| БрМЭЦМі: |
БОЮФРДздгкзїепеХЫЩШЛЃЌРњДЮЕФДѓДйЫљУцСйЕФММЪѕФбЕуЃЌзюживЊЕФЛЙЪЧЗўЮёжЮРэЁЃЯЃЭћБОЮФЖдДѓМвЕФгаЫљЦєЗЂЁЃ
|
|
ОЉЖЋЗўЮёЪаГЁЃЈfw.jd.comЃЉЪЧЮЊЕкШ§ЗНШэМўЗўЮёЩЬКЭОЉЖЋЩЬМвЬсЙЉЗўЮёЕФНЛвзЦНЬЈЁЃОЉЖЋЗўЮёЪаГЁЪЧвЛИівЕЮёМЋЖШИДдгЕФЯЕЭГЃЌдквЕЮёЩЯКИЧСЫЗўЮёРрЩЬЦЗЁЂДйЯњЁЂМЦЗбЁЂЖЉЙКЁЂЖЉЕЅЁЂжЇИЖЁЂНсЫуЁЂЭЫПюКЭЗЂЦБЕШТпМЃЌМИКѕЩцМАЕНЕчЩЬЕФЫљгадЊЫиЁЃ

ОЉЖЋЗўЮёЪаГЁМмЙЙ
ШчЩЯЭМЫљЪОЃЌЩЬМвЖЉЙКЗўЮёДгЕЅЦЗвГНјШыЃЌШЛКѓВщбЏКмЖраХЯЂЃЌШчМлИёЁЂЦРМлЁЃдкЩЬМвЕуЛїСЂМДЖЉЙКжЎЧАЃЌЩЬМвЛсВЛЭЃЕиЖдБШИїРрЗўЮёЃЌДгЧАЖЫЕНКѓЖЫЫљгаЕФЗўЮёЛљБОЩЯЖМЛсЫЂаТЃЌФЧУДЃЌУПвЛДЮЫЂаТЃЌЕїгУЗўЮёОЭЛсГаЪмвЛДЮЗўЮёЕФЕїгУЁЃЕБЖЉЕЅСПдіМгвЛБЖЕФЪБКђЃЌЪЕМЪЗўЮёЗУЮЪСПзюЩйЪЧ
10 БЖЁЃ
ФЧУДЮЊСЫгІЖдШчДЫДѓЕФЕїгУСПЃЌУПФъЕФ 618ЁЂЫЋ 11ЃЌОЉЖЋЗўЮёЪаГЁгжзіСЫЪВУДЃПЯТУцЮвУЧЛсНВНВ 618ЁЂЫЋ
11 БИеНКѓУцЃЌЯЕЭГНјаажиЙЙЃЌЖМДгФФаЉЗНУцНјааСЫгХЛЏЃЌШЅЬсИпСЫЯЕЭГЕФШнджадЃЌЬсИпСЫЯЕЭГгІЖдЗхжЕСїСПЕФФмСІЁЃ
ЪзЯШвЊећРэздМКЕФжиЙЙЫМТЗЃЌДѓжТећРэЮЊМИИіНзЖЮЃКЪсРэБЁШѕЕуЁЂЯЕЭГИФдьЁЂЩЯЯпКЭИДХЬЁЃ

ЯъЯИРДЫЕЃЌжиЙЙПЊЪМвЊЖдЯЕЭГзівЛДЮШЋУцЕФЪсРэеяЖЯЃЌЦфФПЕФОЭЪЧвЊевЕНЯЕЭГБЁШѕЕуЁЃЖјЪсРэЗНЗЈПЩвдДгЯЕЭГВПЪ№ёюКЯЁЂUMP
БЈОЏ & ШежОЁЂТ§ SQL & ЭтВПвРРЕЕШВЛЭЌВуУцзїЮЊЧаШыЕуНјааЁЃ
дкЯЕЭГИФдьНзЖЮЃЌЭЈЙ§ЖдЯЕЭГБЁШѕЕуЕФЪсРэЃЌНјааЯЕЭГМмЙЙИФдьЗНАИЕФЩшМЦЃЌРћгУЖўАЫдРэЃЌМЏжаОЋСІЕНзюживЊЕФЛЗНкЃЌМДЛЦН№СїГЬЕФгХЛЏЃЌзюКѓжЦЖЈМЦЛЎХХЦкЁЃЕБШЛЃЌЮвУЧПЩвдРћгУУєНнЕФЫМЯыЃЌаЁВНПьХмЃЌГжајгХЛЏИФНјЁЃ
ЩЯЯпОЭЪЧСйУХвЛНХЃЌЬЈЩЯвЛЗжжгЃЌЬЈЯТЪЎФъЙІЁЃЮЊСЫБЃжЄЩЯЯпГЩЙІЃЌвЊНјааГфЗжЕФЩЯЯпГяБИЁЃЪзЯШвЊећРэЩЯЯпМЦЛЎКЭЧаСїЗНАИЃЌЦфжаАќРЈЗжНзЖЮЩЯЯпЁЂЛвЖШЩЯЯпЕШЁЃМЦЛЎзМБИКУжЎКѓОЭвЊНјааЗДИДЕФбЙВтКЭбнСЗЃЌАќРЈМЋЖЫЧщПіЕФНЕМЖКЭдЄАИЕФЦєгУЕШЕШЁЃОбщРДНВЃЌДѓЖрЪ§ЩЯЯпЪЇАмЃЌЗДИДЛиЙіЕФАИР§ЃЌДѓЖрвЛЮоМЦЛЎЃЌЖўЮодЄАИЁЃ
МДЪЙНјааСЫжмУмЕФЩЯЯпГяБИЃЌЩЯЯпШдШЛПЩФмГіЯжвтЯыВЛЕНЕФЮЪЬтЃЌЫљвдЮвУЧвЊЖдУПвЛДЮЩЯЯпНјааИДХЬзмНсЃЌДгНЬбЕжаГЩГЄЃЌВЂзмНсГіПьЫйЖЈЮЛЮЪЬтЕФММФмЃЌвдМАЬсЩ§ЙЄОпЪЙгУЕФФмСІЁЃ
ЮвУЧвдДЫЮЊЫМТЗЃЌЭЈЙ§ОЉЖЋЗўЮёЪаГЁНјааж№вЛНщЩмЁЃ
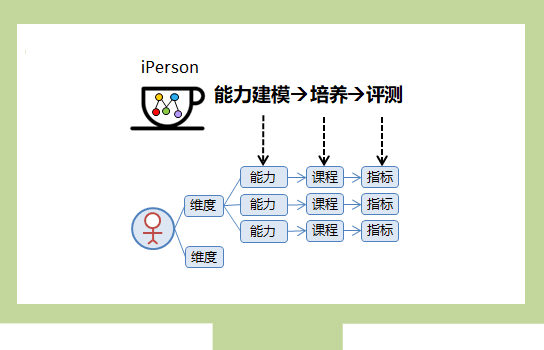
вЛЁЂЪсРэБЁШѕЕу
евГіБЁШѕЕуЕФЗНЗЈгаКмЖрЃЌЗўЮёЪаГЁзїЮЊвЛИіЧАЬЈЯЕЭГЃЌЮвУЧДгзюгАЯьгУЛЇИажЊКЭЬхбщЕФНЧЖШНјааЪсРэЁЃ

ЖўЁЂЯЕЭГИФдь
ЭЈЙ§ЪсРэЯЕЭГБЁШѕЕуЃЌечБ№ГіШЗШЯЕФИФдьЕуЁЃ
1. UMP МрПиБЈОЏ & ШежО
ЮвУЧГЃЫЕЃЌбаЗЂШЫдБгаСНжЛблОІЃЌвЛжЛЪЧМрПиБЈОЏЃЌСэвЛжЛОЭЪЧШежОЃЌЫљвдЮоТлЪВУДЧщПіМрПиБЈОЏШежОвЛЖЈВЛФмЩйЁЃЭЈЙ§ВЩгУ
AOP ЕФЗНЪНЃЌЖдЙЄГЬЫљгаВуНјааЭГвЛЧаУцЬэМгМрПиБЈОЏКЭШежОЁЃ

ЬиБ№вЊЫЕЕФЪЧЃЌЩшжУСЫБЈОЏвЛЖЈвЊМДЪБДІРэКЭгХЛЏЃЌЮоТлЪЧадФмБЈОЏЛЙЪЧПЩгУТЪБЈОЏЃЌашзЈШЫИњНјЭЦЖЏгХЛЏЃЌШчЙћИФЖЏСПКмДѓЛђЗчЯеКмИпЃЌПЩЕїећБЈОЏуажЕБИзЂКѓЦкгХЛЏЃЌОЏабРЧРДСЫЕФЧщПіЁЃ
2. ШЗШЯДѓСїСПвГУцГЌЪБЪБМф
ГЌЪБЪБМфЕФЩшжУВЩгУЩйГЌЪБЁЂЖржиЪдЃЌетЪЕМЪЩЯЪЧвЛжжПьЫйЪЇАмВпТдЃЌШчЕкШ§ЗННгПкЕїгУГЌЪБЃЌШчЙћЩшжУЙ§ГЄЃЌдкЗУЮЪСПДѓЕФЪБКђЃЌОЭЛсЕМжТЧыЧѓЯпГЬЛ§бЙЁЂCPU
ьИпЕШЮЪЬтЁЃ
ГЌЪБЩшжУвЛЪЧШЋУцМьВщ MySQLЁЂJimDBЁЂJSF ЕШ RPC ЕїгУЕФГЌЪБЩшжУЃЌгШЦфЪЧДѓСїСПШыПкЕФЕїгУСДТЗЃЌЖўЪЧИљОнбЙВтНсЙћНсКЯОпЬхвЕЮёГЁОАНјааЩшжУЕїећЁЃ
3. НтОіТ§ SQL ЮЪЬт
Т§ SQL ЮЪЬтДѓЖрЪ§ЧщПіЯТЖМЪЧУЛгаЫїв§ЛђепЫїв§ЪЙгУДэЮѓв§Ц№ЕФЃЌШчЫїв§зжЖЮЪЧ varchar РраЭЃЌЕЋЪЧГЬађжаЧыЧѓ
DB ЕФЪБКђДЋЕФЪЧ long РраЭЃЌдьГЩЫїв§ЪЇаЇЁЃ
ЪзЯШЭЈЙ§ DBA евГіТ§ SQLЃЌЦфжажиЕуЙизЂЕїгУДЮЪ§ИпКЭЯьгІЫйЖШТ§ЕФ SQLЃЌЭЈЙ§ Query
ID евЕНЖдгІЕФ SQLЃЌШЛКѓЭЈЙ§ EXPLAIN жДааМЦЛЎВщПД SQL УќжаЕФЫїв§ЁЃЬэМгЫїв§вЛЖЈвЊНсКЯ
MySQL жДааМЦЛЎРДХаЖЯЃЌЭЌЪБЬэМг Index вЊзЂвтЧјЗжЖШЃЌЧјЗжЖШ =count(Distinct
Ыїв§жЕ)ЃЏзмЬѕЪ§ЃЌЧјЗжЖШдННгНќ 1ЃЌЫЕУїЧјЗжЖШдНИпЃЌВщбЏЕФЪБКђОЭЛсЙ§ТЫЕєИќЖрЕФааЪ§ОнЁЃШчЙћФГаЉ SQL
ВйзїгаДѓСПЕФ JOIN ВйзїЃЌОЭвЊЯыАьЗЈВ№Зж SQLЃЌаоИФДњТыТпМЃЌетвВЪЧвЛжжЦНКтЕФЙ§ГЬЁЃ

4. НЕМЖПЊЙи
НЕМЖПЊЙиПЩвдЗРжЙЮЪЬтЗЂЩњЕФЪБКђзМБИКУЕФЙІФмВЛПЩгУЃЌвдЯТЭМ Solr НЕМЖПЊЙиЮЊР§ЃЌЕБ so ГіЮЪЬтЪБЃЌЮвУЧПЩвдЙиБе
so ЕФаДТпМЃЌsa КЭ sb ВЛгАЯьМЬајаДЃЌЭЌЪБНЋЖСТпМЧаЛЛЕН saЃЌзіЕНЦНЛЌЧаЛЛЁЃЕБ so ЛжИДжЎКѓЃЌПЊЦє
so ЕФаДТпМЃЌНЋЖСТпМПЊЙиЧаЛЛЕН soЃЌвВФмзіЕНЦНЛЌЛжИДЁЃЕБШЛЃЌвЊзЂвт so ЙЪеЯЪБЖЮПЩФмГіЯжЕФЪ§ОнВЛвЛжТЮЪЬтЁЃ

5. ЖСаДЗжРы + ЖрМЖЛКДцВпТд
ЛКДцВпТдПЩвдгааЇЗРжЙЧыЧѓжБДяЪ§ОнПтЃЌдьГЩЪ§ОнПтбЙСІДѓЕФЮЪЬтЁЃБОДЮжиЙЙВЩгУЕФЛКДцВпТдЪЧ JVM+JimDB+DBЃЌЛКДцЕФЪ§ОнжївЊЪЧСаБэвГ
/ ЦЕЕРвГКЭЕЅЦЗвГЕФЗўЮёРрФПКЭЗўЮёаХЯЂЁЃдкЦєЖЏЛКДцВпТдЕФЙ§ГЬжаЃЌвВвЊПМТЧЛКДцЕФДЉЭИТЪЃЌвдДЫРДЕїећЛКДцзюгХЕФЙ§ЦкЪБМфЁЃ
ВЛНіШчДЫЃЌЮвУЧЛЙвЊНЋЛКДц JimDB жаМфМўЕФВЛЮШЖЈвђЫиЕФПМТЧЗХЕНБИАИжаЃЌШчЖрЛњЗПЕФВПЪ№ВЩгУМИжїМИДгЃЌжїДгжЎМфЪЧЗёжЇГжздЖЏЧаЛЛЕШЕШЁЃ

ЗўЮёаХЯЂЖрМЖЛКДцВпТдМмЙЙ
дкЪЙгУ JimDB ЛКДцЪБЃК
вЊзЂвтДѓ Key ЮЪЬтЃЌЗёдђСПвЛЩЯРДКмШнвзв§Ц№ЛКДцМЏШКЕФЕЅЦЌШШЕуЮЪЬтЃЌШчЗўЮёаХЯЂПЩвдИљОн SpuId
ЕФЮГЖШРДЩшжУ KeyЃЌЕЋЛКДцЗўЮёаХЯЂЛсдьГЩЪЕЪБМлИёбгГйЃЌПЩвдЭЈЙ§Ъ§ОнвьЙЙЕФЗНЪНЭЌВНМлИёЪ§ОнЁЃ
вЊзЂвтЛКДцЙ§ЦкЕФЮЪЬтЃЌВЛНЈвщЪЙгУ JimDB ЕФЙ§ЦкЩшжУЃЌЖјЪЧздЖЈвх timestamp гЩгІгУГЬађХаЖЯЪЧЗёЙ§ЦкЃЌетбљПЩвддк
DB хДЛњВЛШЗЖЈЛжИДЪБМфЕФЧщПіЯТЃЌШдФмДгЛКДцЛёШЁЪ§ОнЁЃ
ЖдгкФЧаЉЁАГпДчНЯаЁЁБЁЂЁАИпЦЕЕФЖСШЁВйзїЁБЁЂЁАБфИќВйзїНЯЩйЁБЕФЪ§ОнгІШЋВПгЩ JimDB РДПЙСПЃЌШчЗўЮёРрФПЃЌУПИіРрФП
ID зїЮЊЛКДц KeyЃЌПЩвдЭЈЙ§ЫЋаДЛђЪ§ОнвьЙЙЕФЗНЪНЁЃ
6. Solr джБИВпТдЃЈСаБэвГ / ЦЕЕРвГЃЉ
Solr ЕФЪЙгУжївЊЗўЮёгкЫбЫїКЭСаБэвГЖрЮЌЖШЕФМьЫїЃЌЕЋЪЧ Solr МЏШКЧщПіЗЧГЃВЛРжЙлЃЌШчЙћ Solr
хДЛњЃЌВЛНіЫбЫїВЛПЩгУЃЌИќдуИтЕФЪЧЗўЮёЪаГЁСаБэвГЭъШЋВЛПЩгУЃЌЫљвдЖд Solr ЕФджБИГЩЮЊЕБЮёжЎМБЁЃ
ЕБШЛ Solr ЕФджБИВпТдПЩвдВЮПМЗўЮёРрФПКЭЗўЮёаХЯЂЕФЖрМЖЛКДцВпТдЃЌЕЋЪЧСаБэвГПЩФмЩцМАЕНЕФШШЕуЮЪЬтКЭЗжвГТпМЖМЪЙЮЪЬтБфЕУИќМгИДдгЁЃЦфЪЕ
Solr ЕФзюгХЬцЛЛЗНАИгІИУЪЧ ESЃЌЕЋвЛЗНУцЯогкзЪдДЮЪЬтЃЌСэвЛЗНУцдМьЫїТпМИДдгЃЌИФдьЯогкЪБМфЬѕМўЃЌгжПЩФмЗчЯеМЋДѓЃЌЫљвджївЊПМТЧгУ
DB+JimDB НјааШнджЁЃ
ШчЙћгУ Solr ЫбЫїЧа DB&JimDB ЭЯЕзЃЌШчЙћ Solr НЕМЖ DBЃЌФЧ DB ЪЧЗёгазуЙЛЕФПЙбЙФмСІжЇГжЖрЮЌЖШЕФМьЫїЃПЮоТлдѕУДЯыЃЌетЖМВЛЪЧвЛИіКУжївтЃЌЖјЧвОбщИцЫпЮвУЧЃЌDB
ОЭВЛЪЧгУРДПЙСПЕФЁЃФЧШчЙћ Solr НЕМЖ JimDBЃЌШчКЮеыЖдЖрЮЌЖШМьЫїЩшМЦ JimDB ЕФ KeyЃПЙ§ЖрЕФ
Key ВЛНіЛсВњЩњДѓСПЕФЪ§ОнЃЌЛЙЛсгаЯрЕБЕФГЩБОБЃжЄЪ§ОнвЛжТадЃЌЫљвд JimDB ЭЯЕззїЮЊвЛИіЙ§ЖЩЗНАИЃЌЕБ
Solr НЕМЖ JimDB ЪБЃЌЭЌЪБвВНјааСЫНЕЮГЃЌжЛБЃжЄЭЈГЃМьЫїЗНЪНЁЃ
злЩЯЃЌЫфШЛ Sorl ПЩвдНЕМЖ JimDBЃЌЕЋ Solr ЕФЕЅЛњЮЪЬтЪЧБиаыНтОіЕФЮЪЬтЃЌЫљвд Solr
МЏШКВПЪ№ВЩгУЖўжївЛБИЕФджБИМмЙЙЃЌЕБРШЗЛЛњЗП Solr жї s0 ЛђТэОдЧХЕФ Solr жї S1 ГіЮЪЬтЃЌПЩвдЧаЛЛ
Solr БИЃЌШчЙћДЫЙ§ГЬжаЃЌSolr БИжБНгБЛСїСПЛїПхЃЌдђжБНгНЕМЖЧаЛЛЖдгІЛњЗПЕФ Jimdb ДгЃЌШчЙћЛЙЪЧПИВЛзЁЃЌОЭЦєЖЏОВЬЌвГЭЯЕзЁЃ

7. ЪзвГЗжСїМгди
ЙйЭјЪзвГЪЧвЛИіЭјеОЕФУХЛЇЃЌШчЙћЪзвГНјВЛШЅЃЌФЧзїЮЊвЛИіНЛвзЦНЬЈИќВЛФмНјШыСаБэвГЁЂЕЅЦЗвГЛђНсЫувГСЫЃЌЫљвдЬиБ№ашвЊзЂвтЪзвГЕФМгдиадФмКЭПЊЬьДАЕФЮЪЬтЃЌвВе§ЛљгкДЫЃЌЖдЪзвГЕФМгдиВЩгУвьВНЗжСїМгдиЃЌВЛЭЌЕФЧјгђЕїгУВЛЭЌЕФЧыЧѓЃЌВЛЭЌЕФЧыЧѓЪ§ОнгжЯрЛЅИєРыЃЌВЂЭЈЙ§ЗжСїМгдиЬсЩ§МгдиЫйЖШЃЌЭЌЪБВЛАбМІЕАЖМЗХдквЛИіРКзгРяЃЌБЃжЄвГУцЕФШнджКЭНЕМЖЁЃ

8. ЕЅЦЗвГМгдигХЛЏ
ЗжСїМгдиЕФЫМЯывВПЩвдгІгУдкЕЅЦЗвГжаЃЌвдБЃжЄПЩЯИСЃЖШЕиНЕМЖЁЃЕЅЦЗвГЕФЬиЪтаддкгкЪЕЪБМлИёЃЌжБНгВЩгУЛКДцПЩФмЛсдьГЩМлИёбгГйЃЌЕМжТдкЕЅЦЗвГПДЕНЕФМлИёгыНсЫувГВЛвЛжТЃЌЫљвдЖдЕЅЦЗвГЬэМгЛКДцЪБДІРэЪЕЪБМлИёашвЊНјааЫЋаДВйзїЃЌвдДЫБЃжЄЕЅЦЗвГМлИёЕФЪЕЪБадЁЃ

ЗЂВМЗўЮёИќаТМлИёЃЌаД MySQLЃЌЭЈЙ§вьВНШЮЮёИќаТжї JimDB МлИёЪ§ОнЁЃЗўЮёаХЯЂЖСШЁжї JimDB
жаМлИёЃЌЮоЙ§ЦкдђжБНгЗЕЛиЃЌЙ§ЦкЛђЮДУќжадђЗУЮЪжї MySQLЃЌЛёШЁзюаТЪ§ОнЗЕЛигУЛЇЃЌЭЌЪБвьВНИќаТжї JimDB
МлИёЁЃ
Ш§ЁЂЩЯЯп
1. бЙВт
ЭЈЙ§ЪсРэЯЕЭГБЁШѕЕуВЂНјааЯЕЭГИФдьВПЪ№ЩЯЯпжЎКѓЃЌЮвУЧОЭвЊЖдЯпЩЯеце§ФмГадиФмСІНјаабЙВтЃЌЭЈЙ§бЙВтжЊЕРЯЕЭГЕФМЋЯожЕЪЧЖрДѓЃЌЕБЯЕЭГГаЪмВЛзЁЗУЮЪЪБЃЌОЭЛсдйБЉТЖГіЦПОБЃЌШчЗўЮёЦї
CPUЁЂЪ§ОнПтЁЂФкДцЁЂЯьгІЫйЖШЕШЃЌДгЖјДйЪЙЮвУЧдйНјаагХЛЏЁЃЯпЩЯбЙВтЪЧдкСшГПвЛСНЕуЃЌДгЯпЩЯАўРыГівЛаЁВПЗжМЏШКЃЌЫљгаЗўЮёЦїКЭХфжУЪЙгУЕФЖМЪЧЯпЩЯецЪЕЕФГЁОАНјаабЙВтЃЌбЙВтГЁОАЗжЮЊЖСвЕЮёКЭаДвЕЮёЁЃ

ЪзЯШЃЌЮвУЧНјааСЫСНДЮбЙВтЃЌдкЮДгХЛЏЧАНјааСЫвЛДЮбЙВтЃЌЭЈЙ§ЖдбЙВтНсЙћЕФЗжЮіЃЌПДПДЯЕЭГЦПОБжївЊГіЯждкФФРяЁЃЕквЛДЮбЙВтНсЙћЗЂЯжДѓСПЧыЧѓДЉЭИжБНгЕїгУ
DBЃЌдьГЩ DB ЕФадФмМБОчЯТНЕЃЌЪ§ОнПтЗўЮёЦїЕФ CPU ЖрДЮьИпЃЌетГЩЮЊЮвУЧжиЙЙгХЛЏЕФжиЕуЃЌгХЛЏТ§
SQLЃЌНјааЪ§ОнПтЖСаДЗжРыЃЌЬэМгЖрМЖЛКДцЃЌгХЛЏЯЕЭГЕїгУЕШЁЃ
ИљОнЕквЛДЮбЙВтНсЙћНсЙћНјаагХЛЏКѓЃЌЕкЖўДЮбЙВтадФмгаСЫКмДѓЕФЬсЩ§ЁЃ
2. бнСЗ
дкбЙВтбнСЗЙ§ГЬжаЃЌвВБЉТЖГіКмЖрЮЪЬтЃЌШчЪ§ОнХфжУДэЮѓЮДаЃбщЁЂЗўЮёЦїФкДцЮДЕїећЁЂЪЙгУаТРЉШнЛњЦїбЙВтЕШЃЌетЕМжТГіЯжСЫвЛСЌДЎЕФЮЪЬтЁЃбЙВтПЊЪМЗўЮёЦї
CPU90%ЃЌЪ§ОнПтЮоШЮКЮЯьгІЃЌвђЮЊЪ§ОнПтХфжУДэЮѓЕМжТЗўЮёЦїИљБОУЛгаСЌНгЕНЪ§ОнПтЁЃЗўЮёЦїФкДц 1G
дьГЩЦЕЗБ Full GCЃЌадФмзмЪЧЬсЩ§ВЛЩЯШЅЁЃаТЗўЮёЦїдьГЩКмЖрХфжУЮДЭЌВНЁЂШЈЯоЮДЩъЧыЃЌЛЈЗбКмЖрЪБМфНтОіЃЌгАЯьбЙВтжїСїГЬЁЃ
3. дЄАИ
дЄАИЕФжДааАќРЈЗЂЯжЮЪЬтЁЂЖЈЮЛЮЪЬтКЭНтОіЮЪЬтЁЃЗЂЯжЮЪЬтвЊНсКЯШэгВМўЮЪЬтЃЌЖЈЮЛЮЪЬтАќРЈМрПиБЈОЏКЭШежОЗжЮіЃЌетОЭвЊПДжЎЧАЬэМгМрПиЕФСЃЖШКЭШежОЪЧЗёДђЕФгагУЃЌзюКѓОЭЪЧНтОіЮЪЬтЁЃ
ЯЕЭГЩЯЯпжЎКѓЃЌЯЕЭГадФмИКдивВТдгаЦЎИпЃЌUMP БЈОЏвВНгѕрЖјжСЃЌЭЈЙ§МрПиКЭШежОбИЫйХХВщЯпЩЯвўЛМКЭЗчЯеЃЌЙЉВЛЭЌГЬЖШЦєгУНЕМЖдЄАИЁЃ
ЫФЁЂИДХЬ
ЗўЮёЪаГЁетДЮЯЕЭГжиЙЙЛЙЪЧЗЧГЃЫГРћЕФЁЃЖјдкећИіЙ§ГЬжавВБЉТЖГіСЫКмЖрЮЪЬтЃЌгавЛЕуЪЧЩЯЪіУЛгаЬсЕНЕФЃЌФЧОЭЪЧаФРэвђЫиЕФХрбЕЁЃШчдкбЙВтбнСЗЪБЃЌЧАЦкгЩгкгіЕНИїжжЮЪЬтЕМжТНсЙћГйГйВЛФмЕНДядЄЦкаЇЙћЃЌећЬхЭХЖгПЊЪМГіЯжМБдъЃЌДІРэВйзїПЊЪМБфаЮЃЌГіЯжжЪвЩЩљвєНјааздЮвЗёЖЈЕШЃЌЛЙКУКѓЦкМДЪБЕїећЃЌЙ§ГЬж№НЅНјШые§ЙьЃЌДѓМвПЊЪМТ§Т§ЛжИДГЃЬЌЁЃ
ЫљвдЃЌеце§ЩЯЯпЧАЮвУЧОЭПЊЪМНјааСЫаЁИДХЬЃЌеыЖдаФРэаФЬЌНјааСЫЕїећКЭХрбЕЃЌВЂЭъЩЦСЫдЄАИЕШФкШнЁЃдкЩЯЯпЪБГіЯжЕФЮЪЬтЃЌЭХЖгБЃГжКмКУЕФаФЬЌДІРэЯпЩЯЕФЮЪЬтЃЌЖјећИіЯЕЭГвВЗЧГЃИјСІЕиЮШЖЈдЫааЁЃ
змНс
зюКѓЃЌвђЮЊЮвУЧвЊДђдьЕФВЛЪЧвЛИіЯЕЭГЃЌвВВЛЪЧвЛЖбЯЕЭГЃЌЖјЪЧвЛИіЦНЬЈЩњЬЌЃЌвЊФмЙЛГжајЕиЬсИпЯЕЭГЕФдЫгЊФмСІЁЃетРяЛЙЪЧвдЁАОЋДђЯИЫуЃЌДѓЕРжСМђЁБетОфЛАНсЪјДЫДЮОЉЖЋЗўЮёЪаГЁЕФзмНсЁЃ |