摘要:对任何一个分布式系统,高可用HA都是最核心的设计目标之一,而OpenStack这样一个复杂系统,高可用更是涉及到多个层面,本文重点解析了OpenStack各层次的HA设计。
【编者按】本文从OpenStack架构入手,剖析了IaaS的云平台最核心的主要是这三部分:计算、网络、存储,作者指出OpenStack这样一个复杂系统,高可用更涉及到多个层面,只要有一个层面做不到高可用,那么整个OpenStack都没法高可用,随后他从基础服务Mysql和RabbitMQ,Nova、Neutron、Cinder接入与控制服务,网络服务三块探讨了OpenStack各层次的HA设计。
以下为原文:
一、OpenStack架构与HA分析
OpenStack实际上是由众多服务组合而成,它们之间的关联或多或少,而且具有一定的层次关系,每个服务就像积木块一样,你可以根据实际需要进行取舍并组合搭建,因此良好的运营架构整合能力是应用OpenStack的前提。
任何一个IaaS的云平台最核心的主要是这三部分:计算、网络、存储,OpenStack也不例外。在OpenStack里面这三者分别对应的是Nova,Neutron,Cinder这几个服务。从社区给出的OpenStack各个服务的应用统计来看,也是这几个服务接受程度最高,也相对最成熟,另外,从目前OpenStack生态去看,Swift的接受程度并不高,一个重要原因是Ceph在云计算领域的开疆拓土,一定程度上挤占了Swift的市场。相比Swift而言,Ceph是一个大一统的存储解决方案,在对象存储、块存储、文件存储三大方向都能够由Ceph底层的Rados,虽然Ceph Rados不具备数据排重等高级功能,在落地存储上也没有自己很核心的技术,但是在整个架构的Scaling和HA处理方面是做得相当不错,其设计理念比代码实现要超前。统一起来相当方便,而这三者恰恰是任何一个通用云计算平台所需要的。
对任何一个分布式系统,高可用HA都是最核心的设计目标之一。而OpenStack这样一个复杂系统,高可用更涉及到多个层面,只要有一个层面做不到高可用,那么整个OpenStack都没法高可用。
可以看一下一个经典的OpenStack物理架构如下所示:
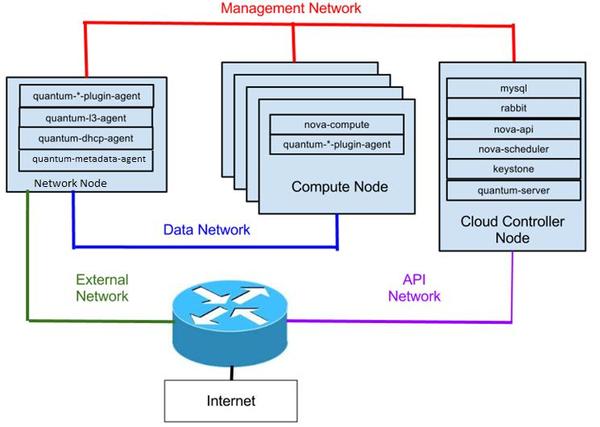
所以OpenStack的高可用可以从两个维度去划分,从功能服务维度划分:
1、基础服务(mysql,rabbitmq)
2、计算(nova)
3、网络(neutron)
4、存储(cinder)
从物理部署层面划分:
1、控制节点(主要部署基础服务+其他服务的接入、调度模块)
2、网络节点(主要部署Neutron的L2/L3/DHCP Agent,DHCP,Virtual Router)
3、计算节点(Nova ComputeAgent,Neutron L2Agent,虚拟机)
不管从那个维度去划分,都需要确保在每个层面上的高可用,并且在各个层面之间进行有效衔接。
在HA设计中,一般来说无状态的模块处理是比较简单的,基本思路是并行运行多个节点或者服务模块且对它们进行负载均衡。典型例子是一个网站的Web服务器集群,往往采用前端加LVS或者Nginx之类的LoadBanlace服务器解决HA问题(LVS和Nginx的高可用又是如何做呢?主要是利用Keepalived,Heartbeat等基于路由冗余协议VRRP或心跳仲裁机制来解决)。
而对于有状态的模块,主要有两种方式来实现HA,一种是多节点基于分布式一致性协议(比如Paxos,Raft协议等)维护相同的状态,典型的代表有Zookeeper,Rabbitmq;一种是基于主从模式的同步或异步复制来维护相同的状态,比如Mysql,Redis。这两种方式前者较复杂,在一些场景下性能会很低,后者在数据一致性和伸缩性方面有所不足。
如前面提到OpenStack的情况会比较复杂,实际实践中这两种都会糅合使用,另外有两点我们可以姑且不考虑:
1、计算节点,主要涉及到虚拟机的可用性,而虚拟机的可用性实际上是跟上层应用密切相关的(要做到一个虚拟机严格的热备是很困难的,存储容易做到,但是CPU和内存就难了,所以主要还是靠上层应用处理),而且对于上层应用来说可能并不需要,应用可能有基于业务逻辑的容错设计。
2、存储方面,Cinder虽然是OpenStack的存储服务,但是跟Swift不同,打个比喻,Cinder只是一个存储管理器而不是存数据的“硬盘”,真正的“硬盘”是底层的LVM、Ceph、GlusterFS以及其他软件或硬件构成的存储系统等,所以OpenStack在存储方面的高可用更多的是指Cinder这个管理器的高可用性,而数据存储的高可用性已经由底层的存储系统来解决了(比如Ceph)。
综合上述分析OpenStack的高可用,主要是确保控制节点和网络节点的高可用,映射到功能服务维度上,就是确保基础服务(Mysql和Rabbitmq)高可用,Nova,Neutron和Cinder的接入与调度高可用,以及Neutron所创建的DHCP和Virtual Router等虚拟网络设施的高可用。下面逐一进行探讨。
二、OpenStack各层次的HA设计
a) 基础服务Mysql和RabbitMQ
Mysql作为开源DBMS已经是相当成熟了,功能也非常全面,支持多种数据库表引擎,生态完善,但是如果从分布式数据库系统的角度去看,其实还不是很成熟。目前大家用得最多还是基于binlog复制的Master-Slave模式进行数据复制,并基于此做高可用和读写分离等设计。比较好用的方案有MHA。在一主多备的情况下,能够在最少的数据丢失的基础上实现一定的分布式容错与计算。MHA的典型架构如下:
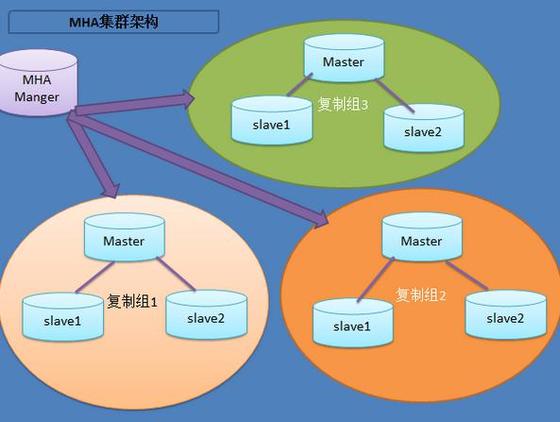
不同于MHA这种上层的HA方案(主要是受限于Mysql基于binlog的replication机制的局限性,在性能和可靠性方面有冲突),在Mysql的MariaDB和Percona分支上,使用兼容innodb的XtraDB引擎,基于Galera集群方式的分布式方案也是越来越收到追捧。虽然复杂度更高,但是分布式实时数据一致性的优势还是非常吸引人的。当然,这种方案有一些功能上的局限性,另外在写少读多的情况下其实相对1-Master-N-Slave架构没有多少优势。基于Galera集群的方案如下:
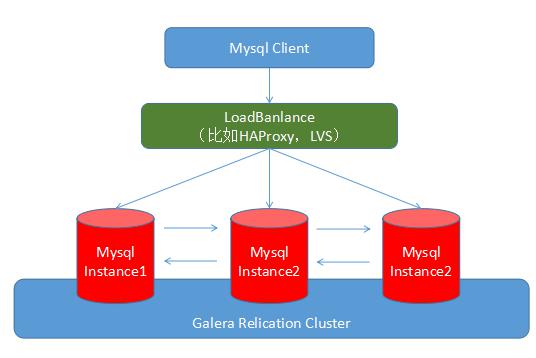
Rabbitmq,在开源的分布式消息队列里面,Rabbitmq算是以稳定可靠而著称,虽然在吞吐量上与Kafka族系的消息队列有一些差距,但是经过调优后还是在同一个数量级。另外Rabbitmq是完全实现AMQP且有一定扩展的,这一点比很多MQ就强不少了,生态系统完善。Rabbitmq基于Erlang构建,后者虽然很小众,但也正因为如此才更显示Rabbitmq的过人之处。
Rabbitmq内置有Cluster集群功能,同一个Cluster的节点会共享topic,exchange,binding和queue等元信息,但是对于真正的queue消息数据是要依赖于Mirror Queue机制来实现消息的HA的,而且组成Cluster建议至少3个节点,否则网络分区发生的时候也不好做决策。所以Cluster+Mirror Queue基本是实现Rabbitmq高可用的最佳方案(在Rabbitmq官网上还介绍了另外一种采取PaceMaker+DRBD的HA方案,但是这种相对来说太麻烦了。Mirror Queue下的消息性能不会太高,毕竟所有分布式一致性协议的性能都不会太高,而且由于消息复制的原因,节点之间的流量会增加不少)
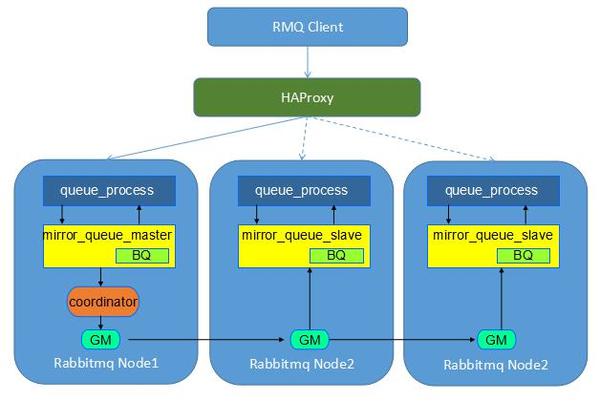
b) Nova、Neutron、Cinder接入与控制服务
解决了基础服务后,对于OpenStack核心的Keystone、Nova-API、Nova-Conductor、Nova-Scheduler、Neutron-Server、Cinder-API、Cinder-Scheduler等,其实都是无状态的,只要多起两个,并且能够做到负载均衡,那么也就基本达成了HA的目标了(这里要注意Nova的调度和Cinder的调度需要进行同步互斥)。考虑到OpenStack的对外API基本是HTTP-RESTful的,所以常见的采用Nginx(或HAProxy)+keepalived(或PaceMaker)来实现这一层次的HA接入。如下图所示:
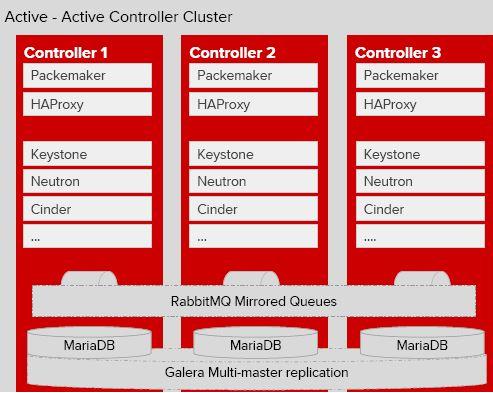
c) 网络服务
在OpenStack中,网络处理占据了相当大的一块,而且由于网络的特殊性与复杂性,一般要独立部署网络节点。网络节点上最核心的就是L3Agent、DHCPAgent以及由它们所管理的DHCP server和Virtual Router服务(先不讨论LBaas,截至OpenStack KILO版本,LBaas其实都还不算很成熟,基于HAproxy的参考实现目前也还没包含内置的HA机制)。
首先看DHCP,由于这个比较简单,就犹如DNS天然是支持多DNS的,所以可以在多个网络节点上部署DHCP Agent来达到多DHCP server并行,且把用户私有网络的DHCP分布在上面就可以了。
对于Router服务,由于涉及到到路由和外网接入,所以这里不能同时运行多个一样的Router服务(地址与路由冲突问题),目前简单的是采取A/P模式来部署。由控制节点上的L3 Router Plugin去对网络节点上的L3 Agent周期性做心跳探测,从而实现L3 Agent的failover机制,当出现故障时迁移Router到新的网络节点上。 这是一种较为保守且简单的方案,但是这种方案会有网络分区的问题,所以仍然还是有可能出现两个L3 Agent同时服务的现象,所以需要人工干预。
从OpenStack Juno版本开始引入了分布式虚拟路由DVR,核心思想是把原来网络节点上的Router服务分布到各个计算节点上去了,只把DHCP和SNAT留在网络节点上。这样就大大增强了Router的容灾能力,而且大大增强了整个集群的东西、南北向通讯能力(突破了网络节点的瓶颈)。OpenStack另外一个孵化项目DragonFlow也实现了类似DVR的功能,只是实现的方式不一样,更符合Neutron本身的插件架构,更具有SDN的味道。无论是DVR还是DragonFlow目前都还不够成熟。综合上面的分析,目前网络服务这块,一个简单稳定的部署方案还是以网络节点的A/P容灾模式以failover方式的网络服务的HA机制。
三、总结
总而言之,OpenStack在整体架构上是可以整合出一套行之有效的HA方案的,较弱的应该是网络上,目前社区也有相当多的努力在进行优化改进,随着后续新版本不断完善,OpenStack的高可用性将不断增强。我们以OpenStack为基础,已经整合构建了具有较高可用性的弹性计算、分布式块存储和虚拟私有网络等IaaS核心功能,后续也将在HA方面不断尝试新的技术,进一步提升服务质量。
作者简介:黄明生,绿星云科技CTO及联合创始人,曾任腾讯基础架构部云平台研发总监,拥有超过十年的大型分布式系统架构、设计与开发经验。2012年后专注云计算领域,对亚马逊公有云AWS、开源云计算平台OpenStack和虚拟化技术LXC、Docker等有较深入的研究。同时对关系数据库、网络应用与优化等方面也有尝试,并带领研发团队服务于腾讯云后台架构获得丰富的实战经验。
|





