����������ƣ�DDD���ĸ���Դ��2004��������ģר��Eric
Evans�������鼮:��Domain-Driven Design �C Tackling Complexity
in the Heart of Software������������������������ơ��������ĸ�����Ӧ��֮�������ؽ�ǿ��2011�귢����һƪ���¡�����������ƺ�ʵ����������������DDD�ģ�
�������������ʵ�������OOAD��һ����չ�����죬DDD������������������Ƽ������Լ����ܹ������˷ֲ�滮��ͬʱ��ÿ��������˲��Ժ����͵Ļ��֡�
������Ҫ����Ϊʲô�����ں��ؿ�Դ�ڲ��ƹ�DDD���������ͨ������ DDDLib
�� Koala �ȹ�����������һ���̣��ƹ��������������Щ���⣬�Լ�������ν����һ���⡣
Ϊʲôѡ��DDD
��ͳ��ģʽ������ŵ����ڿ�����Ա�dz���Ϥ�������ɱ��ͣ�����Ҳ��һЩ����
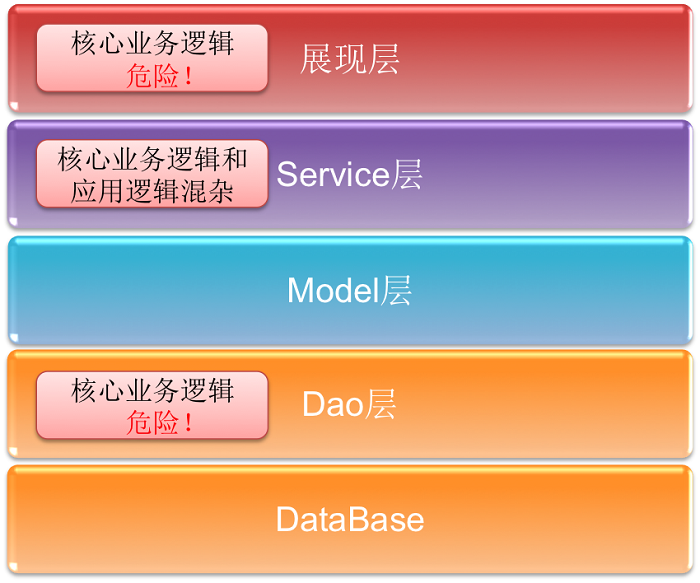
����DDD����ģʽ֮ǰ����ͳ�Ŀ���ģ���������е�Model-Dao-Service-UI����ģ�ͣ�ͨ���ǻ�������ű���Transaction
Script���ͱ�ģ�飨Table Module��ģʽ��ʵ�֣�����ģʽͨ��������Ʊ����ٽ�ģ��ʵ�����������ض��ı���һЩ���ԣ���洢���̡����ڱ������ģʽ���״������¼������⣺
1��ҵ��ģ��ȫ�DZ��ĸ��ƣ�����ʵ��ӳҵ��
2������ҵ���ɢ�ڸ����ط����dz�Σ�գ�����չ�ѣ��������Ķ���
���ֿ���ģʽ�ʺ�һЩ����С������ά����չ����С����С����Ŀ�����ڴ�����ҵ��ϵͳ���Ʒ����չά������������dz��������£�ȱ��Ҳ�dz����ԡ�
��Զ��ԣ�DDD���������ĵ�ô���
1���������ģ����ʵ��ӳҵ����ʵ��ʹ��DDD����������ƣ�ģ��ͨ����ҵ�����ʵ��ӳ��ҵ��������������Ƿ�ɢ�ڸ�Service�У������ڶ�ҵ������⡣
2��ʹ������ͳһ��ģ���ԣ�������ҵ��ͨ�뽨ģ�� DDD�����ȶ�ҵ��ģ�����ǹ�ע����ű�����ƣ��ڽ�ģ�����У������������Ƕ���ʵҵ��ķ�ӳ�뽨ģ�������ҵ��ר�Ҹ�����ͨ�����Ƽ�����ҵ��Ĺ�ͨ���ҡ�
3���������Ըߣ�DDD�У������Ϊ���ģ�ÿ�����������һ������������ھ۵�ҵ��������������Կ����γ�ֱ�ӵĸ��á���������ģ����ƣ������������ض������ݿ⼰���ԣ�ģ���ǿ�����ȫ������û�м����ϵij�ͻ��
4��ҵ��Խ���ӣ�DDD������Խ���ԣ�����ģ�Ͳ���OO��ƣ�ͨ����ְ����䵽��Ӧ��ģ�Ͷ����Service�����Ժܺõ���֯ҵ��������ҵ���ø���ʱ������ģ���Գ�������ơ�
DDDLib�dz�
DDD��������һ��˼�룬�������¼������ں��ؿ�Դ�������ǵ�������ʦ�ͳ²��ܹ�ͬ������DDDLib�⣬�Ƕ�DDD˼��ĺ���֧����ʵ�֡�
DDDLib��һ����֧��DDD˼��ʵ�ֵ���⣬DDDLib�»���ʹ�õ�
Hibernate��JPA��MyBatis��noSQL�ȼ���Ϊʵ�֡�
��ͬDDD��Ҫ������ʹ��DDDLib ����Ŀ�ֲ�ͼΪ��

1���û�����/չ�ֲ�
�������û�չ����Ϣ�������û��ڽ����ϵ�������struts��tapestry��springMVC��ҳ���ܡ�
2��Ӧ�ò�
��������Ӧ�õĻ�������������е�ҵ������
Ӧ�ò������������һЩ����������ص��������ʵĹ�����������־������ȡ����⣬Ӧ�ò�Ҳ������������һЩ�Ȳ�����չ�ֲ㣬Ҳ����������㣬��������ĿǰӦ����ص�һЩ�������ʽ�ת�˵�ҵ��Ķ�ȡ���빦�ܣ���ȡ���벻��ת�˵ĺ���ҵ���壩��
3�������
�˲���DDD�ĺ��ģ��������������ִ��ӿھ�λ�ڴ˲㡣
�������Ϣ����ҵ�������ĺ������ڡ�
��Ҫ����ҵ������״̬����ҵ�������״̬�־û��IJ�������������ʩ�㡣
�����Ӧ���������ԭ����ҵ�����仯�����������κα仯����Ӧ��Ӱ�쵽����㡣��Щ�����仯��������ͬ��չ�ֿ�ܣ���ͬ��ҳ��չ�����ݣ��Ƿ�Ҫ��ҳ���Ƿ�֧���ֻ��ͻ��ˣ��Ƿ�WebService���Ƿ��ṩOpenAPI�ȵȡ�
4��������ʩ��
�˲���Ϊ������ε�֧�ţ�����Ϊ�����ij־û��ṩ֧�֣���������Ӧ�ò��������ҵ���Ӧ������(���Ͷ��ŵ�)ʱ�����ǻᶨ������ӿڣ�Ȼ���ڻ�����ʩ����ʵ������ӿڣ������ض���ҵ���Ӧ������
DDDLib�ĺ���ʵ�����£�

��ͼ����ʹ�� DDDLib ��Ŀ�����弼���ܹ�ͼ��Ҳ������DDDLib������ԭ��
1���������ҵ����ģ���һ�㲻�����κ��ض��ļ�����ܣ���֤����ҵ���ԡ�DDDLib�е������ֻ����JDK��DDDLib��Domain���Լ��ִ��ӿڼ������Զ���ӿڡ�
2��ʹ�òִ��Ͳ�ѯͨ����Ϊ��洢������صIJ����ӿڣ�������ض����ݿ⼼����洢���ʵ�������
3���ṩ���ֲ�ͬ��IoC����ʵ�ּ�InstanceFactoryʵ��������������ض�IOC
������������
4����������ֵ������������Լ������������Ҫ�أ�����㲻�����ݿ���������ҵ��ģ�㡣���������ʹ�õĹ����У����ջ��ǰ��������Ϊ���ݿ��������ʹ�ã���ʵ��ķ���Ҳ�������ݿ�IJ�����ΪΪ��
�����ѯ��������ɾ��һ��ʵ�壬������Ȼ�ع鵽�����ݿ�Ϊ���ĵķ���ȥ�ˣ�������Ҫ����ġ�
5���ı������ݿ�Ϊ���ĵĺ�������ʶ��ҵ����Ϊ���Ǻ��ģ����ݿ�洢��֧�š���ʶ�����ݿ���֧�ŷdz��ؼ���ҵ���ϵ��κ���Ϊ����ϵͳ��������Ҫ�洢��¼�����ݿ�洢�Ƕ�ҵ��ʵ�ֵ�֧�ţ�Ҳ����ʹ���ļ���������ƿռ�������洢���ʡ�����һ�£�ʹ�����ݿ������Ƶ���Ŀ�����վ����˴洢����Ϊ�ض������ݿ⣬�����һ����Ҫ����Ϊ�ƿռ��������洢��ʽ���ͻᷢ������ϵͳ��Ҫ������ƿ�������ʹ��DDDLib��ֻ������ִ�ʵ�֣��ṩһ���ƿռ��ʵ�־����ˣ�����ҵ������ȫ����Ҫ�䶯���ġ�
DDDLib��ʵ�ֹ�����Ҳ�������ڲ��IJ������飬�����ܶ�ε����ۺʹ�ĥ�γ������ڵĸ�֡�������IJ��֣��ҽ�����DDDLib�ڼ�����Ҫ����ϵ�ʵ��ϸ�ڡ�
DDDLib�ִ���ʵ��
��DDDLib 1.0��3.5�汾���ִ�ʵ�����������Σ��ֱ��ǣ�
1����ÿ�����������һ���ִ��ӿڼ�һ���ִ�ʵ�֡�
���ֲִ�ʵ�ַdz������飬������Ա�����Ͽ����ַ�ʽ���ִ��ӿڼ�ʵ�ַdz��࣬һ���浼����Ŀ��̫�࣬����Ҳ����������ظ�������
2����spring data���ϣ���ÿ�����������ִ��ӿڣ����붨��ʵ�֡�����ģʽ��ǰ���ģʽ�����Ż���ֻ����ӿڲ�����ʵ�֣�����spring
data�������������������������в�ѯ��ģʽ�����һЩ���ӵIJ�ѯ������ʤ�Ρ�
3���ṩĬ�ϵ�hibernate��JPA��ͨ�òִ��ӿڡ�
Ϊÿ���ִ�����һ���ӿڣ�����ģʽ�����IJ������ܣ�ʹ��spring data�������Ż�������Ҳ�зdz�������⣬�������JPA��ʵ�����˼·�������γ���ͨ�òִ��ӿڼ���ͬ����ʵ�ֵ�˼·������һ��ͨ�õIJִ��ӿڣ�����ͨ�õ���ɾ�IJ����ݿ���Ϊ��
4��֧��MyBatis��ͨ�òִ��ӿ�
DDDLib��JPA��hibernate�ִ�ʵ�֣����������һ���ϼѵķ�������������ʵ��ʹ��ͨ�õIJִ��������˴����ظ����룬��DDDLibһֱ�ǻ���Hibernate/JPA�ṩ��ʵ���뼼��֧�֣�����Ŀ��ʹ�ù����У��������������ʺ�ʹ��Hibernate/JPAģʽ����Ŀ����MyBatis������Ҳ�dz�����������£�Koala�ŶӶ���ʵ����MyBatis�IJִ�ʵ�֣�����֤����JPA/Hibernateģʽ��API��һ���ԡ�
DDDLib�е�DTO
DTO�����ݴ���������������Ȼ�����ݣ����ԣ�����������������滹���в�������ijЩ���ϲ��ʺϽ��д��䣬��Щʱ���仹��Ҫ���л��������������е�����������Զ����Ա�¶��������Щ���Կ���Ҫ�ϲ�������Ҫ�ֽ⣬֮���������ǰ�˵�ʹ�á����Ǿ�����ר�������������ݵ�DTO��ֻ�����ԣ�û�в�������Ҫ��ʱ��������л���ǣ�ʵ��Զ�̵��á�
����DDD��DTO�����ã�����DTOͬʱҲ������ʵ����DTO��ת���������⣬�ڴ����������������ԡ�
DDDLib�е����ݿ�֧����Ϊ��
��DDDLibʵ���У��ṩ��Repository�Լ�QueryChannelService�����ӿڣ��ֱ�ʹ����������Լ�Ӧ�ò㣬���Ƕ����ݿ�IJ����ӿڡ�
SQL/HQL/JPQL���
��ʹ��DDDLib�Ĺ����У���ͬ�ij־ò��ܵ�SQL���Բ�һ��������MyBatisʹ�õ���SQL��Hibernateʹ�õ���
HQL��JPA��ʹ�õ���JPQL��
��Щ���д���Ķ��ڹ�˾Ҳ������һ��������������ʷ���£�
1��д�ڴ�����
public static Resource newResource(String name,String identifier,String level,String menuIcon){
����Resource resource = null;
����List<Resource> resources = Resource.getRepository().find("select r from Resource r where r.name =
? " + "and r.identifier = ?", new Object[]{name,identifier}, Resource.class);
����...
} |
����dz��������⣺����Ҫ��ѯ������дSQL������ģʽ�ǹ�˾�����ʹ�÷�ʽ����ȱ��Ҳ�dz����ԡ��ŵ���ֱ�ۣ�ȱ�����ǣ�DDDLib���������ض�����������Щ���д��д�������У���ζ����������������ض��ļ�����䣬Υ����DDDLib��Ŀ�ꡣ
2����@NamedQueryע��д������
@Entity
@NamedQuery(name="findAllEmployeesByFirstName",queryString=
"SELECT OBJECT(emp) FROM Employee emp WHERE emp.firstName = 'John'")
public class Employee implements Serializable {
����...
} |
��Koala��Ʒ������ǰ��DDDLib֧��Hibernate�Լ�JPA��������ģʽ��֧��@NamedQuery����ע�⡣����������������ַ�ʽ������û�н����������⣬�������������Ķ������⡣
3����������ѯ+xmlʵ��
/**
* �ж�һ����Դ�Ƿ�������Դ
*/
public static boolean hasChildByParent(Long parentId) {
����return !Resource.findByNamedQuery("hasChildByParent", new Object[] { parentId }, Resource.class).isEmpty();
} |
���ڶ�Ӧ�� XML �����ж��壺
<named-query name="hasChildByParent">
<query>
select distinct m.id from ResourceLineAssignment m where m.parent.id=?
</query>
</named-query> |
Koala�ŶӺ��ڶ��������ǵķ�ʽ��ʹ��������ѯ+xml���÷�ʽ��ʵ�֣����һ������ַ�ʽ���ṩ��MyBatisЭ���֧��ʵ�֣������һ�����Ͽɡ�
ʹ�����ַ�ʽ�������Ĵ����в�������ض��ļ�����䣬������������⣬��ͬ�ļ���ʵ���²�ͬ��xml��������ģʽ�ǿ��Խ��ܵġ�
������ģʽҲ����һЩ���⣬������
a) ��̬������ѯ��֧�֡�һЩ��ѯ�������Ƕ�̬�ģ�����ģʽ�µ�HQL/JPQL�Dz�֧�ֵģ�������ͨ����̬������ѯ������ҵ����ģ�����Ӧ����������Ӧ�ò㣬�����ʱ��Ȼ���Խ��ܡ�
b) ��չ�����洢���ʵ����⡣Hibernate/JPA/MyBatis�dz��õij־ò��ܣ���������Խ��Խ��ij�������NoSQL���ƴ洢�ȷǹ�ϵ�ʹ洢��ʹ������ģʽ��ƥ����Щ�洢����ǰû���ֳɵĽ������
4����ʹ����䣬��ʹ��QueryCriterion
DDDLib���ṩ��QueryCriterion���ֲ�ѯ���ƣ����������������ض��־ò��ܵ�Ӱ�졣�ܿ�ϧ�������ں����ƹ�ʹ��
DDDLib ʱ��û���ἰ����ʵ�֣���˺��ص�DDDһֱδʹ�ô˷�����
���ַ�ʽ����MyBatis����֧�֣�����NoSQL���ƴ洢�������洢����ͬ��û���ֳɵĽ��������
DDDLib����ʹ���˵����ַ�����
JPA�µ�д����


MyBatis�µ�д����


�ƹ�DDD��������ս
��������˴�ͳ����ģʽ��һЩ���⣬���Ǵ���һ���Ƕ���˵����ͳ�Ŀ���ģʽҲ���������ŵ㣺
ʹ�óɱ��ͣ����ڴ�ͳ����������ʹ��SSH�ȿ�ܣ����������еĿ�����Ա��û�����ִ��ۣ��������Բ��뿪����
�����ٶȿ죺��ͳģʽ�Ŀ����ٶ�Ҳ�죬����ʹ��һЩ���ٿ�����ܣ�����һЩ��ҵ�����Ŀ���DZȽϺ��ʵġ�
��ʵ����Ŀ�Ŀ����У���ͳģ�Ƶ�ȱ�㲢�����ԣ����ڴ���Ŀֻע��ʵ��ҳ��Ч����������Ƶĺû���ά����չ�����Ȳ�û�б����ӡ�
������Щ���⣬�ڹ�˾�����ƹ�ʹ��DDD˼���һЩ�ѵ����谭�������ǹ�˾����һЩ��Ŀ��ʹ��DDD�������������Ʋ������ԣ�����ǰ�ڻ����ʹ�óɱ���
��һ���棬�Դֿ�����Ա��˵����ͳ��ģʽ�������ܺ�ϰ�ߣ���->DAO->Services->UI���ַdz�������û��ѧϰ�ɱ����ƹ�ʹ��DDD��һ������Ȼ�����ϲ�û���κδ��£�ʹ�õĻ���Hibernate��Struts��Spring��Щ���õļ��������ؼ��DZ����˼�벻һ����DDD��Ҫ�㣬��������������ѯͨ����Щ�ÿ�����Ա���Ⲣ��Ϥ���ֱ�����Ҳ�Ǹ���С����ս���ƹ���ھ���������������Ա����Щ��������ɡ�
���⣬��ȻDDD�����ȶ�������з�����ģ����д�����Ⱥ��ģ��ٿ��DZ������ʵ�֣�����ʵ�ʵĿ��������У���������ģʽӰ�죬����ʹ����DDDģʽ��������Ա�������ǻ��ô�ͳ��ʽ����������ģʽ�����⣬�磺
1.������Ա��������Ʊ����ٸ��ݱ�����������������Ŀ��Ȼ���Ƕ�ʵ�������ɾ�IJ飬���dz���DTO��ʵ������һģһ���������������Ա��DTO�Ĵ��ڵı�Ҫ�������⡣
2.�ڴ�ͳ��ģʽ�У��������ݿ�Ļ���������Dao�����Ρ�DDDLib�ṩ���������ݲ�ѯͨ����������Ա������Щ��Ҫʹ�òִ�����Щ��Ҫʹ�ò�ѯͨ�������������⡣
3.DDDLib�ṩ��ֵ����������������������������ֵ���з��룬������ʵ�ʵ���Ŀ�У��������Ա����Ŀʹ���������Ȼ��ֱ��������������ɾ�IJ飬��������ʹ�õ�ֵ����������ۺϡ�������ЩҪ�ء�
���������� DDD �ֱ�ɴ�ͳ��ʽ�����ֽ�һ���ÿ�����Ա�о�DDD�봫ͳģʽû�б����������ǼӾ��˿�����Ա��ʹ��
DDD �����ʡ�
��ν����Щ����
1.�ڹ�˾�ڲ��ƹ�����DDD&DDDLib
DDD��������������ϸ�ںʹ�ͳ�ķ�ʽû�����𣬸������Ҫ�ÿ�����Ա��������ת�����������ƹ�DDD&DDDLib��������dz���Ҫ��������DDD˼��������ʹ��DDD�����շdz������������ʹ�ã�����ʲô�ã���ΪʲôҪ�������ĸо���
2.���ڽ���DDD�ڼ����ϵĽ�����̽��
��ǰ��������DDDLib��һЩ����ʵ��ϸ�ڷdz��������ԣ�������ǻᶨ���ټ����뷨����Ա���������ۣ��ռ�ʹ���ߵ���������ϵ������Ż�ʵ�֡�
����������ļ�����Ҳͨ�����ۣ���˼���棬�ҵ���ѵ�ʵ�ַ�ʽ��
3.�ƶ���ѱ���ʵ����ָ��DDD��ʽ�ı���
���ǵ�������Ա�Ӵ�ͳģʽת�䵽DDDLib�������ת�估ѧϰ�ɱ����⣬ͨ����˾�ļܹ��������дһ�����DEMO��ʾ�������α�д���룬�����ѯͨ����ֵ����DTO���ִ����ۺϵȵ�ʵ����ϸ�ڣ�����������Ա��ȷ��д��
4.ͨ����ʵ��Ŀ���ô����ʶ��DDD���ŵ�
��һЩ��Ŀ�ϣ�ʹ�� DDD ��û��ʵ�ʵ��ŵ㣬ֻ����ҵ���ӣ���Ҫ���ϵ��������Ʒ��������Ŀ���űȽ��ʺ�
DDD������ͨ��������ʵ����Ŀ�еĴ�����ʾ��˵��ʹ��DDD�ĺô���
5.����һ����DDD˼��Ŀ���ƽ̨������������ʹ��DDD����
��ʹ���˽ϳ��� DDDLib ֮����Ҳ�Ƴ��˻�������˼���Koala����ƽ̨�������������ƽ̨���ܸ������ÿ���������ʹ��DDD��
�ܽ�
��Ŀǰ����˾�Ĵ���Ŀ�Ѿ���ʹ��DDDLib&Koalaƽ̨��ʵ�֡�������Ա��������������˼�룬��������������DDDLibʵ����������Լ���������뷨�������ִ�û��native
SQL֧�֣�NoSQL���ʵ�֣�DTO�Ƿ��б�Ҫ��û�����־ۺϣ�������Ƿ��ʹ�ù�������ʵ���費��Ҫ�������ԣ�����ʱ�䣬�����ߣ��ȡ�
�����������Ǽƻ������·������չ��������
1) ����֧�ּ���ϸ��
������NoSQL�IJִ�ʵ�ֵ�֧�֣��Ϻõ�֧�ַ�Spring IOC�ȣ�����ϸ������Ȼ��Ҫ�Ż���
2) �ƶ���Ϊ�Ż���DDDLib���淶
�����ִ�����ѯͨ�����ۺϵ����Ϊ�����ṩ��Ϊ�Ż��ļ���ʵ�ֱ������õ�֧��DDD��ơ�
3) ���ƻ���DDDLib��Koala����ƽ̨
��һ������ Koala����ƽ̨�����õ�֧��DDD&DDDLib�����ʵ�֡�
4) �ƹ�DDD����
��˾����Koala�����Դƽ̨�����ø�����˳��Բ����뵽ʹ�� DDD��
DDDLib���ƶ����������������Ӧ�á�
|


