|
【编者按】本文作者是 Archanaa Panda ,从 2000 以来一直在软件开发(构架、设计和编程)团队担任 Java / JavaEE 构架师,目前立志于做一个与时俱进的独立的顾问架构师。在本篇文章中,作者通过多个方面为生产环节的日志提供建议和指导,最后还介绍了一个高性能的智能日志技术,帮助大家构建高性能的智能日志框架。
1.摘要
当应用在生产过程中,日志通常处于开发周期的次要位置,但实际上高性能的日志可能成为开发团队的重要生命线。在此我们假设读者已熟悉了各种日志框架,如 Log4j 、 SLF4J 等,所以不再详细介绍,本文旨在为「真实」的生产日志提供指南,检测其对应用质量的影响,同时还为大家介绍了一个被遗忘已久的高性能的智能日志技术。
2.介绍
在为应用搭建架构、设计、开发甚至是提升性能的整个环节中,大家都常常忽略日志的重要性。最后当应用程序一切准备就绪打算部署的时候,会发生什么呢?
糟糕!应用程序已经脱离你的开发环境,它无法运行出你想要的 IDE 平台,而且没有对应的调试器可用,此时你才想起来日志的重要性似乎为时已晚。然后当你费劲地想从一大堆日志中尝试调试出应用哪里出了问题,才发现这个任务不仅仅是艰巨,而且极其无聊、繁琐,还会浪费大量的时间。根据你多年的经验和专业知识来看,这样的做法毫无疑问是大海捞针!再或者你把这个任务分配给下属或运维团队,而这样一份繁琐无比费力不讨好的工作,搁谁身上都会招致抱怨!甚至他们也无功而返,集体抱怨你的失策,你只有让专业架构师和设计师参与进来。
所以,日志应该是生产应用的重要生命线,谁都不应该掉以轻心。当然,众所周知,可以根据需求开启或关闭各种日志的记录级别,市面上知道有多种日志类别和日志框架,如 Log4j 、 Commons Logging 或是 SLF4J ,我们可以直接将日志发到不同目的地,如文件、数据库、 JMS 队列等。
但是我们中有多少人会真正地计划日志呢?又有多少人理解日志是如何影响系统质量的呢?谁又会不断地去优化日志,时刻记得一旦应用上线,日志会对系统和工作生活产生哪些影响?还有多少人已经尝试过利用日志框架的先进功能来提升日志性能呢?
本文主要想唤醒大家对应用日志的重视,同时为部署应用日志提供基本指导。最后,本文会介绍一个被遗忘已久的日志技术,在不影响应用性能和质量的前提下,帮助大家实现高质量的日志记录。
3.记录其他系统质量属性
3.1.1监控
日志记录是最常见的质量监控方式,它可以帮助应用开发者探究到问题的根源。但这些往往只通过监控来实现,对于开发者来说,在代码的各个地方编写一个 System.out.println() 或 logger.log() 语句再简单不过。然而,问题在于大量的日志可能会导致有用的事件日志被忽略掉,这样完全达不到日志记录的目的。所以,开发者可能会寻找其他系统监控技术,如使用或开发 JMX 控制台。这一点会在后面的 「为待生产的应用进行日志记录」章节中详细讨论。
3.1.2 性能
不管咨询哪位性能专家或架构师,对于 90% 的应用来说,过多的日志记录都会对性能产生非常不利的影响。日志是一种 I/O 密集型活动,的确会对应用性能产生不良影响,特别是传统的日志方式还会写入应用线程环境的 FileAppender 中。不仅如此,日志代码还会造成大量的堆消耗和垃圾收集,比如:
if (logger.isDebugEnabled())
logger.debug("name "+person.name+" age "+person.age+" address "+person.address); |
除此之外,内部调用日志到 Log4J Appender 的 doappend() 方法,会与线程安全同步。这也意味着,应用线程不仅在同步地进行大量的磁盘 I/O 操作,还会在写入日志时互相阻塞!在某电子政务门户网站上最严峻的性能情形之一就是,线程转储显示在日志记录写入到单个文件 appender 时,应用日志也被写入到这个的 appender 文件集中!

事实上,性能专家首先会确定应用的当前日志级别,然后通常只是把日志级别从 DEBUG 切换 INFO 或 WARNING 模式,来达到提升应用性能的目的。但是,在完成性能基准测试工作或即时可伸缩问题之后,应用开发者在寻找应用功能性 bug 的根本原因时,又会将日志级别改回到 DEBUG 模式。事实上,这并不是一个科学的日志操作。在「为待生产的应用进行日志记录」中,我们还会进一步讨论日志规范和卫生维护。「高性能质量的日志记录」中也会详细阐述在不影响应用性能的前提下能够实现质量记录的相关技术。
3.1.3安全性(审核和其他敏感信息)
审核日志是一类特殊的日志,主要用于应用的安全审核和跟踪用户操作。以下示例主要介绍了日志在安全性方面的帮助。
但是,如果走向另一个极端,日志中携带的敏感信息,如用户的帐户密码,可能会暴露系统漏洞。
第三,记录应用程序的事件和流程可能有助于开发者监控和调试,但同时可能会无意地暴露应用的内部架构。
在当前的云应用环境中,应用可以在公共云上托管,这样的漏洞会对应用所有者的知识产权构成威胁。
3.1.4可扩展性和高可用性
日志记录会和扩展性、高可用性之间互相影响。利用「高性能质量的日志」技术来提高应用性能,用更少的硬件提高扩展性和可用性,在现有的资源和条件下,你的应用完全可以「重拳出击」。
当应用被扩展成能够对可用性进行主动或被动配置时,就会有多个应用实例,而日志策略就显得非常重要。应用是否能支持,或者开发团队是愿意收集来自10个不同机器或目录的日志,还是找一个位置能集中收集日志呢?此时,集中的分布式日志变得至关重要。
3.1.5可恢复性
像如 Oracle 这样的重要数据库,已经使用 Redo 日志来确保事务恢复。应用也可以参考这种做法,使用一类特殊的日志帮助恢复,以防万一。
3.1.6错误处理和容错
在大多数应用中,日志只是其中一种错误处理方式,有时只用来评估错误。在复发性错误,如短信/邮件服务器或数据库长期不可用的情况下,重复地、频繁地记录错误是百害而无一利,特别在大量的异常堆栈跟踪下,只会大大地增加 I/O 活动。在这个过程中,当你要分析一个星期前被忽略的老问题时,这时候关于这个问题的日志早已滚动更新,这种方法只会「火上浇油」。
3.1.7容量
在考虑应用的容量问题时,架构师会参考生产环节的日志大小,再估计所需的磁盘空间、集中文件系统的配置等。
对于分布式环境中的集中式日志,也需要估计分布在网络到远程机器的日志对象的大小。
4.缺少重要日志的案例分析
本节主要介绍作者对嵌入式应用案例的研究经验,如果在架构、设计和开发阶段忽略了日志记录的重要性,问题一旦发生,之前所做的一切可能功亏一篑,只得在惨痛的教训面前学着「吃一堑,长一智」。
举一个大家都熟悉的场景, GPS 设备就是一个嵌入式应用,装载在车中可以进行位置跟踪。该设备不提供任何用户界面,除了 LEDs 和几个按钮,所以几乎没有人来管理车辆内部的应用程序,不像豪华车型那样会和服务器端应用进行交互。因此,如果设备应用出现了问题,应用开发者应该如何诊断问题根源呢?随着各种卡车被运往全国各地,日志又是何时写入车内设备的呢?
应用开发者可能会异想天开,全国各地都配备了服务工程师,能够取下设备带回去进一步分析。以上设想纯属虚构,实际上,开发者只会和服务工程师登入设备的操作系统去复制日志。但面对繁杂的日志,连续的加班作战只会让人身心疲惫!
为了更方便地完成这项工作,应用开发者在设备的桌面服务应用中加上「日志下载」按钮。服务工程师就可以直接利用笔记本里的服务应用下载相关的设备日志。这至少是一个进步,至少不必再让车停下来再取走设备了,也给了本该陪同服务工程师夜以继日下载日志的可怜开发者们一丝喘息的空间。显然,服务工程师也不至于全世界乱跑了,他们只要盯着应用开发团队注意下载日志即可。
最后,开发团队不得不提高设备应用的性能,让它像发送其他跟踪数据一样,直接通过无线 GPRS 就可以发送日志到后端服务器。
需要注意是,在初始的预估和开发过程中,所有这些额外工作都没有被计入需求池或预算中。开发团队已经有一个典型的由客户功能需求驱动的思维定势。应用日志既不是一个客户驱动的需求,也并非是突出的非功能属性。所以新手开发者通常缺乏远见,也无力说服高层或管理者给他们足够的时间预算来建立这样的设施。当这些设备准备上市时,他们遇到了这样的问题,经理和客户气得脸红脖子粗,而他们不得不挑灯夜战。真是一个费力不讨好的活儿!
5.为待生产的应用进行日志记录
在上一节「记录其他系统质量属性」中,我们已经遇到了一些在生产环境中不得不面临的问题。接下来在本节中,我们再罗列出哪些该做和哪些不该做,为应用的待生产状态做准备。
日志规范极其重要,因为这一步将为本文讨论的其他最佳实践铺平道路。事实上,许多生产系统还会有那些无聊的日志,如 「 Hi 」 、 「 Came over here 」、「 Done 」、「 xxxyyyyzzzz 」。这些日志通常会在应用调试阶段或开发阶段的单元测试中产生。
但生产阶段还有人仍然采用这样的无聊日志,其给出的理由是它们只会在调试时产生,而且便于关闭。但是,在实践中开发者很少这样做,关闭的同时也关掉了一些有价值的日志。为了更好地控制日志,需要开发者非常精细地配置日志框架,但在生产中却常常忽略这一点
同时,代码审查必须提高效率。当高级开发者或团队领导审查日志时,必须确保删除掉无用的日志,即使要面对一些挑衅的言论,比如有人说「我已经在测试时删过日志了」,「不就是个日志么!它又不是引发问题的原因」。但这是一个很好的规则,日志并不是开发过程中用来调试问题的方式,负责调试的是我们 IDE 的调试器!
应用日志写入应用服务器的 SystemOut 或 SystemError 文件显示不是最高效的办法,但在生产环境中仍然常见,或如前所述,电子政务门户的线程互相阻塞,共同争夺一个 FileAppender 或者一个文件 I/O 。
最起码,开发者应该将有基于软件包或完全限定类为已有的记录器命名约定,并可能将不同的日志分类记录到不同的 Appender 位置。
在生产过程中,应该牢记日志级别应该是 WARNING 或根据日志信息设为 INFO 级别。
一个有效的方法是在中央配置或常量类中,列举出所有可能的日志,并只允许开发者使用这些日志。我们将在「设计高性能的智能日志」章节中进行讨论。
几乎所有的服务器端应用都必须采用集群和分布式环境,因为这两种技术可以提供可扩展性和可用性。在集群环境中,日志应该反映出组件、模块、子系统以及其过程实例。
在分布式和集群的环境采用集中的日志服务器,可以避免从多个目录和机器上收集日志的繁琐。同时,对于移动 I/O 到一个单独的机器上也更加方便,而应用性能可以不再受日志 I/O 的影响。
在「缺少重要日志的案例分析」章节中的趣闻中也提道,在厚客户端或嵌入式应用的日志几乎不会发送给到开发团队,也无从帮助他们进行问题分析。远程传输日志的机制需要再深思熟虑,再适当地列入项目计划进行开发。
Log4j 的映射诊断环境( MDC )和嵌套诊断环境( NDC )使用 ThreadLocal 储存环境特定信息。它们可以存储如用户名、事务 ID 这样的信息,来识别特定用户或事务所做的全部操作。这就不需要为了日志记录,在类和方法中传递特定环境信息。利用 PatternLayout 的 %X 或 X { key } ,存储的值将在日志中呈现。
这包括规划日志滚动更新之前的日志文件大小和最大数量。为什么需要规划呢?因为日志文件常常大到用文本编辑器都打不开!正如脚本会定期对数据库进行备份一样,也应该有脚本来备份和归档日志。当超出磁盘空间限制时,压缩日志文件也是不错的想法,这样远程传输起来会更加容易。
获取位置信息常常以昂贵的性能损失为代价,因为日志框架试图确定当前的线程堆栈,从而获得该方法、文件名和行数。确切地说,日志信息本身就可以通过提供服务器、子系统、模块、组件、线程等信息找出日志的来源。
如果可能的话,日志中应该有足够的信息显示错误发生的位置,并尽可能避免巨大的堆栈跟踪。当然,这不是一个像 NullPointerException 那样的特例。但它可以为一些容易识别的特定应用错误进行记录。此外,当经常性问题长期发生时,如与 Email 、短信或数据库服务器的连接问题,日志记录也会每隔5分钟地记录该问题,而不是每隔几秒就用巨大的堆栈跟踪填充日志。
对于新手来说,最基本的 AOP 教材案例就是日志。因为日志本身就是一个横切关注点,新手可以在进入方法之前或退出方法之后注入日志。在应用于生产有价值的应用之前,应该严肃地考虑这个示例或观点。对于以上已经建立的示例,日志记录可不是一件小事,它值得像大多数其他非功能性需求( NFRs )一样进行详细布局规划。
最滑稽地使用日志记录的典型案例之一就是「性能日志」,如下所示:
19 Sept 2010 10:20:30 PERF INFO Thread-25 OrderInsertAction.
java Time taken in processing OrderInsertAction: 50ms
19 Sept 2010 10:20:33 PERF INFO Thread-8 OrderInsertDao.java Time taken in insert 30ms |
笔者就曾犯过这样的问题,却没意识到它增加 I/O 对性能产生的严重危害。
更明智的做法是捕获 「 TimeStatistic 」 的总时间,并用计数器算出用 GUI 屏幕显示同样内容的平均时间、最长时间、最短时间。
6.设计高性能的智能日志
在这一节中主要讨论的策略是将集中式日志包装成记录器,日志采用整数编码而不是字符串。这项技术已经由作者在导师的建议下成功地实现。
目前在网上有许多文章都介绍如何用 JMS 队列和主题或 sockets 来构建集中式日志记录。集中式日志记录能够通过移动 I/O 活动到不同的机器上进一步提高性能,虽然会对程序节点有轻微的开销。
但是,这里的关键是结合代码来记录集中式日志,而非冗长的字符串。现有框架 Log4J 或者 Commons Logging 鼓励使用字符串来记录信息,这样的作法会对内存、磁盘和网络资源造成一定影响,而这些工作完全可以通过一段简单的代码搞定。
一个单独的文件可以列出错误代码和可识别字符串之间的映射。
如以下日志记录:
[090822 16:02:48] TX WARNING (Tx-2-thread-1: 1163 transmitData):
Server has not responded with an ACK, so trying again. |
与下面的日志进行对比
1300604499194,4,192168001002,20600,1001,2,500000 |
以上日志显示了长时间戳、日志级别、生成日志的机器IP地址、处理的整数值、处理模块、应用的实例ID和一个完整的错误代码,代码翻译过来也会传达相同的含义。这种对象非常便于在网络中以二进制格式进行传输。如果有上下文信息能进一步限定日志中的信息,一个 Object[] 数组也可以被传递,而主错误代码将转化成为带有 printf() 格式占位符的字符串。
使用短码表示错误的做法,几乎在所有的主流产品中都很常见,如 Oracle 、 WebSphere 、 Microsoft 。例如,在微软的 Office 应用出现错误时,所反馈的错误对话框就是一个难以读懂的整数代码,然后会发送给微软用于诊断。
在查看错误时,可以将各种错误代码翻译成完整的字符串进一步解读。这样做的好处有如下几点:
- 避免构造或传输长字符串,进一步减少内存使用。
- 网络传输中日志是非常轻量的,所以在调试日志时也尽可能保持最小开销。
- 防止日志随机构造
- 通过自定制工具更高效地搜索特定错误
此外,通过防止直接使用 Log4J 或其他类似的框架可以执行日志记录,或者在你最喜欢的日志框架上或自定制日志上编写一个定制格式,比如:
public class LogClientFacade {
public void log(int logLevel, int instanceId, int subsystemId, int componentId, int errorCode);
public void logWithContext(int logLevel, int instanceId, int subsystemId, int componentId, int errorCode, Object[] contextInfo);
public void logWithEx(int logLevel, int instanceId, int subsystemId, int componentId, int errorCode, Throwable ex);
...
} |
这样的日志接口能确保开发者注意到在分布式环境下诊断日志的基本信息,比如子系统、部件或其他,不必在在实时操作中记录源代码的行号和文件名。
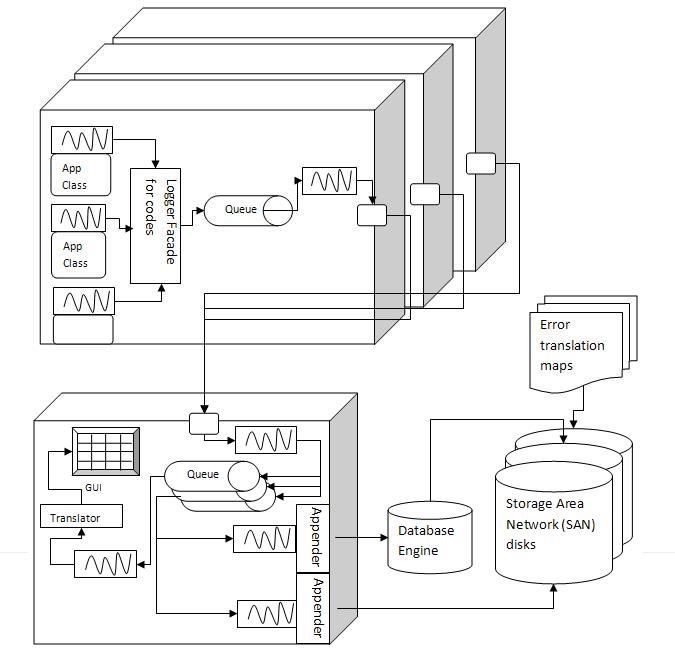
上图显示了一种解决方案的建议设计。其目的是通过在队列和异步处理中收集信息,或在接收器线程中进行转移,尽量确保日志的处理过程不存在阻塞。这种方式在网络传输过程中,以二进制序列化格式进行信息传输具有诸多优势,特别是完整的解决方案是同步地使用同一语言时。
当他们倒进服务器查看离线日志时,应该有一个简单的图形用户界面来观看日志。然后用一个翻译机将日志转换为文本格式,而日志本身也会以二进制格式写入磁盘。需要注意的是,这种方法能和云环境很好地关联,从而确保部署的知识产权的保密性。
6.1A 注意实施
扩展现有框架也是一种好方法,如 Log4J 、 Commons Logging 、 SLF4J 。但是,这样做的话,为了遵循框架内部API的通用性,可能会牺牲一部分效率。例如, Log4J 会序列化日志消息,而堆栈跟踪会作为字符串在 SocketAppender 和 JMSAppender 中进行网络传递。该框架相当易于扩展,而且能覆盖所选择框架的特定部分,如通过添加或扩展新的 Appenders ,扩展内部的数据传输对象,如 LoggingEvent ,并进行自定义序列化。再者,如果需要最大的灵活性,你可以仅用较短的时间来创建一个简单的自定义日志框架。
另一个有趣的决定是在应用运行在服务器时是否使用 JMS ,或者通过使用一个独立队列,如 WebSphereMQ 、HornetQ 或 ActiveMQ 。如果选择 JMS ,以下是作者的几点建议:
- 使用宽松质量属性来避免增加事务、持续性并允许队列重复。记住,严格可靠性会降低性能,对日志而言这是不必要的。
- 在一个 JVM 中,要么是在日志服务器或在客户子系统,最好是使用轻量的 java.util.concurrent 队列或 in-VM 队列实现,从而避免系列化开销。
- 建议使用消息代理或运输桥梁,而不是用一个集中式队列,并做相同的远程调用。
本人的个人偏好是使用简单的 socket。
7.总结
在这篇文章中,我们已经讨论了最佳实践和日志记录中所发现的弊端。我们还提出了一种结合集中式日志和代码的技术,从而取代字符串实现高性能的智能日志实践。
作者将构思高性能智能日志的设计归功于她的导师Akash Gupt先生,是 InterGlobe 科技公司的解决方案架构师,在他的指导下,作者成功地实施并观察到这种技术的巨大性能优势。
8.引用
Pro Apache Log4J by Samudra Gupta
Log4J Source code
|





