|
һ�� ������Ʒ�������
������Ʒ���������������Ƽ��������з�����Ʒ�������棬��Ҫ������Ϊ���������û��ṩ�������ٵĹ������顣��Ȼֻ�ж̶̼����ʱ�䣬���ǵ����������Ѿ������˶��618�����˫11�Ŀ��飬Ŀǰ�Ѿ��ܹ��������ճ�ʹ�õ���ȸ衢�ٶȵ�ȫ������������ȣ����ǵIJ�Ʒ��������֮ͨ�������纭���ڼ�����Ʒ�ĺ������ݡ�֧�ֶ�ʱ���߲�����ѯ�������Լ���ҵ���ص㣺
���������ݣ��ڼ������Ʒ����
�߲�����ѯ����PV���ڣ�
������Ҫ������Ӧ��
�����Ѿ���Ϊ�����ճ����ɻ�ȱ��Ӧ�ã���������û����Google���ٶȵ��������棬����������ʲô��������վ����Ʒ�����Ծ���������ͬ��������Ի������Ĺ�ϵ�����ǵĹ�֮ͬ����1.
���������ݣ��ڼ������Ʒ����2. �߲�����ѯ����PV���ڣ�3. ������Ҫ������Ӧ����Щ��ͬ��ʹ��Ʒ����ʹ��������������Ƶļ����ܹ�����ϵͳ��Ϊ��1.
������Ϣ����ϵͳ��2. ����ϵͳ��3. ��������ϵ��4.����������ϵͳ��
ͬʱ����Ʒ����������ҵ���ԣ����������һЩ��֮ͬ����
1. ��Ʒ�����Ѿ��ṹ������ɢ������Ʒ����桢�۸������ִ��ȶ��ϵͳ��
2. �ٻ���Ҫ��ߣ���֤ÿһ����������Ʒ���ܹ�����������
3. Ϊ��֤�û����飬��Ʒ��Ϣ���������۸��ı仯��ʵʱ��Ҫ��ߣ����¸�������ÿ��ĸ�����Ϊǧ��
4. ��ǿ�ĸ��Ի�����������һ����Դ�ֱ������������Ҫ�����û��ĸ��Ի�������ͼ�������û�������С˵���е��û�ϣ��������С˵�е�����Ҫ������С˵�е���ϣ���ҵ���־С˵��
���ⲻͬ���������������Ա𡢶�����ʱ������ͳ̶ȡ��Դ�����ƫ�ó̶��Լ������Ա��硰��������ʡ���ƫ�ò�ͬ��������Щ��Ҫ�бȽ����Ƶ��û�����ϵͳ���ṩ֧�֡�
һ������ܹ�ͼ
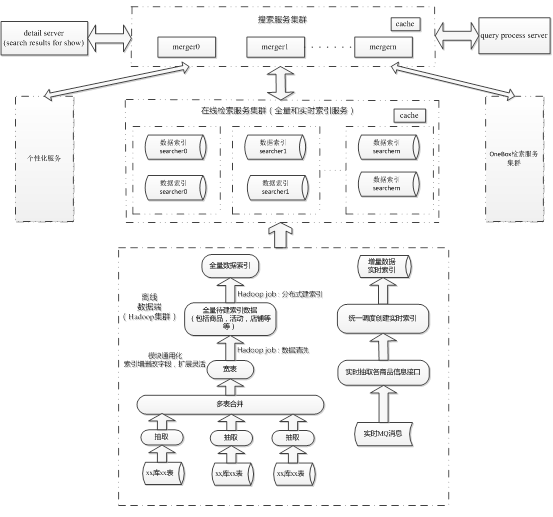
��������Ⱥ���ɺܶ��merger�ڵ���ɵļ�Ⱥ�����յ���ѯquery������ͨ��qp�����в��Ե��·�������������Ⱥ����������Ⱥ�����Ը�������ķ��ؽ�����кϲ�����Ȼ�����detail
server��װ��������շ��ظ��û���
query processor server������query��ͼʶ�����
����������Ⱥ���ɺܶ��searcher�ڵ���ɣ�ÿ��searcher�ж�Ӧһ��С��Ƭ����������ȫ�����ݺ�ʵʱ�������ݣ���
detail server���������չʾ����
���������ˣ�����ȫ������������������Ϊ����������Ⱥ�ṩȫ��������ʵʱ�������ݡ�
���� ������Ϣ����ϵͳ
������Ʒ���ݷֲ��ڲ�ͬ���칹���ݿ����KV�й�ϵ�����ݿ⣬��Ҫ����Щ���ݳ�ȡ��������������ƽ̨�У����Ϊȫ����ȡ��ʵʱ��ȡ��
����ȫ��������������Ʒ����ɢ���ڶ��ϵͳ�Ŀ���У�Ϊ�˱��������������Զ��ϵͳ����������Ʒά�Ƚ��кϲ���������Ʒ������Ȼ��������ƽ̨�ϣ�ʹ��MapReduce����Ʒ���ݽ�����ϴ��֮���������ҵ������������������һ��ȫ�����������ݡ�
����ʵʱ������Ϊ�˱�֤���ݵ�ʵʱ�ԣ�ʵʱ���ø���Ʒ��Ϣ�ӿڻ�ȡʵʱ���ݣ������ݺϲ��������ȫ���������Ƶķ����������ݣ������������������ݡ�
���� ����ϵͳ
��ϵͳ�����������ĺ��ģ��ڽ������ϵͳ֮ǰ��������Ϣ��Ȼ������Ʒά�Ƚ��д洢�ġ�����ϵͳ��������һ���Թؼ���ά�Ƚ��д洢����Ϣ��һ���֮Ϊ����������
��ϵͳ����ȫ���������Ĵ�����һ�µģ�Ψһ���������ڴ������������IJ��졣һ������£�ȫ���������������������Ӵ���hadoop���У�ʵʱ������С�����õ�����������������
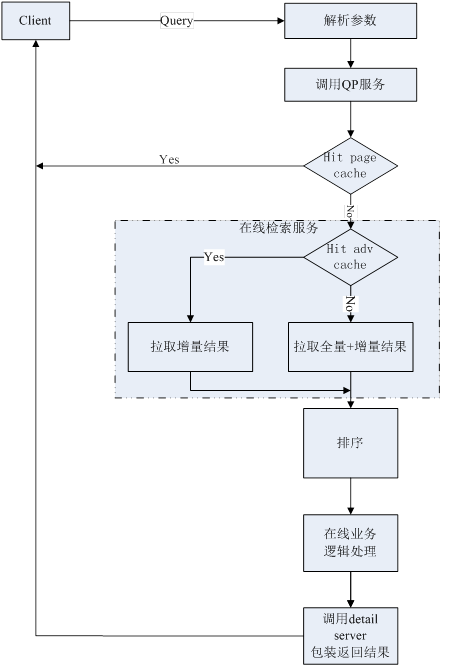
�ġ� ��������ϵͳ
��������ϵͳ���������������û�������Ӧ��ϵͳ�����ϵͳ���ֻ��1��searcher������������������û��������Ҫ����������Query
Processor�������ѯ��ͼ����������������ȷ�ԡ����ŷ��������������������ӻ���ģ�飬�������������ܡ�������������������Ʒ����������������װ����Ӽ��������ж�����ȥ����Ϊdetail
server�����������Ľ�һ�������������ݽ����������ݿ�ֿ�ֱ��ķ�Ƭ��������ʱ�������������ɶ����Ƭ��searcher����ɡ���Ȼ��Ȼ����Ҫһ��merger���������Ƭ�Ľ�����кϲ������ˣ�������������ϵͳ�걸��
֮��������������������������������������������ͨ�����������㡣����618��1111֮�����������������ͨ������ÿ��searcher�з����������������㡣��������Ʒ���ݵIJ������ӣ�ֻ��Ҫ������������ķ�Ƭ����Ӧ������searcher�������㡣
��������ϵͳ�ڲ��Ĵ����������£�
����������У�����ģ�����ȡ���ģ��dz��ȶ���������ģ�������ҵ��������ģ�龭����Ҫ�Ķ����ܹ���Ҫ�ȶ�����Ч��ͨ�á�����ҵ���ص���ʵ��ģ�Ͷ࣬���������ٶȿ죬����Ч����Ϊ�˽����һ��ͻ����Ҫ������ҵ����ܹ����룬�Զ�̬���ӿ�ķ�ʽ���ɵ���������ܹ��У���������ı����Ժ�������������ά�ȵ�����ԣ��ı���������Լ�����searcher���У�������������ԣ��������������Ի���ҵ���Ȩ�ȵȣ�������merger���С�ʵ�ּܹ�������ҵ���˾��ְ������Ӱ����š�
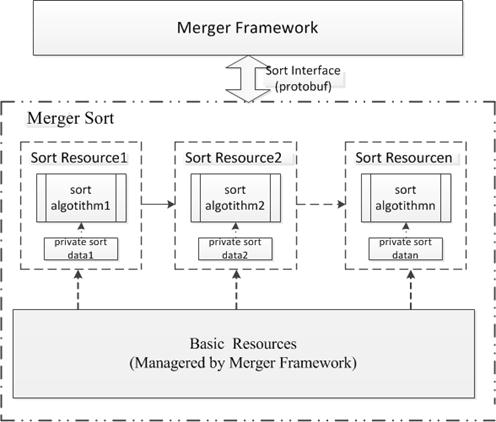
������ܹ�����
�塢 ����������ϵͳ
����ϵͳ��Ҫ�����û���Ϊ���ݵ�ʵʱ�ռ����ӹ����������ݴ洢�����ݼ��е��У�������Щ���ݽ���������ȡ����������Ҫ���˵�����ָ����UV��ֵ��ת���ʣ����Ի���������Щ���ݸ����Ż�Ŀ�깹�����ע���ݡ�Ȼ����ڻ���ѧϰ������ϵͳ���������������ģ�͡���������ģ����ÿ����µ�ѵ��֮ǰ��Ű�������ݡ����������ڻ���ģ�͵��������֮�ϣ��ϲ㻹����һ��������棬���籣�ϵ��̺�Ʒ�ƵĶ����ԣ��Լ�����ս�Է��ֵ�Ʒ�Ƶȶ�ͨ��ҵ��������ʵ�֡�һ����ڻ���ѧϰ������ģ����Ҫ�ϳ��ڵ�Ͷ�뵫��ģ���ӽ�׳�����ױ������ֶ��ҵ�©�������ҿ�����ת���ʺ�UV��ֵ�ɳ�����������
����������Ҫ��Ϊ�˿��ٷ�Ӧ�г��ı仯�������ͼ�Ӱ��Ч��������һ������ҩһ������ҩ�����������Ч�á�
������Խ���˫11������ϵͳ�����Ż�
1.�����뼶�л�����������Ⱥ�����������������κ�һ���������ֶ������ϵ����������뼶�������л����������������������IJ���Ӧ�ò����˵������ϣ����Խ��ж�̬���ݡ�
2.����ڼ���������ʵʱ����ÿ����������Ʒ���ݵ���Ϣ����Ƶ�����漰ǧ������д������������������ṹ�����˵���������������������´��ڵ�һ�������ƣ���Ʒ�������IJ�����Ϊ��ʽ���¡�ʹ����ڼ���Ʒ���������´ﵽ�����
3.����ڼ�ĸ��Ի������������������ڼ�����������ƽʱ5�����ϣ��߷���������ƽʱ��7����Ϊ�˱���ϵͳ�ȶ������Ի������������˽���������������������Ļ������������Ե��Ż���ʵ������������ṹ���ӵ����Ϸֱ������term�Ļ��棬����Լ��㻺��ͷ�ҳ���档���ϲ�ķ�ҳ����ܶ�ʱ��ᱻ�û��ĸ��Ի�������������ǵײ������Ի����term����Ľ�����������ã�����������ʹCPU���ع��ߡ�
�ߡ� �����ڵ������������Ʒ�ͼ����Ĵ���
1. ���Ի�����
���Ի�֮ǰ����������ͬһ����ѯ����ͬ�û������Ľ������ȫ��ͬ�ġ�����ܲ������������û�����������Ʒ�����У����������Ϊ�س�����Ϊ��Ʒ�������û������ر�����ijЩƷ�ơ��۸��̵���Ʒ��Ϊ�˼����û���ɸѡ�ɱ�����Ҫ��������������û����и��Ի�չʾ��
���Ի��ĵ�һ���Ƕ��û�����Ʒ�ֱ�ģ���ڶ����ǽ�ģ�ͷ�������������֮�����û����в�ѯʱ��mergerͬʱ�����û�ģ�ͷ���������������û�ģ�ͷ����û�ά��������������������Ʒ��Ϣ������ģ�����������������ݶԽ�����������������û����ظ��Ի������
2. ��������
�û���ʹ������ʱ����Ŀ�IJ������Dz�����Ʒ�������ܲ�ѯ�������Ϣ��Ϊ��������һ������������Query
Processor�����Ӷ�Ӧ��ͼ��ʶ�𡣵ڶ����ǽ������һϵ�д�ֱ�������ϲ�����һ��QPʶ��������ѯ��ͼ�����������Ϸ�����Ӧ�Ľ�����ظ��û���
3���������
����������ھ�������������������ͼ������Ҫ�ں�̨����һ��ǿ���֪ʶ����ϵ������Ӻ����������ھ�������ı�ǩ������Ч���õ������������£Ч���õ����֡������ʺ�����ĸ��ȣ�����Щ��Ϣһͬ������������ȥ�����������ʺ��ͻ��ѵ�������������ͼ������صĽ��������������������Ҳ���Դ��ⲿ��վץȡ�м�ֵ��Ϣ��������֪ʶ����ϵ��
4��ͼ�����
�ܶ�ʱ���û�����֪���������һ����Ʒ��ͨ��������ͼ��������з������Ծ������ھ�������ͼ���ܶ�ʱ���û������������������ڳ��п���һ������ʳƷ����һ��ʱ�е��·�������ͨ�����ռ���Ѹ���������ҵ����Ƚϼ۸����⿴��ͬ�´���һ���Ƚ�ϲ�����·�Ҳ����ͨ�����ռ������ҵ���Ŀǰ�������ڿ�ʼչ���ⷽ��Ŀ��������߷�����Ҫͨ��CNN�㷨����ͼƬ����������ȡ����ȡ������������ͬ������ȡ���������Ҫ�Ǻ������������Ƶļ�����ͼ������δ�������Կ���һ���µĵ��̹�����ڡ�����Ŀǰ�����з��µ�ͼ��������档
|





