|
无论是国外的Google、Facebook、Amazon,还是国内的Baidu、Taobao等,这些高性能的服务器在处理高并发的请求时,都能快速、准确的给予应答。通过查阅资料,了解现有大型网站的技术架构,发现目前常用的技术有分层、缓存、负载均衡、数据库性能优化,分布式系统等等。接下类分别对这些技术进行简单介绍。
1 分层与服务分离
无论OSI的7层网络结构,还是计算机底层硬件与上层软件之间的分层,甚至于Web领域大家非常熟悉的MVC开发模式,分层在计算机领域无处不在。分层可以将不同的功能部件独立起来,下层为上层提供访问接口,支撑上层的功能;上层调用下层接口来完成服务。
分层也是服务器端采用的一种方法,通过将数据库、文件资源等与应用服务器分开,可以缓解服务器压力。
另外,根据业务需求的不同,将明显没有交集的业务分开,独立成不同的模块单独进行管理,也可以在很大程度上提升服务器性能。
2 缓存
缓存在计算机很多地方都有涉及,比如在内存与硬盘之间增加Cache、增加IO缓冲区来缓解速度之间的不匹配。缓存的出现主要是依据计算机中著名的二八定律。缓存的技术主要包括本地缓存、分布式缓存、CDN和反向代理。
根据二八定律,80%的操作集中在20%的数据上。网站将常用的数据缓存在本地应用服务器中,以后直接通过缓存中的数据来响应用户的请求,而不用再去计算。这样就可以减少响应时间。
分布式缓存相比本地缓存速度要慢,因为应用服务器要访问专门的缓存服务器来获取数据,但是应用服务器主要用于处理请求,其自身内存有限,如果缓存大量数据,应用程序的运行速度将受到明显影响。因此很多大型网站都使用远程分布式缓存,部署大内存的服务器作为专门的缓存服务器。
缓存的另外两种表现形式是CDN和反向代理。不同的地方在于,CDN部署在网络提供商(比如电信、移动、联通等)的机房,用户在请求网站服务时,可以直接从网络提供商机房获取数据;而反向代理则部署在网站的中心机房,当用户的请求到中心机房后,首先访问的服务器是反向代理服务器,如果反向代理服务器中有相应资源的缓存,就将其直接返回给用户,而不用再去请求应用服务器。
3 负载均衡
负载均衡的原理就是去中心化。当用户并发请求量巨大时,如果将所有的请求都交给一个服务器去处理,很可能造成服务器宕机,即使能够正确响应,响应时间也可能会比较长,给用户造成不好的体验。
大型网站都是将一个域名绑定不同的服务器IP,这样表面上好像只有一台服务器在提供服务,实际则是一个服务器集群在提供相同的服务。负载均衡器接收所有用户的请求,再根据每台应用服务器正在处理的请求数量来对请求进行分配。这样就能在很大程度上提高系统的性能,同时扩展性也得到很大提升――当某台服务器宕机时,直接替换就可以,其它服务器继续相应用户请求;当用户请求量超过预定峰值时,也可以通过实时增加服务器来缓解压力。
4 数据库性能优化
使用缓存后,大部分的数据操作不需要通过数据库即可完成。但是仍有一部分读操作(缓存访问不命中,缓存过期)和全部的写操作需要访问数据库,在网站的用户达到一定规模时,数据库因为负载压力过高而成为网站的瓶颈。因而需要对数据库进行优化,常用的技术主要包括读写分离、结合非关系型数据库使用、分布式数据库等。
一般情况下,数据库读操作所需要的时间比写操作的要少很多,通过将数据库的读写操作分离可以明显改善数据库性能。目前很多大型网站都配置数据库主从关系,主数据库用于写操作并将数据同步更新到从数据库上,从数据库只负责读操作。例如,新浪云计算平台(SAE)给用户的数据库就进行了主从配置。
同时,可以利用非关系型数据库和搜索引擎对数据检索的优势,来减轻应用服务器直接访问关系型数据库的压力。
当对业务进行分离后,可以根据业务所涉及的数据,将数据库进行分库部署在不同的服务器上。
5 冗余
网站需要7x24小时连续运行,但是服务器随时可能出现故障,特别是服务器规模比较大时,出现某台服务器宕机是必然事件。要想保证在服务器宕机的情况下网站依然可以继续服务,不丢失数据,就需要一定程度的服务器冗余运行,数据冗余备份,这样当某台服务器宕机时,可以将其上的服务和数据转移到其它机器上继续运行。
接下来,我们主要针对缓存中的Memcached技术进行介绍。
1 Memcached
1.1 Memcached简介
Memcached是一个高性能的分布式对象缓存系统,用于动态Web应用,以减轻数据库负载[1]。它通过在内存中缓存数据和对象来减少应用程序读取数据库的次数,从而提高网站的性能。如图1是Memcached在网站中的位置示意图。

图1 Memcached位置示意图
Memcached以键值对的形式将数据(或对象)缓存在内存中,虽然使用到了多个服务节点,但是和一般分布式缓存系统不同的是,每一份数据在Memcached中只存在一份,每个Memcached服务节点之间相互不可见。因此,Memcached中每份数据的键值是唯一的。
简而言之,Memcached类似于一个典型的非关系型存储系统,可以归入基于内容的键值对存储类型[2]。
1.2 Memcached工作原理
当高并发的外部请求访问服务器时,负载均衡服务器会根据各应用服务器的使用情况进行分配转发,如果需要对数据进行读取,应用服务器会按照一定的Hash算法计算键值的结果,并根据计算结果访问Memcached的某一个服务节点,服务节点再次计算键值的第二次Hash值,再根据计算结果对数据进行读取,如果缓存中有数据则直接返回给应用,否则需要从数据库获取数据,同时将获取到的数据写入到Memcached中[3]。

图2 Memcached工作原理
2 性能分析
在本机上安装Memcached,客户端使用Memcached提供的接口进行数据的存储与访问,并与直接通过MySQL获取数据的方式进行对比。
2.1 Memcached安装
由于Memcached主要用于服务器端,而服务器端操作系统大多用Linux,因此网上多数教程是关于在Linux上安装使用Memcached的。在Windows上安装更加简单,只需找到对应操作系统的版本即可[4]。
安装Memcached后,打开服务即可使用相应功能,Memcached默认监听11211端口,如果是在本机上,直接使用127.0.0.1:11211就可以访问了,这点和MySQL非常类似。
Memcached提供了很多高级语言的接口,可以根据这些接口来完成对数据的存储与访问。
2.2 Memcached和MySQL性能比较
为了比较使用Memcached前后访问数据性能的情况,进行以下模拟实验。
硬件条件:
CPU:Intel Core 2.60GHz;
内存:2GB;
软件条件:
操作系统:Window 64;
Memcached最大内存:64MB;
Memcached最大连接数:1024。
MySQL中共有29120条记录,使用多线程模拟用户的并发访问,每个用户请求100次数据读取。表1是在用户数量为N的条件下,测试所有请求都处理完所用时间T的结果。
表1 测试结果
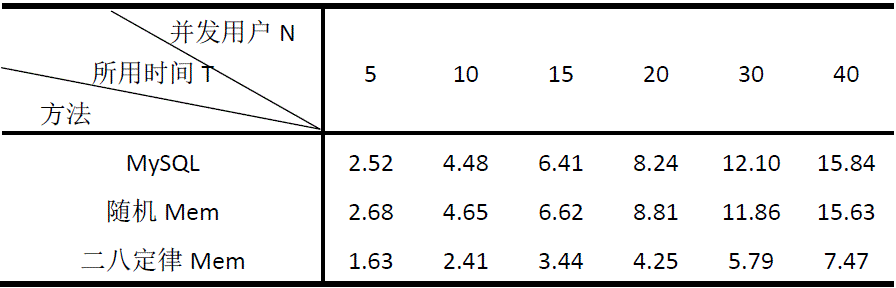
三种方法说明:MySQL表示所有的数据请求直接通过访问数据库返回;随机Mem表示在增加了Memcached缓存后,对于每个用户的100次请求,数据之间没有任何关系,完全随机;二八定律Mem表示用户的请求遵循二八定律,就是说平均100次请求中,有比较多的次数访问的是相同数据,这个可以通过程序模拟,在访问时控制相应次数访问相同的数据。
图3、图4分别对应表1的两种数据表示。

图3 柱状图显示结果

图4 折线显示结果
由于在完全随机访问的条件下,数据的命中率非常低(几乎为0),每次请求都需要从数据库中获取,同时还要将请求到的数据保存在缓存中,因此效率比直接从数据库中获取还要低。但是当用户多次请求相同的数据是,使用Memcached
明显比直接从MySQL中获取效率要高很多。
整个测试过程还存在着一些不足之处:
1.受实际条件限制,Memcached服务节点数只有1个;
2.另外,数据库中数据量级也不是非常大;
3.没有测试数据写入的情况
3 关键问题
通过上述分析可知,Memcached在一些条件下对提升数据访问效率有很大作用。对于那些不常变动访问频率又非常高的数据,将其放在缓存中,可以很好的缓解数据库的压力,进而提升系统性能。但同时,Memcached自身也还存在着一些不足之处:
由于Memcached是将数据缓存在内存中,当出现断电情况时,数据将立即消失;
所有数据在Memcached中只保存一份,因此可靠性不是很高,一旦某台服务节点出现故障,相应的数据将丢失;
Memcached在设计之初每个key的value最大是1MB,随着目前数据量的快速增长,缓存数据量大的文件,比如音频、视频等有很大不足。 |





