAA����֮ǰ�Ҷ��ڻ���Entity Framework�������������ʵ��Ҳд��һЩ���£��������ѿ��Բο��������������ϵ�����»��ܡ���
�ܽ�
���Ķ�NLayerApp�Ļ����ṹ�㣨���ݷ��ʲ��֣���������Unit
Of Work��ʵ�ֽ����˷�������ܣ���һ����ʼ�����ǽ�һ��ѧϰNLayerApp��Domain Model���֡�
Microsoft NLayerApp����������ʵ�� - ����ģ�Ͳ�
���Ľ��ص����Microsoft NLayerApp������ģ�Ͳ㣬���漰��Domain.Core��Domain.Core.Entities��Domain.MainModule�Լ�Domain.MainModule.Entities�ĸ���Ŀ��Domain.Core��Ŀ�����˻����ӿڵĶ����Լ���Լģʽ��Specification
Pattern����ʵ�֣�Domain.Core.Entities�������֧��Entity Framework��STE��Self-Tracking
Entity����ʵ�ִ��룬�����ġ�Microsoft NLayerApp����������ʵ�� - �����ṹ�㣨���ݷ��ʲ��֣����Ҷ�STE����һЩ���ܣ�������ʵ����Entity
Framework��EF����ϵıȽϽ��ܣ�EF�����˱�ϵ�����µ����۷�Χ����ˣ�����Ҳ�������STE�ľ���ʵ�ַ�ʽ��̫�����ۣ�Domain.MainModule������Ŀ������Բ�ͬ��ʵ�嶨���˲ִ��ӿڣ�ͬʱʵ������Ŀ����Ĺ�Լ���͡��������Ҳ�Ǹ���Ŀ����Ҫ���֣�Domain.MainModule.Entities��Ŀ�а�����NLayerApp����ģ�͵ĺ��Ĵ��롣���Ľ��Ӳִ��ӿڡ���Լ�������������ģ�����ĸ������NLayerApp��Domain
Model����һ���Ľ��ܡ�
�ִ��ӿ�
���������ڡ�Microsoft NLayerApp����������ʵ���CDDD���ֲ�ʽDDD����ֲ㡷һ���е����ۣ��ִ��ľ���ʵ���Ƿ��ڻ����ṹ��ģ����ִ��Ľӿ����Ƿ�������ģ�Ͳ�ġ�Domain.Core��Ŀ��IRepository�ӿھ��Dzִ��ӿڣ����еIJִ����Ҫʵ�ָýӿ��ж���������뷽������Domain.Core��Ŀ�»���һ���̳�IRepository�ӿڵ�IExtendedRepository�ӿڣ���������һЩ����ķ�������չIRepository�Ĺ��ܡ���ʵ��������NLayerApp�в�û�������õ�IExtendedRepository�ӿڣ��������Ҳ���ڴ����������ۡ���ͼ��NLayerApp����ִ��Ľӿں�ʵ����ص����ϵͼ��Ϊ�˷����������������ͼ�н�������Customer�ִ��Ķ�����ʵ�ֲ��֣�

���ȣ�ICustomerRepository�ӿڼ̳���IRepository�ӿڣ�����չIRepository�������ض���Customerʵ��IJִ�����ˣ�����ʵ��ICustomerRepository�ӿڵ��࣬�����߱��ִ��Ļ������ܣ����һ������ض���Customerʵ��IJִ���������Σ�Repository��ʵ����IRepository�ӿڣ�����Ϊ���вִ�ʵ�ֵĻ��࣬ʵ����IRepository�ӿ��ж���ķ��������ڲִ����ֵĽ�ɫ����һ���㳬���ͣ�Layer
Supertype�������CustomerRepository��̳���Repository�࣬ͬʱʵ����ICustomerRepository�ӿڣ�����Repository�����Ѿ�ʵ����IRepository�ж�������з��������CustomerRepository�������ȥʵ����Щ������ֻ��Ҫ�ѹ�ע�����ICustomerRepository��ʵ���ϼ��ɡ�������λ�ڻ����ṹ���CustomerRepository���룬���������Ѳο���
public class CustomerRepository
:Repository<Customer>,ICustomerRepository
{
#region Constructor
/// <summary>
/// Default constructor
/// </summary>
/// <param name="traceManager">Trace manager dependency</param>
/// <param name="unitOfWork">Specific unitOfWork for this repository</param>
public CustomerRepository(IMainModuleUnitOfWork unitOfWork, ITraceManager traceManager)
: base(unitOfWork, traceManager) { }
#endregion
#region ICustomerRepository implementation
/// <summary>
/// <see cref="Microsoft.Samples.NLayerApp.Domain.MainModule.Customers.ICustomerRepository"/>
/// </summary>
/// <param name="specification">
/// <see cref="Microsoft.Samples.NLayerApp.Domain.MainModule.Customers.ICustomerRepository"/>
/// </param>
/// <returns>Customer that match <paramref name="specification"/></returns>
public Customer FindCustomer(ISpecification<Customer> specification)
{
//validate specification
if (specification == (ISpecification<Customer>)null)
throw new ArgumentNullException("specification");
IMainModuleUnitOfWork activeContext = this.UnitOfWork as IMainModuleUnitOfWork;
if (activeContext != null)
{
//perform operation in this repository
return activeContext.Customers
.Include(c => c.CustomerPicture)
.Where(specification.SatisfiedBy())
.SingleOrDefault();
}
else
throw new InvalidOperationException(string.Format(
CultureInfo.InvariantCulture,
Messages.exception_InvalidStoreContext,
this.GetType().Name));
}
#endregion
} |
������ͼ������ICustomerRepository�ӿ���չ��IRepository�ӿ����ṩ��Customer�йصIJִ�����������Ӧ�ó��������˵��������������������ϵͳ����չ�ԡ�����֮ǰ���������Apworks������ʣ�����Apworks�IJִ��ӿ�ֻ�ṩ��һЩ�ܻ����IJ���������ϣ���ܹ��ڲִ�������һЩ�����ҳ��ѯ����IJ�����֮ǰ��������ǣ����ⶨ��һ���ӿڣ�IFooRepository������������һЩ��ҳ��ѯ������Ȼ���òִ�ʵ��ͬʱʵ��IRepository��IFooRepository�����£�

����������ȥFooRepository��һ�������IJִ�ʵ�֣���IFooRepository��IRepository֮��û���κ���ϵ��IFooRepository������û�����֡��ִ��������壬����ԭ������һ�ֲִ�����ʵ���Ͽ���������Ҫ��IoC�����зֱ�ΪIRepository��IFooRepositoryע����ͬ�����ͣ�FooRepository���Ա��ڳ������ܹ���ȷ�ؽ���IRepository��IFooRepository�ľ���ʵ�֣��Ӷ�ͨ��IRepository����IFooRepository�ֱ��ò�ͬ�IJִ���������Ȼ����������Ŀǰ�����Σ�FooRepositoryͬʱʵ��IRepository��IFooRepository�ӿڣ���ôC#�ǿ���ͨ��as�ؼ��ֽ���ʵ����IRepository��IFooRepository��ʵ�������ת���ģ����磺
IContainer container = IoCFactory.Instance.CurrentContainer;
using (IRepositoryContext ctx = container.Resolve<IRepositoryContext>())
{
IRepository<Foo> repository = ctx.GetRepository<Foo>();
// do sth. with repository ...
IFooRepository<Foo> fooRepository = repository as IFooRepository<Foo>();
if (fooRepository != null) // this is required...
{
// do sth. with fooRepository
}
} |
������Ӧ�ó����Ĺ����У�������ȥԼ��������Աһ��Ҫ��FooRepositoryȥʵ��IFooRepository�ӿڣ������������������ת�����ɹ�����ˣ��ж�fooRepositoryʵ���Ƿ�Ϊ�վ��Ե÷dz���Ҫ��
��������ƻ�������һ��ȱ�ݣ���������IFooRepositoryû�����֡��ִ��������壬��͵�������Ӧ�õ����ڲִ�������Լ���ϡ����磬�����������������Ҫ�õ�һ���ӿ�IMyInterface�����Ķ������£�
interface IMyInterface<T, S>
where T : IRepository<S>
where S : class
{ } |
��ô���������Ǿ���ȥ����һ���࣬���������ͨ�����Ͳ���T��ʹ��IFooRepository�ӿڣ�
// error:
class MyClass : IMyInterface<IFooRepository<MyEntity>, MyEntity>
{ } |
���֮�£�NLayerApp����һ����������������Ϊ��������ƣ�����ͼ��������������ˡ�IFooRepository��һ�ֲִ����ĸ����֮�����ֲ�ͬ����Ƶ���Ҫ�����ڸ����������������������ϡ�

��Լ��Specification��
��Domain.Core��Ŀ�£�NLayerApp������Ӧ�ó�������ģ�Ͳ�����Ҫ�õ��Ĺ�Լ��ܣ���Ҫ��ͨ��LINQ
Expression��ʵ�ֵġ���ISpecification�ӿ��ж�����SatisfiedBy�������÷�������һ��LINQ
Expression������ִ���ж���������Ƿ��ܹ����㵱ǰ��Լ����������NLayerApp�Ĺ�Լ�ṹ����ͼ��ʾ��

�йع�Լģʽ����μ�����Specifications������Specification
Pattern�����йع�Լģʽ��Ӧ�ó����Լ�֧��LINQ Expression��.NET��Լʵ�֣���μ�����EntityFramework֮�����������ʵ����ʮ������Լ��Specification��ģʽ�������ľͲ����ظ���Щ�����ˡ�
ֵ��һ����ǣ�NLayerApp�Ĺ�Լʵ�֣���Specification��������������һЩ�����������ʹ����ʵ��Ӧ����ʹ�ù�Լ��÷dz����㡣
�������Domain Services��
��DDD�У������ĸ���õ�����չ������ʾ���κβ��У�����������һ�ֲ��������ͣ����ֲ�������������ᵽ�κζ����ϡ���ˡ�������������Ӧ�ò�������ṹ���ר��������ģ����Ҳ���ڷ������ҵġ�EntityFramework֮�����������ʵ������չ�Ķ���������Services����һ���У�������������˼Ľ��ܣ����������Ѳο�����NLayerApp���ԣ���ʵ����һ��Bank
Transfer�ķ������ȶ�����IBankTransferDomainService�Ľӿڣ�Ȼ����BankTransferDomainServiceʵ�ָýӿڡ�����ִ�еIJ����߾�������BankAccountʵ�壬����������Ҫת�˵Ľ���Application�㣬BankingManagementService��PerformTransfer������ʹ���˸÷�����ʵ�������˻�ת�ˡ�
����ģ�ͣ�Domain Model��
֮ǰ��Ҳ�ᵽ����NLayerApp������ģ���Ǹ���Entity Framework��Data
Model��ͨ��T4�Զ����ɵģ������г��˰�����Data Model����������Ķ������Լ������Ĺ�ϵ�⣬�������˻���Entity
Frameworkʵ��STE�Ĵ��롣���ϸ��Ͻ����Ⲣ����һ������������ģ�ͣ�����STE��ʵ��ǣ�浽�˺ܶ༼������������ʵ��ϸ�ڣ����⣬���е��������DataContract���Σ�Ҳ����ζ�����ǽ�ͬʱ��DTO�����ݴ����������С�NLayerApp�Ĺٷ������ж�����ʵ���й�˵���������������������Ǻܺõ�DDDʵ���������ܹ�������NLayerApp�����⣬NLayerApp����C#��partial�ؼ��������������������ҵ����Domain.MainModule.Entities��Ŀ��Partial��Ŀ¼�а�������Щ���룬������Orderʵ����ʵ����GetNumberOfItems��������һ��������ǰ�ڡ�EntityFramework֮�����������ʵ��
��һ������DataTable��EntityObject��һ�������۵�˼·����ͬ�ġ��ڴˣ�����Ҳ����NLayerApp��������ʵ�ֹ�����̫����ܣ�����������ѿ���ͨ�����Խ������ۡ�
�ܽ�
���Ķ�NLayerApp������ģ�Ͳ����˼Ľ��ܣ�����Բִ��ӿڵ����������ϸ���ۡ���ƪ�����ҽ�����NLayerApp��Ӧ�ò㡣
Microsoft NLayerApp����������ʵ�� - Ӧ�ò�
NLayerApp�У�������ģ�Ͳ�֮����Ӧ�ò���ֲ�ʽ����Distributed
Services�����֡�Ӧ�ò���Ҫ����������Կͻ��˵��������ݣ�Ȼ��Э������ģ�Ͳ�������ṹ����������������Զ����������ֲ�ʽ������ΪӦ�ò���ͻ���֮���ṩͨѶ�Ľӿںͼ����ܹ����ϸ��˵���Ѿ����߱��κ��������������ˣ�������Ӧ�ó�������һ�����п��Ľ�ɫ������ASP.NET
WebӦ�ó�����ԣ���ֻ��Ҫ����Ӧ�ò�����Ľӿڣ�Ȼ��ͨ��IoC���Ӧ�ò����ʵ�弴�ɣ�����ֲ�ʽ�����֧�֡���Ȼ���������Ҫ����������ϵͳ�ļ��ɵĻ�����ôʵ��һ���ֲ�ʽ�����Ǻ��б�Ҫ�ġ���������������NLayerApp�е�Ӧ�ò㡣NLayerApp��Ӧ�ò��н�����Application
Service����Ϊ���֣�Banking Management��Customers Management�Լ�Sales
Management������Դ�Application.MainModule.csproj��Ŀ�п�������ÿ��Ӧ�÷����У�����Ϊ���ַ������˽ӿڣ�����IBankingManagementService�ȣ�Ȼ��ʹ����Ӧ����ʵ������Щ�ӿڡ��ӽṹ�Ͽ������DZȽϼģ�����Ҳ���ٶ�����ÿ��Ӧ�ò����ľ���ʵ����������ܣ����м��������һ��Ǵ����ٽ�һ������һ�¡�
������ע�루Constructor Injection��
Ӧ�÷����ʵ�֣�ʹ���˹�����ע���Ի����������ʵ��������CustomerManagementService��Ĺ��캯����������������ICustomerRepository��ʵ�����Լ�ICountryRepository��ʵ�������ֲ�ʽ�������ʹ��IoCFactory.Instance.CurrentContainer.Resolve���������ICustomerManagementService�ľ���ʵ��ʱ��IoC���������������Ϣ���Զ�����ICustomerRepository��ICountryRepository���������Ӷ��ڴ���ICustomerManagementService�����ʱ������������repositoryʵ�崫��CustomerManagementService�Ĺ��캯�������ǿ��Դ�Infrastructure.CrossCutting.IoC.csproj��Ŀ��IoCUnityContainer���ConfigureRootContainer���ҵ�����������ϵ�����ô��롣�й�NLayerApp��IoC������ʵ����ο���Microsoft
NLayerApp����������ʵ�� - �����ṹ�㣨Cross-Cutting���֣�����
//Register Repositories mappings
// ...
container.RegisterType<ICustomerRepository, CustomerRepository>(new TransientLifetimeManager());
container.RegisterType<ICountryRepository, CountryRepository>(new TransientLifetimeManager());
//Register application services mappings
// ...
container.RegisterType<ICustomerManagementService, CustomerManagementService>(new TransientLifetimeManager()); |
�ع����ٿ�CustomerManagementService�࣬���Ĺ��캯����ҪICustomerRepository��ICountryRepository����������������ΪCustomerManagementService�౾����ʵ������Ҫ�õ���Щ�ִ�������ʵ�ϣ�ICustomerManagementService�ӿڵ�ʵ�ֲ����涨ʵ�������������������������磬����������Ϊ���Ե���Ҫ�������һ��MockCustomerManagementService����Ҳʵ����ICustomerManagementService�ӿڣ��������������ԣ����������Mock����ʹ��Dictionary��List�����ݽṹ��ģ��repository�Ĺ��ܣ�������MockCustomerManagementService�У�Ҳ������ICustomerRepository��ICountryRepository��ʵ���ˡ��������ǵ�MockCustomerManagementService����ʵ�����£�
public class MockCustomerManagementService
: ICustomerManagementService
{
private readonly List<Customer> customerRepository =
new List<Customer> customerRepository;
public MockCustomerManagementService() { }
public void AddCustomer(Customer customer)
{
if (!customerRepository.Contains(customer))
customerRepository.Add(customer);
}
// other method implementations...
} |
Ȼ����IoCUnityContainer�У���ע��ICustomerManagementService�Ĵ����Ϊ���¼��ɣ�
| container.RegisterType<ICustomerManagementService,
MockCustomerManagementService>(new TransientLifetimeManager()); |
���ݴ������DTO��
��NLayerApp�У�ʹ������ʵ�壨Domain Entities����Ϊ���ݴ������DTO����ͬʱҲʵ����һЩ�����ض���;��DTO������DistributedServices.MainModule.csproj��Ŀ���PagedCriteria����Ӧ�÷����Ͻ�����ʵ����Ϊ���ݴ��������������Ҳ�;�����������߲㣺�ֲ�ʽ�����У�Ҳ����ʹ������ʵ����ΪDTO��ԭ��ܼ��ֲ�ʽ����û�н�DTOת��Ϊ����ʵ���ְ������Ӧ�ò��������һ���棬ԭ��WCF���ڿͻ��˲���Contracts�Ĵ������͵�ʱ�����ε�����ʵ����ΪDTO�������ıˣ���ò��NLayerApp�Ŀͻ��˳�����ֱ�����õ�����ʵ�����������ݽ����ģ���DDD�ĽǶȽ������������������ġ���ȻҲӦ�þ���������������NLayerApp�У������View
Model���ܹ�������ʵ��Ľṹ���Ӧ������ֱ�ӽ�����ʵ������DTO��һ���̶��Ͻ����˿������Ӷȣ�����������ʡ�NLayerApp����ٷ���������Ҳ�ᵽ��������⣺
The latter case is when we use DTOs
(Data Transfer Objects) for remote communications between
Tiers, where the domain model's internal entities would
not flow to the presentation layer or any other point
beyond the internal layers of the Service. DTO objects
would be those provided to the presentation layer in
a remote location.
If the implementation of the entities
is strongly linked to a specific technology, it is contrary
to the DDD Architecture recommendations because we are
contaminating the entire architecture with a specific
technology. However, we have the option of sending domain
entities that are POCO (Plain Old CLR Objects), that
is, serialized classes that are 100% custom code and
do not depend on any data access technology. In this
case, the approach can be good and very productive,
because we could have tools that generate code for these
entity classes for is.
Thus, this approach (Serialization
of Domain entities themselves) has the disadvantage
of leaving the service consumer directly linked to the
domain entities, which could have a different life cycle
than the presentation layer data model and even different
changing rates. Therefore, this approach is suitable
only when we maintain direct control over the whole
application (including the client that consumes the
web-service), like a typical N-Tier application. On
the other hand, when implementing SOA services for unknown
consumers it is usually a better option to use DTOs,
as explained below.
NLayerAppʹ�õ��ǡ����л�������ʵ�塱��Serialized
Domain Entities�����ַ�ʽ�������������˽�һ�¼����й�DTO�����Ҫ�㡣
1.DTO�������Ҫ����ͻ��ˣ������ͻ���Ӧ�ó������ⲿϵͳ���ɵ�Web
Services�ȣ����ͻ��˵�View Model��Ҫʲô�������ݣ������ʲô����DTO��Ӧ�ò㸺���շ�DTO���ݣ�������DTO���ݷ�������ģ���е�ʵ�壬����ʵ����װDTO��ORM�������Domain
Model���ϵ�����ݿ�֮����迹ʧ�⣬��DTO�������View Model��Domain Model֮����迹ʧ��
2.DTOӦ����POCO���������������κμ������
3.������С��ϵͳ�����Կ���ʹ������NLayerApp��Serialized
Domain Entities��ʽ���������߿���Ч�ʣ�������Ǵ���ϵͳ�����ǽ���ʹ��DTO�������ѻ����ÿ�θ���View
Modelȥ���DTO�ܺ�ʱ�����Ҿ������Ӧ�ó����ģ�ϴ��ʱ�������㹦��ȽϺã�ĥ�����������ڽ����ϵͳ���ɵ�ʱ��Ҳ�᷽��һЩ�����Կ���ʹ��DSL���Զ����������ɼ��������DTO���������
4.WCF�����Ĵ�����Data Contracts����һ��DTO�����ר�����ļ�������ôҲ���������ڶ��㲻ì�ܣ�Serialized
Domain Entities������Data Contracts����ʽ�����ڿͻ��˳����У�һ���̶���������ֱ�ӽ�Serialized
Domain Entities����DTO�ĸ���Ӱ��
Ӧ�ò����������Э��ְ��
�ܶ�����������Ӧ�ò���ڵ����壬�ܾ��ð��մ�ͳ������ܹ��������ݷ��ʲ㣨DAL����ҵ�����㣨BLL���ͱ��ֲ㣨Presentation����NLayerApp��ϵͳ�ܹ�Ϊ����չ����Ӧ�ò������Э��ְ�ܼ�����ڵı�Ҫ�ԡ�����BankingManagementService��PerformTransfer�����У�������λ�ڻ����ṹ��ķֲ�ʽ��������λ��Domain
Model���repository��UoW�IJ�����������PerformTransfer��������Щ�������������������һ���ض���Ӧ���������ת�˵Ĺ��ܡ�ͨ������£�Ӧ�ò�Ĵ����л���������¸�������ķ��ʣ���ˣ�DDD�ķֲ㲢�����ϸ��͵ģ��ϲ������������ֱ���²㣩����Ȼ��������Ӧ�ó���������Ҫ���Э����������ض����������Ļ���Ӧ�ò�Ҳ����ʡ�ԡ�
OK������������۵������һ���ҽ���Ҫ����һ��NLayerApp�еķֲ�ʽ����Distributed
Services�����֡�
Microsoft NLayerApp����������ʵ�� - �ֲ�ʽ����
Microsoft NLayerApp���û���WCF�ķֲ�ʽ�������Ϊ��磨�������͵�GUI���ṩ�˷��ʽӿڣ��ͻ��˳���ֻ��Ҫ����Service���ü���ʹ��NLayerAppӦ�ó������ṩ�Ĺ��ܡ���NLayerApp�У��ֲ�ʽ���ֵ������ṹ���DZȽϼģ���Ҫ����DistributedServices.Core��DistributedServices.MainModule�Լ�DistributedServices.Deployment������Ŀ��
DistributedServices.Core
����ĿΪ����λ�ڷֲ�ʽ����������ṩ���������Ͷ����빦��ʵ�֣������������Ŀ�ж��������쳣������ص�Fault
Contract���������ԣ�Attribute�����塣
DistributedServices.MainModule
����Ŀ����NLayerAppӦ�ó���������������������DTO��������Լ��Service
Contract����������Լ��Operation Contract����������ģ�黮�֣���C#��partial
class���Էֱ�ʵ�������й������ͻ����������۹����������ֵIJ�����IMainModuleService�ӿ��ж�����NLayerApp�ķֲ�ʽ���������ṩ�����в����ӿڣ���MainModuleService��������ʵ���˸ýӿڡ�����ģ�黮�ֵIJ�ͬ��MainModuleService���ʵ�ֲ��ֱ����䵽������ͬ���ļ��У�MainModuleService.BankingManagement.cs��MainModuleService.CustomersManagement.cs��MainModuleService.SalesManagement.cs��
��IMainModuleService.cs�ļ������ǿ��Կ������������еķ����������Ƿ����IJ������Ƿ���ֵ��������ԭʼ�������ͣ�Primitive
Data Types������DTO����ʽʵ�����ݴ���ġ�NLayerApp��Domain Entitiesͬʱ��ΪDTO���������й�DTO�Լ�Domain
Entities as DTOs����ϸ���ݣ���ο���ƪ��Microsoft NLayerApp����������ʵ��
- Ӧ�ò㡷һ�ģ�����Ͳ��ٶ�˵�ˡ�
��IMainModuleService�ӿڵ�ʵ����MainModuleService���У���������ͨ��IoC������ǰ��Ҳ��ϸ����IoC������NLayerApp��ʵ��ʹ�õ���Microsoft
Unity�����Ӧ�ò������ʵ�����Ӷ�ִ����Ӧ�IJ�����ͨ���������ǿ��Ե�֪��NLayerApp��Ӧ�ò���Ҳ��ʹ��IoC��������òִ����������Domain
Service���ľ���ʵ�ֵģ��ɴ˿ɼ���NLayerApp�ڲ����֮�����ʹ�õ�IoC����ʵ�ֲַ���������MainModuleService����GetBankAccounts������ʵ�ִ��룬�������ǿ����˽�ֲ�ʽ������IoC������ʹ�÷�ʽ��
public List<BankAccount> GetBankAccounts(BankAccountInformation bankAccountInformation)
{
//Resolve root dependency and perform operation
IBankingManagementService bankingManagement = IoCFactory
.Instance
.CurrentContainer
.Resolve<IBankingManagementService>();
List<BankAccount> bankAccounts = null;
//perform work!
bankAccounts = bankingManagement.FindBankAccounts (
bankAccountInformation.BankAccountNumber,
bankAccountInformation.CustomerName);
return bankAccounts;
} |
DistributedServices.Deployment
����Ŀ��ʵ����һ��WCF Web Application�����Ƿֲ�ʽ�����������Ŀ����������WebӦ�ó���ķ�ʽ����ASP.NET
Web Server������IIS���ϡ�����Ŀ�µ�MainModule.svc�ļ���������ʹ�õ�WCF Service��Ҳ����DistributedServices.MainModule��Ŀ�е�MainModuleService�ࣩ����web.config�ļ����������Ϣ���������ã�
- ����Entity Framework�������ַ���
- ��ʹ�õ�IoC����������
- ������Ϻ��ٳ����������Ϣ
- Web Application��������Ϣ
- WCF Service��������Ϣ
�ڲ���NLayerApp��ʱ����Ҫ��DistributedService.Deployment��Ŀ����ASP.NET
Web Server������IIS���ϣ�������Web��������֮�ͻ��˳���ͨ��WCF�Ŀͻ��������Լ�������������NLayerApp��Ӧ�ó����ˡ�
�ֲ�ʽ�������ĵ���
���ǿ�����soapUI���������зֲ�ʽ����ĵ��ԡ�soapUI��һ���Ƚ��Ŀ�Դ�����Web
Service�ĵ�������Թ��ߣ�����Ե���˴��鿴�ù��ߵĹ�����ҳ�������л���������ӡ����ڣ������ǿ�ʼʹ��soapUI�����зֲ�ʽ�������ĵ��ԣ����ڱ��˵�ϵͳ��Ӣ�İ棬Ϊ�˱��ⷭ��IJ�ȷ���������ߣ������������������в����Լ������İ�ϵͳ������������
- �ɹ�����NLayerApp
- ��DistributedServices.Deployment��Ŀ�£��ҵ�MainModule.svc�ļ����Ҽ�������ѡ��View
in Browser���⽫����ASP.NET Development Server������IE�������չʾ����ҳ�棺

- ����soapUI����Navigator Panel�У��Ҽ�����Projects�ڵ㣬ѡ��New
soapUI Project����ʱ����New soapUI Project�Ի�����Initial
WSDL/WADL�ı���������http://localhost:88/MainModule.svc?wsdl����ʱProject
Name�ı�����Զ��ԡ�MainModule����䣬��ʱ���������ѡ�ֱ�ӵ���OK��ť

- ��Navigator Panel��չ��MainModule�ڵ㣬���ǿ��Կ���������������Endpoint��WS2007ForIntranetClients��BasicBindingForSliverlightClients������DistributedServices.Deployment��Ŀ��web.config�е������������

- չ��BasicBindingForSliverlightClients�ڵ㣬���ǿ��Կ�����IMainModuleService�ӿ������������з�����չ��GetCustomerByCode��������˫��Request
1���ڴ�Request 1�Ի����У���߲����г��˵��øò�����SOAP Envelope

- ��<mic:customerCode>�ڵ�������A0001�����ǻ������Request
XML��
<soapenv:Envelope xmlns:soapenv=
<a href="http://schemas.xmlsoap.org/soap/envelope/">http://schemas.xmlsoap.org/soap/envelope/</a> <br>
xmlns:mic="Microsoft.Samples.NLayerApp.DistributedServices.MainModuleService">
<soapenv:Header/>
<soapenv:Body>
<mic:GetCustomerByCode>
<!--Optional:-->
<mic:customerCode>A0001</mic:customerCode>
</mic:GetCustomerByCode>
</soapenv:Body>
</soapenv:Envelope> |
- ����Request 1�Ի������Ͻǵ���ɫ��ͷ����ֱ�ӵ���GetCustomerByCode����������÷��ؽ��

- Ҫ���Էֲ�ʽ�����������úöϵ㣬Ȼ����Visual Studio��ѡ��Debug �C>
Attach to Process�˵����ڵ�����Attach to Process�Ի����У�ѡ��ASP.NET
Development Server �C Port 88��Ȼ��Attach��ť���⽫ʹVisual
Studio�������ģʽ

- �ٴε���Request 1�Ի����е���ɫ��ͷ�Ե��÷ֲ�ʽ����ʱ�����ִ�н���ͣ�ڶϵ㴦����������Ա����

�ܽ�
������Ҫ��NLayerApp�ķֲ�ʽ�������漰�ĸ�����Ŀ���˼��ܣ�ͬʱ��������һ��ʵ���������Էֲ�ʽ����IJ�������Խ�������ϸ��ʾ���ֲ�ʽ�����ǿͻ��˳�����NLayerAppӦ�ó�����н����Ľӿڲ��֣��������κ�ҵ����������Э����������ֻ��һ��ͨѶ�ֶεļ���ʵ�֡�
NLayerApp�Ľ���Ҳ��������ˣ���ϵ�����½����ټ�������GUI��������ϸ�����ˣ���ΪGUI���ֵĿ������ض������Ľ�Ϸdz����ܣ�����WPF��Sliverlight�Լ�ASP.NET
MVC���й���Щ���ݣ����߿��Բο��������һ���Ķ�ѧϰ����ϵ�����¾Ͳ��ټ�����WPF��Sliverlight�Լ�ASP.NET
MVC��Щ������������һ�������ˡ� |


