|
在百度多年部署使用SSD的过程中,积累了很多经验,也发现了传统SSD的一些缺陷。本文作者认为,非常有必要按照大规模存储系统的需求重新设计SSD的软硬件架构,以彻底解决其不足,于是提出了“软件定义Flash”概念。
百度是国内最早大规模使用SSD/Flash的互联网公司之一,早在2007年,就开始在搜索引擎中大规模使用SSD。在过去的几年中,百度数据中心部署了数以十万计的SSD,支撑了每天60亿次的搜索请求及其背后的广告、大数据实时分析处理、CDN等系统。在百度多年部署使用SSD的过程中,积累了很多经验,也发现了传统SSD的一些缺陷。在实际系统中,传统SSD只能为上层软件或存储系统提供硬件裸带宽(raw bandwidth)的40%左右,甚至更低。因为Flash必须先擦除再写入的特性(Out-of-place Update)以及需要7%~50%的预留空间(over-provisioning space)来处理随机写,传统SSD还需要提供10%左右的空间来做Flash通道之间的奇偶校验,因此,传统SSD只能提供硬件裸容量(raw capacity)的50%~70%给上层应用或存储系统。另外,传统SSD的性能往往会在使用过程中出现抖动,或随着剩余空间变小而降低。考虑到百度大规模的数据中心和大规模的SSD部署,传统SSD的不足给我们带来了巨大的成本和效率开销。
我们认为非常有必要按照大规模存储系统的需求重新设计SSD的软硬件架构,以彻底解决其不足。于是我们提出“软件定义Flash”(SDF,Software–Defined Flash)的概念。SDF是一个软件硬件协同的系统,把底层Flash通道的接口暴露给上层软件,软件可以管理数据的分布,以充分挖掘硬件的并发性;同时针对大规模存储系统的特性设计软硬件架构,消除了传统SSD的冗余空间和奇偶校验空间,使得几乎所有的Flash空间都能提供给上层软件使用。百度自行实现了SDF所有的软件和硬件设计,并部署在内部存储系统上,实现了99%的容量利用率和95%的带宽利用率。相对于传统同配置的PCIE SSD,性能提高了3倍,成本降低了50%。
传统SSD的特性与不足
SSD是采用NAND为介质的存储设备,与机械硬盘不同,它不需要任何机械操作,因而功耗很低,带宽比机械硬盘高1个数量级,IOPS高两个数量级。随着NAND颗粒不断降价,SSD应用更加广泛,基本成为数据中心的标准配置之一。但其每GB成本仍然比机械硬盘贵1个量级以上,因此,充分发挥SSD的潜能就显得非常重要。
NAND有如下两个特性,决定了SSD的一切设计取舍。
先擦除才能写(Out-of-place Update):一个物理块必须先擦除才能写入新数据。
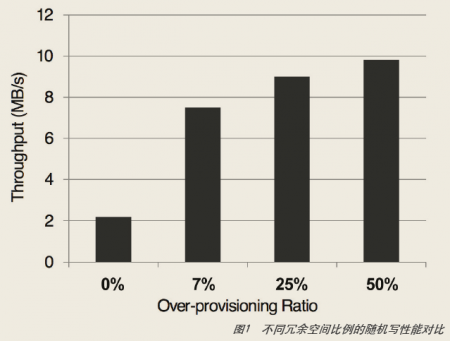
该特性会影响随机写性能,因为更新的数据不能直接覆盖旧数据,而是必须先写到一块已擦除过的新块中,等写到一定程度,需要把老的、无用的数据统一删除,以腾出空间给新数据。这个过程需要merge操作,非常耗时。因此传统SSD必须预留很大容量(一般为7%~50%),作为写缓存,以降低merge的代价。一般越高端、性能越好的SSD冗余空间就越大。也就是说,一个本来有1TB空间的SSD,为了确保高效,用户只能使用500GB。这意味着落到用户的每GB成本就更高,但如果冗余空间较小,往往性能也没法满足用户的需求。
我们选择一款SATA接口的SSD硬盘,通过调节冗余空间,在不同比例下做随机写测试,可以看到,冗余空间为7%时相对于0%有接近4倍的性能提升,冗余空间为50%相对于7%有40%多的性能提升(如图1所示)。
Out-of-place Update还会导致一个问题是写放大系数(Amplification Factor)。SSD在做垃圾回收的过程中要做merge操作,会把一些有效数据搬移到新块,并把原来的块擦掉,导致了额外的擦除。如果写放大系数太大,会大大降低SSD的使用寿命,一般写放大系数都在2~3之间。
传统SSD的大部分设计努力,都是在保证一定性能的前提下,尽量降低冗余空间的比例和写放大系数。
单个NAND的性能非常有限,必须利用多个NAND并发操作来达到较高的性能。
一般一个页的读延时是几十μs,写延时是ms量级,一个NAND芯片内部会有多个plane,一个SSD会有多个NAND通道。SSD控制器会把数据尽量strip到多个通道中的多个plane中,以通过并发访问提高总性能。传统SSD的硬件架构如图2。

一个SSD控制器包含十个到几十个Flash通道,每个通道一般包含1~2个NAND颗粒,每个NAND颗粒有数个到十几个Flash plane。如果用户要写一块数据到SSD,这时SSD控制器会负责把数据拆成小块,并发写到多个通道中,以充分利用硬件的并发性。如果要读数据,SSD也会根据之前写的映射关系找到对应的通道,将数据读出来。传统SSD的控制器需要承担数据stripping、layout和mapping管理等策略,很难针对不同应用需求、不同访问模式做到最优,而且会增加硬件复杂度,提升成本。
NAND还有一些其他特点,如读写以为页单位,擦除以块为单位,数据必须经过BCH校验,使用过程中会出现坏块,每个块都有固定的使用寿命等,这导致了SSD设计还有其他一些妥协,如磨损平衡、地址映射等。
软件定义硬件原则
所谓软件定义硬件,从系统角度来看,有两个原则。
- 应用驱动。
- 软硬件协同系统。
从实现的角度,有如下三个设计原则。
- 硬件要简单,可控性大于智能化。
- 尽可能暴露硬件底层接口。
- 软件从层次化变成竖井化。
软件定义Flash
基于这样的设计原则,在2011年初,我们开始着手设计面向大规模存储需求的下一代SSD——SDF。
SDF拥有与传统SSD完全不一样的架构和设计,我们针对海量存储系统的数据访问模式设计,底层硬件接口暴露给上层软件,取消了传统的Linux文件系统和I/O栈,主要创新包括以下几点。
全新的硬件架构
底层Flash通道暴露给上层软件,软件可直接管理数据的layout以充分挖掘硬件的并发能力。SDF的架构如图3所示,可以看到,其架构和SSD有明显不同。在SDF中,每个Flash通道对于上层软件来说都是一个独立的小SSD,软件通过自己定义的调度器来管理数据的布局,使得多个通道能比较容易同时工作,这样实际带宽可以在不同场景下都能达到硬件裸带宽的极限。

每个Flash通道具有一个独立的FTL(Flash Translation Layer)控制器,实现了简单的地址映射、坏块管理等功能。
全新的软件架构
消除了传统的Linux文件系统和I/O栈,我们自行研发了轻量级的用户态文件系统,大大降低了I/O请求延时。SDF的软件架构如图4所示。

基于从层次到竖井的设计原则,我们可以看到,SDF的软件栈,只保留了最底层的硬件驱动,其他层次都没有了,Linux的文件系统也变成了用户态的一个轻量级文件系统。
不对称的读写粒度,写单位是2MB,刚好是一个擦除块的大小;读单位是8KB,刚好是一个页的大小。在互联网大规模存储系统中,为了提高I/O性能,一般都会在内存中把随机写合并成顺序写,典型系统包括Google的LevelDB,Facebook的Haystack,以及百度的新存储体系。可以把持久化写的粒度设置成NAND的擦除块大小,并且硬件不做stripping,这样就不需要预留冗余空间,也不需要垃圾回收,因此写放大系数恒为1。
全新的系统视角
通过软硬件结合的办法保证系统的可靠性。因为存储系统本身已对数据进行了3副本备份或做了Erasure Code,因此并不需要硬件提供非常苛刻的可靠性保障。而传统SSD除了对数据做了必须的BCH校验,还在通道之间做了横向的奇偶校验,奇偶校验数据存储在一个独立的通道,相当于消耗了一个通道的容量。SDF取消通道间的奇偶校验,把之前存放奇偶校验数据的通道用来存放数据,相当于多增加了10%的存储空间。
具体的设计细节和设计原则,可以参考百度发表在ASPLOS 2014上的论文《SDF: Software-Defined Flash for Web-scale Internet Storage Systems》。
SDF性能数据
2011年设计的SDF采用25nm的Micron MLC NAND,控制器采用Xilinx的FPGA,硬件板卡由第三方ODM提供,百度自行设计了Verilog RTL代码、驱动代码和用户态文件系统代码。
在大压力测试时,性能数据如表1。

百度SDF和“市场某主流PCIE SSD”采用同样的硬件配置,但性能更好。SDF的读带宽达到1.59GB/s,是PCIE 1.1 x8实际性能的上限,带宽利用率99%;写性能达到0.96GB/s,是44个Flash通道写聚合性能的上限,写带宽利用率达到96%。
我们可以通过定义不同的软件调度策略来激活不同的Flash通道,通过不断增加工作的通道数量,可以看到,其读写性能也线性提高(如图5),可见SDF的设计具有非常良好的扩展性。

结论
百度提出软件定义硬件的概念,并依此原则设计了软件定义Flash(SDF),我们将SDF部署在实际生产环境,每GB成本比市场上主流的PCIE SSD降低了50%,性能提高了3倍。同时在ASPLOS、EUROSYS、ISLPED等全球顶级计算机系统和体系结构会议发表论文3篇,发明专利9个,取得了良好的应用效果和学术成果。
SDF除了可以应用在百度的大规模存储系统中,也可以用在其他基于LSM-tree的存储系统,如Haystack、LevelDB等,具有很好的适应性。
|





