| БрМЭЦМі: |
БОЮФРДздгк51ctoЃЌЮФеТДгвьВНЛЏКЭВЂааЛЏСНИіЗНАИжаИјДѓМвНщЩмШчКЮДІРэМмЙЙЩшМЦжаЕФИпВЂЗЂетИіЮЪЬтЁЃ
|
|
ИпВЂЗЂЕФДѓЩБЦїЃКвьВНЛЏ
ЭЌВНКЭвьВНЃЌзшШћКЭЗЧзшШћ
ЭЌВНКЭвьВНЃЌзшШћКЭЗЧзшШћЃЌетМИИіДЪвбОЪЧРЯЩњГЃЬИЃЌЕЋЪЧЛЙЪЧгаКмЖрЭЌбЇЗжВЛЧхГўЃЌвдЮЊЭЌВНПЯЖЈОЭЪЧзшШћЃЌвьВНПЯЖЈОЭЪЧЗЧзшШћЃЌЦфЪЕЫћУЧВЂВЛЪЧвЛЛиЪТЁЃ
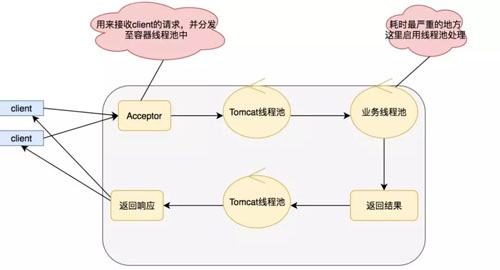
ЭЌВНКЭвьВНЙизЂЕФЪЧНсЙћЯћЯЂЕФЭЈаХЛњжЦЃК
ЭЌВНЃКЕїгУЗНашвЊжїЖЏЕШД§НсЙћЕФЗЕЛиЁЃ
вьВНЃКВЛашвЊжїЖЏЕШД§НсЙћЕФЗЕЛиЃЌЖјЪЧЭЈЙ§ЦфЫћЪжЖЮЃЌБШШчзДЬЌЭЈжЊЃЌЛиЕїКЏЪ§ЕШЁЃ
зшШћКЭЗЧзшШћжївЊЙизЂЕФЪЧЕШД§НсЙћЗЕЛиЕїгУЗНЕФзДЬЌЃК
зшШћЃКЪЧжИНсЙћЗЕЛижЎЧАЃЌЕБЧАЯпГЬБЛЙвЦ№ЃЌВЛзіШЮКЮЪТЁЃ
ЗЧзшШћЃКЪЧжИНсЙћдкЗЕЛижЎЧАЃЌЯпГЬПЩвдзівЛаЉЦфЫћЪТЃЌВЛЛсБЛЙвЦ№ЁЃ
ПЩвдПДМћЭЌВНКЭвьВНЃЌзшШћКЭЗЧзшШћжївЊЙизЂЕФЕуВЛЭЌЃЌгаШЫЛсЮЪЭЌВНЛЙФмЗЧзшШћЃЌвьВНЛЙФмзшШћ?
ЕБШЛЪЧПЩвдЕФЃЌЯТУцЮЊСЫИќКУЕФЫЕУїЫќУЧЕФзщКЯжЎМфЕФвтЫМЃЌгУМИИіМђЕЅЕФР§згЫЕУїЃК
ЭЌВНзшШћЃКЭЌВНзшШћЛљБОвВЪЧБрГЬжазюГЃМћЕФФЃаЭЃЌДђИіБШЗНФуШЅЩЬЕъТђвТЗўЃЌФуШЅСЫжЎКѓЗЂЯжвТЗўТєЭъСЫЃЌФЧФуОЭдкЕъРяУцвЛжБЕШЃЌЦкМфВЛзіШЮКЮЪТ(АќРЈПДЪжЛњ)ЃЌЕШзХЩЬМвНјЛѕЃЌжБЕНгаЛѕЮЊжЙЃЌетИіаЇТЪКмЕЭЁЃ
ЭЌВНЗЧзшШћЃКЭЌВНЗЧзшШћдкБрГЬжаПЩвдГщЯѓЮЊвЛИіТжбЏФЃЪНЃЌФуШЅСЫЩЬЕъжЎКѓЃЌЗЂЯжвТЗўТєЭъСЫЁЃ
етИіЪБКђВЛашвЊЩЕЩЕЕФЕШзХЃЌФуПЩвдШЅЦфЫћЕиЗНБШШчФЬВшЕъЃЌТђБЫЎЃЌЕЋЪЧФуЛЙЪЧашвЊЪБВЛЪБЕФШЅЩЬЕъЮЪРЯАхаТвТЗўЕНСЫТ№ЁЃ
вьВНзшШћЃКвьВНзшШћетИіБрГЬРяУцгУЕФНЯЩйЃЌгаЕуРрЫЦФуаДСЫИіЯпГЬГиЃЌsubmit ШЛКѓТэЩЯ future.get()ЃЌетбљЯпГЬЦфЪЕЛЙЪЧЙвЦ№ЕФЁЃ
гаЕуЯёФуШЅЩЬЕъТђвТЗўЃЌетИіЪБКђЗЂЯжвТЗўУЛгаСЫЃЌетИіЪБКђФуОЭИјРЯАхСєИіЕчЛАЃЌЫЕвТЗўЕНСЫОЭИјЮвДђЕчЛАЃЌШЛКѓФуОЭЪизХетИіЕчЛАЃЌвЛжБЕШзХЫќЯьЪВУДЪТвВВЛзіЁЃетбљИаОѕЕФШЗгаЕуЩЕЃЌЫљвдетИіФЃЪНгУЕУБШНЯЩйЁЃ
вьВНЗЧзшШћЃКетвВЪЧЯждкИпВЂЗЂБрГЬЕФвЛИіКЫаФЃЌвВЪЧНёЬьжївЊНВЕФвЛИіКЫаФЁЃ
КУБШФуШЅЩЬЕъТђвТЗўЃЌвТЗўУЛСЫЃЌФужЛашвЊИјРЯАхЫЕетЪЧЮвЕФЕчЛАЃЌвТЗўЕНСЫОЭДђЁЃШЛКѓФуОЭЫцаФЫљгћЕФШЅЭцЃЌвВВЛгУВйаФвТЗўЪВУДЪБКђЕНЃЌвТЗўвЛЕНЃЌЕчЛАвЛЯьОЭПЩвдШЅТђвТЗўСЫЁЃ
ЭЌВНзшШћ PK вьВНЗЧзшШћ
ЩЯУцвбОПДЕНСЫЭЌВНзшШћЕФаЇТЪЪЧЖрУДЕФЕЭЃЌШчЙћЪЙгУЭЌВНзшШћЕФЗНЪНШЅТђвТЗўЃЌФугаПЩФмвЛЬьжЛФмТђвЛМўвТЗўЃЌЦфЫћЪВУДЪТЖМВЛФмИЩ;ШчЙћгУвьВНЗЧзшШћЕФЗНЪНШЅТђЃЌТђвТЗўжЛЪЧФувЛЬьжаНјааЕФвЛИіаЁЪТЁЃ
ЮвУЧАбетИігГЩфЕНЮвУЧДњТыжаЃЌЕБЮвУЧЕФЯпГЬЗЂЩњвЛДЮ RPC ЕїгУЛђеп HTTP ЕїгУЃЌгжЛђепЦфЫћЕФвЛаЉКФЪБЕФ
IO ЕїгУЁЃ
ЗЂЦ№жЎКѓЃЌШчЙћЪЧЭЌВНзшШћЃЌЮвУЧЕФетИіЯпГЬОЭЛсБЛзшШћЙвЦ№ЃЌжБЕННсЙћЗЕЛиЃЌЪдЯывЛЯТЃЌШчЙћ IO ЕїгУКмЦЕЗБФЧЮвУЧЕФ
CPU ЪЙгУТЪЛсКмЕЭКмЕЭЁЃ
е§ЫљЮНЪЧЮяОЁЦфгУЃЌМШШЛ CPU ЕФЪЙгУТЪБЛ IO ЕїгУИуЕУКмЕЭЃЌФЧЮвУЧОЭПЩвдЪЙгУвьВНЗЧзшШћЁЃ
ЕБЗЂЩњ IO ЕїгУЪБЮвВЂВЛТэЩЯЙиаФНсЙћЃЌЮвжЛашвЊАбЛиЕїКЏЪ§аДШыетДЮ IO ЕїгУЃЌетИіЪБКђЯпГЬПЩвдМЬајДІРэаТЕФЧыЧѓЃЌЕБ
IO ЕїгУНсЪјЪБЃЌЛсЕїгУЛиЕїКЏЪ§ЁЃ
ЖјЮвУЧЕФЯпГЬЪМжеДІгкУІТЕжЎжаЃЌетбљОЭФмзіИќЖрЕФгавтвхЕФЪТСЫЁЃетРяЪзЯШвЊЫЕУїЕФЪЧЃЌвьВНЛЏВЛЪЧЭђФмЃЌвьВНЛЏВЂВЛФмЫѕЖЬФуећИіСДТЗЕїгУЪБМфГЄЕФЮЪЬтЃЌЕЋЪЧЫќФмМЋДѓЕФЬсЩ§ФуЕФзюДѓ
QPSЁЃ
вЛАуЮвУЧЕФвЕЮёжагаСНДІБШНЯКФЪБЃК
CPUЃКCPU КФЪБжИЕФЪЧЮвУЧЕФвЛАуЕФвЕЮёДІРэТпМЃЌБШШчвЛаЉЪ§ОнЕФдЫЫуЃЌЖдЯѓЕФађСаЛЏЁЃетаЉвьВНЛЏЪЧВЛФмНтОіЕФЃЌЕУашвЊППвЛаЉЫуЗЈЕФгХЛЏЃЌЛђепвЛаЉИпадФмПђМмЁЃ
IO WaitЃКIO КФЪБОЭЯёЮвУЧЩЯУцЫЕЕФ,вЛАуЗЂЩњдкЭјТчЕїгУЃЌЮФМўДЋЪфжаЕШЕШЃЌетИіЪБКђЯпГЬвЛАуЛсЙвЦ№зшШћЁЃЖјЮвУЧЕФвьВНЛЏЭЈГЃгУгкНтОіетВПЗжЕФЮЪЬтЁЃ
ФФаЉПЩвдвьВНЛЏ
ЩЯУцЫЕСЫвьВНЛЏЪЧгУгкНтОі IO зшШћЕФЮЪЬтЃЌЖјЮвУЧвЛАуЯюФПжаПЩвдЪЙгУвьВНЛЏЕФЧщПіШчЯТЃК
Servlet вьВНЛЏ
Spring MVC вьВНЛЏ
RPC ЕїгУШч(DubboЃЌThrift)ЃЌHTTP ЕїгУвьВНЛЏ
Ъ§ОнПтЕїгУЃЌЛКДцЕїгУвьВНЛЏ
ЯТУцЮвЛсДгЩЯУцМИИіЗНУцНјаавьВНЛЏЕФНщЩмЁЃ
Servlet вьВНЛЏ
Ждгк Java ПЊЗЂГЬађдБРДЫЕ Servlet ВЂВЛФАЩњЃЌдкЯюФПжаВЛТлФуЪЙгУ Struts2ЃЌЛЙЪЧЪЙгУЕФ
Spring MVCЃЌБОжЪЩЯЖМЪЧЗтзАЕФ ServletЁЃ
ЕЋЪЧЮвУЧвЛАуЕФПЊЗЂЖМЪЧЪЙгУЕФЭЌВНзшШћЃЌФЃЪНШчЯТЃК

ЩЯУцЕФФЃЪНгХЕудкгкБрТыМђЕЅЃЌЪЪКЯдкЯюФПЦєЖЏГѕЦкЃЌЗУЮЪСПНЯЩйЃЌЛђепЪЧ CPU дЫЫуНЯЖрЕФЯюФПЁЃ
ШБЕудкгкЃЌвЕЮёТпМЯпГЬКЭ Servlet ШнЦїЯпГЬЪЧЭЌвЛИіЃЌвЛАуЕФвЕЮёТпМзмЕУЗЂЩњЕу IOЃЌБШШчВщбЏЪ§ОнПтЃЌБШШчВњЩњ
RPC ЕїгУЃЌетИіЪБКђОЭЛсЗЂЩњзшШћЁЃ
ЖјЮвУЧЕФ Servlet ШнЦїЯпГЬПЯЖЈЪЧгаЯоЕФЃЌЕБ Servlet ШнЦїЯпГЬЖМБЛзшШћЕФЪБКђЮвУЧЕФЗўЮёетИіЪБКђОЭЛсЗЂЩњОмОјЗУЮЪЃЌЯпГЬВЛЙЛЮвЕБШЛПЩвдЭЈЙ§діМгЛњЦїЕФвЛЯЕСаЪжЖЮРДНтОіетИіЮЪЬтЁЃ
ЕЋЪЧЫзЛАЫЕЕУКУППШЫВЛШчППздМКЃЌППБ№ШЫЬцЮвЗжЕЃЧыЧѓЃЌЛЙВЛШчЮвздМКИуЖЈЁЃ
Ыљвддк Servlet 3.0 жЎКѓжЇГжСЫвьВНЛЏЃЌЮвУЧВЩгУвьВНЛЏжЎКѓЃЌФЃЪНБфГЩШчЯТЃК
дкетРяЮвУЧВЩгУаТЕФЯпГЬДІРэвЕЮёТпМЃЌIO ЕїгУЕФзшШћОЭВЛЛсгАЯьЮвУЧЕФ Serlvet СЫЃЌЪЕЯжвьВН
Serlvet ЕФДњТывВБШНЯМђЕЅЃЌШчЯТЃК
@WebServlet(name
= "WorkServlet",urlPatterns = "/work",asyncSupported
=true)
public class WorkServlet extends HttpServlet{
private static final long serialVersionUID = 1L;
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse
resp) throws ServletException, IOException {
this.doPost(req, resp);
}
@Override
protected void doPost(HttpServletRequest req,
HttpServletResponse resp) throws ServletException,
IOException {
//ЩшжУContentType,ЙиБеЛКДц
resp.setContentType("text/plain;charset=UTF-8");
resp.setHeader("Cache-Control","private");
resp.setHeader("Pragma","no-cache");
final PrintWriter writer= resp.getWriter();
writer.println("РЯЪІМьВщзївЕСЫ");
writer.flush();
List<String> zuoyes=new ArrayList<String>();
for (int i = 0; i < 10; i++) {
zuoyes.add("zuoye"+i);;
}
//ПЊЦєвьВНЧыЧѓ
final AsyncContext ac=req.startAsync();
doZuoye(ac, zuoyes);
writer.println("РЯЪІВМжУзївЕ");
writer.flush();
}
private void doZuoye(final AsyncContext ac, final
List<String> zuoyes) {
ac.setTimeout(1*60*60*1000L);
ac.start(new Runnable() {
@Override
public void run() {
//ЭЈЙ§responseЛёЕУзжЗћЪфГіСї
try {
PrintWriter writer=ac.getResponse().getWriter();
for (String zuoye:zuoyes) {
writer.println("\""+zuoye+"\"ЧыЧѓДІРэжа");
Thread.sleep(1*1000L);
writer.flush();
}
ac.complete();
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
} |
ЪЕЯж Serlvet ЕФЙиМќдкгк HTTP ВЩШЁСЫГЄСЌНгЃЌвВОЭЪЧЕБЧыЧѓДђЙ§РДЕФЪБКђОЭЫугаЗЕЛивВВЛЛсЙиБеЃЌвђЮЊПЩФмЛЙЛсгаЪ§ОнЃЌжБЕНЗЕЛиЙиБежИСюЁЃ
AsyncContext ac=req.startAsync();гУгкЛёШЁвьВНЩЯЯТЮФЃЌКѓајЮвУЧЭЈЙ§етИівьВНЩЯЯТЮФНјааЛиЕїЗЕЛиЪ§ОнЃЌгаЕуЯёЮвУЧТђвТЗўЕФЪБКђЃЌСєИјРЯАхвЛИіЕчЛАЁЃ
ЖјетИіЩЯЯТЮФвВЪЧвЛИіЕчЛАЃЌЕБгавТЗўЕНЕФЪБКђЃЌвВОЭЪЧЕБгаЪ§ОнзМБИКУЕФЪБКђОЭПЩвдДђЕчЛАЗЂЫЭЪ§ОнСЫЁЃac.complete();гУРДНјааГЄСДНгЕФЙиБеЁЃ
Spring MVC вьВНЛЏ
ЯждкЦфЪЕКмЩйШЫРДНјаа Serlvet БрГЬЃЌЖМЪЧжБНгВЩгУЯжГЩЕФвЛаЉПђМмЃЌБШШч Struts2ЃЌSpring
MVCЁЃЯТУцНщЩмЯТЪЙгУ Spring MVC ШчКЮНјаавьВНЛЏЃК
ЪзЯШШЗШЯФуЕФЯюФПжаЕФ Servlet ЪЧ 3.0 вдЩЯЃЌЦфДЮ Spring MVC 4.0+ЃК
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>3.1.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>4.2.3.RELEASE</version>
</dependency> |
web.xml ЭЗВПЩљУїЃЌБиаывЊ 3.0ЃЌFilter КЭ Serverlet ЩшжУЮЊвьВНЃК
<?xml version="1.0"
encoding="UTF-8"?>
<web-app version="3.0" xmlns="http://java.sun.com/xml
/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee
http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd">
<filter>
<filter-name>testFilter</filter-name>
<filter-class>com.TestFilter</filter-class>
<async-supported>true</async-supported>
</filter>
<servlet>
<servlet-name>mvc-dispatcher</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet
</servlet-class>
.........
<async-supported>true</async-supported>
</servlet> |
ЪЙгУ Spring MVC ЗтзАСЫ Servlet ЕФ AsyncContextЃЌЪЙгУЦ№РДБШНЯМђЕЅЁЃвдЧАЮвУЧЭЌВНЕФФЃЪНЕФ
Controller ЪЧЗЕЛи ModelAndViewЁЃ
ЖјвьВНФЃЪНжБНгЩњГЩвЛИі DeferredResult(жЇГжЮвУЧГЌЪБРЉеЙ)МДПЩБЃДцЩЯЯТЮФЃЌЯТУцИјГіШчКЮКЭЮвУЧ
HttpClient ДюХфЕФМђЕЅ demoЃК
@RequestMapping(value="/asynctask",
method = RequestMethod.GET)
public DeferredResult<String> asyncTask()
throws IOReactorException {
IOReactorConfig ioReactorConfig = IOReactorConfig.custom().setIoThreadCount(1).build();
ConnectingIOReactor ioReactor = new DefaultConnectingIOReactor(ioReactorConfig);
PoolingNHttpClientConnectionManager conManager
= new PoolingNHttpClientConnectionManager(ioReactor);
conManager.setMaxTotal(100);
conManager.setDefaultMaxPerRoute(100);
CloseableHttpAsyncClient httpclient = HttpAsyncClients.custom().setConnectionManager
(conManager).build();
// Start the client
httpclient.start();
//ЩшжУГЌЪБЪБМф200ms
final DeferredResult<String> deferredResult
= new DeferredResult<String>(200L);
deferredResult.onTimeout(new Runnable() {
@Override
public void run() {
System.out.println("вьВНЕїгУжДааГЌЪБЃЁthread id is
: " + Thread.currentThread().getId());
deferredResult.setResult("ГЌЪБСЫ");
}
});
System.out.println("/asynctask ЕїгУЃЁthread
id is : " + Thread.currentThread().getId());
final HttpGet request2 = new HttpGet("http://www.apache.org
/");
httpclient.execute(request2, new FutureCallback
<HttpResponse>()
{
public void completed(final HttpResponse response2)
{
System.out.println(request2.getRequestLine() +
"->" + response2.getStatusLine());
deferredResult.setResult(request2.getRequestLine()
+ "->" + response2.getStatusLine());
}
public void failed(final Exception ex) {
System.out.println(request2.getRequestLine() +
"->" + ex);
}
public void cancelled() {
System.out.println(request2.getRequestLine() +
" cancelled");
}
});
return deferredResult;
} |
зЂвтЃКдк Serlvet вьВНЛЏжагаИіЮЪЬтЪЧ Filter ЕФКѓжУНсЙћДІРэЃЌУЛЗЈЪЙгУЃЌЖдгкЮвУЧвЛаЉДђЕуЃЌНсЙћЭГМЦжБНгЪЙгУ
Serlvet вьВНЪЧУЛЗЈгУЕФЁЃ
дк Spring MVC жаОЭКмКУЕФНтОіСЫетИіЮЪЬтЃЌSpring MVC ВЩгУСЫвЛИіБШНЯШЁЧЩЕФЗНЪНЭЈЙ§ЧыЧѓзЊЗЂЃЌФмШУЧыЧѓдйДЮЭЈЙ§Й§ТЫЦїЁЃ
ЕЋЪЧгжв§ШыСЫаТЕФвЛИіЮЪЬтФЧОЭЪЧЙ§ТЫЦїЛсДІРэСНДЮЃЌетРяПЩвдЭЈЙ§ Spring MVC дДТыжаздЩэХаЖЯЕФЗНЗЈЁЃ
ЮвУЧПЩвддк Filter жаЪЙгУЯТУцетОфЛАРДНјааХаЖЯЪЧВЛЪЧЪєгк Spring MVC зЊЗЂЙ§РДЕФЧыЧѓЃЌДгЖјВЛДІРэ
Filter ЕФЧАжУЪТМўЃЌжЛДІРэКѓжУЪТМўЃК
Object asyncManagerAttr
= servletRequest.getAttribute(WEB_ASYNC_MANAGER_ATTRIBUTE);
return asyncManagerAttr instanceof WebAsyncManager
; |
ШЋСДТЗвьВНЛЏ
ЩЯУцЮвУЧНщЩмСЫ Serlvet ЕФвьВНЛЏЃЌЯраХЯИаФЕФЭЌбЇЖМПДГіРДЫЦКѕВЂУЛгаНтОіИљБОЕФЮЪЬтЃЌЮвЕФ IO
зшШћвРШЛДцдкЃЌжЛЪЧЛЛСЫИіЮЛжУЖјвбЁЃ
ЕБ IO ЕїгУЦЕЗБЭЌбљЛсШУвЕЮёЯпГЬГиПьЫйБфТњЃЌЫфШЛ Serlvet ШнЦїЯпГЬВЛБЛзшШћЃЌЕЋЪЧетИівЕЮёвРШЛЛсБфЕУВЛПЩгУЁЃ

ФЧУДдѕУДВХФмНтОіЩЯУцЕФЮЪЬтФи?Д№АИОЭЪЧШЋСДТЗвьВНЛЏЃЌШЋСДТЗвьВНзЗЧѓЕФЪЧУЛгазшШћЃЌДђТњФуЕФ CPUЃЌАбЛњЦїЕФадФмбЙеЅЕНМЋжТЁЃФЃаЭЭМШчЯТЃК
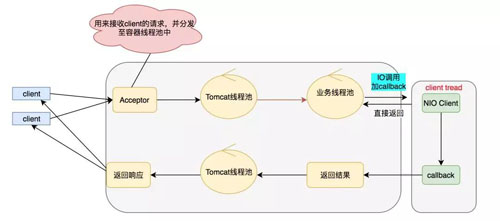
ОпЬхЕФ NIO Client ЕНЕззіСЫЪВУДЪТФиЃЌОпЬхШчЯТУцФЃаЭЃК
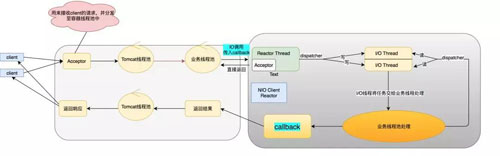
ЩЯУцОЭЪЧЮвУЧШЋСДТЗвьВНЕФЭМСЫ(ВПЗжЯпГЬГиПЩвдгХЛЏ)ЁЃШЋСДТЗЕФКЫаФдкгкжЛвЊЮвУЧгіЕН IO ЕїгУЕФЪБКђЃЌЮвУЧОЭПЩвдЪЙгУ
NIOЃЌДгЖјБмУтзшШћЃЌвВОЭНтОіСЫжЎЧАЫЕЕФвЕЮёЯпГЬГиБЛДђТњЕФоЯоЮГЁОАЁЃ
дЖГЬЕїгУвьВНЛЏ
ЮвУЧвЛАудЖГЬЕїгУЪЙгУ RPC Лђеп HTTPЃК
Ждгк RPC РДЫЕЃЌвЛАу ThriftЃЌHTTPЃЌMotan ЕШжЇГжЖМвьВНЕїгУЃЌЦфФкВПдРэвВЖМЪЧВЩгУЪТМўЧ§ЖЏЕФ
NIO ФЃаЭЁЃ
Ждгк HTTP РДЫЕЃЌвЛАуЕФ Apache HTTP Client КЭ Okhttp вВЖМЬсЙЉСЫвьВНЕїгУЁЃ
ЯТУцМђЕЅНщЩмЯТ HTTP вьВНЛЏЕїгУЪЧдѕУДзіЕФЁЃЪзЯШРДПДвЛИіР§згЃК
public class
HTTPAsyncClientDemo {
public static void main(String[] args) throws
ExecutionException, InterruptedException, IOReactorException
{
//ОпЬхВЮЪ§КЌвхЯТЮФЛсНВ
//apacheЬсЙЉСЫioReactorЕФВЮЪ§ХфжУЃЌетРяЮвУЧХфжУIO ЯпГЬЮЊ1
IOReactorConfig ioReactorConfig = IOReactorConfig.custom().setIoThreadCount(1).build();
//ИљОнетИіХфжУДДНЈвЛИіioReactor
ConnectingIOReactor ioReactor = new DefaultConnectingIOReactor(ioReactorConfig);
//asyncHttpClientЪЙгУPoolingNHttpClientConnectionManagerЙмРэЮвУЧПЭЛЇЖЫСЌНг
PoolingNHttpClientConnectionManager conManager
= new PoolingNHttpClientConnectionManager(ioReactor);
//ЩшжУзмЙВЕФСЌНгЕФзюДѓЪ§СП
conManager.setMaxTotal(100);
//ЩшжУУПИіТЗгЩЕФСЌНгЕФзюДѓЪ§СП
conManager.setDefaultMaxPerRoute(100);
//ДДНЈвЛИіClient
CloseableHttpAsyncClient httpclient = HttpAsyncClients.custom().setConnectionManager
(conManager).build();
// Start the client
httpclient.start();
// Execute request
final HttpGet request1 = new HttpGet("http://www.apache.org/");
Future<HttpResponse> future = httpclient.execute
(request1,
null);
// and wait until a response is received
HttpResponse response1 = future.get();
System.out.println(request1.getRequestLine() +
"->" + response1.getStatusLine());
// One most likely would want to use a callback
for operation result
final HttpGet request2 = new HttpGet("http://www.apache.org/");
httpclient.execute(request2, new FutureCallback
<HttpResponse>()
{
//CompleteГЩЙІКѓЛсЛиЕїетИіЗНЗЈ
public void completed(final HttpResponse response2)
{
System.out.println(request2.getRequestLine() +
"->" + response2.getStatusLine());
}
public void failed(final Exception ex) {
System.out.println(request2.getRequestLine() +
"->" + ex);
}
public void cancelled() {
System.out.println(request2.getRequestLine() +
" cancelled");
}
});
}
} |
ЯТУцИјГі httpAsync ЕФећИіРрЭМЃК
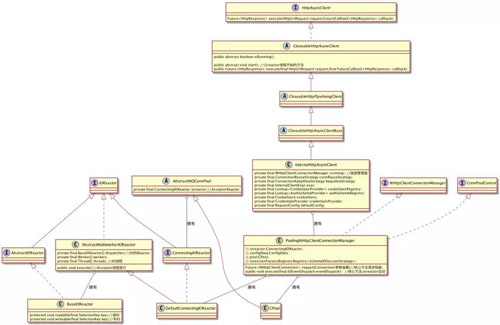
ЖдгкЮвУЧЕФ HTTPAysncClient зюКѓЪЙгУЕФЪЧ InternalHttpAsyncClientЃЌдк
InternalHttpAsyncClient жагаИі ConnectionManagerЃЌетИіОЭЪЧЮвУЧЙмРэСЌНгЕФЙмРэЦїЁЃ
Жјдк httpAsync жажЛгавЛИіЪЕЯжФЧОЭЪЧ PoolingNHttpClientConnectionManagerЁЃ
етИіСЌНгЙмРэЦїжагаСНИіЮвУЧБШНЯЙиаФЕФЃЌвЛИіЪЧ ReactorЃЌвЛИіЪЧ CpoolЃК
ReactorЃКЫљгаЕФ Reactor етРяЖМЪЧЪЕЯжСЫ IOReactor НгПкЁЃдк PoolingNHttpClientConnectionManager
жаЛсгагЕгавЛИі ReactorЃЌФЧОЭЪЧ DefaultConnectingIOReactorЃЌетИі
DefaultConnectingIOReactorЃЌИКд№ДІРэ AcceptorЁЃ
дк DefaultConnectingIOReactor гаИі excutor ЗНЗЈЃЌЩњГЩ IOReactor
вВОЭЪЧЮвУЧЭМжаЕФ BaseIOReactorЃЌНјаа IO ЕФВйзїЁЃетИіФЃаЭОЭЪЧЮвУЧЩЯУцЕФ 1.2.2
ЕФФЃаЭЁЃ
CPoolЃКдк PoolingNHttpClientConnectionManager жагаИі CPoolЃЌжївЊЪЧИКд№ПижЦЮвУЧСЌНгЃЌЮвУЧЩЯУцЫљЫЕЕФ
maxTotal КЭ defaultMaxPerRouteЃЌЖМЪЧгЩЦфНјааПижЦЁЃ
ШчЙћУПИіТЗгЩгаТњСЫЃЌЫќЛсЖЯПЊзюРЯЕФвЛИіСДНг;ШчЙћзмЙВЕФ total ТњСЫЃЌЫќЛсЗХШы leased ЖгСаЃЌЪЭЗХПеМфЕФЪБКђОЭЛсНЋЦфжиаТСЌНгЁЃ
Ъ§ОнПтЕїгУвьВНЛЏ
ЖдгкЪ§ОнПтЕїгУвЛАуЕФПђМмВЂУЛгаЬсЙЉвьВНЛЏЕФЗНЗЈЃЌетРяЭЦМіздМКЗтзАЛђепЪЙгУЭјЩЯПЊдДЕФЁЃ
вьВНЛЏВЂВЛЪЧИпВЂЗЂЕФвјЕЏЃЌЕЋЪЧгаСЫвьВНЛЏЕФШЗФмЬсИпФуЛњЦїЕФ QPSЃЌЭЬЭТСПЕШЕШЁЃ
ЩЯЪіНВЕФвЛаЉФЃаЭШчЙћФмКЯРэЕФзівЛаЉгХЛЏЃЌШЛКѓНјаагІгУЃЌЯраХФмЖдФуЕФЗўЮёгаКмДѓЕФАяжњЁЃ
ИпВЂЗЂДѓЩБЦїЃКВЂааЛЏ
ЯыБиШШАЎгЮЯЗЕФЭЌбЇаЁЪБКђЖМЛУЯыЙ§вЊЪЧздМКЛсЗжЩэжЎЪѕЃЌОЭФмвЛБпДђгЮЯЗвЛБпЩЯПЮСЫЁЃ
ПЩЯЇЯжЪЕжаВЂУЛгаетИіММЪѕЃЌФувЊУДжЛгаРЯРЯЪЕЪЕЕФЩЯПЮЃЌвЊУДОЭжЛгаЬгПЮШЅДђгЮЯЗСЫЁЃ
ЫфШЛдкЯжЪЕжаЮвУЧЮоЗЈЪЕЯжЗжЩэетбљЕФММЪѕЃЌЕЋЪЧЮвУЧПЩвддкМЦЫуЛњЪРНчжаЪЕЯжетбљЕФдИЭћЁЃ
МЦЫуЛњжаЕФЗжЩэЪѕ
МЦЫуЛњжаЕФЗжЩэЪѕВЛЪЧЬьЩњОЭгаСЫЁЃдк 1971 ФъЃЌгЂЬиЖћЭЦГіЕФШЋЧђЕквЛПХЭЈгУаЭЮЂДІРэЦї 4004ЃЌгЩ
2300 ИіОЇЬхЙмЙЙГЩЁЃ
ЕБЪБЃЌЙЋЫОЕФСЊКЯДДЪМШЫжЎвЛИъЕЧФІЖћОЭЬсГіДѓУћЖІЖІЕФЁАФІЖћЖЈТЩЁБЁЊЁЊУПЙ§ 18 ИідТЃЌаОЦЌЩЯПЩвдМЏГЩЕФОЇЬхЙмЪ§ФПНЋдіМгвЛБЖЁЃ
зюГѕЕФжїЦЕ 740KHz(УПУыдЫаа 74 ЭђДЮ)ЃЌЯждкЙ§СЫПь 50 ФъСЫЃЌДѓМвШЅТђЕчФдЕФЪБКђЛсЗЂЯжЯждкЕФжїЦЕЖМФмДяЕН
4.0GHZСЫ(УПУы 40 вкДЮ)ЁЃ
ЕЋЪЧжїЦЕдНИпДјРДЕФЪевцШДЪЧдНРДдНаЁЃК
ОнВтЫуЃЌжїЦЕУПдіМг 1GЃЌЙІКФНЋЩЯЩ§ 25 ЭпЃЌЖјдкаОЦЌЙІКФГЌЙ§ 150 ЭпКѓЃЌЯжгаЕФЗчРфЩЂШШЯЕЭГНЋЮоЗЈТњзуЩЂШШЕФашвЊЁЃгаВПЗж
CPU ЖМПЩвдгУРДМхМІЕАСЫЁЃ
СїЫЎЯпЙ§ГЄЃЌЪЙЕУЕЅЮЛЦЕТЪаЇФмЕЭЯТЃЌдНДѓЕФжїЦЕЦфЪЕећЬхадФмЗДЖјВЛШчаЁЕФжїЦЕЁЃ
ИъЕЧФІЖћШЯЮЊФІЖћЖЈТЩЮДРД 10-20 ФъЛсЪЇаЇЁЃ
дкЕЅКЫжїЦЕгіЕНЦПОБЕФЧщПіЯТЃЌЖрКЫ CPU гІдЫЖјЩњЃЌВЛНіЬсЩ§СЫадФмЃЌВЂЧвНЕЕЭСЫЙІКФЁЃ
ЫљвдЖрКЫ CPU ж№НЅГЩЮЊЯждкЪаГЁЕФжїСїЃЌетбљШУЮвУЧЕФЖрЯпГЬБрГЬвВИќМгЕФШнвзЁЃ
ЫЕЕНСЫЖрКЫ CPU ОЭвЛЖЈвЊЫЕ GPUЃЌДѓМвПЩФмЖдетИіБШНЯФАЩњЃЌЕЋЪЧвЛЫЕЕНЯдПЈОЭПЯЖЈВЛФАЩњЃЌБЪепИуЙ§вЛЖЮЪБМфЕФ
CUDA БрГЬЃЌЮвВХвтЪЖЕНетИіВХЪЧеце§ЕФВЂааМЦЫуЁЃ
ДѓМвЖМжЊЕРЭМЦЌЯёЫиЕуАЩЃЌБШШч 1920*1080 ЕФЭМЦЌга 210 ЭђИіЯёЫиЕуЃЌШчЙћЯывЊАбвЛеХЭМЦЌЕФУПИіЯёЫиЕуЖМНјаазЊЛЛвЛЯТЃЌФЧдкЮвУЧ
Java РяУцПЩФмОЭвЊбЛЗБщРњ 210 ЭђДЮЁЃ
ОЭЫуЮвУЧгУЖрЯпГЬ 8 КЫ CPUЃЌФЧвВЕУбЛЗМИЪЎЭђДЮЁЃЕЋЪЧШчЙћЪЙгУ CudaЃЌзюЖрПЩвд 365535*512
= 100661760(вЛвк)ИіЯпГЬВЂаажДааЃЌОЭетжжМЖБ№ЕФЭМЦЌФЧвВЪЧТэЩЯДІРэЭъГЩЁЃ
ЕЋЪЧ Cuda вЛАуЪЪКЯгкЭМЦЌетжжЃЌгаДѓСПЕФЯёЫиЕуашвЊЭЌЪБДІРэЃЌЕЋЪЧжИСюМЏКмЩйЫљвдТпМВЛФмЬЋИДдгЁЃ
гІгУжаЕФВЂаа
вЛЫЕЦ№ШУФуЕФЗўЮёИпадФмЕФЪжЖЮЃЌФЧУДвьВНЛЏЃЌВЂааЛЏетаЉПЯЖЈЛсЕквЛЪБМфдкФуФдКЃжаЯдЯжГіРДЃЌВЂааЛЏПЩвдгУРДХфКЯвьВНЛЏЃЌвВПЩвдгУРДЕЅЖРзігХЛЏЁЃ
ЮвУЧПЩвдЯыЯыгаетУДвЛИіашЧѓ,дкФуЯТЭтТєЖЉЕЅЕФЪБКђЃЌетБЪЖЉЕЅПЩФмЛЙашвЊВщгУЛЇаХЯЂЃЌелПлаХЯЂЃЌЩЬМваХЯЂЃЌВЫЦЗаХЯЂЕШЁЃ
гУЭЌВНЕФЗНЪНЕїгУЃЌШчЯТЭМЫљЪОЃК
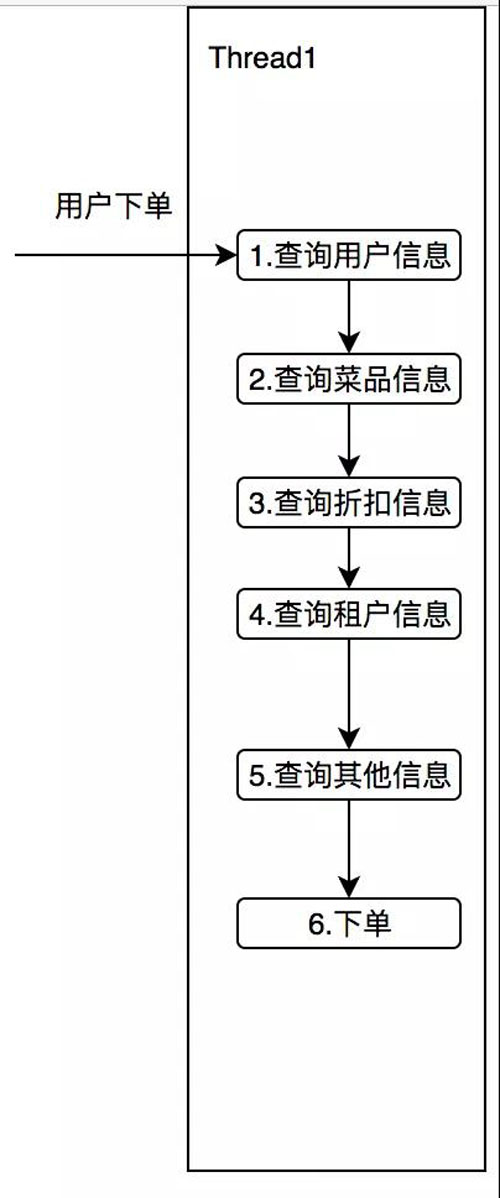
ЩшЯывЛЯТет 5 ИіВщбЏЗўЮёЃЌЦНОљУПДЮЯћКФ 50msЃЌФЧУДБОДЮЕїгУжСЩйЪЧ 250msЃЌЮвУЧЯИЯывЛЯТЃЌетЮхИіЗўЮёЦфЪЕВЂУЛгаШЮКЮЕФвРРЕЃЌЫЯШЛёШЁЫКѓЛёШЁЖМПЩвдЁЃ
ФЧУДЮвУЧПЩвдЯыЯыЃЌЪЧЗёПЩвдгУЖржигАЗжЩэжЎЪѕЃЌЭЌЪБЛёШЁетЮхИіЗўЮёЕФаХЯЂФи?
гХЛЏШчЯТЃК
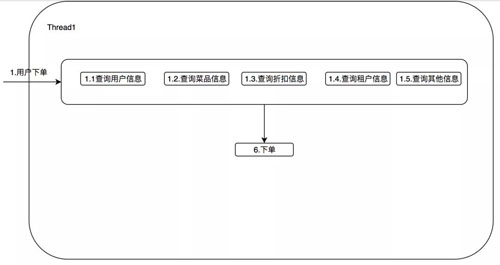
НЋетЮхИіВщбЏЗўЮёВЂааВщбЏЃЌдкРэЯыЧщПіЯТПЩвдгХЛЏжС 50msЁЃЕБШЛЫЕЦ№РДМђЕЅЃЌЮвУЧеце§ШчКЮТфЕиФи?
CountDownLatch/Phaser
CountDownLatch КЭ Phaser ЪЧ JDK ЬсЙЉЕФЭЌВНЙЄОпРрЁЃPhaser ЪЧ 1.7
АцБОжЎКѓЬсЙЉЕФЙЄОпРрЁЃЖј CountDownLatch ЪЧ 1.5 АцБОжЎКѓЬсЙЉЕФЙЄОпРрЁЃ
етРяМђЕЅНщЩмвЛЯТ CountDownLatchЃЌПЩвдНЋЦфПДГЩЪЧвЛИіМЦЪ§ЦїЃЌawait()ЗНЗЈПЩвдзшШћжСГЌЪБЛђепМЦЪ§ЦїМѕжС
0ЃЌЦфЫћЯпГЬЕБЭъГЩздМКФПБъЕФЪБКђПЩвдМѕЩй 1ЃЌРћгУетИіЛњжЦЮвУЧПЩвдгУРДзіВЂЗЂЁЃ
ПЩвдгУШчЯТЕФДњТыЪЕЯжЮвУЧЩЯУцЕФЯТЖЉЕЅЕФашЧѓЃК
public class
CountDownTask {
private static final int CORE_POOL_SIZE = 4;
private static final int MAX_POOL_SIZE = 12;
private static final long KEEP_ALIVE_TIME = 5L;
private final static int QUEUE_SIZE = 1600;
protected final static ExecutorService THREAD_POOL
= new ThreadPoolExecutor(CORE_POOL_SIZE, MAX_POOL_SIZE,
KEEP_ALIVE_TIME, TimeUnit.SECONDS, new LinkedBlockingQueue<>(QUEUE_SIZE));
public static void main(String[] args) throws
InterruptedException {
// аТНЈвЛИіЮЊ5ЕФМЦЪ§Цї
CountDownLatch countDownLatch = new CountDownLatch(5);
OrderInfo orderInfo = new OrderInfo();
THREAD_POOL.execute(() -> {
System.out.println("ЕБЧАШЮЮёCustomer,ЯпГЬУћзжЮЊ:"
+ Thread.currentThread().getName());
orderInfo.setCustomerInfo(new CustomerInfo());
countDownLatch.countDown();
});
THREAD_POOL.execute(() -> {
System.out.println("ЕБЧАШЮЮёDiscount,ЯпГЬУћзжЮЊ:"
+ Thread.currentThread().getName());
orderInfo.setDiscountInfo(new DiscountInfo());
countDownLatch.countDown();
});
THREAD_POOL.execute(() -> {
System.out.println("ЕБЧАШЮЮёFood,ЯпГЬУћзжЮЊ:"
+ Thread.currentThread().getName());
orderInfo.setFoodListInfo(new FoodListInfo());
countDownLatch.countDown();
});
THREAD_POOL.execute(() -> {
System.out.println("ЕБЧАШЮЮёTenant,ЯпГЬУћзжЮЊ:"
+ Thread.currentThread().getName());
orderInfo.setTenantInfo(new TenantInfo());
countDownLatch.countDown();
});
THREAD_POOL.execute(() -> {
System.out.println("ЕБЧАШЮЮёOtherInfo,ЯпГЬУћзжЮЊ:"
+ Thread.currentThread().getName());
orderInfo.setOtherInfo(new OtherInfo());
countDownLatch.countDown();
});
countDownLatch.await(1, TimeUnit.SECONDS);
System.out.println("жїЯпГЬЃК"+ Thread.currentThread().getName());
}
} |
НЈСЂвЛИіЯпГЬГи(ОпЬхХфжУИљОнОпЬхвЕЮёЃЌОпЬхЛњЦїХфжУ)ЃЌНјааВЂЗЂЕФжДааЮвУЧЕФШЮЮё(ЩњГЩгУЛЇаХЯЂЃЌВЫЦЗаХЯЂЕШ)ЃЌзюКѓРћгУ
await ЗНЗЈзшШћЕШД§НсЙћГЩЙІЗЕЛиЁЃ
CompletableFuture
ЯраХИїЮЛЭЌбЇвбОЗЂЯжЃЌCountDownLatch ЫфШЛФмЪЕЯжЮвУЧашвЊТњзуЕФЙІФмЕЋЪЧЦфШдШЛгаИіЮЪЬтЪЧЃЌЮвУЧЕФвЕЮёДњТыашвЊёюКЯ
CountDownLatch ЕФДњТыЁЃ
БШШчдкЮвУЧЛёШЁгУЛЇаХЯЂжЎКѓЃЌЮвУЧЛсжДаа countDownLatch.countDown()ЃЌКмУїЯдЮвУЧЕФвЕЮёДњТыЯдШЛВЛгІИУЙиаФетвЛВПЗжТпМЃЌВЂЧвдкПЊЗЂЕФЙ§ГЬжаЭђвЛаДТЉСЫЃЌФЧЮвУЧЕФ
await ЗНЗЈНЋжЛЛсБЛИїжжвьГЃЛНабЁЃ
Ыљвддк JDK 1.8 жаЬсЙЉСЫвЛИіРр CompletableFutureЃЌЫќЪЧвЛИіЖрЙІФмЕФЗЧзшШћЕФ
FutureЁЃ(ЪВУДЪЧ FutureЃКгУРДДњБэвьВННсЙћЃЌВЂЧвЬсЙЉСЫМьВщМЦЫуЭъГЩЃЌЕШД§ЭъГЩЃЌМьЫїНсЙћЭъГЩЕШЗНЗЈЁЃ)
ЮвУЧНЋУПИіШЮЮёЕФМЦЫуЭъГЩЕФНсЙћЖМгУ CompletableFuture РДБэЪОЃЌРћгУ CompletableFuture.allOf
ЛуОлГЩвЛИіДѓЕФ CompletableFutureЃЌФЧУДРћгУ get()ЗНЗЈОЭПЩвдзшШћЁЃ
public class
CompletableFutureParallel {
private static final int CORE_POOL_SIZE = 4;
private static final int MAX_POOL_SIZE = 12;
private static final long KEEP_ALIVE_TIME = 5L;
private final static int QUEUE_SIZE = 1600;
protected final static ExecutorService THREAD_POOL
= new ThreadPoolExecutor(CORE_POOL_SIZE, MAX_POOL_SIZE,
KEEP_ALIVE_TIME, TimeUnit.SECONDS, new LinkedBlockingQueue<>(QUEUE_SIZE));
public static void main(String[] args) throws
InterruptedException, ExecutionException, TimeoutException
{
OrderInfo orderInfo = new OrderInfo();
//CompletableFuture ЕФList
List<CompletableFuture> futures = new ArrayList<>();
futures.add(CompletableFuture.runAsync(() ->
{
System.out.println("ЕБЧАШЮЮёCustomer,ЯпГЬУћзжЮЊ:"
+ Thread.currentThread().getName());
orderInfo.setCustomerInfo(new CustomerInfo());
}, THREAD_POOL));
futures.add(CompletableFuture.runAsync(() ->
{
System.out.println("ЕБЧАШЮЮёDiscount,ЯпГЬУћзжЮЊ:"
+ Thread.currentThread().getName());
orderInfo.setDiscountInfo(new DiscountInfo());
}, THREAD_POOL));
futures.add( CompletableFuture.runAsync(() ->
{
System.out.println("ЕБЧАШЮЮёFood,ЯпГЬУћзжЮЊ:"
+ Thread.currentThread().getName());
orderInfo.setFoodListInfo(new FoodListInfo());
}, THREAD_POOL));
futures.add(CompletableFuture.runAsync(() ->
{
System.out.println("ЕБЧАШЮЮёOther,ЯпГЬУћзжЮЊ:"
+ Thread.currentThread().getName());
orderInfo.setOtherInfo(new OtherInfo());
}, THREAD_POOL));
CompletableFuture allDoneFuture = CompletableFuture.allOf(futures.toArray(new
CompletableFuture[futures.size()]));
allDoneFuture.get(10, TimeUnit.SECONDS);
System.out.println(orderInfo);
}
} |
ПЩвдПДМћЮвУЧЪЙгУ CompletableFuture ФмКмПьЕФЭъГЩашЧѓЃЌЕБШЛетЛЙВЛЙЛЁЃ
Fork/Join
ЮвУЧЩЯУцгУ CompletableFuture ЭъГЩСЫЖдЖрзщШЮЮёВЂаажДааЃЌЕЋЪЧЫќвРШЛЪЧвРРЕЮвУЧЕФЯпГЬГиЁЃ
дкЮвУЧЕФЯпГЬГижаЪЙгУЕФЪЧзшШћЖгСаЃЌвВОЭЪЧЕБЮвУЧФГИіЯпГЬжДааЭъШЮЮёЕФЪБКђашвЊЭЈЙ§етИізшШћЖгСаНјааЃЌФЧУДПЯЖЈЛсЗЂЩњОКељЃЌЫљвддк
JDK 1.7 жаЬсЙЉСЫ ForkJoinTask КЭ ForkJoinPoolЁЃ

ForkJoinPool жаУПИіЯпГЬЖМгаздМКЕФЙЄзїЖгСаЃЌВЂЧвВЩгУ Work-Steal ЫуЗЈЗРжЙЯпГЬМЂЖіЁЃ
Worker ЯпГЬгУ LIFO ЕФЗНЗЈШЁГіШЮЮёЃЌЕЋЪЧЛсгУ FIFO ЕФЗНЗЈШЅЭЕШЁБ№ШЫЖгСаЕФШЮЮёЃЌетбљОЭМѕЩйСЫЫјЕФГхЭЛЁЃ
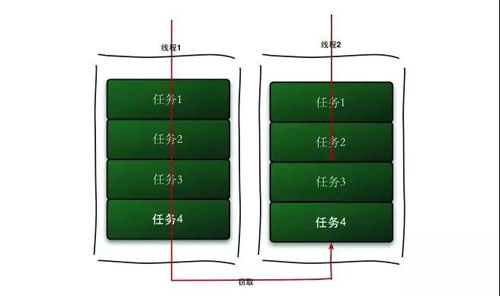
ЭјЩЯетИіПђМмЕФР§згКмЖрЃЌЮвУЧПДПДШчКЮЪЙгУДњТыЭъГЩЮвУЧЩЯУцЕФЯТЖЉЕЅашЧѓЃК
public class
OrderTask extends RecursiveTask<OrderInfo>
{
@Override
protected OrderInfo compute() {
System.out.println("жДаа"+ this.getClass().getSimpleName()
+ "ЯпГЬУћзжЮЊ:" + Thread.currentThread().getName());
// ЖЈвхЦфЫћЮхжжВЂааTasK
CustomerTask customerTask = new CustomerTask();
TenantTask tenantTask = new TenantTask();
DiscountTask discountTask = new DiscountTask();
FoodTask foodTask = new FoodTask();
OtherTask otherTask = new OtherTask();
invokeAll(customerTask, tenantTask, discountTask,
foodTask, otherTask);
OrderInfo orderInfo = new OrderInfo(customerTask.join(),
tenantTask.join(), discountTask.join(), foodTask.join(),
otherTask.join());
return orderInfo;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool(Runtime.getRuntime().availableProcessors()
-1 );
System.out.println(forkJoinPool.invoke(new OrderTask()));
}
}
class CustomerTask extends RecursiveTask<CustomerInfo>{
@Override
protected CustomerInfo compute() {
System.out.println("жДаа"+ this.getClass().getSimpleName()
+ "ЯпГЬУћзжЮЊ:" + Thread.currentThread().getName());
return new CustomerInfo();
}
}
class TenantTask extends RecursiveTask<TenantInfo>{
@Override
protected TenantInfo compute() {
System.out.println("жДаа"+ this.getClass().getSimpleName()
+ "ЯпГЬУћзжЮЊ:" + Thread.currentThread().getName());
return new TenantInfo();
}
}
class DiscountTask extends RecursiveTask<DiscountInfo>{
@Override
protected DiscountInfo compute() {
System.out.println("жДаа"+ this.getClass().getSimpleName()
+ "ЯпГЬУћзжЮЊ:" + Thread.currentThread().getName());
return new DiscountInfo();
}
}
class FoodTask extends RecursiveTask<FoodListInfo>{
@Override
protected FoodListInfo compute() {
System.out.println("жДаа"+ this.getClass().getSimpleName()
+ "ЯпГЬУћзжЮЊ:" + Thread.currentThread().getName());
return new FoodListInfo();
}
}
class OtherTask extends RecursiveTask<OtherInfo>{
@Override
protected OtherInfo compute() {
System.out.println("жДаа"+ this.getClass().getSimpleName()
+ "ЯпГЬУћзжЮЊ:" + Thread.currentThread().getName());
return new OtherInfo();
}
} |
ЮвУЧЖЈвхвЛИі Order Task ВЂЧвЖЈвхЮхИіЛёШЁаХЯЂЕФШЮЮёЃЌдк Compute жаЗжБ№ Fork
жДааетЮхИіШЮЮёЃЌзюКѓдкНЋетЮхИіШЮЮёЕФНсЙћЭЈЙ§ Join ЛёЕУЃЌзюКѓЭъГЩЮвУЧЕФВЂааЛЏЕФашЧѓЁЃ
parallelStream
дк JDK 1.8 жаЬсЙЉСЫВЂааСїЕФ APIЃЌЕБЮвУЧЪЙгУМЏКЯЕФЪБКђФмКмКУЕФНјааВЂааДІРэЁЃ
ЯТУцОйСЫвЛИіМђЕЅЕФР§згДг 1 МгЕН 100ЃК
public class
ParallelStream {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<Integer>();
for (int i = 1; i <= 100; i++) {
list.add(i);
}
LongAdder sum = new LongAdder();
list.parallelStream().forEach(integer -> {
// System.out.println("ЕБЧАЯпГЬ" + Thread.currentThread().getName());
sum.add(integer);
});
System.out.println(sum);
}
} |
parallelStream жаЕзВуЪЙгУЕФФЧвЛЬзвВЪЧ Fork/Join ЕФФЧвЛЬзЃЌФЌШЯЕФВЂЗЂГЬЖШЪЧПЩгУ
CPU Ъ§ -1ЁЃ
ЗжЦЌ
ПЩвдЯыЯѓгаетУДвЛИіашЧѓЃЌУПЬьЖЈЪБЖд ID дкФГИіЗЖЮЇжЎМфЕФгУЛЇЗЂШЏЃЌБШШчетИіЗЖЮЇжЎМфЕФгУЛЇгаМИАйЭђЃЌШчЙћИјвЛЬЈЛњЦїЗЂЕФЛАЃЌПЩФмШЋВПЗЂЭъашвЊКмОУЕФЪБМфЁЃ
ЫљвдЗжВМЪНЕїЖШПђМмБШШчЃКelastic-job ЖМЬсЙЉСЫЗжЦЌЕФЙІФмЃЌБШШчФугУ 50 ЬЈЛњЦїЃЌФЧУД
id%50 = 0 ЕФдкЕк 0 ЬЈЛњЦїЩЯ;=1 ЕФдкЕк 1 ЬЈЛњЦїЩЯЗЂШЏЃЌФЧУДЮвУЧЕФжДааЪБМфЦфЪЕОЭЗжЬЏЕНСЫВЛЭЌЕФЛњЦїЩЯСЫЁЃ
ВЂааЛЏзЂвтЪТЯю
ЯпГЬАВШЋЃКдк parallelStream жаЮвУЧСаОйЕФДњТыжаЪЙгУЕФЪЧ LongAdderЃЌВЂУЛгажБНгЪЙгУЮвУЧЕФ
Integer КЭ LongЃЌетИіЪЧвђЮЊдкЖрЯпГЬЛЗОГЯТ Integer КЭ Long ЯпГЬВЛАВШЋЁЃЫљвдЯпГЬАВШЋЮвУЧашвЊЬиБ№зЂвтЁЃ
КЯРэВЮЪ§ХфжУЃКПЩвдПДМћЮвУЧашвЊХфжУЕФВЮЪ§БШНЯЖрЃЌБШШчЮвУЧЕФЯпГЬГиЕФДѓаЁЃЌЕШД§ЖгСаДѓаЁЃЌВЂааЖШДѓаЁвдМАЮвУЧЕФЕШД§ГЌЪБЪБМфЕШЕШЁЃ
ЮвУЧЖМашвЊИљОнздМКЕФвЕЮёВЛЖЯЕФЕїгХЗРжЙГіЯжЖгСаВЛЙЛгУЛђепГЌЪБЪБМфВЛКЯРэЕШЕШЁЃ
ЩЯУцНщЩмСЫЪВУДЪЧВЂааЛЏЃЌВЂааЛЏЕФИїжжРњЪЗЃЌдк Java жаШчКЮЪЕЯжВЂааЛЏЃЌвдМАВЂааЛЏЕФзЂвтЪТЯюЁЃЯЃЭћДѓМвЖдВЂааЛЏгаИіБШНЯШЋУцЕФШЯЪЖЁЃ
зюКѓИјДѓМвЬсИіСНИіаЁЮЪЬтЃК
дкЮвУЧВЂааЛЏЕБжагаФГИіШЮЮёШчЙћФГИіШЮЮёГіЯжСЫвьГЃгІИУдѕУДАь?
дкЮвУЧВЂааЛЏЕБжагаФГИіШЮЮёЕФаХЯЂВЂВЛЪЧЧПвРРЕЃЌвВОЭЪЧШчЙћГіЯжСЫЮЪЬтетВПЗжаХЯЂЮвУЧвВПЩвдВЛашвЊЃЌЕБВЂааЛЏЕФЪБКђЃЌетжжШЮЮёГіЯжСЫвьГЃгІИУдѕУДАь? |








