|
微服务架构解决了很多问题,但是同时引入了很多问题。本文要探讨的是如何解决下面这几个问题。
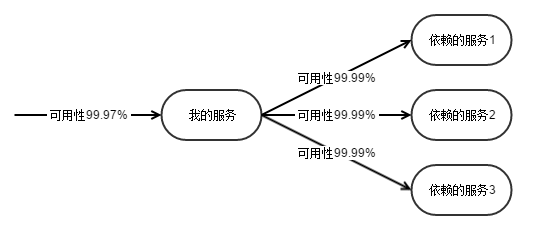
有大量的同步 RPC 依赖,如何保证自身的可靠性?
依赖的微服务调用失败了,我应该失败,还是成功。依赖很多外部服务之后,自身如何保障稳定性。如果所有依赖的服务成功,我才算成功,自身的稳定性就堪忧了。
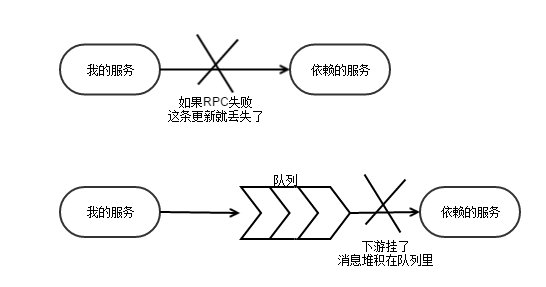
RPC 调用失败,降级处理之后如何保证数据可修复?
如果调用失败时,选择跳过。那么因此产生的数据不一致性问题如何修复?平时毛毛雨,可以忽略。但是大故障之后,人工还是要来擦屁股的,这个成本就特别高。使用消息队列的最大的意义是在让消息可以在故障的时候堆积起来,等故障恢复了再慢慢来处理,减少人工介入的成本。
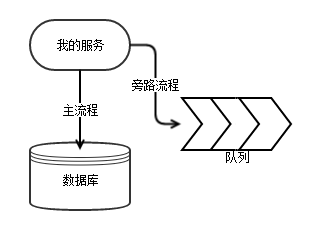
消息队列是一个RPC主流程的旁路流程,怎么保证可靠性?
依赖消息队列做系统解耦的时候,怎么确保消息自身是可靠入队列的?消息是否需要先可靠写入队列,然后再提交数据库事务?如果消息必须先写入队列,比如
kafka。但是 kafka 挂了怎么办?那我在线业务岂不被离线的队列给连累了?
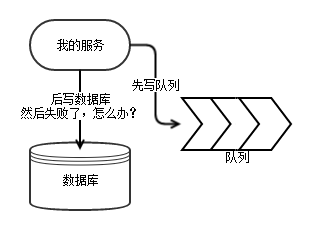
消息队列怎么保持与数据库的事务一致?
如果消息是先写入队列,然后数据库提交事务。那么就会有因为并发修改的情况下,数据库提交失败,但是消息已经写入到队列的情况。如果队列后面挂了奖励等业务流程,这个时候就会导致错发,或者要求奖励那边去再查一遍数据库的状态。但是如果先提交数据库事务,后写入队列,又无法严格保证队列里的消息是没有丢失的。
这些问题是所有混用了 RPC 和异步队列的业务都会遇到的普遍问题。这里我给一个提案来解决以上的所有问题。
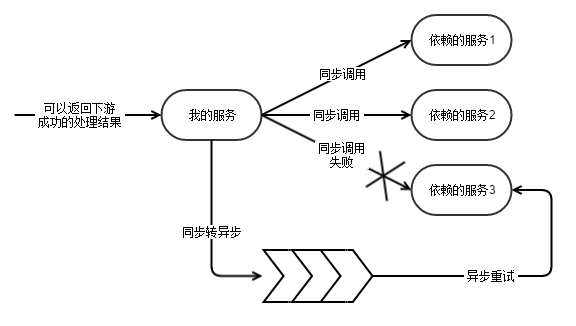
同步转异步,解决稳定性问题
在平时的时候,都是 RPC 同步调用。如果调用失败了,则自动把同步调用降级为异步的。消息此时进入队列,然后异步被重试。所以处理下游依赖就变成了三种可能性
完全强依赖,下游不能挂
因为我的返回值依赖了某个下游的处理结果,我必须同步调用它。但是不是强依赖,可降级。降级时不返回这部分的数据。同步调用降级时转为异步的。
完全异步化。下游服务只是消费我写入的队列,我不与之直接RPC通信
把消息队列放入到主流程
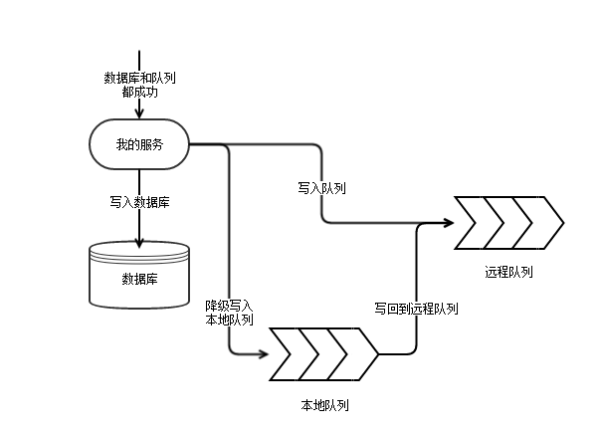
如果要把重要的业务逻辑挂在消息队列后面。必须要保证消息队列里的数据的完整性,不能有丢失的情况。所以不能是把消息队列的写入作为一个旁路的逻辑。如果消息队列写入失败或者超时,都应该直接返回错误,而不是允许继续执行。
Kafka 的稳定性和延迟时常不能满足在线服务的需要。比如如果要可靠写入三副本,Kafka
需要等待多个 broker 的应答,这个延迟可能会有比较大的波动。在无法及时写入的情况,我们需要使用本地文件充当一个缓冲。实际上是通过引入本地文件队列结合远程分布式队列构成一个可用性更高,延迟更低的组合队列方案。这个本地的队列如果能封装到一个
Kafka 的 Agent 作为本地写入的代理,那是最理想的实现方式。
保障数据库与队列的事务一致性
需求是当数据库的事务成功时,消息一定要保证写入了队列里。如果数据库的事务失败,消息不应该出现在队列里。所以肯定不能先写队列,再写数据库,否则要让
Kafka 支持消息的回滚,这会是一个很麻烦的事情。那么就要防范这么两种情况
数据库写入成功。然后写队列,但是队列写入失败。返回错误,让上游重试。但是上游可能会放弃,导致消息丢失。
数据库写入成功。然后全机房断电了。
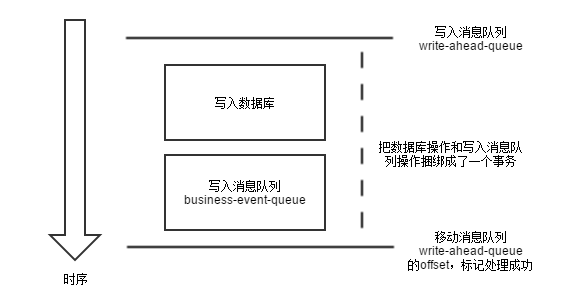
这两种情况下都会出现消息没有写入队列的情况。如何仅仅依靠 Kafka 和 Mysql 这两个组件,实现数据库与队列的事务一致性呢?构想如下
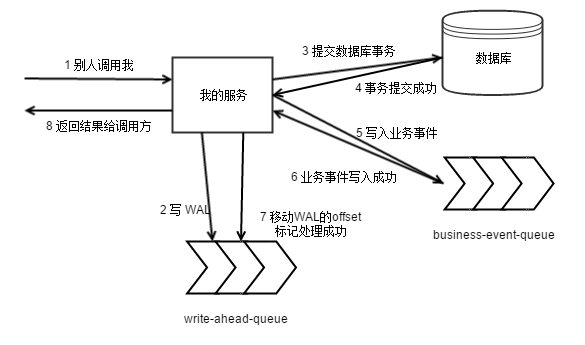
所有请求,先写入到 write-ahead-queue 这个 topic。如果这个消息就写入失败,直接返回错误给调用方,让其重试。
处理数据库事务
如果数据库事务失败。则移动 write-ahead-queue 的 offset,代表这个请求已经被处理完毕。
如果数据库事务成功。则接下来写 business-event-queue 这个 topic
如果写入队列成功。则移动 write-ahead-queue 的 offset,代表这个请求已经被处理完毕。
如果写入队列失败,返回成功给调用方。然后异步去重试写入 business-event-queue 这个
topic
在数据库事务成功到消息写入到business-event-queue这个topic中间,write-ahead-queue
的 offset 都是没有被移动的。也就是如果这个过程被中断,可以从 write-ahead-queue
恢复回来。
经过重试,最终 business-event-queue 写入成功。这个时候移动 write-ahead-queue
的 offset,标记这个请求被处理完毕
也就是说,通过引入 write-ahead-queue,以及控制这个
topic 的 offset 位置,来标记完整的分布式事务是否已经被处理完成。在过去,这个处理是否完成是以数据库的事务为标准的,没有办法保障数据库事务之后发生的事情的必然发生。
虽然看上去很复杂。但是这个连两阶段提交都不是,因为没有回滚的需求,只要数据库写入成功,消息队列写入无论如何都要成功。整个方案的关键是通过
write-ahead-queue 的写入和offset的移动这两个动作,标记了一个分布式事务的范围。只要这个过程没有完全做完,就会通过不断重试
write-ahead-queue 的方式保证其最终会被完整执行。
在没有 write-ahead-queue 的时候,我们的 RPC 执行过程是这样的
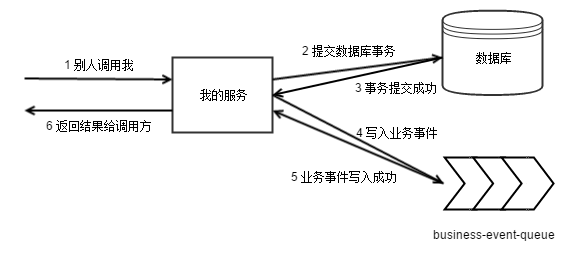
这个串行过程,因为没有保护,所以可能被中断,不能被确保完整执行。引入 write-ahead-queue
的目的就是让这个过程变得可靠
Write-Ahead-Queue 的 Offset 管理
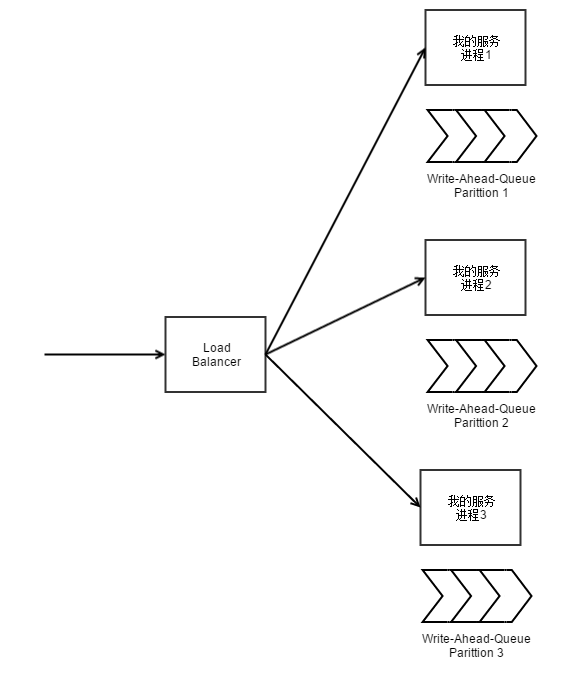
前面的事务方案的假设是整个处理过程,对于一个 Kafka 的Partition 是独占的。这也就意味着有多少个
RPC 的并发处理线程(或者协程)就需要有多少个对应的 Partition 来跟踪对应线程的处理状态。这样就会变得很不经济,需要开大量的
Kafka Partition。但是如果让多个 RPC 线程共享一个 Kafka Partition,那么由谁来移动
Offset 来标记事务的执行成功呢?这里就需要引入一个 Offset 管理者,来去协调多个 RPC 线程的
Offset 的移动。
RPC 线程1,写入了 WAL1 (Write-Ahead-Log),其 Offset 为 1
RPC 线程2,写入了 WAL2,其 Offset 为 2
RPC 线程3,写入了 WAL3,其 Offset 为 3
RPC 线程3执行完毕,欲把WAL3标记为执行成功,移动Offset到3。但是因为前面1和2,还没有执行成功,这个时候Offset不能被移动。
RPC 线程1执行完毕,欲把WAL1标记为执行成功,移动Offset到1。因为前面没有尚未执行完成的WAL,所以这个时候Offset被移动到1成功。
RPC 线程2执行完毕,欲把WAL2标记为执行成功,移动Offset到2。因为后面的3已经被执行完了,所以Offset被直接更新为3。
这个处理逻辑和 TCP 的窗口移动逻辑是非常类似的。用这种方式,大概就是一个RPC的进程,对应一个kafka的partition去跟踪它的处理流程。相当于给
RPC 框架,加了一个 WAL 的保护,用于保证 RPC 流量会被完整地跑完。
其他方案
实现跨数据库和消息队列的事务一致性,还有两种做法:
去哪儿网,利用数据库作为队列,然后用数据库的多表事务来保障一致性:设计消息中间件时我关心什么?(解密电商数据一致性与完整性实现,含PPT)
淘宝 Notify,利用两阶段提交的消息 broker 来实现:淘宝的消息中间件(2013) - taowen
- SegmentFault
两种实现都需要用 mysql 来作为消息中间件,引入了比较高的运维成本。
总结
前面给了三个独立的技术方案
使用同步转异步的方案,提高同步 RPC 的可用性,同时提高数据一致性。
引入本地队列作为兜底,提高消息队列的总体可用性,以及降低延迟。
通过引入两级队列,让 Write-Ahead-Queue 来保证 Business-Event-Queue
一定会在数据库事务成功之后被写入。
我们只需要把这三个独立的方案结合到一起,就可以把队列技术应用到纯 RPC 同步组合的微服务集群里,用于提高可用性和数据的一致性。同时可以保证这份消息数据是可靠的,从而给其他的业务逻辑把自己放在队列后面,建立了前提条件。
|





