|
������վ�ܹ��ݻ�
����һ���߿��á������ܡ�����չ���������Ұ�ȫ����վ��
������վ����ϵͳ���ص�
1.�߲���������������Ҫ��Ը߲����û������������ʡ�
2.�߿��ã�ϵͳ7��24Сʱ����Ϸ���
3.�������ݣ���Ҫ�洢�������������ݣ���Ҫʹ�ô�����������
4.�û��ֲ��㷺�������������:������ͻ���������Ϊȫ���û��ṩ����ģ��û��ֲ���Χ�㣬�����������ǧ�����
5.��ȫ�������ӣ����ڻ������Ŀ����ԣ�ʹ�û�����վ�������ܵ�������������վ����ÿ�춼�ᱻ�ڿ�����
6.������ٱ��������Ƶ�����ʹ�ͳ�����İ汾����Ƶ�ʲ�ͬ����������ƷΪ������Ӧ�г��������û��������Ʒ����Ƶ���Ǽ��ߵġ�
7.����ʽ��չ���봫ͳ������ҵ����ҵӦ��ϵͳһ��ʼ�滮��ȫ���Ĺ��ܺͷǹ�������ͬ���������еĴ��ͻ�����վ���Ǵ�һ��С��վ��ʼ�������ط�չ�����ġ�
����վ�ܹ��ݻ���չ����
1. ��ʼ�ε���վ�ܹ�

��ʼ�ε���վ�ܹ�
Ӧ�ó������ݿ⡢�ļ������е���Դ����һ̨�������ϡ�
2. Ӧ�÷�������ݷ������

Ӧ�÷�������ݷ������
Ӧ�÷���������Ҫ����������ҵ�����������Ҫ�����ǿ���CPU
���ݿ����������Ҫ���ٴ��̼��������ݻ��棬�����Ҫ�����Ӳ�̺�����ڴ�
�ļ�����������Ҫ�洢�����û��ϴ����ļ��������Ҫ�����Ӳ��
3. ʹ�û��������վ����
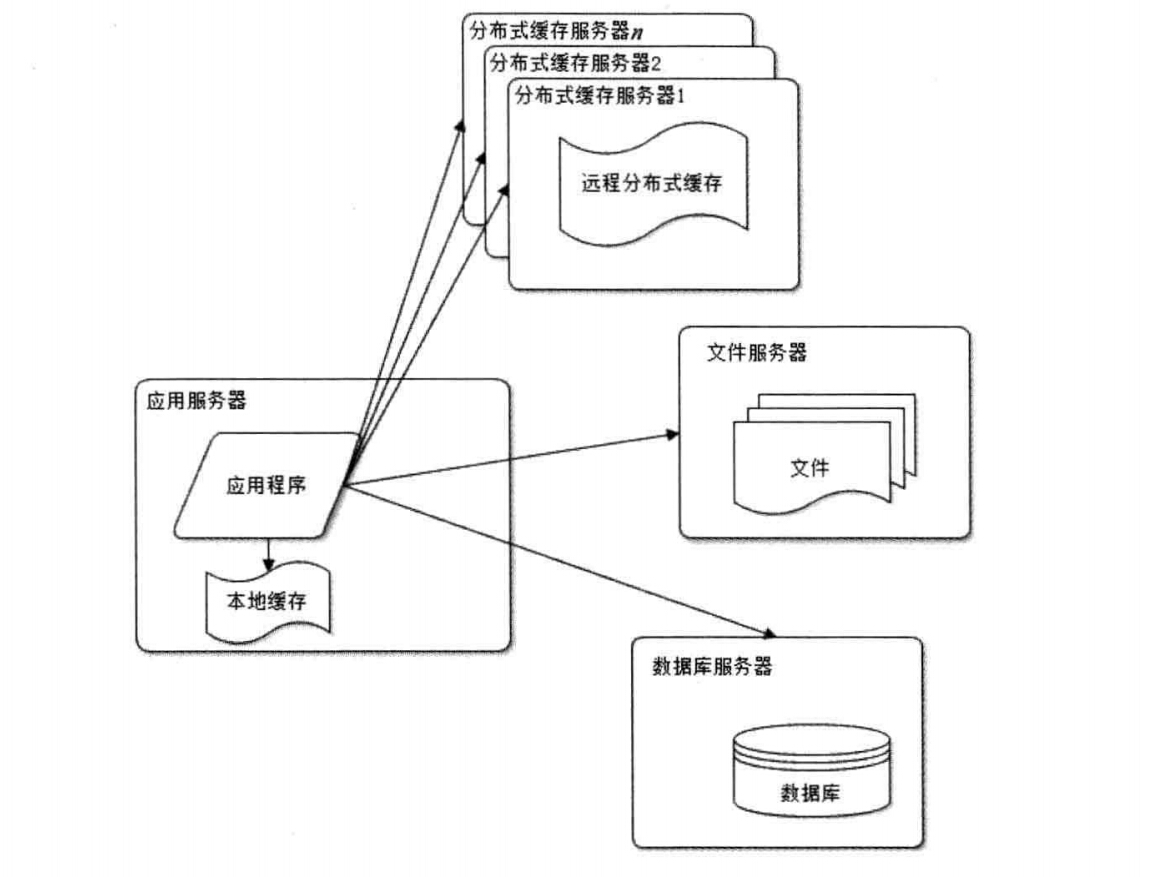
��վʹ�û���
������Ӧ�÷������ϵı��ػ��棺�����ٶȸ��죬������Ӧ�÷������ڴ����ƣ��仺�����������ޣ����һ���ֺ�Ӧ�ó������ڴ�������
������ר�ŵķֲ�ʽ����������ϵ�Զ�̻��棺Զ�̷ֲ�ʽ�������ʹ�ü�Ⱥ�ķ�ʽ��������ڴ�ķ�������Ϊר�ŵĻ�������������������������������ڴ��������ƵĻ������
4. ʹ��Ӧ�÷�������Ⱥ������վ�IJ�����������

Ӧ�÷�������Ⱥ����
���ؾ�����ȷ��������������û�������ķ�������ַ���Ӧ�÷�������Ⱥ�е��κ�һ̨�������ϡ�
5. ���ݿ��д����

���ݿ��д����
�����ȱ����ܣ�ͨ��������̨���ݿ����ӹ�ϵ�����Խ�һ̨���ݿ�����������ݸ���ͬ������һ̨�������ϡ�
Ӧ�÷�������д���ݿ��ʱ���������ݿ⣬�����ݿ�ͨ�����Ӹ��ƻ��ƽ����ݸ���ͬ���������ݿ⣬������Ӧ�÷����������ݵ�ʱ�Ϳ���ͨ�������ݿ������ݡ�Ϊ�˱���Ӧ�ó�����ʶ�д���������ݿ⣬ͨ����Ӧ�÷�������ʹ��ר�ŵ����ݷ���ģ�飬ʹ���ݿ��д�����Ӧ������
6. ʹ�÷��������CDN������վ��Ӧ

��վʹ�÷��������CDN���ٷ���
CDN�ͷ������������ԭ�����ǻ��棬��������CDN�����������ṩ�̵Ļ�����ʹ�û���������վ����ʱ�����ԴӾ����Լ�����������ṩ�̻�����ȡ���ݣ����������������վ�����Ļ��������û��������Ļ��������ȷ��ʵķ������Ƿ�������������������������������л������û��������Դ���ͽ���ֱ�ӷ��ظ��û���
7. ʹ�÷ֲ�ʽ�ļ�ϵͳ�ͷֲ�ʽ���ݿ�ϵͳ

ʹ�÷ֲ�ʽ�ļ�ϵͳ�ͷֲ�ʽ���ݿ�ϵͳ
�ֲ�ʽ���ݿ⣺����վ���ݿ��ֵ�����ֶΣ�ֻ���ڱ������ݹ�ģ�dz��Ӵ��ʱ���ʹ�á�����������ʱ����վ�����õ����ݿ����ֶ���ҵ��ֿ⣬����ͬҵ������ݿⲿ���ڲ�ͬ�������������ϡ�
8. ʹ��NoSQL����������

ʹ��NoSQL����������
NoSQL���������棺Դ�Ի������ļ����ֶΣ��Կ������ķֲ�ʽ���Ծ��и��õ�֧�֡�Ӧ�÷�������ͨ��һ��ͳһ���ݷ���ģ����ʸ������ݣ�����Ӧ�ó�������������Դ���鷳��
9. ҵ����

ҵ����
ҵ���֣����ݲ�Ʒ���֣���һ����վ��ֳ����ͬ��Ӧ�ã�ÿ��Ӧ�ö�������ά����Ӧ��֮�����ͨ��һ�������ӽ�����ϵ������ҳ�ϵĵ�������ÿ����ָ��ͬ��Ӧ�õ�ַ����Ҳ����ͨ����Ϣ���н������ݷַ�����Ȼ���Ļ���ͨ������ͬһ�����ݴ洢ϵͳ������һ������������ϵͳ��
10. �ֲ�ʽ����

�ֲ�ʽ����
�ֲ�ʽ�����Խ�Ӧ��ϵͳ�й��õ�ҵ����ȡ����������������Щ�ɸ��õ�ҵ���������ݿ⣬�ṩ����ҵ�����Ӧ��ϵͳֻ��Ҫ�����û����棬ͨ���ֲ�ʽ������ù���ҵ�������ɾ���ҵ�������
������վ�ܹ��ݻ��ļ�ֵ��
1.������վ�ܹ������ĺ��ļ�ֵ������վ�������Ӧ��
2.����������վ������չ����Ҫ��������վ��ҵ��չ
��վ�ܹ��������
1.һζ���˾�Ľ������
2.Ϊ�˼���������
3.��ͼ�ü��������������
������վ�ܹ�ģʽ
ģʽ�Ĺؼ�����ģʽ�Ŀ��ظ��ԣ������볡���Ŀ��ظ��Դ�����������Ŀ��ظ�ʹ�á�
��վ�ܹ�ģʽ
Ϊ�˽��������վ���ٵĸ߲������ʡ��������ݴ������߿ɿ����е�һϵ����������ս�����ͻ�������˾��ʵ�����������������������ʵ�ָ����ܡ��߿��á�������������չ����ȫ�ȸ��ּ����ܹ�Ŀ�ꡣ��Щ��������ֱ�������վ�ظ�ʹ�ã��Ӷ����γɴ�����վ�ܹ�ģʽ��
1. �ֲ�
��ʵ���У���ķֲ�ṹ�ڲ������Լ����ֲ㣬�磺

��1��Ӧ�ò�
��ͼ�㣨��������
ҵ�����㣨����ʦ����
��2�������
���ݽӿڲ㣨��������������������ݸ�ʽ��
��������
2. �ָ�
���˵�ֲ��ǽ������ں���������з֣���ô�ָ����������������������з֡�
3. �ֲ�ʽ
���ڴ�����վ���ֲ�ͷָ��һ����ҪĿ����Ϊ���зֺ��ģ����ڷֲ�ʽ���𣬼�����ͬģ�鲿���ڲ�ͬ�ķ������ϣ�ͨ��Զ�̵���Эͬ������
�ֲ�ʽ�����վ�߲����������⣺
��1��.�ֲ�ʽ��ζ�ŷ�����ñ���ͨ�����磬����ܶ�������ɱȽ����ص�Ӱ�졣
��2��.������Խ�࣬������崻��ĸ���Ҳ��Խ��һ̨������崻���ɵķ����������ÿ��ܻᵼ�ºܶ�Ӧ�ò��ɷ��ʣ�ʹ��վ�����Խ��͡�
��3��.�����ڷֲ�ʽ�����б�������һ����Ҳ�dz����ѡ�
��4���ֲ�ʽ������վ�������۸��ӣ���������ά�����ѡ�
����վӦ���У����õķֲ�ʽ���������¼��֣�
1.�ֲ�ʽӦ�úͷ����ֲ�ͷָ���Ӧ�úͷ���ģ��ֲ�ʽ����
������վ���ܺͲ�����
�ӿ쿪���ͷ����ٶ�
�������ݿ�������Դ����
ʹ��ͬӦ�ø��ù�ͬ�ķ���
����ҵ���ܵ���չ
2.�ֲ�ʽ��̬��Դ����վ�ľ�̬��Դ�����ֲ�ʽ���𣬲����ö��������������������롱��
����Ӧ�÷������ĸ���ѹ��
�ӿ�������������ص��ٶ�
��������վ�ֹ�����
3.�ֲ�ʽ���ݺʹ洢����ͳ��ϵ���ݿ����NoSQL�������Ƿֲ�ʽ�ġ�
4.�ֲ�ʽ���㣺Ŀǰ��վ�ձ�ʹ��Hadoop����MapReduce�ֲ�ʽ�����ܽ��д������������㣬���ص����ƶ�����������ƶ����ݣ����������ַ�����������λ���Լ��ټ���ͷֲ�ʽ���㡣
5.�ֲ�ʽ���ã�֧����վ���Ϸ���������ʵʱ���¡�
6.�ֲ�ʽ�����ֲ�ʽ������ʵ�ֲ�����Эͬ��
7.�ֲ�ʽ�ļ���֧���ƴ洢��
4. ��Ⱥ
ʹ�÷ֲ�ʽ�Ѿ����ֲ�ͷָ���ģ��������𣬶����û����ʼ��е�ģ�飨����վ��ҳ��������Ҫ����������ķ�������Ⱥ��������̨������������ͬӦ�ù���һ����Ⱥ��ͨ�����ؾ����豸��ͬ�����ṩ����
5. ����
������ǽ����ݴ���ھ�����������λ���Լӿ촦���ٶȡ������Ǹ����������ܵĵ�һ�ֶΡ�
��1��.CDN�������ݷַ����磬�����ھ����û��������������̣��û����������������ȵ��������������������ﻺ����վ��һЩ��̬��Դ�����ٱ仯�����ݣ����Ϳ���������ٶȷ��ظ��û���
��2��.���������������վǰ�˼ܹ���һ���֣���������վ��ǰ�ˣ����û�������վ����������ʱ�����ȷ��ʵ��ľ��Ƿ�����������������ﻷѸ��վ�ľ�̬��Դ�����轫�������ת����Ӧ�÷��������ܷ��ظ��û���
��3��.���ػ��棺��Ӧ�÷��������ػ������ȵ����ݣ�Ӧ�ó�������ڱ����ڴ���ֱ�ӷ������ݣ�������������ݿ⡣
��4���ֲ�ʽ���棺�����ݻ�����һ��ר�ŵķֲ�ʽ���漯Ⱥ�У�Ӧ�ó���ͨ������ͨ�ŷ��ʻ������ݡ�
ʹ�û�������ǰ��������
���ݷ����ȵ㲻���⣬ijЩ���ݻᱻ��Ƶ���ķ��ʣ���Щ����Ӧ�÷��ڻ����С�
������ij��ʱ�������Ч������ܿ���ڣ���������ݻ����Ѿ�ʧЧ�����������Ӱ��������ȷ�ԡ�
6. �첽
ϵͳ������ֶγ��˷ֲ㡢�ָ�ֲ��ȣ������첽��ҵ��֮�����Ϣ���ݲ���ͬ�����ã���ʮ��һ��ҵ������ֳɶ���Σ�ÿ����֮��ͨ���������ݵķ�ʽ�첽ִ�н���Э����
��1���ڵ�һ��������ͨ�����̹߳����ڴ���еķ�ʽʵ���첽��
��2���ڷֲ�ʽϵͳ�ж����������Ⱥͨ���ֲ�ʽ��Ϣ����ʵ���첽���ֲ�ʽ��Ϣ���пɿ����ڴ���еķֲ�ʽ����
�첽�ܹ��ǵ��͵�������������ģʽ�����߲�����ֱ�ӵ��ã�ֻҪ�������ݽṹ���䣬�˴˹���ʵ�ֿ�������仯��������Ӱ�죬�����վ��չ�¹��ܷdz�����������֮�⣬ʹ���첽��Ϣ���л����������ԣ�
��3�����ϵͳ�����ԣ������߷������������ϣ����ݻ�����Ϣ���з������д洢�ѻ��������߷��������Լ�������ҵ������ϵͳ����������ϡ������߷������ظ���������������Ϣ�����е����ݡ�
��4���ӿ���վ��Ӧ�ٶȣ�����ҵ����ǰ�˵������߷������ڴ�����ҵ�����������д����Ϣ���У�����Ҫ�ȴ������߷����������Ϳ��Է��أ���Ӧ�ӳټ��١�
�����������ʸ߷壺ʹ����Ϣ���н�ͻȻ���ӵķ����������ݷ�����Ϣ�����У��ȴ������߷��������δ������Ͳ����������վ���̫��ѹ����
7. ����
���ʺ��غ�С�ķ���Ҳ���벿��������̨����������һ����Ⱥ��ĸ����ͨ������ʵ�ַ������߿��á����ݿ���˶��ڱ��ݣ��浵���棬ʵ���䱸���⣬Ϊ�˱�֤����ҵ��߿��ã�����Ҫ�����ݿ�������ӷ��룬ʵʱͬ��ʵ���ȱ��ݡ�
8. �Զ���
���������Զ���
�Զ����������
�Զ�������
�Զ�����ȫ���
�Զ�������
�Զ������
�Զ�������
�Զ���ʧЧת��
�Զ���ʧЧ�ָ�
�Զ�������
�Զ���������Դ
9. ��ȫ
ͨ��������ֻ�У�������������֤
��¼�����Ȳ�����Ҫ������ͨ�Ž��м���
��ֹ�����˳�����վ��ʹ����֤��ʶ��
���ڳ��������ڹ�����վ��XSS������SQLע�����Ӧ����
����������Ϣ��������Ϣ���й���
�Խ���ת�˵���Ҫ�������ݽ���ģʽ�ͽ�����Ϣ���з��տ���
�ܹ�ģʽ����������Ӧ��

��������ϵͳ�ܹ�
�������
1.��������㣺�ṩ���ݿ⡢���桢�洢�����������ݷ����Լ�����һЩ��������������Щ����֧�����������ĺ������ݺ߲������ʣ�������ϵͳ�ļ���������
2.�м�㣨ƽ̨�����Ӧ�÷���㣩���������ĺ��ķ�����������ϵ���û�����Щ���ָ��Ϊ�����ķ���ģ�飬ͨ���������ú����������ݹ����ظ���������ҵ�������
3.API��ҵ��㣺���ֿͻ��ˣ�����Web��վ���͵�����Ӧ�ã�ͨ������API���ɵ���������ϵͳ�У���ͬ���һ����̬ϵͳ��
��Щ���ֲ�ͷָ���ҵ��ģ�����������ģ��ֲ�ʽ����ÿ��ģ�鶼������һ������ķ�������Ⱥ�ϣ�ͨ��Զ�̵��õķ�ʽ�����������ʡ�
��
�õ���ƾ��Բ���ģ�£���������Ӳ��ij��ģʽ�����Ƕ������������֮�ϵĴ����봴�¡�
������վ���ļܹ�Ҫ��
�ܹ�����߲�εĹ滮�����Ըı������
�����ܹ����й���������ṹ������ij�������������ָ����������ϵͳ�����������ơ�
�����ܹ������ܡ������ԡ������ԡ���չ�ԺͰ�ȫ�ԡ�
����
1.������ˣ�ͨ����������桢ʹ��ҳ��ѹ������������ҳ�桢����Cookie������ֶθ������ܡ�
2.CDN������վ��̬���ݷַ������û��������������̻�����ʹ�û�ͨ����̷���·����ȡ���ݡ�
3.��������������������ȵ��ļ����ӿ�������Ӧ�ٶȣ�����Ӧ�÷���������ѹ����
4.Ӧ�÷������ˣ����ػ���ͷֲ�ʽ���棬ͨ���������ڴ��е��ȵ����ݴ����û����ӿ����������̣��������ݿ⸺��ѹ��
5.�첽���������û�����������Ϣ���еȴ�����������������ǰ����ֱ�ӷ�����Ӧ���ͻ���
6.��Ⱥ������̨���������һ����Ⱥ��ͬ�������������崦���������������ܡ�
7.������棺ͨ��ʹ�ö��̡߳������ڴ�������ֶ��Ż����ܡ�
8.���ݿ�������ˣ����������桢SQL�Ż��������Ż��ֶ��Ѿ��Ƚϳ��죬NoSQL���ݿ�ͨ���Ż�����ģ�͡��洢�ṹ�������Ե��ֶ������ܷ���������������ԡ�
������
��վ�߿��ÿ����Ƶ�ǰ���DZ�Ȼ����ַ�����崻������߿�����Ƶ�Ŀ����ǵ�������崻���ʱ�������Ӧ����Ȼ���á�
��վ�߿��õ���Ҫ�ֶ������࣬Ӧ�ò����ڶ�̨��������ͬʱ�ṩ���ʣ����ݴ洢�ڶ�̨�������ϻ��౸�ݣ��κ�һ̨������崻�������Ӱ��Ӧ�õ�������ã�Ҳ���ᵼ�����ݶ�ʧ��
1. ��Ӧ�÷���������̨������ͨ�����ؾ����豸���һ����Ⱥ��ͬ�����ṩ�����κ�һ̨������崻���ֻ��Ҫ�������л��������������Ϳ���ʵ��Ӧ�õĸ߿��ã�����һ��ǰ��������Ӧ�÷������ϲ��ܱ�������ĻỰ��Ϣ��
2.�Դ洢����������Ҫ�����ݽ���ʵʱ���ݣ���������崻�ʱ��Ҫ�����ݷ���ת�Ƶ����õķ������ϣ����������ݻָ��Ա�֤�����з�����崻���ʱ��������Ȼ���á�
3.������������֤��ͨ��Ԥ������֤���Զ������ԡ��Զ������ԡ��Զ����������Ҷȷ������ֶΣ����ٽ������������ϻ����Ŀ��ܣ�������Ϸ�Χ����
������
��������ָͨ��������Ⱥ�м�����������ֶ������ⲻ���������û���������ѹ���Ͳ������������ݴ洢����
�����ܹ������Ե���Ҫ�������Ƿ���ö�̨������������Ⱥ���Ƿ�������Ⱥ�������µķ������������µķ��������Ƿ�����ṩ��ԭ�����������ķ���Ⱥ�п����ɵ��ܵķ����������Ƿ������ơ�
1. ����Ӧ�÷�������Ⱥ��ֻҪ�������ϲ��������ݣ����еķ��������ǶԵȵģ�ͨ��ʹ�ú��ʵĸ��ؾ����豸�Ϳ�����Ⱥ�в��ϼ����������
2.���ڻ����������Ⱥ�������µķ��������ܻᵼ�»���·��ʧЧ���������¼�Ⱥ�дֻ������ݶ������ʡ���Ȼ��������ݿ���ͨ�����ݿ����¼��أ��������Ӧ���Ѿ������������棬���ܻᵼ��������վ��������Ҫ�Ľ�����·���㷨��֤�������ݵĿɷ����ԡ�
3.���ڹ�ϵ���ݿ⣺��Ȼ֧�����ݸ��ƣ������ȱ��Ȼ��ƣ����Ǻ����������ģ��Ⱥ�Ŀ������ԣ���˹�ϵ���ݿ�ļ�Ⱥ�����Է������������ݿ�֮��ʵ�֣�ͨ��·�ɷ������ֶν������ж�����ݿ�ķ��������һ����Ⱥ��
4.����NoSQL���ݿ⣺Ϊ�������ݶ����������������Ե�֧��ͨ���dz��ã����������ڽ�����ά����������ʵ�ּ�Ⱥ��ģ������������
��չ��
��վ����չ�Լܹ�ֱ�ӹ�ע��վ�Ĺ�������
������վ�ܹ���չ�Ժû�����Ҫ����������վ�����µ�ҵ���Ʒʱ���Ƿ����ʵ�ֶ����в�Ʒ����Ӱ�죬����Ҫ�κθĶ����ߺ��ٸĶ�����ҵ���ܾͿ��������²�Ʒ��
1. �¼������ܹ���ͨ��������Ϣ����ʵ�֣����û����������ҵ��ʱ�乹�����Ϣ��������Ϣ���У���Ϣ�Ĵ�������Ϊ�����ߴ���Ϣ�����л�ȡ��Ϣ���д�����ͨ�����ַ�ʽ����Ϣ��������Ϣ�������뿪�����������������µ���Ϣ��������������µ���Ϣ����������
2.�ֲ�ʽ����ҵ��Ϳɸ��÷�����뿪��ͨ���ֲ�ʽ�����ܵ��á�������Ʒ����ͨ�����ÿɸ��õķ���ʵ��������ҵ�������������в�Ʒû���κ�Ӱ�졣�ɸ��÷������������ʱ��Ҳ����ͨ���ṩ��汾�����Ӧ��ʵ��������������Ҫǿ��Ӧ��ͬ�������
3.����ƽ̨�ӿڣ����������������ߣ�������վ����ʹ����վ���ݿ����ܱ߲�Ʒ����չ��վҵ��
��ȫ��
��վ�İ�ȫ�ܹ����DZ�����վ���ܶ�����ʺ�����������վ����Ҫ���ݲ�����ȡ��
��
���ܡ������ԡ������ԡ���չ�ԺͰ�ȫ������վ�ܹ�����ĵļ���Ҫ�ء�
˲ʱ��Ӧ����վ�ĸ����ܼܹ�
��վ�����ǿ�ָ�꣬���Ծ������ֵ���Ӧʱ�䡢�������ȼ���ָ�꣬ͬʱҲ�����۵ĸ��ܣ�����������һ�����������ص���Ķ������û��ĸ��ܺ���ʦ�ĸ��ܲ�ͬ����ͬ���û�����Ҳ��ͬ��
��վ���ܲ���
��ͬ�ӽ��µ���վ����
1. �û��ӽǵ���վ����
���û��Ƕȣ���վ���ܾ����û����������ֱ�۸��ܵ�����վ��Ӧ�صĿ컹������
�û����ܵ���ʱ�䣬�����û����������վ����ͨ�ŵ�ʱ�䡢��վ������������ʱ�䡢�û������������������������Ӧ���ݵ�ʱ�䡣

��ʵ����ʹ��һЩǰ���Ż��ֶΣ�
�Ż�HTMLʽ�� ����������˵IJ������첽���� ���������������� ʹ��CDN����
�������
2. ������Ա�ӽǵ���վ����
������Ա��ע����Ҫ��Ӧ�ó��������������ϵͳ�����ܣ�������Ӧ�ӳ١�ϵͳ����������������������ϵͳ�ȶ��Եȼ���ָ�ꡣ
��Ҫ�Ż��ֶΣ�
����������ݶ�ȡ
ʹ�ü�Ⱥ�����������
ʹ���첽��Ϣ�ӿ�������Ӧ��ʵ������
ʹ�ô����Ż��ֶθ��Ƴ�������
��ά��Ա�ӽǵ���վ����
��Ҫ�Ż��ֶΣ�
�����Ż��Ǹ��� ʹ�ø��Լ۱ȶ��Ʒ����� �������⻯�����Ż���Դ����
���ܲ���ָ��
1. ��Ӧʱ��

��Ӧʱ����ϵͳ����Ҫ������ָ�ֱ꣬�۵ط�ӳ��ϵͳ�ġ���������
ʵ����ͨ�����õİ취���ظ����õ������������Ӧʱ�䡣
2. ������
ָϵͳ�ܹ�ͬʱ�����������Ŀ���������Ҳ��ӳ��ϵͳ�ĸ������ԡ�
��վϵͳ�û��� >> ��վ�����û��� >> ��վ�����û���
���Գ���ͨ�����߳�ģ�Ⲣ���û��İ취������ϵͳ�IJ�������������Ϊ����ʵģ���û�����Ϊ�����Գ������������߳�Ȼ��ͣ�ط�������������������֮�����һ������ȴ�ʱ�䣬���ʱ�䱻����˼��ʱ�䡣
3. ������
ָ��λʱ����ϵͳ��������������������ϵͳ�����崦��������
TPS(ÿ��������)����������һ����������ָ�꣬����HPS(ÿ��HTTP��������QPS(ÿ���ѯ��)�ȡ�
��ϵͳ��������С������Ĺ����У������ŷ�����ϵͳ��Դ����������ϵͳ���������������ӣ��ﵽһ���������Ų����������ӷ����½����ﵽϵͳ�������ϵͳ��Դ�ľ���������Ϊ�㡣
��������У���Ӧʱ����ʵС�����������ﵽ����������������������ϵͳ�������ϵͳʧȥ��Ӧ��
4. ���ܼ�����
���ܼ����������������������ϵͳ���ܵ�һЩ����ָ�꣬����System Load���������߳������ڴ�ʹ�á�CPUʹ�á�����������I/O��ָ��
System Load����ϵͳ���أ�ָ��ǰ���ڱ�CPUִ�к͵ȴ���CPUִ�еĽ�����Ŀ�ܺͣ��Ƿ�ӳϵͳæ�г̶ȵ���Ҫָ�ꡣ
���ܲ��Է���
���ܲ��ԣ���ϵͳ��Ƴ��ڹ滮������ָ��ΪԤ��Ŀ�꣬��ϵͳ����ʩ��ѹ������֤ϵͳ����Դ�ɽ��ܷ�Χ�ڣ��Ƿ��ܴﵽ����Ԥ�ڡ�
���ز��ԣ���ϵͳ���ϵ����Ӳ�������������ϵͳѹ����ֱ��ϵͳ��ij����������ָ��ﵽ��ȫ�ٽ�ֵ��
ѹ�����ԣ������ȫ���ص�����£���ϵͳ����ʩ��ѹ����ֱ��ϵͳ���������ٴ����κ������Դ˻��ϵͳ���ѹ������������
�ȶ��Բ��ԣ�������ϵͳ���ض�Ӳ�������������绷�������£���ϵͳ����һ��ҵ��ѹ����ʹϵͳ����һ�νϳ�ʱ�䣬�Դ˼��ϵͳ�Ƿ��ȶ����ڲ�ͬ������������ͬʱ��������ѹ���Dz����ȵģ��ʲ������ԣ����Ϊ�˸��õ�ģ�������������ȶ��Բ���ҲӦ�����ȵض�ϵͳʩ��ѹ����
���ܲ�����ѭ��ͼ��ʾ�����߹��ɣ�

���ܲ�������
�������ʾ���ĵ�ϵͳ��Դ���������ʾϵͳ��������������������
a~b�Σ���վ���ճ���������
c�㣺ϵͳ����ص�
d�㣺ϵͳ������
�������������Ӧ�����û����ʵĵȴ�ʱ�䣨ϵͳ��Ӧʱ�䣩���磺

�����û�������Ӧʱ������
���ճ��������䣬���Ի����õ��û���Ӧʱ�䣬���Ų����û��������ӣ���Ӧ�ӳ�Խ��Խ��ֱ��ϵͳ�������û�ʧȥ��Ӧ��
���ܲ��Ա���
���Ա�������ӳ�������ܲ������߹��ɣ���ʾ����

���ܲ��Խ������
�����Ż�����
1. ���ܷ���
����������ĸ������ڵ���־�������ĸ�������Ӧʱ�䲻����������Ԥ�ڡ�
��������ݣ�����Ӱ�����ܵ���Ҫ�������ڴ桢���̡����硢����CPU���Ǵ�������Ǽܹ���Ʋ�����������ϵͳ��Դȷʵ���㡣
2. �����Ż�
Webǰ�������Ż�
Ӧ�÷����������Ż�
�洢�����������Ż�
Webǰ�������Ż�
һ��˵��Webǰ��ָ��վҵ����֮ǰ�IJ��֣�������������ء���վ��ͼģ�͡�ͼƬ����CDN����ȣ���Ҫ�Ż��ֶ����Ż���������ʡ�ʹ�÷��������CDN�ȡ�
����������Ż�
1. ����http����
��Ҫ�ֶ��Ǻϲ�CSS���ϲ�JavaScript���ϲ�ͼƬ��
�������һ�η�����Ҫ��Javascript��CSS�ϲ���һ���ļ������������ֻ��Ҫһ������
ͼƬҲ���Ժϲ�������ͼƬ�ϲ���һ�ţ����ÿ��ͼƬ���в�ͬ�ij����ӣ���ͨ��CSSƫ����Ӧ������������첻ͬ��URL��
2. ʹ�����������
������Ƶ�ʱȽϵ͵ġ�ʹ��Ƶ�ʱȽϸߵ��ļ�������������У����Լ��õظ������ܡ�ͨ������HTTPͷ�е�Cache-Control��Expires�����ԣ����趨��������棬����ʱ����������죬�����Ǽ����¡�
ijЩʱ��̬��Դ�ļ��仯��Ҫ��ʱӦ�õ��ͻ��������������ͨ���ı��ļ���ʵ�֣�������Javascript�ļ������Ǹ���Javascript�ļ����ݣ���������һ���µ�Javascript�ļ�������HTML�ļ��е����á�
ʹ�������������Ե���վ�ڸ��¾�̬��Դʱ��Ӧ�����������µİ취��������Ҫ����10��ͼ���ļ������˰�10���ļ�һ��ȫ�����£���ʮһ���ļ�һ���ļ����£�����һ���ļ��ʱ�䣬�����û������ͻȻ��������ʧЧ�����и��»��棬��ɷ�����������������������������
3. ����ѹ��
�ڷ������˶��ļ�����ѹ������������˶��ļ����н�ѹ����������Ч����ͨ�Ŵ������������
ѹ���Է����������������һ����ѹ������ͨ�Ŵ������ã�����������Դ����������ҪȨ�⿼�ǡ�
4. CSS����ҳ�������桢JavaScript����ҳ��������
���������������ȫ��CSS֮��Ŷ�����ҳ�������Ⱦ�������õ������ǽ�CSS����ҳ�������棬���������������CSS��
JavaScript���෴��������ڼ���JavaScript������ִ�У��п��ܻ������������棬���ҳ����ʾ���������JavaScript��÷���ҳ�������档
5. ����Cookie����
̫���Cookie������Ӱ�����ݴ��䣬��������Cookie�д�����������
����ijЩ��̬��Դ�ķ��ʣ���CSS��JavaScript�ȣ�����Cookieû�����壬���Կ��Ǿ�̬��Դʹ�ö����������ʣ���������̬��Դʱ����Cookie������Cookie���������
CDN����
CDN��Content Distribute Network�����ݷַ����磩�ı�����Ȼ��һ�����棬���ҽ����ݻ���������û�����ĵط���ʹ�û��������ٶȻ�ȡ���ݣ��������һ����

����CDN����վ�ܹ�
CDN�ܹ������һ���Ǿ�̬��Դ��������Щ�ļ�����Ƶ�Ⱥܸߡ�
�������

���÷����������վ�ܹ�
����������������б�����վ��ȫ�����á�
����ͨ�����û��湦�ܼ���Web����
�����������ʵ�ָ��ؾ���Ĺ��ܣ�ͨ�����ؾ������Ӧ�ü�Ⱥ�������ϵͳ���崦������������������վ�߲�������µ����ܡ�
Ӧ�÷����������Ż�
Ӧ�÷��������Ǵ�����վ�ķ���������վ��ҵ����붼�������������վ������ӣ��仯���ĵط����Ż��ֶ���Ҫ�л��桢��Ⱥ���첽�ȡ�
�ֲ�ʽ����
��վ�����Ż���һ���ɣ����ȿ���ʹ�û����Ż����ܡ�
1. ����Ļ���ԭ��
����ָ�����ݴ洢����Խϸ߷����ٶȵĴ洢ý���У��Թ�ϵͳ������һ���滺������ٶȿ죬���Լ������ݷ��ʵ�ʱ�䣬��һ�����������������Ǿ������㴦���õ��ģ���ô����������������ظ����㼴��ֱ��ʹ�ã���˻��滹���ټ�������á�
����ı��ʣ��ڴ��Hash������վӦ���У����ݻ�����һ��Key��Value����ʽ�洢���ڴ��Hash���С�Hash�����ݶ�д��ʱ�临�Ӷ�ΪO(1)��

Hash���洢����
������Ҫ���������Щ��д�Ⱥܸߡ��仯���ٵ����ݡ�

ʹ�û����ȡ����
2. ����ʹ�û���
Ƶ���ĵ�����
��������б������Ƶ���ĵ����ݣ��ͻ��������д�뻺���Ӧ�û���������ȡ���棬���ݾ���ʧЧ�����Σ�ͽ��ϵͳ������һ����˵�����ݵĶ�д����2:1���ϣ���д��һ�λ��棬�����ݸ���ǰ���ٶ�ȡ���Σ�����������塣
û���ȵ�ķ���
����ʹ���ڴ���Ϊ�洢���ڴ���Դ��������ޣ������ܽ����е����ݶ�����������ֻ�ܽ����·��ʵ����ݻ���������������ʷ�������������档
���ݲ�һ�������
һ���Ի������������ʧЧʱ�䣬һ������ʧЧʱ�䣬��Ҫ�����ݿ������¼��ء����Ӧ��Ҫ����һ��ʱ������ݲ�һ�¡��ڻ�����Ӧ���У������ӳ�ͨ���ǿ��Խ��ܵģ����Ǿ���Ӧ���������ضԴ�������һ�ֲ��������ݸ���ʱ�������»��棬������Ҳ���������ϵͳ����������һ�������⡣
���������
������Ϊ������ݶ�ȡ���ܵģ��������ݶ�ʧ�����治���ò���Ӱ�쵽Ӧ�ó���Ĵ��������Դ����ݿ�ֱ�ӻ�ȡ���ݡ����ǵ�����������ʱ�����ݿ���п�����ȫ���ܳ�����˴��ѹ����崻�����������������վ�����á������������������ѩ�����������ֹ��ϣ��������ܼ�������������������ݿ���������ָ���վ���ʡ�
ʵ���У��е���վͨ�������ȱ����ֶ����������ԣ���ij̨���������崻�ʱ������������л����ȱ��������ϡ��������������Ȼ��Υ������ԣ����治Ӧ�ñ������ɿ�������Դʹ�á�
ͨ���ֲ�ʽ�����������Ⱥ�����������ݷֲ�����Ⱥ��̨�������Ͽ���һ���̶��ϸ��ƻ���Ŀ����ԡ���һ̨���������崻���ֻ�в��ֻ������ݶ�ʧ�����´����ݿ�����ⲿ�����ݲ�������ݿ�����ܴ�Ӱ�졣
����Ԥ��
�����д�ŵ����ȵ����ݣ��ȵ��������ǻ���ϵͳ����LRU��������δ���㷨���Բ��Ϸ��ʵ�����ɸѡ��̭�����ģ����������Ҫ���ѽϳ���ʱ�䡣�������Ļ���ϵͳ���û���κ����ݣ����ؽ��������ݵĹ����У�ϵͳ�����ܺ����ݿ⸺�ض���̫�ã���ô����ڻ���ϵͳ����ʱ�Ͱ��ȵ����ݼ��غã��������Ԥ�����ֶν�������Ԥ�ȡ�����һЩԪ��������е����б�����Ŀ��Ϣ������������ʱ�������ݿ���ȫ�����ݵ��������Ԥ�ȡ�
���洩
�����Ϊ��ǡ����ҵ���߶���������߲���������ij�������ڵ����ݣ����ڻ���û�б�������ݣ����е������䵽���ݿ��ϣ�������ݿ���ɺܴ�ѹ��������������һ���ĶԲ��ǽ������ڵ�����Ҳ������������valueֵΪnull����
3. �ֲ�ʽ����ܹ�
�ֲ�ʽ����ָ���沿���ڶ����������ɵļ�Ⱥ�У��Լ�Ⱥ��ʽ�ṩ���������ܹ���ʽ�����֣�һ������JBoss
CacheΪ��������Ҫ����ͬ���ķֲ�ʽ���棬һ������MemcachedΪ�����IJ��ͨ�ŵķֲ�ʽ���档
JBoss Cache��JBoss Cache�ķֲ�ʽ�����ڼ�Ⱥ�����з������б�����ͬ�Ļ������ݣ���ij̨�������л������ݸ��µ�ʱ��֪ͨ��Ⱥ�������������»������ݻ�����������ݡ�

��Ҫ����ͬ����JBoss-Cache
JBoss Cacheͨ����Ӧ�ó���ͻ��沿����ͬһ̨�������ϣ�Ӧ�ó���ɴӱ��ؿ��ٻ�ȡ�������ݣ��������ַ�ʽ�����������ǻ������ݵ����������ڵ�һ���������ڴ�ռ䣬���ҵ���Ⱥ��ģ�ϴ�ʱ�����������Ϣ��Ҫͬ������Ⱥ���еĻ���������۾��ˡ�������ַ������������ҵӦ��ϵͳ�У������ڴ�����վʹ�á�
Memcached���Ժ���
4. Memcached
����ơ���������ܡ�����ͨ�ŵķ�������Ⱥ���������ݿ������ļܹ��� ������ͨ�ŵ�Memcached

��ͨ��ϴ��
Զ��ͨ�������Ҫ�����������Ҫ�أ�
ͨ��Э�飺��ѡ��TCPЭ�黹��UDPЭ�飬�ֻ�HTTPЭ�顣
ͨ�����л�Э�飺���ݴ�������ˣ�����ʹ�ñ˴˿�ʶ����������л���ʽ����ʹͨ�ŵ�����ɣ���XML��JSON���ı����л�Э�飬����Google
Protobuffer�ȶ��������л����л�Э�顣
Memcachedʹ��TCPЭ�飨UDPҲ֧�֣�ͨ�ţ������л�Э������һ�����ı����Զ���Э�飬��һ������ؼ��ֿ�ͷ��������һ������������������ȡһ�����ݵ�����Э����get\��
�ḻ�Ŀͻ��˳���
Memcachedͨ��Э��dz���ֻҪ֧�ָ�Э��Ŀͻ��˶����Ժ� Memcached������ͨ�ţ����Memcached��չ���dz��ḻ�Ŀͻ��˳�����֧��������������վ������ԡ�
�����ܵ�����ͨ��
Memcached �����ͨ��ģ�����Libevent��һ��֧���¼�����������ͨ�ų���⡣Libevent����ƺ�ʵ��������ֵ�ø��Ƶĵط����������ȶ��ij����ӷ���ı���ȴ����Memcached��Ҫ�ġ�
��Ч���ڴ����
Memcachedʹ����һ���dz��İ취�����̶��ռ���䡣 Memcached���ڴ�ռ��Ϊһ��slab��ÿ��slab���ְ���һ��chunk��ͬһ��slab���ÿ��chunk�Ĵ�С�ǹ̶��ģ�ӵ����ͬ��С
chunk��slab����֯��һ�𣬽���slab_class��

Memcached�ڴ����
�洢����ʱ�������ݵ�Size��С��Ѱ��һ������Size����Сchunk������д�롣
�����ڴ������ʽ�������ڴ���Ƭ���������⣬�ڴ�ķ�����ͷŶ�����chunkΪ��λ�ġ�
Memcached����LRU�㷨�ͷ�������δ�����ʵ�����ռ�õĿռ䣬�ͷŵ�chunk�����Ϊδ�ã��ȴ���һ���ϴ�С���ݵ�д�롣
���ַ�ʽҲ������ڴ��˷ѵ����⡣
����ͨ�ŵķ�������Ⱥ�ܹ�
���Ǽ�Ⱥ�ڷ���������ͨ��ʹ�ü�Ⱥ�����������������Ƶ�������������Ҳ����Ŀǰ���е���������ݼ����Ļ����ܹ��ص㡣
�첽����
ʹ����Ϣ���н������첽�����ɸ�����վ����չ�ԡ���ʵ�ϣ�ʹ����Ϣ���л��ɸ�����վϵͳ�����ܡ�

ʹ����Ϣ���з�����
�ڲ�ʹ����Ϣ���е�����£��û�����������ֱ��д�����ݿ⣬�ڸ߲���������£�������ݿ���ɾ��ѹ����ͬʱҲʹ����Ӧ�ӳټӾ硣
��ʹ����Ϣ���к��û���������ݷ�����Ϣ���к��������أ�������Ϣ���е������߽��̣�ͨ������£��ý���ͨ������������ר�ŵķ�������Ⱥ�ϣ�����Ϣ�����л�ȡ���ݣ��첽д�����ݿ⡣������Ϣ���з����������ٶ�Զ�������ݿ⣨��Ϣ���з�����Ҳ�����ݿ���и��õ������ԣ�������û�����Ӧ�ӳٿɵõ���Ч���ơ�
��Ϣ���о��кܺõ��������á�����ͨ���첽����������ʱ��߲���������������Ϣ�洢����Ϣ�����У��Ӷ���ƽ�߷��ڵIJ�������

��������д����Ϣ���к��������ظ��û��������ں�����ҵ��У�顢 д���ݿ�Ȳ�������ʧ�ܣ�
�����ʹ����Ϣ���н���ҵ���첽��������Ҫ�ʵ���ҵ�����̽�����ϣ��綩���ύ��������д����Ϣ���У��������������û������ύ�ɹ�����Ҫ����Ϣ���еĶ��������߽�������������ö�����������Ʒ�������ͨ�������ʼ���
SMS��Ϣ֪ͨ�û������ɹ������⽻���ס�
ʹ�ü�Ⱥ
����վ�߲������ʵij����£�ʹ�ø��ؾ��⼼��Ϊһ��Ӧ�ù���һ���ɶ�̨��������ɵķ�������Ⱥ����������������ַ�����̨�������ϴ��������ⵥһ����������ѹ���������Ӧ������ʹ�û�������и��õ���Ӧ�ӳ����ԡ�

���ø��ؾ��⼼����������
�����Ż�
1. ���߳�
����Դ���õĽǶȿ���ʹ�ö��̵߳�ԭ����Ҫ��������
IO����
��CPU
�����߳���=[����ִ��ʱ��/(����ִ��ʱ��-IO�ȴ�ʱ��)xCPU�ں���]
��������߳�����CPU�ں����������ȣ���IO����ʱ��ɷ��ȡ����������CPU������������ô�߳���������CPU�ں�����
����̰߳�ȫ����Ҫ�ֶΣ�
���������Ϊ��״̬������״̬������ָ���������洢״̬��Ϣ��������Ա���������߳�Ա����Ҳ����״̬�����������̲߳�������ʱ��Ͳ������״̬��һ�¡������������ƽǶȿ�����״̬����ʱһ�ֲ�����ơ�
ʹ�þֲ������ڷ����ڲ�����������Щ����ᱻÿ������÷������̴߳��������dz�������ʶ�ؽ���Щ���ݸ������̣߳�������ֶ����̲߳������ʵ����Ρ�
����������Դʱʹ���������̷߳�����Դ��ʱ��ͨ�����ķ�ʽʹ���̲߳�������ת��Ϊ˳��������Ӷ�������Դ�������ġ��������߳�ͬ��˳��ִ�У����ܻ��ϵͳ���ܲ�������Ӱ�졣
2. ��Դ����
ϵͳ����ʱ��Ҫ����������Щ�����ܴ��ϵͳ��Դ�Ĵ��������٣��������ݿ����ӡ�����ͨ�����ӡ��̡߳����Ӷ���ȡ�
������Java�������õĶ�������springĬ�Ϲ���Ķ����ǵ�����Ҫע����� Spring �ĵ�����
Spring ���������ĵ������������õ���ģʽ����ĵ�������
����أ�ͨ�����ö���ʵ�������ٶ�������Դ���ġ��������ݿ����Ӷ���ÿ�δ������ӣ����ݿ����˶���Ҫ����ר�ŵ���Դ��Ӧ�ԣ����Ƶ�������ر����ݿ����ӣ������ݿ�����������������Եģ�ͬʱƵ�������ر�����Ҳ��Ҫ���ѽϳ���ʱ�䡣�����ʵ���У�Ӧ�ó�������ݿ����ӻ�����ʹ�����ӳأ�Connection
Pool) �ķ�ʽ��
3. ���ݽṹ
Ŀǰ�ȽϺõ��ַ��� Hash ɢ���㷨��Time33�㷨�� �����ַ������ַ���������33,���
Hashֵ���㷨ԭ��Ϊ��
hash(i) = hash(i-1) * 33 + str[i] Time33��Ȼ���ԽϺõؽ����ͻ�������п��������ַ�����HashCodeҲ�ȽϽӽ������ַ�����AA����HashCode��2210,�ַ�����AB����HashCode��2211��
����ijЩӦ�ó����Dz��ܽ��ܵģ���������£�һ�����еķ����Ƕ��ַ���ȡ��Ϣָ�ƣ��ٶ���Ϣָ���� HashCode�������ַ���С�ı仯�Ϳ���������Ϣָ�Ƶľ�ͬ����˿��Ի�ýϺõ����ɢ�С�

ͨ��MD5����HashCode
4. ��������
��JVMΪ�������ڴ���Ҫ�ɻ���Ϊ�ѣ�heap ) �Ͷ�ջ��stack)����ջ���ڴ洢�߳���������Ϣ���緽���������ֲ������ȡ������Ǵ洢������ڴ�ռ䣬����Ĵ������ͷš��������վ���������С�ͨ���Զ����������ڵĹ۲죬���ִֶ�����������ڶ�������ݣ��ⲿ�ֶ������������Ӧ�ñ�������ռ������ͷ��ڴ棬�����
JVM �ִ��������ա�

JVM�ִ��������ջ���
�洢�����Ż�
��еӲ�� VS ��̬Ӳ��
��еӲ���������������ʣ�Ҫ���ʵ����ݴ洢�������Ĵ��̿ռ��ϣ���������ʣ�Ҫ���ʵ����ݴ洢�ڲ������Ĵ��̿ռ䣩ʱ�������ƶ���ͷ�۵Ĵ����������ܱ��ֲ��Ҳ�dz���
�������ڴ�һ������������ʡ����� SSD ����С�Ĺ��ĺ��ٵĴ������������� ����վӦ���У���Ӧ�÷������ݶ�������ģ����������
SSD ���и��õ����ܱ��֡�
B+�� VS LSM��
Ϊ�˸������ݷ������ԣ��ļ�ϵͳ�����ݿ�ϵͳͨ��������������洢���ӿ����ݼ����ٶȣ������Ҫ��֤�����ڲ��ϸ��¡����롢ɾ������Ȼ����ͳ��ϵ���ݿ��������ʹ��B+����

B+��ԭ��ʾ��ͼ
B+����һ��ר����Դ��̴洢���Ż��� N ���������������ڵ�Ϊ��λ�洢�ڴ����У��Ӹ���ʼ���������������ڵĽڵ��źʹ���λ�ã�������ص��ڴ���Ȼ��������ң�ֱ���ҵ���������ݡ�
Ŀǰ���ݿ��������������� B+�������IJ��������㡣��˿�����Ҫ 5
�δ��̷��ʲ��ܸ���һ����¼�����δ��̷��ʻ��������������IDȻ���ٽ���һ�������ļ���������һ�������ļ�д��������
Ŀǰ���� NoSQL ��Ʒ��� LSM ����Ϊ��Ҫ���ݽṹ��

LSM��ԭ��ʾ��ͼ
LSM �����Կ�����һ�� N �ϲ���������д�������������롢�ġ�ɾ���������ڴ��н��У����Ҷ��ᴴ��һ���¼�¼���Ļ��¼�µ�����ֵ����ɾ�����¼һ��ɾ����־
������Щ�������ڴ�����Ȼ����һ�����������������������趨���ڴ���ֵ�Ὣ����������ʹ��������µ��������ϲ����������������������Ҳ�����趨��ֵ�ʹ�������һ�����������ϲ����ϲ������У��������¸��µ����ݸ��Ǿɵ����ݣ�����¼Ϊ��ͬ�汾����
����Ҫ���ж�����ʱ�����Ǵ��ڴ��е���������ʼ���������û���ҵ����ʹӴ����ϵ�������˳����ҡ�
�� LSM ���Ͻ���һ�����ݸ��²���Ҫ���̷��ʣ����ڴ漴����ɣ��ٶ�Զ����
B+���������ݷ�����д����Ϊ���������������������д���������ʱ��ʹ�� LSM �����Լ���̶ȵؼ��ٴ��̵ķ��ʴ������ӿ�����ٶȡ�
��Ϊ�洢�ṹ��B+�����ǹ�ϵ���ݿ������еģ�NoSQL ���ݿ�Ҳ����ʹ��
B+����ͬ������ϵ���ݿ�Ҳ����ʹ��LSM��
RAID VS HDFS
RAID (���۴����������У�������Ҫ��Ϊ�˸��ƴ��̵ķ����ӳ٣���ǿ���̵Ŀ����Ժ��ݴ�������Ŀǰ�������l��ļ������֧�ֲ�������̣�8����߸���
����ͨ��ʹ��RAID������ʵ�������ڶ������ϵIJ�����д�����ݱ��ݡ�
������RAID������

����RAID����ԭ��ͼ
RAID0�����м�������ݶ�д�ٶȣ�����RAID0�������ݱ��ݣ���Ϊ������ֻҪ��һ�������������Ծͱ��ƻ������д��̵����ݶ�����
RAID1���κ�һ����̵������ᵼ�����ݶ�ʧ������һ���´��̾Ϳ���ͨ���������ݵķ�ʽ�Զ��������м��ߵĿɿ��ԡ�
RAID10�����RAID0��RAID1���ַ�������߿ɿ��Ը������ܣ�RAID10���������ʽϵͣ���һ���������д�������ݡ�
RAID3��RAID3������ʵ����ʹ�á�
RADI5��RAID5�������ʹ�ã�����RAID3Ƶ��д��һ����̵������
RAID6�����ݿɿ����ڳ���ͬʱ��������̵�����£���Ȼ���������ݡ�

����RAID�����Ƚ�
RAID ��������ͨ��Ӳ��ʵ�֣�����ר�õ�RAID����������ֱ��֧�֣�Ҳ����ͨ������ʵ�֡�RAID�����ڴ�ͳ��ϵ���ݿ⼰�ļ�ϵͳ��Ӧ�ñȽϹ㷺�������ڴ�����վ�Ƚ�ϲ��ʹ�õ�NoSQL�Լ��ֲ�ʽ�ļ�ϵͳ�У�RAID����ȴ����䡣
HDFS�Կ飨Block) Ϊ��λ�����ļ����ݣ�һ���ļ����ָ�����ɸ�Block��Ӧ�ó���д�ļ�ʱ��ÿд��һ��Block��HDFS�ͽ����Զ����Ƶ�������̨�����ϣ���֤ÿ��Block��������������ʹ����̨������崻���������Ȼ���Է��ʣ��൱��ʵ����RAID1�����ݸ��ƹ��ܡ�
�����ļ����д�������ʱ��ͨ��MapReduce�������������ܣ����������������������MapReduce
Task)ͬʱ��ȡ�ļ��Ķ��Block�������������൱��ʵ����RAID0�IJ������ʹ��ܡ�

HDFS�ܹ�ԭ��ͼ
HDFS���MapReduce�Ȳ��м����ܽ��д����ݴ���ʱ��������������Ⱥ�ϲ�����д�������еĴ��̣�����RAID֧�֡�
��
��վ�����Ż�����������վ������������ʱ�Ľ������������վ����������ܶ������û��߲�������ʱ�����ģ�������վ�����Ż�����Ҫ�����Ǹ��Ƹ߲����û���������µ���վ��Ӧ�ٶȡ�
��վ���ܶ������û�������һ�����۸��ܣ������Ż�������Ŀ�ľ��Ǹ����û������飬ʹ���Ǹо���վ�ܿ졣
�û�����Ŀ������������ͨ�������ֶθ��ƣ�Ҳ����ͨ���Ż�����������ơ� |





