|
教程中的英文很简单,我相信学OpenCL的人都能看得懂,而且看原汁原味的英文表述,更有利于我们了解各种术语的来龙去脉。
我把这些教程翻译成自己的中文表述,主要是强化理解需要,其实我的英文很烂。
一、并行计算概述
在计算机术语中,并行性是指:把一个复杂问题,分解成多个能同时处理的子问题的能力。要实现并行计算,首先我们要有物理上能够实现并行计算的硬件设备,比如多核CPU,每个核能同时实现算术或逻辑运算。
通常,我们通过GPU实现两类并行计算:
任务并行:把一个问题分解为能够同时执行的多个任务。
数据并行:同一个任务内,它的各个部分同时执行。
下面我们通过一个农场主雇佣工人摘苹果的例子来描述不同种类的并行计算。

1.摘苹果的工人就是硬件上的并行处理单元(process elements)。
2.树就是要执行的任务。
3.苹果就是要处理的数据。
串行的任务处理就如下图所示,一个工人背着梯子摘完所有树上的苹果(一个处理单元处理完所有任务的数据)。

数据并行就好比农场主雇佣了好多工人来摘完一个树上的苹果(多个处理单元并行完成一个任务中的数据),这样就能很快摘完一颗树上的苹果。

农场主也可以为每棵树安排一个工人,这就好比任务并行。在每个任务内,由于只有一个工人,所以是串行执行的,但任务之间是并行的。

对一个复杂问题,影响并行计算的因素很多。通常,我们都是通过分解问题的方式来实施并算法行。
这又包括两方面内容:
1.任务分解:把算法分解成很多的小任务,就像前面的例子中,把果园按苹果树进行划分,这时我们并不关注数据,也就是说不关注每个树上到底有多少个苹果。
2.数据分解:就是把很多数据,分成不同的、离散的小块,这些数据块能够被并行执行,就好比前面例子中的苹果。
通常我们按照算法之间的依赖关系来分解任务,这样就形成了一个任务关系图。一个任务只有没有依赖任务的时候,才能够被执行。

这有点类似于数据结构中的有向无环图,两个没有连通路径的任务之间可以并行执行。下面再给一个烤面包的例子,如果所示,预热烤箱和购买面粉糖两个任务之间可以并行执行。

对大多数科学计算和工程应用来说,数据分解一般都是基于输出数据,例如:
1.在一副图像中,对一个滑动窗口(例如:3*3像素)内的像素实施滤波操作,可以得到一个输出像素的卷积。
2.第一个输入矩阵的第i行乘以第二个输入矩阵的第j列,得到的向量和即为输出矩阵第i行,第j列的元素。
这种方法对于输入和输出数据是一对一,或者多对一的对应关系比较有效。
也有的数据分解算法是基于输入数据的,这时,输入数据和输出数据一般是一对多的关系,比如求图像的直方图,我们要把每个像素放到对应的槽中(bins,对于灰度图,bin数量通常是256)。一个搜索函数,输入可能是多个数据,输出却只有一个值。对于这类应用,我们一般用每个线程计算输出的一部分,然后通过同步以及原子操作得到最终的值,OpenCL中求最小值的kernel函数就是典型代表[可以看下ATI
Stream Computing OpenCL programming guide第二章中求最小值的kernel例子]。
通常来说,怎样分解问题和具体算法有关,而且还要考虑自己使用的硬件和软件,比如AMD
GPU平台和Nvdia GPU平台的优化就有很多不同。
二、常用基于硬件和软件的并行
在上个实际90年代,并行计算主要研究如何在cpu上实施指自动的指令级并行。
1.同时发射多条指令(之间没有依赖关系),并行执行这些指令。
2.在本教程中,我么不讲述自动的硬件级并行,感兴趣的话,可以看看计算机体系结构的教程。
高层的并行,比如线程级别的并行,一般很难自动化,需要程序员告诉计算机,该做什么,不该做什么。这时,程序员还要考虑硬件的具体指标,通常特定硬件都是适应于某一类并行编程,比如多核cpu就适合基于任务的并行编程,而GPU更适应于数据并行编程。

现代的GPU有很多独立的运算核(processor)组成,在AMD GPU上就是stream core,这些core能够执行SIMD操作(单指令,多数据),所以特别适合数据并行操作。通常GPU上执行一个任务,都是把任务中的数据分配到各个独立的core中执行。
在GPU上,我们一般通过循环展开,Loop strip mining
技术,来把串行代码改成并行执行的。比如在CPU上,如果我们实现一个向量加法,代码通常如下:
for(i = 0; i < n; i++)
2: {
3: C[i] = A[i] + B[i];
4: }
|
在GPU上,我们可以设置n个线程,每个线程执行一个加法,这样大大提高了向量加法的并行性。
__kernel void VectorAdd(__global const float* a, __global const float* b, __global float* c, int n)
2: {
3: int i = get_global_id(0);
4: c[i] = a[i] + b[i];
5: }
|
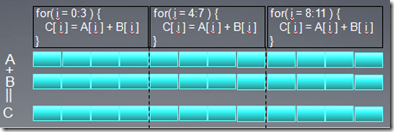
上面这个图展示了向量加法的SPMD(单指令多线程)实现,从图中可以看出如何实施Loop strip mining
操作的。
GPU的程序一般称作Kernel程序,它是一种SPMD的编程模型(the Single Program
Multiple Data )。SPMD执行同一段代码的多个实例,每个实例对数据的不同部分进行操作。
在数据并行应用中,用loop strip mining来实现SPMD是最常用的方法:
1.在分布式系统中,我们用Message Passing Interface
(MPI)来实现SPMD。
2.在共享内存并行系统中,我们用POSIX线程来实现SPMD。
3.在GPU中,我们就是用Kernel来显现SPMD。
在现代的CPU上,创建一个线程的开销还是很大的,如果要在CPU上实现SPMD,每个线程处理的数据块就要尽量大点,做更多的事情,以便减少平均线程开销。但在GPU上,都是轻量级的线程,创建、调度线程的开销比较小,所以我们可以做到把循环完全展开,一个线程处理一个数据。

GPU上并行编程的硬件一般称作SIMD。通常,发射一条指令后,它要在多个ALU单元中执行(ALU的数量即使simd的宽度),这种设计减少了控制流单元以级ALU相关的其他硬件数量。
SIMD的硬件如下图所示:

在向量加法中,宽度为4的SIMD单元,可以把整个循环分为四个部分同时执行。在工人摘苹果的例子中,工人的双手类似于SIMD的宽度为2。另外,我们要知道,现在的GPU硬件上都是基于SIMD设计,GPU硬件隐式的把SPMD线程映射到SIMD
core上。对开发有人员来说,我们并不需要关注硬件执行结果是否正确,我们只需要关注它的性能就OK了。
CPU一般都支持并行级的原子操作,这些操作保证不同的线程读写数据,相互之间不会干扰。有些GPU支持系统范围的并行操作,但会有很大开销,比如Global
memory的同步。
|





