|
架构师在设计微服务架构的时候,一般会关注模式、拓扑以及粒度等问题,但是有一个最为基础的决策是线程模型。我们现在有了很多的开源工具、编程语言和技术栈,软件架构师所面临的选择要比以往更多了。
这样的话,我们很容易就会迷失在语言的细节和/或不同库的差异之中,从而无法分辨什么东西才是最重要的。
为微服务选择正确的线程模型并确定它将如何与数据库连接进行关联非常重要,这决定了你的解决方案是刚刚能用,还是会成为一个很棒的产品。
作为架构师,在考虑效率和复杂性之间的权衡时,关注线程模型是一种有效的方式。服务会被分解为并行的操作,通过共享的资源来进行处理,所以应用会变得更加高效,其响应的延迟也会更短(这会在一定的范围之内,参见Amdahl定理)。不过,并行操作和安全的资源共享会为代码引入更多的复杂性。
代码越复杂,工程师完全理解起来就会越困难,这意味着在每次变更的时候更有可能引入新的bug。
架构师最为重要的责任之一就是在效率和代码复杂性之间找到一个平衡。
单线程单进程的线程模型
最基本的线程模型就是单线程单进程模型,按照这种方式编写代码是最简单的。
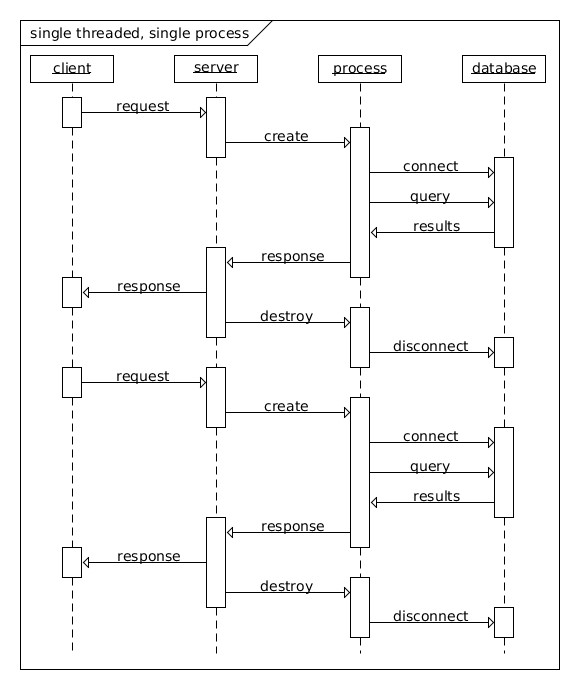
单线程单进程服务同一时间无法在多个核心上执行。在现代的裸机服务器上,核心数量一般能够达到24个。如果按照这种模型构建服务的话,它所能使用的服务器核心数量不会超过一个。如果有额外的负载的话,这些服务的吞吐量不会随之增加,它们的CPU利用率百分比不会超过个位数。鉴于如此高的未利用率,所以有一种补偿策略就是使用更大的服务器池来处理负载。
这种方式可以运行,但是它非常浪费,最终的成本会非常高昂。最为流行的云计算供应商都以非常便宜的价格提供单虚拟核心实例,这样做是为了以更细的粒度来支持这种模式,从而应对扩展性的需求。
单线程多个新进程的线程模型
在复杂性和效率方面更进一步的就是单线程多进程的线程模型,在这种方式下,会为每个请求创建一个新的进程。编写这种类型的微服务相对比较简单,但是跟前面的模型相比它包含了更多的复杂性。

创建进程的开销以及持续创建和销毁数据库连接会占用处理器的时间,因此会增加所有协作服务的延迟。这种线程模型之所以会创建更多的数据库连接是因为数据库连接是属于每个进程的,无法跨进程边界共享。进程的存活时间只会在请求的时间范围内,所以每个请求必须要重新连接数据库。
按照这种线程模型运行的微服务应该延迟对数据库的连接,直到需要的时候再创建连接。如果代码路径不需要的话,那就没有必要耗费成本创建数据库连接了。尽管数据库连接无法跨进程缓存,但是有些环境支持跨进程的opcode缓存,这样的话,我们可以将服务的配置数据存储起来,如连接到数据库的主机IP和凭证信息,两个流行的opcode缓存样例就是Zend
OpCache和APC。
单线程多进程重用的线程模型
在代码复杂性和性能方面的下一步提升就是这种线程模型,这是一种单线程多线程的模型,新的请求都会重用已有的worker进程。这与前面的线程模型有所不同,在前面的模型中,会为每个请求都创建一个新的进程。而在这个线程模型中,在进程提供就绪之后,就不会创建新的进程了。

这种服务在复杂性方面相对来说比较简单直接,但是需要额外的代码来管理worker进程的生命周期。这些代码必须要正确地进行重新初始化。例如,程序员可能会维护一些静态变量,而不是以参数的形式传递大量的数据。这样的话,代码会更加简单,针对每个新的请求都对这些静态变量进行重置的话,代码就能正常运行。但是如果代码没有重置这些变量的话,那么它就会基于之前的请求来进行处理,而不是基于当前的请求。在代码复杂性方面,另外一点就是需要包含恢复失效(stale)数据库连接的逻辑。当与数据库的连接由于不活跃而断掉的时候,原有的数据库连接实例可能会出现失效的情况。
因为每个进程能够服务于多个请求,所以没有必要针对每个请求都重新连接数据库。数据库连接会进行重用,这样的话能够规避创建连接的成本,从而减少延迟。但是,每个进程本身还是需要创建和管理自己的数据库连接。因为进程之间无法共享数据库连接,所以进程间公用的数据库会打开更多的连接。打开过多的连接将会降低数据库的性能。这是因为数据库连接是有状态的,数据库应用必须要在自己的进程中为每个连接分配资源。
多线程单进程的线程模型
我们有一种保护数据库的更好方式,这就是在多线程、长期存活的单进程模型中通过可配置的连接数来使用连接池。尽管数据库连接无法跨多进程共享,但是在同一个进程中,它可以在多个线程间共享。

如下是一个样例:如果有100个单线程的进程,每个进程有10台服务器,那么数据库将会有100 X 10
= 1000个连接。如果我们的每个进程有100个线程,共有10台服务器,每个进程在它的连接池中配置了10个连接,那么数据库只会有10
X 10 = 100个连接,它依然能够实现很高的吞吐量。对于服务和数据库来说,跨线程的连接池都是一种高效的方案。
这种连接池技术既能实现很高的吞吐量又能保护数据库,但是它会带来额外的代码复杂性。因为线程必须共享有状态的数据库连接,所以开发人员需要识别并修正并发相关的缺陷,比如死锁、活锁、线程饿死和竞态条件。解决这些缺陷的方式之一就是进行序列化地访问,但是太多的序列化访问会降低并行性。对于初级的开发人员来说,这些类型的缺陷很难识别和修正。
多线程、长期存活的单进程模型有两种实现风格:一种是为请求分派一个专属的线程,另一种是所有的请求共享一个线程。在前者的线程模型中,每个请求会有一个专门的线程与之关联,这要限制并行处理的请求数量。太多的连接可能会导致效率低下,这是因为在操作系统的CPU调度器中需要执行太多的任务切换。
在后者的线程模型中,我们没有必要为每个请求创建额外的线程,但是I/O相关的任务必须要在单独的线程池中运行,这样的话,能够防止系统因为遇到较慢的操作而hang住,请求处理器需要等待线程池的处理结果。
这种方式没有为每个请求创建专门的线程,对于异步操作我们可以期望有很高的吞吐量和较低的延迟,但是对于同步操作来说,相对于为每个请求创建专属的线程,这种方式不会带来性能方面的改善。
小结

结论
在考虑采用哪种库和语言之前,软件架构师应该反思哪种线程模型能够最适合其工程文化和能力。在代码复杂性和效率之间取得一个很好的平衡将会有助于理清这些困惑,在各种可行的技术栈之间做出选择时,也能有一个正确的方向。因为微服务的范围要比单体应用更小,为了实现更高的效率,可以在代码复杂性方面做出更多的努力。
|





