|
PostgreSQL��������
�в���ͬѧϣ���˽�PostgreSQL�ı���������MySQL�ĶԱȽ���������ڴˆ������䣬����Ȥ��ͬѧ���Ե������ҷ�E-Mail���ҿ��Է�����ϸ�Ľ��ܼ�һЩ�ԱȽ����
2015����PostgreSQL��ʽ���й���һ�꣬���ǿ���Խ��Խ�����ҵѡ����PostgreSQL��
�й��ƶ�����ʹ��PostgreSQLʵ�ֲַ�ʽ���ݿ�ܹ���
����ҵ����ƽ��������ȷ��ʾ��ʹ��PostgreSQL��Ϊ��һ�����ݿ��ѡ�͡�
��Ϊ���˷���PostgreSQL�ں��о����顣
��������ʽ�ṩPostgreSQL����
�����˽�MySQLӦ�ö��Ǵ�2005�����ҿ�ʼ����ʱ�ڻ�����������LAMP��ǰ���١���������֪�����ǣ���ʱPostgreSQL�ѷ�չ�˽�30�꣬�����Ѿ�����40�ꡣ1973��MichaelStonebraker��2014��ͼ�齱�������ڲ�������У�з��˵�ǰȫ������Ҫ�Ĺ�ϵ�����ݿ�ʵ�֣�Ingres���˺�½������ΪPostgres��Postgres95��ֱ�����ڵ�PostgreSQL��PostgreSQL���ڶ������Ʒ�Ʋ�Ʒ������ͬLinux��RedHat��SUSE��Ubuntuһ������ǰ�����ڶ���������ݿⶼ�ǻ���PostgreSQL���п����ģ�ͬʱ������֪�������OLAP������Greenplum���ݿ⣬��EnterpriseDB��˾�߶ȼ���Oracle���PPAS���ݿ�Ҳ�ǻ���PostgreSQLʵ�֡�
PostgreSQL��MySQL��ȹ��ܸ�Ϊ���ƣ�ͬʱ���ڽ��и���SQL��ѯʱ���ر��Ƕ������JOIN��ѯ�����ܼ��ȶ���Ҳ��Ϊ���㣬�ǹ�����ҵ��ѡ��Ӧ���ں���ҵ��ϵͳ�Ŀ�ԴOLTPҵ���ϵ�����ݿ����档PostgreSQL����Ϊȫ�����Ƚ��Ŀ�Դ���ݿ⣬֧��NoSQL
JSON�������͡�������Ϣ����PostGIS���ḻ�Ĵ洢���̲���������ʵ�ֻ���Tuple����PostgreSQL�д˵�λ��Block��ҪС�������StreamingReplication����ͬ����
��MySQL��ͬ��PostgreSQL��֧�ֶ��������档��֧��Extension������䣬�Լ�ͨ����ΪFDW�ļ�����Oracle��Hadoop��MongoDB��SQLServer��Excel��CSV�ļ�����Ϊ�ⲿ�����ж�д��������ˣ�����Ϊ���������ϵ�����ݿ��ṩ���öԽӡ�
��PostgreSQL�����ʵ�����ݸ��Ƽ�����HA�߿��ü�Ⱥ
ҵ�����������ݿ��HAʵ�ֶ��ǻ��ڹ����洢��ʽ�ģ�����ͼ���������ʽ�£����ݿ�1��1����ʹ��һ�������洢�������ݡ�

����������������Ӵ洢��VIP����������ҵ������������Զ���ڷ�����״̬��ֻ�е�������ֹ��Ϻ���Ż���д洢��VIP�Ľӹܡ�����ͳ����ҵ�У������Ľṹ�ȱȽ��ǣ����ҽ��밢����֮ǰ������Ĵ������ҵ��ʹ�������ļܹ�������Oracle
RAC��DB2�IJ��з�����������������Oracle��MySQL��SQLServer�����ǽ�����������˵��������Postgres�����Ѿ�֧�ֻ������ݿ�ײ��StreamingReplicationģʽʵ�����ݸ����ˣ�ͬʱ֧�ֱ�����Ϊֻ���������ṩҵ�������ˣ�������Դ������ҵ��˵�Ǽ�����˷ѡ�
��ͳ��HA������ʵ�ֻ���Streaming Replication��ʽʱ��������Ҫͨ��������Ϊ���ƵĽű������жϺͿ��ơ�2006�굽2011�꣬��Ϊ��ͬ�Ŀͻ�����ͬ�����ݿ��д�˶������ƵĽű������еİ�װ���ü�ά���Ѷȶ��е���������ȴ����2011�꣬����SUSEϵͳ��HA֧�ֹ����нӴ�����Corosync
+Pacemaker��HA�ṹ�������� ��Master-Slaveģʽ���������ģʽ�£�ϵͳ֧��promote��demote���Խ�����ݿ����Streaming
Replication����ģʽ���л����⡣
Corosync + Pacemaker MS ģʽ����
���ν�����Ҫ��Լܹ������ģʽ�Ĵ���ԭ������������Ҫ�˽��������÷�ʽ�����Ա��ν�����Ҫ��Լܹ������ģʽ�Ĵ���ԭ������������Ҫ�˽��������÷�ʽ�����Բο�http://clusterlabs.org/wiki/PgSQL_Replicated_Cluster��ͬʱ����ǰ���µ�Red
Hat Enterprise Linux 7��SUSE Linux Enterprise Server
11/12�е�HA��������ڴ˼ܹ�����Ҳ����ͨ�����̵Ĺٷ��ĵ���ٷ�����֧�ֵõ����õ���ϸ˵����

��ͼ��3�����Σ�0.x���Σ��������ݿ����ҵ��1.X���Σ�����Pacemaker����ͨѶ��2.X���Σ��������ݿ�����ݸ��ơ�ͬʱ�ṩ�����д����VIP1
192.168.0.3�ͱ���ֻ������VIP2 192.168.2.3���û�����Ӧ�ó������ͨ��VIP1���ж�д��������ֻ����������ͨ��VIP2ʵ�֡�

��ͼ�У�������������е�ģʽ�����ж�д����ͨ��VIP1���뵽Master�ڵ㣻Slave�ڵ�Ļ����ӵ�VIP2��ͨ����IP֧��ֻ��������Streaming
Replicationͨ��eth2�������ڵ������ͬ�����ұ���Master����ʱ��ģʽ��ԭSlave��promote��ΪMaster�ڵ㣻VIP1�л���node2�����ṩ����VIP2�л���node2�����ṩ����
�ڴ˴���ϵͳ��node1�л���node2�ж��ֿ����ԡ�
1. Master�ڵ�ͨ��pacemaker������Ϊ����Switchover�л����������������ģʽ����е��������ҹ����п��Ա�֤����Master�ڵ��е����ݻḴ�Ƶ�Slave���ٽ���node2�ϵ�promote��������ˣ����ݿ������е������������ģ��Ҳ�������κ����ݶ�ʧ����������������Ӳ����Ҫ��������ά��ʱ��
2. Master�ڵ�������ֹ���ʱ��������Failover������PostgreSQL��˫�ڵ��Ƽ�ʹ�õ���asyncģʽ��������Master�ڵ����ʱ��������û���ü����Ƶ�Slave����Щ���ݽ���ʧ��������PostgreSQL��Streaming
Replication��������Ϊ��λ�ģ�������ݿ������һ�����ǿ��Եõ����ϵģ����Բ�����ֱ�����ij������ֻ�ָ���һ��������
��ǰ��һ���Ƚ����ص����⣬��������ͼ��ʾ���л���node1�����Ҫ���³�Ϊ���ڵ㣬����Ҫ���½���ȫ�������ݸ��ƻָ���������ΪMaster����ʱ���������û���Ƶ�Slave��Master�����һ������ʱ�佫��Slave�е�����ʱ����£���Master���һ�������Ϊ1001����Slave�е�����ֻ�ָ���999������ʱSlave�ڵ�promote��Ϊ�µ�Master�������µIJ�������999������Ľ��Ϊ������Ҳ����˵ԭMaster�е�1000��1001���������������ݽ����ɻָ��������ڵ�ǰ��������ݿ����Ѿ��ύ������֧��ֱ�ӻ��ˣ����ԣ����������ݿ��TB�����⽫��Ҫ6~7Сʱ��
���������ܿ콫�ᱻ���ơ�PostgreSQL9.5��Ϊ�û��ṩpg_rewind���ܡ���Master�ڵ�Failover��ԭMaster�ڵ����ͨ��pg_rewind����ʵ�ֹ���ʱ���ߵĻ��ˡ����˺��ٴ��µ������л�ȡ���µĺ������ݡ���ˣ���Ȼ֮ǰû���ύ����������ACIDԭ��������ʹ�ã���ԭMaster�����������������ȫ����ʼ���Ϳ��Լ�������Streaming
Replication������Ϊ�µ�Slaveʹ�á�
Corosync + Pacemaker M/S ��������
���������н�ͼ������http://clusterlabs.org/wiki/PgSQL_Replicated_Cluster��
Corosync + Pacemaker M/S���û�����
RA��Resource Agent��Դ������PostgreSQL���µ�RA����ͨ��https://github.com/ClusterLabs/resource-agents/blob/master/heartbeat/pgsql���ء�����㷢�����RA�������������Ҳ�������и�д��
����ϵͳ�汾��Fedora19�����ϡ�Red Hat Enterprise Linux 7�����ϡ�SUSE
Linux Enterprise Server 11 SP3�����ϡ�
���ݿ�Ҫ��PostgreSQL9.1�����ϣ�����PostgreSQL 9.1���ϲ�֧��Streaming
Replication����ˣ�������汾�͵����ݿ���ʵ�ִ˹��ܡ�
��̨������������ͬ��NTPʱ��Դ����ͬ��ʱ����
ͨ��yum��zypper��װpacemaker����Ҫ����HA��Դ��������corosync��HA����ͬ�����ƣ���pcs3��HA�����������ù��ߣ���ͨ��yum��zypper���κ�������ʽ��װPostgreSQL���ݿ⣬��װʱ���ȷ����pg_ctl���psql���dataĿ¼�Ĵ��λ�ã���Ϊ����ʱҪ�õ���

PostgreSQL Streaming Replication����
��node1�г�ʼ��PostgreSQL���ݿ⡣

����postgresql.conf�ļ��������ġ�

ע�⣺wal_level = hot_standby��ʹ����־֧��Streaming Replication��archive_mode
= on�������鵵ģʽ��archive_command = 'xxx'��ָ���鵵�ı��淽����hot_standby
= on����������Ϊstandbyģʽʱ��ʵ��ֻ����ѯ������������Ҫ�������ܼ��ӳٵ��趨��
��dataĿ¼�µ�pg_hba.conf�ļ��������ġ�
ע�⣺�������ú�����192.168.x.x���ε�IP��������������Դ����ݿ���з��ʣ���ȫ�Կ��ܻή�͡���ˣ�ֻ��Ϊ��ϰʹ�ã����������������ϸ����IP����ָ��ֻtrustijIP����д��192.168.100.123/32��
������ɺ�����node1�ϵ�PostgreSQL��

��node2�������ݳ�ʼ����

ע�⣺ͨ��pg_basebackup�����node1�н��������ݿ��е����ݶ�ͬ����/var/lib/pgsql/dataȥ��
����basebackup��ɺ���node2�е�dataĿ¼�½���recovery.conf�ļ���¼���������ݡ�

ע�⣺primary_conninfoָ���������������ڵ�λ�á�replicate��ʹ�õ��û���������������pg_hba.conf��ʹ��trust��ʽ�������ڴ˲����в���Ҫ����password��
������ɺ�����node2�ϵ�PostgreSQL�������ͬ��Ч����

�����node1��ͨ��psql�����¼���ݿ����Եõ�������Ϣ��֤�����ݿ�˵�Replication������������

�Դˣ�PostgreSQL��Streaming Replication������ɣ��������ݿ�����ݽ����г������ơ�
ע�⣺���������������Ѿ����Streaming Replication���ã�������HAǰ�뽫�����������ϵ�PostgreSQL��ֹͣ����Ϊ��HA�ܹ��У�������Դ��Ӧ������HA�������й����ģ��������ͬʱҲ��ȷ��ϵͳ����ʱPostgreSQL�����Զ������������ͨ��chkconfig��飩��

Corosync + Pacemaker HA ��������
corosync�����ļ�ֻ��һ����/etc/corosync/corosync.conf��

���ǿ��Կ�������ǰquorum��expected_votesΪ2��������Ϊ����ʹ��2�ڵ㡣totem����bindnetaddr:192.168.1.0��mcastaddr:
239.255.1.1������˵��corosync��ʹ�ñ���������192.168.1.X���ε�IP��Ϊ�������˴�ע�⣬����Ҫд����IP����ϸ��ַ��ϵͳ���Զ����֡�ͨ��scp������ļ����Ƶ�node2����ͬ��Ŀ¼����֤��Ȩ��һ�¡�
�������Ϳ����������ڵ�������corosync�ˡ�������ϵͳ��Fedora
19��RHEL7��SUSE12��ķ���������������ʹ�õ��ǵͰ汾����ϵͳ������/etc/init.d/corosync
start��service corosync start ��

pacemakerĬ�������������Ⱦ�ģ���Ϊ�˱�֤HA��ʼ״̬���ǻ�������²������˲������������HA��Դ�����á���������һЩ�����Ҳʮ��ʵ�ã�����ʱ���ǻᷢ�������ڵ�HA����ʱ��Դ��Ϣ��ͬ������ʱ���ǿ�������һ�����ŵĽڵ㣬Ȼ����һ�ڵ��ϵ�cib�ļ���գ�Ȼ���������pacemaker�������½ڵ�ͻ��Զ�ͬ�����нڵ���������á�

Pacemaker��Դ����
ͨ��pcs�����й��߽���HA��Դ�����á�pcs�����п���Э��������Ϊconfig.pcs�����ýű����Խ�������HA���õ��롣���ȣ����ǽ���һ��ȫ����Ϣ�����ã�ָ�����ڵ�ǰ��2�ڵ㣬���Ժ���no-quorum-policy��Ĭ�ϵ�resource-stickinessΪINFINITY�����κ���ԴĬ�϶�����������Դ�ɹ�ͬ���еģ�?Ĭ�ϵ�migration-thresholdΪ1�����κ������migrationʱ��������һ�Ρ�

ע�⣺stonith-enabled="false"��ʾ��ʹ���κε�Դ�����豸����������������������ʹ�á���ϤRHEL��Ⱥ��ͬѧ������ΪStonith��ͬ��Fence�豸��
����VIP1��VIP2���Լ�pgsql��Դ��

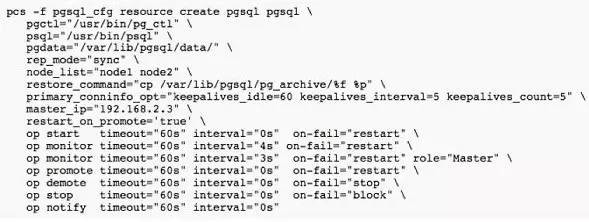
vip-master(VIP1)��vip-rep(VIP2)��ԱȽϺ����⡣����pgsql��Դ�У�����������ϤLinux��Ⱥ�Ļᷢ�֣�һ�������HA������Ӧ����Դ�������һ������start/stop/status�Ľű������˴���ͨ��һ��agentʵ�֣�����ֻҪ���ú�PostgreSQL��pgctl��psql��pgdata���ļ���Ŀ¼λ�ü��ɣ�����ʮ�ַ��㡣��Ҫ��ΪPostgreSQL
RA�Ѿ�����start|stop|status|monitor|promote|demote|notify�IJ����ű���https://github.com/ClusterLabs/resource-agents/blob/master/heartbeat/pgsql������л��Դ����л�����߰ɣ�����ͷ��2070�д��룬�������ǰ�Լ�д��Ҫ����öࡣ
�����ϵ�IP��pgsql��Դ���й�������Ҳ��pacemaker���ĵط������ǿ��Կ��������ȣ���һ����resource
master����������ΪmsPostgresql��pgsql�������Masterģʽ��Դ�����ģ�͵���Դ������cloneģ�ͣ������������ڵ�ͬʱ������Ȼ������һ��master-group����vip-master��vip-rep�ӵ�������С���������constraintcolocationָ����master-group�е���Դ��vip-master��vip-rep����������msPostgresql��Master�ڵ�������һ�����orderpromote��order
demote��������ڵ������˳��

ע�⣺Master�ڵ����RA�Զ�ʶ��msPostgresql����promote�Ժ�Ż����master-group��IP�ҽӣ�ͬʱ���ڽ���demoteʱҲ��ֻ�е�msPostgresql���ͣ���Ž���master-group��IP�Ͽ�������

�˴���config.pcs����ǰ���pcs�����ɣ�ͨ��crm_mon����Կ������е���Դ�����

�Դ��������ý���������Խ�node1��PostgreSQL��dataĿ¼mv�������ط������л���Ч������������
�����Ŵ�������HA��־��Ϣ�ᱣ����/var/log/message�С����ϵͳ�����⣬����ͨ������־���з���������һ�����Ҫ��������������HAǰһ��Ҫȷ��NTP�����Ƿ���������������������ʱ�䲻Ҫ���̫��Ȼ�Ŵ�����鷳�������п��ܵ��¼�Ⱥ���������⡣
��ȥ���꣬�����ļ�Ⱥ�ܹ��Ѿ��ںܶ���ҵʹ�ã�����������20G��1T֮�䡣PG��һ������OLTP��ϵͳ����ǰ����ʵʩ����ҵ����Ǵ�ͳ��ҵ�����û���Ҫ�Ǵ�OracleǨ�����ġ��ڴ����ݼ��������棬������Greenplum��Hadoop�Ƚ��д�������ʱPostgreSQLҲ����ʹ��FDW���ܽ��жԽӡ�
PostgreSQL Syncģʽ��ǰ������
ǰ���ᵽ��ǰPostgreSQL��2�ڵ�������Ƽ�ʹ�õ���async��ģʽ����sync�Dz��Dz�֧�֣����ǵģ���ǰPostgreSQL֧��syncģʽ����ʹ2�ڵ�Ҳ�������ã��������������⣺
����syncͬ��ģʽҪ��Master��Slave����д��ɹ���Ž��������Commit������������ܻ��ܵ�Ӱ�졣
���ϵͳ���й�����slave���ֹ��ϣ����ڵ�Ҳ���ܵ�Ӱ��ʹϵͳ���ֹ��ϣ���HA����Ҳ��Failover��Pacemaker��ǰ���µ�PostgreSQLRAҲ��û�н�������⡣
�����Ҫʹ��syncģʽ��Streaming Replication���ҽ���1��2����ģ��ʵ�֣������ģ����Pacemaker��û���ṩ3�ڵ��ʵ�ַ������д��Ľ���
������һ�¡�PostgreSQL�й��û��ᡱ��Postgres�й��û�����һ����Ӫ�����壬������Ϊ�й���PostgreSQL�û�����ǰ��QQ����Ⱥ�Ѿ��г���4000�˹�ģ���ڹ�ȥ��2��������ȫ��9�����оٰ�����Ϊ�������й�
Let'sPostgres�������¼���ɳ����ͬʱ֧������ۼ�̨�������PostgreSQL�������
Q&A
Q1���ų����ޣ�PG���MySQL��Oracle��ɶ���ƣ�
A1��PG�кܶ�MySQLû�еĹ��ܣ�����O2O��ҵΪ����PGֱ���ṩPostGIS��������Ч�������ݿ���ͨ��SQL���и��ӵĶ�λ��ѯ����ҵ��ֱ�ӹ���������ܻ�ӭ���½�����
Q2��������ҵ����async���ƣ���ôӦ�����ݶ�ʧ��������ô��
A2�����ȣ�������ҵ�����Ҫ��100%���ݲ���ʧ��Ӧ��ʹ��sync������async���������PostgreSQL��֧�ֵģ�ֻ��Ҫ��3�ڵ㷽������ǰ����������½���HA�л�Ҳ�ǿ��Եģ�ֻ��Corosync+Pacemakerû��ֱ��֧�֣���Ҫ���Ƕ�RA���и��ӵĽű����ơ�
Q3��threshold����Ϊ1ʱ������1�Σ�������������ֱ���л��ˡ�����Ϊ2ʱ�� 2�γ��ԣ���������������ڳɹ���ָ�ԭֵ���ò��Խ���Ƿ���ȷ��
A3���ǵģ���˼���dz���1�Σ���Pacemaker��Щֵ��������ʱ�ģ���ʱ�ͻ�ָ�ԭֵ�������ͨ��clean����������ڵ��ϵļ�����������ֵ�ָ�������
Q4��MySQL��binlog������PG����ʲô����
A4��MySQL��ֻ�ù�4�����°汾����binlog����ʮ���˽⣬�빫˾MySQL��ţ�����У��Ҹо���������ʽ�Ǻܽӽ��ģ�����ʹ����־���лָ�����PostgreSQL�IJ����л���TupleΪ��λ�����������һ��row����������ij��row�б��Ĺ���1���ֶε�ֵ����һ�����۽����PG��StreamingReplication�����ϸ��
Q5��3�ڵ㷽��д�ɹ�2���ͷ��أ�����,3�����ɹ��ŷ��أ�
A5��3�ڵ�����£�ϵͳ����2���ڵ���ͬ������3�����첽�����Գɹ�2���ͷ��ء�
Q6��PG��HA���˽�������Ļ�������������
A6��PG��HA��������LiveKeeper������MSCS�ȷ���������HA����PG��ֻ��һ�����������κ�HA������������PG�Խӣ������Ҫ����StreamingReplication���л���Ҫ�Լ�д�ű���?
Q7���Ҹо�PG���HA���MySQL�Դ�������û������㡣PG������mysql-proxy�����ĸ��ؾ����м����MMA������������֮ǰ��˵PG�ڼ�Ⱥ��鲻�Ǹ��ã�����������������ʧ���Dz���PG���Ǹ��ʺϵ�����
A7����ǰPGҵ�����ͨ��PGPoolʵ��1��Master���ж�д��n��Slave����ֻ�����ؾ���ķ�����PG�ֲ�ʽ��Ⱥ��ǰ������Postgres-X2��ȷʵ���ӣ������ⷽ��Ҳ����Ŭ������������������ϣ������кܶ�PG�û���ѡ��ͨ��Ӧ�ó����Զ�����зֿ⼯Ⱥģ�ͣ��Ͼ���Ҫ��ǿһ������û��InfiniBand����������������£�������ӳٶ������ڴ�ͳ��Ⱥ�н����
Q8��PG��sharding�������ܷ����һ�¡�
A8�����PG������һ����Ϊpg_shard�ĵ�������������Զ����ݿ��е�һ���ض��ı�����sharding��������չ��64̨��������������֤�˱�������һЩ�����������Կ��dz��ԡ�
Q9���ܷ�Ա�һ��PG��HA������
A9�� Corosync + Pacemake��֧��Replicationģʽ����Linux�������Ҹ�Ϊ���Ƽ��ķ����������洢ͬ��Ҳû�����⣻ԭRHEL�е�RHCS�����ü�����й����洢��Linux�����������㣬��Ҫע��RHCS��Ҫ��ʹ�õģ�LiveKeeper��������Ը���һЩ�����Ҫ֧��Replication��Ҫд�Ƚϸ��ӵĽű�����MSCS��Windowsƽ̨�ر����й������м����û��������õģ�VCS����Windows��Linuxƽ̨��ͬ��ֻ�������й����洢�����ʹ�á�
Q10�� PG�ı�������MySQL�ı�����������ģ����Ե��ŵ����ģ���ӡ����PG�������������ʾ�ɵ�����һ�����������������˺��ѿ���
A10��PGĬ�ϵı��������ڶ������ݿ�ṹ�ı����ɣ�ͨ���������������ݵ��ȣ��������Ժ����ܺܲ��˵��9.6�Ժ�ǰ9.4������ơ��ڴ˴����棬�����������ڰ����Ƶ�PPAS���Ѿ��õ������2~1000�����������ܱ����ֺ㶨��������Ϊ������Խ��Խ�ർ������ƿ����
|







