|
Tumblr成立于2007年,是目前全球最大的轻博客网站,拥有超过1.96亿的博客,930亿帖子。同时,该网站Blog请求更已达到2.3万每秒。

Tumblr是目前全球最大的轻博客网站,也是轻博客网站的始祖。当下已有超过1.96亿博客,930亿帖子,每秒2万3千请求。近日,该公司网站可靠性工程师Michael?Schenck在HighScalablity上公布了其架构设计。
以下为译文
在Tumblr,blog是网站流量最大的一部分。而在tumblelogs中,高度可缓冲成为一个非常重要的特性。鉴于Tumblr支撑的高views/post比率,做到这一点并不容易,下面一起看向blog支撑部分的架构。
状态
- 278个员工,6个人负责Tumblr的perimeter(Perimeter-SRE),包括一个manager。
- 超过2800台服务器,不到20%用于blog支撑
- 峰值期间每秒2.3万blog请求
- 峰值期间每秒6500个blog缓存清理
- 超过1.96亿blog
- 超过930亿post
平台
曾经架构――基于映射的分割
早期,Tumblr运行在一个非常小的规模――1活跃加1备用的proxy服务器,以及同样配置的varnish节点。这种规模的Tumblr非常易于管理、监控,服务的可用性也非常高。然而不久后,Tumblr就不得不疯狂的扩展以应对用户暴增可能带来的容量限制。
添加1个独立的proxy节点
添加一个独立的proxy服务器非常普遍,同时还涉及了DNS。通常情况下,类似Round-Robin A Record这些基础的东西可能就会满足需求,但是很多情况下,一个健康检查GSLB配置同样值得你投入,即使是在同一个地理位置下。
DNS的缺点是,域名服务器会以一个恒定的速率对每个IP做出响应,然而问题在于并不能保证每个查找都用于相同数量的请求。在1分钟内,用户A对一个Resolved IP进行的请求可能是10次,而用户B可能会达到100次。如果你有两个IP,A和B分别使用1个,假设只有这两个用户访问,那么一个proxy服务器的请求速度可能是另外一个的十倍。
这个问题可以通过Lower TTL来解决,比如一个30 second TTL可以将请求在这两个proxy间平衡。在前30秒,A被送到P1,B被送到P2,而在后30秒可能就会置换,在最后每个proxy服务器处理都会处理大约60个请求左右。Lower TTL的缺点在于会造成更多的查询,因此会带来更多的DNS开销。但是值得庆幸的是,DNS基本上是开销最低的第三方服务。
添加1个独立的varnish节点
当DNS给你带来更多proxy层上的空间时,varnish的扩展往往会复杂一点。尽管你困扰于并发请求带来的单varnish节点容量限制,但是简单添加1个varnish节点并不能达到你的预期需求。这个操作可能会降低cache-hit比率,让清理在resource/time上更加密集,并不能真正的增加你的缓存容量。
迭代单varnish节点最简单的方法就是静态分割,这包括确定你的唯一识别符,并将这些空间在两个节点中分割。对Tumblelogs来说,这就是blog的主机名称。鉴于DNS区分大小写,你只需考虑40个字符,字母数字“a-z”、“0-9”以及“-”、“_”、“.”、“~”4个字符。因此对于两个varnish节点,blog主机名称根据首字母在两个缓存节点中分割。
均匀的分布式分割――通过一致性哈希
前面的两个例子(DNS round-robin和静态分割)虽然想法是正确的,但是并未做一个细粒度的分割。在小规模下,这种粒度可能并不会带来问题。但是随着流量的增长,差异性逐渐的造成问题。减少least-hot和most-hot节点间差异至关重要,这里就有了一致性哈希的用武之地。
分割proxy流量
如果你的服务器环境满足这个条件,即可以改变路由器(建立于用户和proxy服务器之间)的路由表,那么你可以利用其ECMP的优势。ECMP可以在一致性哈希环中将proxy分割,然后将请求者们映射到这些分割后的碎片上。通过将多路径(proxy服务器)路由基础设施发送给一个特定的IP(高可用IP)来实现这个操作,在这里,ECMP将哈希请求源以确定哪个proxy来接收这个请求会话包。典型的ECMP实现提供了Layer 3 (IP-only)和Layer 3+4(IP:port)哈希选项,Layer 3意味着所有特定IP上的请求都会交由一个制定的proxy,这点非常有利于debug,但是对于使用了单一NAT IP的大型网络来说并不有利。Layer 3+4则提供了非常经典的分布式特性,但是debug指定客户端变得非常有挑战。
这里有非常多的方法来INFORM多路径路由器,然而我们更推荐使用OSPF或者iBGP来做动态route advertisements。一个只需要监视loopback interface上的高可用IP,允许内部路由,并将其IP作为一个next-hop advertise给高可用IP。同时我们还发现,BIRD是proxy服务器执行route advertisements的一个轻量级及可靠手段。
分割Varnish流量
Tumblelogs由它们FQDN的识别,例如一个blog的所有URI路径都会在这个blog的FQDN下发现。绝大多数的Tumblelogs都是tumblr.com的子域,比如engineering.tumblr.com,但是Tumblr也允许用户自定义域名。
当着眼格式的FQDN时,TLD在最小变化上有着绝对的优势,然后就是域名,子域名。因此,大部分的有效位都在域名最左端。
理解问题域
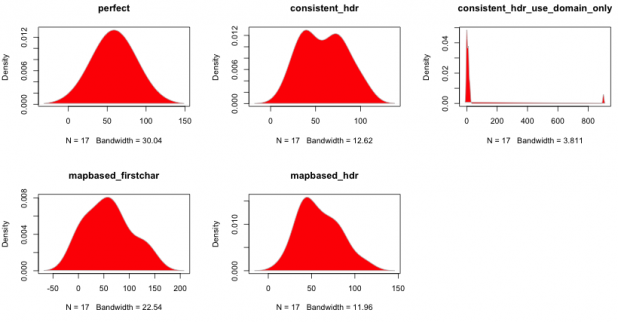
- 追求完美――在测试数据集上寻求最完美的哈希
- consistent_hdr――在主机标识上做一致性哈希(现实示例中最好结果)
- consistent_hdr_use_domain_only――在基域名上做一致性哈希(比如tumblr.com或foo.net),只存在两种结果tumblr.com和其他
- mapbased_firstchar――将主机表示的第一个字母映射给varnish节点,这也是我们最原始的静态分割实现
- mapbased_hdr――主语主机表示映射
当一致性哈希被确立为最适合方案时,我们开始聚焦哈希函数是否合适。HAProxy默认使用的是SDBM哈希函数,然而在更深入的调查后,对比了SDBM、CRC、MD5、DJB2等,我们发现DJB2提供了更好的分布。
对比静态分割和一致性哈希
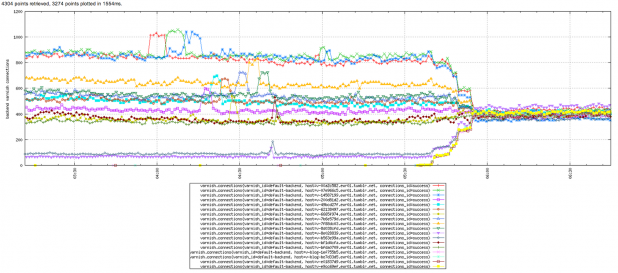
上图显示了每个varnish节点上的变化,对比了使用最佳哈希函数前后
附加思考
节点增长
在这两种模型中,节点增长都意味着keyspace转移,因此缓存失效。在一致性哈希模型中,失效key所占的比率更加容易预测。在静态分割模型中,除下做很具体的统计,很难预测到这个百分比。
节点故障
通过静态分割,单点故障将导致?1/N的key无法访问,除非你提供一个故障转移机制。HAProxy确实允许你拥有一个备份节点,因此你需要做出决策,是否要为每个key space都做活跃和备份缓存节点设置,或者共享一个备份节点。一个极端意味着你将浪费50%的硬件,另一个(共享备用节点)则意味着两个故障节点就需要备用节点支撑活跃节点的2倍keyspace。
通过一致性哈希,节点故障被自动处理。当一个节点被移除后,那么1/N的key会被转移同时无效,然后把这些分配到剩余的活跃几点上。
清理缓存
清理请求可以很简单的发送到单独的varnish节点上,那么从多个varnish节点上的清理应该同样简单。取代谨慎的保持proxy和清理同步,将所有清理请求发送到相同的proxy显然更加简单。同时,需要注意的是,拒绝不同IP空间上的清理请求非常重要,这可以防止恶意的批量清理。
学到的知识
- 有时候,问题的答案比你问题出现的更早。当面对一些扩展性挑战时,不要在那些已经在其他地方攻克过的问题上浪费时间。
- 保持简单。通过复杂性来解决扩展性问题必然深受其害。
- 理解你的哈希函数。哈希函数的选择同样至关重要。
- Degrade,not fail。让proxy具备监视自己后端到达情况的能力非常必要。如果出现异常,不要停止advertise路由,继续advertise非优先级路由。这种情况下,如果你所有的后端都出了问题,那么你仍然可以显示错误页面。
|





