|
这是Go1.1发布后性能提升分析系列的第一篇文章。
Go官方文档(这里和 这里)报告说,用Go1.1重新编译你的代码就可以获得30%-40%的性能提升。对linux/amd64平台而言,有大量的评测可以证明上述性能提升,对linux/386和linux/arm类平台,结果甚至更让人惊讶。但是我暂时持保留意见。
关于gccgo,本系列重点关注提升Go1.1性能的gc系列编译器(5g,6g和8g)。由于和gc编译器共享相同的运行时和标准库,gccgo间接受益于这些改进,但不作为本次基准测试系列的重点。
Go1.1在编译器,运行时和标准库上有许多直接导致程序速度提升的特色改进,尤其是:
代码生成优化。涵盖3个gc编译器,包括更好的寄存器分配,减少不必要的间接加载,减少代码量
内联优化。包括部分内置函数调用的内联,处理接口转换时编译器生成的存根方法的内联。
减少栈使用。进而减轻栈大小的压力,更少分裂栈。
引入并行垃圾收集器。收集器仍然是标记-删除,但是垃圾收集期间可以使用所有的CPU。
更精细的垃圾收集。减少堆的大小,进而获得更低的GC延时
新的运行时调度器。在调度goroutine时做出更好的决策。
调度器和net包整合的更紧密。大幅减少包处理的延时并获得更高的吞吐。
部分运行时和标准库用汇编重写。利用特定的移动或密码指令的优势。
autobench介绍
没有事实依据的不可复现的评测比任何事情都让我不满。由于这个系列要列出大量的数字,给出一些强有力的结论,对我而言,有必要提供一个渠道,大家可以在自己机器上验证我的结果。
为此,我已经建立了一个简单的基于make的工具,用于比较Go1.0和Go1.1在一系列综合基准测试中的性能。它可以运行在任何Go支持的任何平台上。虽然该项目仍处于开发阶段,它已经产生了很多有用的数据。这些数据存放在代码库中。你可以在Github找到这个项目:https://github.com/davecheney/autobench
我要感谢那些从自己机器提交基准测试结果数据的Go社区的成员,这使得我对Go1.1的相对性能做出明智的结论。
如果你对参与autobench感兴趣,很快将有一个记录Go1.1性能的分支产生。
一图胜千言万语
为了更好的展示基准测试结果,AJ Starks 已经开发了一个好用的工具。benchviz 可以将misc/benchcmp枯燥的基于文本的输出转换成漂亮的图表。你可以在AJ的博客上看到所有关于benchviz
的信息。
http://mindchunk.blogspot.com.au/2013/05/visualizing-go-benchmarks-with-benchviz.html
在传统的misc/benchcmp工具之后,对所有的改进,当运行时间的减少,或者吞吐的增加,以条状图的形式向右扩展,反之,向左收缩。
Go1 在linux/amd64平台基准测试
这篇文章的剩余部分将会集中在linux/amd64的性能评测。6g编译器被认为是gc编译器包中的旗舰编译器。除了在前后端的代码生成优化,标准库和运行时的性能敏感部分已经用汇编重写以充分利用SSE2指令。
这篇文章接下来的数据来自此结果文件 linux-amd64-d5666bad617d-vs-e570c2daeaca.txt

Go1基准测试包是一个综合的基准测试,它试图获取真实世界中标准库中的主要包的使用情况。总体上,这个结果支持之前30%-40%性能提升的结论。通过查看提交到autobench库中的结果,很明显GobDecode和Gzip性能有所退步,并且问题
5165 和 5166 都产生了。相对而言,后者的罪魁祸首应该至少部分归于迁移到64位int 。
net/http 基准测试
这一系列的基准测试是从net/http包中抽出来的,它展示了Brad Fitzpatrick
和Dmitry Vyukov以及许多其他人贡献到net和net/http包中的工作。
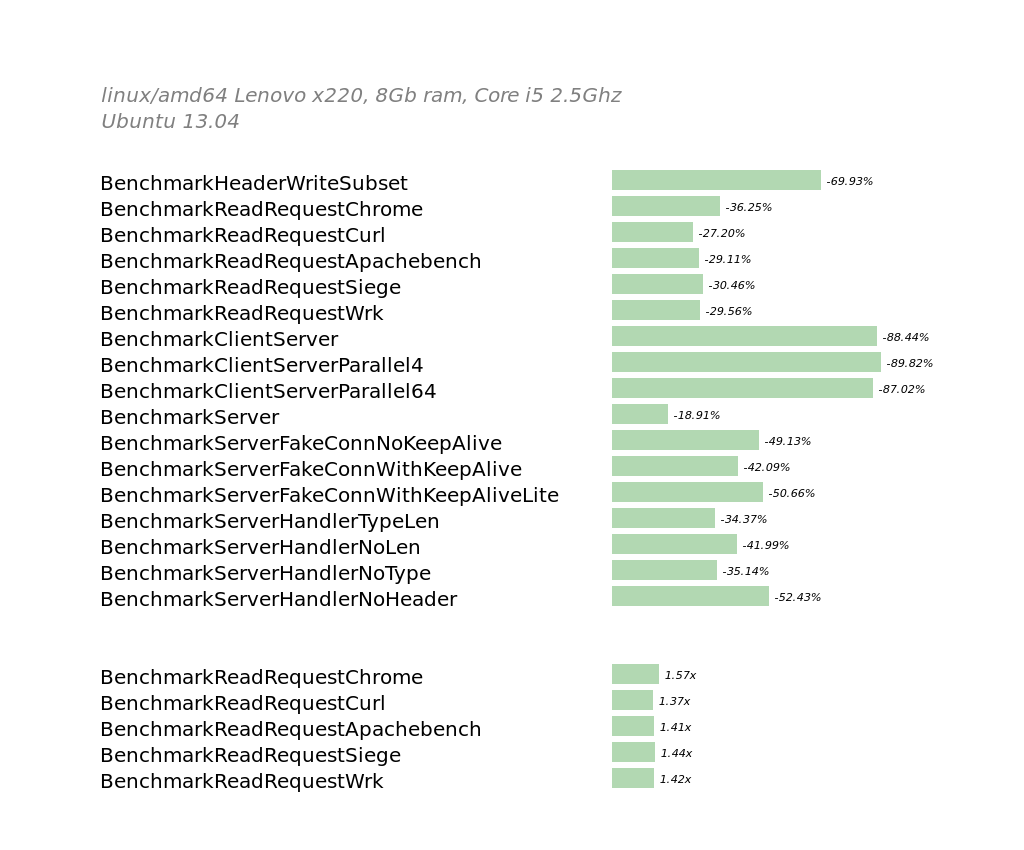
这个系列的基准测试中需要指出的是,ReadRequest(用于解包一个HTTP请求)的性能提升。ClientServerParallel基准测试目前并不能在所有的amd64平台运行,因为部分amd64平台还不支持新的和net聚合的运行时。完成剩余的BSD和Windows平台的支持是1.2周期的重点。
Runtime 微基准测试
在这里展示的最后一个基准测试是从runtime包中抽取的。
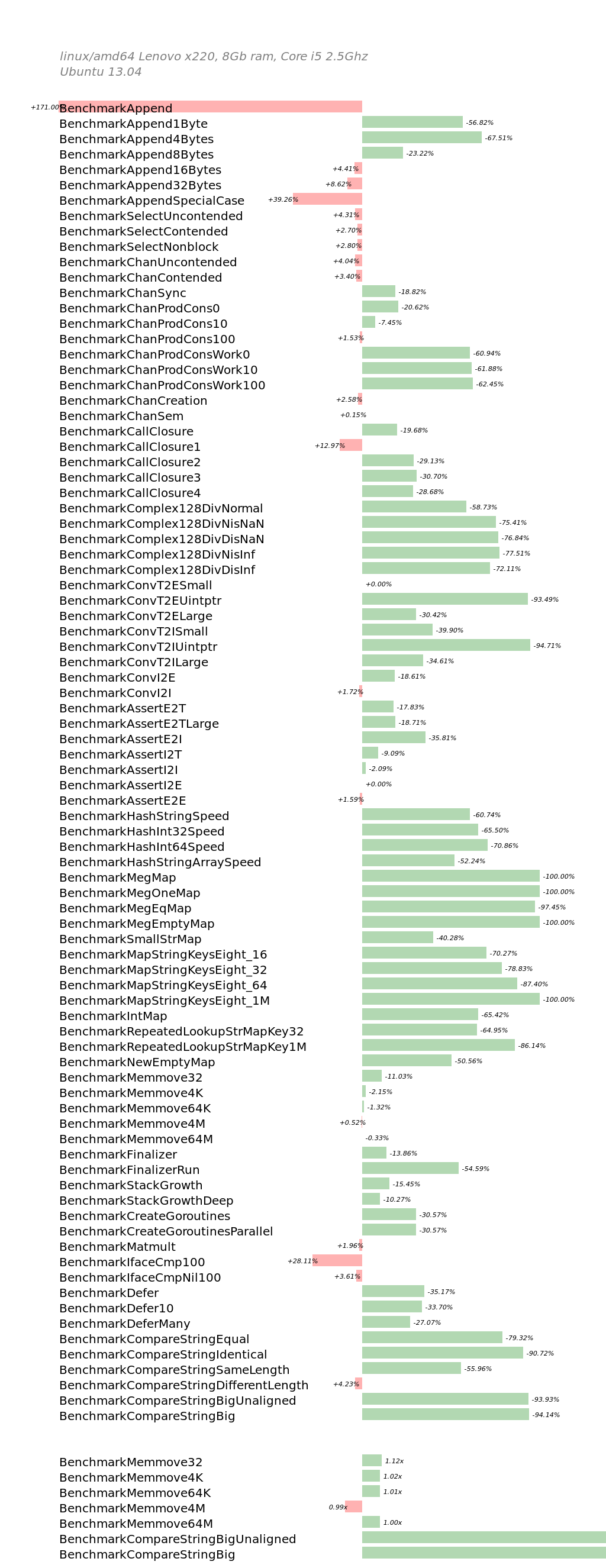
Runtime基准测试展示了runtime包非常低层次部分的微型基准测试。
上面明显的衰退就是第一个Append基准测试。然而在实际时间中,基准测试却从36ns/op提升到100ns/op,这意味着,对于某些append使用场景是存在性能衰退的。这可能已经在建议CL
9360043中指出。
Runtime基准测试中最大的赢家就是惊人的map。新的map代码由khr在issue
3886声明并贡献。包括Channel操作的开销减少(感谢Dmitry的新调度器),涉及complex128操作的优化,以及用64位汇编重写的hash和内存移动操作的提速。
结论
对于运行现代64位intelCPU的linux/amd64平台,6g编译器和运行时可以生成显著高校的代码。其他的amd64平台也有类似的提升,具体的提升程度会有变化。如果你有能力,我鼓励你审阅autobench代码库中的基准测试数据,并提交你自己的结果数据。
在接下来的文章中,我会着重在Go1.1给386和arm平台带来的性能提升。
这是探讨最近发布的Go1.1性能提升三篇系列文章中的第二篇。
在第一篇中,我们探讨了amd64平台上的性能提升,以及所有平台受益于运行时和编译器前端性能优化得到的普遍性能提升。
这篇文章中,我将主要着重于运行在386机器上Go1.1的性能。
Go1 在linux/386平台的基准测试
谈到性能,8g编译器是个短板。386开发模型中,可用的通用寄存器数目较少,及其诡异使用限制对编译和优化带来了很大挑战。然而,这阻挡不了Rémy
Oudompheng在Go1.1开发过程中对8g编译器作出许多重大贡献。
首先,古怪的387浮点数模型被弃用(除非你运行在非常古老的带有GO386=387开关的硬件上),并由SSE2指令取代。
其次,Rémy做了很多努力,从6g迁移了代码生成优化的代码到8g(同时也迁移到了5g,arm编译器)。涉及迁移的代码包括编译器前端、垃圾收集,以及引入了一个将除法重写为简单的移位和乘法操作的框架
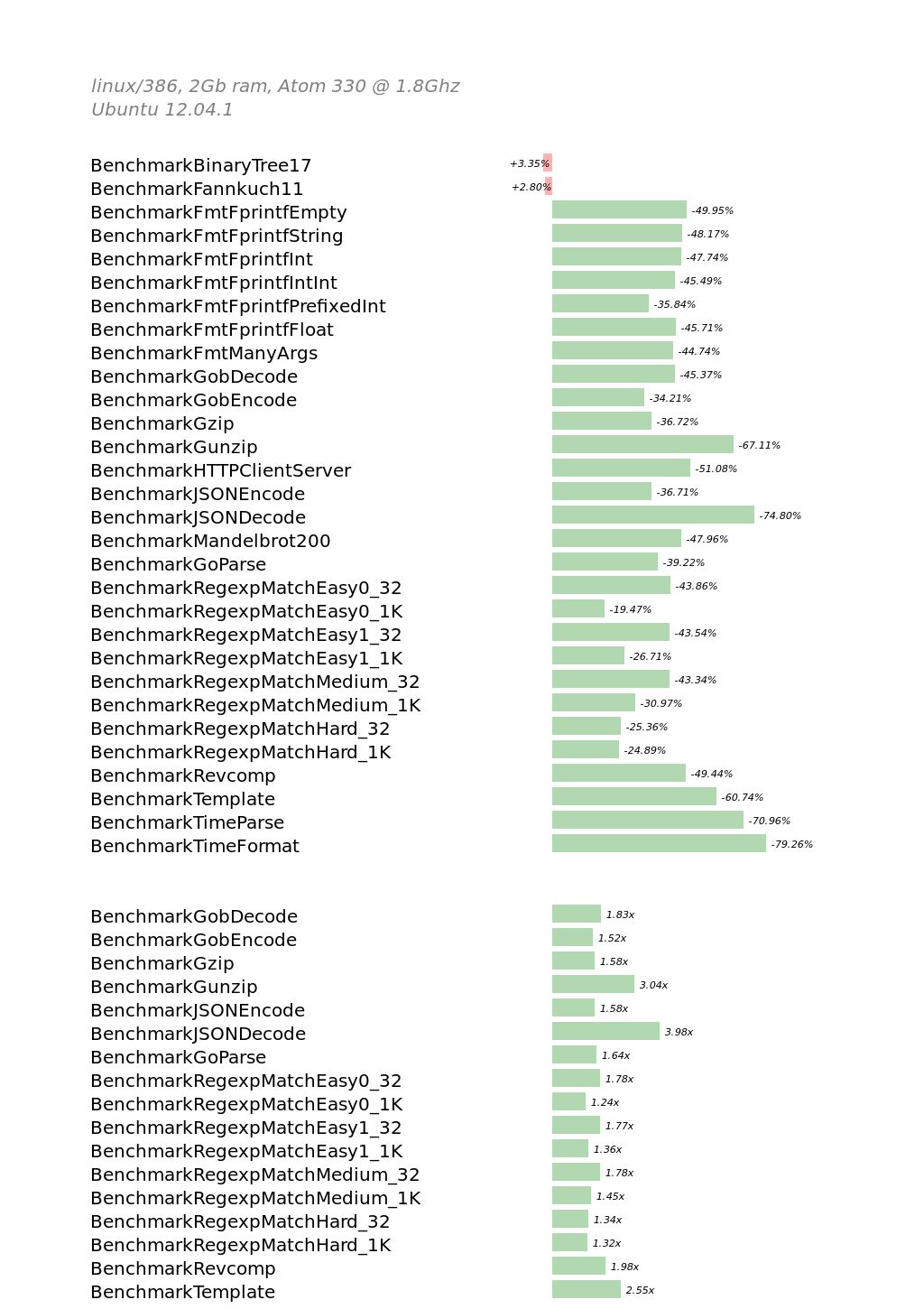
整体上看,这台机器上的linux/386结果显示出了和linux/amd64一样的性能提升,甚至某些基准测试项还超过了后者。然而,和linux/amd64不一样的是,Gzip和Gob基准测试中,linux/386性能没有衰退。
BinaryTree17 和 Fannkuch11这两个测试项轻微地性能衰退,应该是由因为垃圾收集器变得更加精确引起的。垃圾收集器更加精确,引入了一些额外的记账信息来记录分配在堆上的对象的大小和类型,进而反映在以上基准测试中。
net/http 基准测试
之前一篇linux/amd64文章中展示出来的net包中的性能提升在linux/386平台一样存在。ClientServer基准测试的性能提升并没有像amd64那样被标出来,然而,由于运行时和net包结合的更加紧密,整体上仍然表现出显著的性能改善。

Runtime 微基准测试
和第一篇的amd64基准测试一样,runtime微基准测试显示出了有好有坏的结果。一些低层次的操作变的稍微慢一些,同时,其他一些操作,如map,性能有显著提升。
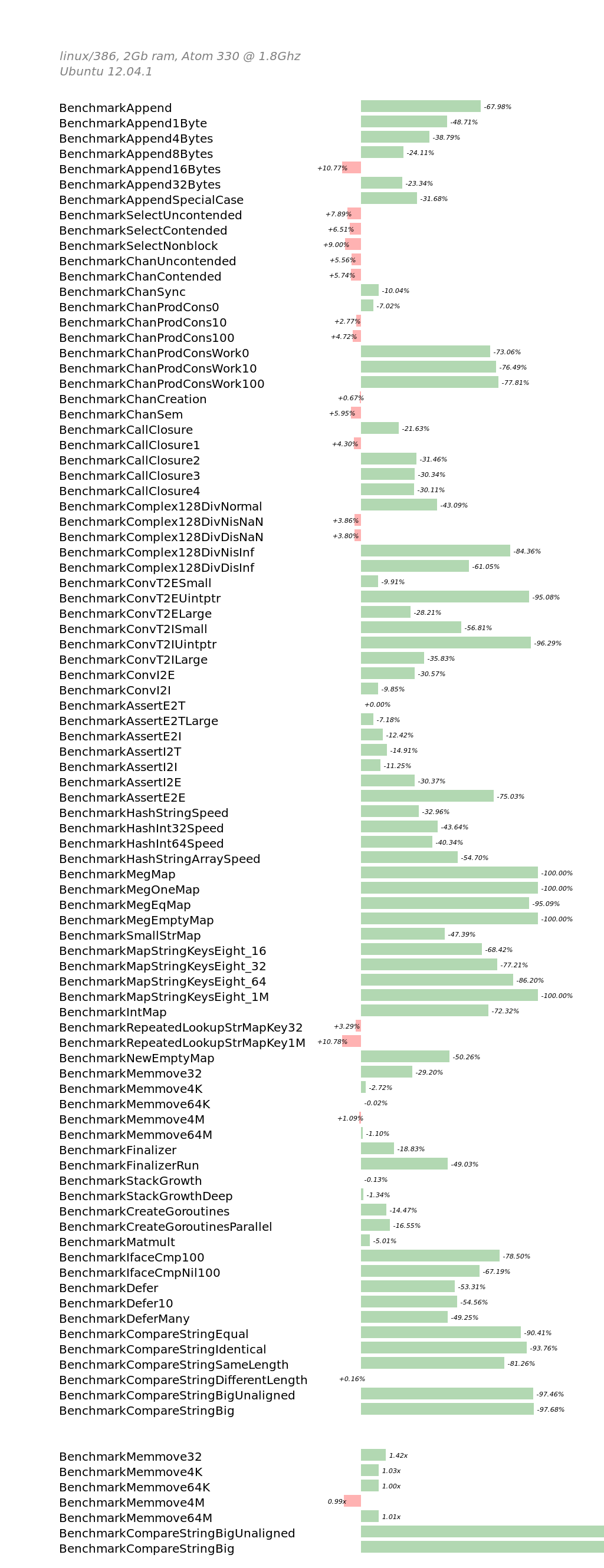
最后这两个基准测试,截断在下面,是因为他们性能提升太多了,屏幕容不下。这个性能提升主要归功于这个变化,其为strings,bytes,runtime包引入了一个更快的低层次的Equals操作。结果不言自明。
benchmark old MB/s new MB/s speedup
BenchmarkCompareStringBigUnaligned 29.08 145.48 39.39x
BenchmarkCompareStringBig 29.09 1253.48 43.09x |
结论
虽然8g不是gc系列编译器中的最好的,(Ken Thompson自己也曾说,386平台基本上没有多余可用的寄存器),linux/386很容易就实现了之前声称的30%-40%的性能提升。甚至在一些基准测试中,相比Go1.0,linux/386打败了linux/amd64
除此之外,由于内存使用的减少,现在所有的编译器在编译时只需要大概之前一半的内存,这样的直接结果就是Go1.1比Go1.0编译速度提高了30%。
我鼓励你去审查autobench代码库中的基准测试数据。如果你有能力,请提交你自己的测试结果。
在这个系列的最后一篇文章中我将关注Go1.1给arm平台带来的性能提升。我向你保证,最后一篇的将是最精彩的。
这是探讨最近发布的Go1.1性能提升系列文章中的最后一篇。你可以阅读第一篇和第二篇了解amd64和386的分析内容。
这篇文章重点关注arm平台的性能。
Go1.1是一次重要的发布,因为这次发布将arm平台提升到和amd64和386平台并列的高度并且开始支持更多的操作系统。
Go1.1给arm平台带来的一些亮点包括:
支持cgo
额外的尝试支持freebsd/arm和netbsd/arm
更好代码生成(目前引入了一个半成品的窥孔优化器),更好的寄存器分配器,以及许多小的减少代码量的改进
支持ARMv6主机,包括Raspberry Pi
GOARM环境变量可选,GOARM的值会基于编译的主机自动确定
内存分配器性能大幅提升。消除了许多之前代价高昂的模拟64位指令
显著提升的软件层除法/模运算
这些改进离不开Shenghou Ma, Rémy Oudompheng和Daniel
Morsing的努力,他们在Go1.1的开发周期中对编译器和运行时作出了巨大贡献。
再一次,非常感谢 Anthony Starks,他帮助我给这篇文章准备了基准测试数据和图片。
Go1 在linux/arm平台的基准测试
由于Go这次发布开始支持不止一种arm架构,在这里展示的是基于很多主机的基准测试数据给出的Go1.1在arm平台上的代表性的性能分析。从左上到右下依次为:
Beaglebone Black, Texas Instruments
AM335x Cortex-A8 ARMv7
Samsung Chromebook, Samsung Exynos 5250
Dual Cortex-A15 ARMv7
QNAP TS-119P, Marvell Kirkwood ARMv5
Raspberry Pi Model B, Broadcom 2835
ARMv6
和以前一样,这里展示的结果数据可以在autobench代码库中获取。点击缩略图可以看大图。
嘿,图片在我在iSteve上无法显示!额,iOS设备对网页内加载的图片大小有限制,我们的图片超过了这个限制。但是,如果你点击加载失败的图片,在单独的新页面图片是完整的。对此不变,我很抱歉

(原图尺寸2500×2500像素,请单击查看大图)
BinaryTree17基准测试的性能提升以及提升幅度没那么大的Fannkuch11基准测试的性能提升,受堆分配器性能的影响。部分堆分配过程会更新存储在64位数中的统计数据,这些统计数据体现在runtime.MemStats中。
在Go1.1的开发周期中,在部分原子符号上的快速工作去除了许多这样的64位操作,这也导致runtime基准测试的性能下降。
net/http基准测试
所有的样例中,net/http基准测试都获益于新的轮询实现和对纯Go语言实现的net/http包的改进。这些工作归功于Brad
Fitzpatrick和Jeff Allen。

(原图尺寸2500×2500像素,请单击查看大图)
runtime基准测试
runtime基准测试的结果和amd64/386平台类似。总体的趋势是性能提升,尤其是在某些例子中,有大幅提升,如map操作。

(原图尺寸2500×5000像素,请单击查看大图)
Append基准测试集中的性能提升受益于Rob Pike提交的改进,这个改进避免在向[]byte添加少量数据时调用runtime.memmove。
在所有样例中都存在的问题是一些channel操作的性能衰退。这可能是由于在arm平台上进行原子操作的代价过于高昂。目前,所有的原子操作都是有runtime包来实现。但将来有可能由对应的编译器直接操作以减少开销。
CompareString 基准测试比其他平台的结果稍差是因为CL 8056043还没有移植到arm平台上。
结论
添加了对cgo的支持,net包的吞吐优化,代码生成和垃圾收集器的优化,Go1.1对在arm平台上写Go程序展示了一个里程碑式的改进。
一句话总结这个系列的文章,显然Go1.1践行了在所有三个支持的平台上整体30-40%的性能提升的承诺。仅从编译器层面考虑,虽然6g仍然是旗舰编译器并且得益于底层最快的硬件,8g和5g相对于去年Go1.0的发布也显示出大幅性能提升。
等等,还有
如果你觉得这个系列的文章还不错,并且想关注Go1.2的进度,我将很快建一个新的autobench分支来追踪Go1.1和tip(Go1.2)。准备好之后我会发布博客和tweet。
由于Go1.2开发窗口已在5月14日打开。Dmitry Vyukov已经提交了内存分配器和垃圾收集器的改进,原子符号的目标是进一步减少GC的开销。Carl
Shapiro也已经开始了精确栈分配空间的收集的工作。
Go1.2的提案还包括一个更好的内存分配器,改进调度器使其可以抢占长时间运行的goroutine(目的是减少GC延迟)
最后,Go1.2已经有了发布时间表。虽然我们不能准确的说那些功能会在或者不会在Go1.2,但是我们能够确定Go1.2应该在2013年年底完成。
|





