|
摘要: 介绍如何设计一个稳定、高并发、消息保序的IM系统,以及如何通过使用存储层的高级功能来优化系统架构。
在构建社交IM和朋友圈应用时,一个基本的需求是将用户发送的消息和朋友圈更新及时准确的更新给该用户的好友。为了做到这一点,通常需要为用户发送的每一条消息或者朋友圈更新设置一个序号或者ID,并且保证递增,通过这一机制来确保所有的消息能够按照完整并且以正确的顺序被接收端处理。当消息总量或者消息发送的并发数很大的时候,我们通常选择NoSQL存储产品来存储消息,但常见的NoSQL产品都没有提供自增列的功能,因此通常要借助外部组件来实现消息序号和ID的递增,使得整体的架构更加复杂,也影响了整条链路的延时。
功能介绍
表格存储新推出的 主键列递增 功能可以有效地处理上述场景的需求。具体做法为在创建表时,声明主键中的某一列为自增列,在写入一行新数据的时候,应用无需为自增列填入真实值,只需填入一个占位符,表格存储系统在接收到这一行数据后会自动为自增列生成一个值,并且保证在相同的分区键范围内,后生成的值比先生成的值大.
主键列自增功能具有以下几个特性:
1.表格存储独有的系统架构和主键自增列实现方式,可以保证生成的自增列的值唯一,且
严格递增 。
2.目前支持多个主键,第一个主键为分区键,为了数据的均匀分布,不允许设置分区健为自增列。
3.因为分区健不允许设置为自增列,所以主键列自增是 分区键级别的自增
。
4.除了分区键外,其余主键中的任意一个都可以被设置为递增列。
5.对于每张表,目前 只允许设置一个主键列为自增列 。
6.属性列不允许设置为自增列。
7.自增列自动生成的值为 64位的有符号长整型 。
8.自增列功能是 表级别 的,同一个实例下面可以有自增列的表,也可以有非自增列的表。
9.仅支持在创建表的时候设置自增列,对于已存在的表不支持升级为自增列。
介绍了表格存储的主键列自增功能后,下面通过具体的场景介绍下如何使用。
场景
我们继续文章开头的例子,通过构建一个IM聊天工具,演示主键列自增功能的作用和使用方法。
功能
我们要做的IM聊天软件需要支持下列功能:
1.支持用户一对一聊天
2.支持用户群组内聊天
3.支持同一个用户的多终端消息同步
现有架构
第一步,确定消息模型

1.上图展示这一消息模型
2.发送方发送了一条消息后,消息会被客户端推送给后台系统
3.后台系统会先存储消息
4.存储成功后,会推送消息给接收方的客户端
第二步,确定后台架构
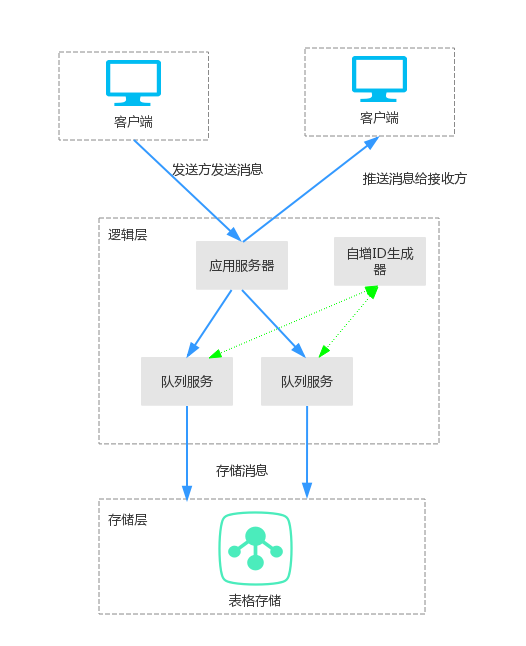
1.后台架构主要分为两部分:逻辑层和存储层。
2.逻辑层包括应用服务器,队列服务和自增ID生成器,是整个后台架构的核心,处理消息的接收、推送、通知,群消息写复制等核心业务逻辑。
3.存储层主要是用来持久化消息数据和其他一些需要持久化的数据。
4.对于一对一聊天,发送方发送消息给应用服务器后,应用服务器将消息存到接收方为主键的表中,同时通知应用服务器中的消息推送服务有新消息了,消息推送服务会将上次推送给接收方的最后一条消息的消息ID作为起始主键,从存储系统中读取之后的所有消息,然后将消息推送给接收方。
5.对于群组内的聊天,逻辑会更加复杂,需要通过异步队列来完成消息的扩散写,也就是说发到群组内的一条消息会给群组内的每个人都存一份。

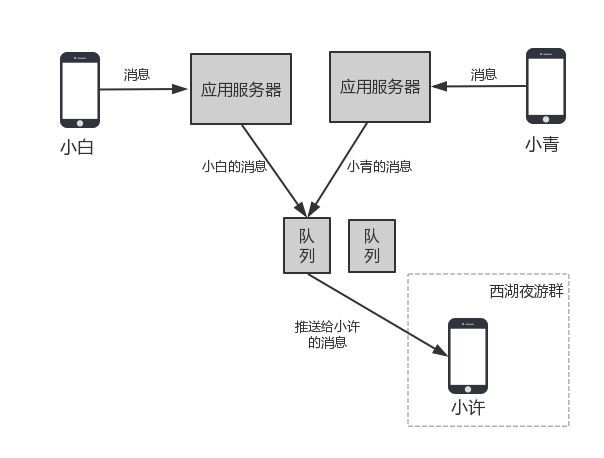
1.上图展示了省略掉存储层后的群消息发送过程。
2.使用扩散写而非扩散读,主要是由于以下两点原因:
a.群组内成员一般都不多,存储成本并不高,而且有压缩,成本更低。
b.消息扩散写到每个人的存储中(收件箱)后,为每个接收方推送消息时,只需要检查自己的收件箱即可,这时候,群聊和单聊的处理逻辑一样,实现简单。
3.发送方发送了一条消息后,这条消息被客户端推送给应用服务器,应用服务器根据接收者的ID,将消息分发给其中一个队列,同一个接收者的消息位于同一个队列中,在队列中,顺序的处理每条消息,先从自增ID生成器中获取一个新的消息ID,然后将这条消息写入表格存储系统。写成功后再写入下一条消息。
4.同一个接收方的消息会尽量在一个队列中,一个队列中可能会有多个接收方的消息。
5.群组内聊天时可能会出现同一个时刻两个用户同时发送了消息,这两个消息可能会进入不同的应用服务器,但是应用服务器会将同一个接收方的消息发给同一个队列服务,这时候,对于同一个接收方,这两条消息就会处于同一个队列中,如下图:
1.每个队列中的数据串行处理,每次写入表格存储的时候,分配一个新的ID,比之前的ID要大,为了保证消息可以严格递增,避免前一个消息写失败导致无法严格递增的情况出现,需要在写入数据到存储系统的时候,持有一个用户级别的锁,在没有写成功之前,同用户的其他消息不能继续写,以免当前消息写失败后导致乱序,当写成功后,释放这个锁,下一个消息继续。
2.上一步中,如果队列宕机,这些消息需要重新处理,这时候,原有消息就会进入一个新的队列,这时候新的队列需要一个新的消息ID,但要比之前已有的消息ID更大,而这个新队列并不知道之前的最大ID是啥,所以,这里每个队列没法自主创建自增ID,而需要一个全局的自增ID生成器。
3.为了支持多终端,在应用服务器中会为每个终端持有一个session,每个session持有一个当前最新消息的ID,当被通知有新消息时,会去存储系统读取当前消息之后的所有消息,这样就保证了多终端同时在线时,每个终端都可以同步消息,且相互不影响,见下图。
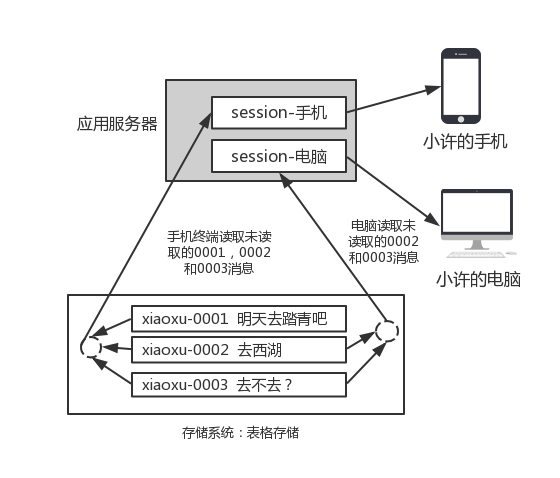
在多终端中,如果有部分终端由在线变成了离线,那么应用服务器会将这个终端的session保存到存储系统的另一张表中,当一段时间后,这个终端再次上线时,可以从存储系统中恢复出之前的session,继续为此终端推送之前未读取的消息。
第三步,确定存储系统
存储系统,我们选择了阿里云的 表格存储 ,主要是因为下列原因:
1.写操作不仅支持 单行写 ,也支持 多行批量写 ,满足大并发写数据需求。
2.支持按 范围读 ,消息多时可翻页。
3.支持 数据生命周期管理 ,对过期数据进行自动清理,节省存储费用,详细文档
4.表格存储是阿里云已经商业化的云服务, 稳定可靠 。
5.表格存储 价格便宜,对于数据量大的用户还可以以更优惠的价格购买套餐。
6.读写性能优秀,对于聊天消息,延迟基本在毫秒,甚至微妙级别。
第四步,确定表结构
确定的表格存储的表结构如下:

1.表格存储的表结构分为两部分,主键列部分和属性列部分,主键列部分最多支持4个主键,第一个主键为分区健。
2.使用前,需要确定主键列部分的结构,使用过程中不能修改;属性列部分是Schema
Free的,用户可以自由定制,每一行数据的属性列部分可以不一样,所以,只需要设计主键列部分的结构。
3.第一个主键是分片键,目的是让数据和请求可以均衡分布,避免热点,由于最终读取消息时是要按照接收方读取,所以这里可以使用接收方ID作为分片键,为了更加均衡,可以使用接收方ID的md5值的部分区域,比如前4个字符。这样就可以将数据均衡分布了。
4.第一个主键只用了部分接收方ID,为了能定位到接收方的消息,需要保存完整的接收方ID,所以,可以将接收方ID作为第二个主键。
5.第三个主键就可以是消息ID了,由于需要查询最新的消息,这个值需要是单调自增的。
6.属性列可以存消息内容和元数据等。
到此,我们已经设计出了一个完整的聊天系统,虽然这个系统已经可以运行,且能处理大并发,性能也不差,但是还是存在一些挑战。
挑战
1.多个用户在一个队列中,这个队列串行执行,为了保证消息严格递增,这里执行过程中要持有锁,这里就会有一个风险点:如果发送给某个用户的消息量很大,这个用户所在的队列中消息会变多,就有可能堵塞其他用户的消息,导致同队列的其他用户消息出现延迟。
2.当出现重大事件或者特定节假日,聊天信息量大的时候,队列部分需要扩容,否则可能扛不住大压力,导致整体系统延迟增大或者崩溃。
针对上述两个问题,问题2可以通过增加机器的方式解决,但是问题1没法通过增加机器解决,增加机器只能缓解问题,却没法彻底解决。那有没有办法可以彻底解决掉上述两个问题?
新架构
上面两个问题的复杂度主要是由于需要消息严格递增引起的,如果使用了表格存储的主键列自增功能,那么上层的应用层就会简单的多。
使用了表格存储**主键列自增功能**后的新架构如下:
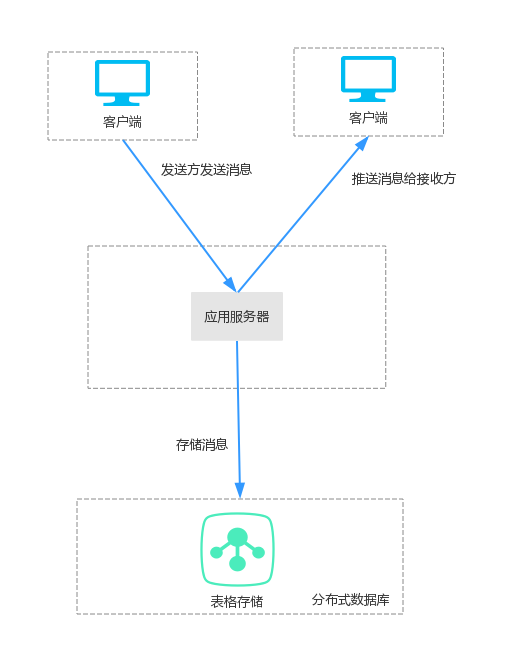
1.最明显的区别是少了队列服务和自增ID生成器两个组件,架构更加简单。
2.应用服务器接收到消息后,直接将消息写入表格存储,对于主键自增列message_id,在写数据时不需要填确定的值,只需要填充一个特定的占位符即可,这个值会在表格存储系统内部自动生成。
3.新架构中自增操作是在表格存储系统内部处理的,就算多个应用服务器同时给表格存储中的同一个接收方写数据,表格存储内部也能保证这些消息是串行处理,每个消息都有一个独立的消息ID,且严格递增。那么之前的队列服务就不在需要了。这样也就
彻底解决了上面的问题1
4.表格存储系统是一个云服务,用户并不需要考虑系统的容量,而且表格存储支持按量付费,这样也就
彻底解决了上面的问题2
5.之前只能有一个队列处理同一个用户的消息,现在可以多个队列并行处理了,就算某些用户的消息量突然变大,也不会立即堵塞其他用户,而是将压力均匀分布给了所有队列。
6.使用主键自增列功能后,应用服务器可以直接写数据到表格存储,不再需要经过队列和获取消息ID,
性能表现会更加优秀。
实现
有了上面的架构图后,现在可以开始实现了,这里选用JAVA SDK,目前4.2.0版本已经支持主键列自增功能,4.2.0版本Java
SDK文档和下载地址。
第一步,建表
按照之前的设计,表结构如下:
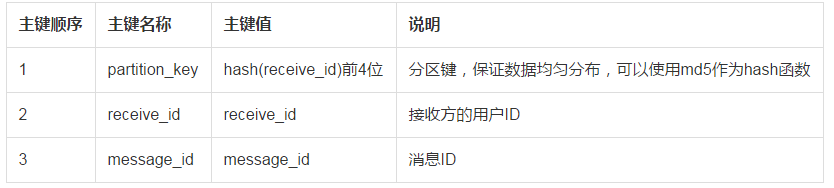
第三列PK是message_id,这一列是主键自增列,建表时指定message_id列的属性为AUTO_INCREMENT,且类型为INTEGER。
private static void createTable(SyncClient client) {
TableMeta tableMeta = new TableMeta(“message_table”);
// 第一列为分区建
tableMeta.addPrimaryKeyColumn(new PrimaryKeySchema("partition_key",
PrimaryKeyType.STRING));
// 第二列为接收方ID
tableMeta.addPrimaryKeyColumn(new PrimaryKeySchema("receive_id",
PrimaryKeyType.STRING));
// 第三列为消息ID,自动自增列,类型为INTEGER,属性为PKO_AUTO_INCREMENT
tableMeta.addPrimaryKeyColumn(new PrimaryKeySchema("message_id",
PrimaryKeyType.INTEGER, PrimaryKeyOption.AUTO_INCREMENT));
int timeToLive = -1; // 永不过期,也可以设置数据有效期,过期了会自动删除
int maxVersions = 1; // 只保存一个版本,目前支持多版本
TableOptions tableOptions = new TableOptions(timeToLive,
maxVersions);
CreateTableRequest request = new CreateTableRequest(tableMeta,
tableOptions);
client.createTable(request);
} |
通过上述方式就创建了一个第三列PK为自动自增的表。
第二步,写数据
写数据目前支持PutRow和BatchWriteRow两种方式,这两种接口都支持主键列自增功能,写数据时,第三列message_id是主键自增列,这一列不需要填值,只需要填入占位符即可。
private static void putRow(SyncClient client, String receive_id) {
// 构造主键
PrimaryKeyBuilder primaryKeyBuilder = PrimaryKeyBuilder.createPrimaryKeyBuilder();
// 第一列的值为 hash(receive_id)前4位
primaryKeyBuilder.addPrimaryKeyColumn(“partition_key”,
PrimaryKeyValue.fromString(hash(receive_id).substring(4)));
// 第二列的值为接收方ID
primaryKeyBuilder.addPrimaryKeyColumn(“receive_id”,
PrimaryKeyValue.fromString(receive_id));
// 第三列是消息ID,主键递增列,这个值是TableStore产生的,用户在这里不需要填入真实值,只需要一个占位符:AUTO_INCREMENT
即可。
primaryKeyBuilder.addPrimaryKeyColumn("message_id",
PrimaryKeyValue.AUTO_INCREMENT);
PrimaryKey primaryKey = primaryKeyBuilder.build();
RowPutChange rowPutChange = new RowPutChange("message_table",
primaryKey);
// 这里设置返回类型为RT_PK,意思是在返回结果中包含PK列的值。如果不设置ReturnType,默认不返回。
rowPutChange.setReturnType(ReturnType.RT_PK);
//加入属性列,消息内容
rowPutChange.addColumn(new Column("content",
ColumnValue.fromString(content)));
//写数据到TableStore
PutRowResponse response = client.putRow(new PutRowRequest(rowPutChange));
// 打印出返回的PK列
Row returnRow = response.getRow();
if (returnRow != null) {
System.out.println("PrimaryKey:" + returnRow.getPrimaryKey().toString());
}
// 打印出消耗的CU
CapacityUnit cu = response.getConsumedCapacity().getCapacityUnit();
System.out.println("Read CapacityUnit:"
+ cu.getReadCapacityUnit());
System.out.println("Write CapacityUnit:"
+ cu.getWriteCapacityUnit());
} |
第三步,读数据
读消息的时候,需要通过GetRange接口读取最近的消息,message_id这一列PK的起始位置是上一条消息的message_id+1,
结束位置是INF_MAX,这样每次都可以读出最新的消息,然后发送给客户端
private static void getRange(SyncClient client, String receive_id, String lastMessageId) {
RangeRowQueryCriteria rangeRowQueryCriteria = new RangeRowQueryCriteria(“message_table”);
// 设置起始主键
PrimaryKeyBuilder primaryKeyBuilder = PrimaryKeyBuilder.createPrimaryKeyBuilder();
// 第一列的值为 hash(receive_id)前4位
primaryKeyBuilder.addPrimaryKeyColumn(“partition_key”,
PrimaryKeyValue.fromString(hash(receive_id).substring(4)));
// 第二列的值为接收方ID
primaryKeyBuilder.addPrimaryKeyColumn(“receive_id”,
PrimaryKeyValue.fromString(receive_id));
// 第三列的值为消息ID,起始于上一条消息
primaryKeyBuilder.addPrimaryKeyColumn(“message_id”,
PrimaryKeyValue.fromLong(lastMessageId + 1));
rangeRowQueryCriteria.setInclusiveStartPrimaryKey(primaryKeyBuilder.build());
// 设置结束主键
primaryKeyBuilder = PrimaryKeyBuilder.createPrimaryKeyBuilder();
// 第一列的值为 hash(receive_id)前4位
primaryKeyBuilder.addPrimaryKeyColumn(“partition_key”,
PrimaryKeyValue.fromString(hash(receive_id).substring(4)));
// 第二列的值为接收方ID
primaryKeyBuilder.addPrimaryKeyColumn(“receive_id”,
PrimaryKeyValue.fromString(receive_id));
// 第三列的值为消息ID
primaryKeyBuilder.addPrimaryKeyColumn("message_id",
PrimaryKeyValue.INF_MAX);
rangeRowQueryCriteria.setExclusiveEndPrimaryKey(primaryKeyBuilder.build());
rangeRowQueryCriteria.setMaxVersions(1);
System.out.println("GetRange的结果为:");
while (true) {
GetRangeResponse getRangeResponse = client.getRange(new
GetRangeRequest(rangeRowQueryCriteria));
for (Row row : getRangeResponse.getRows()) {
System.out.println(row);
}
// 若nextStartPrimaryKey不为null, 则继续读取.
if (getRangeResponse.getNextStartPrimaryKey()
!= null) {
rangeRowQueryCriteria.setInclusiveStartPrimaryKey(getRangeResponse.getNextStartPrimaryKey());
} else {
break;
}
}
} |
上面演示了表格存储及其主键列自增功能在聊天系统中的应用,在其他场景中也有很大的价值,期待大家一起去探索。 |





