摘要:StreamCQL是一个类SQL的声明式语言,它用于在流(streams)和可更新关系(updatable relation)上的可持续查询,可在流处理平台分布式计算能力之上通过使用简易通用的类SQL语言,使得业务逻辑的开发变得统一和简易。
StreamCQL是一个类SQL的声明式语言,它用于在流(streams)和可更新关系(updatable relation)上的可持续查询,目的是在流处理平台分布式计算能力之上,通过使用简易通用的类SQL语言,使得业务逻辑的开发变得统一和简易。在功能上,StreamCQL弥补了传统流处理平台上一些基本业务功能的缺失,除了过滤、转换等基本SQL能力之外, 还引入基于内存窗口的计算、统计、关联等能力,以及流数据的拆分、合并等功能。
StreamCQL重要概念介绍
- 流:流是一组(无穷)元素的集合,流上的每个元素都属于同一个schema;每个元素都和逻辑时间有关;即流包含了元组和时间的双重属性。流上的任何一个元素,都可以用Element<tuple, Time>的方式来表示,tuple是元组,包含了数据结构和数据内容,Time就是该数据的逻辑时间。
- Window:窗口(window)是流处理中解决事件的无边界(unbounded)及流动性的一种重要手段,把事件流在某一时刻变成静态的视图,以便进行类似数据库表的各种查询操作。在stream上可以定义window,窗口有两种类型,时间窗口(time-based)和记录窗口(row-based)。两种窗口都支持两种模式,滑动(slide)和跳动(tumble)。
- 算子:算子是包含了一系列运算关系的组合,比如聚合算子,就包含了查询(select),窗口,聚合(aggregate),排序(sort),窗口前过滤(filter before window),窗口之后的过滤(where),聚合之后的过滤(having)等功能,除此之外,还有流拆分算子,流合并算子等。StreamCQL中的算子分为三类:输入算子、输出算子、功能算子。
StreamCQL架构介绍
StreamCQL总体架构如下图所示:
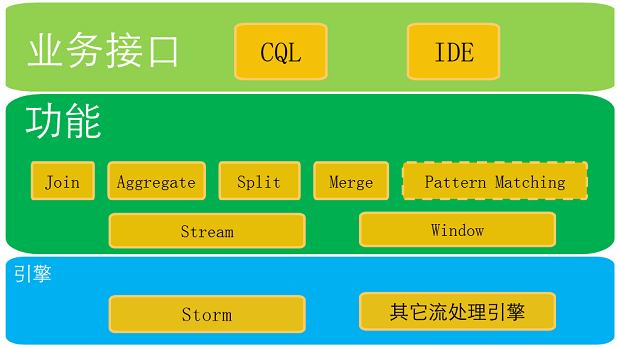
图1?StreamCQL架构图
StreamCQL的总体架构分为引擎、功能、业务接口三层,每隔层次之间分工明确,责任清晰,可以轻易进行功能拓展。
1. 引擎
StreamCQL的引擎层,可以适配各种不同的流处理引擎,比如Flink等,目前主要适配Storm。
引擎层的作用在于完成完成对各类算子对底层不同流处理引擎的接口适配、拓扑的构建、提交查看删除等操作。
以Storm适配为例,在Storm中,对外接口分为Spout和Bolt,其中,Spout就对应输入算子,Bolt对应输出算子和功能算子;StreamCQL中所有操作是以算子为单位的,各类运算都发生在不同的算子内部。算子分为输入算子、输出算子和功能算子,在Storm适配层中,就包含输入算子对Spout的适配,输出算子和功能算子对Bolt的适配,以及emit的适配,topology builder的适配。只要通过几百行代码就可以完成对Storm引擎的适配工作。
StreamCQL引擎层和Streaming的对外接口如下图所示:

图2 StreamCQL底层解耦架构
StreamCQL在Storm自身的IRichSpout,IRichBolt接口基础上,实现了StormSpout、StormBolt和StormOutputBolt来屏蔽底层不同引擎带来的接口变更。
StreamApapter是一个适配器,主要作用就是将Streaming算子注入到Spout和Bolt中。
IInputStreamOperator、IFunctionStreamOperator和IOutputStreamOperator是所有的输入输出和功能性算子的接口,同用户自定义接口一致。
该架构使用依赖注入的原则,实现了各个每个层级算子之间的解耦。
2. 功能
功能层以Stream和Window为基础,构建出了Join,Aggregate等算子。
Stream即流,该功能构建出了整个流处理平台数据流的基础。定义了数据流动、解析和分发规则。
Window:window是流上一段时间内数据的集合。StreamCQL上绝大部分的计算,都是基于窗口的。
流和窗口构成了整个流处理平台的核心。
StreamCQL功能层的算子包含Join算子、Aggregate算子、Split算子、Merge算子、Functor算子、filter算子、union算子、输入算子和输出算子,模式匹配算子目前暂时没有实现。
Join算子提供的功能类似关系型数据库的Join功能。目前StreamCQL支持的Join类型包含Inner?Join,Left?(outer)?Join,Right?(outer)?Join,Full?(outer)?Join?,Cross?Join四种类型。目前只支持双流Join。由于流的特殊性,Join的时候,两个流的数据都是在不断发生变化的,所以两个流任何一个流的数据变化,都会触发Join操作。如果只想让某个流触发Join,那么就应该使用UNIDIRECTION关键字。
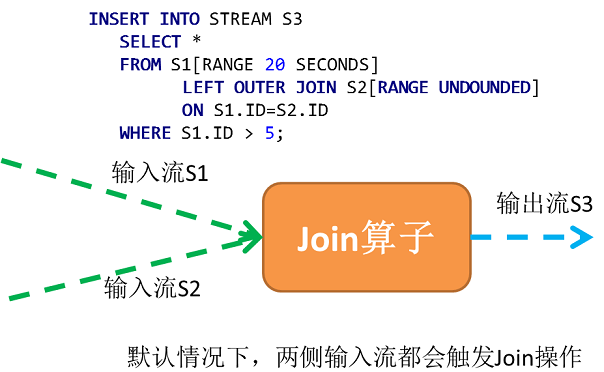
图3 双流Join示例
下表时当有数据流动的时候,双向Join的输出举例。

图4 双流Join结果示例

图5 双流Join单流触发Join示例

图6 双流Join单流触发Join数据示例
Filter算子适合只有单纯数据过滤的简单场景,不支持任何其他列转换运算,不支持窗口。
Functor算子在Filter算子的基础上?添加了列转换运算,支持Select子句运算。
Aggregate算子是一个大而全的算子,在Functor的基础上,添加了窗口功能,并支持分组,聚合,窗口前过滤,窗口后过滤,聚合后过滤(having),排序功能。

图7 aggregate聚合算子内部关系说明
Split算子的主要作用在于完成单个流到多个流的拆分,支持每个流输出不同数据。

图8?Split算子示例
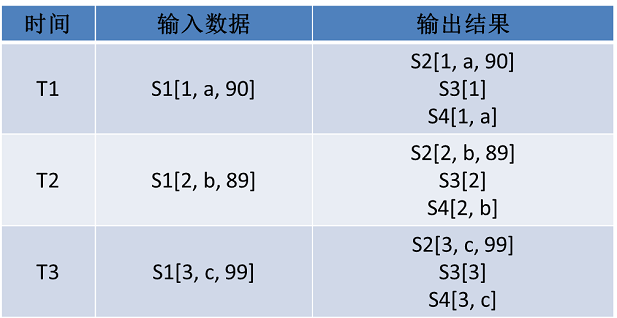
图9?Split算子输出举例
Merge算子作用正好和Split算子相反,支持多流到单个流的合并。Merge算子要求每个流都有一个字段和其他流中的一个字段匹配,这样才会合并做同一条数据。类似关系型数据库中的多留等值Join。

图10?Merge算子示例

图11?Merge算子数据输出示例
Union算子在CQL语法层面不支持,但是在CQL内部,会自动将满足条件的算子优化为Union算子。Union算子不支持任何过滤查询运算,只是简单进行流合并。
Input和output算子是单纯的输入和输出算子,其中包含数据的读取,写入,序列化、反序列化功能。
3. 业务接口
StreamCQL的业务接口构建在Storm所有功能之上,分为CQL和IDE,其中IDE指的是类似Eclipse的开发IDE,这种IDE以功能层各类算子和窗口为基础,可以很容易进行拖拉拽等流拓扑开发;IDE功能目前还没有实现。
CQL指的是CQL的语法,包含语法定义,语法解析,语义分析,流抽象拓扑构建等功能。CQL对StreamCQL对外功能展示的入口。相关CQL语法设计和对外拓展接口可以在Github上查看语法手册。
|





