|
д��ƪ���µ�Ŀ�ģ���Ҫ�ǰѽ�������ѧϰ��һЩ��������������ͬʱ��Ϊ֮ǰ���¡������ֲܷ�ʽ������洢ϵͳ��Ƹ�Ҫ���IJ�����������Ȼ������ˮƽ�dz����ޣ���ͷ��֮ǰд������Ҳ������㣬�����Ǵ���ϣ��ͬѧ�ǿ����˴�������£�����ӭ�������۲�ָ����
�Ҵ���Ǵ�2010�����ʼ����߲����������ܷ������ͷֲ�ʽ��һ��������о���������Ҳ��������꣬����ʵ�ܶණ����Ȼ��һ֪��⣬�����ᵽ�����������Ҳ���κ�һ���Ҷ����ܽ��ĺ����������Ҫ�������С�������ƽʱ�ڹ�����ѧϰ�У����Ҳֻ�ܴ�����һ֪��ʼ��������ĥ�����ϸĽ���
���ˣ����濪ʼ˵���ǽ���Ҫ��Ƶ�ϵͳ��
���ϵͳ��Ŀ�����ȷ�����ǧ������PV����վ�����һ�����ں�̨�ĸ߲����ķֲ�ʽ����ϵͳ������ϵͳ����ҵ�����Ĵ��������ּ��㡢�洢����־�����ݵȷ������ݣ�������������SNS��������ͣ��ʼ����д������ϲ�������ij�����
��ο��������߲���������Ҫ�����Ұѷ���������ٺ�һ�㣩˵�����ܼ����ǡ��֡�����Ρ��֡�����˵���ǰѲ�ͬ��ҵ��ֲ�ͬ�ķ�������ȥ�ܣ���ֱ��֣�����ͬ��ҵ��ѹ���ֲ�ͬ�ķ�����ȥ�ܣ�ˮƽ��֣�����ʱ�̲�Ҫ���DZ��ݡ���չ�����������������⡣˵�������Ƚϼ�����ƺ�ʵ���������ͻ�Ƚ����ѡ���ǰ�ҵ����£����ǡ��������㡱�ķ�ʽ�����һ��ϵͳ��������Ǿͷ���˳������
�������������������ǵ�����Ӧ����δ洢��ȡ�á���������֮ǰȷ���ġ��֡��ķ�������ȷ������2�㣺
��1�����ǵķֲ�ʽϵͳ������ͬ��ҵ�洢��ͬ�����ݣ���2��ͬ����ҵ��ͬһ������Ӧ�洢��ݣ������еĴ洢�ṩ��д�����еĴ洢ֻ�ṩ����
�ã��Ƚ�������2�㡣���ڣ�1��Ӧ���������⣬����˵��������ϵͳ���������ͼ���������һ��ɽկ�����ذɣ������������ͽС�ɽ�ơ�
���ˣ����¶���ɽ�ƣ�Stwi������ô�����ҹ�ע���ˡ���һ��ҵ������ݣ��϶��͡��ҷ��˵����ġ����ҵ��������Ƿֿ��洢�ģ���ô�������ڰѣ�ÿһ��ҵ������������ݵĴ洢����Ϊһ��group������group�ķ�ʽ�����������ҵ������ݵĴ洢��������˵��2�������������Ѿ�֪�������ݰ�ҵ���group����ȥ��ȡ����ôһ��group������Ӧ������Щ��ɫ�أ���Ȼ�ģ�Ӧ����һ̨��Ҫ�Ļ�������Ϊgroup�ĺ��ģ����dz���ΪGroup
Master���ǵģ����������group����Ҫ���������group�����ݣ���Group Master��Ӧ�ö����ҵ������ж�д�����⣬���ǻ���ҪһЩ������ɫ�����dz�����ΪGroup
Slaves����Щslave������ɶ�����أ����Ǹ���ȥGroup Master�������ݣ����������ֺ���ͬ�������ṩ��������ע���ҵ��ôʣ������������Ժ���͡����������Ѿ�����һ��group�Ļ���������
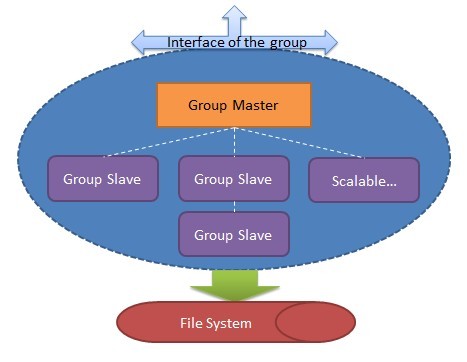
һ��group�ṩ����Ľӿڣ��ϻ�������ô��ȡ���ݣ���group�ĵײ������ʵ�ʵ�File System��������HDFS��Group
Master��Group Slave���Թ���ͬһ��File System�����ڲ��ܶ����ݵ�ǿһ����ϵͳ����Ҳ���Էֱ�ָ��ͬ��File
System��������һ���ԣ�����ͣд�����ϵͳ崻�ʱ�����ݵ�ϵͳ��������֮Ӧ��Ϊ�����File System������״̬����״̬����Group
Master����Group Slave��
������˵һ��group��ι�����ͬ���Ⱥ������⡣���ȣ�һ��group��Group Master��Group
Slave��Ӧ����ǿһ���Ի�����һ���ԣ�����һ���ԣ�Ӧȡ���ھ����ҵ�����������ǵġ�ɽ�ơ���˵��Group
Master��Group Slave����Ҫ��ǿһ���ԣ�����һ���ԣ�����һ���ԣ���������Ҫ��Ϊʲô����Ϊ���ڡ�ɽ�ơ�������һ��Group
Masterд��һ�����ݣ�����һ��Group Slave������һ�������ڡ�����ΪGroup Master�Ѿ�д������Group
Slave��δ���´����ݣ�������ͨ����������������⣬���磬���ڡ�ɽ�ơ��Ϸ���һ�����ģ�����ע�ҵ��ˡ���û�м�ʱͬ���ؿ����ҵ��������ģ���û��̫��Ӱ�죬ֻҪ���Ժ������ܿ������µ����ݼ��ɣ��������ν������һ���ԡ�����Group
Master�ҵ�ʱ��д�����ж�һС��ʱ��������Group Slave�����棬�Ժ�Ҫ�ٽ�������⡣��������Ҫ����ϵͳ����ɽ�ƣ������Ա����ﳵ��֧����һ��ģ���ô��һ���ԣ�����һ���ԣ����������Ҫ��ͬʱд����ҵ�Ҳ�Dz������ܵģ�����������ϵͳ��Ӧ��֤��ǿһ���ԡ�����֤���ܶ�ʧ�κ����ݡ�
���������������ǵġ�ɽ�ơ�Ϊ��������һ��group����������ͬ�������裬��������һ������Ҫдһ�����ݣ�����ֻ��Group
Master��д����ôGroup Master���������д��������д�Ķ��У�Ȼ��Group Master��֪ͨ����Group
Slave������������ݣ�֮��������ݲ�������д��File System����ô���ھ���һ�����⣬�Ƿ�Ӧ������Group
Slave��������������ݣ�����д�ɹ����أ������漰һЩNWR�ĸ��������һ��ȡ�ᣬ��������һ��Group
Slaveͬ���ɹ������ܷ���д����ijɹ�������Ϊʲô�أ���Ϊ������ʱ��Group MasterͻȻ�ҵ��ˣ���ô�������ٿ����ҵ�һ̨Group
Slave���ֺ�Group Master��ȫͬ�������ݲ�����������������ʣ�µġ�������Group Slave�����첽���ظ�����������ݣ�����Ȼ�����������ж����������������ﲻͬ��Group
Slave�ڵ㣬���Ǻܿ��ܶ�����һ�������ݣ���������Щ���ݻ�һ�£���ǰ������������������ȡ�ᣬ�С���ͬ����ģʽ����֮ǰ��˵��ǿһ����ϵͳӦ��ι����أ�����Ȼ������õ�����Group
Slave��ͬ����ɲ��ܷ���д�ɹ�������Group Master���ˣ�û�£�����Group Slave���Ͼ��У����ᶪʧ���ݣ����Ǹ����Ĵ��۾��ǣ��ȴ�ͬ����ʱ�䡣�������ǵ�group�ǿ������������ֲ��ģ���ô�ȴ�����Group
Slaveͬ����ɽ��Ǻܴ��������ս�������ۺϿ��ǣ����˶�ijЩ�ر��ϵͳ�����á�����һ���ԡ��͡���ͬ����������ϵͳ���Ƿ��ϸ߲�������Ӧ������ġ����ң�����һ���dz���Ҫ��ԭ����ͨ�����ϵ������Ƕ�>>д����Ҳ���ǡ�����һ���ԡ����ϵ�Ӧ�ó�����
�ã��������ղ��������ᵽ�����Group Master崻��ҵ������ٿ����ҵ�һ����������ͬ����Group
Slave������������������������Group Slave���������ֺ�Group Masterͬ������ǰ����������ô��������������أ������漰�����ֲ�ʽѡ�١��ĸ����PaxosЭ�飬ͨ���ֲ�ʽѡ�٣������ҵ�һ����ӽ�Group
Master��Group Slave�������������Ӷ���֤ϵͳ�Ŀɳ�����������Ȼ���ڴ˹����У���������һ����ϵͳ����Ȼ����һС��ʱ���д�����жϡ����ڼ������裬���ǵġ�ɽ�ơ��Ѿ�����һЩ��ģ��������ɽ�ơ����ĵ����groupҲ������̨���������������������ֲ�������������ƣ������ĸ������ϵ��������ϣ�������Ӱ�����group������������ֻ�ǻ���һЩС��Ӱ����ѡ�
��ô�������group����ʣ2�����⣬һ�����֪��Group Master�ҵ����أ�������ͼ�������Ѿ�����Group
Slave�ǿ���չ�ģ���ô�¼����Group SlaveӦ���ȥ��͵�����ݴӶ��������ڵ�ͬ���أ���������һ�����ǵķ����������ģ������ṩһ�����ơ��������ķ�����˭�ṩ�أ��������ǽ�������Global
Master�������ó�����group�����нڵ�������Group Master����Group Slave����ͣ�������������������ȥ����һ��֤�飬����Ϊ��һ�������������������ʱ��ģ�����ڡ��������������ڼ��Group
Master����������Ч�ԣ�һ�����ڣ����Group Master�������������������ڲ���������������˵��Group
Master�ҵ���������Group Slave�����õ��������ֲ�ʽѡ�٣����Ӷ�����µ�Group Master���������������ܼ��¼����Group
Slave���ϵء�͵�������ݣ���������������Group Master֪ͨ����£��������������н��ͬ��������Ȼ����͵���������õ�ʱ�䲢���ֹۣ�ͨ����Сʱ����
����������ڴ˷ֲ�ʽϵͳ�У�һ��group����ơ���ô���������������ϵͳ���������֡���ǰ�����������ǵ�ҵ����������groupΪ��λ����Ȼ�ڴ�ϵͳ�н�����many
many��groups��������������վ�ܹ���һ��ҵ�������ǵġ�ɽ�ơ�����ҵ����һ��һ�ѵأ�����ô��˭��������Щgroups�أ���Web�����������ֽ���ε���ָ����group�����ɸ�group�������������أ����������Ҫ���۵����⡣
����������һ���µĽ�ɫ����Global Master������˼�壬���ǹ���ȫ�ֵ�һ���ڵ㣬����Ҫ������¹�������1������ϵͳȫ�����ã�����ȫ�ֿ�����Ϣ����2����ظ���group�Ĺ���״̬���ṩ��������������崻���֪ͨ��group����ֲ�ʽѡ�ٲ����µ�Group
Master����3������Client���״ε���������ҳ��������������group������group����Ϣ��location�����أ�������ͬһ��ǰ������Դ�ĸ���ҵ�������Եڶ�������Ҫ����Global
Master��ѯgroup��Ϣ��������ƣ�����4�����ֺ�Global Slave��ǿһ����ͬ����������������״̬����ȫ�ֵġ�������������֤������״̬��
�������ǽ��ͼ����������������������Ȼ�����ϵͳ�����������Ѿ����֡�
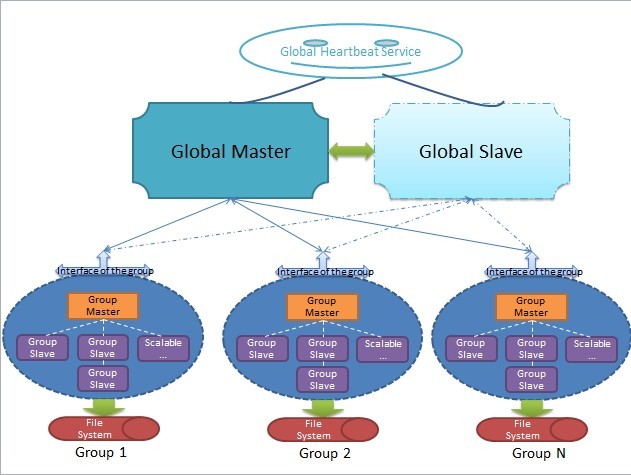
����Ҫ��ȷ���������ǵ�ϵͳ��Ρ��ֲ�ʽ������֮��������һ������Ҫ�Ľڵ㣬����ɳ�Ϊprimary node����ͼ��ʾ�����ǵ�ϵͳ�У�����ڵ��Global
Master��Ҳ������GFS + Bigtable���ĵ�ͬѧ֪������GFS + Bigtable������Ľڵ��Config
Master����Ȼ���Ʋ�һ����������������ȴ��ࡣ�����Ҫ��Global Master����Ϊ��ϵͳ״̬�����ı�־֮һ��ֻҪ����������������ô�������Ա�֤����ϵͳ��״̬�ǻ��������ģ�ʲô��group���������������������ǰ���Ѿ�˵����group�ڻ�ͨ�����ֲ�ʽѡ�١�����֤�Լ����ڵ���������״̬����Ҫ������group�����л������ҵ��ˣ��Ǹ���������Ҫ��������������Global
Master�������ˣ��ҵ��ˣ���ô�죿��Ȼ��ͼ�е�Global Slave�������ó��ˣ���������Ƶ������ɽ�ơ�ϵͳ�У�������һ��Global
Slave����Global Master���֡�ǿһ���ԡ�����ȫͬ������Ȼ������в�ֹһ��Global Slave������Ҳ����Global
Master����ǿһ������ȫͬ���������и��ô�������Global Master�ҵ�������ͣд�����ý��зֲ�ʽѡ�٣�����������������һ��Global
Slave����Global Master�������ɡ������ǿһ�������ĺô�����ô�е�ͬѧ�ͻ��ʣ�Ϊʲô����֮ǰ��group��������ô�㣬��Ҫ��ʲô����һ���ԣ���ʲô�ֲ�ʽѡ�٣�PaxosЭ�����ڼ�����������ʵ�ֵĿӵ�һ�壩�أ��Ҹ����㣬����ѹ����ѹ�������ǵ�ϵͳ�������վ�ǧ��PV���ϵ���վ����ɽ�ơ���������ڼ�PV������ǧ��Ҳ�����ְɣ�����ϵͳ��ѹ����Ҫ�����أ�ϸ�ĵ�ͬѧ�ͻᷢ�֣�ϵͳ��ѹ��������Global
Master����������Global Slave����Ϊ���Ǹ������ṩ���ݵĶ�д�����ǵģ�ϵͳ��ѹ�������ڸ���group������group����Ʋ�����ؼ��ġ�ͬʱ��ϸ�ĵ�ͬѧҲ�����ˣ�����Global
Master��ŵ��Ǹ���group����Ϣ��״̬���������û���ȡ�����ݣ����������½��٣�Ҳ������Ϊ��>>д�����Dz������ģ����ԣ�Global
Slave��Global Master����ǿһ������ȫͬ����������õ�ѡ���������ǵ�ϵͳ��һ̨Global
Master��һ̨Global Slave����ʱ�������������ˡ�
�ã����Ǽ����������Ѿ��˽�Global Master�Ĵ����;����ô��һ������Client�˵�������ε���������ҵ��groupȥ�أ������Global
Master���ṩ���״β�ѯ���������������״�����ָ����groupʱ��ͨ��Global Master�����Ӧ��group����Ϣ���Ժ�Client��ʹ�ø���Ϣֱ�ӳ��Է��ʶ�Ӧ��group���ύ�������group��Ϣ�ѹ��ڻ��Dz���ȷ��group���ܾ�������������Client������Global
Master�����µ�group��Ϣ����Ȼ�����ǵ�ϵͳҪ��Client�˻���group����Ϣ���������ظ�����Global
Master��ѯgroup��Ϣ��������ʵ�����������ÿӵ�������ȥ�������ȣ������Ĺ���ģʽ���������Ddos�������������ͨ��������ȫ�Դ�ʩ�����������group�����յ�����ȷ��Client������ܾ�Ϊ�������Σ������ִ������״Ρ�����ʱ��Global
Master����ֻ�ṩ��ѯgroup��Ϣ�Ķ��������п��ܲ����ظ����ҵ������ԣ��������кܴ���Ż��ռ䣬�Ƚ������뵽�ľ��Dz���DNS���ؾ��⣬��ΪGlobal
Master����Global Slave������ȫͬ��������DNS���ؾ��������Ч�ؽ�����״Ρ���ѯʱGlobal
Master��ѹ�����⣻���ߣ��������ģʽҪ��Client�˻�����Global Master��ѯ�õ���group����Ϣ����һClient��������ô�죿�Ǻǣ����õ��ģ�Client�˵�APIҲ����������Ƶģ�֮�������Webǰ�ˡ�
֮��Ҫ˵�ģ�����ͼ�еġ�Global Heartbeat���������Ǹ�ʲô�����أ�����Ϊ����һ������Global
Master��Global Slave�Ľڵ㣬Global Master����Global Slave����ͣ��Global
Heartbeat������ΪGlobal Master�����Global Master�������������ڸ�����״̬���������õ�����������Global
Slave�滻֮��ԭ����group�ڵġ�������һ��������ͬ���ǣ��˴�Global Master��Global
Slave��ǿһ���Ե���ȫͬ��������Ҫ�ֲ�ʽѡ�١���ͬѧ������Ҫ���ˣ�����Global Heartbeat�ҵ����أ���ֻ�ܸ����㣬����ܲ���������Ϊ��û���κ�ѹ�������ҹҵ��˱����˹���Ԥ����������GFS
+ Bigtable����Global Heartbeat����Lock Service��
���ڽ���������ǵġ�ɽ�ơ�ϵͳ������ǰ����ƪ���̵棬���ǵ�ϵͳ�����Ѿ���������������ʣ�µĹ�������Ҫ����������������ô����ʱ�ų����ǵġ�ɽ�ơ�ϵͳȫò�ˣ�
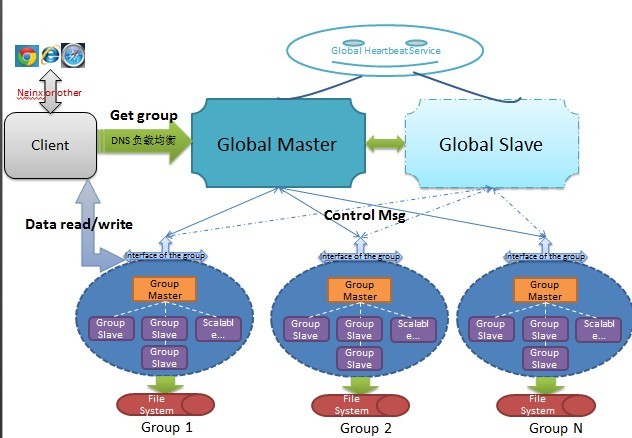
ǰ�憪���˰��죬Ҳ������ͬѧ���IJ������ף����ˣ����ڿ�ʼ��ͼ˵�����ڣ�
��1������ϵͳ��N̨������϶��ɣ�����Global Masterһ̨��Global Slaveһ̨����̨������֮�䱣��ǿһ���Բ���ȫͬ��������Global
Slave��ʱ����Global Master���������DZ�Global Heartbeat��һ̨������������֤��һ��Global
Master����������Global Heartbeat������ѹ����ͨ����Ϊ�䲻�ܹҵ���������ҵ��ˣ�������˹���Ԥ���ָܻ�������
��2������ϵͳ�ɶ��groups�ϳɣ�ÿһ��group������Ӧҵ������ݵĴ�ȡ�����������ݽڵ㣬��������ѹ���ĵط���ÿһ��group��һ��Group
Master��һ�������Group Slave���ɣ�Group Master��Ϊ��group�����ڵ㣬�ṩ����д����Group
Slave��ֻ�ṩ�������ұ�֤��ЩGroup Slave�ڵ��У�������һ����Group Master������ȫͬ����ʣ���Group
Slave��Group Master�ܹ��ﵽ����һ�£�����֮���ԡ���ͬ����ģʽ������֤����һ���ԣ�
��3��ÿһ��group�Ľ���״̬��Global Master��������Global Master��group��������Ϣ������֤��һ��Group
Master������������Group Master崻����ڸ�group��ͨ���ֲ�ʽѡ�ٲ����µ�Group
Master����ԭ��崻��Ļ�����������������Ȼ��һС��ʱ����Ҫ�ж�д�������л��µ�Group Master��
��4��ÿһ��group�ĵײ���ʵ�ʵĴ洢ϵͳ��File system����������״̬�ģ������ɷֲ�ʽѡ�ٲ�����Group
Master������ԭ����File system�ϼ���������
��5��Client���϶˿���Ϊ��Web����Client�ڡ��״Ρ��������ݶ�дʱ����Global Master��ѯ��Ӧ��group��Ϣ�������仺�棬������ֱ������Ӧ��group����ͨ�ţ�Ϊ����������״Ρ���ѯ���Global
Master����Client��Global Master֮������DNS���ؾ��⣬����Global Slave�ֵ����ֲ�ѯ������
��6����Client�Ѿ�ӵ���㹻��group��Ϣʱ������ֱ����groupͨ�Ž��й������Ӷ�������ѹ���������ɸ���group�ֵ��������������Ҫ�Ĺ�����
���ˣ��������ǵġ�ɽ�ơ�ϵͳ�������ˣ�����Ҫ��������ʵ�֣����к�Զ��·Ҫ�ߣ�ϸ֦ĩ�ڵ�����Ҳ�ᱩ¶���ࡣ�����ϵͳ�������ϼ��㣬���д�����Map-Reduce������group�У�ϵͳ��������ӣ���Ϊ��ʱ���⿼�ǵ����ݵĴ洢ͬ�����⣬����Ҳ��Ҫͬ����������������������Ƶġ�ɽ�ơ�ϵͳ����Ҫ�ֲ�ʽָ�꣺
һ���ԣ���ǰ��������Global����ǿһ���ԣ�Group��������һ���ԣ�
�����ԣ�Global������֤��HA���߿����ԣ���Group������֤���������˷����ݴ��ԣ�
����Replication��Global����������ȫͬ����Group�������ǰ�ͬ��ģʽ�������Խ��к�����չ��
���ϻָ�����ǰ��������Global������ȫͬ�������Ͽɲ����ж���slave�ָ���������Group�������÷ֲ�ʽѡ�ٺ�����һ���ԣ�����ʱ�н϶�ʱ���д������Ҫ�жϲ��л���slave��������������ɲ��жϡ�
��������һЩָ�꣬����Ͳ��ٶ�˵�ˡ�����һЩϸ�ڣ���Ҫ��һ�£�����֮ǰ����������ͬѧ�ᵽ��group��master��ʱ����slaveȥ���棬������һ����group����������slave��Ҫ�ֵ�֮ǰ������master�����slave��ѹ�����п��ܼ����ҵ������ѩ������Դ���������ɲ�����������������һ��group�ڣ����ٻ�����һ�������������ݡ���;��slave��ƽʱ����ѹ����ֻͬ�����ݣ������������������ʱ�����ɸñ���slave�������Ϊ��master���Ǹ�slave���Ӷ�����ѩ��ЧӦ����������һ���������µ����⣬���ڱ���slaveƽʱ����ѹ�������뿹ѹ�����Ȼ����һ��������Ǩ�ƣ�����Ǩ��Ҳ��һ�����鷳�����⡣�����õķ�̯ѹ��������һ����Hash�㷨����״Hash�����ɽ��½����������group��Ӱ�콵����С�ij̶ȡ�
���⣬����һ����Ϊ���ֵ����⣬����ϵͳ����־��������Ҫ��ϵͳ崻�����λָ�֮ǰ�IJ�����־���Ƚϳ����ķ����Ƕ���־�����գ�Snapshot���ͻطŵ㣨checkpoint����������Copy-on-write��ʽ���ڽ���־��snapshot�洢��������崻����ҳ���Ӧ�Ļطŵ㲢�ָ�֮���snapshot������ʱ�Կ������µ�д���������������һ�£�������Ҫ����Copy-on-write��ͬ����
�����˵˵ͼ�е�Client���֡���Ȼ���ģ���������Web�Ľӿڣ������������ǵġ�ɽ�ơ�ϵͳ�������������ҵ����������Ҫ�ģ���Ҫ����group����Ϣ����Client��Web֮�䣬������������Nginx֮��ķ���������������ڣ�����һ���������������Ѿ������˱��ĵķ��룬�����DZ��������ǣ�һ���߲��������ܵ���վ�������ܵ�Ҫ���Ǵ���㿪ʼ�ģ���Ϊ��㣬���û����������
���ڣ�������������GFS����ƣ�
�����ԣ���ôţ��ϵͳ������Ʋ������ģ����ǵġ�ɽ�ơ���������ѧϰGFS + Bigtable����Ҫ˼�롣˵���⣬Ҳ������һ�䣬�����������У����ʰڵ��е���ˣ���NWR���ֲ�ʽѡ�٣�Paxos����Copy-on-write�ȣ�����Ȥ��ͬѧ������google�˽⡣��Ϊ˵ʵ�ڵģ���Щ������Ҳû��������ֻ��һ֪��⡣���⣬��ҿɲο�һЩ�ֲ�ʽ��Ŀ����ƣ���Cassandra�������Ա���Oceanbase�ȣ��Լ������⡣ |





